はじめに
本投稿は、Schooの2016年末特別企画「Schoo advent calendar 2016」の記事になります。
初っ端なので悩みましたが、今回はSchooの幾つかの環境の中から(比較的最近に手を入れた環境として)、「開発環境」について書いてみたいと思います。
Advent Calenderの最初としては、これからメンバーが書くであろう記事のなかでも利用されている環境かもしれませんので。
Schooの開発環境について
Schooでは2014年よりDocker環境下での開発環境を用意しています。
つい先日に(Docker1.12のリリースにあわせて)環境を再構築しましたので、そのあたりをサックリとまとめてみたいと思います。
まずは全体構成を
まずは、、、言葉で説明するよりも先に構成図を貼り付けておきます。
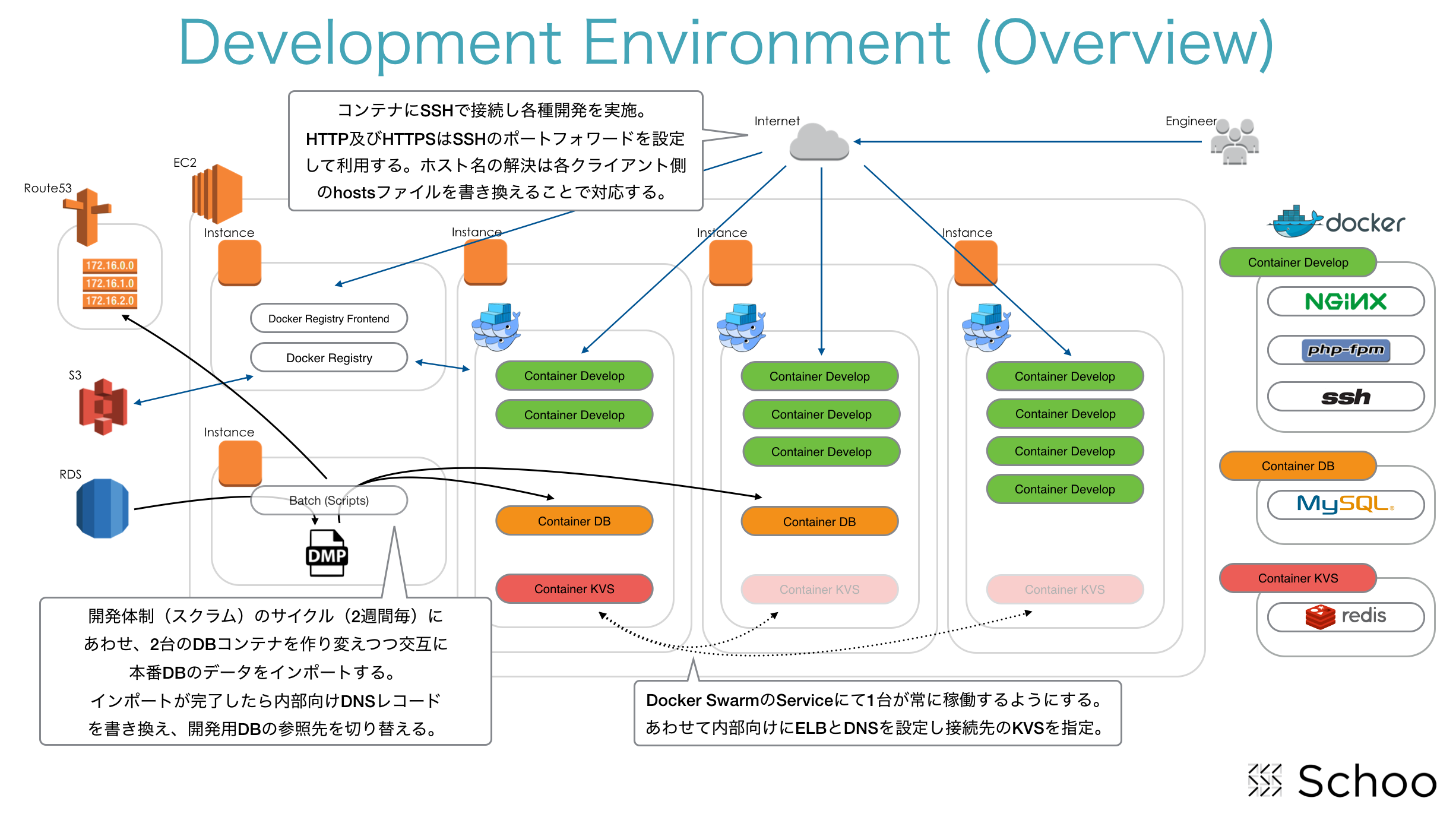
上記をもとにして細かなところを全部ではありませんが、以降にて説明していきたいと思います。
Docker Cluster群
Dockerは1.12からdocker-engineにCluster管理機能がビルトインされています。
ビルトイン機能となったことでClusterが組み易くなっているので、まだ触ったことのない人はサッサと触ってみることをオススメします。
簡単な例を示すと「如何に組みやすいか」を示すことができると思うので例を上げてみます。
例えば2台のDockerがあるとして、まずは1台目で以下のようなコマンドを実行します。
- 1台目
$ docker swarm init \
--listen-addr $(curl http://169.254.169.254/latest/meta-data/local-ipv4):2377 \
--advertise-addr $(curl http://169.254.169.254/latest/meta-data/local-ipv4)
上記ではSchooの場合はAWSを使っているので、自身のIPを$(curl http://169.254.169.254/latest/meta-data/local-ipv4)として取得していますが、利用される環境にあわせてこの部分は変更してください。
- 2台目
1台目で実行したコマンドの結果として2台目以降で打ち込むべきコマンドが表示されますが、例えば以下のようなコマンドになります。
$ docker swarm join \
--token JDFKOI-1-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX-7XXXXXXXXXXXXXXXXXXXXXXX \
172.16.83.100:2377
上記は例なのでIPは適当ですし、tokenも伏せ字で置換えてあります。
ハイ!完成!!
2台目以降で実行するコマンド内のIPは1台目のIPとなるので、2台目以降とでは上記の場合は2377番ポートでの疎通がとれていて、tokenに間違いなければ、これだけでClusterが組めちゃいます。
またCluster化した環境下でコンテナを実行する場合は、基本、非Cluster環境下で使っていたrunサブコマンドの代わりにserviceサブコマンドでcreateと置き換えるだけです。
他にもnodeサブコマンドなどもありますので、必要に応じて利用してください。
さて、開発エンジニア陣が作業するのは、このCluster(Multi-AZで作ってあります)上に配置されたコンテナになります。
他にもCluster内には開発用のDBやKVSとしてRedisをコンテナとして動作させていますが、これらについては以降で説明することにします。
またこのCluster環境下のコンテナは、開発エンジニアだけでなくデザイナーも自身で利用するコンテナを立ち上げ、そこで各ページのレイアウトやCSSなどを作成/変更しGithubへと対応分をpushするといったように、開発エンジニアと同じように利用しています。
Docker Registry
Imageの格納先(保存先)となるRegistryについても、簡単にではありますが触れておきます。
今であれば、どこからでもPrivateに使うことが可能なRegistryは選択肢として幾つかありますが、SchooがDockerを利用し始めた頃は選択肢がなく、Privateなものは自分たちで用意するしかありませんでした。
ということで、Registryサーバ自体もDocker環境の利用開始時から、AWS EC2上に自分たちで立ち上げたものを利用しています。
ちなみに、このRegistryが動くサーバもDockerで構成されており、Registryも、そのFrontendもコンテナで動いており、イメージはAWSのS3に保存されています。
また、このRegistryサーバはPrivateなので認証はかかっていますが、どこからでも利用可能となっており、例えば「インターネット越しでカフェでノートPCから」でもpullすることができるので、作業場所の制約もRegistryサーバにはありません。
あまり複雑でもないしRegistry周りはググれば沢山情報出てくるようなので、ここの説明はこれくらいでw
Docker Images
次に開発環境として用意しているImageについて説明します。
先に載せた構成図の右端に書かれていますが、基本で用意しているのは以下のImageになります。
- Nginx+php-fpmが動作するSSHでのシェルログインが可能なイメージ
- ちょっとだけチューニングしてあるMySQL
- ほぼ素の状態のRedis
上記のうち自身の開発環境として利用するのは1の、「SSHでログイン可能な、開発環境としての設定が若干してある本番とほぼ同等の設定のNginxやphp-fpmをインストールした、Amazon Linux環境を丸々イメージ化」したもの(長いw)になります。
いつもイメージを0ベースで作るときは、AWSのt2.microとかの小さなEC2インスタンスで諸々作り込んだ後に、そのルートディスク(EBS)を別のRegistryサーバなどのDockerコマンドが動く環境にマウントし、
$ cd <イメージ化したいルートディレクトリ> && sudo tar --numeric-owner -cjp . | docker import - <イメージ名>
とコマンド実行してイメージ化しています。
今ではAmazon Linuxの公式イメージが出ているので、こんなことやらなくても良いのですが、公式イメージの配布が始まる前は本番構成と同じような環境を作成するために、このようにしてImageを作成していました。
さて、次に2の「ちょっとだけチューニングしてあるMySQL」ですが、これはDocker Registryで配布されているMySQLイメージに文字コードやInnodb周りのチューニングをちょっとだけしてあるものです。
これを元のイメージとして動かすコンテナとしては、複数のコンテナを開発のスプリント期間にあわせた2週間サイクルで作り直すようになっています。
コンテナの再作成を前提にしているため、データディレクトリは永続化していません。
DB周りについては、以降でもう少し説明します。
最後に3の「ほぼ素の状態のRedis」ですが、これは、、、ほぼ何もしていませんw
Cacheとしての利用が原則ですので、「データが空になった際」でも「正常に動作する必要がある」だろうし、そうでない場合も「即時で復旧できる手段が明確になっている必要がある」ということから困ったら作り直しで対応したいがためです。
「だったらmemcacheでも・・・」ってツッコミが聞こえてきそうですが、「そこは、それ。。。」w
「一時的にでも永続化すると楽にコード組める情報ってあるじゃないですか。」的な理由でRedis使ってます。
DB(MySQL)コンテナ
さて先立ってImageのところで頭出ししましたが、DBのコンテナは環境内に複数台が動作しています。
Sourceコードの最新はGithubから持ってくれば良いのですが、データの最新となるとちょっと面倒ですよね。
Schooでは仕組みとして以下の図のような構成と処理順序で、開発サイクルにあわせて2週間毎にDBを最新の情報に入れ替えています。
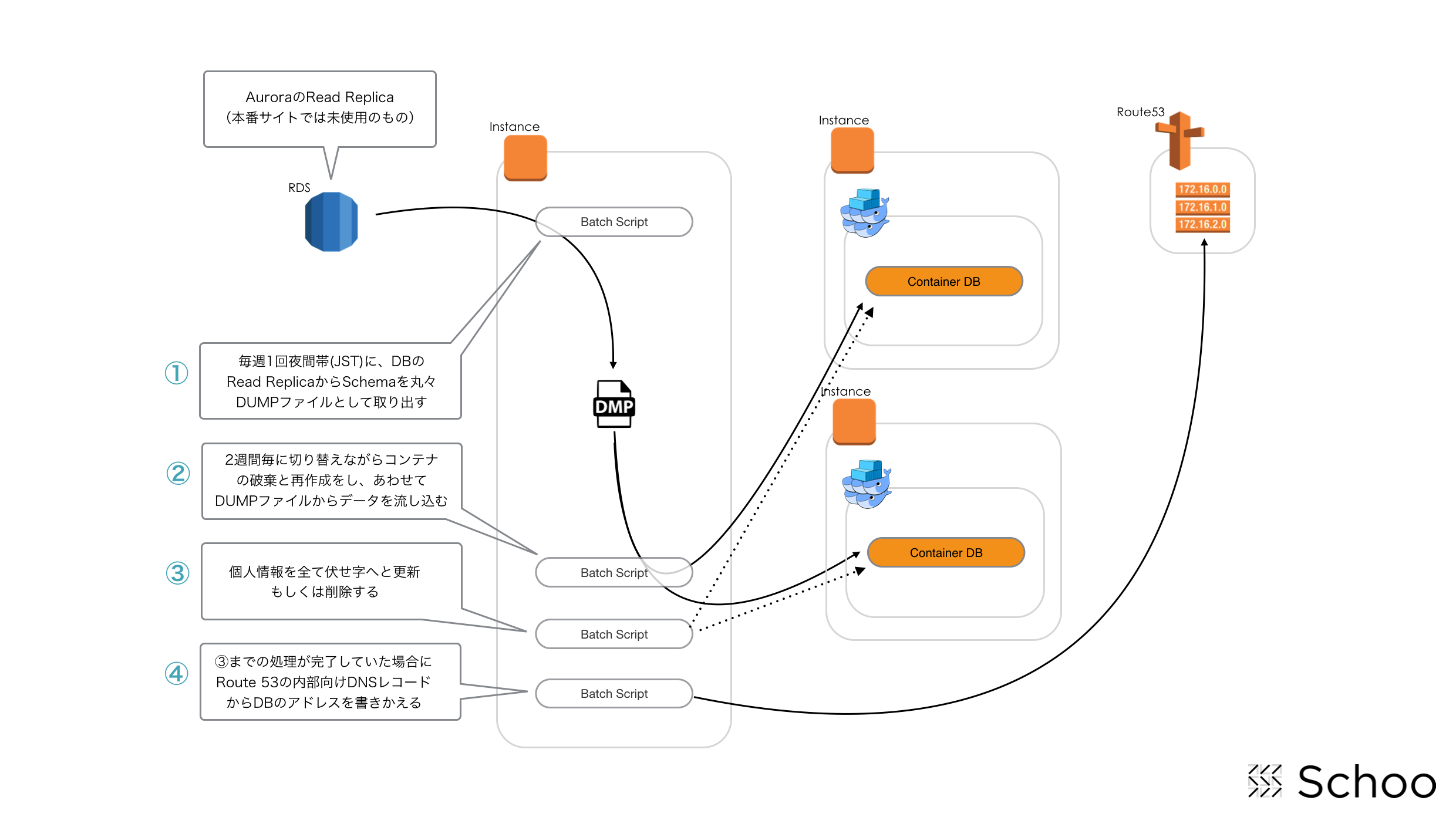
上記図で示しているように、内部的には幾つかのScriptが繋がって一つの仕組みとなっているのですが、以下の処理順序になっています。
- 夜間にDBの該当SchemaをDUMPファイル化
- 2週間毎に接続先を変えつつDBコンテナを再作成しDUMPファイルからデータを流し込む
- フィルタリング処理として個人情報を伏せ字(「X」とか)に更新(UPDATE)
- Route53で管理している内部向けDNSの開発用DBサーバのレコードを更新
仕組みとしては上記のように単純になっていますが、2週間毎に接続先を変える処理部分とかは、仮に開発用DBサーバが増えてもスクリプトに手をいれること無く対応できるようになっていたりもします。
また、伏せ字への変換は一見面倒かとは思うかも知れませんが、開発で使う情報ですので「ユーザに対し間違った情報を送りつけることがないように」であるとか、そもそも「個人情報保護」の観点から誰もが簡単に利用できるようにするべきではないためにも、フィルタリングの仕組みを組み込んであります。(とはいえ、簡単なストアド・プロシージャなんですけどね。)
で、最後に全て正常に完了していたらDNSのレコードを更新することで、開発サイクルにあわせてDBを切り替えるようになっています。(Source上の接続先DBは、IPアドレスではなくDNS登録のあるレコードで記載されてます)
あっ、ちなみに「開発サイクルであるところの2週間を超えるような開発案件があった場合で且つDBに対する変更が必要な場合はどうするの?」問題に対しては以下の何れかにて対応しています。
- 最初の2週間でDB変更をする設計と実装前提で作業をしてもらって、先に本番DBへの変更を2週間以内にやっておく
- 切り替わり都度に開発DBに対する変更を作業する
ちなみにCluster組んでいる環境下なんで、このあたりとあわせてゴニョゴニョと・・・って構想もあるんですが、まだ手が出せていないです。
そのうちやります。たぶんw
開発コンテナの利用
開発コンテナはDockerなので自身のPC内にpullすることもできますが、基本的にはCluster上に構築したコンテナ内で開発します。
SchooはWebサービスなので、ブラウザアクセスが基本なのですが、開発時にブラウザで確認する際はポート80番、443番であるほうが色々と都合が良いこともあるので、サーバ上で立ち上げたコンテナの任意のポートを自身のPC上の80番と443番のポートにSSHでポートフォワーディングして利用します。
ちなみに、ポート80番と443番は所謂「エフェメラルポート」になるので、自身のPC上であればroot権限が必要なことが環境によっては注意すべきポイントでしょうか。
ポートフォワーディングして自身のPC上の80番と443番のルーティングをしたら、自身のPCに適当なホスト名(「hoge.schoo.jp」など)をPC内のhostsファイルを変更するなどして割り振り、この設定したホスト名でブラウザからアクセスし各種確認を行います。
SourceはGit管理されてGithubに上げるようになっているので、コーディング自体は自身のPCでもコンテナ内でも、エンジニア毎によって様々な方法、自由にコーディングしています。
また、コンテナという単位で各自環境を持っていますので、これをImage化してRegistryに登録したりというようなことも、今の段階ではエンジニアが自由に行っています。
個人的なImageが増え過ぎたら整理するなり、ルール化するなりする必要はあると思いますが。
また、各個人のコードをMergeする場合の環境として「Integration(結合)環境」もあるのですが、これもDocker上に構築されています。
Slackを使ったChatOpsな環境もあるので、リリースする前に上記のIntegration環境にSourceを上げたりといったところも一定自動化されています。
このあたりはきっと誰かが記事化してくれるでしょうからw、この程度の説明にしておきます。
まとめ
以上がSchooの開発環境の概要説明になります。
今回は開発環境を取り上げて説明してみましたが、Schooの各種環境ってAWSの様々なサービスを数多く使っているので(AWSからは離れられないかも…)、一つ一つを分解して細かに説明していくと・・・普通に丸1日くらいは時間が必要になります。
とはいえ、原則「疎結合であること」を前提に組み合わせ、分離していくことができるように構成を考えるときには注意していますし、大部分がそのようにもなっていますので、今回のように一定単位で切り出しながら記事化も良いかもなぁ…と思いました。
とうことで、次の方!よろしくおねがいします!!