読み込んだcsvファイルの日本語が文字化けに・・・
Azure Databricks notebook上で
以下のコードを記載してcsvを読み込みました。
df = spark.read\
.format("csv")\
.options(header="true", inferSchema="true")\
.load(order_items_csv)
display(df)
読み込んだ結果は以下です。
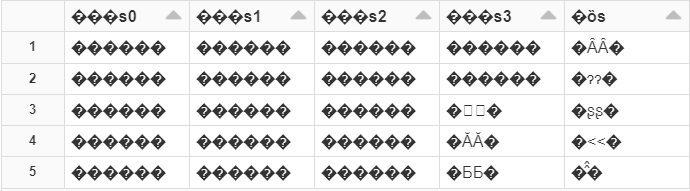
見事に文字化けしてますね・・・
文字コードの変換
どのように文字コード変換をするか調べました。
そこで、以下の1行を加えます。
.option('charset', 'shift-jis')\
全体は以下のようになります。
df = spark.read\
.format("csv")\
.options(header="true", inferSchema="true")\
.option('charset', 'shift-jis')\
.load(order_items_csv)
display(df)
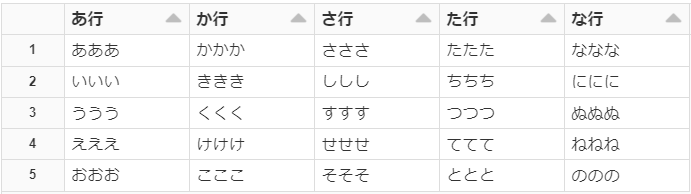
問題なく読めるようになりました!