はじめに

これは ドリコムAdventCalendar の9日目の記事です。
8日目はsazae657さんによるドリコムの俺を支えるUIツールキットです。
自己紹介
@hiracy といいます。
ドリコムのインフラやってます。
- 最近発表したスライド
この内容について
WEBサービス・ソーシャルゲームのインフラにてサーバが増加した時の管理について採用してきたツールとノウハウについて書かせて頂きました。
サーバ増加時の管理にお悩みのインフラ担当者は参考にしてみてはいかがでしょうか。
プロビジョニング
業者又は自前でラッキングされたサーバやクラウド業者で契約し使えるようになったサーバからOS設定・ミドルウェアインストール等を1台1台コマンドで設定すると日が暮れてしまいます。(たまにやってみるといい気付きがあります)
また、構築した際の手順から別のサーバを構築すると再現性が不完全になってしまいますので、プログラミング言語でサーバの状態を記述できるツールを使うと良いと思います。
ドリコムでは以下のポイントでこのプロビジョニングツールを検討しました
- ツール自体を含む機能の拡張が一般的なプログラミングを習得しているエンジニアであれば容易にできる
- ツール自体の機能の学習・調整に時間を取られない
- gitによるサーバの状態・構築手順の管理ができる
- お金が(かからない|あまりかからない)
検討していた時期の2年前には上記に当てはまるツールがChef-Server/SoloとPuppetくらいしかなかったのですが、1の理由でLWRPによる拡張のしやすさと、2の理由で当時Chef-Serverが色々なミドルウェアのごった煮状態で調整が難しく、得られるメリットが感じられなかったためChef-Soloを拡張することに決めました。
最近だと以下のような、Chefに引けを取らないツールがあるので初めてプロビジョニングツールを検討する方は参考にして頂けたらと思います。
テスト
管理するサーバの冪等性を保証するために主に以下のケースでServerspecを使っています。
- プロビジョニングの後
- セキュリティ対応等ミドルウェアの設定調整やDB・KVSの冗長構成変更の際に実施している、限定的な手動サーバオペレーションの後
現在このようなサーバの状態を一般的なプログラミング言語でテストするツールはServerspec一択のような気がします。(他はshUnit2とか)
CI
インフラがコード化するとCI(継続的インテグレーション)環境を用意し、コードを管理からサーバ構築までの一連の作業を自動化できるようになります。
ドリコムでは以下のような環境と順番にてCIを実施しています。
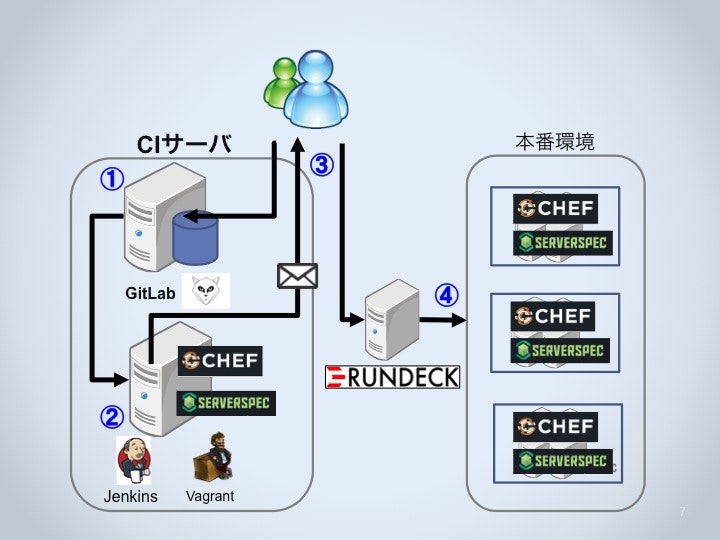
- Chefのレシピを編集して社内のGitLabサーバにpushします。push時にJenkinsサーバにweb hookが発行されます。
- 本番環境でのサーバ構築とテスト(Chef-Solo+Serverspec)と同等の処理をVagrantの仮想環境上で実行します。
- 2の成否結果をインフラ担当者全員にメール送付します。
- 3の成功結果を確認した後、担当者が本番環境にRundeck(後述)やsshを使ってサーバ構築(Chef-Solo+Serverspec)を実行します。
オペレーション(ssh手動運用)
最近はImmutable Infrastructureといった一度サーバを構築したらいじらない、構成を変更する際は新たに作り直すといった手法もあるようですが、採用しているクラウド業者によっては色々な事情で実現できないケースも多く、また手軽に扱えるため手動でのサーバオペレーションの機会は多いと思われます。
Rundeck
Java/Groovy製のオーケストレーションツールでSalesforce.comも使っているそうです。
元々インフラ担当者のサーバオペレーションにcapistranoを使っていたのですが対象サーバのフィルタリングや実行履歴の管理の機能に不足を感じていた際に、その要件を満たしていてしかもWEB UIその他機能も充実しているので採用となりました。
あまり採用している会社もないようなので下記ちょっとだけ紹介したいと思います。
ホスト管理画面
ホスト情報はxmlやyamlで管理するのですが、ドリコムではサーバ監視システムであるZabbixサーバのAPIを介して自動で生成しています。

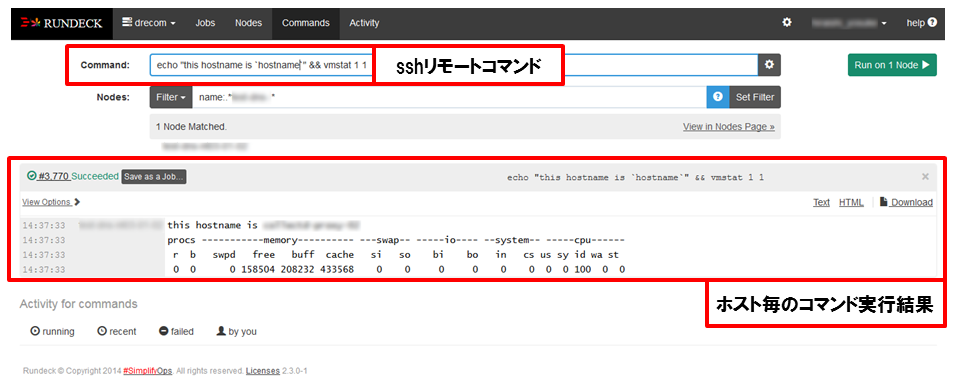
コマンド実行
フィルタリングした結果のサーバのみコマンドを実行します。実行時のユーザはLDAPにて管理しています。
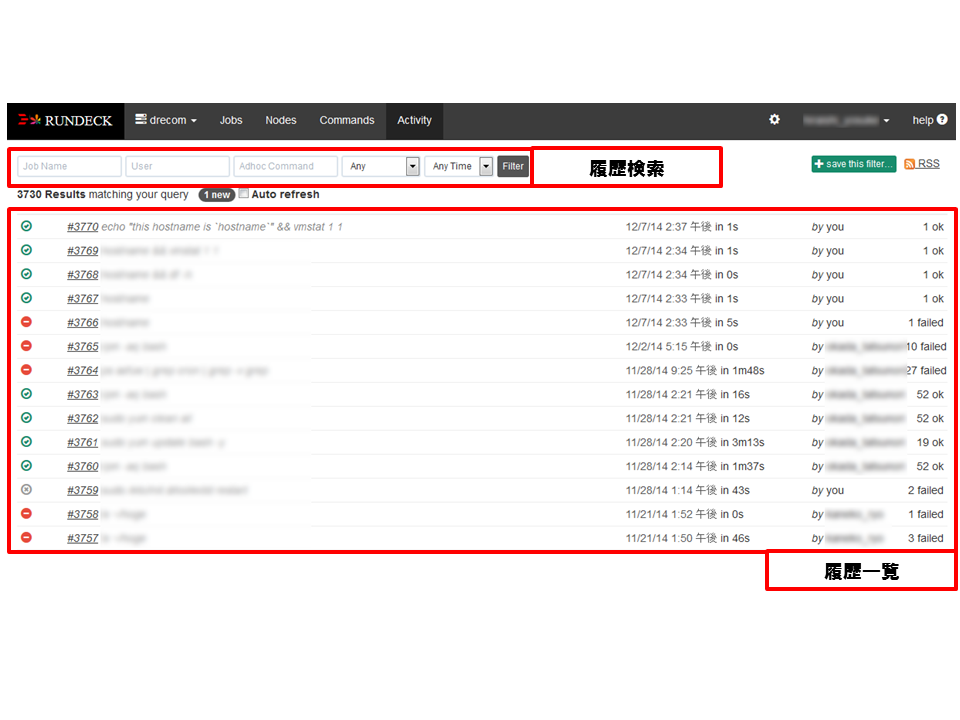
実行履歴管理
過去と同じパターンを検索し再実行することも可能です。
その他
JOBを登録してcronのように使えたり、WEB APIにて別のシステムと連携可能と機能が充実しているので複数サーバオペレーション管理のツールを検討している方にはオススメです。
tmux + ssh + Zabbix API
Rundeckは主にインフラ担当者がサーバ運用に使う位置付けのツールですが、とあるエンジニアからtmux + ssh + Mackerel APIというライフチェンジングなサーバオペレーションについての記事を紹介頂き、Mackerelを社内で監視に利用しているZabbixに置き換えたツールを勢いで作ってみました。
仕組み
上記記事内に「タイトルに Mackerel と書いていますが、半分以上は Mackerel に依存しない話です。」と書かれておりますが、その通りMackerel APIをZabbix APIによるホスト情報取得に置き換えただけです。
ただMackerelには「Service」というサーバ登録時にグルーピング指定を明示的に指定する必要がありますが、ドリコムでは以下のようにホスト名の命名規則に、ある程度厳格な運用をしているためそちらをグルーピングに利用しています。
ホスト名命名規則
[servicename]-[role](-subrole)(-cluster_no)-[server_no]
servicename: サービス名
role: そのサーバの役割
subrole: roleの補助名(option)
cluster_no: クラスタ番号(option)
server_no: サーバ番号
例) anyservice-db-01-01
zabbix APIからホスト情報の取得
tmux + ssh + Mackerel APIと同様に以下の2つのコマンドで対象サーバのIPアドレスを取得できるgemツールを作りました。
app <サービス名>
> サービス名にマッチしたサーバ一覧が出力される
role <サービス名> <ロール名>
> サービス名とロール名にマッチしたサーバ一覧が出力される
使用例
サービスに所属するホスト一覧
$app anyservice
anyservice-web-01-01
anyservice-web-01-02
anyservice-db-01-01
anyservice-kvs-01-01
サービスに所属した特定のロールのホスト一覧
$role anyservice web
anyservice-web-01-01
anyservice-web-01-02
tsshを使って特定のサービス・ロールのサーバをオペレーションする
$tssh `role anyservice web`
デモ

※弊社のサーバ全てslコマンドが使えるようになっているわけではありません
実装について
このような仕組みを持つツールをgemで実現していますが、詳細は割愛させて頂きます。
代わりにZabbix APIをcurl,jqコマンドにてホスト情報のJSONを取得するシェルスクリプトを添付しますのでこのようなツールを作成する時に参考にして頂けたらと思います。
ZABBIX_APIUSER="user"
ZABBIX_APIPASSWORD="passwd"
ZABBIX_HOST="http://zabbix.any"
ZABBIX_API_PATH="api_jsonrpc.php"
ZABBIX_API_URL="${ZABBIX_HOST}/${ZABBIX_API_PATH}"
ZABBIX_JSONRPC="2.0"
CURL_OPTS="-s -d"
login_ans_json=`curl ${CURL_OPTS} \
'{"auth":null, \
"method":"user.login", \
"id":1, \
"params":{ \
"user":"'${ZABBIX_APIUSER}'", \
"password":"'${ZABBIX_APIPASSWORD}'"}, \
"jsonrpc":"'${ZABBIX_JSONRPC}'"}' \
-H "Content-Type:application/json-rpc" ${ZABBIX_API_URL}`
api_key=`echo ${login_ans_json} | jq ".result" | sed "s/\"//g"`
host_json=`curl ${CURL_OPTS} \
'{ "jsonrpc":"'${ZABBIX_JSONRPC}'", \
"method":"host.get", \
"params":{ \
"output": ["extend"], \
"selectInterfaces": ["ip"]}, \
"auth":"'${api_key}'","id":1}' \
-H "Content-Type: application/json-rpc" ${ZABBIX_API_URL}`
echo $host_json | jq .
監視・モニタリング
ツールを選定する際には以下の点を意識してきました。
- コマンド実行結果の値を監視・モニタリングにて状態取得でき、ある程度カスタマイズして表示できるか
- 監視・モニタリング対象のサーバが増えた時にスケールアップ又はスケールアウトが容易か
- 異なるネットワーク間の監視・モニタリングが自分たちのDCにマッチしているか(使用ポート・プロキシ機能有無等)
- 最終的に自分達でツールに手を加えて面倒を見れるか(見れる自信があるか)
- 結局運用してみないと機能不足や見辛さに気付かない事も多いので、とにかく色々試してみる
ドリコムでは以前は主にNagiosとcactiを使っていましたが、急激なサーバ増加の際に対応するための自動化がしづらいということもあり、現在は以下のツールを使いプロビジョニング時の情報からほぼ全自動で最適な監視が設定できるようにしています。
また、最近は以下のような自分達で監視・モニタリングサーバを持たずにWEBサービスを利用することも多くなってきていますので選択肢の中に入れておいて良いのかもしれません
尚、よくあるのが「色々対応しているけど結局何をみたらいいのかわからない状態」になり、障害時や性能劣化が発生している際に誰も何もしない状況に陥るというケースです。
これを防ぐためには事前にエスカレーションフローを決める事や、サービスとして正しい状態とは何かをエンジニアで共有・決定した上でツールの選定や監視・モニタリングする項目の設計をしていくのが良いと思います。
10日目は
tkeoさんが発表します!