Unsupervised Cross-Domain Image Generation 要約
読んだ論文
Unsupervised Cross-Domain Image Generation
Yaniv Taigman, Adam Polyak, Lior Wolf
https://arxiv.org/abs/1611.02200v1
上記の論文を読んだので簡単にまとめます.ICLR2017で発表されている論文で,265引用されている良論文.
3行でまとめる
- 写真をイラストに変換すると言ったドメイン変換を教師なしで実施する手法
- 従来は対応のついた写真-イラストのペアデータセットが必要だったがペアじゃないデータセットで学習する.
- ベースライン手法を2点改良していい感じになったらしい.
関連記事
本論文は有名ということで和文での紹介記事がちらほらあるのですが,自分への備忘録も兼ねてまとめることにしました(基本的には和文記事がある論文は避けて選択していました).以下に記事のリンクをまとめておきます.
DL輪読会
Qiita記事
github: TensorFlow実装
提案手法
ベースライン
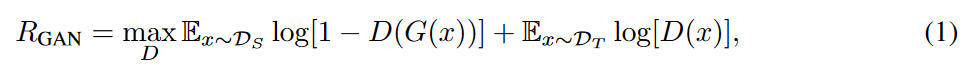
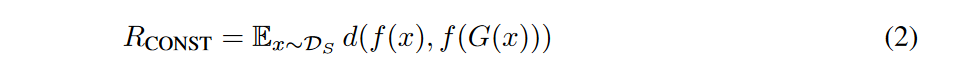
ベースライン手法(関連研究章で触れられているのか?引用不明)では,シンプルにソースドメインかターゲットドメインかを識別する損失関数$R_{GAN}$と,f(・)という表現において元画像xと変換後画像G(x)の距離を算出するdを損失とした$R_{CONST}$を最適化することでDとGを求めている.f(・)は例えば個人の識別といった表現学習モデルを採用すると,その人っぽい画像を維持したままドメイン変換が行われるようになる.このfは適宜設定すれば良いらしいが,Gの元で不変らしい.
ただ,
However, this baseline solution,as we will show experimentally, does not produce desirable results.
ということで,ベースライン手法はあんまり望ましい結果を生まないらしい.
提案モデル
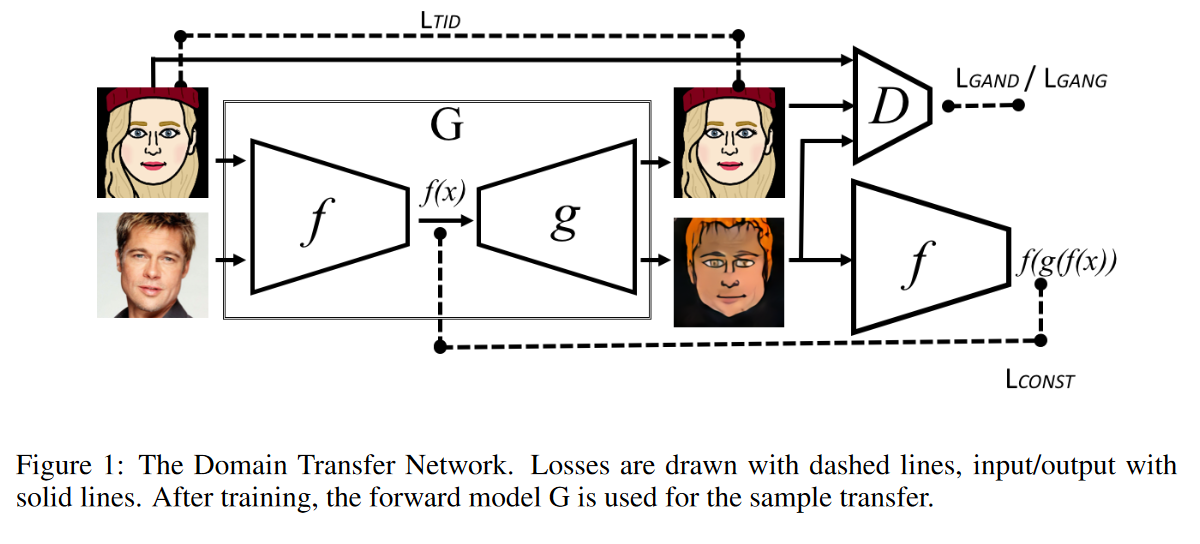
以上より,ベースライン手法を以下の2点において改良することで目的を達成する.
- Gの中でf(・)を使用すること
- これにより$R_{CONST}$に関連した情報をGでも学習できる.
- 多くの応用ではfはターゲットドメインに対して,(ソースドメインに対するときよりも)有効には働かないということで,Gの中にfを使用することで,ソースとターゲット両方からfを訓練しようということである.
- 訓練時にG(x) ただし $x\in \boldsymbol{t}$を考慮すること
- GANに関する損失$L_{GAN}$の形式を変えて,二値分類(ソースorターゲット)から多クラス分類(1:ソースから変換,2:ターゲットから変換,3:ターゲットそのまま)とするように改良した.
- 最終的に$L_D, L_{G}=L_{GANG}+\alpha L_{CONST}+\beta L_{TID}+\gamma L_{TV}$を以下の通りに定義した.
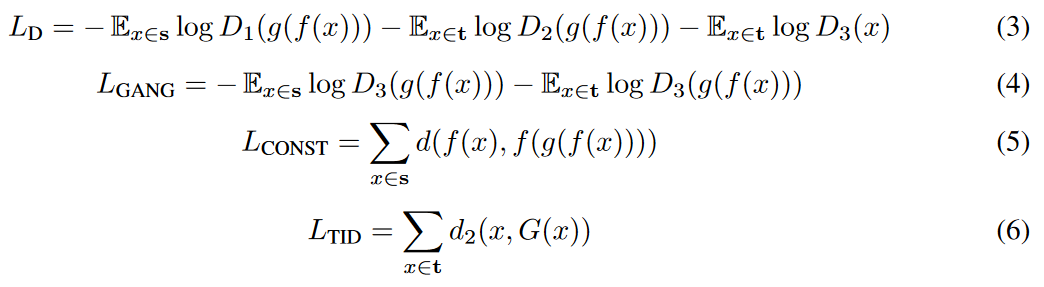
ここが少し理解に苦しんだので補足しておく.
- $L_D$ (時折$L_{GAND}$表記)
- 上記の多クラス分類(1~3)としたことを示すのが$L_D$である.
- 第一項:ソースドメイン(写真)画像を入力xとした時,g(f(x))が1と予測される確率
- 第二項:ターゲットドメイン(イラスト)画像を入力xとした時,g(f(x))が2と予測される確率
- 第三項:ターゲットドメイン(イラスト)画像を入力xとした時,xが3と予測される確率
- 多クラス分類問題なのでDを$D_1~D_3$と準備して(one-hotベクトル表現)いる.
- $L_{GANG}$
- 第一項:ソースドメイン(写真)画像を入力xとした時,g(f(x))が3と予測される確率
- 第二項:ターゲットドメイン(イラスト)画像を入力xとした時,g(f(x))が3と予測される確率
- これは自動生成した結果が**3(ターゲットドメインの元画像)**になる確率なので,自動生成画像か否かを識別する弁別器(いつものGANのヤツ)の損失ということになる.
- $L_{CONST}$
- ソースドメイン(写真)画像xについて,f(x)とf(g(f(x)))の距離を損失としている.
- 例えばf(・)が個人を認識する表現抽出器だった場合,入力と出力で同じ人物かどうかを測っている距離.
- $d, d_2$は今回MSEを採用した.
- $L_{TID}$
- ターゲットドメイン(イラスト)画像xについて,xとG(x)の距離を損失としている.
- すなわち,元のイラストと,それを変換した後のイラスト(イラストを同じモデルでイラスト化するのである)の距離が小さい方がいいよねということ.
- $L_{TV}(z) = \sum_{i,j}((z_{i,j+1}-z_{i,j})^2 + (z_{i+1,j}-z_{i,j})^2)^{\frac{B}{2}}$
- 生成画像をスムーズにするための損失関数
- zは生成画像で多分$z_{i,j}$は各pixel値
- 今回Bは1とした様子
評価実験
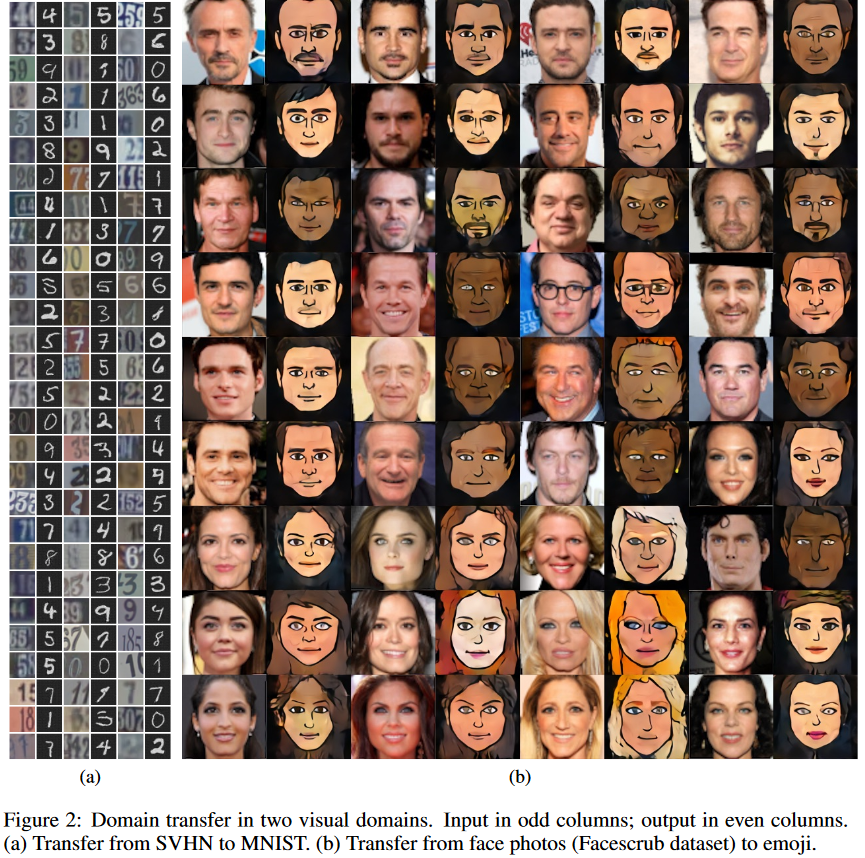
評価実験はSVHN to MNISTと,Facescrub to emojiで実施して,Figure2のような結果になっている.
推定精度評価実験も行っているようで,MNISTの分類器に,SVHNの画像をそのまま入れた場合や,DTN(提案手法)で変換した画像を入れた場合などの推定精度を比較している.結果,元画像の場合40%,DTNの場合90%となった.なお上記のベースライン手法の場合14%(うまく働いていないらしい).
また,昨日要約したドメイン適応(DANN等)を行った場合の推定精度と,DTNで画像変換してその画像で学習した場合の精度を比較したところ,DANNで74%,DTNで80~84%となった.
まとめ
- ドメイン変換を行うGAN構造を提案した論文
- 従来手法では全然駄目だったところを2点の改良によりいい感じにしたところがミソな様子
所管
ゼロから理解するのは中々大変でしたが終わってみるとそこまで複雑な話でもなかったです.ただ,$L_{TV}$直前くらいまで書いた段階で一回記事が消えたところで心が折れかけましたが,2周目は結構サクサク書けてよかったです.最終的にはTV見つつ3時間弱くらいかかりました.本記事は良論文だったので読めてよかったです.