こんにちは.
本記事では,以前構築したデータ収集パイプラインを使って,実際に自作双腕ロボットでデータを収集し,VLA (Vision-Language-Action) モデルを学習させ,布を折り畳むタスクに取り組んだ話を紹介します.なお,ここでいうVLAモデルとは,Physical AI技術の一つであり,カメラ画像や言語指示等を入力として受け取り,ロボットの行動(系列)を出力するモデルを指します.
本記事の要点は以下の通りです。
- 自作双腕ロボットILOHAで布畳みタスクの実機データを約300エピソード収集した
- ACTでは布の端の把持が不安定だった一方,X-VLAでは安定した折り畳みが可能だった
- データ品質ラベルをプロンプトに付与して,異なる品質のデータを併用した
- データ収集時との環境変化によりPolicy性能が低下したが,追加Fine-tuningで改善した
- 実機ではモデル性能以前に,配線やUSB帯域がボトルネックになった
自作ロボットとMeta Quest 3を組み合わせて,ロボットデータ収集パイプラインを構築する方法に興味がある方は,以前の記事もあわせて読んでみてください.
Quest 3と自作ロボットで,低コストにロボットデータ収集システムを構築した話
さて,2024年末にPhysical Intelligenceの$\pi0$が登場して以降,世間のPhysical AIに対する注目が急速に高まっているように感じます.
私が所属する京都大学でも,Physical AIに関心を持つ学生・研究者が増えており,そのような流れの中で 2025年7月にはKyoto University Physical AI Community (KUPAC) という学生主導のコミュニティが発足しました.
その活動の一環でSusHi Tech Tokyo 2026 に出展し,本記事で紹介する布畳みロボットを展示しました.
Sushi techの西1ホールC655でハンカチ畳みVLA展示してます!#KUPAC pic.twitter.com/b173UvaVF8
— K Hiratsuka (@hirekatsu0523) April 27, 2026
以下の部分では,こちらの布を折り畳むVLAロボットをどのように開発したか,また開発中に直面した課題について紹介します.
タスク設定
今回取り組んだタスクは,ALOHAを模倣して独自開発した双腕ロボットであるILOHAを用いた,布の折り畳みです.
布の折り畳みは,人間にとっては日常的な動作ですが,布が柔らかいために,折り畳み中に滑ったり,ねじれたりと,把持位置が少しずれるだけで挙動が大きく変わるため,従来のロボット制御技術にとっては難しいタスクといわれています.
このように従来手法にとっては難易度が高く,なおかつ実用性に結び付きやすい,布の折り畳みタスクに取り組むことで,模倣学習やVLAの有効性を示せるのではないかと考えました.
環境のセットアップは以下の通りです.
- 双腕ロボットILOHA
- 白のテーブル
- 30cm四方のハンカチ
今回は,ハンカチは単一種類のもののみを扱い,初期配置としてはまっすぐに広げた状態で,机の中心付近に,ある程度ランダムに配置しました.
ハンカチについては,ロボットにとって扱いやすいサイズであり,なおかつ程よい厚みを持っていることを条件として選定しました.
なお,このタスクでは,布を2回目に折り返した後に,見た目が長方形に近いことを成功条件としました.
データ収集・データキュレーション
データ収集
学習用データは,前回の記事で紹介したデータ収集パイプラインを使って収集しました.
慣れてきた pic.twitter.com/FqKGHeUnCz
— K Hiratsuka (@hirekatsu0523) April 21, 2026
データ収集時には,Policyにロバスト性を持たせるため,布の初期配置にある程度ランダム性を持たせ,さらに背景の物体の配置や,照明条件もさまざまに変更しました.
| 照明1 | 照明2 | 照明3 |
|---|---|---|
 |
 |
 |
また,布畳みタスクはテレオペレーションでやろうとすると,人間にとっても割と難しく,エピソードごとのデータ品質に大きな差が出ることが分かりました.
そのため,収集後に目視でデータを確認し,学習に使うデータを選別しました.
データキュレーション
収集したデータは,以下の3段階に分類しました.
| 分類 | A | B | C |
|---|---|---|---|
| 説明 | 通常の学習に使える高品質データ | 品質がやや低いデータ | 学習に使うのが難しいデータ |
| 数 | 200 | 53 | 54+ |
| 例 |
Cに分類したデータは,例えば以下のようなものです.
- 布を正しく把持できていない
- 途中で大きく失敗している
- ロボットやカメラの不具合が含まれている
Bに分類したデータは,タスク終盤で若干ミスをしているなど,完全ではないものの,タスクの学習には使えそうなデータです.
モデル選定
次に,実際にタスクを実行する機械学習モデルの選定方法について紹介します.
モデル選定において重視したのは以下の点です.
- lerobotと親和性が高い or 実機デプロイ含めてフレームワークが整備されている
- 布のような柔軟物操作の実績がある
- 学習や推論コストが現実的である
計算機としては学習用にRTX 5090,推論用にRTX 4090を用意していたので,その環境で動作することを一つの基準としました.
また,データ収集環境と展示会場の差異を考慮し,デプロイ時にオンライン強化学習を適用する手法についても調査しました.
当初,候補として挙がっていたのは以下のモデルです.
- lerobot系
- $\pi0.5$ + SARM
https://github.com/KyotoVLATech/lerobot-KVT/blob/dev/sushi/docs/source/sarm.mdx - $\pi0.6$ + RECAP
https://github.com/huggingface/lerobot/pull/3245 - X-VLA
https://github.com/KyotoVLATech/lerobot-KVT/blob/dev/sushi/docs/source/xvla.mdx - SmolVLA
https://github.com/KyotoVLATech/lerobot-KVT/blob/dev/sushi/docs/source/smolvla.mdx - ACT
https://github.com/KyotoVLATech/lerobot-KVT/blob/dev/sushi/docs/source/act.mdx
- $\pi0.5$ + SARM
- その他
- $\pi0.5$ + Online RL (RLinf)
https://github.com/RLinf/RLinf - Diffusion Policy (RL-100)
https://lei-kun.github.io/RL-100/
- $\pi0.5$ + Online RL (RLinf)
$\pi0.5$ + SARMに関しては,高品質なデータセットAを用いて報酬モデルであるSARMの学習を行い,その後,データセットA+Bに対し,報酬を割り当てて$\pi0.5$を報酬重みづけ学習する方針で進めました.しかし,SARMの学習が思っていたよりもうまくいかず,エピソード中の失敗している区間に高い報酬を割り当てるなど,意図しない挙動が見られたため,採用を見送りました.
$\pi0.6$ + RECAPは,報酬モデルの学習までは検証できましたが,検証に利用していた計算機環境では,$\pi0.6$の学習ができなかったため,採用を見送りました.
- RECAPによるエピソードに対する報酬割り当て
| 成功エピソード | 失敗エピソード |
|---|---|
 |
 |
X-VLA, SmolVLAに関しては,Genesis上に構築した,シンプルなピックアンドプレースタスクにおいて,X-VLAの方が高い性能を示したため,SmolVLAの採用は見送りました.
また,RLinfを用いた$\pi0.5$のオンライン強化学習については,要求される計算コストが高すぎるのと,実機デプロイが大変そうだったので採用を見送りました.
RL-100については,論文で高いタスク成功率が報告されていたため,再現実装を試みましたが,模倣学習からオフライン強化学習,オフライン強化学習からオンライン強化学習へ切り替わるタイミングでPolicyの性能が大きく低下する現象が確認され,解決に時間がかかりそうだったので採用を見送りました.
- 再現実装レポジトリ
また,ILOHAが関節配置や見た目においてALOHAとある程度互換性を持つことを生かし,産総研が公開しているAIST Bimanual Manipulation Datasetのfold系タスクデータを学習に使うことも検討していましたが,想定よりもデータ収集時の手首関節周辺の挙動が異なっていたため断念しました.
最終的な構成
最終的には,以下の2系統を用意しました.
- データセットAのみで学習したACT(ベースライン)
- データセットA・BでFine-tuningしたX-VLA
ACTは言語入力を用いない模倣学習ベースのベースライン方策として採用し,X-VLAはVLAの中でも軽量で扱いやすく,柔軟物操作の実績もあるため採用しました.
特に,X-VLAについては,xvla-soft-foldという,大規模な柔軟物操作データセットで学習された重み (xvla-folding) をFine-tuningのベースモデルとして利用しました.
学習戦略としては,$\pi0.7$で報告された知見に基づき,データ品質をプロンプトに含めることで,AとBのデータを区別しつつ,効率的にデータを利用して学習する方法を採用しました.
具体的には,高品質なデータセットAには,タスク指示文の末尾に,以下のようにQuality: Highを付与しました.
Grab the edge of the towel and fold it twice. Quality: High
一方で,そこそこの品質のデータセットBには,以下のようにQuality: Lowを付与しました.
Grab the edge of the towel and fold it twice. Quality: Low
そして推論時には,基本的にはQuality: Highを指定します.
この方法の狙いは,品質の低いデータを単純に捨てるのではなく,モデルに「この軌道は低品質である」という条件付き情報として与えることです.
これにより,高品質データだけでは不足する状態分布を補いつつ,推論時には Quality: High を指定して望ましい行動分布に寄せることを期待しました.
一応,Fine-tuning後にQuality: Low を指定した場合の,推論時の挙動も確認しましたが,定性的には大きな違いは見られませんでした.
この点については,データ量やタスク設定によって結果が変わる可能性があるため,今後もう少し丁寧に検証したいと思います.
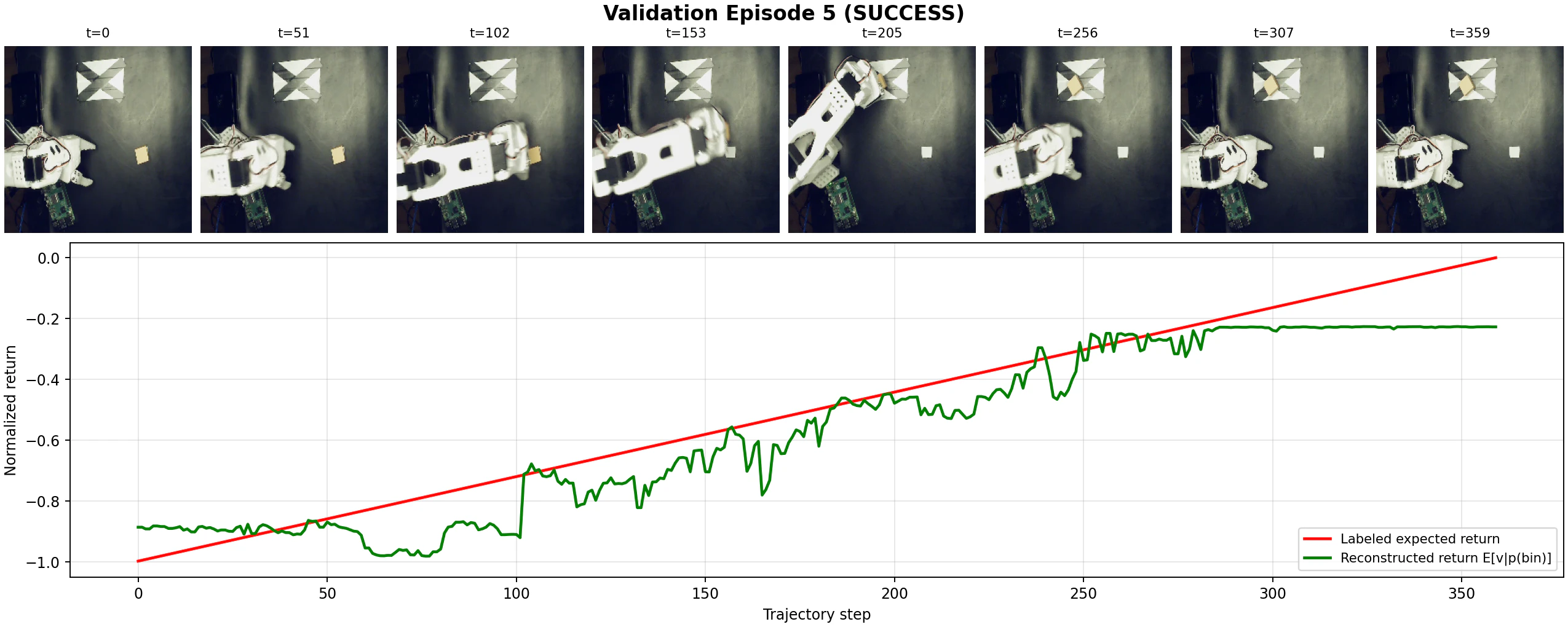
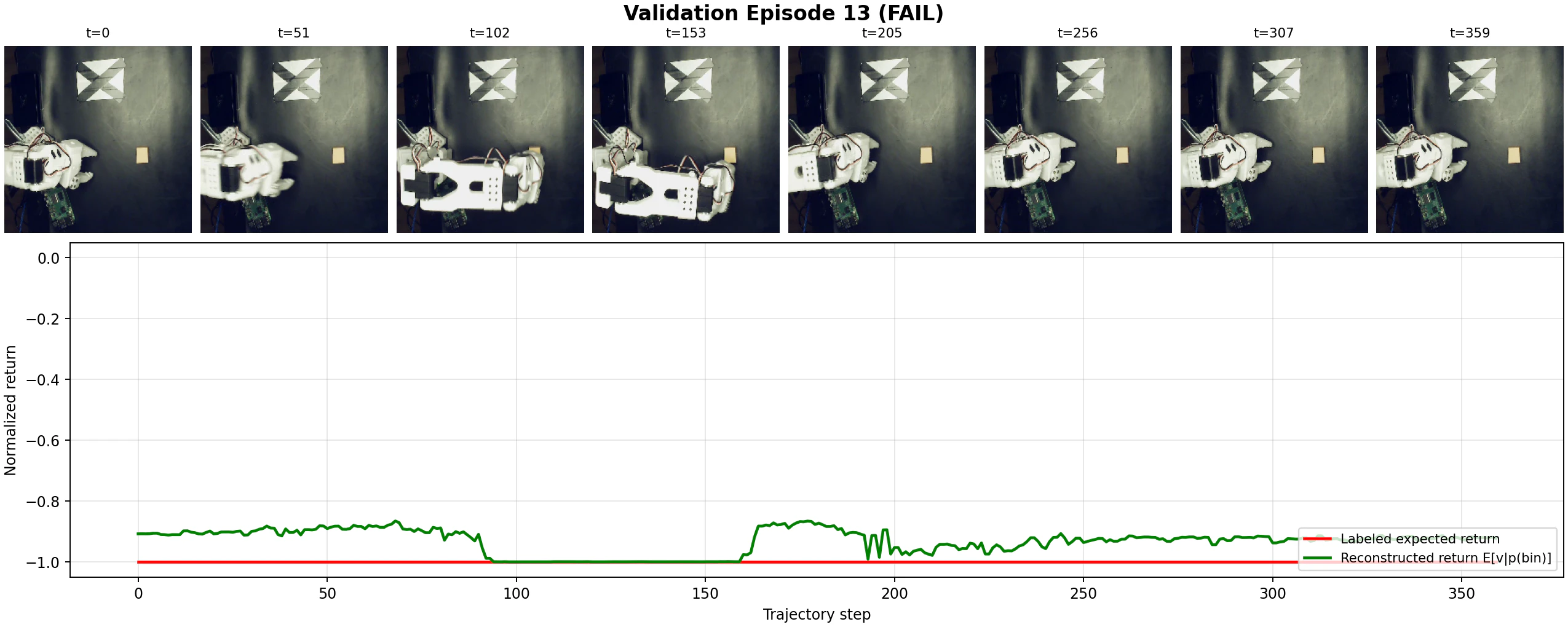
一方で,ベースラインのACTとX-VLAを比較すると,X-VLAの方が明確にタスク成功率が高いという結果になりました.
具体的には,そもそもACTでは布の端をうまく掴むことができませんでしたが,X-VLAは安定して布を畳むことが可能であり,布の初期配置に対するある程度のロバスト性も確認できました.
実機適用で発生した問題
モデルの学習以前に,実機システムとして安定動作させる部分でも多くの問題がありました.
以下ではその一部を紹介します.
Robstrideのコネクタ問題
今回使用している双腕ロボットILOHAはアクチュエータとして一部にRobstrideを採用しています.
このRobstride周りでは,コネクタや配線まわりの安定性に悩まされました.
一般に,ロボットアームの配線には動作中に振動や引っ張りが加わるため,コネクタや配線への負荷は大きいと考えられます.
しかし,Robstrideの一部のモデルが採用しているXT30 (2+2)コネクタには,爪が付いていないため,比較的コネクタが緩みやすい構造となっています.
また,ロボット動作時に自作した配線のはんだにクラックが生じて,動作異常が生じる場合もありました.
これらのコネクタの緩みや,配線の破損はソフトウェア側からは同じようなエラーとして観測されるため,問題の特定に時間がかかりました.
配線については負荷がかかりにくいような配置に変更するなどし,コネクタについては結束バンド等で固定し,緩まないように対策しました.
ロボット開発では,ソフトウェアだけでなく,ハードウェアの基礎的な信頼性確保が重要だと改めて感じました.
RealSenseの帯域問題
今回は観測用カメラに3台のRealSenseを使用しましたが,このようなセットアップにおいてはPCのUSB帯域が問題になりました.
VLAや模倣学習では画像入力が重要になるため,カメラ画像の安定取得はモデル性能以前の前提条件です.
フレーム落ちや遅延が発生すると,推論時の観測と実際のロボット状態がずれ,タスク成功率に悪影響を与えます.
また,同じPC上でUSB-CANモジュールも使用していたため,カメラ由来のUSB負荷がシステム全体の遅延や不安定性につながることも懸念されました.制御信号の遅延はアクチュエータへの異常入力につながる可能性があるため,安全面でも無視できません.
この問題に対しては,USBカードの増設で対応しました.
展示環境での追加Fine-tuning
SusHi Tech Tokyo 2026の展示会場では,照明や背景の条件がデータ収集時の環境とは異なっていました.また,ロボットを取り付けるフレームを輸送のため組み直した関係上,カメラの取り付け角度にも微妙な差が生じていました.
| データ収集時 | 展示会場 |
|---|---|
 |
 |
データ収集時と比較して,展示会場は照明が強いため影がよりはっきりしており,また,背景の色も異なっていることが分かる.
これらの違いにより,事前に学習したモデルのロバスト性が低下し,タスク成功率の低下が確認されました.
そこで,会場で実際にロボットを自律的にrolloutしながら,追加で50エピソード分のタスク成功データを収集し,事前に収集されたデータセットA・Bと合わせた約300エピソード分のデータセットを用いてFine-tuningすることで,展示環境に対してPolicyを適応させました.
これは時間としては70分程度のデータセットであり,RTX 5090上で,バッチサイズ8,60000ステップのフルパラメータチューニングに約3時間半かかりました.
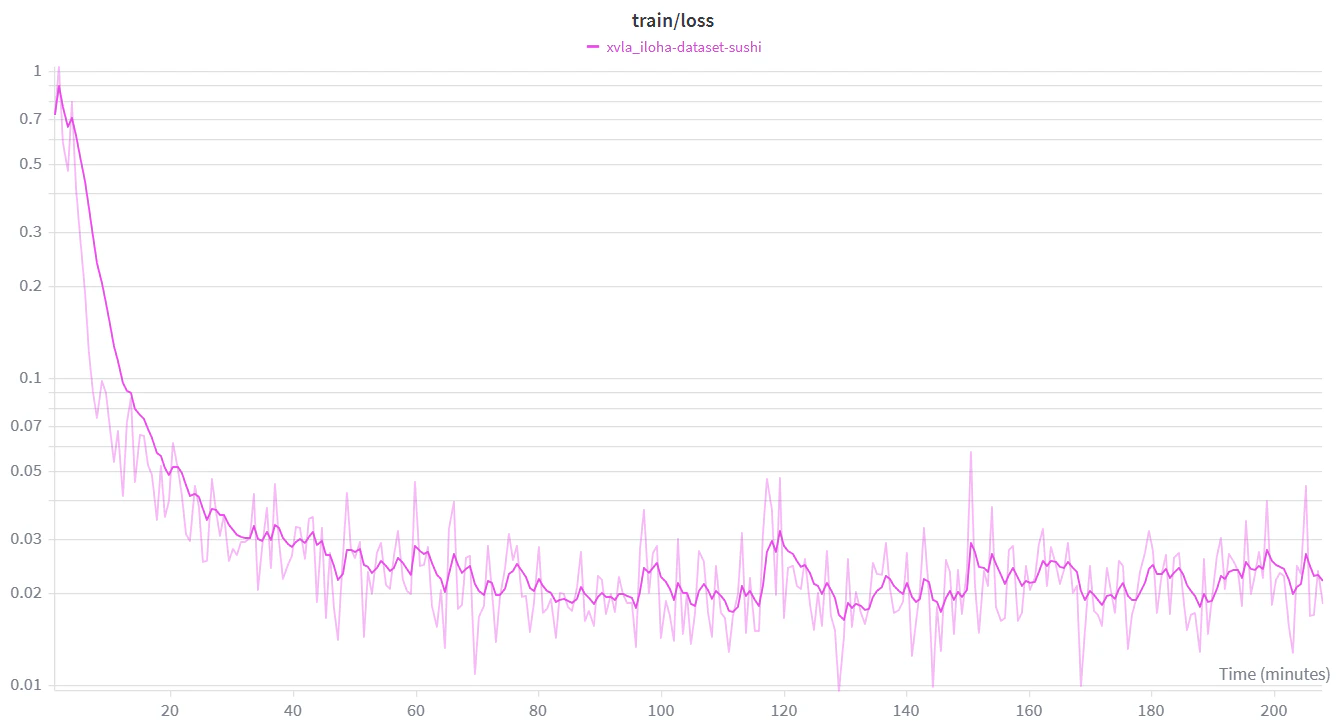
展示中に厳密な定量評価はできませんでしたが,追加Fine-tuning前後で同一条件に近い初期配置で複数回評価したところ,成功率はおおよそ6〜7割から9割以上に改善しました.
公開リソース
- ドライバ
github.com/KyotoVLATech/kvt_aloha_python_controller - PC側ソフトウェア
github.com/KyotoVLATech/lerobot-KVT - Unity側ソフトウェア
github.com/KyotoVLATech/AlohaController - ハードウェア
github.com/KyotoVLATech/Hardware_ILOHA - 電源・CAN分配基板
github.com/KyotoVLATech/Circuit_ILOHA
まとめ
本記事では,自作双腕ロボットILOHAを用いて,布を折り畳むVLAロボットを開発した話を紹介しました.
今回の開発から得られた主な知見は以下の通りです。
- 低品質データは品質ラベル付きで使う余地がある
- ロバスト性に注意してPolicyを学習しても,異なる環境では様々な要因(照明・背景・カメラ角度の差など)で性能が落ちる
- 実機VLAでは,配線やUSB帯域などの基礎的な安定性が前提になる
- 少量の現地データを用いた追加Fine-tuningは,環境適応に有効だった
VLAやPhysical AIの研究は急速に進んでいますが,実際にロボットを動かすと,論文やベンチマークだけでは見えない問題が多く出てきます.
特に,柔軟物操作のようなタスクでは,データ品質,環境差分,実機の安定性が非常に重要になることが分かりました.
今後は,より定量的な評価を行っていくと共に,単なるデモとしてではなく,実用的な家事支援や製造業向けタスクとして成立するレベルを目指して,モデルを改善していきたいと考えています.