2022/08/03追記
- 欠損データを記号で識別しているケースがあり、この場合、設定した前処理では記号を「異常なobjectデータ」と認識し、nanとは異なるものとして処理してしまうため、前処理に記号識別した欠損データをnanに置換を追加。
2022/07/29追記
- 前処理の実施内容に関する図を追加。
2022/06/15追記
- ICE plot、SHAP(XGB)・ICE(RandomForest)実行時にモデル評価結果を追加。
2022/06/09追記
- irisデータセットのようなMultiデータ(目的変数が3分類以上)の場合のみコードを変更しないといけないことがわかりました。以下の3点です。
変更点
1.shap.summary_plot(shap_values, X_selected) → shap.summary_plot(shap_values[1], X_selected)
2.shap.dependence_plot(df3['col_names'][i], shap_values, X_selected) → shap.dependence_plot(df3['col_names'][i], shap_values[1], X_selected)
3.shap.force_plot(explainer.expected_value, shap_values, X_selected) → shap.force_plot(explainer.expected_value[1], shap_values[1], X_selected)
~ ↑↑ 前回記事 ↑↑ :~機械学習で 特徴量を絞って決定木を描くまでを自動化 してみる(問題解決に機械学習を活用:AutoEDA、Boruta-SHAP)〜 の続きです。
はじめに
実務で前回記事で紹介した内容を実務で適用したところ、早速いくつかの課題があり、以下の点を見直すことにしました。
- 現実データはゴミだらけ。。。前回の前処理では削除しすぎてしまうため、欠損値を残すことなどを含め、再考。
- Boruta-SHAPは、データが多いと処理に時間を要する。特徴量選択はBoruta に変更、SHAPの重要度とともにグラフ表示、Boruta-SHAP → Boruta + SHAP という感じ。SHAPのよさである特徴量と目的変数の関係把握も活かしたい。
この記事では、上記の課題に取り組もうと思います。
実行条件など
- Google colabで実行(※前回同様、いくつかのデータセットをLoadできるようにしています。)
-
実行コードは以下。

前処理
前回記事の内容を実務適用すべく、実務で取得したあるデータを確認したところ、「データに予想以上の乱れ(数字カラムへの文字データの混在、欠損値だらけ)」があり、いきなり詰まってしまいました。
確認したデータは、手動で入力されたものではなく、自動で取得されたものなのですが、ここまで乱れているとは思いませんでした。
「異常と思われるデータは削除する」こととしていましたが、ずいぶんデータを取り除くことになることになるなということとあわせて、平均値などで欠損値を補完したり、削除したりすることに、すこし抵抗感もわいてきました。
これは、分析するデータの性質にもよると思いますが、例えば、異常が生じた傾向を確認したいという場合、よくわからないからといって、削除や平均的な補完を行うと、異常を薄めてしまうのではないか? 異常は異常として扱うべきではないか?ということからです。
いろいろ悩んだ末、前処理は以下の方針で行うことにしました。

- 欠損値は、数値、カテゴリー共に「-1」に置換し、認識できるようにしておく。(ラベルエンコーディングは、0から 0,1,2とラベリングされるのでデフォルトは「-1」に。ただ置換する値は変えられるようにしておく。)
- 数字カラムに混在した文字データは「-99」に置換する。
- カテゴリーデータに混在する通常外のカテゴリーデータは自動処理は難しいので、割り切ってこれらもカテゴリー化の対象にする。
- 前処理は、先に「7割以上欠損やIDカラムの削除」を行い、次に 列を指定したうえで「16進数を10進数」を文字データとNA除いて変換、カテゴリーカラムを設定し、NA除いて「ラベルエンコーディング」、最後に「文字データを‐99、NAを-1に置換」という前処理実行後にデータの基本統計量や可視化(Dataprep)を実行することに。(余談:順序通り進めてもobjectが残ることがあったので、objectがあればfloat変換を追加)
- 前処理後データはcsvに出力する。一応、異常な文字データやNAを削除したデータもcsvに出力できるようにしておく。
やみくもに実行すると、文字データやNAを残したままでは処理できなかったり、文字データやNAもエンコーディングしてしまいますので、なかなか大変でした。
NAを残したまま、ラベルエンコーディングする方法は、以下を参考にさせていただきました。
また、この前処理~dtreeviz(決定木)までを一つの枠組みで実行するのは、すこし重たく感じますので、「前処理~可視化まで」と「Boruta~dtreeviz(決定木)」のipynbファイルを分けることにしました。
特徴量選定
前回実行したBoruta-Shapは、以下の利点がありました。
- 選択結果をグラフ表示してくれる
- 選択結果をデータフレームで出力してくれる
ただ、ちょっと処理に時間を要すのが難点でした。
そこで今回は、以下としました。
- Borutaを実行、その後、SHAPも実行し、SHAPによる特徴量重要度であるSHAP値をBoruta選択結果で層別してグラフ化する。
- 重要度の高い特徴量は、SHAPによる散布図も表示させる。(回帰データのみ)
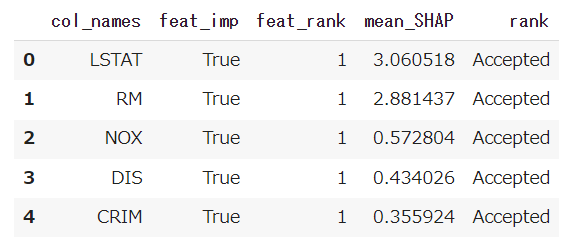
Borutaは、特徴量選択結果をsupport_ で示してくれます。意味のある特徴量はTrueを返してくれます。
また、ranking_では、意味のある特徴量=選択が1、暫定選択が2、3以降は選択対象外というように値を返してくれます。
この選択結果をデータフレームに格納し、これに特徴量のSHAP値を結合しました。(※実行結果は、Bostonデータセットです)
次に、SHAP値(mean_SHAP)をBorutaのranking(rank)で層別してグラフ化しました。
SHAP値は、np.arrayで出力されるのですが、回帰データの場合は[1×n]、2値分類データの場合は[2×n]、3分類データの場合は[3×n]。。。気がつくのに時間を要しましたが、何とかグラフ(plotly)に表示できました。(※実行結果は、Bostonデータセットです)
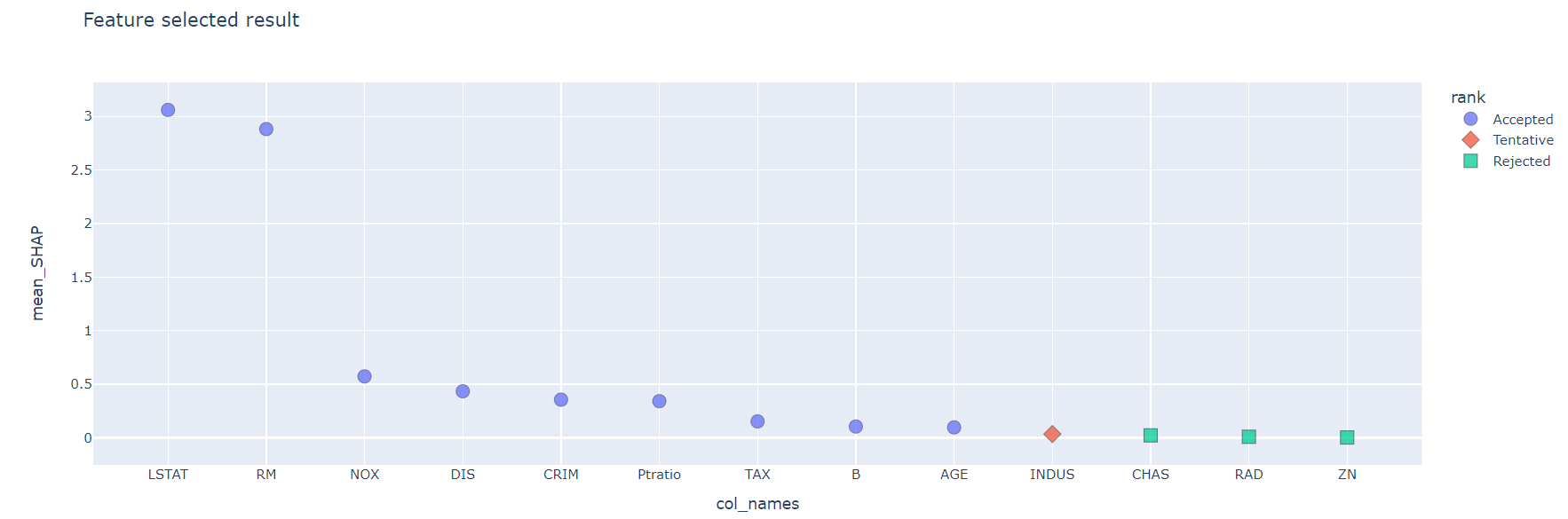
この特徴量重要度のグラフ化により、どの特徴量が重要で、どの特徴量が選択されたかが一目瞭然となります。
Acceptedが選択された特徴量。Bostonデータセットの場合、LSTAT、RMの重要度が高いことがわかります。
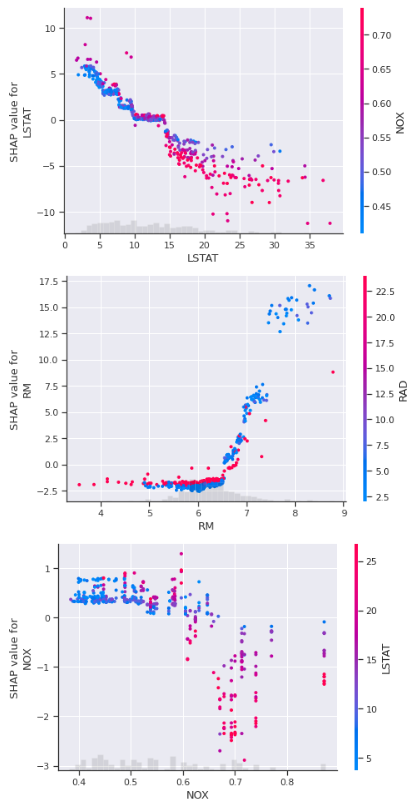
重要な特徴量を絞ることができたら、次に知りたいのは特徴量と目的変数の関係です。
SHAPは、モデルの予測結果に対する各特徴量の寄与=特徴量の増減が結果に与える影響を可視化することができますので、重要度が高い特徴量から順に散布図を自動表示させるようにしました。
先の特徴量重要度をグラフ化するまでの過程は、Boruta, SHAPともにramdomforestをモデルとして与えました。これはBorutaがramdomforestの特徴量重要度に基づいた変数選択手法となっているからです。(※ramdomforest以外で実行しておられる方もおられます)
ただ、SHAPによる特徴量と目的変数の各種可視化の実行においては、ramdomforestのままでは、回帰データはうまくいき、分類データではうまくいきませんでしたので、モデルをxgbとしました。
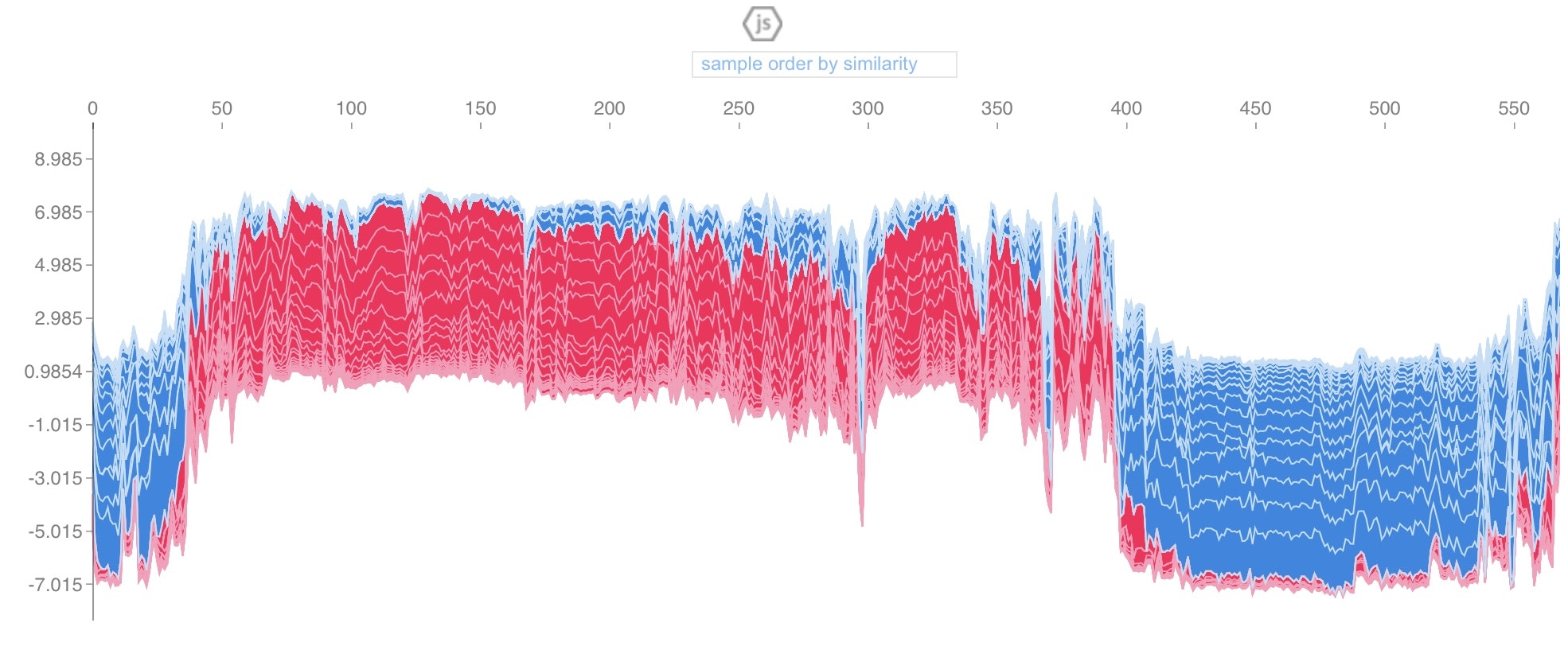
force plotも実装しました。
すべてのデータにおいて、各特徴量の影響がどの程度加算されたものであるか表現できるって、すごいです。(以下はbreast cancerデータセットで描画)
特徴量と目的変数の関係性
最後に、特徴量と目的変数の関係性を決定木で確認します。(こちらは前回と同様です)
決定木は、以下の方針としています。
- dtreevizを使用する。
- 回帰データでも分類データでも処理できるようにする。
- 決定木は階層が深いと可読しにくいので、木の深さを任意に変えられるようにする。
- 木の深さ等のパラメータの最適解を求めた決定木も描画する。
最後に
今回 実装したBoruta+SHAPは、前回のBoruta-SHAPよりも動作が軽快になりました。
あと、特徴量の値の増減が結果に与える影響が可視化できるSHAPの散布図はとてもいいです。
「この特徴量と目的変数には二次的な傾向がある」とか、「この特徴量は○○あたりに変化の臨界点がある」等といったことがわかるってのはすごいです。
これだけでもかなり傾向はつかめます。決定木との合わせ技で、より理解が進むように思いました。
ただ、SHAPは機械学習モデルの予測値を各特徴量に分解してくれるというものなので、モデルの精度もみながら冷静にバランスをもってというスタンスで臨む必要はあると思います。
参考