概要
分析基盤向けデータ統合サービスtroccoでは、RubyでETLを行う機能があります。
この記事では、ETLの利用方法や、簡単なパフォーマンスを調査してみます。
troccoとは
https://trocco.io/lp/index.html
- 分析基盤向けのデータ統合サービス
- 分析に必要な様々なデータ(DB/ストレージ/SaaS/API)を、DWHに統合可能
- DWH自体の管理機能や、運用保守サポート機能も豊富
Ruby ETLの仕組み
troccoは内部的にEmbulkというOSSを利用しています。
Embulkには、Rubyで変換処理を記述できるembulk-filter-ruby_procというプラグインがあり、troccoはこのプラグインに対応しています。
そのため、行ごと・列ごと・複数行(page)ごとの変換処理を実現可能です。
Ruby ETLの利用方法
ざっくり以下の流れでETLが実現できます
- 変換処理(Rubyスクリプト)のコーディング
- Rubyスクリプトのレビュー・転送設定に登録
- 転送設定プレビュー
- 転送ジョブ実行
1. 変換処理(Rubyスクリプト)のコーディング
以下のようなETL用テンプレートをダウンロードします
列ごとの処理用テンプレート
1列の値だけを変換する場合、こちらのテンプレートを利用します。
列内の値がvalueという変数に入ってくるので、その値を利用して処理を記述します。
->(value) do
# Implement ETL here
# return value / 100.0
end
複数行(page)ごとの処理用テンプレート
複数の列を利用して処理を行う場合は、こちらのテンプレートを利用します。
recordsという引数に、複数レコードがHashの配列が入って来ます。
->(records) do
records.each do |rec|
# Implement ETL here
# rec['cvr'] = rec['cv'] / rec['click'].to_f
end
records.dup
end
今回は複数行処理用のテンプレートを利用し、以下のような簡易ETL処理を記述しました。
->(records) do
records.each do |rec|
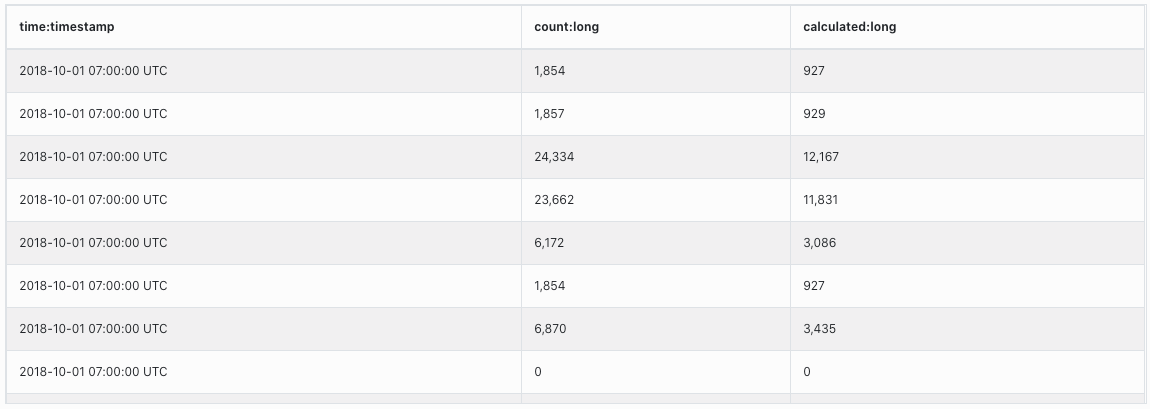
rec['count'] = rec['count'].to_f / 2
end
records.dup
end
2. Rubyスクリプトのレビュー・転送設定に登録
変換処理を記述したRubyスクリプトを、troccoの転送設定に登録します。
残念ながら、現時点ではtroccoの画面から直接コーディング・スクリプトの登録を行うことは出来ず、Slackなどでサポートに依頼する必要があります。
(画面からの登録は現在開発中とのこと)
実際にSlack経由で依頼した所、数時間でレビュー・登録が完了しました。
登録されたスクリプトは画面から確認することが出来ます。
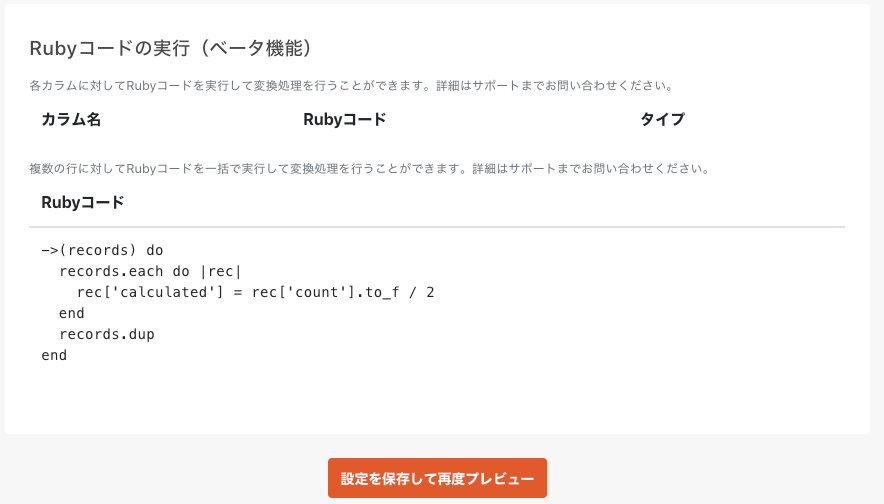
3. 転送設定プレビュー
早速「設定を保存して再度プレビュー」をクリックし、ETLが正しく動いているか確認を行っていきます。
4. 転送ジョブ実行
画面からアドホックにジョブを実行する事が出来るので、試しに実行してみます。
troccoではCPUやメモリを好きな量割り当てることが出来ますが、今回はデフォルトのCPU2コア、メモリ2GBのコンテナで試しました。
パフォーマンス
試しに70GB(約2.2億レコード)のS3上CSVファイルを入力とし、ETLにかかる時間を計測してみました。
念の為、ETLを行わない転送と、ETLを行った場合の2パターンで計測しております。
デフォルト環境なのですが、結構速いです。
ETLを行うと、その分処理オーバーヘッドが追加されるので時間はかかりますが、全然許容範囲内ではないでしょうか。
| Ruby ETL無し | Ruby ETLあり | |
|---|---|---|
| 1回目 | 74分 | 146分 |
| 2回目 | 72分 | 158分 |
| 3回目 | 79分 | 152分 |
| 平均値 | 75分 | 152分 |
まとめ
- RubyでETLが書けるため、簡単な変換処理だったら比較的楽に記述可能
- 転送速度は速いため、ある程度のデータ規模まで耐えられそう(CPUのコア数を上げるオプションを利用すればもっと速くなる)
- 分散処理フレームワーク(Sparkなど)を使わずとも、troccoで気軽に変換処理が書けるのは嬉しいですね!
https://trocco.io/lp/index.html