モチベーション
・教師無しで、顔写真→似顔絵みたいな変換をしたい(教師ありだと、顔写真と似顔絵のペアが大量に必要で、集めるのが大変) ・(他のタスクもやってるけど顔写真→似顔絵のタスクを例として説明します)
・(他のタスクもやってるけど顔写真→似顔絵のタスクを例として説明します)
手法
ベースライン
S : 分布DSからi.i.dでサンプリングされた顔写真集合 T : 分布DTからi.i.dでサンプリングされた似顔絵集合生成モデル G : S → T を学習したい
ここで、Gを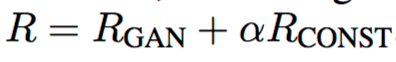 を最小化するようなGとする。
を最小化するようなGとする。
ここで、αはパラメータ。そして、

D : Sから生成されたものと、Tから来たものを見分ける関数 (生成された似顔絵と本物の似顔絵を見分ける関数)
このDを騙すようなGを学習すると、Sから生成されたものとTから来たものの区別が付きにくくなる → いい感じのGができる (GAN)
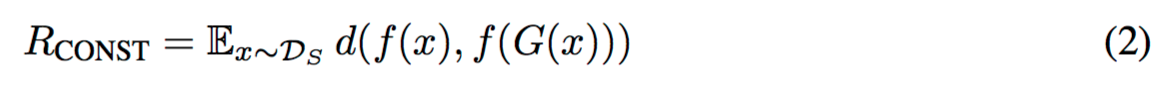
d : Mean Squared Error (Cosine とかHingeとかTripletでもいい)
関数fはこの問題では不変。あらかじめ学習させておく。問題に合わせて適切なものを選ぶ感じで、例えばfを、顔写真から個人を識別するようなネットワークにしたとき、f(顔写真)とf(G(顔写真))のギャップを小さくすることで、顔写真とG(顔写真)の両方が、同一人物だと判定されるようにできる。(Identity-Preservingになるように)
これで、GとDをDNNで構築して最適化すると・・
いい感じに生成できると思いきや、、、できません(って書いてあった)
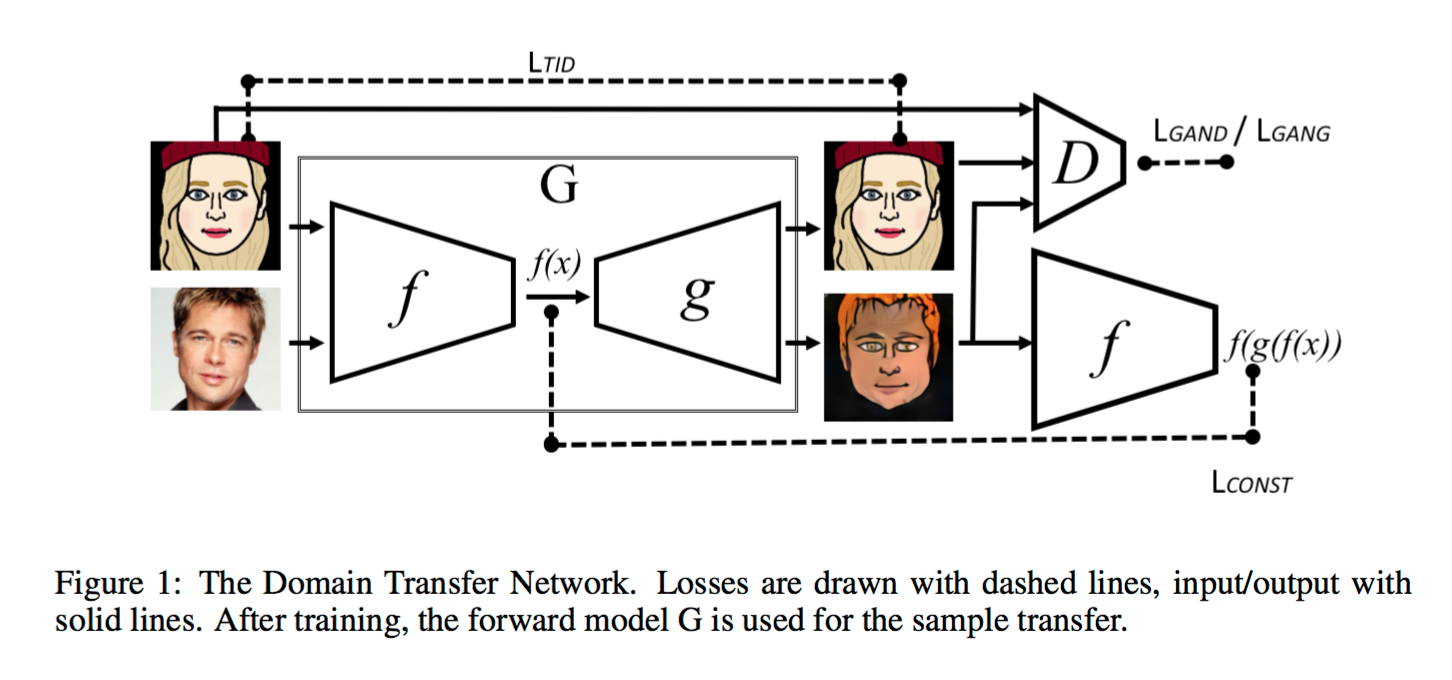
Domain Transfer Network (DTN)
・ベースラインに2つの変更を加える① Gの中にfを入れる
つまり、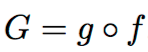 とし、gは何らかの生成関数とする。
とし、gは何らかの生成関数とする。
② 学習の際、Gが似顔絵から似顔絵を生成するようにして、Dを2値分類から3値分類に変える (?)
Sから生成されたG(S) / Tから来たもの の分類
↓
Sから生成されたG(S) / Tから生成されたG(T) / Tから来たもの の分類
(顔写真から生成された似顔絵 / 似顔絵から生成された似顔絵 / 本物の似顔絵)
(順にclass=1/2/3とする)
に変える
このとき、

を最小にするD (Diはclass=iである確率) と
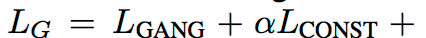
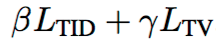
を最小にするgを求めれば良い
ここで、


(4)では、生成された似顔絵が,本物の似顔絵(class=3)である確率を最大化したい(Dを騙したい)
(5)は、(2)とおなじ
(6)では、似顔絵≒似顔絵から生成された似顔絵 にしたい。d2はMSEとか
(7)では、生成される画像をsmoothにするらしい(anisotropic total variation loss)
まとめると
結果
・MNISTとかもやってるけど省略 ・顔写真→似顔絵タスクの実験 ・関数fには、DeepFace使った ・DNNの詳細 > Network D takes 152 × 152 RGB images (either natural or scaled-up emoji) and consists of 6 blocks, each containing a convolution with stride 2, batch normalization, and a leaky ReLU with a parameter of 0.2. Network g maps f ’s 256D representations to 64×64 RGB images through a network with 5 blocks, each consisting of an upscaling convolution,batch-normalization and ReLU. Adding 1 × 1 convolution to each block resulted in lower LCONST training errors, and made g 9-layers deep. We set α = 100, β = 1, γ = 0.05 as the tradeoff hyperparameters within LG via validation. As expected, higher values of α resulted in better f- constancy, however introduced artifacts such as general noise or distortions.結果

左が顔写真、真ん中が人間が書いた似顔絵、右が提案手法が生成したもの
いい感じになった