M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning 要約
読んだ論文
M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning
Issam Laradji, Reza Babanezhad
https://arxiv.org/abs/1807.02552v1
上記の論文を読んだので簡単にまとめます.ICML2018にて発表されたらしいです.githubにPyTorch実装があったのでリンク貼っておきます.
3行でまとめる
- 教師なしのドメイン適応課題に対して,距離学習の観点を応用した手法.
- 距離学習で用いられるTripletLossを用いてソースドメインをクラスタリングできるように学習する.
- ターゲットドメインのクラスタの重心をソースドメインのクラスタの重心に近づけるLossを提案し敵対的学習で訓練する.
前知識として
ドメイン適応
機械学習ではラベル付けにかかるコストが大きいので,既にある大規模なラベル付きデータから別の分野に転移させる(Domain Adaption or Transfer Learning)が研究されている(10日目の自分の記事より).10日目と11日目の記事もドメイン適応の話題.
距離学習
例えば写真の人物の認識問題を考えると,ラベル付きデータセットとしてA,B,Cさんの画像が揃っている時,A,B,Cさんの識別を行う分類器を鍛えることは容易である(教師あり学習).一方,そこにDさんの写真を入力すると,A,B,Cいずれかのラベルしか出力されない.一転して,Dさんの写真がAさんとどれだけ類似しているか?といった距離(というか意図したドメインにおける距離が図れるようなEmbedding空間にマッピングすること)を学習する手法が距離学習(Metric Learning)である.
距離学習とTripletLossについてはこちらの記事がとってもわかりやすく解説してくださっているので,是非事前に一読することをおすすめします.
もう少し背景

キャプションを意訳するだけですが,Fig.2.の青点はMNISTのEmbeddingsで,同じクラスに属する文字が近い距離に位置するように学習されています(例えば左上の塊が数字の1のクラスタ).ここではドット一つが画像1枚を意味します.
次にオレンジ点はUSPSデータセット(MNISTの亜種みたいなデータ)を配置した場合の例(提案手法適用前)で,データセットが変わると,ソースドメインで距離学習したのにターゲットドメインであまりうまくクラスタリングされていない.ソースドメインでMetricLearningしているので当然ターゲットドメイン側での動作は保証されていないのである.
キャプションにはThe right-most imageの説明がされていますが,これは多分Fig3.(下図)の右図のことを意図していて,これが提案手法適用後のUSPSデータセットのEmbeddingsになります.もとに比べてMetricLearningされている感が若干出ています.

ということで,キャプションに出ているEq.(1)~(3)が重要になってきそうですね.
提案手法
ADDA
本稿ではM-ADDAという手法を提案していますが,先行研究としてADDA1が提案されています.そちらは読んでいませんが文献だけ上げておきます.
M-ADDA
M-ADDAは主に次の2ステップで構成される.
- ソースドメインでTripletLossを用いてMetricLearningを行う.
- 同時に,抽出されたソースとターゲットの間の特徴分布を適応させ,推定されたターゲットEmbeddingsをクラスタ状に一般化させる.
M-ADDAの概要図は以下のFig.5の通り.
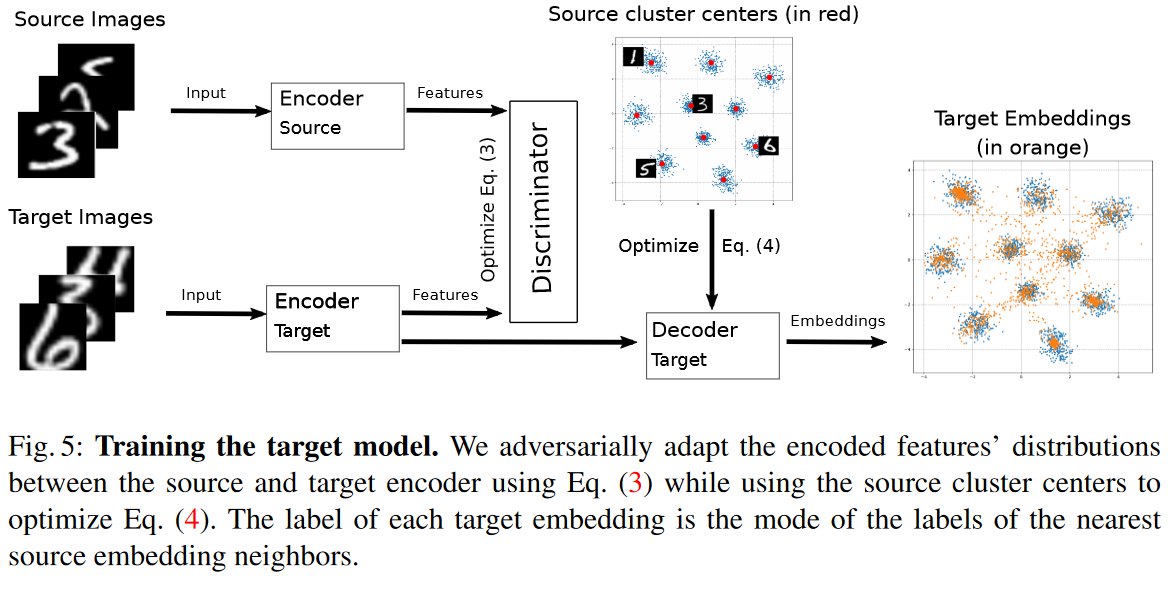
学習手順
まず上記1の通りソースドメインでMetricLearningを行うのですが,ここは上で上げたMetricLearningの記事を読んだほうが良いので割愛.
次にターゲットモデルを訓練する.はじめに,ソースドメインのEmbeddingsに対応する中心ベクトルを$\boldsymbol{C}$と定義する(Fig.5の赤点).各赤点はソースラベル一つずつが割り当てられている.なお,中心は平均値で求めるらしい.続いて以下の式(2)の損失を元に,ターゲットドメイン側の学習を行う.
$L(\theta_{T}, \theta_{D})=L_A(\theta_{T_E}, \theta_{D}) + L_C(\theta_T)$ ....(2)
$L_A(\theta_{T_E}, \theta_{D})=min_{\theta_D}max_{\theta_{T_E}}(-\sum_{i \in S}log D_{\theta_D}(E_{\theta_S}(X_{S_i}))-\sum_{i \in T}log(1-D_{\theta_D}(E_{\theta_{T_E}}(X_{T_i}))))$ ....(3)
$L_C(\theta_T)=\sum_{i \in T}min_j||f_{\theta_T}(x_i)-C_j||^2$ ....(4)
(2)は(3)と(4)の和を取るだけ,(3)は一般的なGANのLossで,ソースドメインかターゲットドメインどちらから来た特徴マップ化を識別する弁別器である.これは識別できないことが望ましいので最小化(負符号なので)するように$\theta_{D}$を最適化する.一方でエンコーダ側はDを騙せる方が良いので最大化するように$\theta_{T_E}$を学習する.これにより,$E_{\theta_S}$と$E_{\theta_{T_E}}$が区別できないような分布を学習する.
同時に(4)の提案手法の肝であるCneter Magnet Lossを最小化する.この損失の最小化により,ターゲットEmbeddingsのクラスタをソースEmbeddingsのクラスタに類似させるらしい.これにより最初に紹介したFig.2.の右図のようにEmbeddingsの分布がズレると言ったことが改善できるとか.この損失は式の通りターゲットドメインの各サンプルに対して,最も近いクラスタとの二乗ノルムの総和をとっており,これを最小化することでクラスタの中心にすべてのサンプルが寄るということであろう.
評価実験
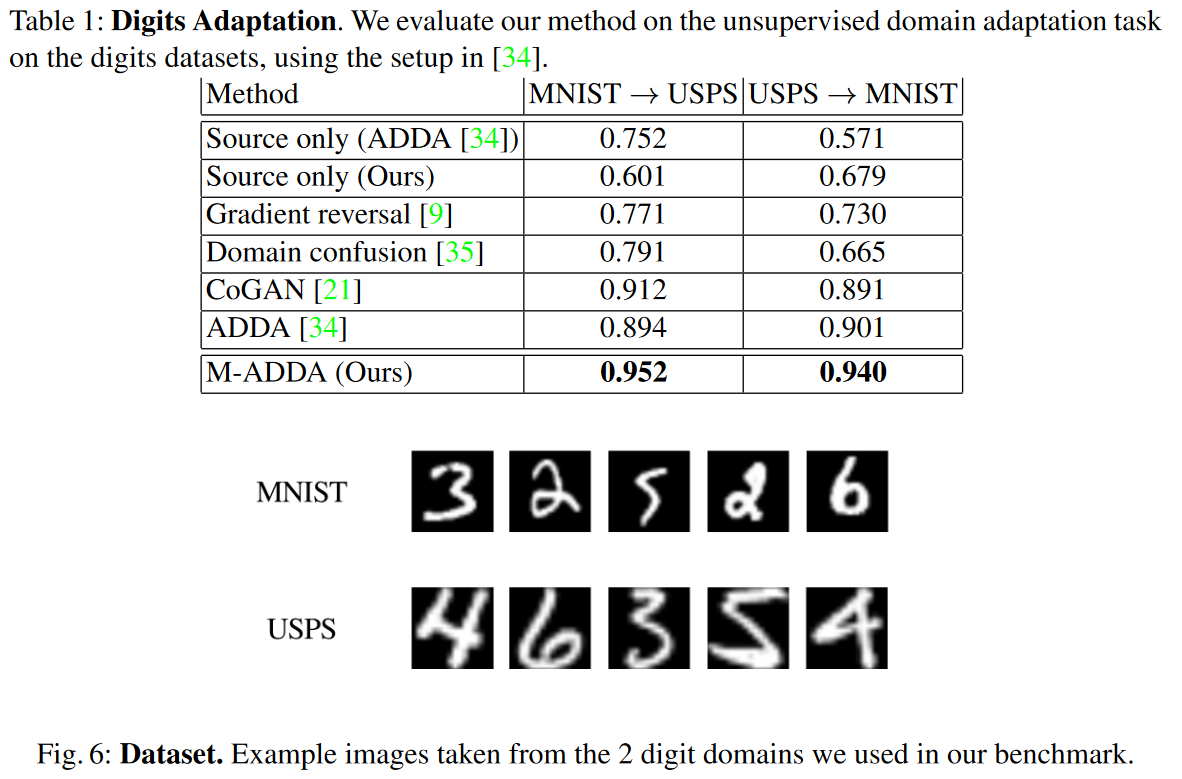
MNIST<->USPSで教師なしドメイン適応を比較検証実験している.Table 1の通り,ADDAやCoGAN等の手法よりもいい感じにドメイン適応できている.別途DSNやPixelDA等と比較している表もあったが何が違うのだろう..
まとめ
- ドメイン適応を行うGAN構造を提案した論文
- 距離学習の観点を導入するのは大賛成で,とても精度が出ているらしいので非常に参考になります.
- ただ,使ってるのが中心を近づけるというシンプルな手法なのでもう少しなにかできそうな気がしますが,教師なしなので意外と難しいのかもです.
所管
似たような論文ばかり読んでいるのと,今回は原理の説明が理論的にシンプルに書かれていたので読みやすかったです.多分1時間半くらいで読了しました.そろそろ知識を入れるだけでなく実装もしていかねばなぁと思う次第です.
-
Tzeng, E., Hoffman, J., Saenko, K., Darrell, T.: Adversarial Discriminative Domain Adapta-tion. arXiv (2017) 392 Citations!! ↩