はじめに
この記事は以前公開した『生成AIの仕組みを「なんとなく」理解する』の続編、実装編です。
前回は、LLM(大規模言語モデル)とは何か、ローカルLLMとは何か、といった概念や仕組みをざっくり解説しました。
開発手法について
この取り組みでは、仕様駆動開発(SDD: Specification-Driven Development) を取り入れて実装を進め、この記事も with AI で作成しました。
開発を進める中での意思決定や、実際に実装して感じたことについては、
『仕様駆動開発で挑むローカルLLM実装:Androidアプリに生成AI機能を組み込む』【現在執筆中】
で詳しく紹介します。ぜひあわせてご覧ください。
というわけで今回は、前回の概念編に続く【実装編】として、
実際のAndroidアプリを題材に、ローカルLLMを使った文章生成機能を組み込みます。
なぜローカルLLMなのか?
このあたりの詳しい部分は、前回記事『生成AIの仕組みを「なんとなく」理解する』をご覧ください。
改めて、今回注目するポイントとしては、
- オフラインで動作: ネットなしで使える(初回モデルダウンロード時を除く)
- プライバシー保護: データが漏れない
- APIコストゼロ: クラウドAPIのような従量課金がかからない
- 任意のモデルを選択できる: 特定分野に特化したもの、デバイス性能に合わせたモデルサイズが小さいものなど
といった特徴を持つローカルLLMを、Android端末上で動かすことです。
ベースとなるアプリの概要
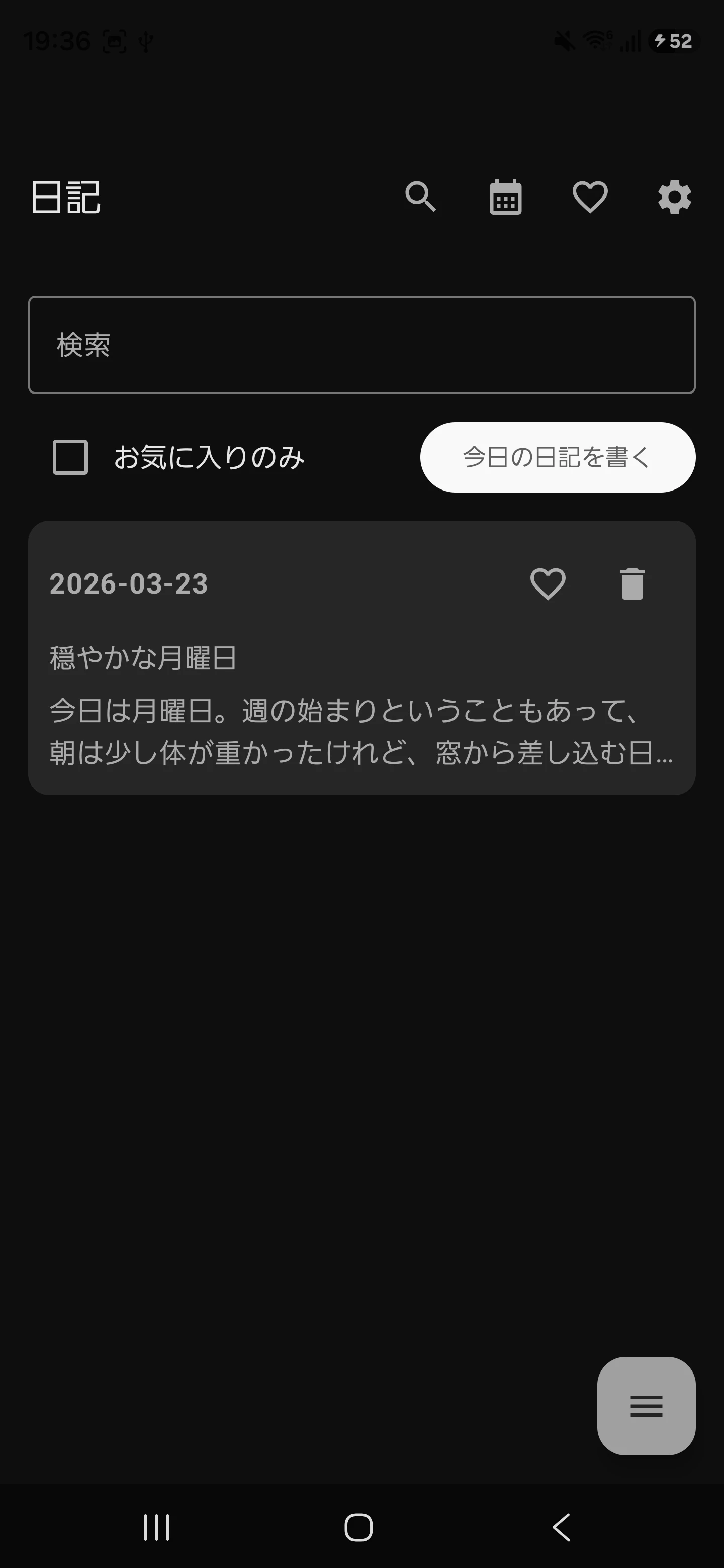
今回AI機能を組み込むのは、日記機能を持つAndroidアプリです。
毎日1件、ユーザーが日記を入力でき、編集画面でタイトル・本文・気分(5段階)・画像を入力できるシンプルな構成になっています。
 |
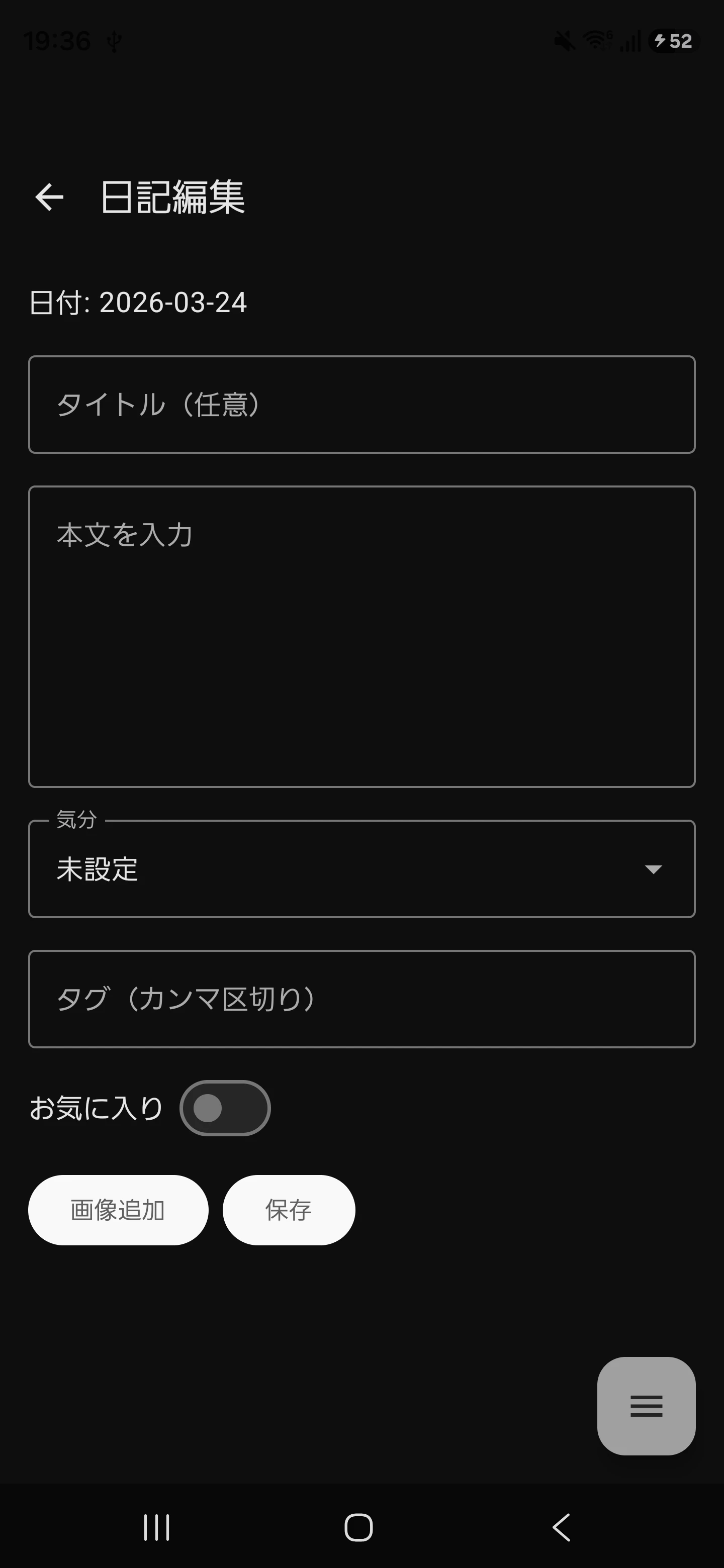 |
今回はこの日記編集画面に【タイトル自動生成】機能を追加します。
日記編集画面内に【タイトル自動生成】ボタンを設置し、本文と気分(5段階)を入力として、タイトルを自動生成させ、画面内に反映します。
こちらが完成後のタイトル自動生成の様子です。
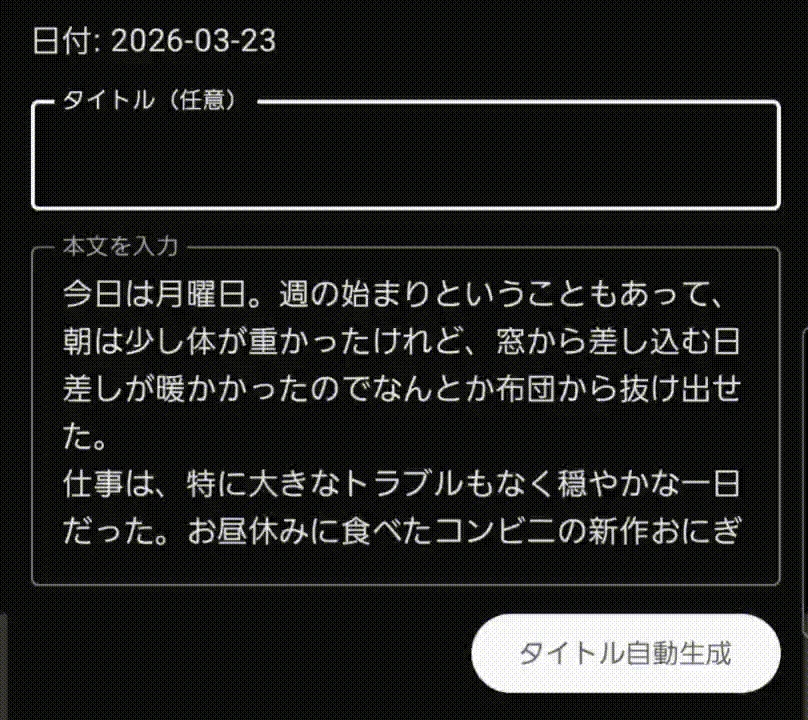
これを見て、「え、それだけ?」と思われた方もいるかもしれません。
ですが、ここで注目してほしいのは、この処理がすべてスマートフォンの中だけで完結しているということです。
少し前まで、LLMによるテキスト生成は個人では簡単にはできない処理でした。
数十億〜数兆のパラメータを持つモデルを動かすには、高価なGPUを搭載したサーバーが欠かせず、だからこそChatGPTのような「クラウドAPI型」のサービスが登場しました。
つまり、LLMをクラウドに頼らざるを得なかったのは、そもそもローカルで動かすのがリソース的に、技術的に困難だったからにほかなりません。
それが今、スマートフォン上で、通信なし・APIキーなし・課金なし・利用制限なしで文章生成ができています。
モデルの軽量化技術(量子化)やモバイル向け推論エンジンの進化によって、ポケットの中のデバイスで完結する時代になりました。
これは、ほんの数年前には想像しづらかった大きな進歩です。
そんな背景を踏まえて、
どこまでスマートフォン内でローカルLLMが実現できるか、下記のポイントで挑みます。
今回の注目ポイント
- そもそもローカルLLMを組み込めるか、どのように実現できるか
- オープンソースの汎用的な軽量モデルで、タスクを全うできるか
- 納得のできる品質のタイトルを、現実的な時間で生成できるか
- プロンプトで出力をコントロールできるか
全体アーキテクチャと実装の流れ
まず実装の全体像を把握しておきましょう。
やるべきことは大きく 3つのSTEP に分かれます。
STEP 1: モデルのダウンロード機構の実装
・Hugging Face OAuth認証 → アクセストークン取得
・リダイレクト制御付きダウンロード → モデルのローカル保存と管理
STEP 2: LLMエンジン(LiteRT-LM)の準備
・ディスク容量チェック → エンジン初期化 → ストリーミング推論
STEP 3: プロンプト調整とモデルの実行
・プロンプト構築 & 推論実行 → ストリーミング出力
・パラメータチューニング → 生成結果の整形(サニタイズ) → UI反映
各STEPの責務は、以下のクラスに分離されています。
| レイヤー | クラス | 責務 | STEP |
|---|---|---|---|
| data | HuggingFaceAuthManager |
OAuth 2.0 + PKCE 認証フロー | 1 |
| data | ModelDownloadManager |
モデルのダウンロード・リダイレクト制御 | 1 |
| data | LiteRtLmAiGeneratorClient |
LLMエンジン初期化・推論実行 | 2 |
| domain | GenerateTextUseCase |
プロンプト結合・ストリーム生成 | 3 |
| domain | TitleGenerationConfig |
サンプラーパラメータの定義 | 3 |
| ui | DiaryEditorViewModel |
UI状態管理・プロンプト構築・結果整形 | 3 |
それでは各STEPを順番に見ていきましょう!
STEP 1. モデルのダウンロード機構の実装 —— 最大の難所
今回は、GoogleがAndroid向けに提供するLLM実行SDK LiteRT-LM を使い、
Hugging Faceで公開されている軽量モデル(gemma-3n-E2B-it-int4.litertlm)を動かします。
実装にあたっては、Googleが公開するサンプルアプリ Google AI Edge Gallery のアーキテクチャを参考にしつつ、カスタマイズを加えました。
ローカルLLMを動かす上での一番の苦戦ポイント:
「モデルをデバイスの適切な場所にダウンロードして配置する」
※ Pythonでtransformersライブラリを使ってモデルをダウンロードする際は、
ダウンロード処理、ダウンロードしたモデルをローカルに配置・管理をよしなにやってくれますが、今回はこれらの部分を自分で実装する必要があります。
1-1. Google AI Edge Gallery の構成を理解する
まず、Googleが公開するサンプルアプリを確認し、どのようにHugging Faceからモデルをダウンロードしているか、全体像を整理します。
ダウンロード処理に関わる主なポイントは以下の通りです。
-
対象モデルの定義 (
model_allowlist.json):ダウンロード可能なモデルのIDやURL、必要なタスク形式などのメタデータがリスト化されています。アプリ起動時にこれを参照してUIを構築します。
このモデルリストは、Android上でのローカルLLM実行がある程度保証されているモデルなので、ここに載っているモデルを選ぶのがおすすめです。
-
ユーザー向け認証フロー (Wiki:
5. Model Management):Hugging FaceのGated modelsを取得するため、アプリ上でログイン(OAuth認証)し、ライセンスに同意した上でバックグラウンドでダウンロードする仕様が解説されています。
今回使用するHugging Faceのモデルはリンクを直接指定してダウンロードできるものではなく、Gated modelなので、ユーザーがHugging Faceにログインしていないとダウンロードできません。
そのため、OAuth認証を実装して、アプリ内でユーザーにログインしてもらう必要があります。Gated model は、利用前にライセンス同意やログインが必要な公開モデルです。
URLにアクセスするだけでは取得できないため、アプリ側で認証フローの実装が必要になります。
-
開発・ビルド時の設定 (
DEVELOPMENT.md):Hugging Face Developer Applicationの作成手順が記載されています。取得したClient IDは
ProjectConfig.ktに、リダイレクト用URLスキームはapp/build.gradle.ktsに設定してビルドする仕組みです。モデルをダウンロードするため、開発者は事前にHugging Faceで、Developer Applicationを登録し、Client IDを発行し、アプリ内に組み込む必要があります。
(次の章で解説します)
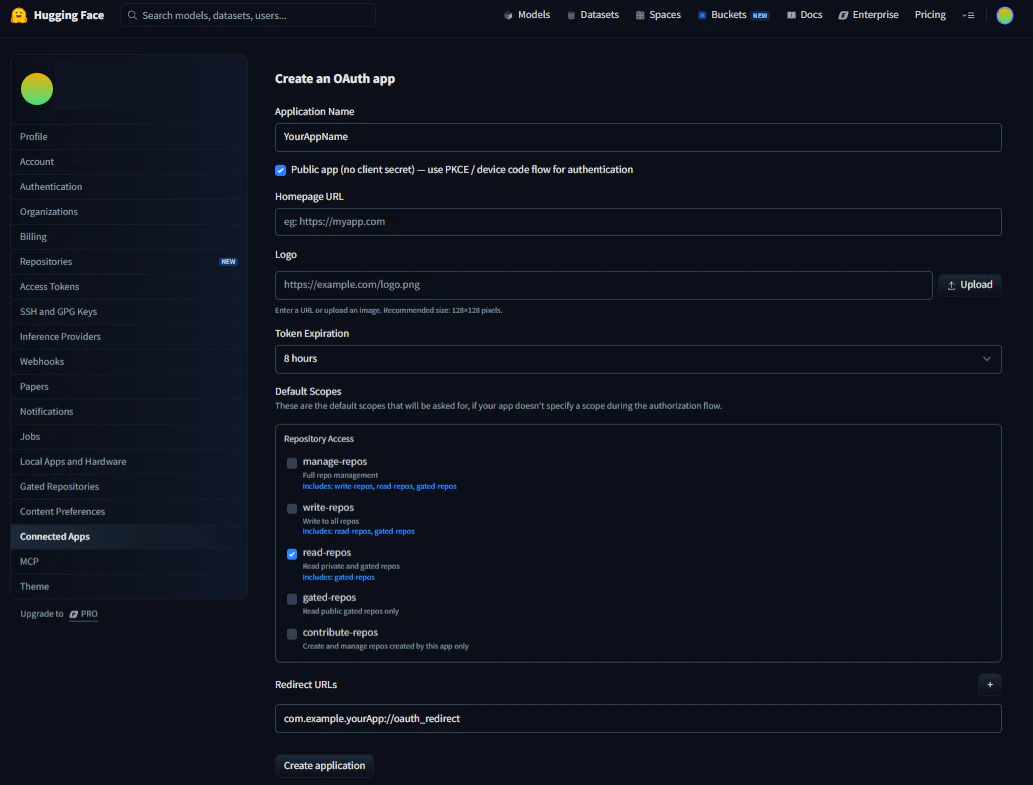
1-2. 事前準備: Hugging Face 側での Developer Application 登録
OAuth認証を使うには、まずHugging Faceにアカウント登録・ログインした上で、Developer Applicationを作成してClient IDを発行する必要があります。
- Developer Applications ページへ移動: ログイン後、 Settings → Connected Apps → Developer Applications の順にたどり、「Create App」ボタンを押下します
-
Create an OAuth app ページで情報を入力: 遷移先のページで、以下の項目を順に入力します
- Application Name: 任意のアプリ名を入力
-
Default Scopes の設定: モデルの読み出し権限をつけるため、
read-reposにチェック -
Redirect URLs の登録: アプリに戻るためのリダイレクトURL(
com.example.yourApp://oauth_redirect)を入力
- アプリの作成: 画面下部の「Create application」を押下すると、画面に Client ID が表示されます
-
Client ID の取得: 表示された Client ID を控え、
BuildConfig等でアプリ内に組み込みます
Client ID 自体は OAuth 公開クライアントの識別子なので秘匿情報ではありませんが、運用上は BuildConfig 経由等で注入し、ハードコードを避ける方が安全です。
1-3. OAuth認証
Hugging Faceのモデルをダウンロードするにはアクセストークンが必要です。
アプリがユーザーにパスワードを直接求めるのではなく、間接的に認証を行います。
そこでOAuthを利用します。Hugging Faceの認証画面でユーザーに許可をもらい、一時的なアクセストークンだけを発行してもらう仕組みです。
この一連の認証フローをまとめると、以下のようになります。
先程、Hugging FaceでDeveloper Applicationを登録した内容を、認証設定として記述します。
必要な認証設定 3つの要素を以下にまとめます。
| ポイント | 説明 |
|---|---|
| Client ID | Hugging Face Developer Applicationで発行された固有ID(秘密ではないが、コード直書きより注入管理が望ましい) |
| REDIRECT_URI | カスタムURLスキーム。認証後にアプリに戻るための仕組み |
| SCOPE |
read-repos のみ。モデルの読み取り権限だけを要求 |
以下が実際の認証マネージャの実装です。
📝 ソースコード: HuggingFaceAuthManager.kt(認証設定)
// ─── HFのアプリ登録に合わせて定数を定義 ───
object HuggingFaceAuthConfig {
// Client ID は秘匿情報ではないが、直書きは避けて BuildConfig などから注入する
const val CLIENT_ID = BuildConfig.HF_CLIENT_ID
const val AUTH_URL = "https://huggingface.co/oauth/authorize"
const val TOKEN_URL = "https://huggingface.co/oauth/token"
const val REDIRECT_URI = "com.example.yourApp://oauth_redirect"
const val SCOPE = "read-repos"
}
// ─── トークン取得結果の型 ───
data class HfTokenResult(
val accessToken: String,
val tokenType: String = "Bearer"
)
// ─── 認証エラーの型定義(sealed classで網羅的に管理) ───
sealed class HfAuthError : Exception() {
data class NetworkError(override val message: String, override val cause: Throwable? = null) : HfAuthError()
data class InvalidResponse(override val message: String) : HfAuthError()
data class Cancelled(override val message: String = "認証がキャンセルされました") : HfAuthError()
}
PKCE (Proof Key for Code Exchange) を使った認証開始
OAuth 2.0 の PKCE 拡張を使うことで、モバイルアプリでも安全に認証できます。
PKCE は、モバイルアプリのように client_secret を安全に保持しにくい環境で、認可コードのなりすましを防ぐための拡張仕様です。
📝 ソースコード: HuggingFaceAuthManager.kt(PKCE認証開始)
class HuggingFaceAuthManager {
// PKCE の状態を保持(1認証フロー中のみ有効)
private var currentCodeVerifier: String? = null
private var currentState: String? = null
/**
* PKCE の code_verifier を生成し、認証URLを構築して Custom Tabs で開く。
*/
fun startLogin(context: Context) {
val codeVerifier = generateCodeVerifier()
val codeChallenge = generateCodeChallenge(codeVerifier)
val state = generateState()
currentCodeVerifier = codeVerifier
currentState = state
val authUri = Uri.parse(HuggingFaceAuthConfig.AUTH_URL).buildUpon()
.appendQueryParameter("client_id", HuggingFaceAuthConfig.CLIENT_ID)
.appendQueryParameter("redirect_uri", HuggingFaceAuthConfig.REDIRECT_URI)
.appendQueryParameter("response_type", "code")
.appendQueryParameter("scope", HuggingFaceAuthConfig.SCOPE)
.appendQueryParameter("state", state)
.appendQueryParameter("code_challenge", codeChallenge)
.appendQueryParameter("code_challenge_method", "S256")
.build()
// Android の Custom Tabs で Hugging Face ログイン画面を表示
val customTabsIntent = CustomTabsIntent.Builder().build()
customTabsIntent.launchUrl(context, authUri)
}
// --- PKCE ヘルパー ---
private fun generateCodeVerifier(): String {
val bytes = ByteArray(32)
SecureRandom().nextBytes(bytes)
return Base64.getUrlEncoder().withoutPadding().encodeToString(bytes)
}
private fun generateCodeChallenge(verifier: String): String {
val digest = MessageDigest.getInstance("SHA-256").digest(verifier.toByteArray())
return Base64.getUrlEncoder().withoutPadding().encodeToString(digest)
}
}
startLogin() が呼ばれると、ブラウザ(Custom Tabs)で Hugging Face のログイン画面が開きます。ユーザーがログインし、アクセスを許可すると、その後のステップに進みます。
実際の画面フローを下記に示しています。
設定画面から「Hugging Faceでログイン」ボタンを押下すると、一連のOAuth認証フローが実行されます。
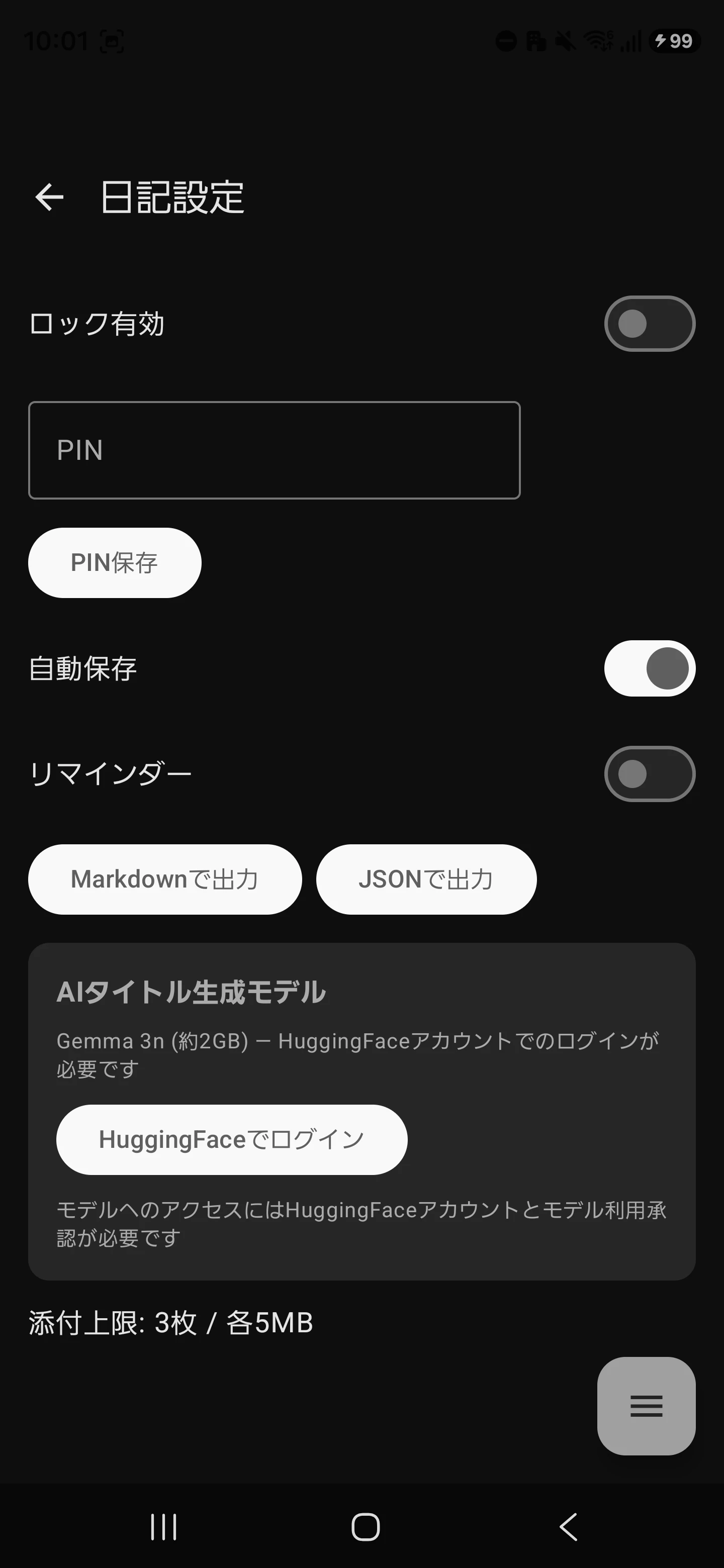 |
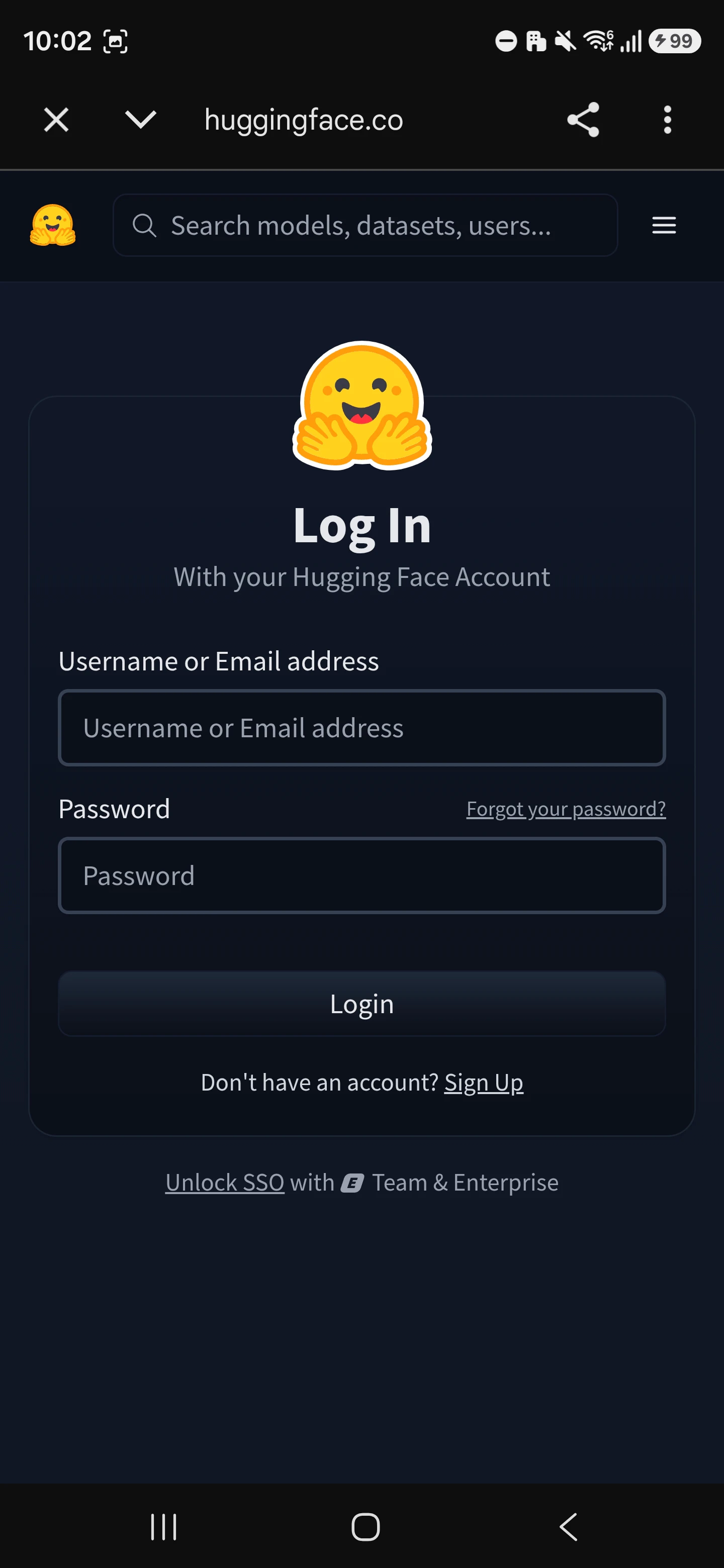 |
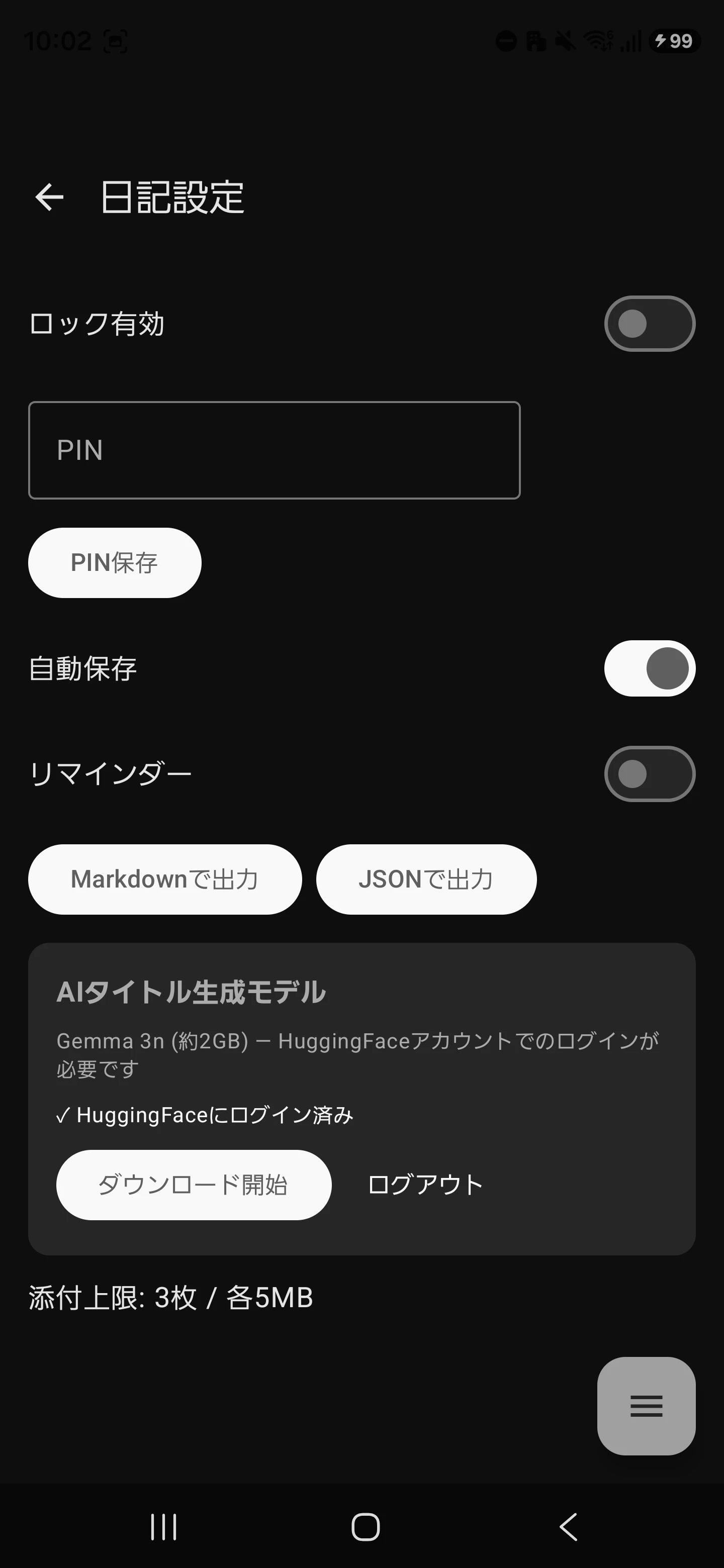 |
認可コード → アクセストークンの交換
ユーザーがログインを許可すると、Hugging Face からカスタムURLスキーム経由でアプリにリダイレクトされます。
handleRedirect() でそのリダイレクトを受け取り、認可コードをアクセストークンに交換します。
トークンは可能な限り短命・メモリ保持に留め、永続化が必要な場合は EncryptedSharedPreferences などOS標準の暗号化ストレージを使うことを推奨します。
📝 ソースコード: HuggingFaceAuthManager.kt(トークン交換)
/**
* OAuthリダイレクトURIからコードを取り出し、アクセストークンと交換する。
*/
suspend fun handleRedirect(redirectUri: Uri): HfTokenResult {
validateRedirectUri(redirectUri)
val code = redirectUri.getQueryParameter("code")
?: throw HfAuthError.InvalidResponse("認可コードが含まれていません")
// ★ CSRF対策:state パラメータの一致を検証
val returnedState = redirectUri.getQueryParameter("state")
val savedState = currentState
if (savedState == null || returnedState != savedState) {
throw HfAuthError.InvalidResponse("state が一致しません。CSRF攻撃の可能性があります")
}
val codeVerifier = currentCodeVerifier
?: throw HfAuthError.InvalidResponse("code_verifier が見つかりません")
val token = exchangeCodeForToken(code, codeVerifier)
// 使用済みの状態をクリア
currentCodeVerifier = null
currentState = null
return token
}
private fun validateRedirectUri(uri: Uri) {
val expected = Uri.parse(HuggingFaceAuthConfig.REDIRECT_URI)
if (uri.scheme != expected.scheme || uri.host != expected.host) {
throw HfAuthError.InvalidResponse("不正なリダイレクトURIです")
}
}
/**
* 認可コードをアクセストークンに交換する(HTTP POST)。
*/
private suspend fun exchangeCodeForToken(code: String, codeVerifier: String): HfTokenResult =
withContext(Dispatchers.IO) {
val postBody = buildString {
append("grant_type=authorization_code")
append("&code=").append(Uri.encode(code))
append("&redirect_uri=").append(Uri.encode(HuggingFaceAuthConfig.REDIRECT_URI))
append("&client_id=").append(Uri.encode(HuggingFaceAuthConfig.CLIENT_ID))
append("&code_verifier=").append(Uri.encode(codeVerifier))
}
val url = URL(HuggingFaceAuthConfig.TOKEN_URL)
val connection = url.openConnection() as HttpURLConnection
try {
connection.requestMethod = "POST"
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded")
connection.connectTimeout = 15_000
connection.readTimeout = 30_000
connection.doOutput = true
connection.outputStream.use { it.write(postBody.toByteArray()) }
val responseCode = connection.responseCode
if (responseCode != HttpURLConnection.HTTP_OK) {
val error = connection.errorStream?.bufferedReader()?.readText() ?: "不明なエラー"
throw HfAuthError.NetworkError("トークン交換に失敗しました(HTTP $responseCode): $error")
}
val response = connection.inputStream.bufferedReader().readText()
val json = JSONObject(response)
val accessToken = json.optString("access_token")
.takeIf { it.isNotEmpty() }
?: throw HfAuthError.InvalidResponse("レスポンスに access_token が含まれていません")
// トークン文字列はログ出力・クラッシュレポート送信対象にしない
HfTokenResult(accessToken = accessToken)
} finally {
connection.disconnect()
}
}
上記コードでは state 検証に加えて、redirectUri の scheme/host も照合しています。
このチェックがないと、悪意あるディープリンク経由で意図しない URI を受け付ける可能性があります。
1-4. リダイレクト制御付きモデルダウンロード —— 独自の工夫ポイント
トークンが取得できたらモデルをダウンロードするのですが、ここに大きな罠があります。
Hugging Faceはモデルの実体を自社サーバーではなく、AWSのS3などのCDNに置いており、リクエストが来るとリダイレクト(302/307)を返します。
CDN は、配信専用のサーバーネットワークです。
ここでは Hugging Face 本体ではなく、実体ファイル配信用エンドポイントとして登場します。
そのため、自動リダイレクトをあえてオフにし、手動でリダイレクトを追跡するロジックを組んでいます。
Android標準の「自動リダイレクト」をオンにしておくと、Hugging Face用のトークン(Authorizationヘッダー)を持ったまま外部のS3サーバーに行ってしまい、S3側で弾かれて400エラーになります。(セキュリティ的にもトークン漏洩になるので危険です)
ダウンロードの状態管理
ダウンロードの進捗をUIに伝えるための sealed class を定義しています。
📝 ソースコード: ModelDownloadManager.kt(状態定義)
sealed class DownloadState {
data class Downloading(val progressPercent: Int) : DownloadState()
data class Completed(val file: File) : DownloadState()
data class Error(val exception: Throwable) : DownloadState()
}
interface ModelDownloadManager {
fun isModelDownloaded(): Boolean
fun downloadModel(hfToken: String? = null): Flow<DownloadState>
val modelFile: File
}
sealed class を使うことで、UIが受け取る状態を「ダウンロード中 / 完了 / エラー」の3つに限定しています。
実際の画面フローを下記に示しています。
|
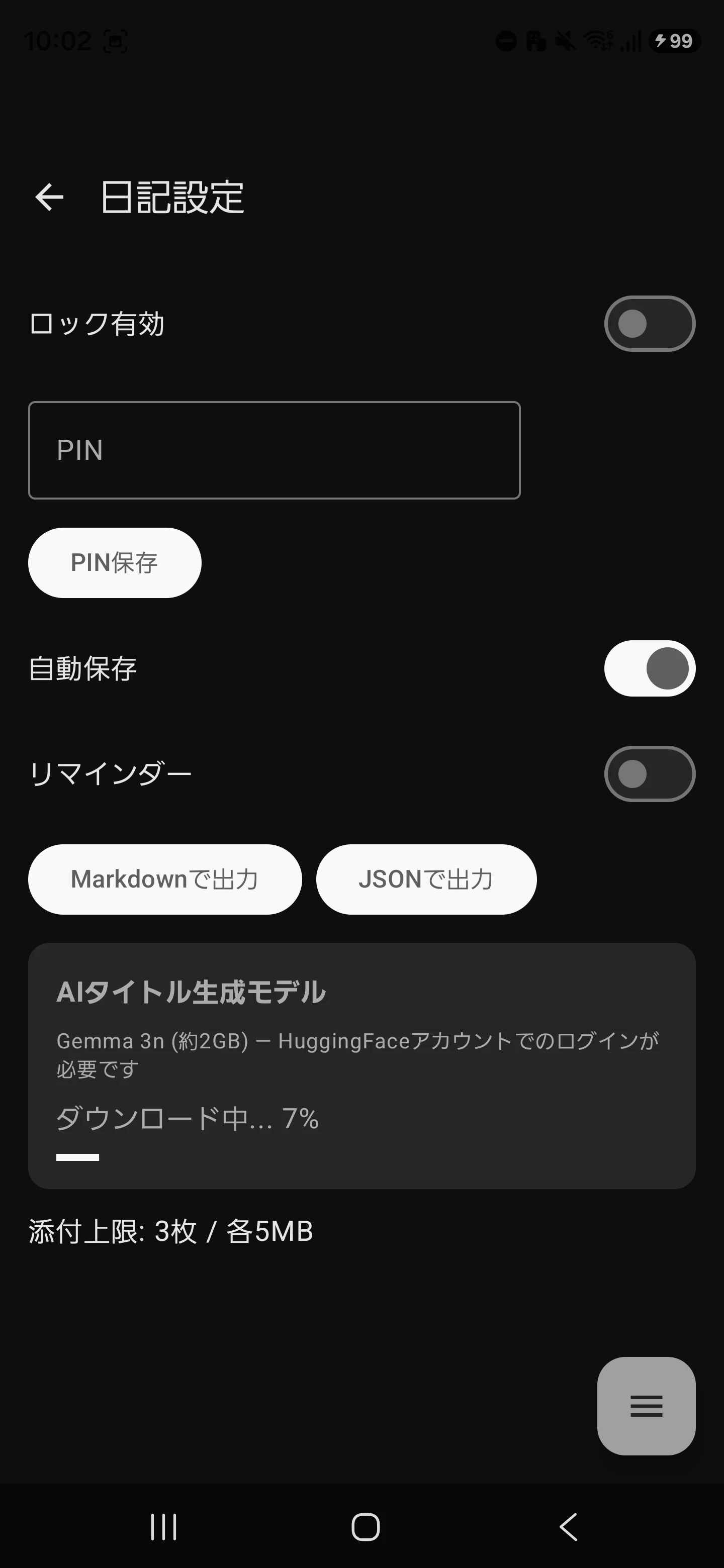 |
 |
リダイレクト手動追跡 —— 実装の核心部分
以下がリダイレクト制御の核心部分です。
📝 ソースコード: ModelDownloadManager.kt(リダイレクト手動追跡)
class ModelDownloadManagerImpl(private val context: Context) : ModelDownloadManager {
companion object {
const val MODEL_URL =
"https://huggingface.co/google/gemma-3n-E2B-it-litert-lm/resolve/main/gemma-3n-E2B-it-int4.litertlm"
const val MODEL_FILE_NAME = "gemma-3n-E2B-it-int4.litertlm"
const val MAX_REDIRECTS = 10
// 公開元が提供する SHA-256 を事前に控えておく
const val EXPECTED_SHA256 = "<公開元のSHA-256>"
}
override val modelFile: File
get() = File(context.filesDir, MODEL_FILE_NAME)
override fun downloadModel(hfToken: String?): Flow<DownloadState> = flow {
if (isModelDownloaded()) {
emit(DownloadState.Completed(modelFile))
return@flow
}
emit(DownloadState.Downloading(0))
// ★ Point 1: 一時ファイルに書き込み、完了後にリネーム(破損防止)
val tempFile = File(context.filesDir, "$MODEL_FILE_NAME.tmp")
var connection: HttpURLConnection? = null
try {
var currentUrl = URL(MODEL_URL)
var redirectCount = 0
while (true) {
ensureHttps(currentUrl)
connection = currentUrl.openConnection() as HttpURLConnection
// ★ Point 2: 自動リダイレクトをオフにする
connection.instanceFollowRedirects = false
connection.requestMethod = "GET"
connection.connectTimeout = 15_000
connection.readTimeout = 60_000
connection.setRequestProperty("Accept-Encoding", "identity")
// ★ Point 3: ホストが huggingface.co の場合のみトークンを付与
// CDN(S3等)へのトークン漏洩を防止
if (!hfToken.isNullOrBlank() && currentUrl.host == "huggingface.co") {
connection.setRequestProperty("Authorization", "Bearer $hfToken")
}
val responseCode = connection.responseCode
if (responseCode == HttpURLConnection.HTTP_MOVED_TEMP ||
responseCode == HttpURLConnection.HTTP_MOVED_PERM ||
responseCode == 307 || responseCode == 308
) {
// リダイレクト先URLを取得してループ継続
val location = connection.getHeaderField("Location")
?: throw Exception("リダイレクト先URLが見つかりません")
connection.disconnect()
currentUrl = URL(location)
redirectCount++
// ★ Point 4: 無限リダイレクト防止
if (redirectCount > MAX_REDIRECTS) throw Exception("リダイレクト上限($MAX_REDIRECTS回)に達しました")
continue
}
if (responseCode == HttpURLConnection.HTTP_UNAUTHORIZED) {
emit(DownloadState.Error(Exception("認証エラー(401): Hugging Faceへのログインが必要です")))
return@flow
}
if (responseCode != HttpURLConnection.HTTP_OK) {
emit(DownloadState.Error(Exception("HTTPエラー: $responseCode")))
return@flow
}
break // 200 OK に到達
}
// ─── ファイルへの書き込み(進捗通知付き) ───
val inputStream = connection?.inputStream
?: throw Exception("ダウンロード接続の初期化に失敗しました")
val fileLength = connection?.contentLengthLong ?: -1L
val data = ByteArray(1024 * 64) // 64KB バッファ
var total: Long = 0
var lastProgress = -1
inputStream.use { input ->
FileOutputStream(tempFile).use { output ->
var count: Int
while (input.read(data).also { count = it } != -1) {
total += count.toLong()
output.write(data, 0, count)
if (fileLength > 0) {
val progress = (total * 100 / fileLength).toInt()
if (progress >= lastProgress + 1) {
lastProgress = progress
emit(DownloadState.Downloading(progress))
}
}
}
}
}
// ★ Point 5: 完了後にリネーム → アトミック(原子的)な配置
val actualSha256 = sha256Of(tempFile)
if (!actualSha256.equals(EXPECTED_SHA256, ignoreCase = true)) {
throw Exception("ダウンロードしたモデルの整合性検証に失敗しました")
}
if (!tempFile.renameTo(modelFile)) {
throw Exception("モデルファイルの配置に失敗しました")
}
emit(DownloadState.Completed(modelFile))
} catch (e: Exception) {
tempFile.delete() // 失敗時は一時ファイルを必ず削除
emit(DownloadState.Error(e))
} finally {
connection?.disconnect()
}
}.flowOn(Dispatchers.IO)
private fun ensureHttps(url: URL) {
if (url.protocol.lowercase() != "https") {
throw Exception("HTTPS以外のURLは許可しません")
}
}
private fun sha256Of(file: File): String {
val digest = MessageDigest.getInstance("SHA-256")
file.inputStream().use { input ->
val buffer = ByteArray(1024 * 64)
while (true) {
val read = input.read(buffer)
if (read <= 0) break
digest.update(buffer, 0, read)
}
}
return digest.digest().joinToString("") { "%02x".format(it) }
}
}
この実装の5つのポイントを以下にまとめます。
| # | ポイント | なぜ必要か |
|---|---|---|
| 1 | 一時ファイル → リネーム | ダウンロード途中でアプリが終了しても、破損したファイルが残らない |
| 2 | instanceFollowRedirects = false |
自動リダイレクトをオフにして、各ホップを自分で制御する |
| 3 | ホスト判定でヘッダー付与 |
huggingface.co の場合のみ Authorization を付与。CDN へのトークン漏洩を防止 |
| 4 | リダイレクト回数制限 | 302/307 ループに陥った場合のセーフガード |
| 5 | renameTo でアトミック配置 |
ダウンロードが完全に完了し、ハッシュ検証に通った後で正式なファイル名に変更 |
実運用では、モデル配布元が公開しているハッシュ値(例: SHA-256)を検証してから採用するのが安全です。
「HTTP 200で落ちてきたからOK」だけでは、破損ファイルや改ざんを検知できません。
ここまでのダウンロードフローの全体像を図にすると、以下のようになります。
STEP 2. LLMエンジン(LiteRT-LM)の準備
モデルファイルをデバイスに保存できたら、いよいよ LiteRT-LM の Engine を初期化して推論を実行します。
2-1. 依存関係の追加
まず build.gradle.kts に LiteRT-LM と Custom Tabs の依存関係を追加します。
dependencies {
// AI & ML (LiteRT-LM for Gemma 3n)
implementation("com.google.ai.edge.litertlm:litertlm-android:0.9.0-alpha02")
// Hugging Face OAuth Custom Tabs
implementation("androidx.browser:browser:1.8.0")
}
2-2. LiteRT-LM クライアントの実装
次は実際のクライアント実装です。
注目してほしいのはディスク容量の事前チェックの部分です。
📝 ソースコード: LiteRtLmAiGeneratorClient.kt(エンジン初期化)
class LiteRtLmAiGeneratorClient(
private val context: Context,
private val modelDownloadManager: ModelDownloadManager,
private val config: TitleGenerationConfig = TitleGenerationConfig()
) : AiGeneratorClient {
private var engine: Engine? = null
companion object {
// XNNPack weight cache に最低限必要な空き容量(1.5GB)
internal const val MIN_CACHE_SPACE_BYTES = 1_500_000_000L
}
@Throws(Exception::class)
private fun getOrInitializeEngine(): Engine {
if (!modelDownloadManager.isModelDownloaded()) {
throw Exception("モデルのダウンロードが必要です")
}
if (engine == null) {
// ★ キャッシュディレクトリの空き容量を事前チェック(SIGABRT 防止)
ensureSufficientDiskSpace(context.cacheDir)
// 古い/破損した XNNPack キャッシュファイルをクリーンアップ
clearXnnpackCache(context.cacheDir)
val config = EngineConfig(
modelPath = modelDownloadManager.modelFile.absolutePath,
backend = Backend.CPU,
cacheDir = context.cacheDir.path,
)
engine = Engine(config).also { it.initialize() }
}
return engine!!
}
なぜディスク容量チェックが必須なのか?
ディスク容量チェックの重要性
ローカルLLMは初期化時にキャッシュ(XNNPack等)を作成します。
このとき空き容量が不足していると、JavaレベルのExceptionではなく、
C++のネイティブレベル(SIGABRT)でプロセスが強制終了(クラッシュ)します。通常の try-catch では捕捉できません。
そのため、エンジン初期化の前に StatFs で空き容量をチェックし、不足していれば Kotlin レベルで例外を投げるようにしています。
📝 ソースコード: LiteRtLmAiGeneratorClient.kt / InsufficientStorageException.kt(空き容量チェック)
/**
* キャッシュディレクトリの空き容量が十分かチェックする。
*/
internal fun ensureSufficientDiskSpace(cacheDir: java.io.File) {
val stat = StatFs(cacheDir.absolutePath)
val availableBytes = stat.availableBytes
if (availableBytes < MIN_CACHE_SPACE_BYTES) {
throw InsufficientStorageException(availableBytes, MIN_CACHE_SPACE_BYTES)
}
}
class InsufficientStorageException(
val availableBytes: Long,
val requiredBytes: Long
) : Exception(
"ストレージの空き容量が不足しています。" +
"AIモデルの動作には約${requiredBytes / 1_000_000_000}GBの空き容量が必要です。" +
"(現在の空き容量: ${availableBytes / 1_000_000_000}GB)"
)
2-3. 推論の実行(ストリーミング出力)
エンジンの初期化が完了したら、プロンプトを渡して推論を実行します。callbackFlow を使って、トークンが生成されるたびにストリーミングでUIに通知します。
処理の要点は「初期化失敗時の即時終了」「入力が長すぎる場合のエラーハンドリング」「トークンの逐次配信」の3つです。
📝 ソースコード: LiteRtLmAiGeneratorClient.kt(ストリーミング推論)
override fun generateStream(prompt: String): Flow<Result<String>> = callbackFlow {
val eng = try {
getOrInitializeEngine()
} catch (e: Exception) {
trySend(Result.failure(e))
close()
return@callbackFlow
}
try {
val convConfig = ConversationConfig(
samplerConfig = SamplerConfig(
topK = config.topK, // 上位K個の候補に絞り込み
topP = config.topP, // 累積確率Pまでの候補から選択
temperature = config.temperature // ランダム性の制御
),
)
eng.createConversation(convConfig).use { conversation ->
conversation.sendMessageAsync(prompt)
.catch { e ->
// 入力が長すぎる場合のエラーハンドリング
val userFriendlyError = if (
e.message?.contains("OUT_OF_RANGE") == true ||
e.message?.contains("Input is too long") == true
) {
Exception("入力テキストが長すぎます。本文を短くしてください。", e)
} else { e }
trySend(Result.failure(userFriendlyError))
close()
}
.collect { message ->
trySend(Result.success(message.toString()))
}
close()
}
} catch (e: Exception) {
trySend(Result.failure(e))
close()
}
awaitClose { /* Engine のライフサイクルは close() で管理 */ }
}.flowOn(Dispatchers.IO)
このように Flow<Result<String>> に統一しておくと、次の STEP 3 で ViewModel 側から「成功時はトークンを追記」「失敗時はメッセージ表示」という分岐をシンプルに実装できます。
STEP 3. プロンプト調整とモデルの実行
3-1. UseCase によるプロンプト結合
ViewModel と AIクライアントの間に GenerateTextUseCase を挟み、システム指示と入力データを結合しています。
📝 ソースコード: GenerateTextUseCase.kt(プロンプト結合)
class GenerateTextUseCase(
private val aiClient: AiGeneratorClient
) {
/**
* テキスト生成を実行します。
* @param systemInstruction 指示(タイトルを生成して等)
* @param inputData 生成元となるテキストデータ
*/
operator fun invoke(systemInstruction: String, inputData: String): Flow<Result<String>> {
val combinedPrompt = """
$systemInstruction
$inputData
""".trimIndent()
return aiClient.generateStream(combinedPrompt)
}
fun close() {
aiClient.close()
}
}
3-2. ViewModel でのタイトル自動生成
UIから実際に呼ばれる ViewModel の処理を見てみましょう。
ここがプロンプト構築とストリーミング表示の制御のメイン部分です。
📝 ソースコード: DiaryEditorViewModel.kt(タイトル自動生成)
fun generateTitleAutomatically() {
val currentState = _uiState.value
if (currentState.body.isBlank()) return
// モデルがダウンロードされていない場合はエラー表示
if (!modelDownloadManager.isModelDownloaded()) {
_uiState.update {
it.copy(errorMessage = "AIモデルのダウンロードが必要です。設定画面からダウンロードしてください。")
}
return
}
_uiState.update { it.copy(isGeneratingTitle = true, errorMessage = null) }
viewModelScope.launch {
// ① システムプロンプト(指示)の定義
val instruction = "次の日記を短くまとめたタイトルを日本語で1つだけ答えてください。" +
"記号や装飾は不要です。タイトルのみ出力してください。"
// ② トークン上限対策のため、本文は先頭1000文字を切り出す
val truncatedBody = currentState.body.take(1000)
// ③ 気分情報も入力に含める
val input = "内容: ${truncatedBody}\n気分: ${moodForPrompt(currentState.mood)}"
// ④ UseCaseを経由してストリーミングを受け取る
val resultFlow = generateTextUseCase(instruction, input)
var currentTitle = ""
resultFlow.collect { result ->
result.fold(
onSuccess = { partialToken ->
currentTitle += partialToken // トークンを徐々に追加
_uiState.update {
it.copy(title = currentTitle.trim(), isGeneratingTitle = true, dirty = true)
}
},
onFailure = { error ->
val userMessage = when {
error is InsufficientStorageException ->
"ストレージの空き容量が不足しています"
else -> "タイトルの生成に失敗しました: ${error.message}"
}
_uiState.update { it.copy(isGeneratingTitle = false, errorMessage = userMessage) }
}
)
}
// ⑤ 生成結果の整形(サニタイズ)
if (_uiState.value.errorMessage == null) {
val sanitizedTitle = sanitizeTitle(currentTitle)
_uiState.update { it.copy(title = sanitizedTitle, isGeneratingTitle = false) }
}
}
}
【タイトル自動生成】ボタンを押下すると、
本文をもとにタイトルがタイピングされるように少しずつ入力欄に表示されます。
気分情報のプロンプト変換
日記には1〜5段階の気分情報があります。これを moodForPrompt() で、モデルが理解しやすい日本語テキストに変換しています。
以下がそのロジックです。
📝 ソースコード: MoodLabels.kt(気分ラベル変換)
fun moodForPrompt(mood: Int?): String {
return when (mood) {
1 -> "5段階中1(とても悪い)"
2 -> "5段階中2(悪い)"
3 -> "5段階中3(ふつう)"
4 -> "5段階中4(良い)"
5 -> "5段階中5(とても良い)"
else -> "未設定"
}
}
これにより、AIモデルに渡されるプロンプトは最終的に以下のようになります。
次の日記を短くまとめたタイトルを日本語で1つだけ答えてください。記号や装飾は不要です。タイトルのみ出力してください。
内容: {今日は朝から天気がよくて、久しぶりに公園を散歩した。桜がちらほら咲き始めていて…}
気分: {5段階中4(良い)}
3-3. LLMのパラメータとプロンプトエンジニアリング
前回の概念編で「LLMは確率的に次の単語を選んでいる」とお話ししました。
この「確率的な選び方」をコントロールするのがパラメータ(サンプラー設定) です。
パラメータの定義
このアプリでは、以下のように設定クラスを1箇所にまとめて管理しています。
/**
* タイトル自動生成時に AI モデルへ渡すパラメータ。
* 「安定寄り」を想定しています。
*/
data class TitleGenerationConfig(
val temperature: Double = 0.3,
val topK: Int = 10,
val topP: Double = 0.95
)
各パラメータの解説と設定の意図
| パラメータ | 値 | 意味 | 今回の設定意図 |
|---|---|---|---|
| temperature | 0.3 |
単語を選ぶ際の「ランダム性(冒険度)」 | 日記の要約ベースなので事実から大きくずれてほしくない。でも何度か押すと少し違うニュアンスのタイトルが出てほしいので、低めだが0ではない値に |
| topK | 10 |
次の候補として上位K個だけを考慮 | 候補を絞り込み、文脈に合わない単語が混ざるのを防ぐ |
| topP | 0.95 |
確率の合計がP(95%)になるまでの候補集合から選択(Nucleusサンプリング) | 多様性を確保しつつ、極端に確率の低い(意味不明な)単語を排除する標準的な設定 |
temperatureの直感的なイメージ
-
0.0→ 常に最も確率の高い単語を選ぶ(固定的・堅い) -
0.3→ ほぼ安定だが、ときどき少し違う表現を選ぶ ← 今回の設定 -
1.0→ 確率分布そのままにランダムに選ぶ(自由・創造的) -
2.0→ かなりランダム(支離滅裂になりやすい)
3-4. プロンプトの工夫と「サニタイズ」の必要性
ここで大事な前提があります。ローカルの軽量モデルは、GPT-4のような巨大なAPIモデルほど賢くはありません。
「タイトルだけ出して」とお願いしても、余計な ```markdown といったコードブロック記号を付けてしまったり、「タイトルはこちらです:」みたいな前置きを入れてしまうことがよくあります。
対策として、以下の2段構えを取っています。
第1段:プロンプトでの強い制約
記号や装飾は不要です。タイトルのみ出力してください。
「不要です」「のみ」と繰り返し強調して、モデルに余計な出力を抑えさせます。
第2段:コード側での後処理(サニタイズ)
プロンプトの指示だけでモデルが完全には従わないケースも想定して、コード側でも防御的に記号を除去します。
サニタイズで対処しているパターンを以下の表にまとめます。
| 処理 | 対象パターン | 理由 |
|---|---|---|
| マークダウン除去 |
*, #, `, >, -
|
モデルが装飾を付けてしまうケース |
| 【】除去 |
【タイトル】 など |
モデルが「カテゴリ」を付けてしまうケース |
| 先頭のコロン除去 | :タイトル内容 |
「タイトル:〇〇」形式で出力されるケース |
| 最初の行のみ採用 | 複数行出力 | 説明文まで一緒に出てくるケース |
| 長さ上限 | 40文字超の出力 | UI崩れや不自然な長文タイトルを防ぐ |
📝 ソースコード: DiaryEditorViewModel.kt(sanitizeTitle)
internal fun sanitizeTitle(raw: String): String {
return raw
.replace(Regex("[\\p{Cntrl}&&[^\\n\\t]]"), "") // 制御文字除去
.replace(Regex("[*#`>\\-]"), "") // マークダウン記号除去
.replace(Regex("【.*?】"), "") // 【】で囲まれた部分を除去
.replace(Regex("^[\\s::]+"), "") // 先頭のコロン・空白除去
.trim()
.lines().firstOrNull()?.trim()?.take(40) ?: "" // 最初の行のみ + 長さ上限
}
この「プロンプト+コード」の2段構えは、ローカルLLMを実用的に使う上でかなり重要なテクニックです。
まとめと今後の展望
今回は「生成AIの仕組み」という座学から一歩踏み出し、実際のAndroid日記アプリにローカルLLM(LiteRT-LM)を組み込む実践的な手順と、パラメタ設定のポイントを解説しました。
今回の実装で得られた知見
-
ローカルLLMのメリットは想像以上:
コストを気にせずたくさん試せることに加え、API提供側の価格改定や仕様変更の影響を受けにくく、自分のものとして半永久的に同じ機能を使い続けられるのは、なかなかのメリット -
ダウンロード処理が最大の壁:
Hugging FaceのOAuth認証、CDNリダイレクトの手動追跡、一時ファイルによる破損防止など、表側以外のハードルが高く感じた -
小さなモデル特有の苦労:
クラウドの大規模モデルと比べると、指示に従ってくれない確率が高いため、プロンプトの工夫や生成結果の後処理(サニタイズ)が重要
(今回はあまり触れていませんが、モデル選びや内部処理に四苦八苦しました。)
技術的なポイントまとめ
| カテゴリ | ポイント |
|---|---|
| 認証 | OAuth 2.0 + PKCE で安全にトークン取得 |
| ダウンロード | 自動リダイレクトOFF + ヘッダー制御 + HTTPS/ハッシュ検証 |
| エンジン初期化 |
StatFs による空き容量チェックで SIGABRT を事前防止 |
| プロンプト | 強い制約文 + 本文切り詰め(1000文字)+ 気分メタデータ |
| 後処理 | 正規表現によるサニタイズで余計な記号を防御的に除去 |
今回の実装が拓く可能性
今回のデモは「日記のタイトル生成」というシンプルな機能でしたが、ここで構築した仕組みには、大きな汎用性と将来性があると考えています。
まず、プロンプトを変えるだけで、他の生成AI機能にも応用できます。
今回はタイトル生成でしたが、同じ基盤を使って「本文の要約」「文章のトーン変換」「タグの自動付与」など、プロンプトの差し替えだけで新しい機能を実現できます。
モデルのダウンロード・管理・推論実行という複雑な部分はすでに動いているため、機能追加のハードルは大幅に下がりました。
次に、モデルの選択が疎結合であることも大きなポイントです。
今回はHugging Faceで公開されているオープンなモデル(Gemma 3n)をダウンロードして使いましたが、この設計はモデル自体と切り離されています。
つまり、別の軽量モデルに差し替えることも、自分で専用モデルをファインチューニングしてHugging Faceに公開し、それをアプリからダウンロードして活用することも可能です。
🟨 : 今回実装済み / ⬜ : 今後の拡張例
これは、モデルのダウンロードから実行までの一連のパイプラインが検証済みだからこそ見える展望です。
OllamaやLM Studioなど、PC上で動かすローカルAI管理ツールの普及によって、ローカルLLM運用は確実に加速しています。この流れはモバイルにも広がっており、スマートフォンでローカル運用する時代はすでに現実のものになりつつあります。
少し前まで、「スマートフォン上のローカルAI」は実験的で性能も限定的という印象が強かったかもしれません。
しかし今回の実装を通じて、実用レベルの機能をスマートフォン単体で実現できることを実証できました。通信なし・APIキーなし・課金なしという条件でです。
この記事が、ローカルLLMの可能性に触れるきっかけとなれば幸いです。
最後まで読んでいただき、ありがとうございました!