~データ前処理に対する抵抗感を払しょくしてやる!~
はじめに
データの前処理までも自動でやってくれるPycaretというライブラリもありますが、やはり、ある程度のデータの前処理はできないとダメだから・・・とにかく使えそうな処理を記録することにしました。
実行条件など
・Google colabで実行
・Kaggleのタイタニックデータで実行
・※これ以外でも使えそうという処理はどんどん追加してゆきます
タイタニックのデータセットについて
以下サイト(Kaggle)の「train.csv」を使わせていただいた。
**タイタニックデータセットの項目と内容**
|項目|内容|
|:-----------|:------------------|
|PassengerId|乗客ユニークID|
|Survived|生存フラグ(0=死亡,1=生存)|
|Pclass|チケットクラス(1=上級,2=中級,3=下級)|
|Name|乗客名|
|Sex|性別(male=男性,female=女性)|
|Age|年齢|
|SibSp|同乗している兄弟,配偶者の数|
|parch|同乗している親,子供の数|
|ticket|チケット番号|
|fare|料金|
|cabin|客室番号|
|Embarked|出港地(C=Cherbourg,Q=Queenstown,S=Southampton)|
前処理してみよう!
1. ライブラリのインストールおよびインポート
以前もある記事で描いたが、使用するライブラリをいちいち検討するのは面倒なので、基本以下としています。乱暴ですいません。
pip install japanize-matplotlib
# Import required libraries
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
from scipy.stats import norm
2. データの読み込み
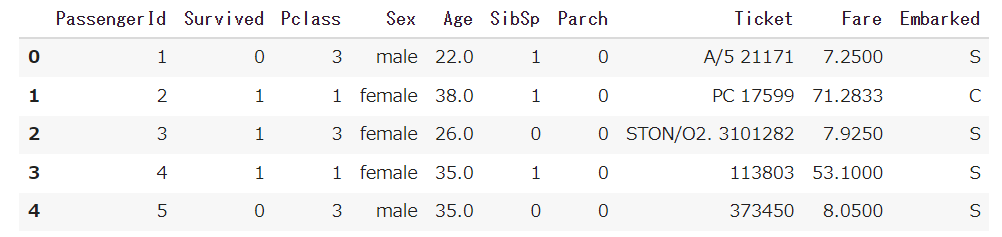
df=pd.read_csv('train.csv')
df.head()

3. 基礎データ確認
まず、データのカラム、欠損値有無、データ型を確認しました。
df.info()

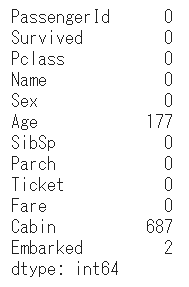
各カラムの欠損数も確認しました。
df.isnull().sum()
Age、Cabin、Embarkedには欠損値があり、何らかの処置が必要なことがわかります。
その他の基礎データ確認
df.dtypes
df.duplicated().any()
df.describe()
pd.set_option('display.max_rows', None)
df['列の名前'].value_counts()
4. データ確認
欠損値があったCabinはどのようなデータなのかについて見てみました。
df['Cabin'].value_counts()

Cabinの中身(データ)はバラバラですね。
一応グラフ化もしてみましたが、これから特徴や傾向をつかむことはむつかいように思います。
sns.countplot(y="Cabin", data=df)
df.head()


↑ こちらはPandas-Profilingでのグラフです。こちらの方がバラバラ感がよくわかります。
pd.scatter_matrix(df)
その他のデータ確認
df.astype('str').describe()
df[(df[‘列名1’] == ‘A’ ) & (df[’列名2‘]>123)]
# 列名1がA かつ 列名2が123以上の条件で抽出
# 第1引数:縦列、第2引数:横列、[margins=True:合計値カラムの表示]
pd.crosstab(df['列名A'], df['列名B'])
train_data =train[['Sex', 'Survived']].groupby(['Sex'])
train_data.describe()

# グラフでも確認
sns.countplot('Sex', data=train, hue='Survived')
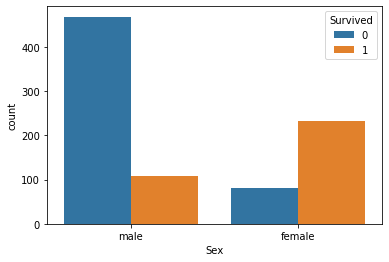
参考
ここではこれ以上データ確認については述べませんが、以下ライブラリが便利がと思います。
5. データ分析に関連しない列の削除
次に、カテゴリー化できないものや、データ分析に関連しないデータは列ごと削除しました。
ここでは、先ほどのCabinと、objectデータのName,Ticketは(データ分析には活かせそうにないので)列ごと削除することにしました。
# 特定列削除
df.drop("Cabin", axis = 1, inplace = True)
df.head()

# 特定列削除
df.drop("Name", axis = 1, inplace = True)
df.head()
# 特定列削除
df.drop("Name", axis = 1, inplace = True)
df.head()

ずいぶん、すっきりしました。
その他の削除
df = df.select_dtypes(exclude='object')
df_past = df_past.rename(columns={'Pclass': 'Class'})
6. 欠損値の処理
再度、データのカラム、欠損値有無、データ型を確認しました。
項目数は11→8となり、すこしスッキリしました。

次は、AgeとEmbarkedの欠損値処理を行うことにします。
まずはAgeです。ヒストグラムでこのデータの傾向をみてみます。一山の分布となっています。ピークはすこし左よりの分布となっているように思います。
sns.distplot(
df['Age'],bins=10, color='#123456',label='data',
kde_kws={'label': 'kde','color':'k'},
fit=norm,fit_kws={'label': 'norm','color':'red'},
rug=False
)
plt.legend()
plt.grid()
plt.show()

左よりの分布を考慮し、欠損値には「中央値」を補完しました。
df['Age'].fillna(df['Age'].median(), inplace=True)
再度、データのカラム、欠損値有無、データ型を確認してみます。 Ageの欠損値はなくなりました。
df.info()

次は、Embarkedです。まず傾向をグラフで見てみました。これは欠損値以外が表示されたものですが、S,C,Q の3パターンのでデータであることがわかります。
sns.countplot(y="Embarked", data=df)

Embarkedの欠損値処理は、もっとも多い「S」に補完しました。以下infoの通り、補完によって欠損値がなくなったことがわかります。
df["Embarked"] = df["Embarked"].fillna("S")
df.info()

他の欠損値処理について
実務では、中途半端に欠損値を補ったりせず、欠損データは削除することも多いでしょう。以下はそのような場合のコードです。
df = df.dropna(how='any')
# 別の方法
df.dropna(subset=[‘列名‘], axis=0, inplace=True) #axis=0(デフォルト)で行、inplace=Trueでdf変更反映
df = df[‘列名‘].replace(‘-‘,np.nan)
df.fillna(0)
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull = 0:
nonnull_list.append(col)
df.drop(nonnull_list, axis=1)
df.drop('列名', axis=1)
df.fillna(df.mean()) # 平均値で補完
df['Age'].fillna(df['Age'].median(), inplace=True) # 中央値で補完
df['Embarked'].fillna('S', inplace=True) # 'S'で補完
7. ラベルエンコーディング(カテゴリーデータの数値変換)
SexとEmbarkedはカテゴリーデータなので、ラベルエンコーディングを行いました。まずはSexです。以下のコードの実行でmale=0に、female=1となりました。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['Sex'])
df['Sex'] = le.transform(df['Sex'])
df.head()

つぎはEmbarkedです。以下のコードの実行でEmbarkedも0,1,2にエンコーディングできました。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df['Embarked'])
df['Embarked'] = le.transform(df['Embarked'])
df.head()

その他のエンコーディング
df['列の名前'] = df['列の名前'].replace('文字データA', 10). astype(float)
df['列の名前'].value_counts()
dic = {
'文字データA': 45
'文字データB': 75
'文字データC': 120}
df['列の名前'] = df['列の名前'].replace(dic). astype(float)
df['列の名前'].value_counts()
df["和暦"].value_counts().keys() [1].split("平成")[1].split("年")[0)
# 20
y_list = {}
for 1 in df["和暦"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
for 1 in df["和暦"].value_counts().keys():
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
for 1 in df["和暦"].value_counts().keys():
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list(i) = year
df("和暦") = df("和暦").replace(y_list)
"2020年第1四半期".replace("年第1四半期", ".25 ") #第一引数に置換元文字列、第二引数に置換先文字列を指定
year = {
"年第1四半期": ".25 ",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
# year = {k,j}
year_list = {}
for i in df[”取引時点"].value_counts().keys():
for k, j in year. items():
if k in i:
year_rep = i.replace(k, j)
year_list [i] = year_rep
df[”取引時点"] = df[”取引時点"].replace(year_list).astype(float)
df.info()
import collections
counter = collections.Counter(df['Ticket'].values)
count_dict = dict(counter.most_common())
encoded = df['Ticket'].map(lambda x: count_dict[x]).values
df['TicketID'] = encoded
print('エンコード結果: ', encoded)
df['Age']=df['Age'].astype(int)
df.head()
# 'size'を'XL','L','M' → 整数(1, 2, 3)に変換
size_mapping = {'XL': 3, 'L': 2, 'M': 1}
df['size'] = df['size'].map(size_mapping)
df.head()
pip install category_encoders
# Ordinal_Encode
import category_encoders as ce
# Eoncodeしたい列をリストで指定。もちろん複数指定可能。
list_cols = ['列A','列B','列C','列D']
# 序数をカテゴリに付与して変換
ce_oe = ce.OrdinalEncoder(cols=list_cols,handle_unknown='impute')
df_ce_ordinal = ce_oe.fit_transform(df)
df_ce_ordinal.head()
8. 新たな特徴量の生成
SibSpは、兄弟,配偶者の数。 Parchは、両親,子供の数 です。この2つの説明変数はいわば家族の数です。またこの2つ相関も高く、このまま分析に使うのはよくありませんので、足し合わせて新しい変数にしました。(これは「Kaggleスタートブック」に紹介されていた内容です)
df['FamilySize'] = df['Parch'] + df['SibSp'] + 1
sns.countplot(y='FamilySize', data = df, hue='Survived')
df.head()

これも「Kaggleスタートブック」に紹介されていた内容ですが、FamilySizeが1という方が大部分です。またグラフの通り、FamilySizeが1の方は生存率が低い傾向もみられ案す。このことからFamilySizeが1であるか否かを特徴として取り上げてもよさそうです、
df['IsAlone'] = 0
df.loc[df['FamilySize'] == 1, 'IsAlone'] = 1
df.head()

最後に、FamilySizeに統合したSibSpとParchのデータは列ごと削除しました。
df.drop("SibSp", axis = 1, inplace = True)
df.head()

df.drop("Parch", axis = 1, inplace = True)
df.head()

df.info()

df.isnull().sum()

これで欠損値もなくなり、前処理は無事に終了しました。
ここでは「PassengerId」は残していますが、これも削除して問題ないと思います。
参考:Nameから敬称を抽出し特徴量に
# Nameの確認
df = pd.read_csv('train.csv')
df['Name'].head()
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
Name: Name, dtype: object
# Nameを[family‗name,honorific.name]に区分(引数2はなくても実行されたがNone列含む4分割となった)
name_df = df["Name"].str.split("[,.]",2, expand=True)
# columnを設定
name_df.columns = ["family_name", "honorific", "name"]
name_df.head()

# 各列にstrip()を用いることで先頭と末尾の空白文字が削除される(念のため各列に適用)
name_df["family_name"] = name_df["family_name"].str.strip()
name_df["honorific"] = name_df["honorific"].str.strip()
name_df["name"] = name_df["name"].str.strip()
name_df.head()
# dfにname_dfを列結合
df = pd.concat([df, name_df], axis=1)
# グラフで確認する
sns.boxplot(x="honorific", y="Age", data=df)

# Mr、Miss、Mrs、Master以外の敬称はotherとして統合
df.loc[~((df ["honorific"] =="Mr")|(df [ "honorific"] =="Miss")|(df[ "honorific"] =="Mrs")|(df [ "honorific"] =="Master")),
"honorific"] = "other"
df.head()
pip install scikit-learn
from sklearn.preprocessing import LabelEncoder
# honorificをラベルエンコード
le = LabelEncoder()
le = le.fit(df ["honorific"])
df["honorific"] = le.transform(df["honorific"])
df.head()
sns.boxplot(x="honorific", y="Age", data=df)

私は実行していないが、年齢の欠損値を、敬称ごとの平均年齢で補完されている例があった。
敬称ごとの平均年齢を求め、年齢が欠損しているデータに敬称の平均年齢を補完。
※補完後、敬称ごとの平均年齢を求めたhonorific_Age は不要のため削除。
# 敬称ごとの平均年齢で年齢が欠損しているデータを穴埋め
honorific_age_mean = df [["honorific", "Age"]].groupby("honorific").mean().reset_index()
honorific_age_mean.columns = ["honorific", "honorific_Age" ]
df = pd. merge (df, honorific_age_nean,on="honorific", how="left")
df.loc [(df ["Age"].isnull()), "Age"] = df["honorific_Age"]
df = df.drop([ "honorific_Age"), axis=1)
その他の便利なコード記述
説明変数と目的変数の設定を一発で
FEATURES = df.columns[:-1]
TARGET = df.columns[-1]
X = df.loc[:, FEATURES]
y = df.loc[:, TARGET]
first_column = df.pop('列A')
df.insert(0,'列A',first_column)
df
最後に
前処理はとても億劫であったが、やってみたら・・・まぁやれなくないなという感じです。
これで完璧!といえるかどうかは別として、このあたりまで処理した後、Pycaret活用・・・といった流れの方が現実的なのかもしれません。
参考サイト
参考書籍