概要
- RedshiftをS3(Parquet)+Athenaで置き換える
- 容量に対するコスパを上げる
- 同時実行数に対する耐障害性を上げる
- データ統合SaaSのtroccoを使えば作業時間5分で出来た
背景
弊社では以前、DWHにRedshiftを使っていました。
しかしデータ量=ノード数が増えすぎたため、AWS料金が高額になり、問題となっていました。
弊社のDWH環境では、クエリ実行時間に対するパフォーマンスよりも、データ量に対するコストパフォーマンスの方が重要でした。
そのためRedshift上にデータロードする高速クエリ実行環境ではなく、S3に保存したデータをAthenaからクエリ実行出来る環境の方が合っていたのです。
この記事ではビッグデータ転送SaaSであるtroccoを使って、Redshift上のデータをS3に退避し、Athenaからクエリ実行する方法をご紹介します。
対象
- Redshiftをお使いで、以下の課題感を持っている方
- Redshiftの料金を抑えたい
- Redshiftのクエリ同時実行数が増えすぎて負荷がヤバい
- Athena試してみたい
- troccoって聞いたことあるけど、何が出来るんだろう?と思っている方
準備するもの
所要時間は、作業時間5分、転送時間60分程です。
- Redshiftクラスタ
- 今回は試験用の小さいクラスタを用意しました(dc2.xlarge * 6 nodes)
- 1億レコードくらいの行動ログデータ(user_id,user_agent,timestamp)を突っ込んで試します
- 転送元テーブル接続
- S3バケット
- データ保存先のバケットを用意しておいて下さい
- IAM User
- S3バケット
- troccoアカウント
- 無料のトライアルが可能ですのでこちらからお申し込み下さい
流れ
- troccoでRedshiftのデータをS3にParquet形式で吐き出す
- Athenaのクエリパフォーマンスを上げるため、列指向ファイルフォーマットのParquet形式で吐き出します
- パスに
date=2019-03-29のようなHiveのダイナミックパーティションも付与してあげまれば、スキャン量が減り、コスパが良くなります
- S3上のデータをGlue Crawlerでデータカタログ化(テーブル作成)
- Athenaでクエリ実行
1. troccoでRedshiftのデータをS3にParquet形式で吐き出す
1-1. 転送設定を作成
troccoトップページを開き、転送元にRedshiftを、転送先にS3 Parquetを選択し、転送設定を作成します。

すると転送設定の作成画面に遷移します。
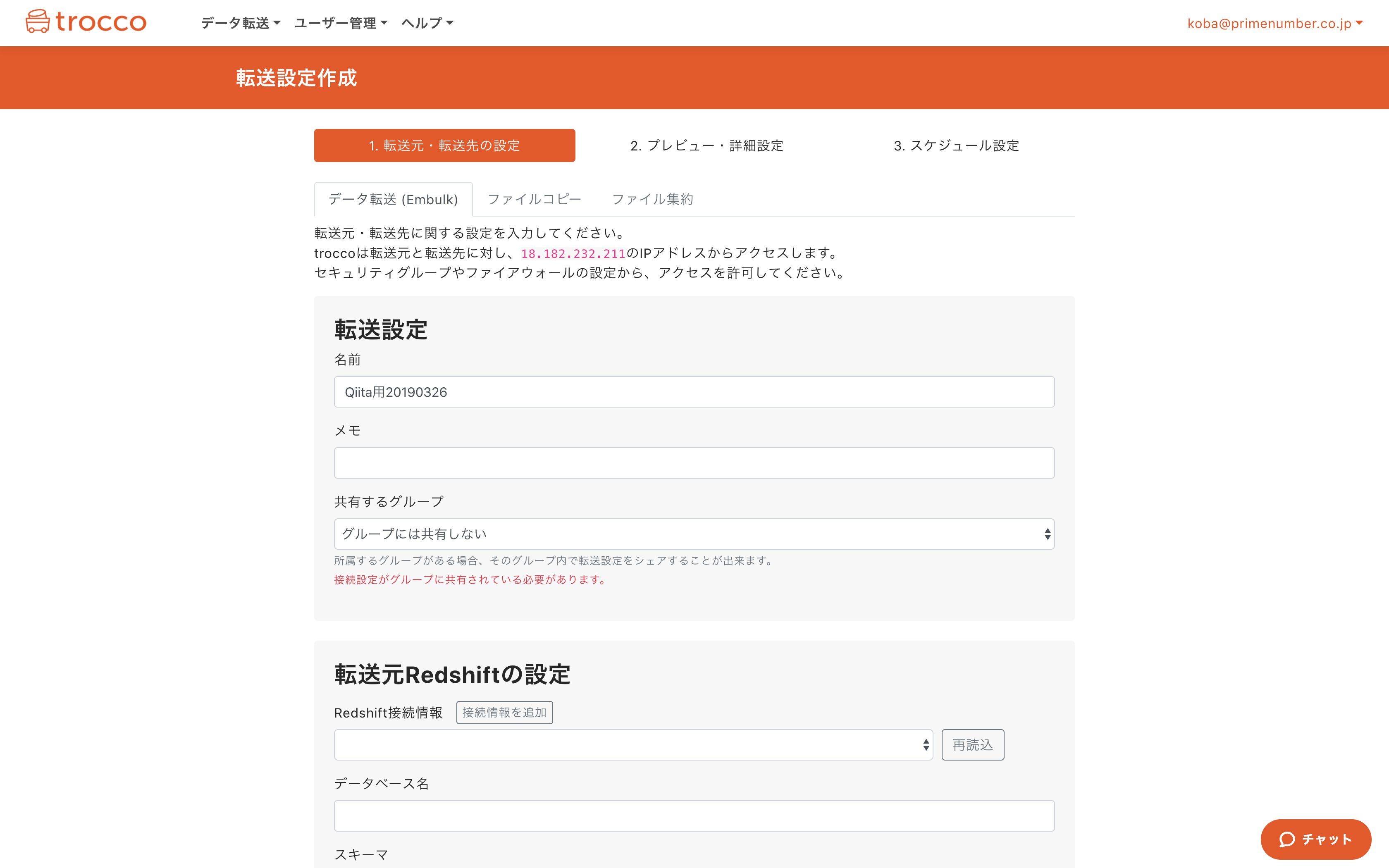
1-2. 転送元Redshiftの設定を入力
「接続情報を追加」を押し、予め用意したRedshiftの接続情報を、フォームに従って入力・保存します。
(AWSクレデンシャルの入力項目がありますが、今回はS3へのUNLOADは行わないため、用意したIAM Userか適当な文字列を入力して下さい)
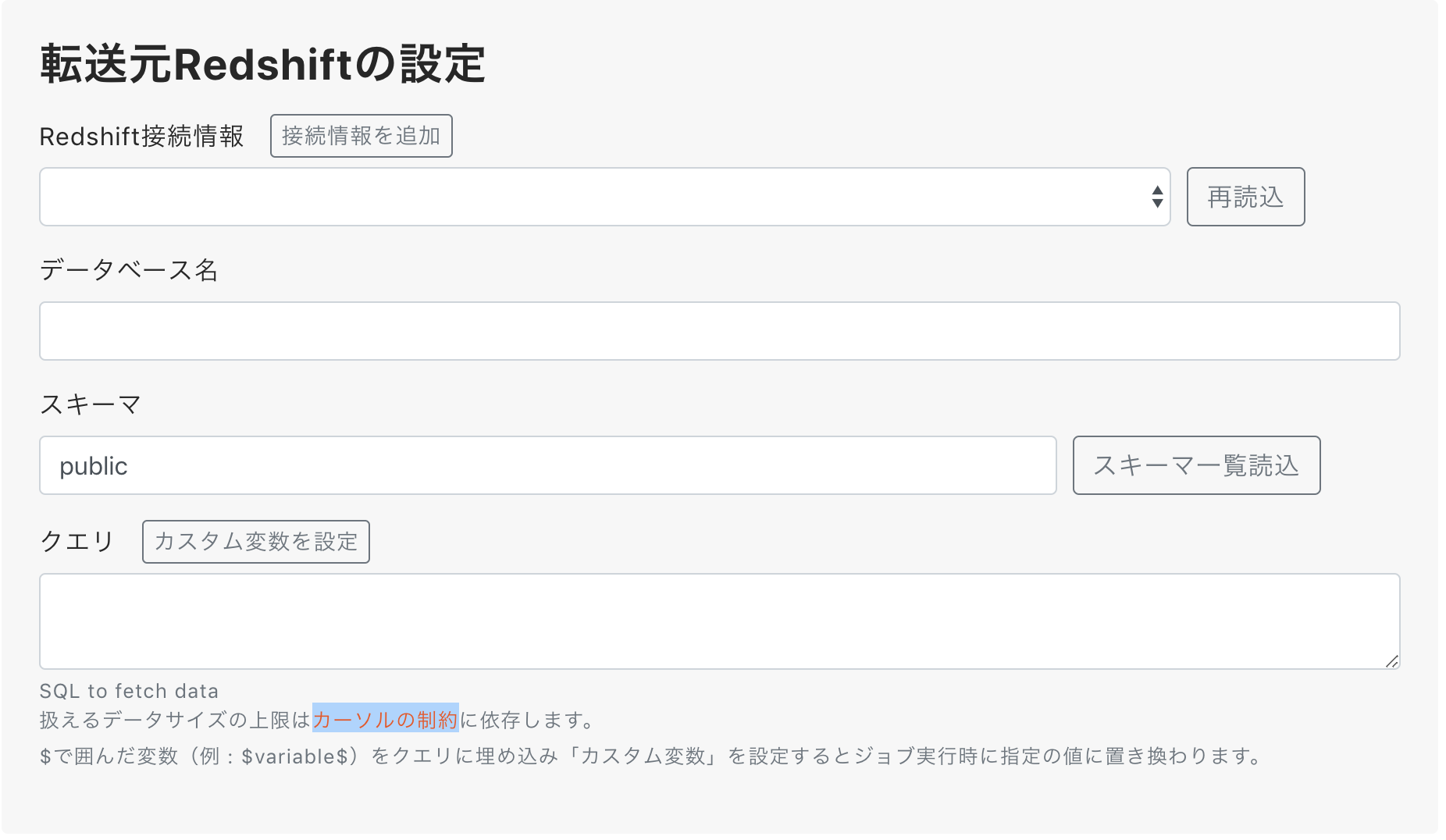
設定は以下のように入力します。
| 項目 | 値 |
|---|---|
| Redshift接続情報 | 再読込ボタンを押すと、登録した接続情報が出現するので選択して下さい |
| データベース名 | 転送するデータが保存してあるデータベース名を入力します |
| スキーマ | 転送するデータが保存してあるスキーマ名を入力します |
| クエリ |
SELECT * FROM public.table_name LIMIT 10000 のように、転送するデータをクエリで指定します。 |
1-3. 転送先S3の設定を入力
次は転送先に関する設定を入力していきます。
先ほどと同じ要領で「接続情報を追加」を押し、予め用意したS3の接続情報(IAM Userクレデンシャル)を、フォームに従って入力・保存します。

設定は以下のように入力します。
| 項目 | 値 |
|---|---|
| S3接続情報 | 再読込ボタンを押すと、登録した接続情報が出現するので選択して下さい |
| バケット | 予め用意した転送先バケット名を入力します |
| パスプレフィックス | ログの出力先パスプレフィックスを指定します。ここではqiita-20190326/と入力しておきます。 |
| リージョン | S3のリージョンを入力します。今回は東京リージョンにバケットを作ったので、 ap-northeast-1 と入力します。 |
| 圧縮方式 | 今回は圧縮ありで Snappy を選びました。他にもGzipなど計6種の圧縮方法に対応しています |
※パスプレフィックスではtest_log/date=$current_date$のように変数を埋め込むことも出来ます。転送日時を使って日付のパーティションを切るような用途で使えます。 |
1-4. プレビュー
ここまでで、設定は完了です。保存してプレビューに進みます。
自動データ設定で列名・データ型などが正しく認識されていることが確認できました。
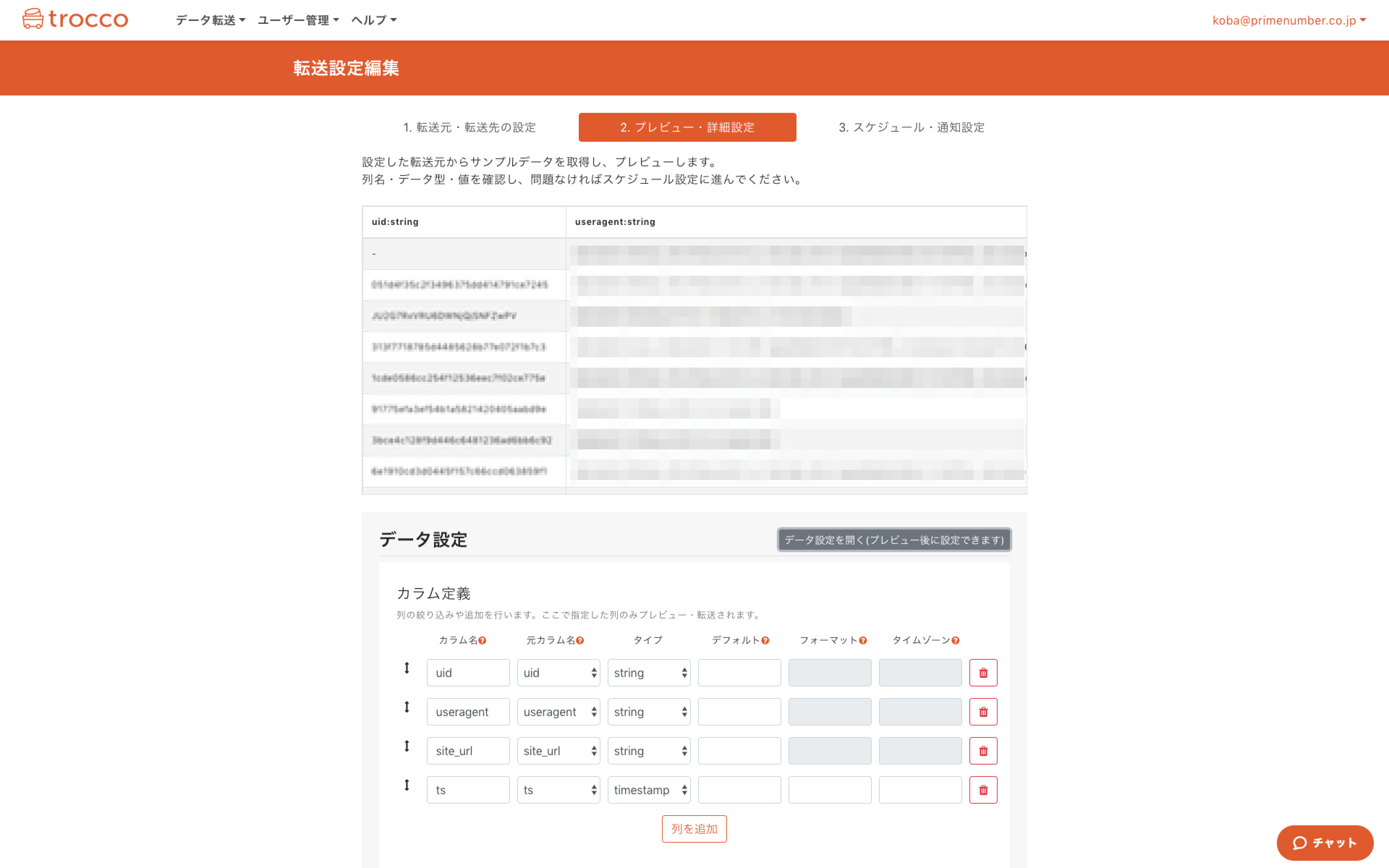
1-5. 詳細設定(Glueデータカタログへの登録設定)
プレビュー画面の下の方に詳細設定がありますが、RedshiftのSSL設定とか、S3 Parquetのブロックサイズとかを変更したければこちらをいじります。
また、Athenaでのクエリ実行に必須である**「Glueデータカタログ」への登録も自動化出来ます**。
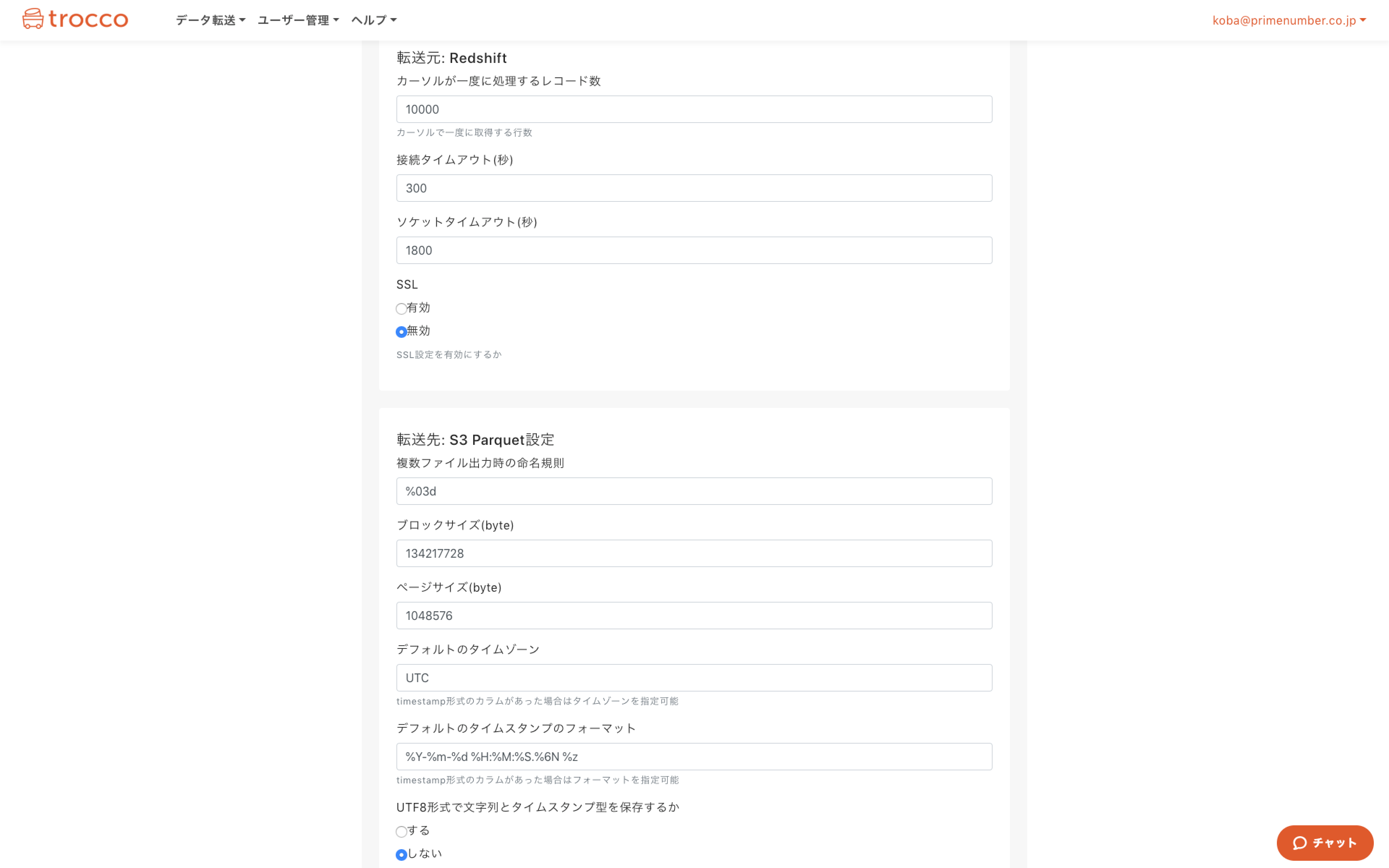
※JSON型、タイムスタンプ型の列がある場合はここで「カラム設定」を行う必要があります
1-6. スケジュール・通知設定
定期実行したり、エラー時にSlack通知したり出来るみたいですが、今回はスキップで。
1-7. ジョブ実行
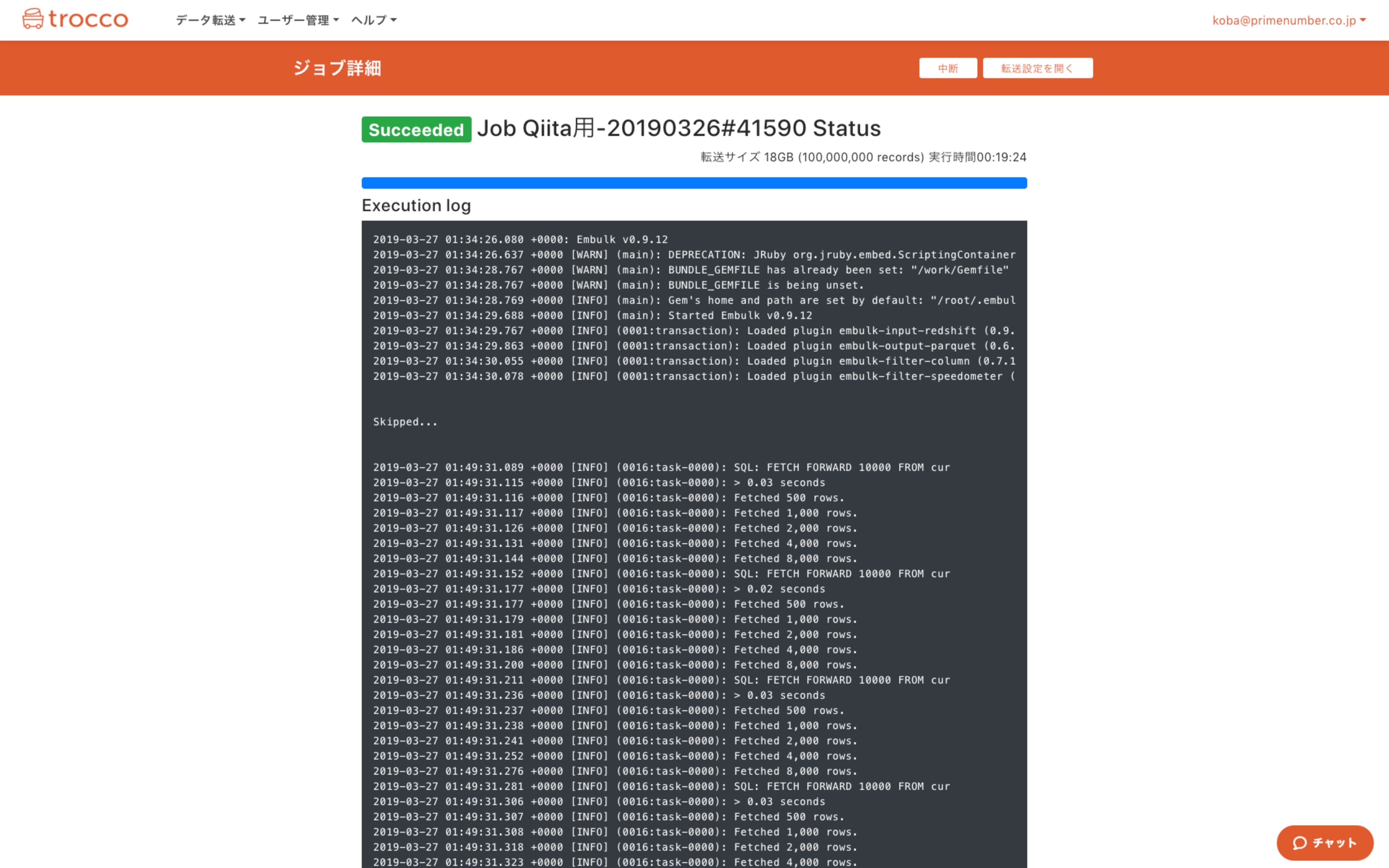
設定が完了したら、右上のボタンから「実行」を押して、転送ジョブを実行します。
1億レコードですが、だいたい20分くらいでParquet形式での保存が完了しました。
2. S3上のデータをGlue Crawlerでデータカタログ化(テーブル作成)
本来ならこの部分の作業が発生すると思っていたのですが、trocco側で自動でテーブル作成を行ってくれるので、作業不要でした(^_^;)
3. Athenaでクエリ実行
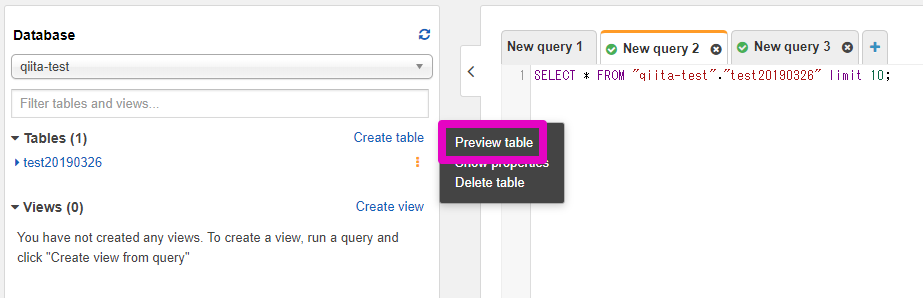
ここまででAthenaでクエリ実行を行う環境が整っているはずです。テーブルが追加されています。
Athenaのコンソールを開き、左メニューのDatabaseから対象のデータベース・テーブルを選択し、Preview tableを押すとデータが見れます。
まとめ
RedshiftのデータをParquet形式で保存するにはいくつかの方法があります。
その中でも、この方法では下記のメリットがあると思います。
- データカタログへの登録まで自動化出来る
- 開発・実装・環境構築作業が一切いらない
- ジョブ管理も行う必要がない
- Redshift以外にも40種を超えるデータをParquetで出力できる
以上、Redshift→S3+Athenaの移行がわずか5分程度の設定作業で実現できました。
参考
今回利用したプラグイン