Domain-Adversarial Training of Neural Networks 要約
読んだ論文
Domain-Adversarial Training of Neural Networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, Victor Lempitsky
https://arxiv.org/abs/1505.07818
上記の論文を読んだので簡単にまとめます.Journal of Machine Learning Research 17 (2016) 1-35の論文で719引用されている良論文.ただし,35ページ...
3行でまとめる
- 昨日同様,ドメイン適応すればいいことあるよねという企画.
- ドメイン適応問題において,ドメイン検出器を敵対させることでドメイン汎用的な特徴抽出器を鍛える.
- 理論の裏付けと徹底的な検証が行われている.
関連研究
以前も紹介した東大松尾研の岩澤先生が人工知能学会全国大会で行動認識の個人適応における類似手法を試している様子です.和文のSlideShareもあるのでこちらも参考にしましょう.英文でもDomain adversarialな手法は結構提案されている様子でした.
提案手法
前置き
- 理論の背景に関する部分は読み飛ばした.
- 35ページの内Methodに絞って読んだにもかかわらず重い!!!
- 理論背景の説明と変数の種類が多いので対応付けるのが大変.
シンプルなMLPの場合
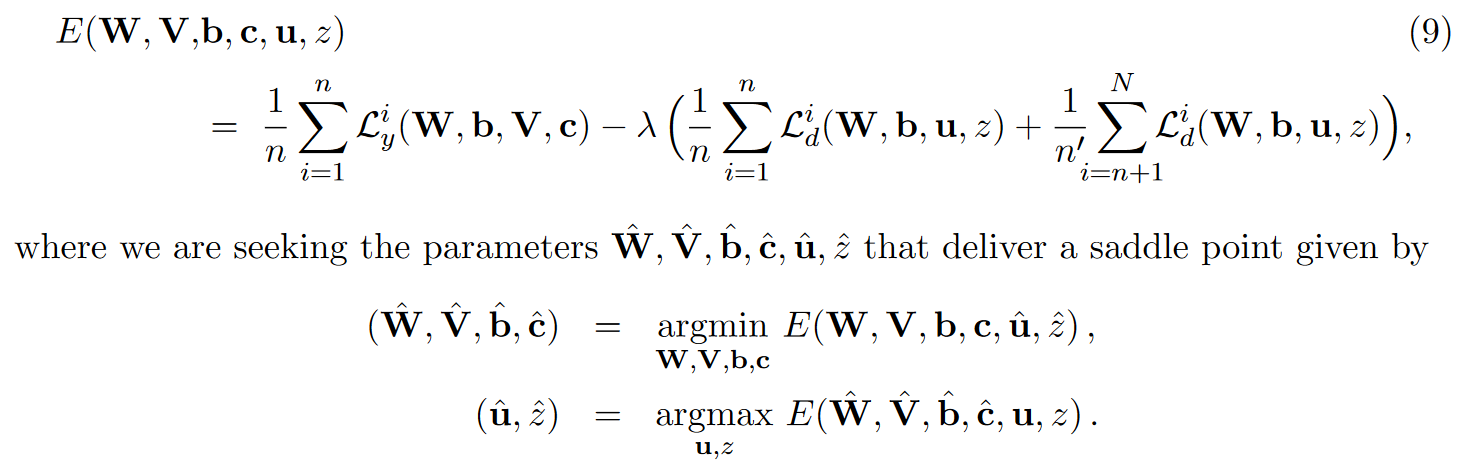
重要なのは上記の損失関数の最適化である.
- まず,各関数,変数の説明を行う.
- nはソースドメイン(ラベルあり)のデータ数
- n'はターゲットドメイン(ラベルなし)のデータ数
- $L_y^i$はソースドメインのラベルに関する予測の損失
- $L_d^i$はドメイン検出器の予測の損失(ソースドメインかターゲットドメインかを識別する)
- $W,b,V,c,u,z$は全てNNのパラメータ
- $W,b$は入力から隠れ層へのパラメータでここは$L_y, L_d$共通
- $V, c$は$L_y$のsoftmaxに対するパラメータで,$u,z$は$L_d$のsoftmaxに対するパラメータ
- 以上を踏まえると上記の損失関数は,
- 第一項:ソースドメインのラベル予測に関する損失(サンプル数で正規化)
- 第二項:ソースドメインのドメイン予測に関する損失(サンプル数で正規化)
- 第三項:ターゲットドメインのドメイン予測に関する損失(サンプル数で正規化)
となる.第一項をラベル予測,第二,三項をドメイン予測(λで重要度設定)とも考えられえる. - ここで,最適化は
- $W, V, b, c$ ラベル予測に関する部分は最小化(ラベル予測の精度が高まるように学習)
- $u, z$ ドメイン予測に特化した部分は最大化(ドメインが予測できないように学習)
これを行うことで,ソースドメインのラベル予測時に,ドメイン予測を最大化するような敵対をさせつつ学習することで,ドメインに汎用的な特徴抽出ができるという発想である.これが後々のAFLにつながっていくようである(3日目参照).
まとめ
- ドメイン予測を敵対させることでドメイン共通な特徴を学習する手法を提案した論文である.
- 恐らくこれが一番最初の提案?と思われ,ここからAFL等に発展していったと思われる.
昨日の補足
- 昨日の記事の方を編集します($L_{similarity}$の話).
所管
本記事だけ読むと簡単なのだが,原文を追いかけるのはすごい大変でした.多分2時間くらいかかっています.更にその前に論文選定やらバックグラウンド調査やらしたりしていたので合計3時間くらいかかりました.ただ,今後敵対的な特徴表現抽出や,ドメイン適応問題は考えていきたいので良い論文でした.