
https://www.databricks.com/jp/glossary/medallion-architecture
はじめに
Databricks のメダリオンアーキテクチャ(Bronze / Silver / Gold)はよく知られていますが、
「なぜそこまで分ける必要があるのか」が腹落ちしていないケースも多いと思います。
本記事では、正解を説明するのではなく、アンチパターンを物語形式で描くことで、
設計を省略したときに現場で何が起きるのかを示します。
「動いているけど、どこかおかしい」
そんな状態が、なぜ危険なのかを感じ取ってもらえれば幸いです。
それでははじまり
部長「俺たちは最強のデータ分析組織になるんや!このベンダーから購入したデータでたくさんのAIやBIを作ってビジネスに生かすんや!」


データサイエンティストA「まずはこれを加工してBIにするためのデータを作りました。ついでに郵便番号にハイフンが入っているものといないものがあったので、統一しておきましたよ」

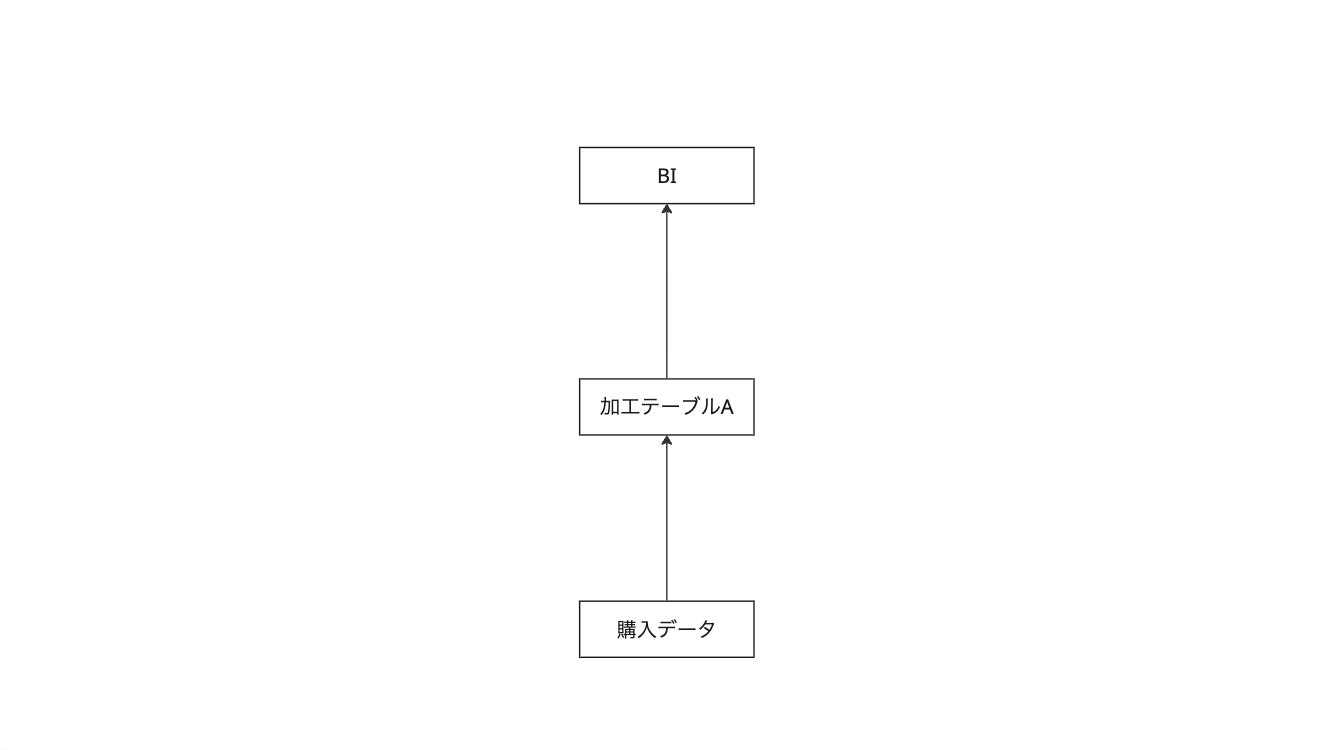
データサイエンティストB「ありがとうAさん、すばらしいわ!郵便番号の前処理もとっても便利だわ!これAIの学習データに使わせてもらうわね」

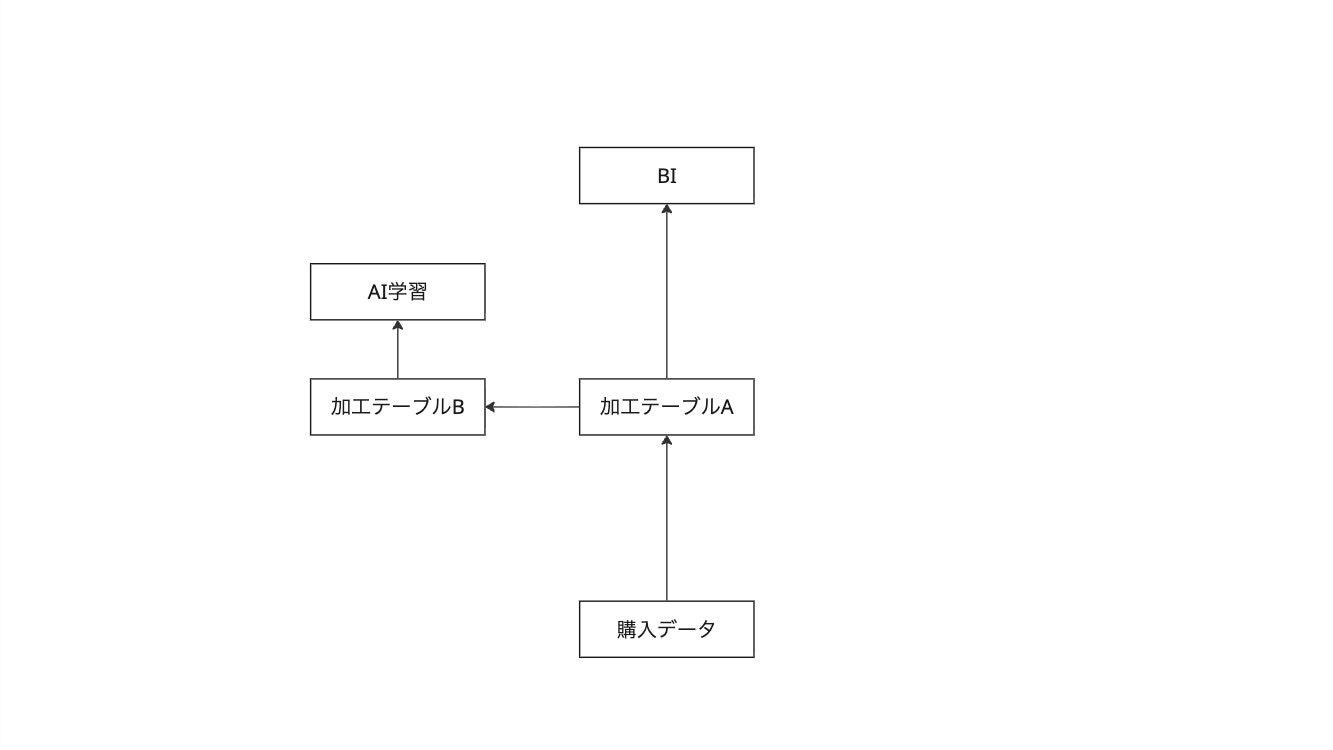
データアナリストA「お、なんだこのデータは俺が欲しいものが全て揃っているじゃないか。会社の基幹システムのデータに掛け合わせて新たな分析BIができるぞ!」

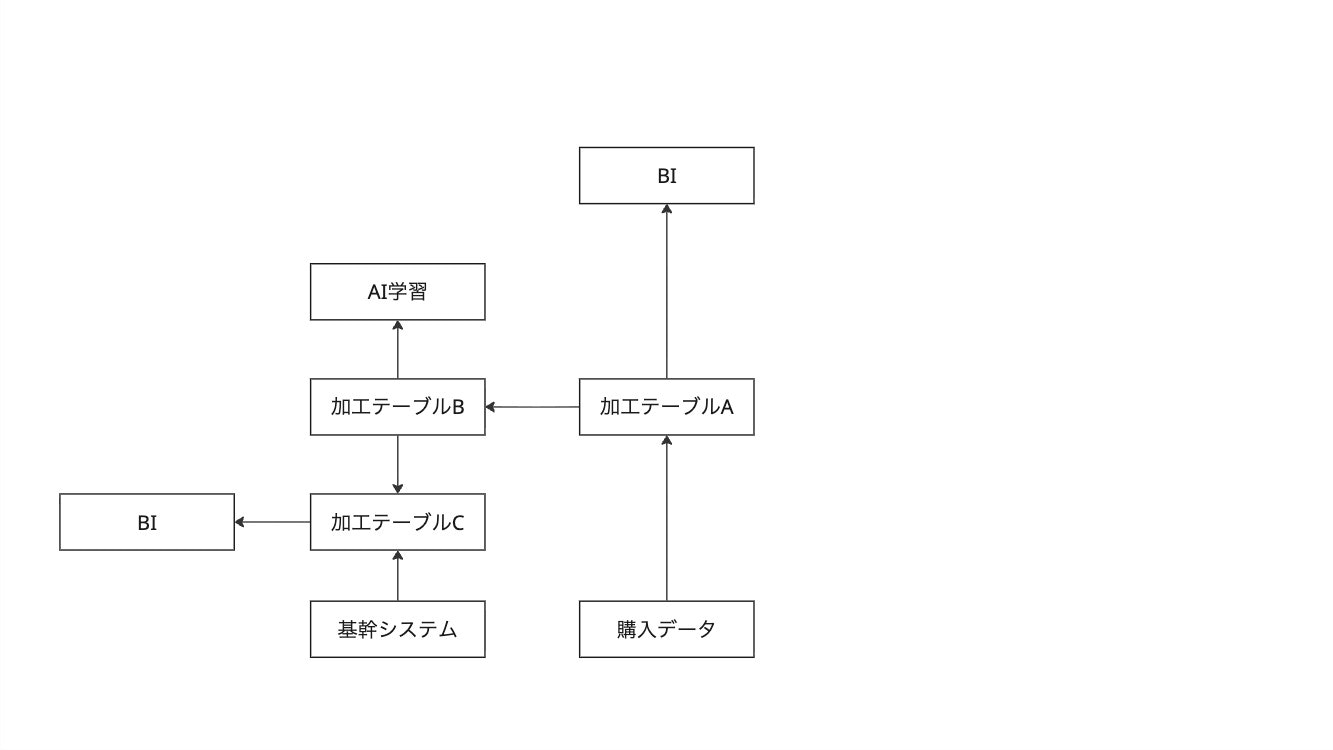
データサイエンティストA「事業部が基幹システムとのデータも掛け合わせて分析したいと要望があった。どうしようかな、、、お、こんなところに基幹システムのデータがいい感じに載っている。これを使おう!」

部長「データ分析は捗っとるかね。私も何か分析してみたいな。」
新卒「このSQLっていうのを使えば、部長でもどんな分析だってできますよ。僕が下地を作ったので、ぜひ使ってください!」
部長「ありがとう新卒君!」

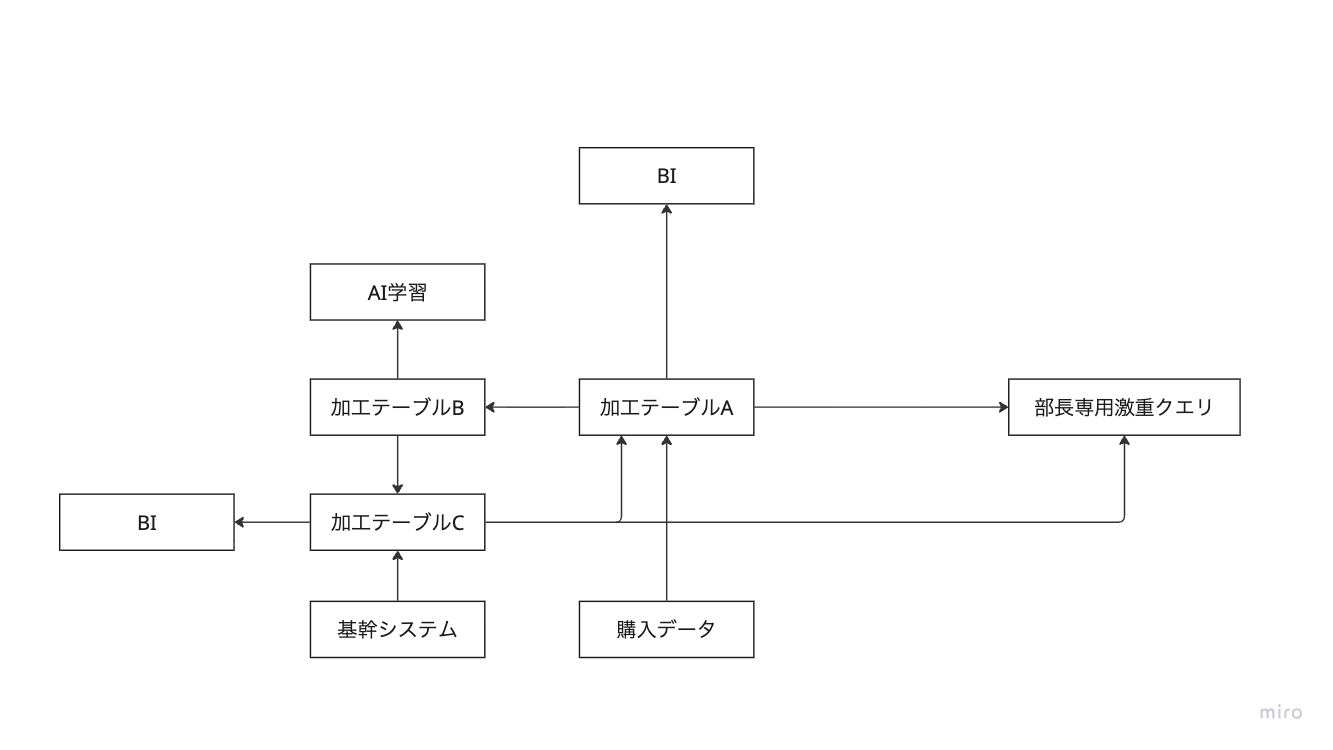
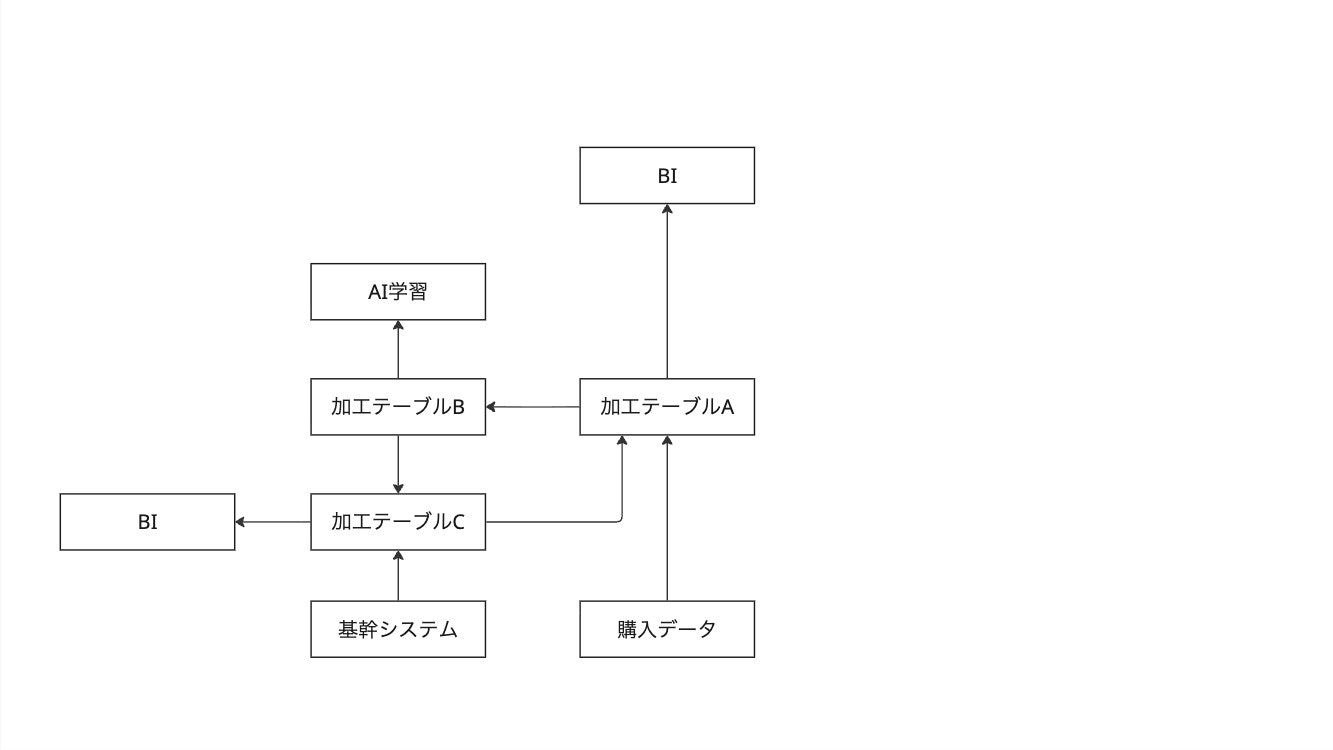
データサイエンティストA「今度事業部がこれを受発注システムに組み込みたいっていうんだ」
データサイエンティストB「そうなの?とっても嬉しいわね!ぜひデータを繋げましょう」
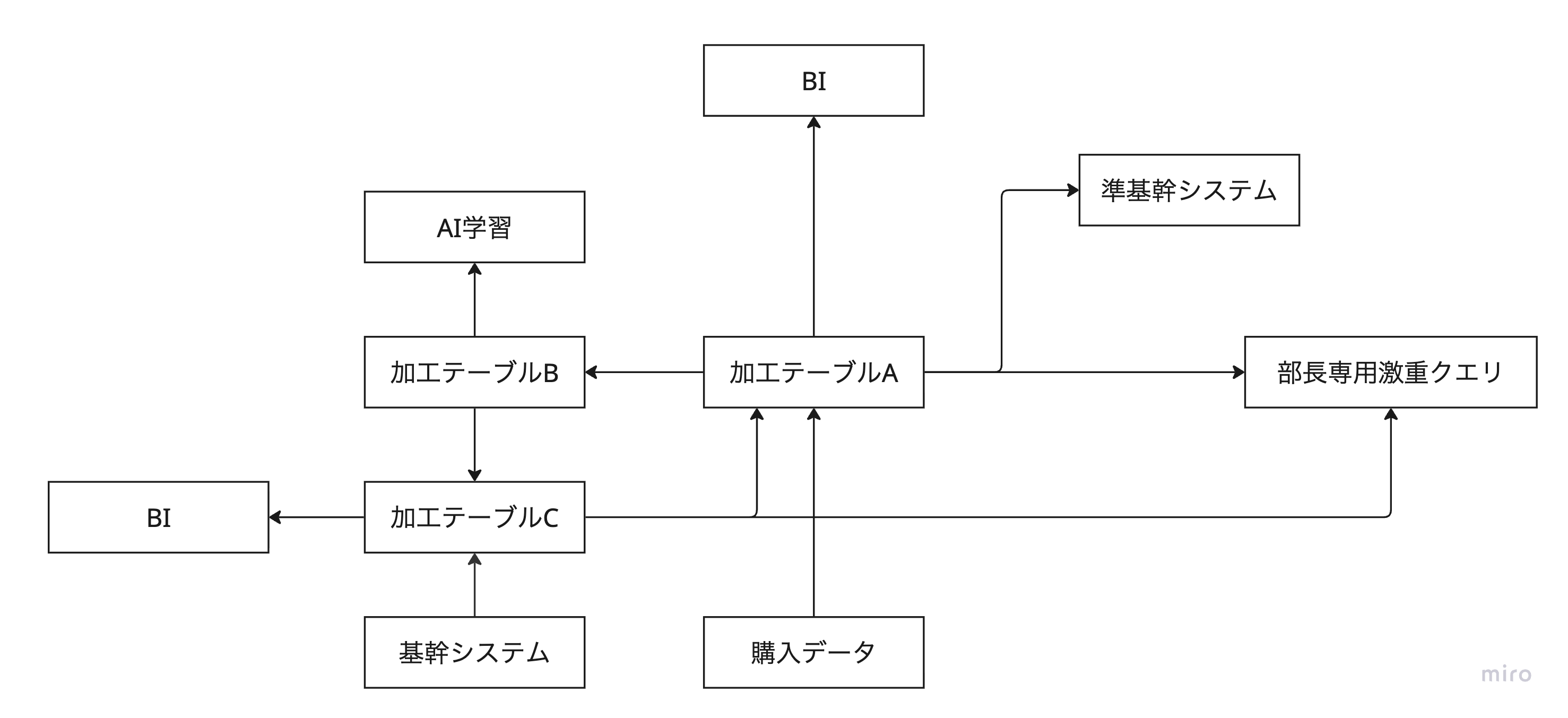
みんな「やった!ビジネスもBIとAIで喜んでくれるし!部長を含めたいろんな人が分析をすぐに始められるくらいいろんなデータが転がっているぞ!なんて最高の分析プラットフォームなんだ!!ばんざーい!!」

数日後
データサイエンティストA「なんか最近すごいコストがかかっているんだけどなんだろう?」
データサイエンティストB「実は、私も別の悩みがあって、データの処理速度がたまにすごく遅くなるの?なんなんでしょう?」

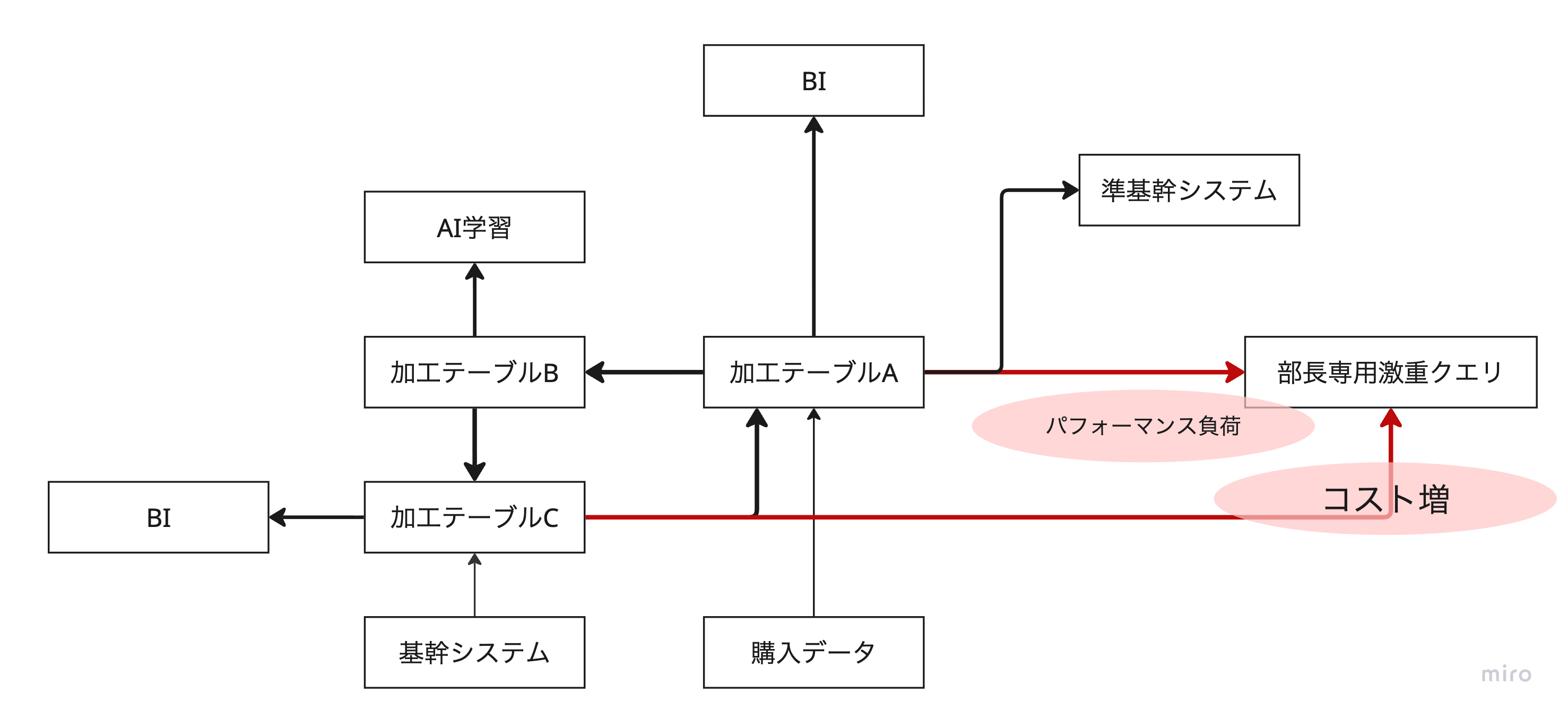
データサイエンティストA「そういえばごめん、BIに表示する郵便番号データの加工を一部変えなきゃいけないんだ。あとはBIに処理するデータを軽くするために一部の行はフィルターして落とすんだよ」
データサイエンティストB「ええっ!それAIの学習にかなり大事なデータなのよ!」

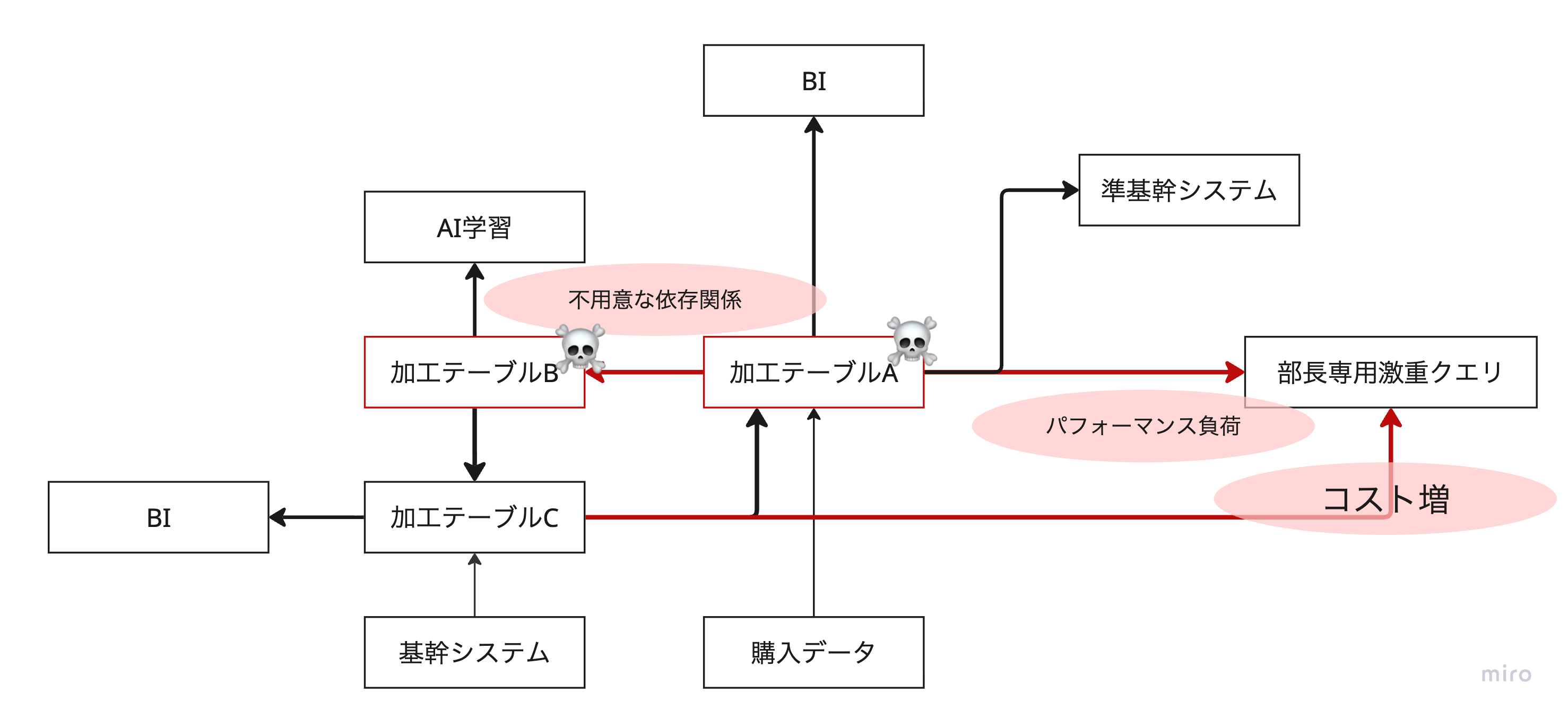
データサイエンティストA「あれ!?俺がテーブルAのデータのフォーマットを変えた瞬間にテーブルAの他の列が壊れた!なんでだよ!」
データアナリストA「む!?なんか入ってくるデータが変わったな?データが表示できなくなったぞ。。。」

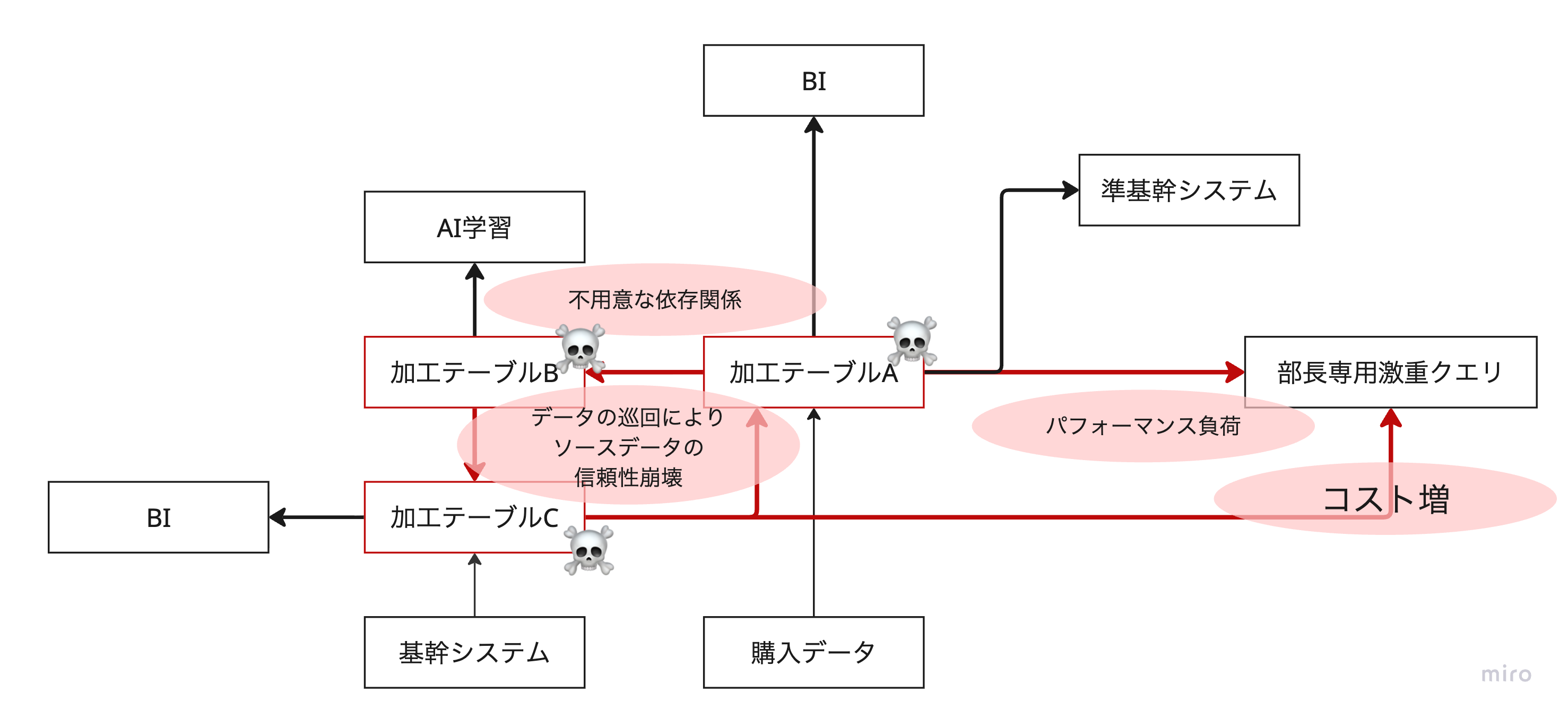
事業部「おい、予測系の基幹システムが壊れたぞ!一体どうなってるんだ!」
事業部「おい、BIが全然見えないぞ!」
事業部「おい、AIの精度が一気に悪くなったぞ!」

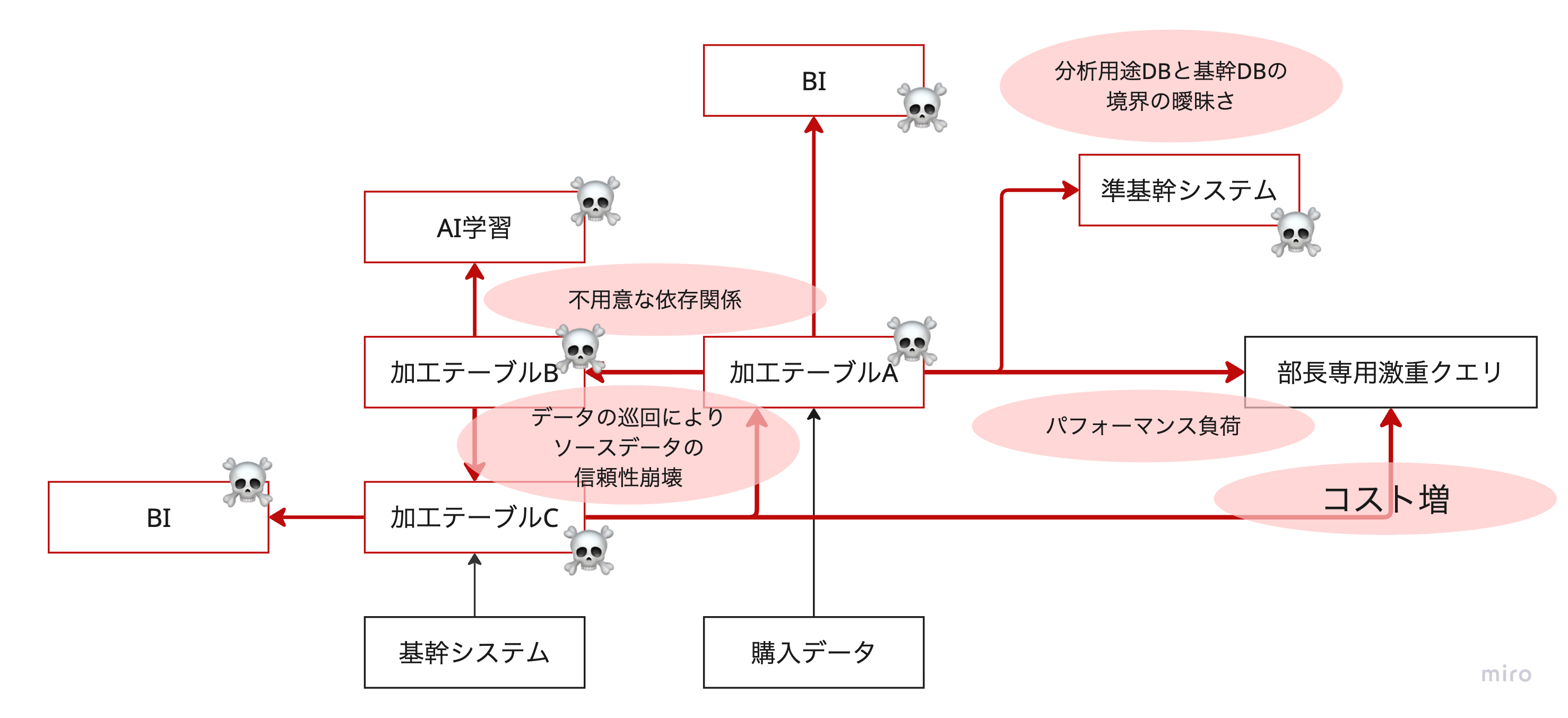
データサイエンティストA「そうだ!ソースデータが悪いんじゃないか?一度データ元を確認しよう。もしかしたら外部ベンダーさんが要件を満たしていない箇所があったのかもしれない。」

新卒「むむむ、みんななんでこのデータの前処理をいちいちいろんな場所で頑張っているんだ?」「まったく、、、みんなわかってないな、この一番大元のデータから変えちゃえばいいじゃないか。あ、この行はAIでも確かあのBIでも使ってないし消しちゃおう!これでみんな楽になるし幸せだぞ!」

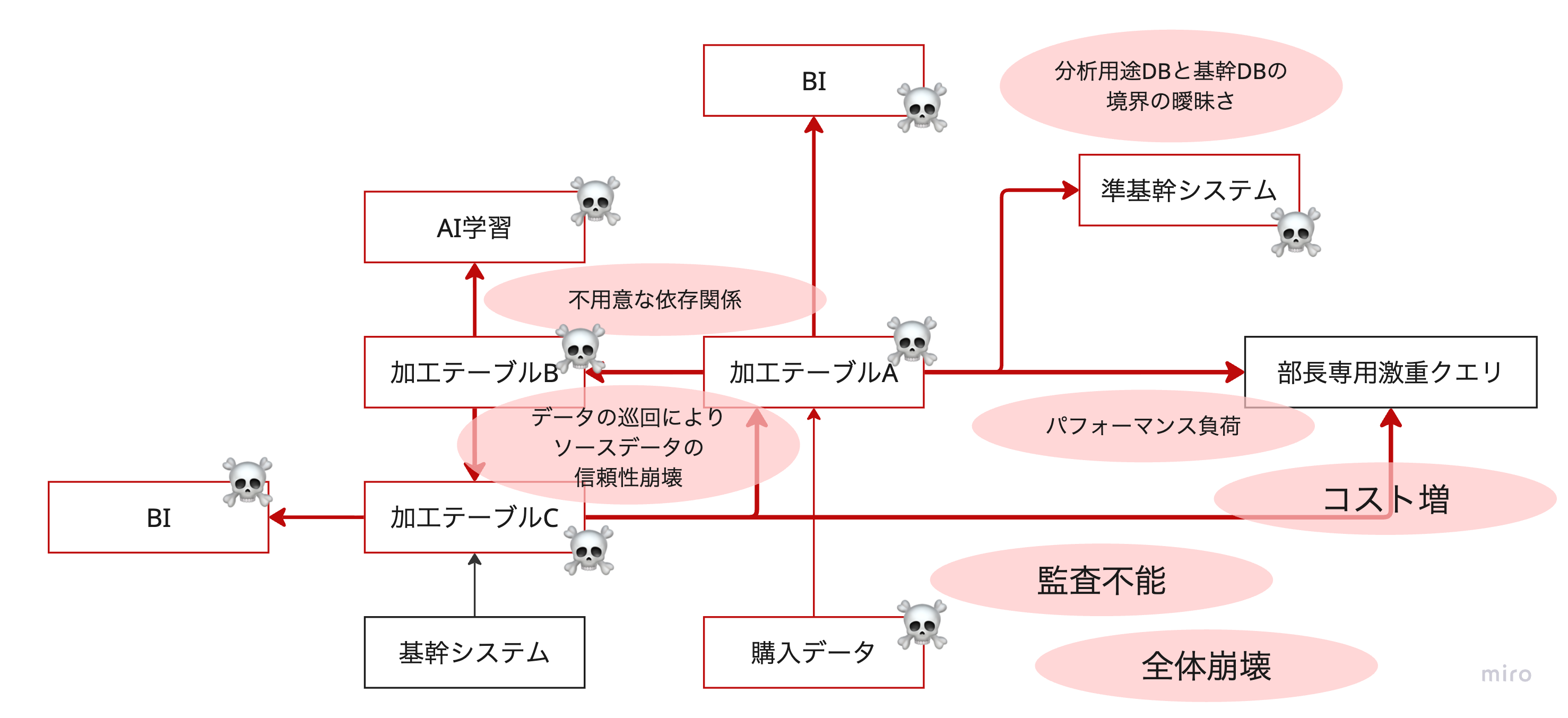
データサイエンティストA「え、社内に置かれているデータと御社からいただいたデータの内容が異なる!?そんなバカな。もうこれどっから直したらいいんだ・・・」

おしまい
まとめ
本ストーリーから学ぶべきポイントを整理します。
監査用データが存在しないことのリスク
基幹システムから連携したデータや外部から購入したデータは、変更不可の形で保持しておくことが重要です。
これにより、データ連携に問題がなかったかを後から調査・証明することが可能になります。
これらのデータを直接加工・更新してしまうと、元データそのものが「信頼すべき唯一のソース」になってしまいます。しかし実際には、元システムのデータは時間とともに変化する可能性があります。
そのため、連携時点の状態をスナップショットとして保存しておく必要があります。
(Streaimingは事情が変わりますが)
これが Bronze テーブル です。
Bronze テーブルへのアクセス権を厳格に制御し、意図しない変更から守ることで、今回のような問題は防ぐことができました。
共通の前処理・クレンジングが定義されていない問題
社内には「ほぼすべてのケースで共通して必要となる前処理」が存在するはずです。
例えば郵便番号ひとつ取っても、「〒000ー0000」「0000000」など表記がバラバラな状態のまま、後続処理で使いたいケースはほとんどありません。
また、操作ミスによって混入したログや、明らかな誤入力など、確実に不要で捨てるべきデータも存在します。
これらを一括して整理・クレンジングするのが Silver テーブル です。
Silver レイヤーを共通化することで、BI データを AI が不用意に利用してしまうリスクなども抑制できます。
このレイヤーは、社内の AI エンジニア、データサイエンティスト、アナリスト全体を横断して理解し、全体最適を考えて管理すべき領域です。
Bronze と同様に、誰もが自由に書き込める場所ではありません。
AI や BI が直接利用できるデータが存在しない問題
部長の「激重クエリ」を回避するためには、あらかじめ 小さく最適化されたテーブル を用意し、大規模な JOIN や時間のかかる処理を事前に済ませておくべきです。
BI や AI が最終的に利用する直前の粒度まで加工しておくことで、システム全体としても不要に重たいクエリを繰り返し実行せずに済みます。
これが Gold テーブル です。
ビジネスで直接利用されるレイヤーであるため、Validation(Constraint)によるデータチェックを挟むことも検討できます。
ここでは、求められるデータ品質の性質も一段階変わってきます。
データが巡回してしまうリスク
データ加工は、上位から下位へ一方向に流れるべきです。
この流れが巡回してしまうと、あるテーブルの変更が別のテーブルを破壊し、結果として自分自身のデータを壊してしまうリスクにつながります。
この状態になると、もはや「どこから直せばよいのか」が分からなくなります。
メダリオンアーキテクチャの本質のひとつは、有向非巡回グラフ(DAG) によってデータフローを定義する点にあります。
レイヤー構造を明確に分けることで、データの流れを固定し、データがぐるぐる巡回する事態を防止できます。
今までの話を踏まえると以下のような形が一例になると思います。
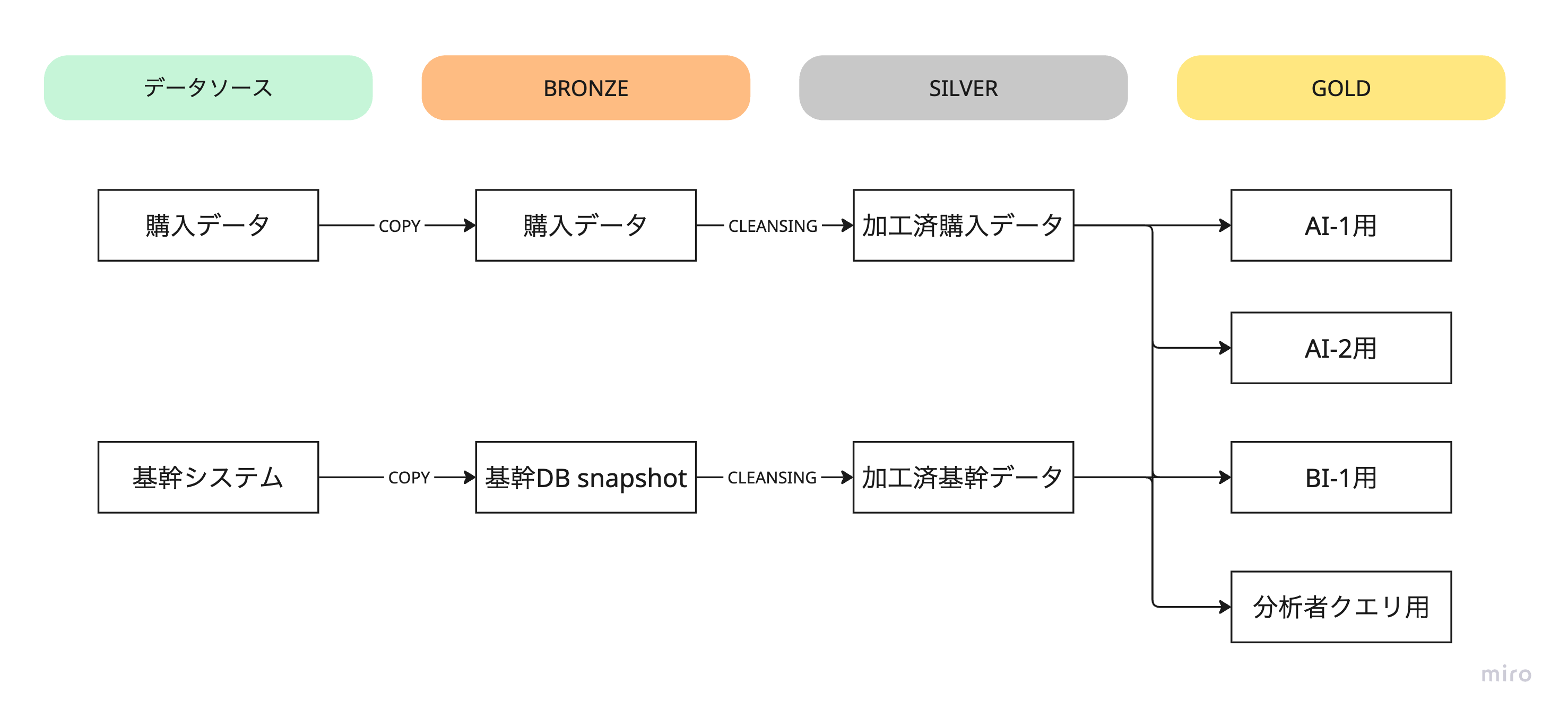
メダリオンアーキテクチャはあくまでも概念であり、詳細は組織やシステム依存します。
今回のストーリーの登場人物・組織であればBRONZEのアクセス制限は強めの方がいいでしょう。また分析者(部長)クエリ先は最初から小さなサイズのテーブルにしておいて、巨大なコストのSQLは未然に防ぎます。
しかしSQLに習熟した組織であればもう少し先のSILVERくらいまで権限を与えられる場合もあるかもしれません。SILVERとGOLDの間にも加工は一回でデータサイエンティストの人数や彼らの作るサービスの数次第ではもう少しその間に中間テーブルが増えるかもしれません。(しかし、その場合でも巡回を引き起こすことはアンチパターンです。)
おわりに
このストーリーは特別な失敗談ではなく、
データ基盤が成長する過程で誰にでも起こり得る話です。
メダリオンアーキテクチャは理想論ではなく、
トラブルを未然に防ぐための実践的な設計です。
もし思い当たる節があれば、
それはレイヤー設計を見直す良いタイミングかもしれません。
※本ストーリーはフィクションです
おまけ
メダリオンアーキテクチャはそれでも難しい概念なので、いくつかイメージを載せておきます。
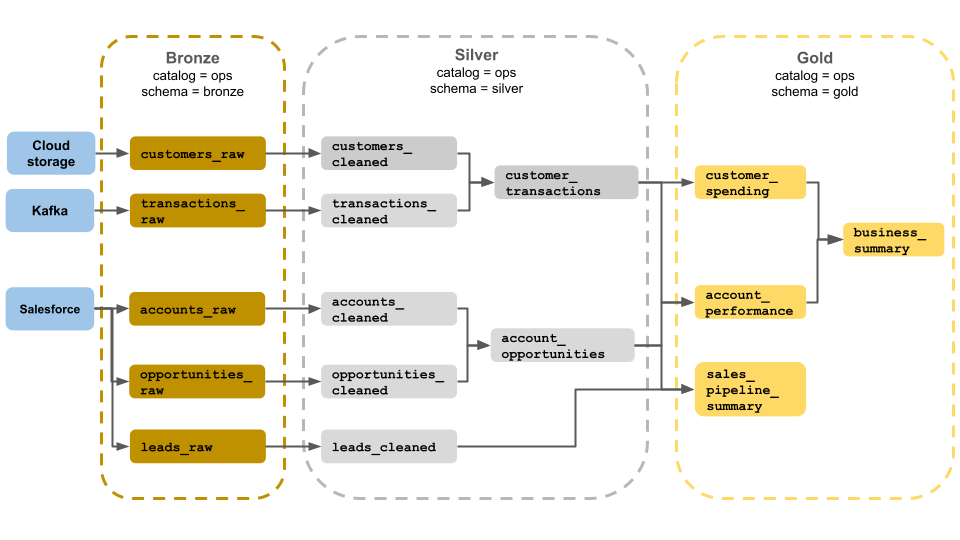
https://learn.microsoft.com/ja-jp/azure/databricks/lakehouse/medallion
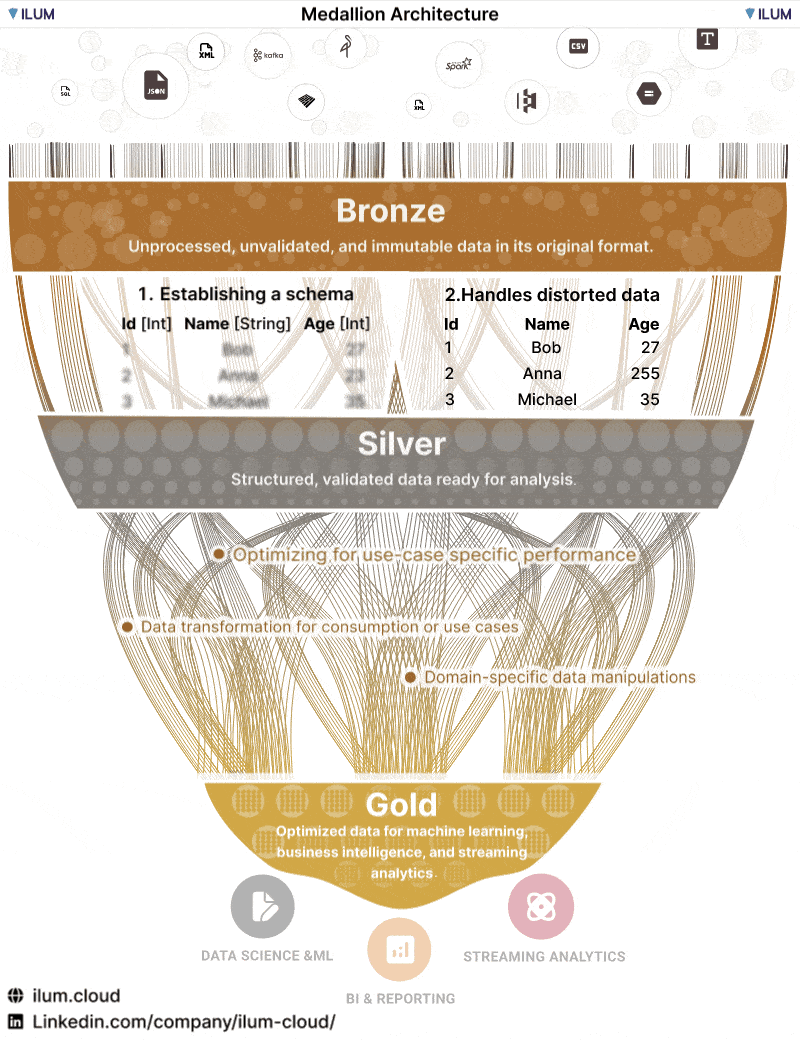
https://ilum.cloud/

https://learn.microsoft.com/ja-jp/fabric/onelake/onelake-medallion-lakehouse-architecture
あとはメダリオンに近い概念もありますので下記の記事もご紹介させてください。
https://qiita.com/mellowlaunch/items/c806980311058b82fb8b?utm_source=chatgpt.com