
はじめに
Auto_ViMLは、必要最小限の変数で高性能な解釈可能モデルを構築することができるAutoMLライブラリです。
実行可能な内容は、データクリーニング、相関の強い特徴量の自動削除、モデル構築、モデル評価の視覚化等、データを与えるだけで一連の手続きはおまかせというライブラリになっています。
この作者は、AutoViz というAutoEDAの作者でもあります。
AutoViz は、動作速度的にもビジュアル的にも優れており、あのPyCaretにも取り入れられているということで、Auto_ViML もよいに違いない!
本記事では、このAuto_ViML をGoogleColabで実行します。
いくつかのデータセットを読み込めるようにセットし、読込んだデータを訓練データとテストデータに分割してAuto_ViML に与えます。
その後、Auto_ViML を実行し、実行結果を確認します。
実行はノーコードです。いくつかの設定をドロップダウンとスライドバーで指定するだけです。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行
まず、AutoViMLをインストール

インストール後、以下が表示されますので[RESTART RUNTIME]をクリックします。

「1.インストール」にて他のライブラリもインストールします。

1.読み込むデータセットとデータセットのタイプを設定します

2.データを読み込みます。
以下は、BostonHousingデータセット(回帰)を読み込んだ際の表示です
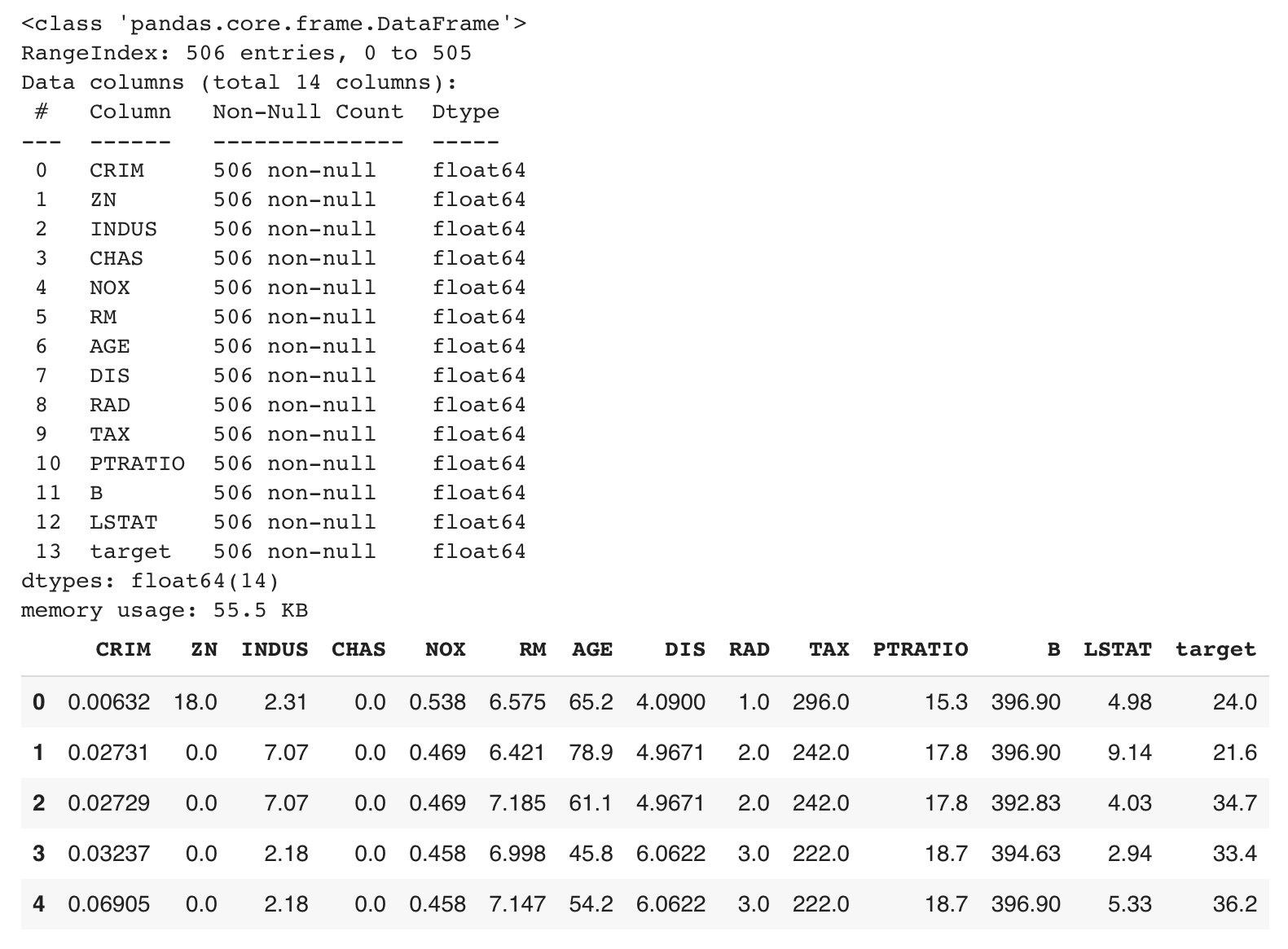
3.データクリーニングを実行します。
実装しているのは必要最小限のクリーニング項目だけです。Auto_ViML はデータ前処理も実行してくれますので、スルーしても大丈夫です。(BostonHousingデータセットは、データ型がすべて数値(float64)で欠損値のない完全データなので、このデータクリーニングはスルーしています。)
- 実装しているクリーニング項目は以下です
- 1.記号識別され欠損データをN.A.(NaN)に置換
- 2.不要なデータ項目の削除
- 3.欠損データを含む行を削除
- 4.カテゴリーデータ項目を Labelエンコード
- 5.すべての Obeject_col を Label encord
- 6.データ項目名を英訳
4.AutoViML

- hyper_param は、RandomSearch (RS) またはGrid Search (GS)の設定です。デフォルトはRSです。
- verbose は、0/1/2のどれかを選択。0— Limited Output; 1- More Charts; 2- Lot of charts and output です。
実行すると、以下の情報が順に示されました。(以下はBostonHousingデータセットで実行した結果です。分類データを適用した場合は混同行列など、分類データにみあったグラフが表示されます。)
DATA SET ANALYSIS では、訓練データ・テストデータ数、認識した目的変数名が示されました。
また、「訓練前にデータはシャッフルせず、ハイパーパラメーターチューニングはランダムサーチを適用した」とも示されました。
############## D A T A S E T A N A L Y S I S #######################
Training Set Shape = (379, 14)
Training Set Memory Usage = 0.04 MB
Test Set Shape = (127, 13)
Test Set Memory Usage = 0.01 MB
Single_Label Target: ['target']
No shuffling of data set before training...
Using RandomizedSearchCV for Hyper Parameter Tuning. This is 3X faster than GridSearchCV...
CLASSIFYING VARIABLESでは、データ項目数や各データ項目のデータ型、ユニーク数、欠損値数が示されます。 また、最後に「データセットにIDまたは低情報量の変数が見つからなかったため、変数を削除せず」と表示されました。明らかに不要なデータ項目は削除してくれるようです。
#######################################################################################
######################## C L A S S I F Y I N G V A R I A B L E S ####################
#######################################################################################
Classifying variables in data set...
Printing upto 30 columns max in each category:
Numeric Columns : ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'RAD']
Integer-Categorical Columns: []
String-Categorical Columns: []
Factor-Categorical Columns: []
String-Boolean Columns: []
Numeric-Boolean Columns: ['CHAS']
Discrete String Columns: []
NLP text Columns: []
Date Time Columns: []
ID Columns: []
Columns that will not be considered in modeling: []
13 Predictors classified...
Data Set Shape: 379 rows, 13 cols
Additional details on columns:
* CRIM: 0 missing, 377 uniques, most common: {14.3337: 2, 0.01501: 2}
* ZN: 0 missing, 25 uniques, most common: {0.0: 276, 20.0: 16}
* INDUS: 0 missing, 71 uniques, most common: {18.1: 99, 19.58: 22}
* CHAS: 0 missing, 2 uniques, most common: {0.0: 348, 1.0: 31}
* NOX: 0 missing, 74 uniques, most common: {0.538: 18, 0.713: 16}
* RM: 0 missing, 344 uniques, most common: {6.229: 3, 5.713: 3}
* AGE: 0 missing, 285 uniques, most common: {100.0: 34, 96.0: 4}
* DIS: 0 missing, 321 uniques, most common: {3.4952: 5, 5.4007: 4}
* RAD: 0 missing, 9 uniques, most common: {24.0: 99, 5.0: 83}
* TAX: 0 missing, 62 uniques, most common: {666.0: 99, 307.0: 30}
* PTRATIO: 0 missing, 46 uniques, most common: {20.2: 105, 14.7: 24}
* B: 0 missing, 269 uniques, most common: {396.9: 91, 395.24: 3}
* LSTAT: 0 missing, 348 uniques, most common: {6.36: 3, 8.05: 3}
--------------------------------------------------------------------
No variables removed since no ID or low-information variables found in data set
Number of Processors on this device = 1
CPU available
GPU active on this device
DATA PREPARATION AND CLEANINGでは、「トレーニングデータセットに欠損値なし、テストデータに欠損値なし... 訓練データとテストデータのラベルエンコーディングと欠損値補完完了...回帰問題:ハイパーパラメータをmaeで最適化」と表示されました。
##############################################################################
D A T A P R E P A R A T I O N AND C L E A N I N G
##############################################################################
No Missing Values in train data set
Test data has no missing values. Continuing...
Completed Label Encoding and Filling of Missing Values for Train and Test Data
Regression problem: hyperparameters are being optimized for mae
ADDING POLYNOMIAL & INTERACTIONSでは、
交互作用変数と二乗変数の両方をデータ項目として追加する前と後における評価スコアの比較が行われ、最後に追加されたデータ項目が示されました。
##############################################################################
######## A D D I N G P O L Y N O M I A L & I N T E R A C T I O N S ###
##############################################################################
Adding Both Interaction and Squared Variables. This may result in Overfitting!
Building Inital Model with given variables...
Model Report :
Number of Variables = 12
CV RMSE Score : 4.994 +/- 0.7402 | Min = 4.081 | Max = 5.928
Successfully transformed x-variables into text-variables after Polynomial transformations
Building Comparison Model with only Poly and Interaction variables...
Model Report :
Number of Variables = 78
CV RMSE Score : 4.203 +/- 0.9263 | Min = 3.342 | Max = 5.918
Time Taken: 0 (in seconds)
Initially adding 8 variable(s) due to Add_Poly = 3 setting
Added variables: ['NOX RM', 'NOX DIS', 'NOX LSTAT', 'INDUS NOX', 'RM^2', 'CRIM NOX', 'NOX PTRATIO', 'NOX^2']
Intxn and Poly Vars are: ['NOX RM', 'NOX DIS', 'NOX LSTAT', 'INDUS NOX', 'RM^2', 'CRIM NOX', 'NOX PTRATIO', 'NOX^2']
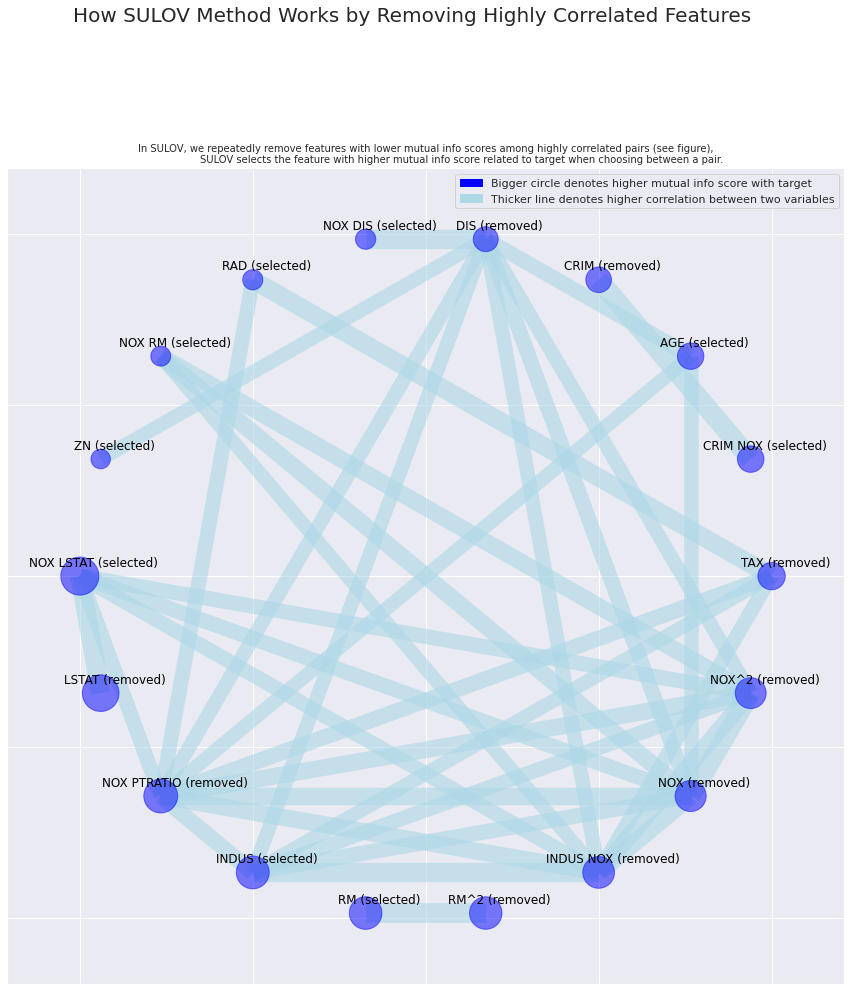
SULOVでは、データ項目間の相関関係を確認し、高い相関関係にあるデータ項目を削除した旨の内容が示されました。下の図は、データ項目間の相関関係とデータ項目選択の結果です。サークル上にデータ項目が配置され、サークルの大きさで目的変数との相関の強さ、データ項目間の線の太さで相関の強さが表現され、データ項目表記の横に記載された(selected)もしくは(removed)が変数選択結果となっています。わかりやすいですね。
#######################################################################################
SULOV: Searching for Uncorrelated List Of Variables in 20 features
#######################################################################################
there are no null values in dataset...
Removing (9) highly correlated variables:
['CRIM', 'NOX', 'DIS', 'TAX', 'LSTAT', 'INDUS NOX', 'RM^2', 'NOX PTRATIO', 'NOX^2']
Following (11) vars selected: ['PTRATIO', 'B', 'NOX LSTAT', 'INDUS', 'RM', 'CRIM NOX', 'AGE', 'NOX DIS', 'RAD', 'NOX RM', 'ZN']

FEATURE SELECTION BY XGBOOSTでは、XGBOOST による特徴量重要度を使った重要なデータ項目の選択結果が示されました。
###############################################################################
####### F E A T U R E S E L E C T I O N BY X G B O O S T ########
###############################################################################
Current number of predictors = 12
Finding Important Features using Boosted Trees algorithm...
using 12 variables...
using 10 variables...
using 8 variables...
using 6 variables...
using 4 variables...
using 2 variables...
Found 12 important features
Performing limited feature engineering for binning, add_poly and KMeans_Featurizer flags ...
Train CV Split completed with TRAIN rows = 341 , CV rows = 38
Binning_Flag set to False or there are no float vars in data set to be binned
KMeans_Featurizer set to False or there are no float variables in data
Skipping MinMax scaling since perform_scaling flag is set to False
CatBoost MODEL TRAINING では、CatBoostによる学習プログレスと結果が示されました。
結果は、単一モデルとアンサンプルモデルの2つです。
このデータセットでは、単一モデルの方がアンサンブルモデルより優れているという結果でした。
#################################################################################
######## CatBoost M O D E L T R A I N I N G ##########
#################################################################################
Rows in Train data set = 341
Features in Train data set = 12
Rows in held-out data set = 38
Finding Best Model and Hyper Parameters for CatBoost model...
CPU Count = 2 in this device
Using CatBoost Model, Estimated Training time = 0.026 mins
Learning rate set to 0.022004
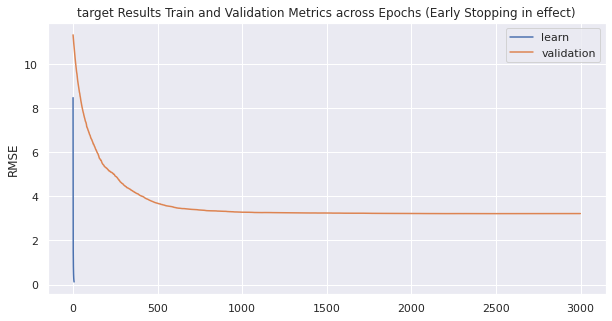
0: learn: 8.4770990 test: 11.3264908 best: 11.3264908 (0) total: 23.4ms remaining: 1m 10s
Warning: Overfitting detector is active, thus evaluation metric is calculated on every iteration. 'metric_period' is ignored for evaluation metric.
500: learn: 1.5338343 test: 3.6926292 best: 3.6926292 (500) total: 1.16s remaining: 5.81s
1000: learn: 0.8147991 test: 3.2828316 best: 3.2827886 (999) total: 2.22s remaining: 4.44s
1500: learn: 0.4738786 test: 3.2464106 best: 3.2449026 (1453) total: 3.29s remaining: 3.28s
2000: learn: 0.2876182 test: 3.2224525 best: 3.2220387 (1989) total: 4.39s remaining: 2.19s
2500: learn: 0.1829021 test: 3.2186669 best: 3.2177274 (2446) total: 5.43s remaining: 1.08s
2999: learn: 0.1198048 test: 3.2211151 best: 3.2176374 (2521) total: 6.47s remaining: 0us
bestTest = 3.217637388
bestIteration = 2521
Shrink model to first 2522 iterations.
Actual training time (in seconds): 7
########### Single_Label M O D E L R E S U L T S #################
5-fold Cross Validation RMSE Score = 3.2176
CatBoost Best Parameters for Model: Iterations = 2521, learning_rate = 0.02
########################################################
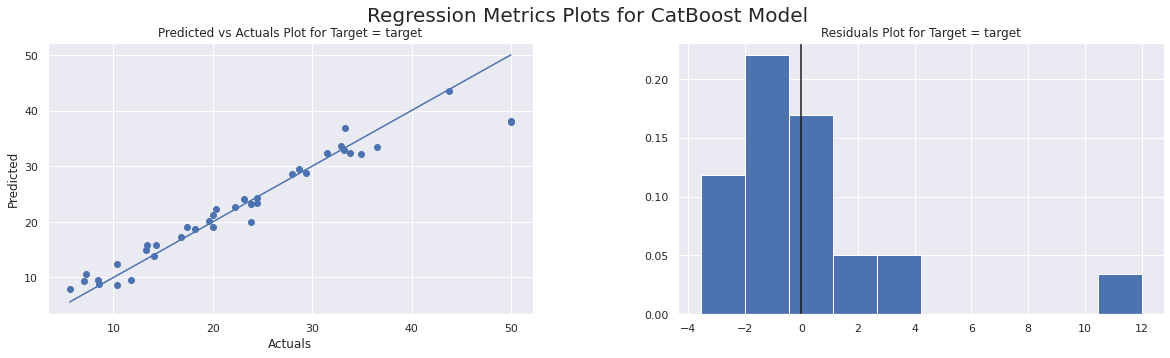
CatBoost Model Prediction Results on Held Out CV Data Set:
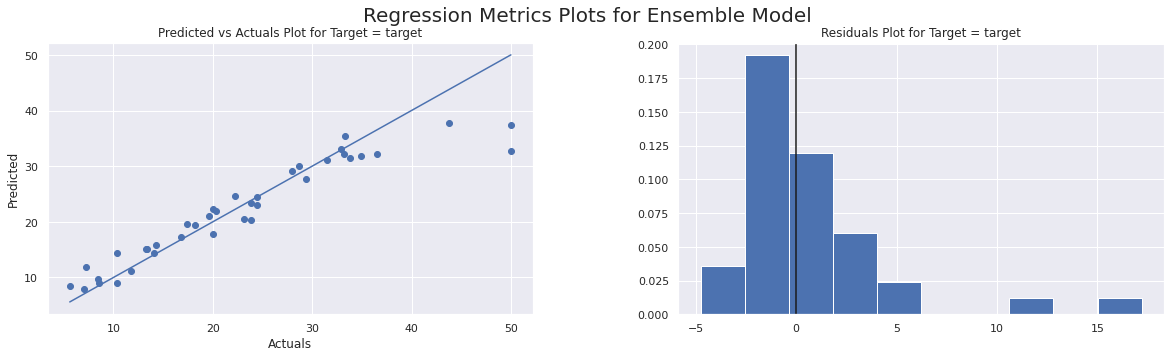
Regression Plots completed in 0.042 seconds
MAE = 1.9624
MAPE = 10% (MAPE will be very high when zeros in actuals)
RMSE = 3.2176
Normalized MAE (as % std dev of Actuals) = 17%
Normalized RMSE (% of Std Dev of Actuals) = 28%
################# E N S E M B L E M O D E L ##################
Time taken = 1 seconds
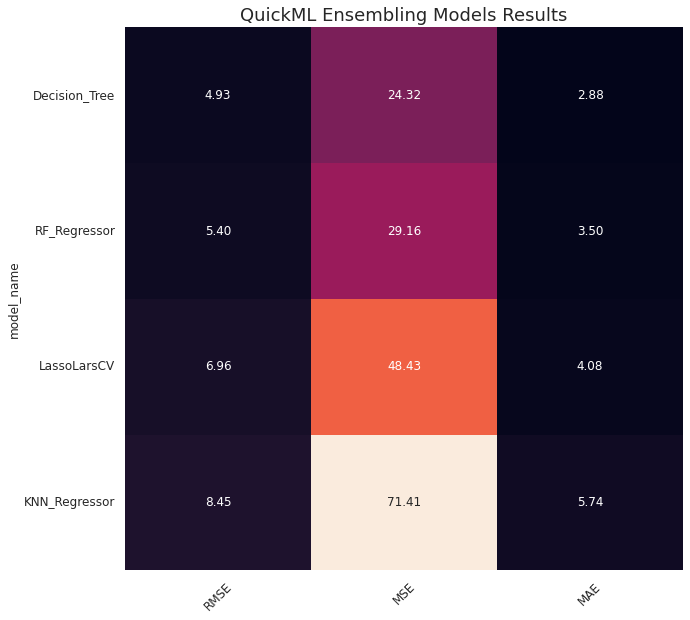
Based on trying multiple models, Best type of algorithm for this data set is Decision_Tree
Displaying results of weighted average ensemble of 5 regressors
#############################################################################
Regression Plots completed in 0.058 seconds
MAE = 2.5585
MAPE = 13% (MAPE will be very high when zeros in actuals)
RMSE = 4.1308
Normalized MAE (as % std dev of Actuals) = 22%
Normalized RMSE (% of Std Dev of Actuals) = 36%
After multiple models, Ensemble Model Results:
RMSE Score = 4.13080
#############################################################################
Single Model is better than Ensembling Models for this data set.
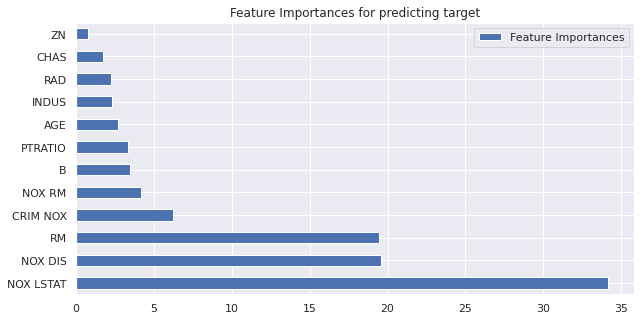
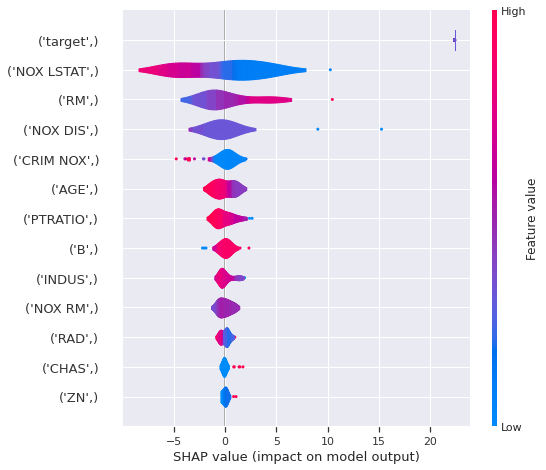
FINALIZING MODEL ON FULL TRAINでは、最後に特徴量重要度とSHAP値のグラフと予測結果保存先が示されました。
###########################################################################
F I N A L I Z I N G M O D E L O N F U L L T R A I N
###########################################################################
0: learn: 8.8038064 total: 2.7ms remaining: 6.8s
500: learn: 1.5122172 total: 1.05s remaining: 4.23s
1000: learn: 0.8511944 total: 2.1s remaining: 3.18s
1500: learn: 0.5165805 total: 3.13s remaining: 2.12s
2000: learn: 0.3305809 total: 4.19s remaining: 1.09s
2500: learn: 0.2199522 total: 5.22s remaining: 41.8ms
2520: learn: 0.2164102 total: 5.3s remaining: 0us
Actual Training time taken in seconds = 5
Training of models completed. Now starting predictions on test data...
Calculating weighted average ensemble of 5 regressors
Completed Ensemble predictions on held out data
Plotting Feature Importances to explain the output of model
Trying to plot SHAP values if SHAP is installed in this machine...
############### P R E D I C T I O N O N T E S T C O M P L E T E D #################
Time taken thus far (in seconds) = 22
Writing Output files to disk...
Saving predictions to ./target/target_Regression_test_modified.csv
Saving predictions to ./target/target_Regression_submission.csv
Saving predictions to ./target/target_Regression_train_modified.csv
############### C O M P L E T E D ################
Time Taken in mins = 0.4 for the Entire Process
5.モデル評価・予測
まず、保存されたテストデータ予測 fileを確認します。異なるデータセットで複数回実行した場合、file_listは複数に及びますので、以下のようにfile_listを表示させています。

BostonHousingデータセットでのモデル評価の実行結果は以下の通りです。実行前に先に確認したfile_list No.を指定するようにしています。(これはsklearnライブラリを利用して描いたものです。)
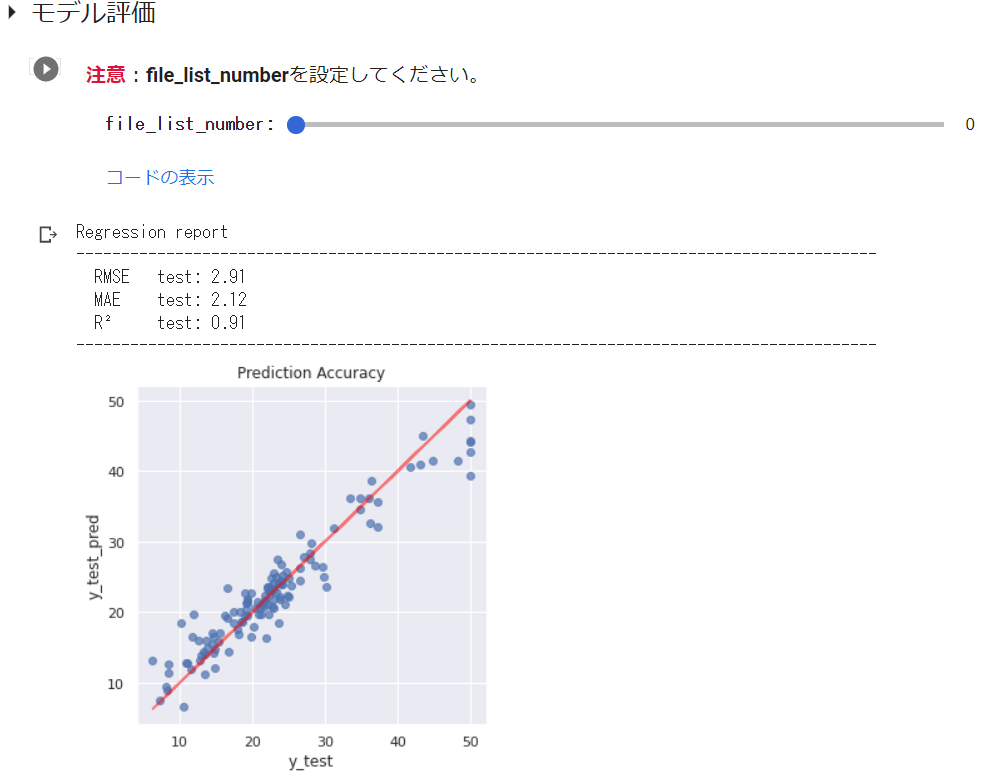
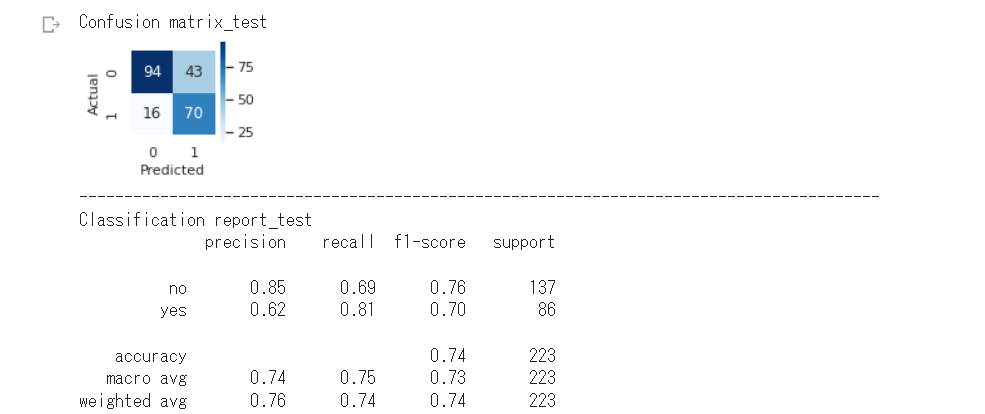
分類データで実行した場合は、以下のように混同行列とClassificationReportを表示します。
これは、datasetでTitanic(seaborn):binary を選択して実行した結果です。このデータには文字列や欠損値が混在しています。あらかじめ実装した前処理(データクリーニング)は実行せず、すべてAutoViMLに任せています。
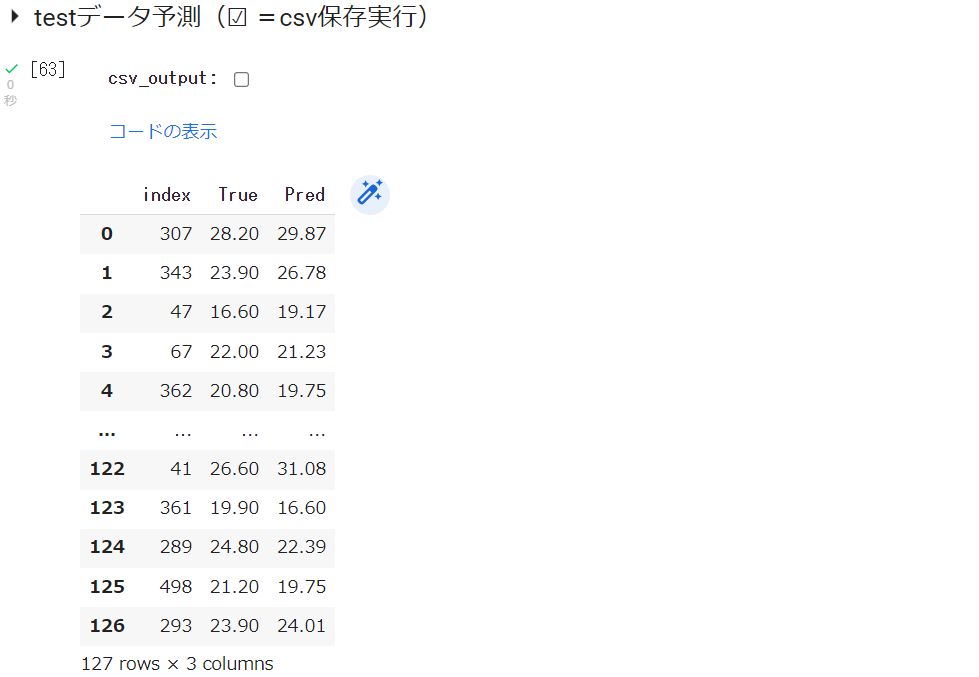
testデータ予測値
最適モデルにtestデータの特徴量Xを与えた時の目的変数yの値をpred、実際の値をtrueとし、データフレームに格納して表示させています。☑︎で、このデータをcsv保存できます。
最後に
この記事では、Boston(回帰データ)とTitanic(分類データ)でAutoViMLを実行しました。
訓練データとテストデータの分割は行いましたが、あとは完全にAutoViMLまかせです。
同じデータで、前々回の記事ではTPOT、前回記事ではAutoGlounを適用しました。
スコアは、AutoGloun > TPOT ≒ AutoViML でした。
AutoViML は、AutoGloun同様、前処理もフルでお任せできます。
視覚化は、AutoViML が最も充実しています。
また、動作速度は、前処理、データ項目選択、アンサンブル学習までこなしているとは思えない速さです。
AutoMLライブラリはいろいろあって悩みますが、視覚化と実行速度重視ならAutoViMLですね。
実行コード
AutoViMLインストール
!pip install autoviml
ライブラリのインストール
!pip install googletrans==4.0.0-rc1 --quiet
#matplotlib日本語化
!pip install japanize-matplotlib
import japanize_matplotlib
データセット読込み
データセットとデータセットタイプ(分類か回帰)選択のフォームセット
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset_type = 'Regression' #@param ["Classification", "Regression"]
dataset = 'Boston_housing :regression' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Titanic(seaborn) :binary', 'Iris :classification', 'Loan_prediction :binary','wine :classification', 'Occupancy_detection :binary', 'Upload']
データセット読み込み→データセットのインフォと先頭5行表示
#@title Load dataset
#ライブラリインポート
import numpy as np
import pandas as pd #データを効率的に扱うライブラリ
import seaborn as sns #視覚化ライブラリ
import warnings #警告を表示させないライブラリ
warnings.simplefilter('ignore')
'''
dataset(ドロップダウンメニュー)で選択したデータセットを読込み、データフレーム(df)に格納。
目的変数は、データフレームの最終列とし、FEATURES、TARGET、X、yを指定した後、データフレーム
に関する情報と先頭5列を表示。
任意のcsvデータを読込む場合は、datasetで'Upload'を選択。
'''
#任意のcsvデータ読込み及びデータフレーム格納、
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
#Diabetes データセットの読込み及びデータフレーム格納、
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns = diabetes.feature_names)
df['target'] = diabetes.target
#Breast_cancer データセットの読込み及びデータフレーム格納、
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names)
#df['target'] = breast_cancer.target #目的変数をカテゴリー数値とする時
df['target'] = breast_cancer.target_names[breast_cancer.target]
#Titanic データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
#目的変数 Survived をデータフレーム最終列に移動
X = df.drop(['Survived'], axis=1)
y = df['Survived']
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#Titanic(seaborn) データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
#重複データをカットし、目的変数 alive をデータフレーム最終列に移動
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1)
y = df['alive'] #目的変数データ
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#iris データセットの読込み及びデータフレーム格納、
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
#df['target'] = iris.target #目的変数をカテゴリー数値とする時
df['target'] = iris.target_names[iris.target]
#wine データセットの読込み及びデータフレーム格納、
elif dataset == "wine :classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
#df['target'] = wine.target #目的変数をカテゴリー数値とする時
df['target'] = wine.target_names[wine.target]
#Loan_prediction データセットの読込み及びデータフレーム格納、
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
#Occupancy_detection データセットの読込み及びデータフレーム格納、
elif dataset =='Occupancy_detection :binary':
data_url = 'https://raw.githubusercontent.com/hima2b4/Auto_Profiling/main/Occupancy-detection-datatest.csv'
df = pd.read_csv(data_url)
df['date'] = pd.to_datetime(df['date']) #[date]のデータ型をdatetime型に変更
#Boston データセットの読込み及びデータフレーム格納
else:
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
df['target'] = boston.target
#データフレーム表示
df.info(verbose=True) #データフレーム情報表示(verbose=Trueで表示数制限カット)
df.head() #データフレーム先頭5行表示
データクリーニング
AutoViMLは、前処理も実行してくれますので、データクリーニングに関するコードは実質なくても大丈夫です。
不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@title 不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@markdown **<font color= "Crimson">注意</font>:Drop_label_is(カラムを指定して削除)の記載は <u> ' ID ' , ' Age ' </u> などとしてください。**</font>
Drop_label_is = 'sibsp', 'parch'#@param {type:"raw"}
try:
if Drop_label_is is not "":
Drop_label_is = pd.Series(Drop_label_is)
print('-----------------------------------------------------------------------------------------')
print("Drop of specified column:", Drop_label_is.values)
df.drop(columns=list(Drop_label_is),axis=1,inplace=True)
else:
print('※削除カラムの指定なし→処理スキップ')
except:
print("※正常に処理されませんでした。入力に誤りがないか確認してください。")
#データの7割以上が欠損値のカラムを削除(☑ =実行)
Over_70percent_missing_value_is_drop = True #@param {type:"boolean"}
#各列ごとに、7割欠損がある列を削除
if Over_70percent_missing_value_is_drop == True:
for col in df.columns:
nans = df[col].isnull().sum() # nanになっている行数をカウント
# nan行数を全行数で割り、7割欠損している列をDrop
if nans / len(df) > 0.7:
# 7割欠損列を削除
print('-----------------------------------------------------------------------------------------')
print("Drop of missing 70% column:", col)
df.drop(col, axis=1, inplace=True)
print('-----------------------------------------------------------------------------------------')
df.head()
欠損データを含む行を削除(☑ =実行)
#@title 欠損データを含む行を削除(☑ =実行)
Null_Drop = True #@param {type:"boolean"}
if Null_Drop == True:
df = df.dropna(how='any')
df.head()
カテゴリーデータ項目を Labelエンコード(対象:Dtype が int64, float64 以外のデータ項目)
#@title カテゴリーデータ項目を Labelエンコード(**対象:Dtype が int64, float64 以外のデータ項目**)
#@markdown **<font color= "Crimson">注意</font>:指定は <u> ' ID ' , ' Age ' , </u> などとしてください。**
Object_label_to_encode_is = '', '', '' #@param {type:"raw"}
Object_label_to_encode_is = pd.Series(Object_label_to_encode_is)
from sklearn.preprocessing import LabelEncoder
encoders = dict()
try:
for i in Object_label_to_encode_is:
if Object_label_to_encode_is is not "":
series = df[i]
le = LabelEncoder()
df[i] = pd.Series(
le.fit_transform(series[series.notnull()]),
index=series[series.notnull()].index
)
encoders[i] = le
print('-----------------------------------------------------------------------------------------')
print('[エンコードカラム]:',i)
le_name_mapping = dict(zip(le.classes_, le.transform(le.classes_)))
print(le_name_mapping)
else:
print('skip')
except:
print("※正常に処理されなかった場合は入力に誤りがないか確認してください。")
print('-----------------------------------------------------------------------------------------')
df.head()
すべての Obeject_col を Label encord(☑ =実行)
#@title すべての Obeject_col を Label encord(☑ =実行)
Encord_all_object_label = True #@param {type:"boolean"}
from sklearn.preprocessing import LabelEncoder
if Encord_all_object_label == True:
le = LabelEncoder()
for col in df.columns:
if df[col].dtype == 'object':
df[col] = le.fit_transform(df[col].astype(str))
print('-----------------------------------------------------------------------------------------')
print(col)
print(le.classes_, "= [0, 1, 2...]" )
# else:
# print(col,':エンコードしない→処理スキップ')
print('-----------------------------------------------------------------------------------------')
df.head()
データ項目名を英訳(☑ =実行)
#@title データ項目名を英訳(☑ =実行)
Column_English_translation = False #@param {type:"boolean"}
from googletrans import Translator
if Column_English_translation == True:
eng_columns = {}
columns = df.columns
translator = Translator()
for column in columns:
eng_column = translator.translate(column).text
eng_column = eng_column.replace(' ', '_')
eng_columns[column] = eng_column
df.rename(columns=eng_columns, inplace=True)
print('-----------------------------------------------------------------------------------------')
print('[カラム名_翻訳結果(翻訳しない場合も表示)]')
print('-----------------------------------------------------------------------------------------')
df.head(0)
AutoViML
AutoViML実行
#@title **AutoViML実行**
#@markdown **<font color= "Crimson">注意</font>: hyper_param はRS/GS(ランダムサーチ/グリッドサーチ)選択|verbose は0/1/2選択(0- Limited Output; 1- More Charts; 2- Lot of charts and output)**</font>
hyper_param = 'RS' #@param ['RS', 'GS']
verbose = 1 #@param {type:"slider", min:0, max:2, step:1}
from autoviml.Auto_ViML import Auto_ViML
#FEATURES、TARGET、X、yを指定
FEATURES = df.columns[:-1] #説明変数のデータ項目を指定
TARGET = df.columns[-1] #目的変数のデータ項目を指定
X = df.loc[:, FEATURES] #FEATURESのすべてのデータをXに格納
y = df.loc[:, TARGET] #TARGETのすべてのデータをyに格納
#testとtrainを分割
from sklearn.model_selection import train_test_split
if dataset_type == 'Classification':
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, stratify = y)
else:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, test_size=0.25)
#訓練データとテストデータ準備
train_data = pd.concat([X_train, y_train], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
test_data = test_data.iloc[:,:-1] #testデータの目的変数削除
#AutoViML実行
model,features,train_modified,test_modified = Auto_ViML(
train = train_data,
target = TARGET,
test = test_data,
sample_submission='',
hyper_param='RS',
feature_reduction=True,
scoring_parameter='',
Boosting_Flag='CatBoost',
KMeans_Featurizer=False,
Add_Poly=3,
Stacking_Flag=False,
Binning_Flag=False,
Imbalanced_Flag=False,
verbose=2,
)
モデル評価
#@title testデータ予測 file_list の表示
#@markdown ※予測結果fileは、**/content/目的変数名/目的変数名_データタイプ_submission.csv** です。該当するfile_list No.を確認してください。</font>
import glob
file_list =[]
print('file_list')
print('-----------------------------------------------------------------------------------------')
print('No. : file path')
for i,name in enumerate(glob.glob('/content/*/*submission.csv')):
print(i,' :',name)
file_list.append(name)
print('-----------------------------------------------------------------------------------------')
#@title モデル評価
#@markdown **<font color= "Crimson">注意</font>**:**file_list_number**を設定してください。</font>
file_list_number = 1 #@param {type:"slider", min:0, max:5, step:1}
filePath = file_list[file_list_number]
#指標関連ライブラリインストール
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import f1_score #F1スコア
from sklearn.metrics import confusion_matrix #混同行列
from sklearn.metrics import classification_report #classification report
import matplotlib.pyplot as plt
pred = pd.read_csv(filePath)
y_test_pred = pd.read_csv(filePath)
if dataset_type == 'Classification':
print('Confusion matrix_test')
#混同行列
sns.set(rc = {'figure.figsize':(1.5,1.5)})
sns.heatmap(confusion_matrix(y_test,y_test_pred),
square=True, cbar=True, annot=True, cmap='Blues',fmt='g')
plt.xlabel('Predicted', fontsize=11)
plt.ylabel('Actual', fontsize=11)
plt.show()
print('-----------------------------------------------------------------------------------------')
print('Classification report_test')
print(classification_report(y_true=y_test, y_pred=y_test_pred))
else:
print('Regression report')
print('-----------------------------------------------------------------------------------------')
print(' RMSE\t test: %.2f' % (
mean_squared_error(y_test, y_test_pred, squared=False)))
print(' MAE\t test: %.2f' % (
mean_absolute_error(y_test, y_test_pred)))
print(' R²\t test: %.2f' % (
r2_score(y_test, y_test_pred) # テスト
))
print('-----------------------------------------------------------------------------------------')
plt.figure(figsize = (5,5))
plt.title('Prediction Accuracy')
ax = plt.subplot(111)
ax.scatter(y_test, y_test_pred,alpha=0.7)
ax.set_xlabel('y_test')
ax.set_ylabel('y_test_pred')
ax.plot(y_test,y_test,color='red',alpha =0.5)
plt.show()
testデータ予測
#@title testデータ予測(☑ =csv保存実行)
csv_output = False #@param {type:"boolean"}
pred = pd.read_csv(filePath)
y_test_ = y_test.reset_index()
col_name = ['index','True','Pred']
result=pd.concat([y_test_,pred],axis=1)
result.columns = col_name
#csv出力
if csv_output == True:
result.to_csv('pred_test_data.csv',encoding='utf_8_sig',index=False)
from google.colab import files
files.download('pred_test_data.csv')
result