Empirical Study and Improvement on Deep Transfer Learning for Human Activity Recognition 要約
読んだ論文
Empirical Study and Improvement on Deep Transfer Learning for Human Activity Recognition
Renjie Ding, Xue Li, Lanshun Nie, Jiazhen Li, Xiandong Si, Dianhui Chu, Guozhong Liu, Dechen Zhan
https://www.mdpi.com/1424-8220/19/1/57
上記の論文を読んだので簡単にまとめます.本当はDeep Transfer Learning for Cross-domain Activity Recognitionを読もうと思ったのですが,これを引用して本稿が最新だったのでこちらを読むことにしました.Sensors MDPIのJournal Paperです.
3行でまとめる
- 教師なしの深層転移学習な手法を色々実践してみたよ.
- 比較した結果MMDが良かったよ.
本稿の貢献
- 教師なしの深層転移学習手法を大規模に実践した初めての論文である.広く一般的に使われる手法を検証しMMDが良く働いたことを示した.
- CNNで抽出された特徴を分析し,同じクラス内の分布は広く,他クラスとの分布は小さいという傾向があり,これが転移に影響を及ぼしている.
- 特徴分布を改善することが役立つと検証すべく,MMDとCenter Lossを組み合わせ,2の傾向の改善に取り組んだ.この改善が教師なし転移に役立つ.
検証した手法
MMD
そろそろおなじみになってきたMMD (Maximum Mean Discrepancy)です.MMDは10日目のDomain Separation Networks,16日目のUnsupervised Domain Adaptation with Residual Transfer Networksでも紹介しています.
$MMD[F, p, q]:=sup_{f \in F}(E_p[f(x)]-E_q[f(y)])$
MMDでは,上式でpとqの分布が同一かを判定する(0だと同一だとみなす).実践的には実際は次式が用いられる.
$MMD[F, X, Y]=sup_{f \in F}(\frac{1}{m}\sum_{i=1}^{m}f(x_i) - \frac{1}{n}\sum_{j=1}^{n}f(y_j))$
深層学習によって得られる特徴表現について,ターゲットソース間での不一致度合を最小化することで同じ表現形式を学習しようとする方法である.なお今回はMK-MMDを採用しているらしい(後で書かれていた).
DANN
こちらもそろそろおなじみのDANN ()です.DANNは11日目のDomain-Adversarial Training of Neural Networksで原典を読んでいます,
詳細な説明は上記引用先に任せますが,簡単に言うと,ソースドメインを単純に訓練する損失と,ソースとターゲットを見分ける弁別器の損失を合わせて学習することで敵対的学習によりソースターゲット間で共通する表現を学習するという手法です.
WD
こちらだけ初見の手法,WD (Wasserstein Distance)です.WDは確率分布間の距離を計算する手法らしく,以下の式で定義されます.
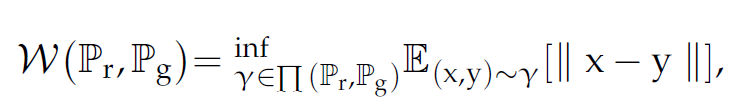
$\Pi (P_r,P_g)$は(x,y)の同時確率分布の集合を示す.そこから$\gamma$を選択し,(x,y)が$\gamma$に従う際の||x-y||の期待値を算出する.この時の最小期待値がWDとなる.
評価実験
データセット
UCI dailyとSports,UCI-HADの三つを使用した.HADの方はエレベータの上り下りがほぼ同一なのでこれは結合して使用した.
今回はユーザ間のTransferが目的なので,ターゲットユーザに対する推定精度が評価指標となる.全員を使ってるときりがないのでランダムに選んだ数人に対して実施した.まずソースユーザたちからは2/3のラベルありデータを訓練に使用し,ターゲットユーザからは2/3のラベルなしデータを適応に使用し,残り1/3をテストに使用した.なお20000エポック中の最高精度を採用している.
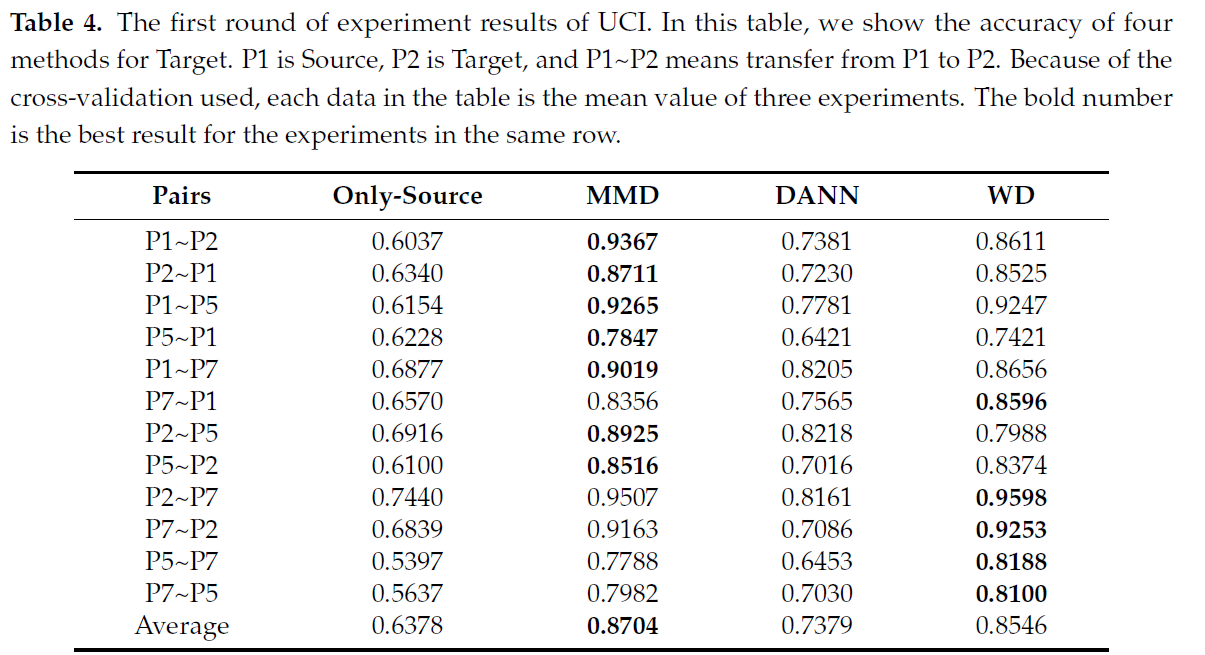
最終的にTable4の結果となり,平均的にMMDが優秀であることを示した.あおTable5にはターゲットドメインの適応データを1/3に減らした評価結果も載っている(が,原典をご覧くださいませ).
この後,各クラスが中央に寄るような損失関数を追加で定義して検証を行っているが,疲れたのでここまでにします.
まとめ
- 教師なしのドメイン適応手法を行動認識におけるユーザ適応に使用した(多分初めての)論文.
- 最近よく使われるベーシックなドメイン適応手法を検証されていて,引用元にするにはいい感じに思います.
- 一方で,個人→個人の転移のみに焦点を当てていたので,不特定多数→個人の検証が気になりました.
所管
今回は論文選定に時間を取りませんでしたが,読むのに1時間半くらいかかりました.ユーザ適応にディープな手法を使うというのは,自分で先駆けてやりたかったのですが,すでにやられていました.残念.ただ差別化するような検討はいくつかできそうかなという印象も受けました.良論文だったと思います.