はじめに
AWS Elemental MediaConvertを利用して、様々な拡張子の動画をmp4に変換する構築についてまとめます。
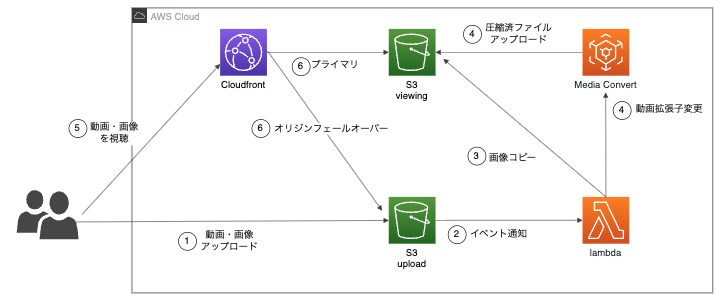
下記が変換フローになります。
- アップロード用S3に動画・画像をアップロードする
- Lambdaにイベント通知する
- 画像の場合、視聴用S3にコピーする
- 動画の場合、MediaConvertを使い、拡張子をmp4に変換
- ユーザーが動画・画像にアクセスし視聴する
- Media Convert で動画をS3にアップロードする前に、アクセスされた場合、オリジンフェールオーバーし、オリジン先がアップロード用S3に変更
6.に関して、Media Convertが実行完了する時間が長い場合、S3にアップロードされる前にリクエストされる可能性があります。
その際に、表示されるよう、オリジンフェールオーバーを利用しています。
S3を作成
S3をアップロード用と動画の拡張子変換後の用のバケット2つ作成します。
S3をアップロード用は、upload-movie-and-image、視聴用(動画の拡張子変換後)viewing-movie-and-imageという名前にしました。
設定は以下の通りです。

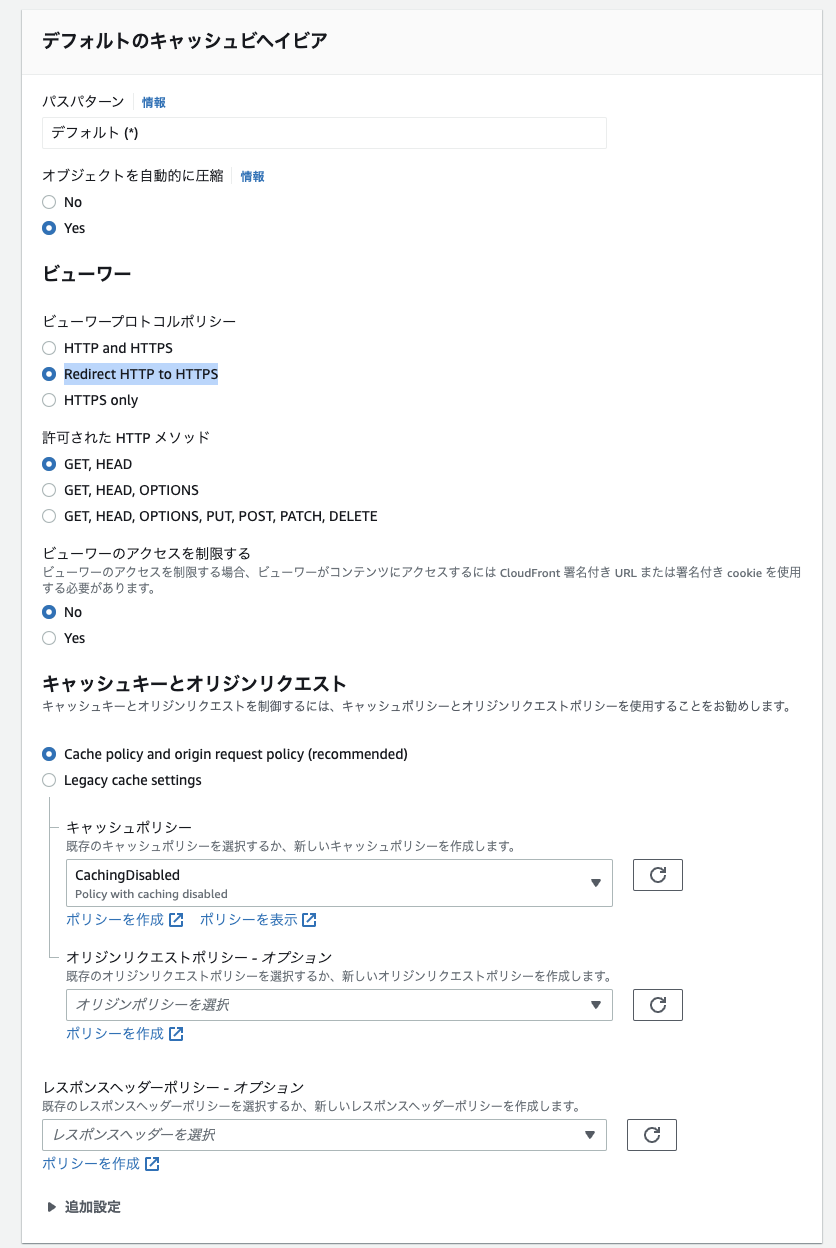
Cloudfront作成
設定は、以下以外は全てデフォルトです。
- オリジンドメインは、s3の
viewing-movie-and-imageを選択 - S3 バケットアクセスは、
Origin access control settings (recommended)を選択- コントロール設定を作成する(設定はデフォルト)
- キャッシュポリシーは、開発中は、
CachingDisabledにしておく - ビューワープロトコルポリシーは、
Redirect HTTP to HTTPS

ディストリビューション作成が成功すると、ポリシーをコピーし、S3のバケット権限に反映させましょう。

そして、s3に適当な画像aws-icon.pngをアップロードし、表示されるか確認しましょう。
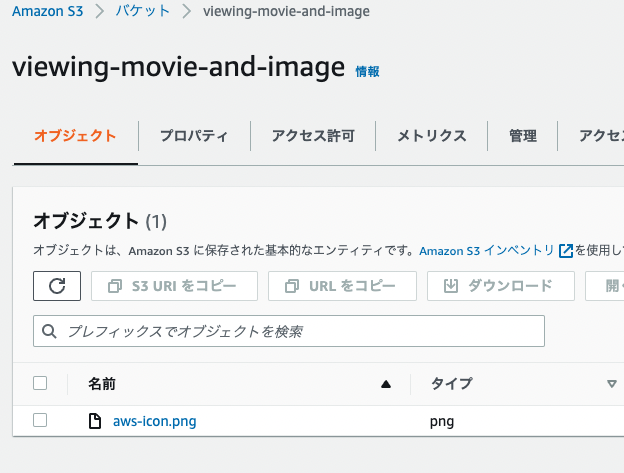
表示されることを確認しました。

オリジンフェイルオーバーを設定
動画変換完了前に、アクセスが来た場合、動画変換前のS3オリジンに向き先を変えるオリジンフェイルオーバーを利用します。
これは、複数のオリジンをグループ化し、オリジンの優先順位を付けることで、優先順位の高いものからオリジンリクエストし、特定のステータスコードが返ってきた場合は優先順位の低いものにフェイルオーバー出来る機能になります。
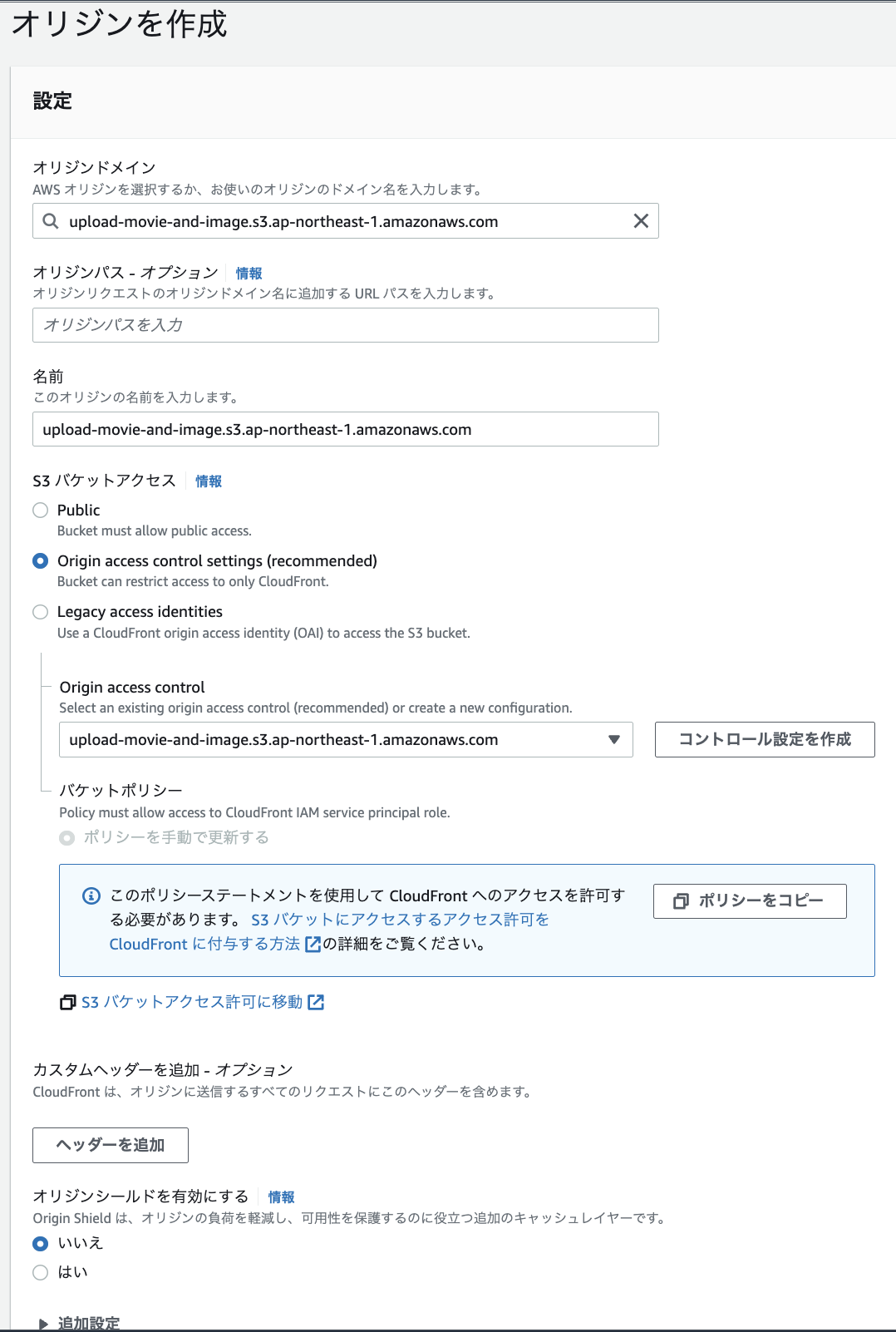
まず、CloudFrontにS3のupload-movie-and-imageをオリジンとして追加しましょう。
先程と同様の設定でよいです。S3のバケットポリシーの変更も行いましょう。
オリジングループ作成
それではオリジングループを作成します。

グループ名は、適当にmovie-and-image-groupとします。
プライマリが一番優先順位が高いため、動画変換後のオリジンであるviewing-movie-and-imageをプライマリにします。
フェールオーバー基準は、全て選択します。

ビヘイビア修正
オリジンとオリジングループをオリジングループであるmovie-and-image-groupに変更します。

これで、動画変換完了前に、リクエストが来た場合、リクエスト先を動画変換前のupload-movie-and-imageバケットにオリジンリクエストされます。
Media Convertのテンプレート作成
動画に関しては、以下の設定にします。
- 解像度は、
1920×1080 - 拡張子は、
.mp4
ジョブテンプレート作成
ジョブテンプレートを作成します。
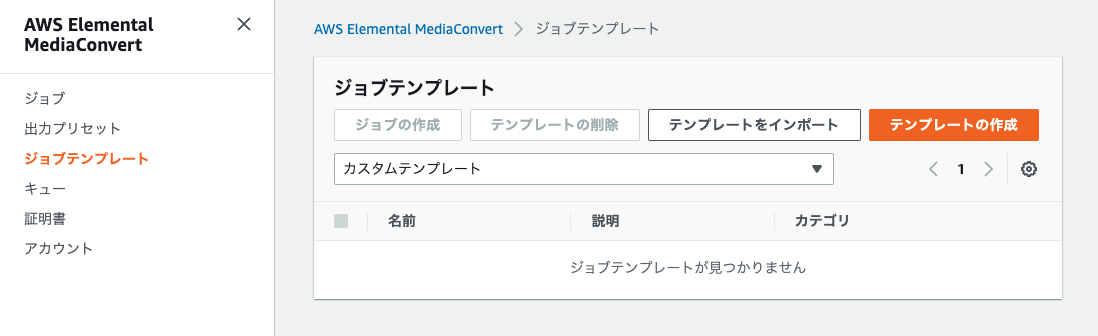
一般設定は、以下のようにしました。

入力を追加し、デフォルトままにします。
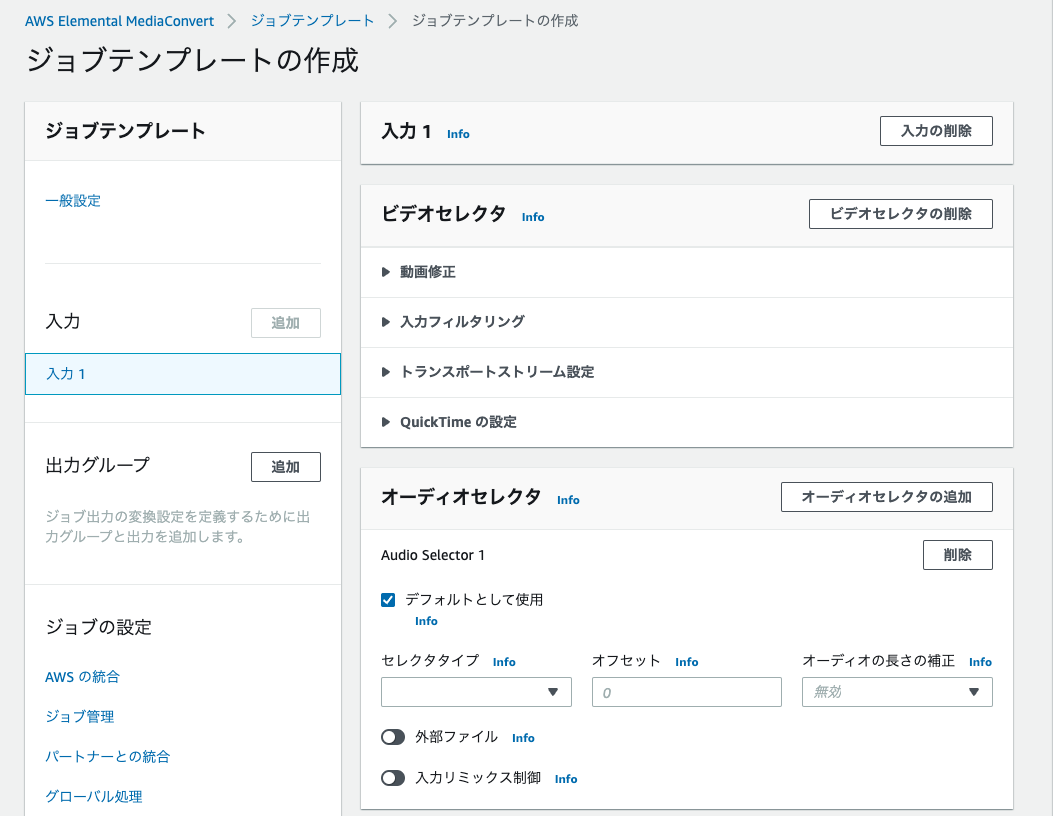
出力グループを追加をクリックし、ファイルグループを選択します。

以下の設定をし、作成します。
- 拡張子:
mp4 - コンテナ:
MPEG-4 コンテナ(デフォルト) - 解像度:
1920×1080 - レート制御モード:
QVBR(デフォルト) -
品質チューニングレベル:シングルパス(デフォルト) -
大ビットレート (ビット/秒):5000000
Media ConvertのIAMロール
Media ConvertからS3に動画をアップロードするためには、Media ConvertのジョブにS3へのアップロード権限を付与する必要がありますので、Media Convertのジョブ用のIAMロールを作成します。
IAMロールは、以下の2つに権限を付与し、MediaConvert_Default_Roleというロール名で作成します。
AmazonAPIGatewayInvokeFullAccessAmazonS3FullAccess



作成後、IAMロールのARNをコピーしておきましょう。Lambdaの環境変数で使用します。
Lambdaを作成
アップロード用S3に動画や画像がアップロードされたとき、以下を実行するLambdaを作成します。
- 動画の場合、拡張子が
.mp4 .mov .m4vの動画を、Media Convertで動画の拡張子を.mp4に変換する - 画像の場合、拡張子が
.png .jpg .jpegの画像を、視聴用S3にコピーする
Lambdaは、最新のPython3.9を選択し、他はデフォルトで作成します。

IAMロール
作成したLambdaのIAMロールに対して、以下の権限を追加付与します。
-
AmazonS3FullAccessをIAMロールにアタッチ -
iam:PassRoleとmediaconvert:CreateJobをIAMポリシーに付与
LambdaのIAMポリシー(AWSLambdaBasicExecutionRole-xxxxx)に権限を付与し、以下の通りになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"iam:PassRole",
"mediaconvert:CreateJob"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:xxxxxxxxxxx:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:xxxxxxxxxxx:log-group:/aws/lambda/media_convert-movie-and-image:*"
]
}
]
}
設定
タイムアウトは、1分に変更します。
環境変数は、以下の4つを設定します。
- JOB_TEMPLATE_NAME:
arn:aws:mediaconvert:ap-northeast-1:[アカウントID]:jobTemplates/[ジョブテンプレート名] - MEDIACONVERT_ENDPOINT:
https://[ランダム文字列].mediaconvert.ap-northeast-1.amazonaws.com- MediaConvertのAPIエンドポイント(MediaConvertのコンソールで確認できます)

- MediaConvertのAPIエンドポイント(MediaConvertのコンソールで確認できます)
- MEDIACONVERT_ROLE:
先程作成したIAMロールのARN - OUTPUT_BUCKET:
viewing-movie-and-image- 視聴用S3のバケット名
以下のようになります。

コード
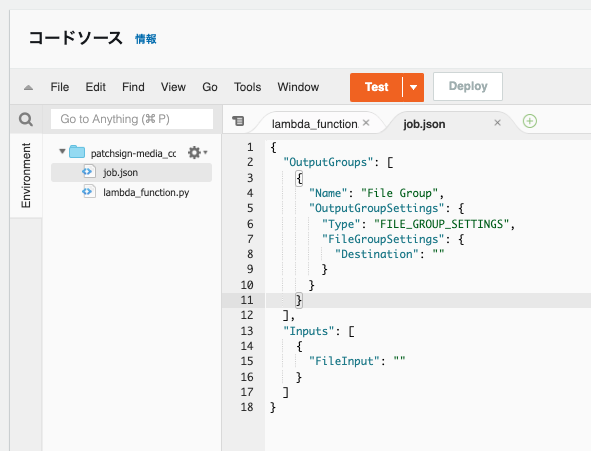
ファイルは、lambda_function.pyの他に、job.jsonファイルを作成します。
Media Convertの処理は、ジョブテンプレートをベースに、Lambda側でインプットとアウトプット用のS3バケットを指定するようにしているため、job.jsonにインプットとアウトプットのバケット情報を追加する必要があります。
import os
import urllib.parse
import boto3
import json
from decimal import Decimal
MEDIACONVERT_ENDPOINT = os.environ['MEDIACONVERT_ENDPOINT']
MEDIACONVERT_ROLE = os.environ['MEDIACONVERT_ROLE']
JOB_TEMPLATE_NAME = os.environ['JOB_TEMPLATE_NAME']
OUTPUT_BUCKET = os.environ['OUTPUT_BUCKET']
s3 = boto3.client('s3')
def decimal_to_int(obj):
if isinstance(obj, Decimal):
return int(obj)
def lambda_handler(event, context):
print("Received event:" + json.dumps(event, default=decimal_to_int, ensure_ascii=False))
input_bucket_name = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
basename = os.path.basename(key).split('.')[0]
extension = os.path.basename(key).split('.')[1]
input_bucket_path = key.split('/')[0]
input_bucket = f"s3://{input_bucket_name}/{key}"
output_bucket = f"s3://{OUTPUT_BUCKET}/{input_bucket_path}/"
if extension in ["mp4", "m4v", "mov"]:
print("mp4,m4v,mov")
try:
with open("job.json", "r") as jsonfile:
job_object = json.load(jsonfile)
job_object["Inputs"][0]["FileInput"] = input_bucket
job_object["OutputGroups"][0]["OutputGroupSettings"]["FileGroupSettings"]["Destination"] = output_bucket
client = boto3.client('mediaconvert', endpoint_url=MEDIACONVERT_ENDPOINT)
response = client.create_job(
Role=MEDIACONVERT_ROLE,
JobTemplate=JOB_TEMPLATE_NAME,
# 入力ファイルの情報や、上書きしたいパラメータの情報などを渡す
Settings=job_object,
)
print("Received response:" + json.dumps(response, default=decimal_to_int, ensure_ascii=False))
return "ok"
except Exception as e:
print(e)
raise e
return "error"
# png,jpeg,jpg
try:
print("png,jpeg,jpg")
# 上記で抜き出したバケット情報とkey情報よりアップロードファイルにアクセスし、コンテンツのタイプを出力する。
response = s3.get_object(Bucket=input_bucket_name, Key=key)
print("CONTENT TYPE: " + response['ContentType'])
# 実際のコピーコマンド
response = s3.copy_object(Bucket=OUTPUT_BUCKET, Key=key, CopySource={'Bucket': input_bucket_name, 'Key': key})
print("Received response:" + json.dumps(response, default=decimal_to_int, ensure_ascii=False))
return "ok"
except Exception as e:
print(e)
raise e
{
"OutputGroups": [
{
"Name": "File Group",
"OutputGroupSettings": {
"Type": "FILE_GROUP_SETTINGS",
"FileGroupSettings": {
"Destination": ""
}
}
}
],
"Inputs": [
{
"FileInput": ""
}
]
}
イベント通知
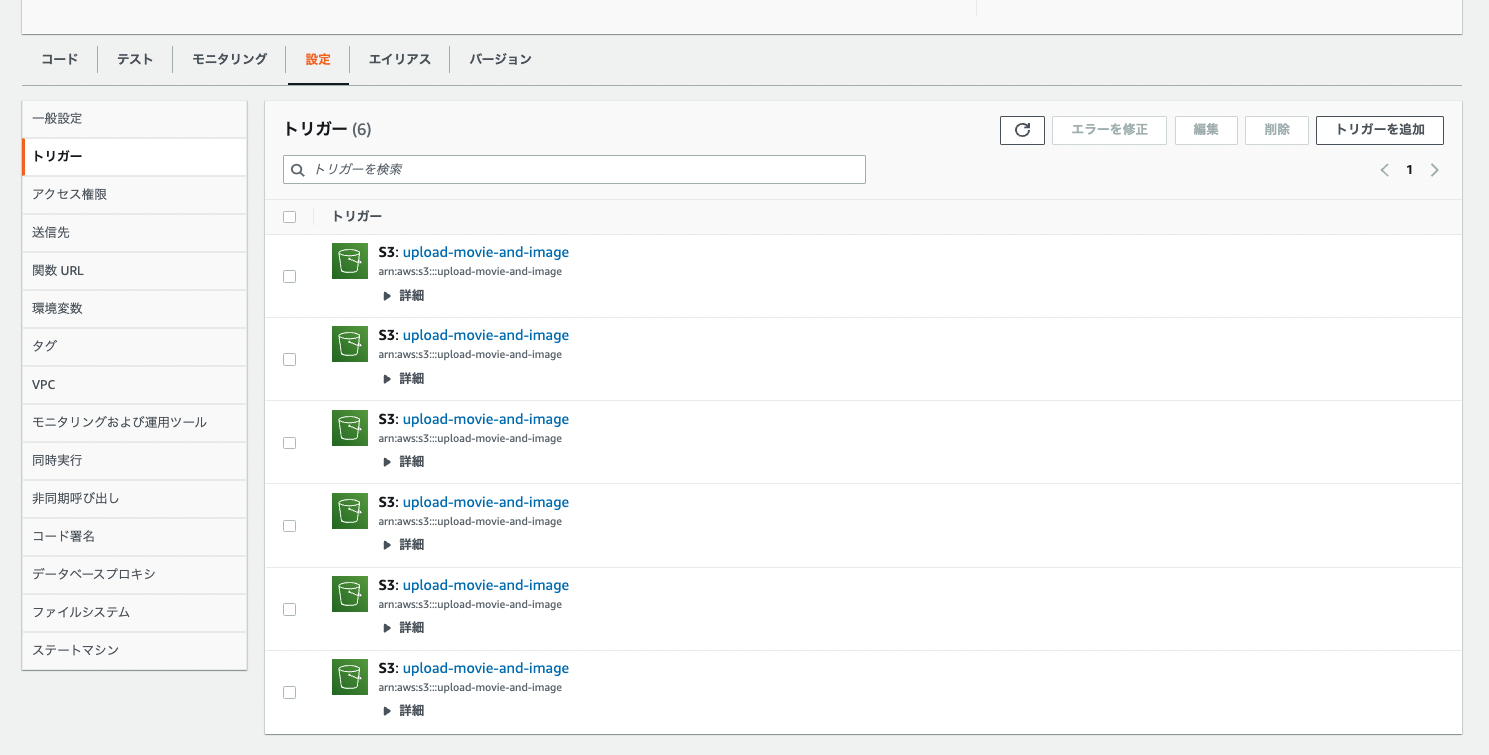
S3に動画・画像がアップロードされた際に、Lambdaが起動できるよう、Lambdaのコンソール画面からトリガー追加をクリックします。

トリガーは、アップロード用のS3を指定し、Suffix(拡張子)は、.jpgなどを選択し、保存します。
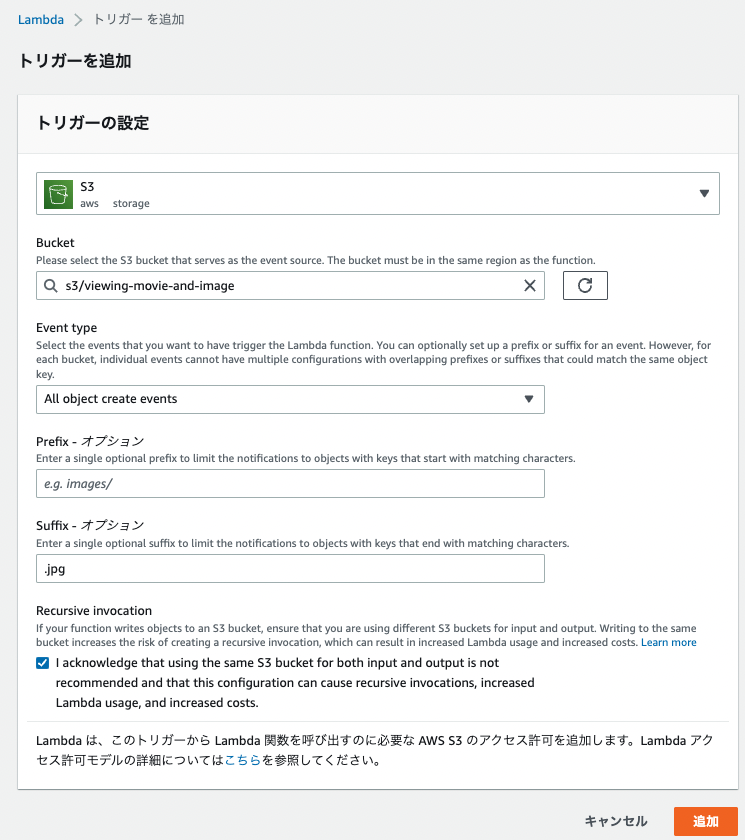
これを対象の拡張子の数だけトリガーとして追加します。
そのため、トリガー数は、.png .jpg .jpegと.mp4 .mov .m4vの合計で6つになりますね。
テスト
では、アップロード用のS3に、動画(.m4v) と 画像(.png)をアップロードしてみましょう。

画像は、コピーされ、動画はmp4に変換されていることが分かります。
動画は、解像度を1920*1080に変換したため、サイズが小さくなっていることが分かります。

参照
コーデック
作成方法
アーキテクチャー