概要
AWSを利用する上でコストを分析することは、コスト削減のために重要です。
AWS Cost ExplorerはAWSのコストに関する情報を取得することができるサービスであり、コスト分析に対する強力なツールとなります。
例えば、他のサービスの使用状況やコストについての情報と組み合わせて、グラフを作成することは分析に効果的です。
しかし、新しくデータが増える度にデータをダウンロードして最新の状態にし、グラフを作り直すのは手間がかかる作業です。
そこで今回は、troccoという分析基盤向けデータ統合サービスを使い、レポート取得の自動化+DWHへの統合+可視化までやってみようと思います。
今回、データの転送手段として採用したtroccoは、AWS Cost Explorerの他にも、様々な広告・CRM・DBなどのデータソースに対応しています。
troccoの使い方まとめ(CRM・広告・データベース他)

ゴール
↓画像のようにグラフをまとめたものを30分くらいで作り上げます(作成後は自動で最新値に更新することも可能です)

こんな人におすすめ
- AWS Cost Explorerを利用しており、分析基盤やデータウェアハウスへのデータ移行を考えている方
- 様々なサービス利用に関する情報をまとめてひとつのサービスで管理したい方
- 管理画面からデータ取得を行う作業に疲れている方
1. DWHと同期する手段の選定
1-1. DWHの選定
まずはデータを集約する場所である、DWH(データウェアハウス)を選定します。
- Amazon Redshift
- Google BigQuery
- MySQLやPostgreSQL
今回はAmazon Redshiftを利用することにします。
1-2. AWS Cost ExplorerのデータをAmazon Redshiftに転送する4つの方法
Amazon Redshiftにデータを集約することが決まったので、続いては転送するための手段を検討します。
1. AWS Cost Explorerのデータを管理画面からダウンロードし、手動でAmazon Redshiftにアップロードする
2. AWS Cost ExplorerとAmazon Redshiftの各APIを用いて、プログラムを書いて連携する
3. Embulkを利用し、自分で環境を構築する
4. troccoを利用し、画面上で設定する
1は単発の実行であれば問題はありませんが、定期的な取り込みを行うことを考えると毎回同じ作業を繰り返すことになり、手間と時間が取られます。
2は連携を始める前にAPIのキャッチアップ+プログラムを書く+環境構築の時間がかかり、エラー対応などの運用工数も継続的に発生します。
3も2と同じくEmbulkはある程度の専門知識が必要になり、自分で環境構築・運用を行うため、手間が発生します。加えてエラーの内容が少し専門的なためエラーの解消に時間が取られる可能性があります。
そこで今回はEmbulkの課題も解決し、プログラムを書かずに画面上の設定のみで作業が完結する、4のtroccoというSaaSを利用します。
2. troccoでAWS Cost Explorer→Redshiftの転送自動化
2-0. 事前準備
データの転送のためにはtroccoのアカウント・AWSのアカウントが必要です。
無料トライアルを実施しているので、事前に申し込み・登録しておいてください!
https://trocco.io/lp/index.html
(申込の際に、この記事を見た旨を記載して頂ければご案内がスムーズに行えます)
2-1. 転送元・転送先を決定
troccoにアクセスして、ダッシュボードから「転送設定を作成」のボタンを押します。
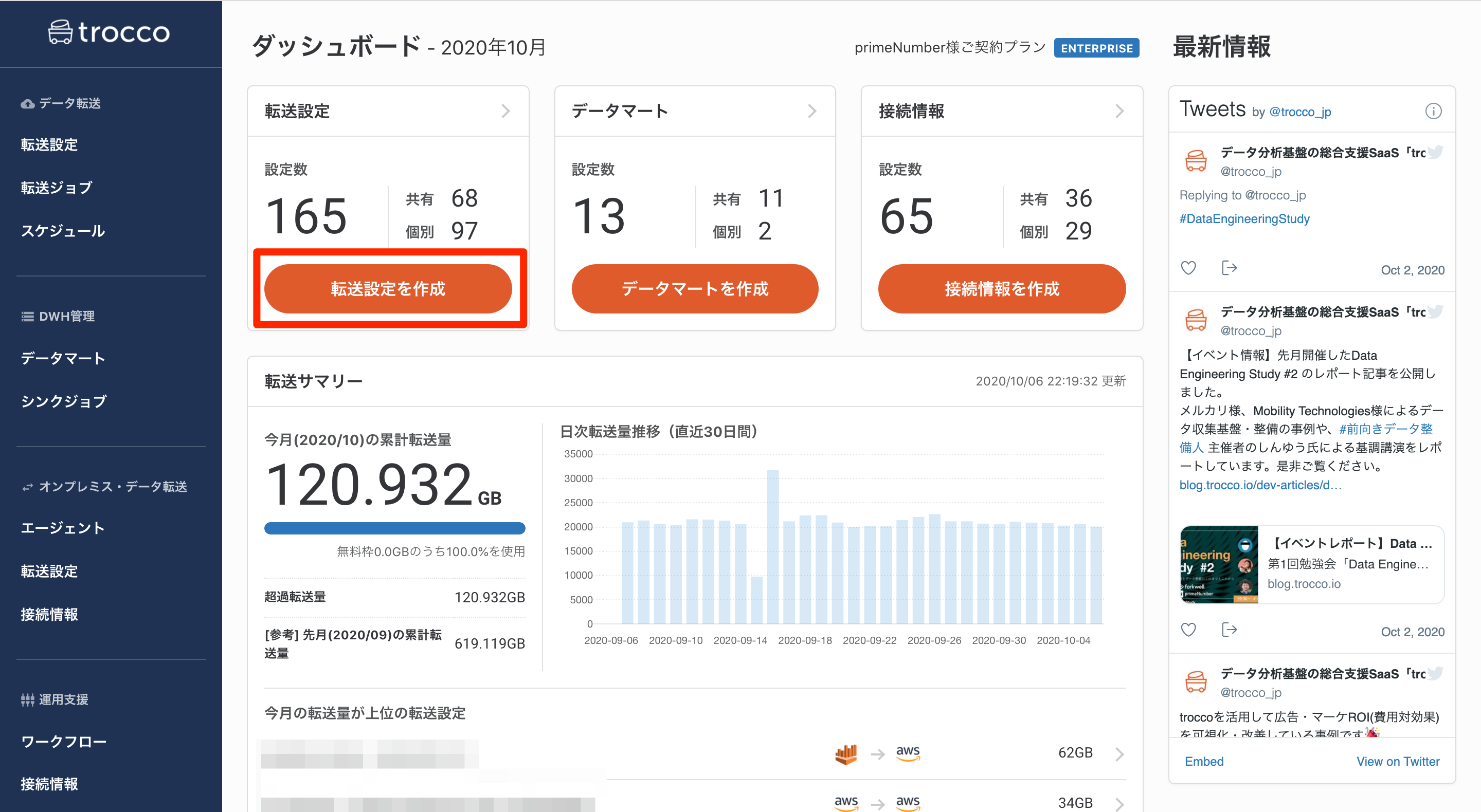
転送元に「AWS Cost Explorer」を指定し、転送先に「Redshift」を選択して転送設定作成ボタンを押します。
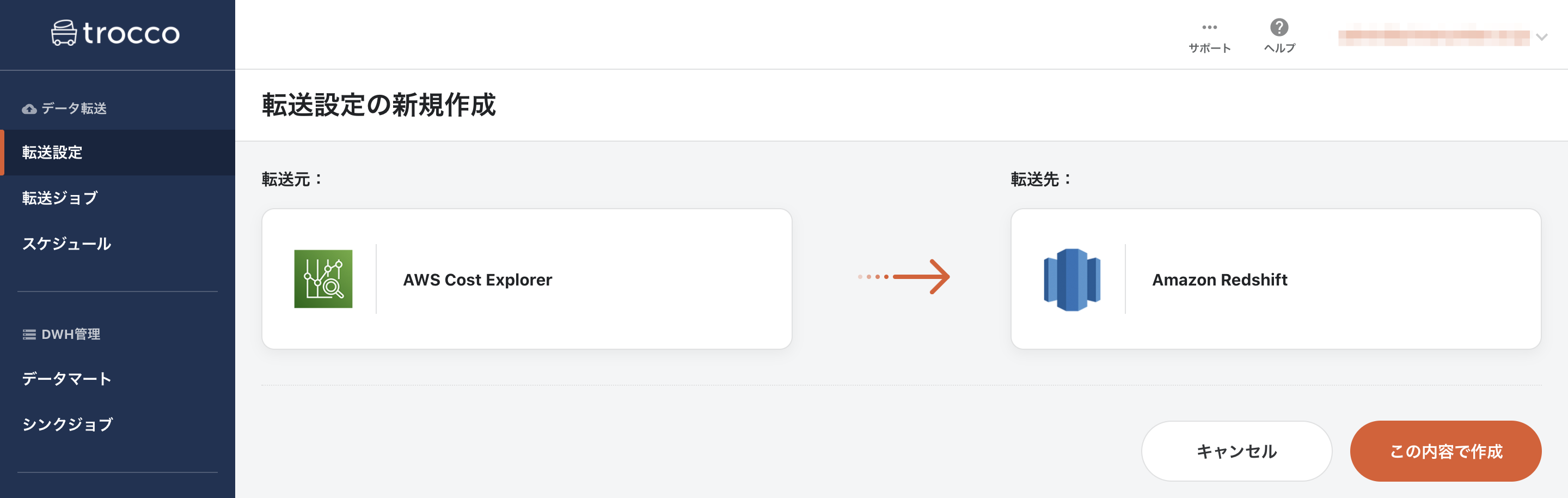
すると、設定画面になるので、必要な情報を入力していきます。
2-2. AWS Cost Explorerとの連携設定
あとで見たときに自分で分かるように転送設定の名前とメモを入力します。

次に「転送元の設定」内の「接続情報を追加」ボタンを押します。
別タブで接続情報の新規作成画面が開きますので、必要事項を記入して保存ボタンを押します。
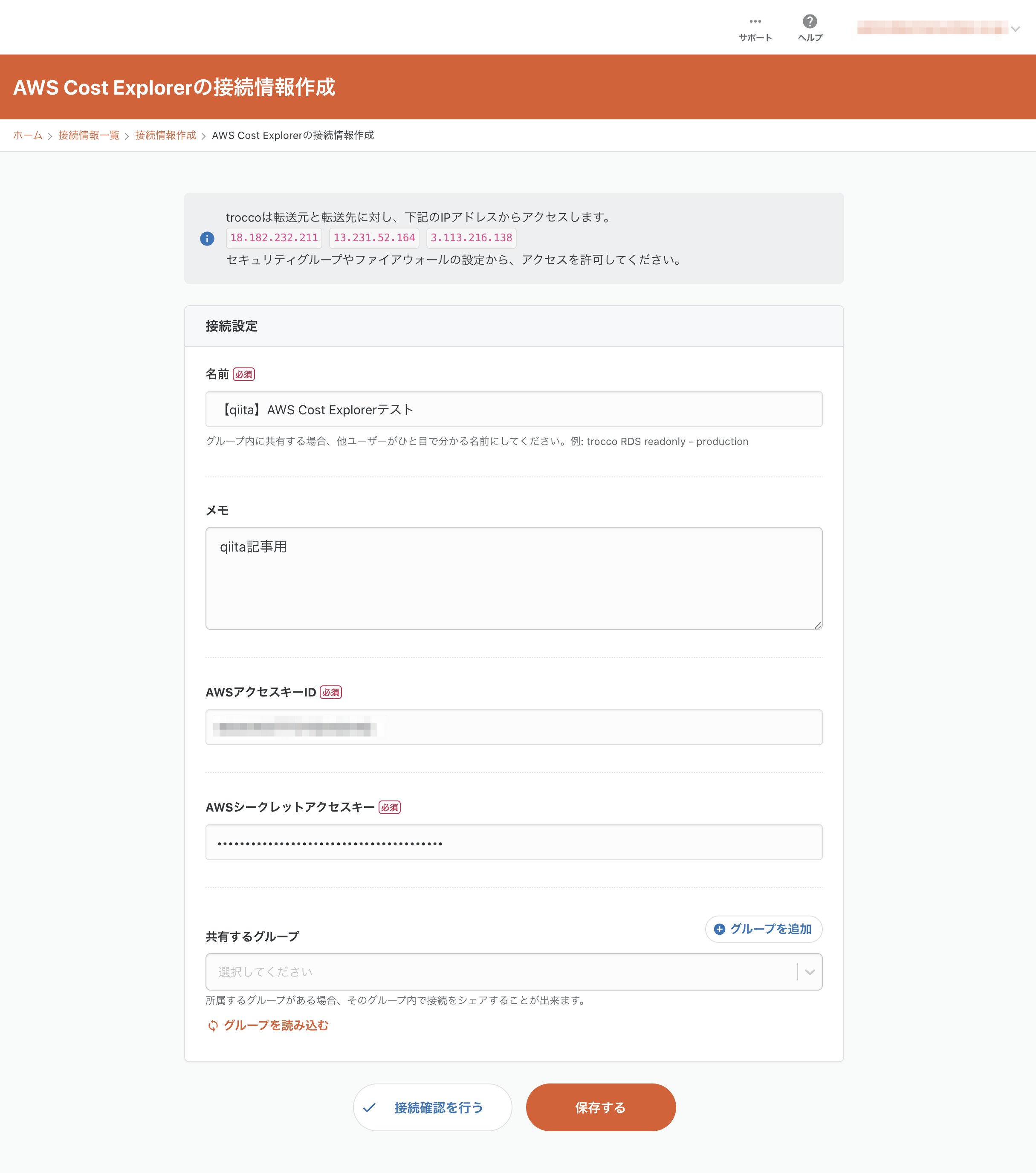
再度転送設定画面に戻り、接続情報の「再読込」ボタンを押すと、先ほど作成した接続情報が選択できるようになります。

これでAWS Cost Explorerとの連携は完了です。
2-3. AWS Cost Explorerからのデータ抽出設定
次に、どのようなデータを取得するかを設定していきます。
ここではUnblededCostのデータを取得してみます。
指標で「UnblededCost」を指定し、データ取得期間を指定します。

2-4. 転送先Redshiftの設定
転送元と同様に設定していきます。
転送先とするデータベース名、スキーマ、テーブルを設定します。
また、一時的にデータを保存するS3バケットとプレフィックスを指定してください。
最後に転送モードを選択します。insertとすることでテーブルにデータを追加することができます。
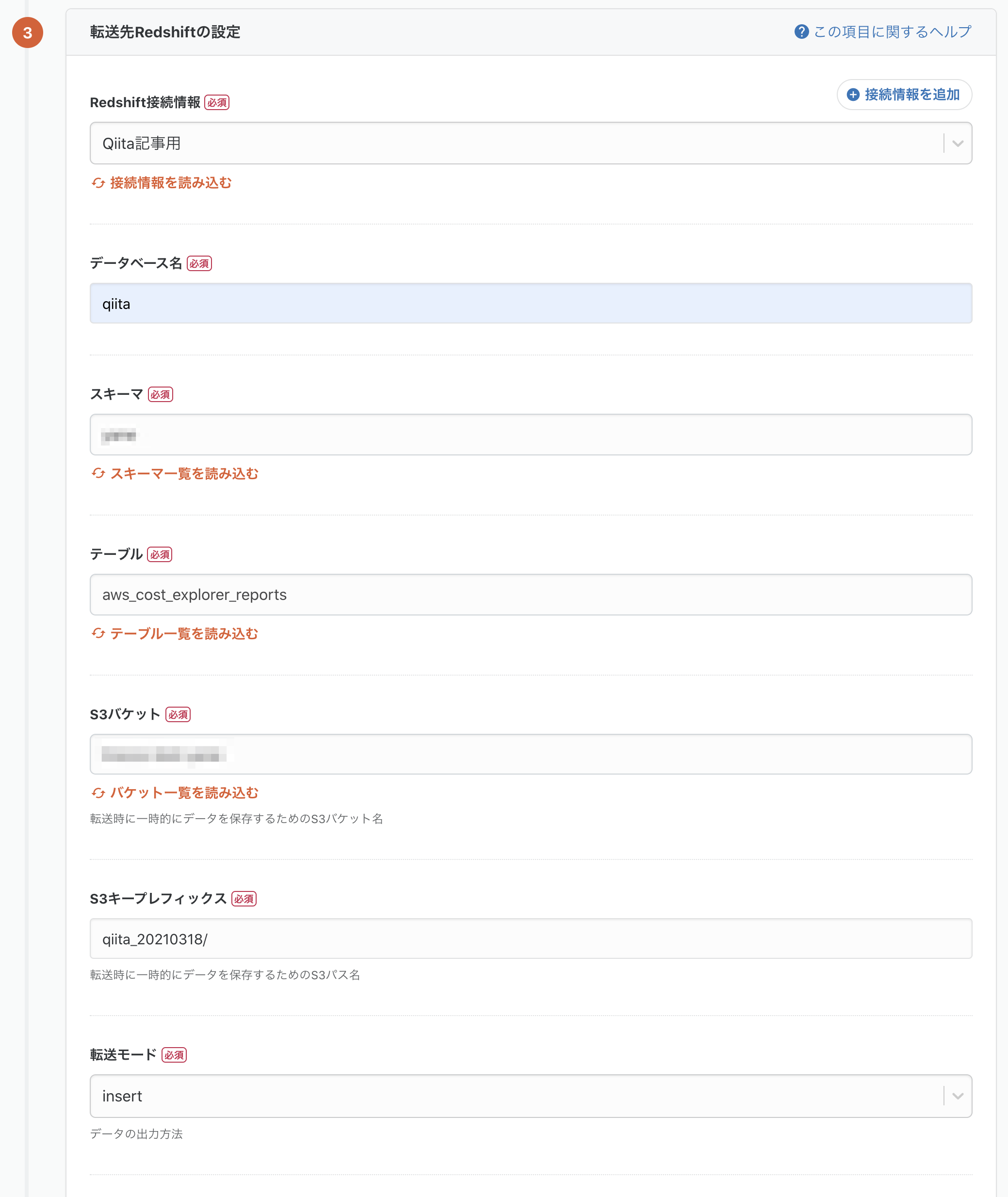
これで入力は完了です。「保存して自動データ設定・プレビューへ」をクリックし、確認作業に進みましょう。
2-5. データのプレビュー
少し待つと、転送元のデータがプレビューされます。ここではAWS Cost Explorerから取り込んだデータが表示されています。

転送したいデータが取れているので、このまま「確認画面へ」で次に進みます。
次の画面では転送設定の内容確認を行うので、設定の確認が終了したら右下の「適用」のボタンを押します。
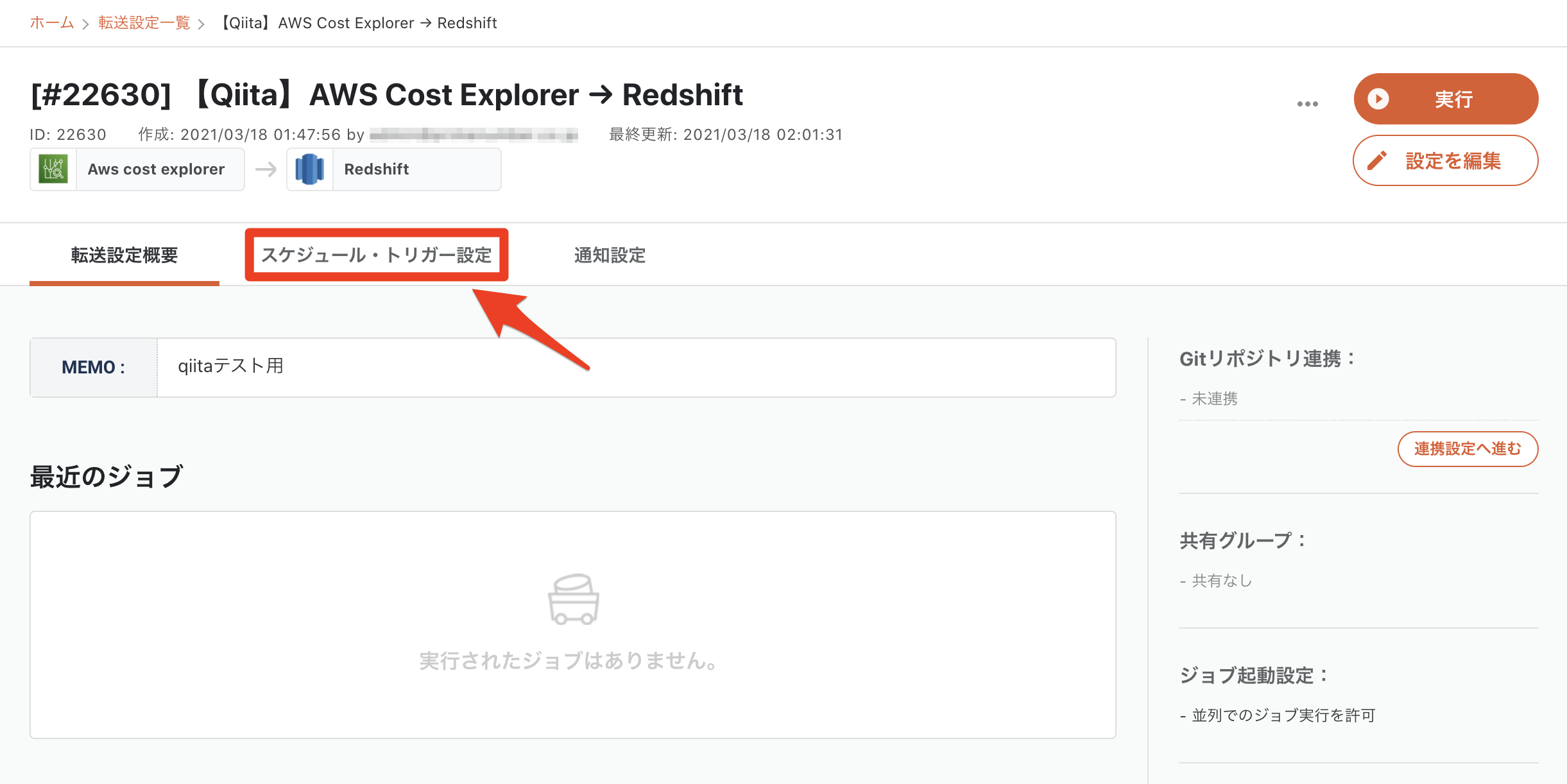
2-6. スケジュール・通知設定
「スケジュール・トリガー設定」タブを開きます。
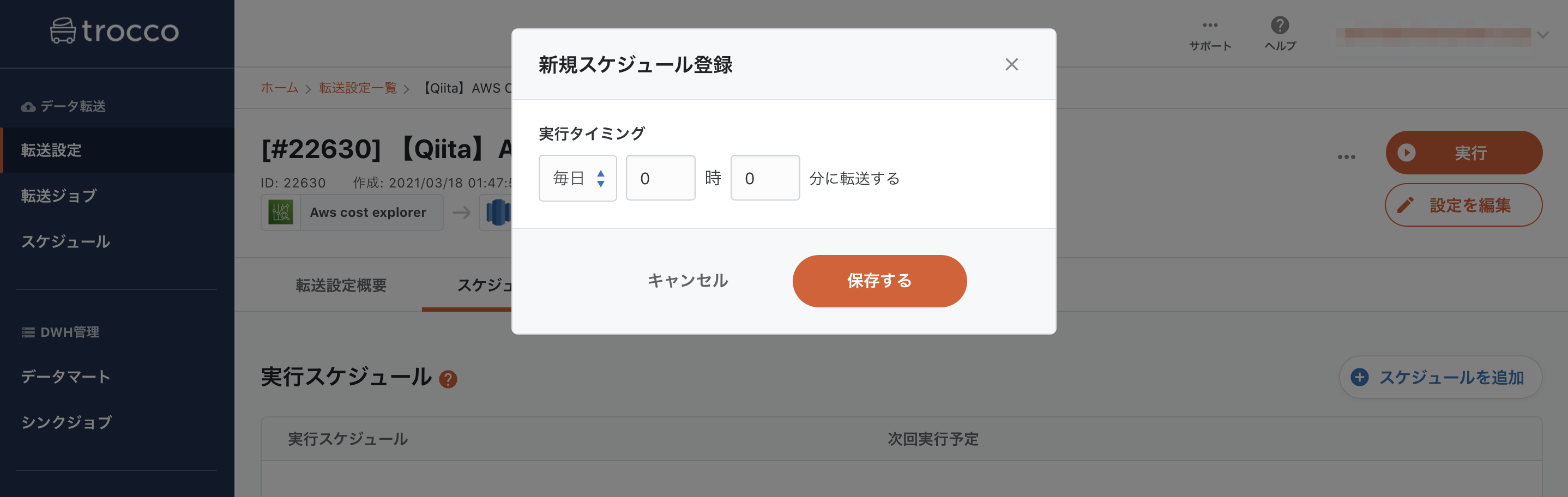
「スケジュールを追加」ボタンを押すと、以下の画像のような入力欄が出てきます。ここで実行スケジュールを設定することで、転送を定期的に実行し自動化することが出来ます。
2-7. データ転送ジョブの実行
設定は以上です。最後に、手動で転送ジョブを実行し、Redshiftにデータを送ります。
手動で実行する場合はジョブ詳細画面の「実行」ボタンを押します。

これで転送は完了です!
3. Redshiftの設定
特に設定することありません。データが転送されているので、今すぐに分析・可視化を行うことが出来ます。
データがきちんと送られているかをプレビューで確認してみます。

転送されていることが確認できました!
4. Lookerで可視化
それでは、これらのデータをLookerで可視化していきます。
まずはRedshiftとLookerを接続の設定を行います。
管理タブを開いて「Database」の「Connections」を開きます。
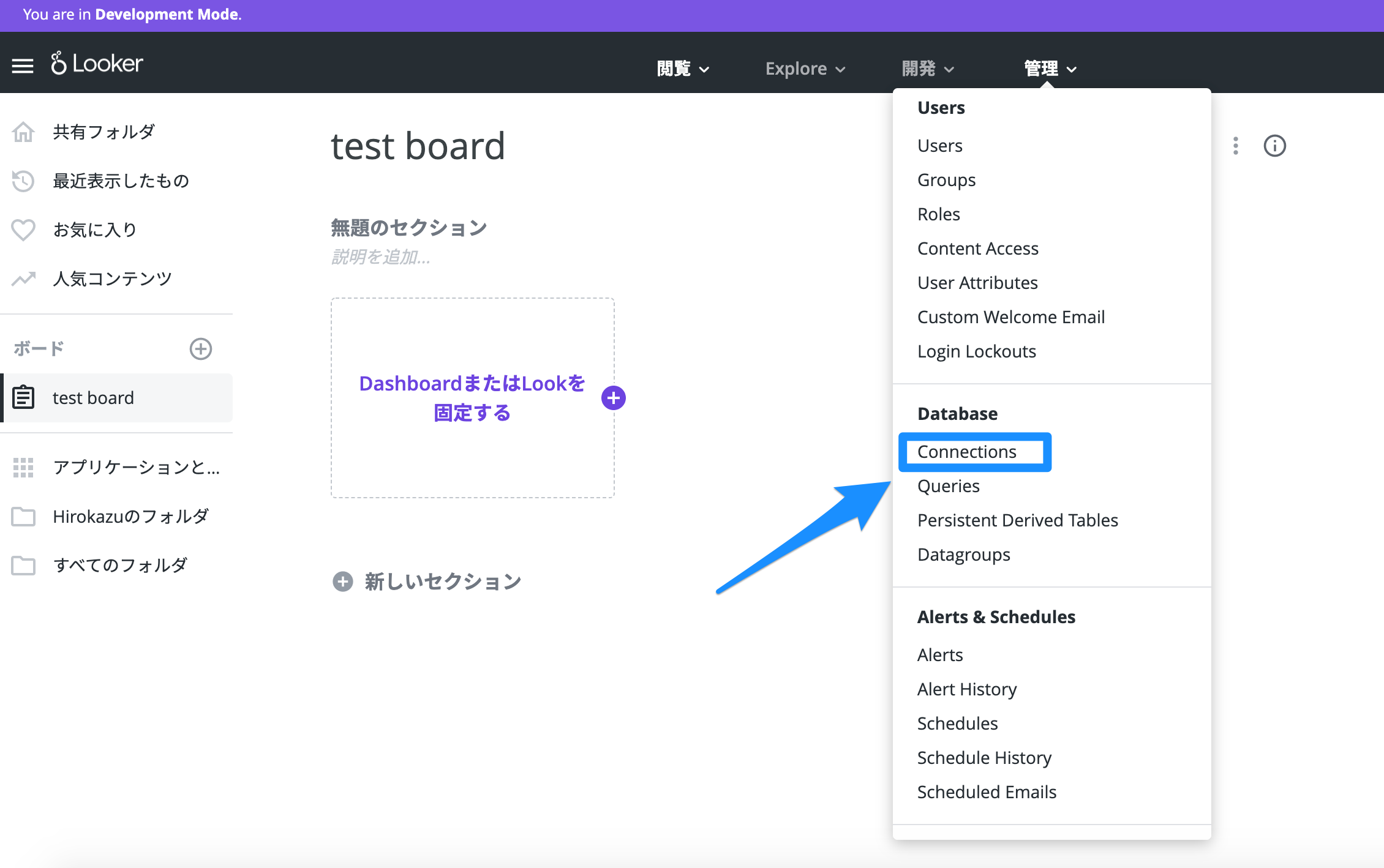
接続しているデータベース一覧が表示されています。ここで「Add Connection」→「Database Connection」から接続するデータベース情報を入力します。


Redshiftのデータベースに接続できたら、次はデータを可視化するために必要なLookMLプロジェクトを作成していきます。
開発タブを開いて「LookMLプロジェクトの管理」に移動します。
「New LookML Project」から新しいLookMLプロジェクトを作成します。

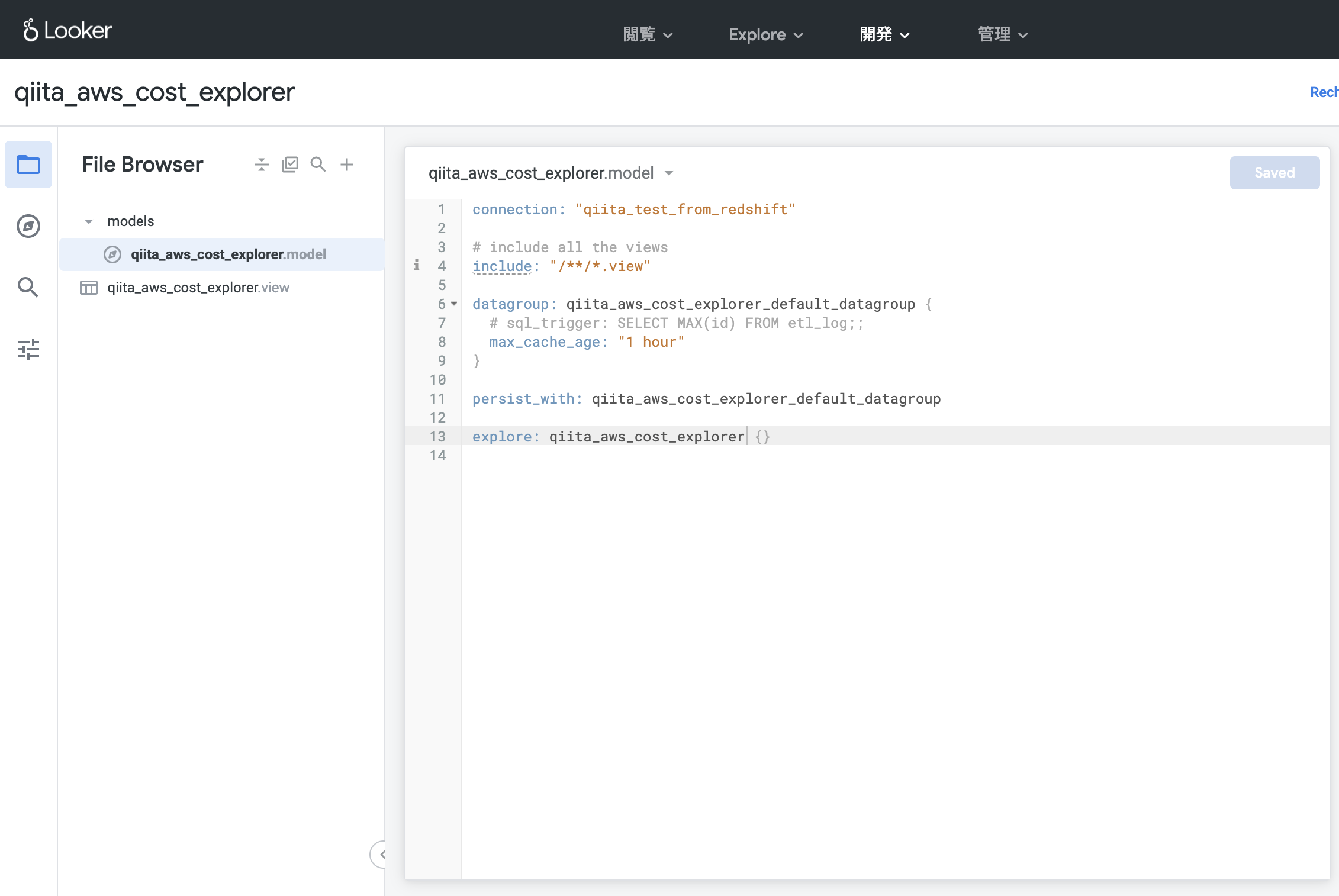
「Create Project」を押したら、エディタでmodelとviewを定義します。
後々必要になるので、modelの中ではexploreを設定しておきましょう。
(書き方が分からない場合はLookerの公式ドキュメントを参照してください)
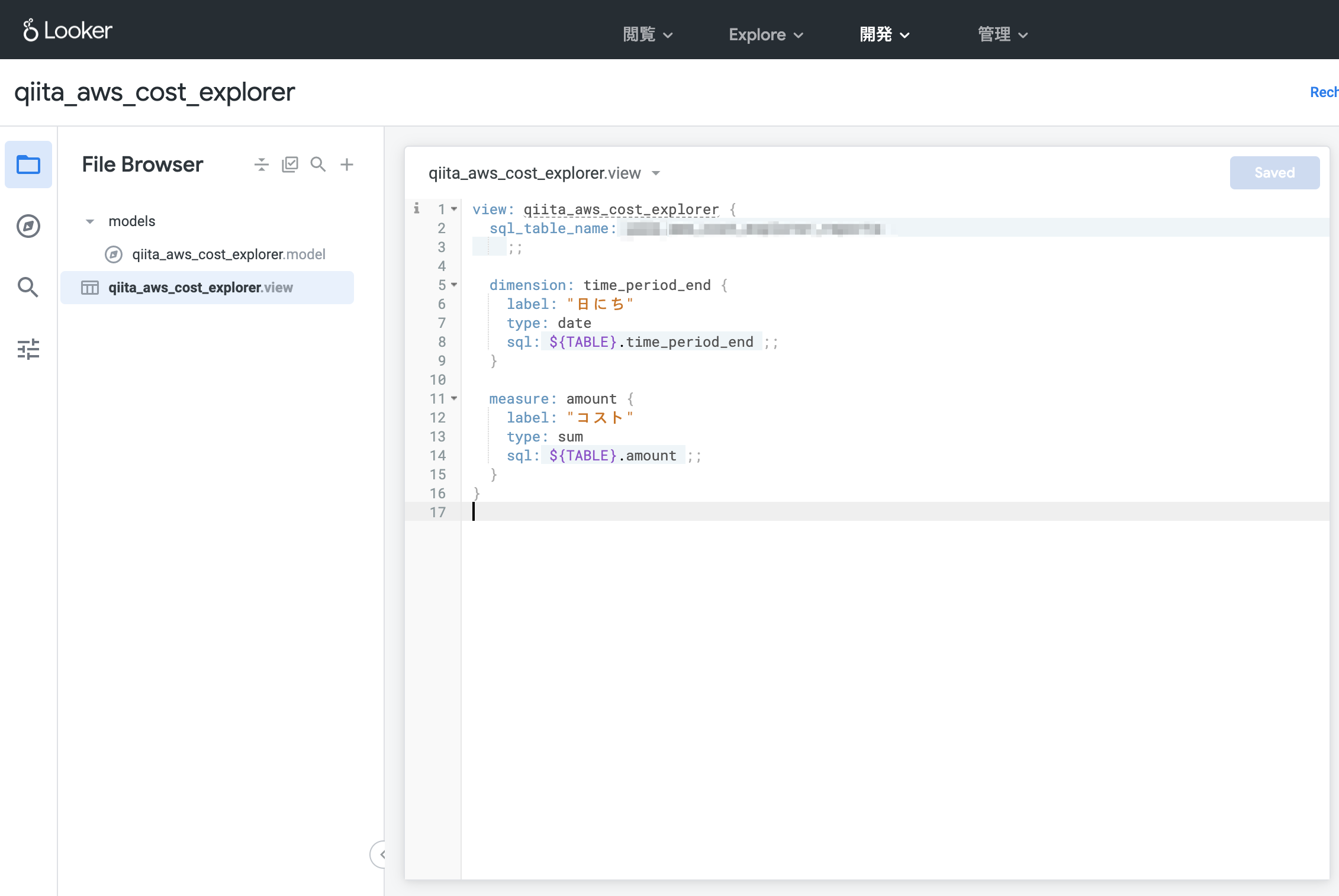
これでグラフを作る準備が整いました。
トップページに戻って「New」からDashboardを作成します。

白紙のダッシュボードができました。ここに各種グラフを追加していきます。まず「Dashboardの編集」を押します。

続いて、「タイルの追加」を押して、新しいグラフを作成していきます。
先ほどのmodel内で定義したExploreを選択します。

DIMENSIONSにグラフの横軸に表示したいデータ、MEASURESにグラフの縦軸に表示したいデータを設定し、Tileに表示したいデータをプロットします。ここでは日毎のコストをまとめてみます。
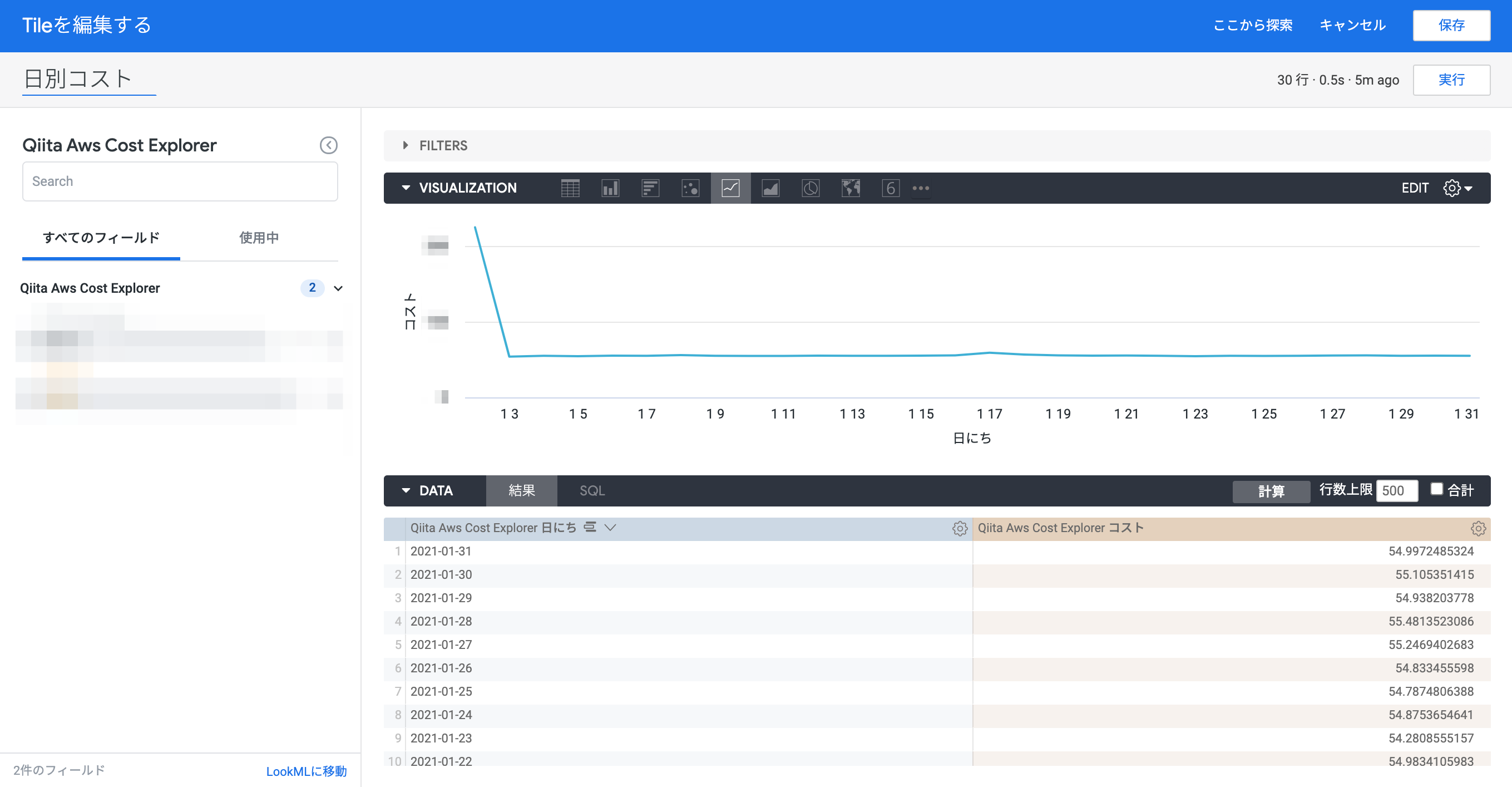
これで一つTileが完成しました。この調子で他のTileも作成すると、今回のゴールであるAWS Cost Explorerのデータダッシュボードが出来上がります。


まとめ
いかがでしたでしょうか。troccoを使うとAWS Cost Explorerの管理画面を触ることなく、簡単にデータを取得し、DWH(Redshift)に貯めることが出来ます。
Redshiftにデータを貯めると、Lookerと連携することでデータを使ってグラフを作り、可視化できます。
実際に弊社サービスのtroccoにおいても、マーケティングKPI等をこのような流れで収集・分析しています。
ぜひ広告データ分析の際にはご活用ください。
https://trocco.io/lp/index.html
実際に試してみたい場合は、無料トライアルを実施しているので、この機会にぜひ一度お試しください。(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内することができます)
その他にも広告やデータベースなど、様々な分析データをETL・転送した事例をまとめました。
troccoの使い方まとめ(CRM・広告・データベース他)