概要
kintoneを使っている方は、売上、顧客、案件データを分析することがあると思います。
しかし肝心の分析を行うためには、kintoneのデータを分析環境に統合するという、手間のかかる作業が待っています。
そこで、今回はtroccoを用いてkintoneのデータをRedshiftに出来るだけ簡単に統合する方法を紹介します。
さらに、Redshiftに統合したデータをLookerで可視化する方法も紹介します。
今回、データの転送手段として採用したtroccoは、kintoneの他にも、様々な広告・CRM・DBなどのデータソースにも対応しています。
troccoの使い方まとめ(CRM・広告・データベース他)

ゴール
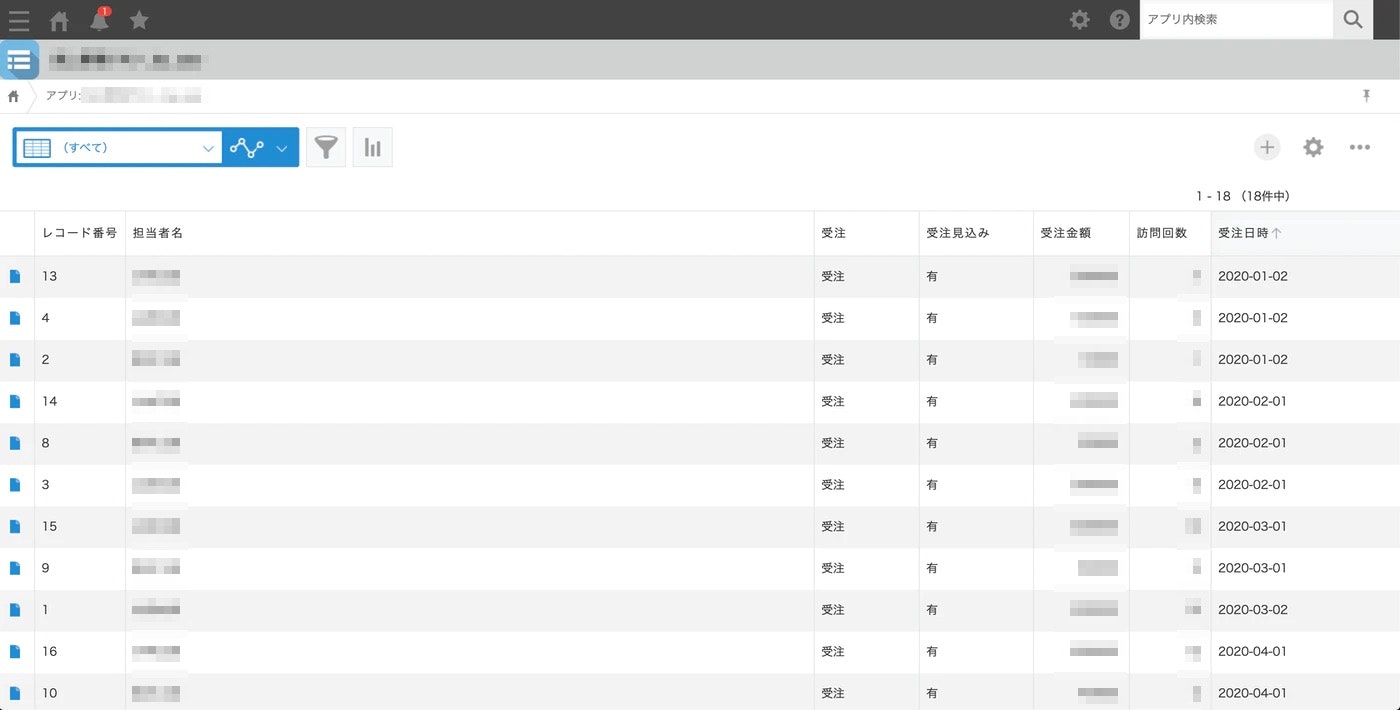
このようなkintoneのデータから
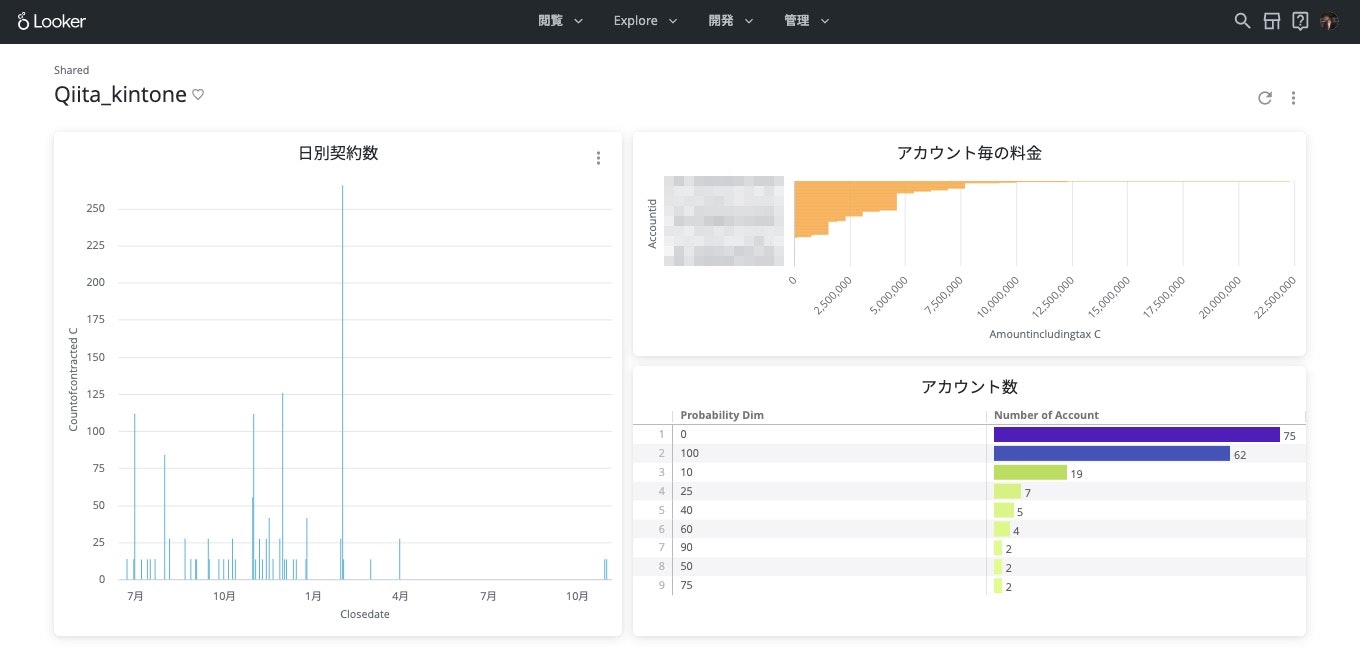
このようなダッシュボードを30分程度で作りあげます(当然、作成後は自動で最新値が更新されるようにします)
こんな人におすすめ
- kintoneのデータを分析基盤やDWH(データウェアハウス)に取り込みたい方
- データをcsvファイルにエクスポートして分析基盤に取り込むまでの作業時間が長く、無駄が多いと感じている方
- データ取得の作業に疲れている方
1. DWHと同期する手段の選定
1-1. DWHの選定
まずはデータの集約先であるDWHを選定します。
Amazon RedshiftGoogle BigQueryMySQL-
PostgreSQLなど
今回はAmazon Redshiftを利用することにします。
1-2.転送手段の選定
データの集約先がRedshiftに決まったので、次は転送するための手段を以下の4つから選びます。
1. データをcsvエクスポートし、手動でRedshiftにアップロードする。
2. kintoneとRedshiftの各APIを用いて、自分でプログラムを書いて連携させる。
3. Embulkを利用し、自分で環境を構築する。
4. troccoを利用し、画面上で設定する。
1は単発の実行なら特に問題はありませんが、定期的に取り込む必要がある場合は非効率な作業になります。
2はAPIのキャッチアップ工数・プログラムを書く工数・環境構築工数が発生する他、エラー対応などの運用工数も継続的に発生します。
3も2と同じく、Embulkはある程度の専門知識が必要になり、自分で環境構築・運用を行う手間が発生します。さらに、エラーの内容が専門的で、詰まると大幅に時間を浪費してしまいます。
そこで、今回はEmbulkの課題も解決してくれて、プログラムを書かずに画面上の設定のみで作業が完結する、4のtroccoというSaaSを利用します。
2. troccoでkintone→Redshiftの転送自動化
2-0. 事前準備
ここからの作業には、troccoのアカウントとkintoneのアカウントが必要になります。
無料トライアルも実施しているので、申し込み・登録をしておいてください!
https://trocco.io/lp/index.html
(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内することができます)
2-1. 転送元・転送先を決定
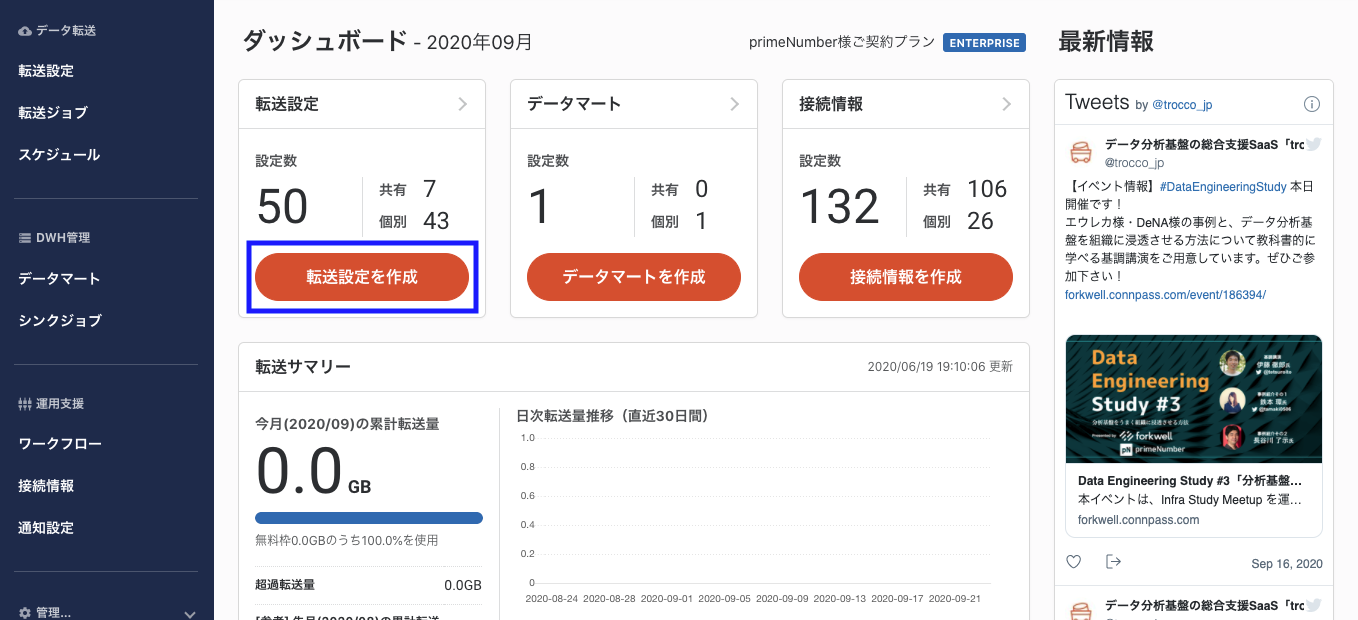
troccoにアクセスし、「ダッシュボード」にある「転送設定を作成」ボタンを押します。
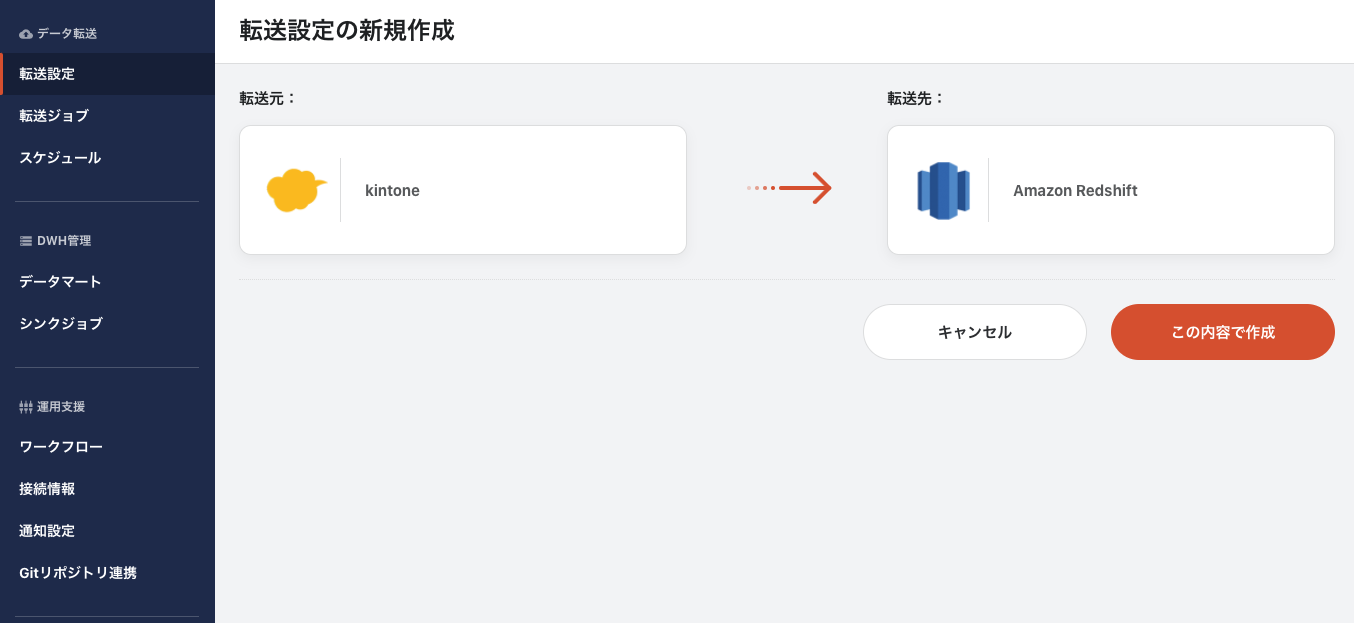
転送元にkintone、転送先にAmazon Redshiftを選択し、「この内容で作成」ボタンを押します。
すると、設定画面になるので、転送に必要な情報を入力していきます。
2-2. kintoneとの連携設定
後に見た時に、一目で何の転送設定か把握できるように、転送設定の名前とメモを入力します。
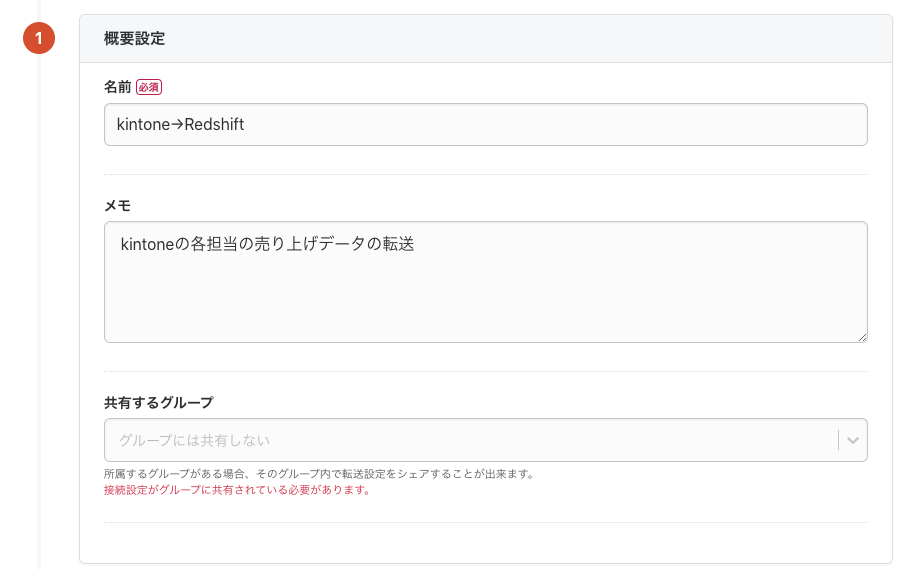
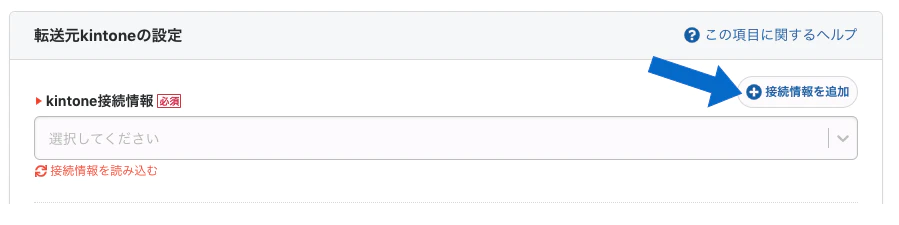
転送設定の名前を決めたら、「転送元の設定」内の「接続情報を追加」ボタンを押し、kintoneの接続情報の設定を行います。
データを取得したいkintoneの情報を入力し、接続情報を作成します。
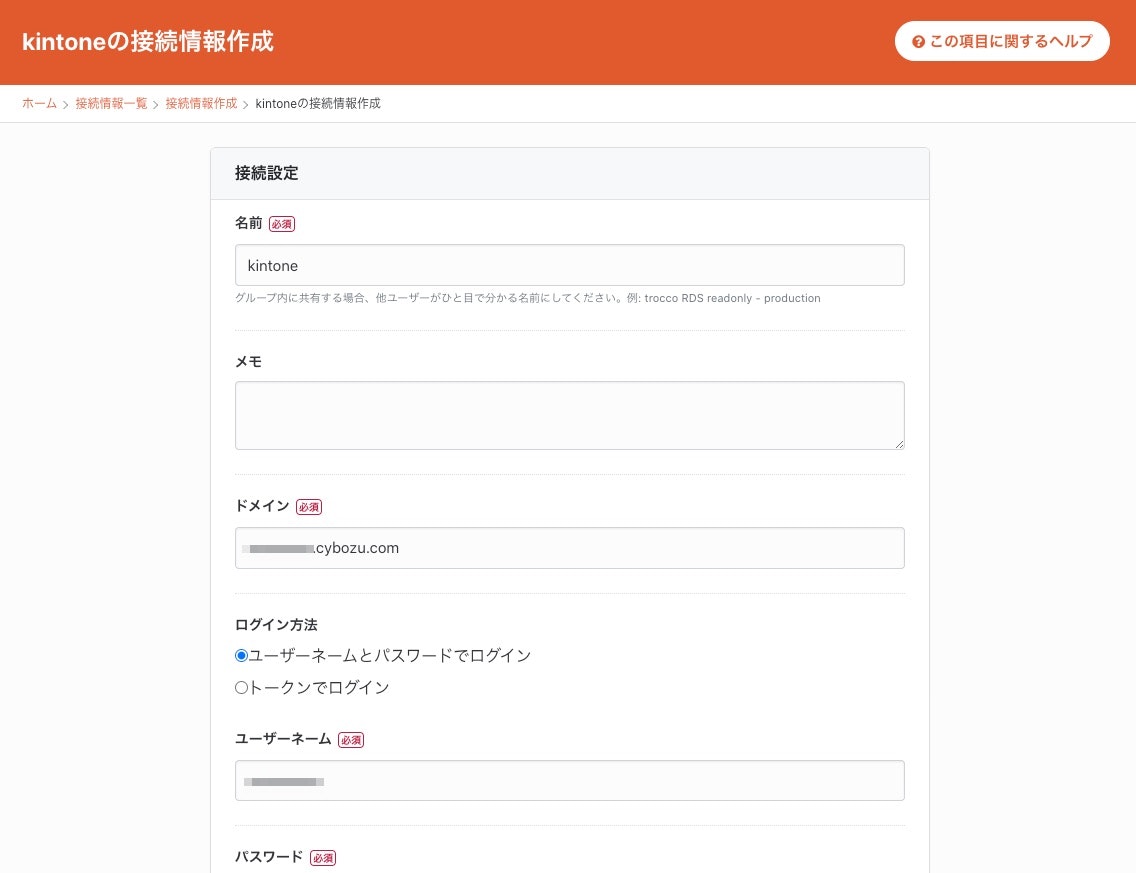
これでkintoneとの連携は完了です。
2-3.kintoneからのデータ抽出設定
次に、kintoneのアプリや取得データを設定します。
kintoneの画面に記載されていないメタデータ(idや更新日時など)は、Cybouzuの開発者向けサイトにを参考に設定していきます。
クエリによる転送レコードの絞り込みも可能です。
今回は、今年のデータだけに絞って転送を行なっています。
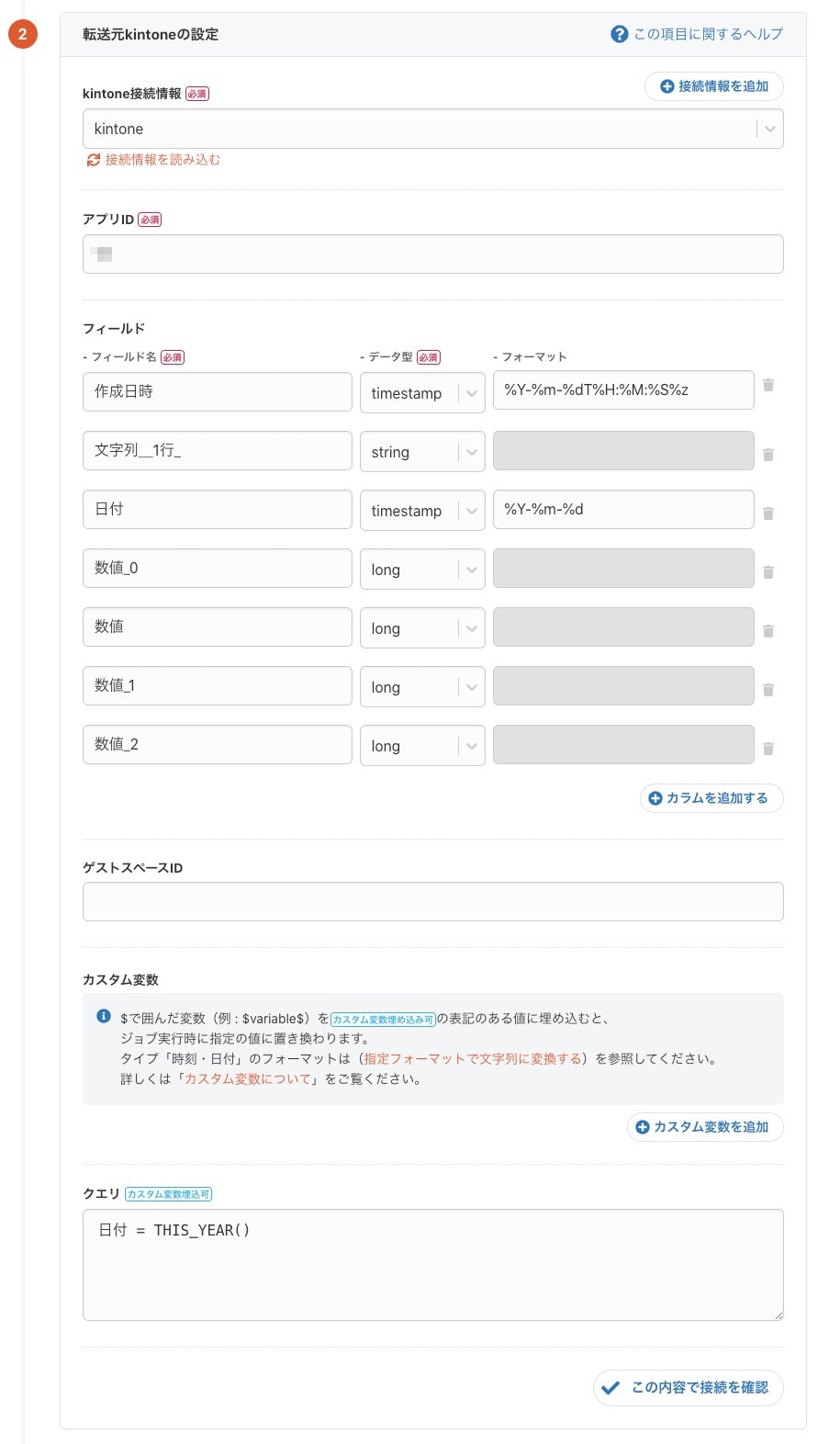
また、カスタム変数を使うことにより、ジョブ実行時に指定の値に置き換えることができます。
以上でkintone側の設定は完了です。
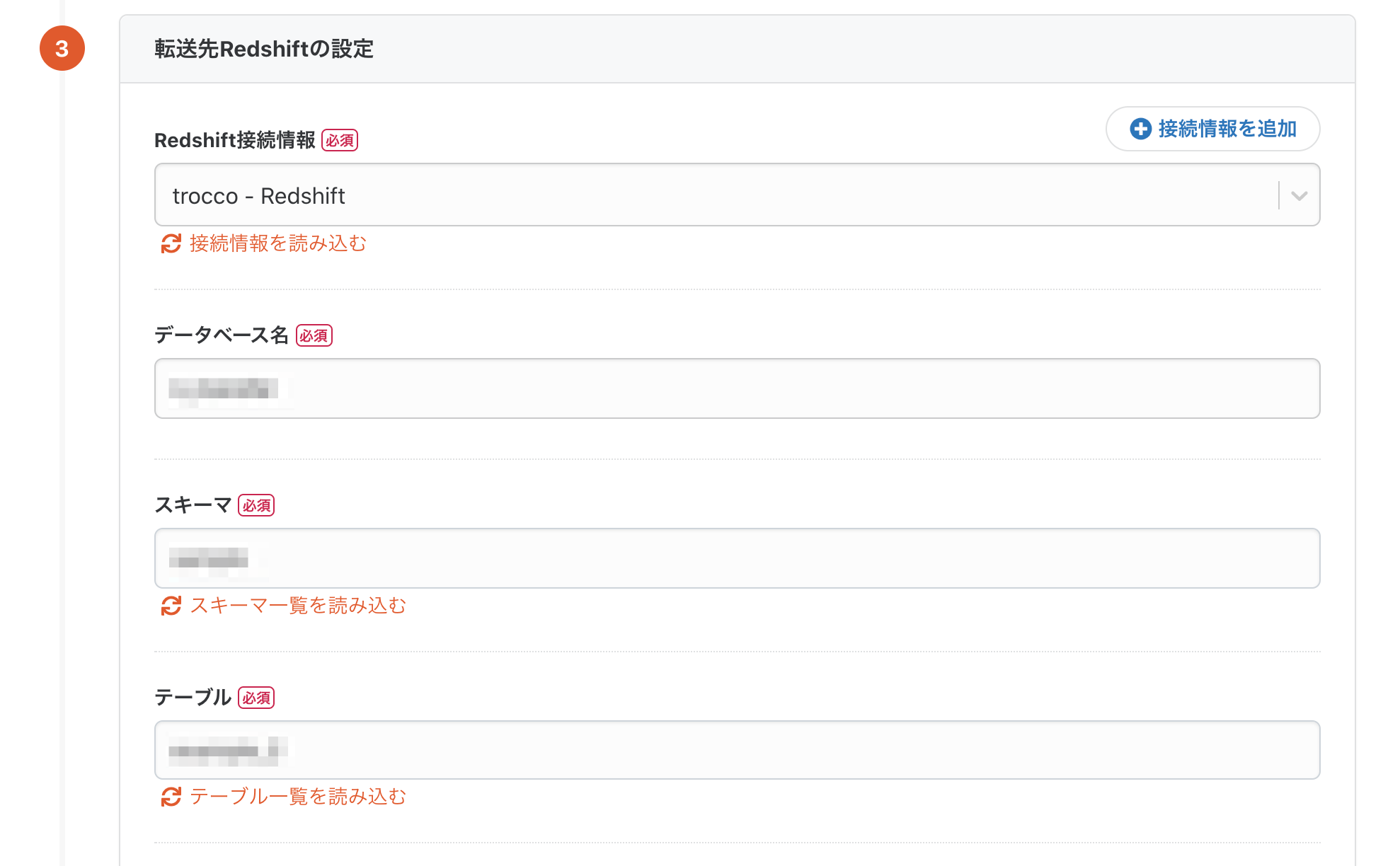
2-4. 転送先Redshiftの設定
次に、転送先のRedshiftの設定を行います。
基本的には転送元と同じ要領です。
「接続情報を追加」ボタンからRedshiftの接続設定を行い、データベース名、スキーマ、テーブルを入力します。
troccoでは一時データの保存にS3を利用するため、S3パケット・S3キープレフィックス・転送モードも必須項目です。これらも入力します。
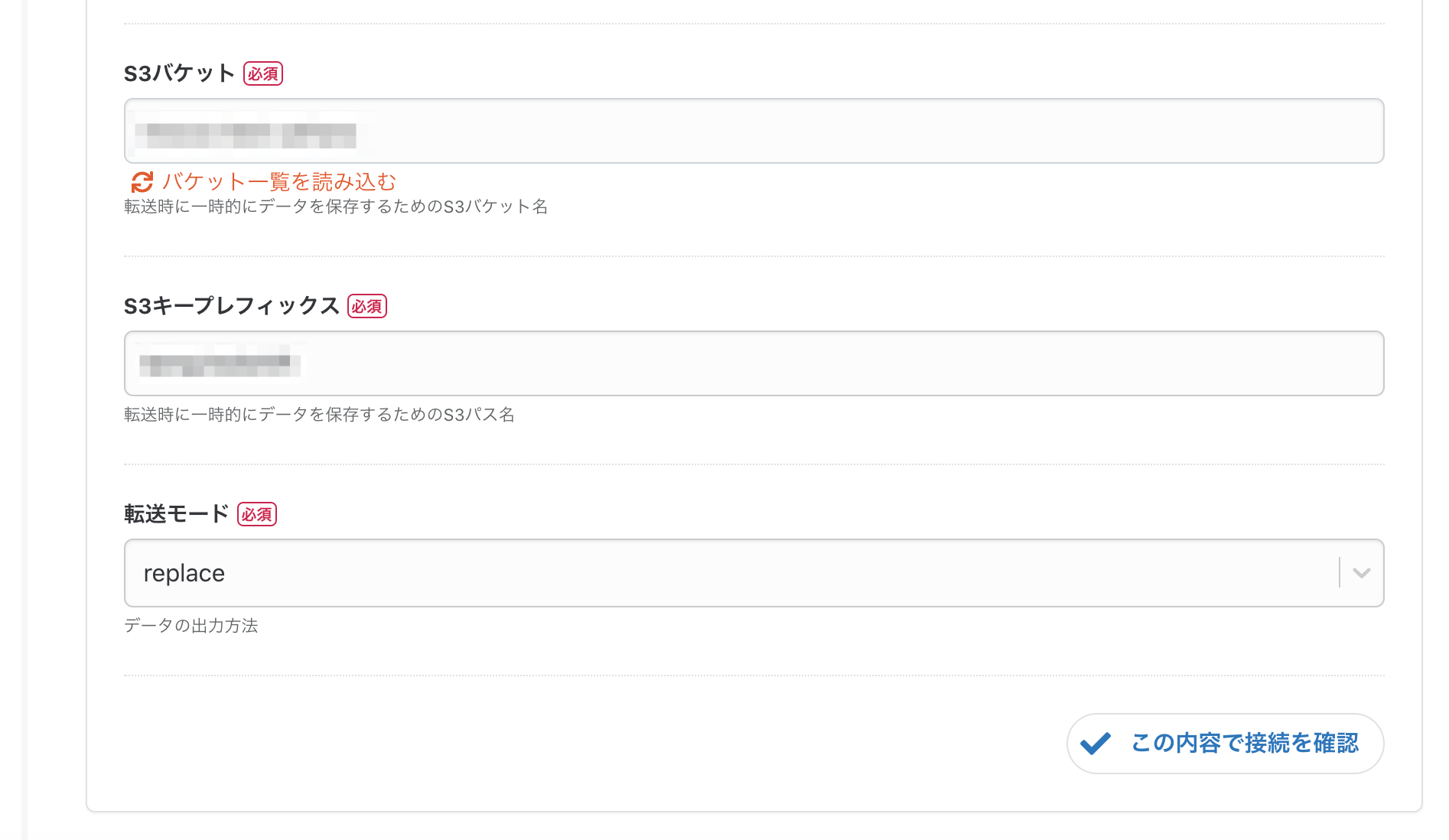
最後に、「この内容で接続を確認」ボタンを押して、接続確認が問題なく通るか確認します。

これで入力は完了です。「保存して自動データ設定・プレビューへ」ボタンを押して、確認作業に進みましょう。
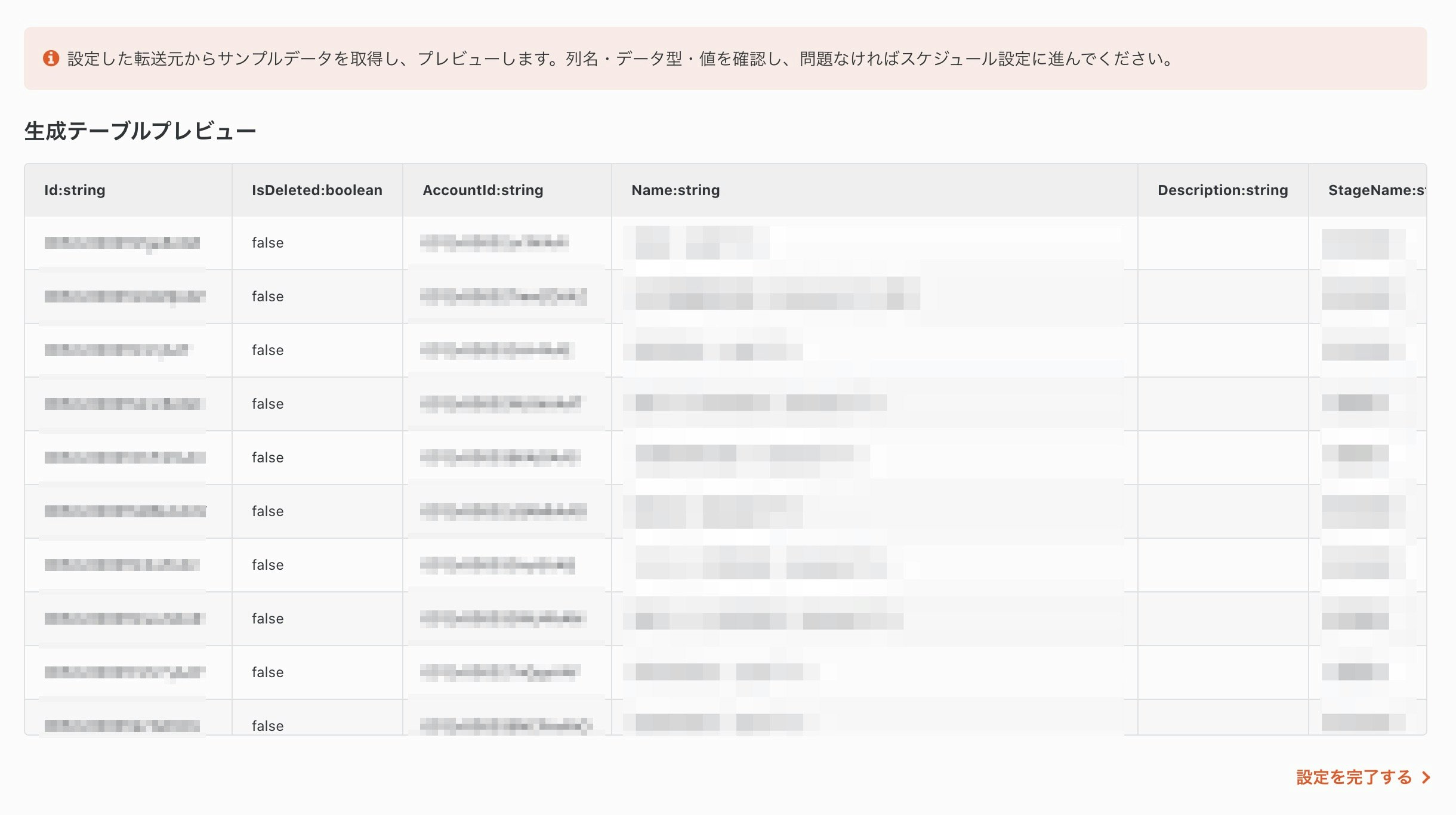
2-5. データのプレビュー
少し待つと、転送元のデータがプレビューされます。kintoneから取り込んだデータが表示されているのが確認できると思います。
問題なければ、「設定を完了する」ボタンを押して、スケジュールや通知設定に進みます。
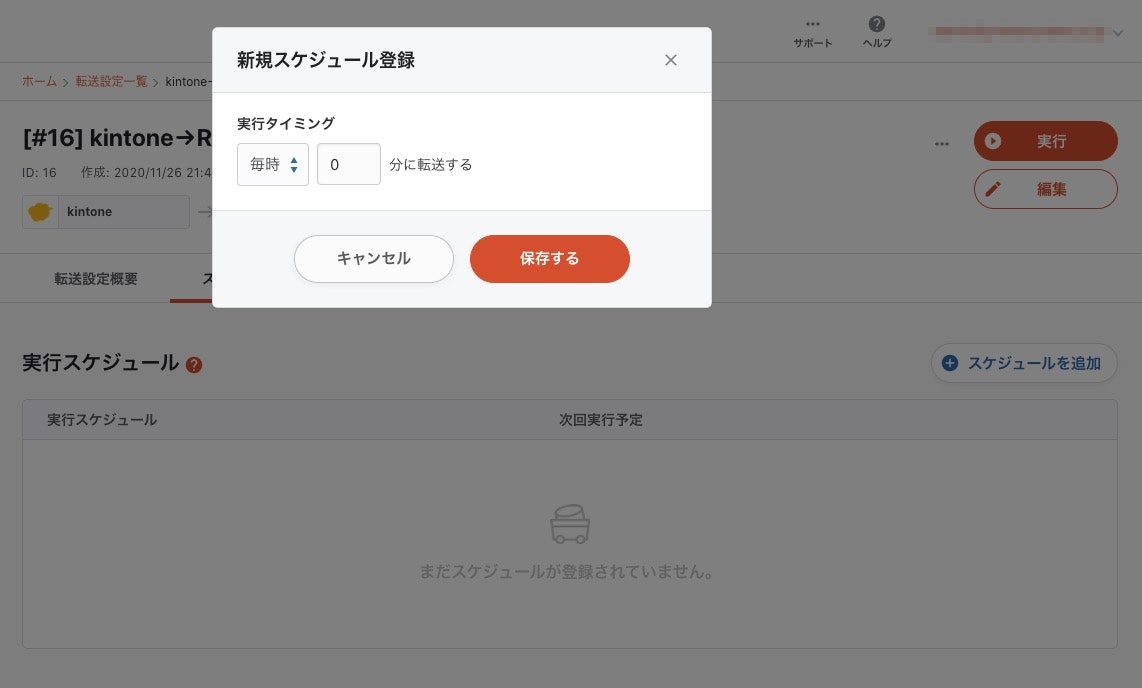
2-6. スケジュール設定
「スケジュール・トリガー設定」タブを開きます。
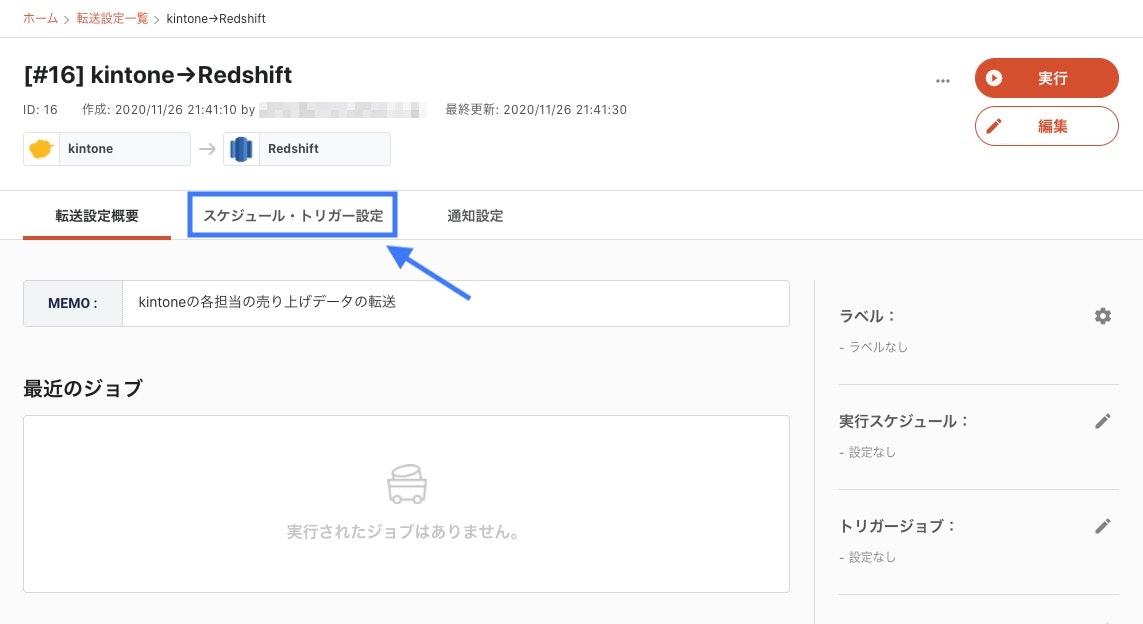
以下のように実行スケジュールを設定することで、転送を自動化することができます。
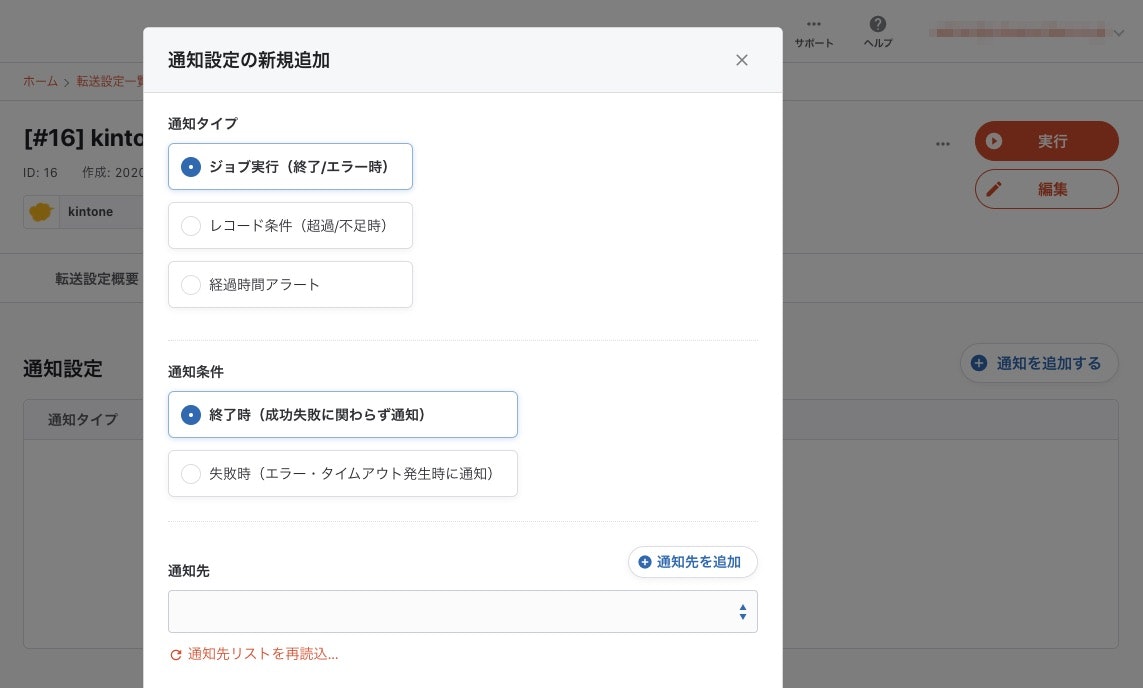
2-7. 通知設定
必須の設定ではないですが、通知タイプ・通知条件・通知先を選択し設定を保存することで、EmailやSlackに通知を行うことができます。
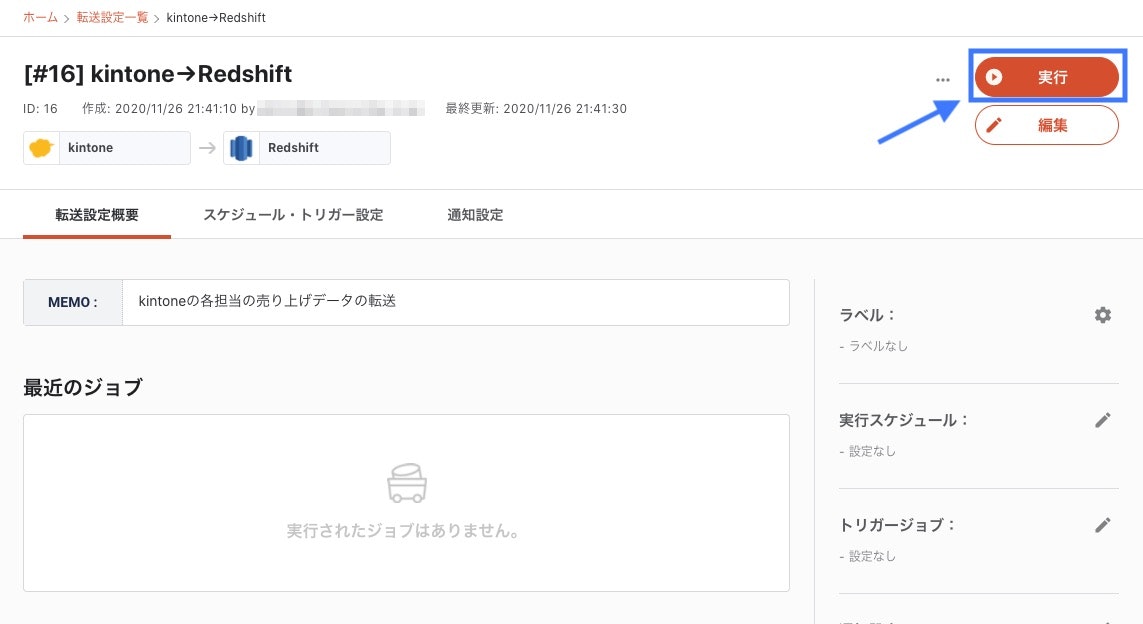
また、必要な時のみ実行したい場合は、転送設定詳細の「実行」ボタンを押すと、手動で転送を実行することもできます。
3. Redshiftの設定
特に設定することはありません。
データがきちんと送られているかプレビューで確認してみます。
データが溜まっているので、今すぐに分析・可視化を行うことができます。
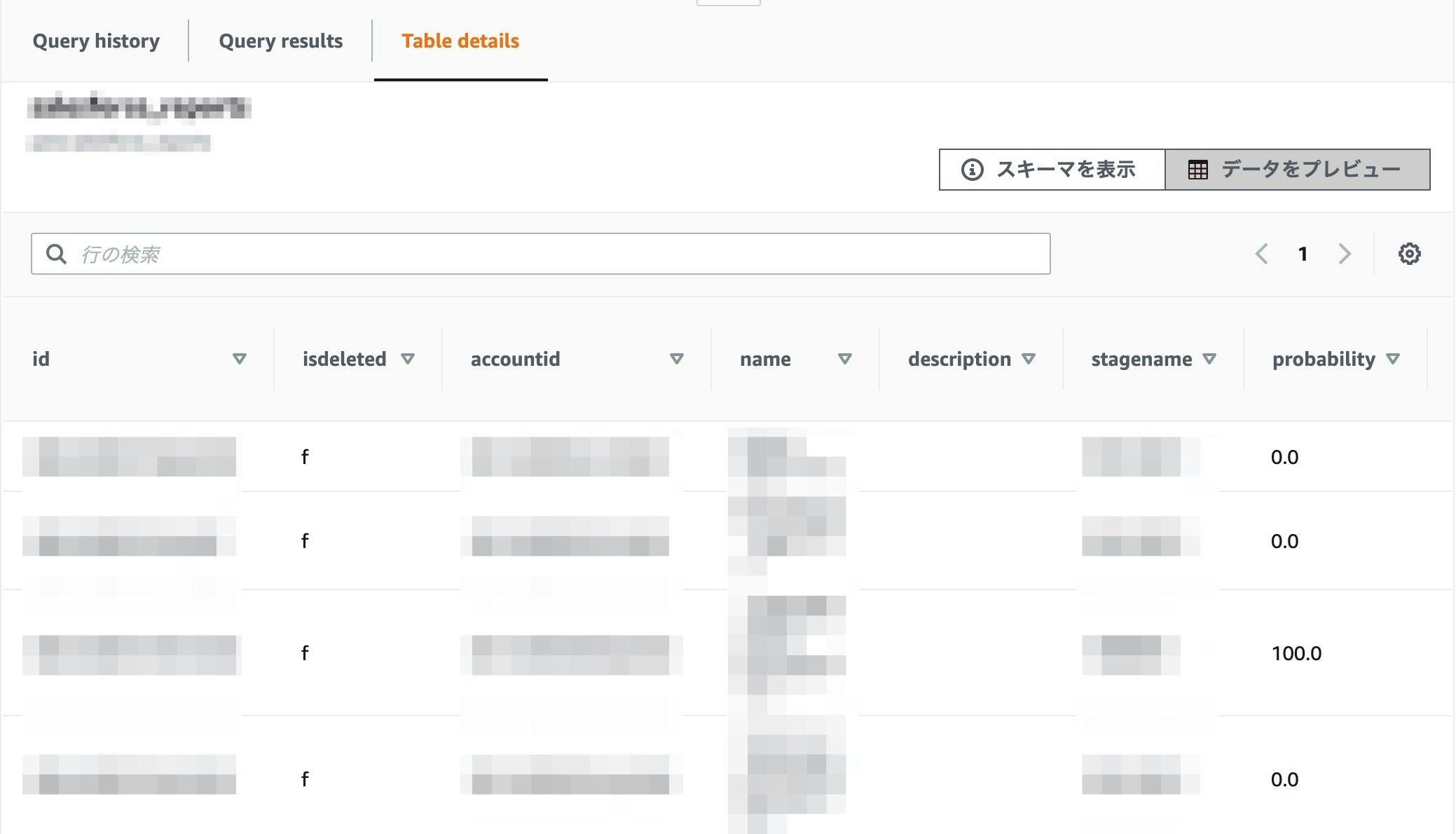
これで、kintoneのデータがRedshiftに同期されていることが確認できました。
4. Lookerで可視化
4-1. RedshiftとLookerの接続設定
ここから、Redshiftに集約されたデータを可視化していきます。
Lookerの画面から、「管理 > Database > Connections」を開きます。
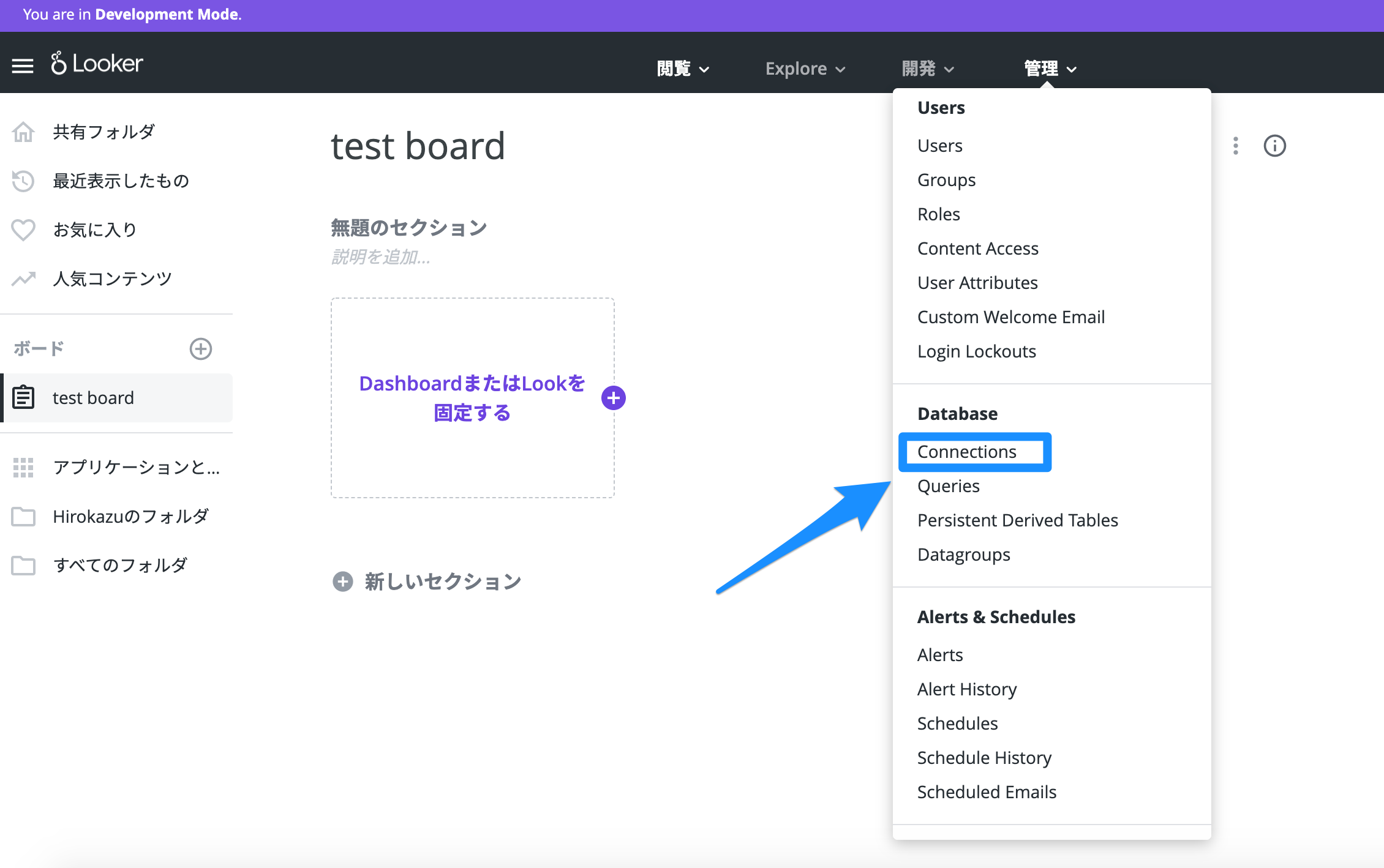
すると、接続しているデータベースが一覧で表示されます。
この画面で「Add Connection > Database Connection」を開き、「Connection Setting」に接続するデータベース情報を入力します。


これで、RedshiftとLookerの接続設定が完了です。
4-2. LookMLプロジェクトの作成
次に、データを可視化するのに必要なLookMLプロジェクトを作成していきます。
「開発 > LookML プロジェクトの管理」を開きます。
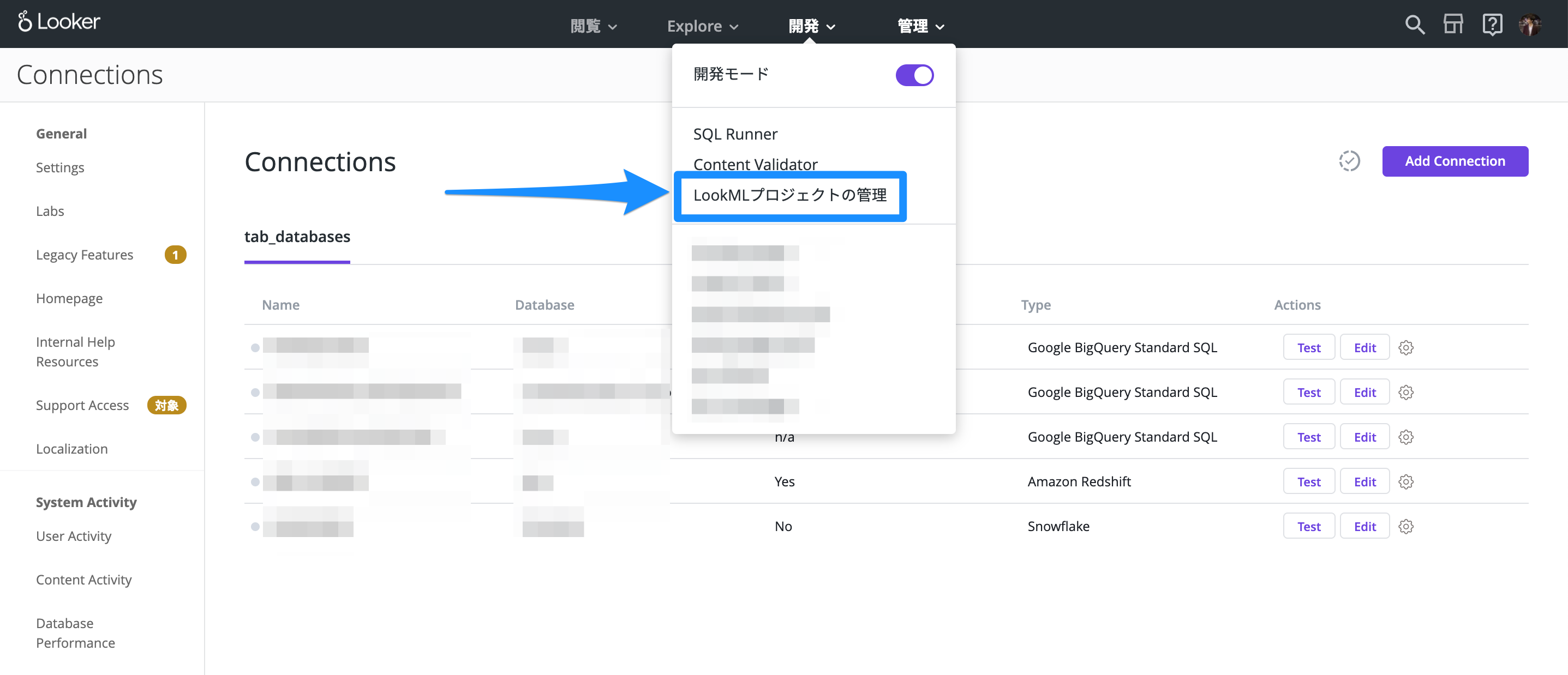
「New LookML Project」を押して、新しいLookMLプロジェクトを作成します。
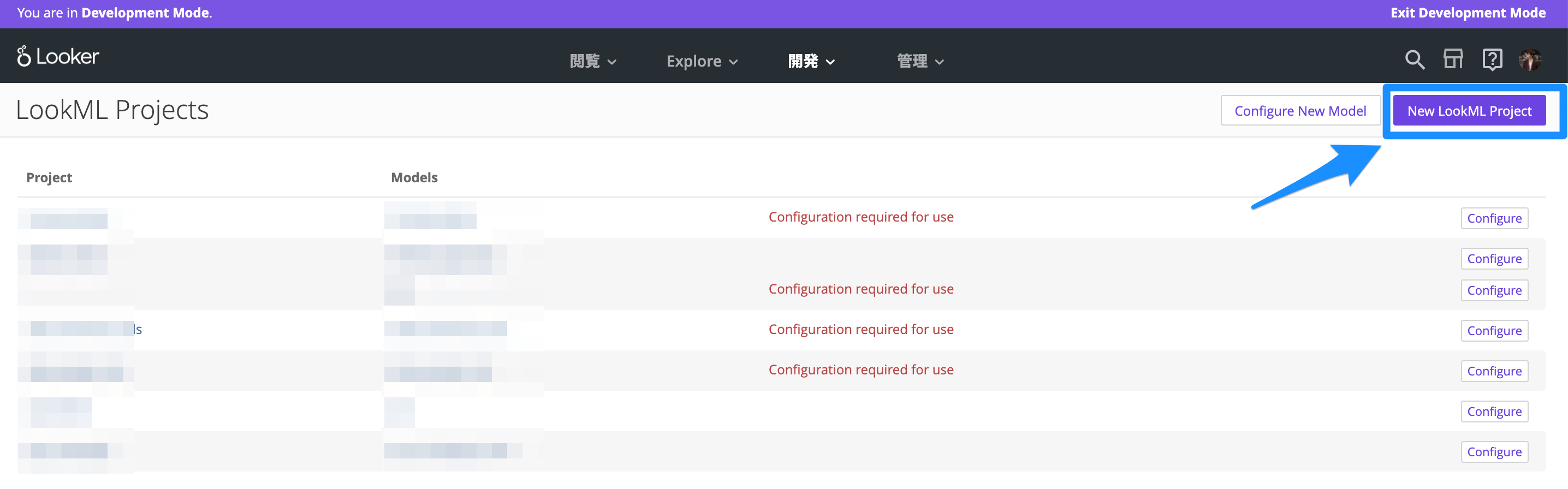
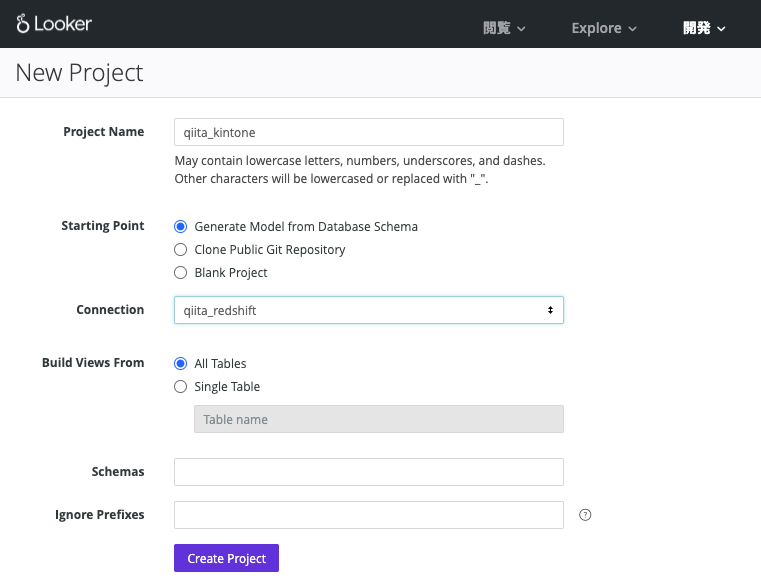
これで、LookMLプロジェクトを作成できました。
4-3. モデルとビューの定義
次に、表示されたエディタで、モデルとビューを定義します。
後々必要になるので、モデルにデータベース接続とその接続を使用するExploreを定義します。
(書き方はLookerの公式ドキュメントを参考にしてください)
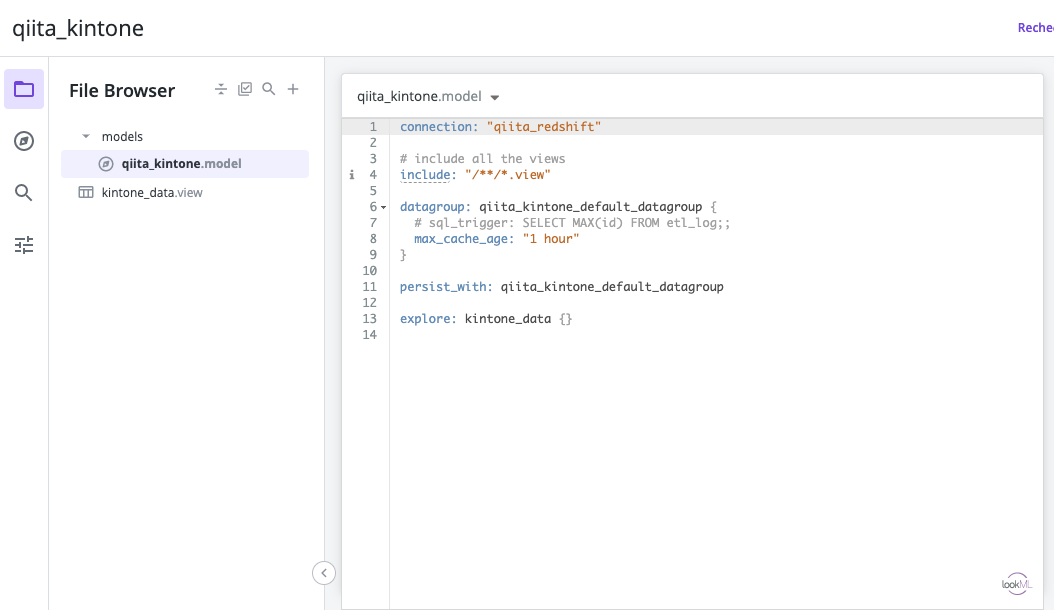
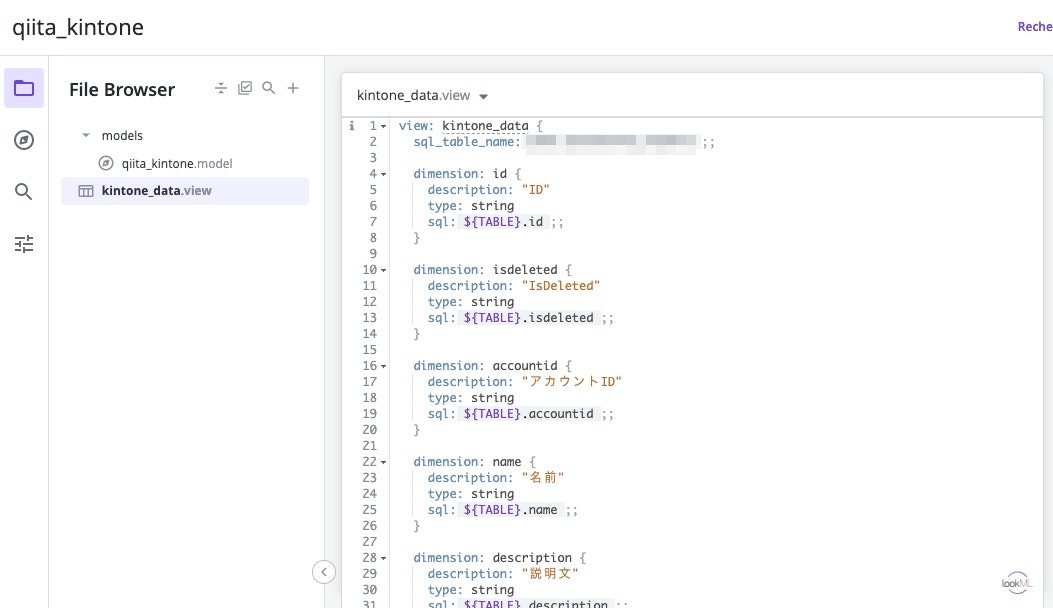
これでグラフを作成する準備ができました。
4-4. グラフの作成
最後に、今回のゴールであるグラフを作成します。
トップページに戻り、「New > Dashboard」を押して、ダッシュボードを作成していきます。

このように白紙のダッシュボードが作成されました。
「Dashboardの編集」を押し、「タイルの追加」を押し、先ほどのモデルで定義したExploreを選択します。
「DIMENSIONS」に横軸にしたいデータ、「MEASURES」に縦軸にしたいデータを選択し、「実行」を押すことで、グラフを作成することができます。
試しに、日毎の契約数を可視化してみます。
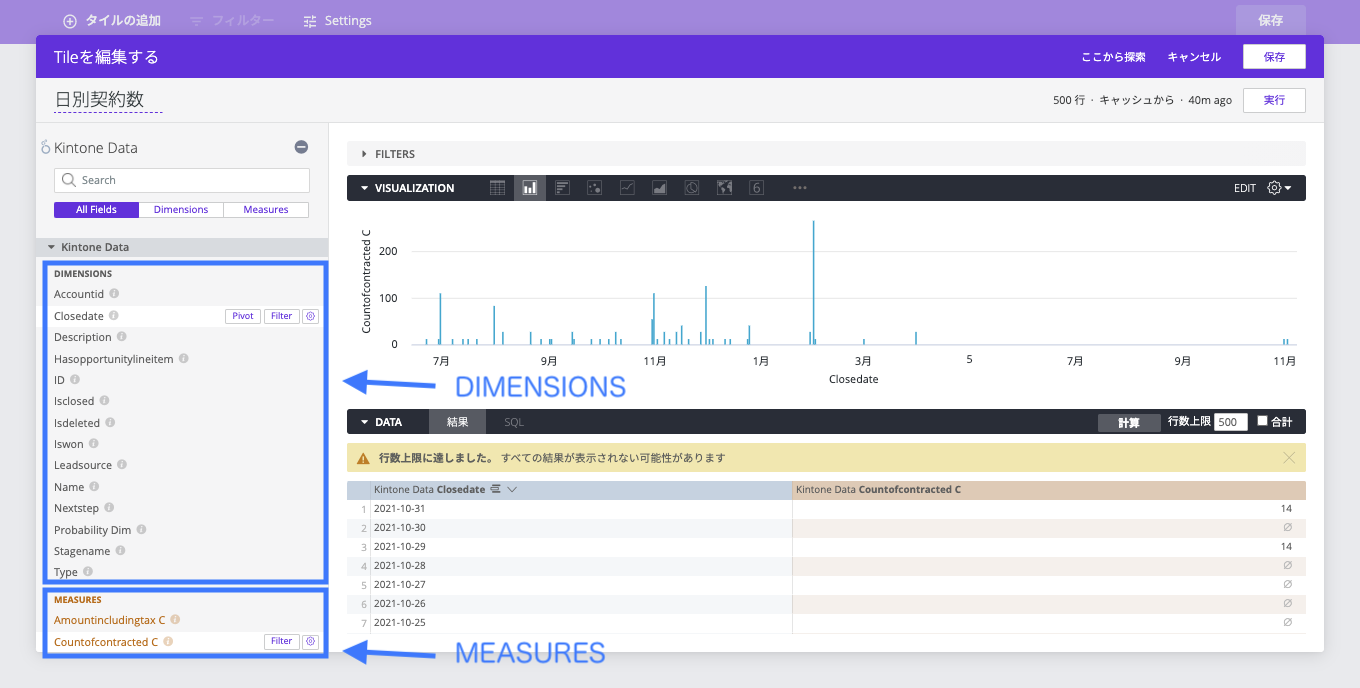
これで一つグラフが完成しました。
このような感じで他のグラフも作成すると、今回のゴールであるkintoneのダッシュボードが完成します。
まとめ
いかがでしたでしょうか。troccoを使うと管理画面を触ることなく、簡単にkintoneのデータを取得し、DWH(Redshift)に貯めることが出来ました。
また、今回のようにRedshiftにデータを貯めると、Lookerを用いてデータを可視化することができます。
実際に弊社サービスのtroccoにおいても、広告データやマーケティングKPI等をこのような流れで収集・分析しています。
troccoは、kintoneの他にも、様々な広告・CRM・DBなどのデータソースにも対応しています。
troccoの使い方まとめ(CRM・広告・データベース他)
実際に試してみたい場合は、無料トライアルを実施しているので、この機会にぜひ一度お試しください。(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内することができます)