2022/08/22:
t-SNEのコードにperplexity未反映、UMAPのコードにn_neighborsが未反映でした。
これらを反映し、値を可変することである程度のクラスタリングができました。
PCAは以前の記事のままとしていますが、t-SNEとUMAPは上記をコードに追加するとともにグラフをmatplotlib⇒Plotlyに変更しました。
- t-SNEとUMAPに適用したデータ ⇒ 再エネに関するtweet
- PCAに適用したデータ ⇒ 「学問ノススメ(本文抽出+ノイズ除去済)」
はじめに
自然言語を扱うのは、前々々回から数えて4回目になります。
前々々回は「ワードクラウド」、「TF-IDFでもワードクラウド」が前々回、前回は「自然言語が可視化できるnlplot」というライブラリを使用しました。
今回は word2vec を実行してみました。
word2vec の word は単語、vec はベクトルということで、なんと、単語をベクトルで表現することができるんですね。これ。
よく**『「王様」から「男性」を引いて「女性」を足すと「女王」になる』**と喩えられるようですが、これぞ単語のベクトル化のなせる技(足し算・引き算ができる)なのでしょう。
また、単語同士のベクトルが近ければ類似語と解釈できることにもなるので、「似てる」、「ちょっと似てる」、「ぜんぜん似てない」。。。等、グループわけもできることになります。
グループわけは 2次元がわかりやすいので、文章から抽出した単語のベクトルを計算、「主成分分析(PCA)」と「T-SNE」で 2次元化し、グラフにプロットしたというのが今回の記事の内容になります。
文章を読み込み、前処理、特定の品詞の抽出。。。という過程は、前回とまったく同じなので、今回実行した word2vec のコードは、前回のコードに後付けしただけです。(なので、コード記述は後付け分のみとしています。)
実行条件など
- Google colabで実行
- **青空文庫の「学問ノススメ」**で実行
※コードは任意データでの実行を意図していますので、「こころ」限定ではありません。 - 前回の記事の「ライブラリのインストール」、「テキストファイル & ストップワード指定」、「モジュールの準備」をそのまま使用しています。この記事では前回の記事のコードは掲載していませんのでご注意ください。(※前回の記事のコードを丸ごと使っても問題ありません)
word2vec実行
from gensim.models import word2vec
# size : 中間層のニューロン数・数値に応じて配列の大きさが変わる。数値が多いほど精度が良くなりやすいが、処理が重くなる。
# min_count : この値以下の出現回数の単語を無視
# window : 対象単語を中心とした前後の単語数
# iter : epochs数
# sg : skip-gramを使うかどうか 0:CBOW 1:skip-gram
model = word2vec.Word2Vec(df_text['words2'],
size=200,
min_count=10,
window=5,
iter=20,
sg = 1) # sg=1:skip-gram使用
# 学習結果
print(model.wv.vectors.shape) # 分散表現の形状
print(model.wv.vectors) #分散表現の配列
(335, 200)
[[-0.15606833 0.09154884 0.1427529 ... 0.03172395 -0.12487664
0.06667794]
[-0.219026 0.09349723 0.13353091 ... 0.04806438 -0.14577825
-0.01028913]
[-0.15505351 0.08061756 0.13742137 ... 0.03023052 -0.14424255
0.05791197]
...
[-0.15994348 0.08921173 0.1391619 ... 0.03586242 -0.14906307
0.04165793]
[-0.13841385 0.07792909 0.13102876 ... 0.02942118 -0.15503067
0.04932646]
[-0.15625252 0.07768033 0.13904253 ... 0.02566543 -0.15500116
0.0419891 ]]
#ベクトル化したテキストの各語彙確認
model.wv.index2word
出力
#matplotlib日本語化
!pip install japanize-matplotlib
PCA
# PCA実行
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
values = pca.fit_transform(model.wv.vectors)
#print(values.shape)
#print(values)
#PCA可視化
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
plt.rcParams["font.size"] = 24
plt.tight_layout()
fig = plt.figure(figsize=(30,18))
for value, word in zip(values, model.wv.index2word):
plt.plot(value[0], value[1], marker='')
plt.annotate(word, (value[0], value[1]))
plt.title('PCA on word2vec embeddings', fontsize=30)
#plt.xlim(**,**)
#plt.ylim(**,**)
plt.xticks(fontsize= 20)
plt.yticks(fontsize= 20)
plt.show()

t-SNE
#@title t-SNE
#@markdown **<font color= "Crimson">ガイド</font>:perplenxity によってクラスタリングの状況が変化します。例えば 2, 5, 10, 30, 50, 100 など振ってみてください。**
perplexity = 2 #@param {type:"slider", min:2, max:100, step:1}
tSNE_text_font_size = 10 #@param {type:"slider", min:8, max:24, step:1}
from sklearn.manifold import TSNE
#実行
tsne = TSNE(n_components=2, perplexity=perplexity,random_state=0)
np.set_printoptions(suppress=True)
values2 = tsne.fit_transform(model.wv.vectors)
#可視化
fig2 = go.Figure()
for value, word in zip(values2, model.wv.index2word):
fig2.add_trace(
go.Scatter(
x = pd.Series(value[0]),
y = pd.Series(value[1]),
mode = 'markers+text',
text = word,
textposition="top center"
)
)
fig2.update_layout(title=dict(text='<b>t-SNE on word2vec embeddings',
font=dict(size=18,
color='grey'),
xref='paper', # container or paper
x=0.5,
y=0.9,
xanchor='center'
),
showlegend=False,
font = dict(size = 10),
width=900,
height=750
)
fig2.show()

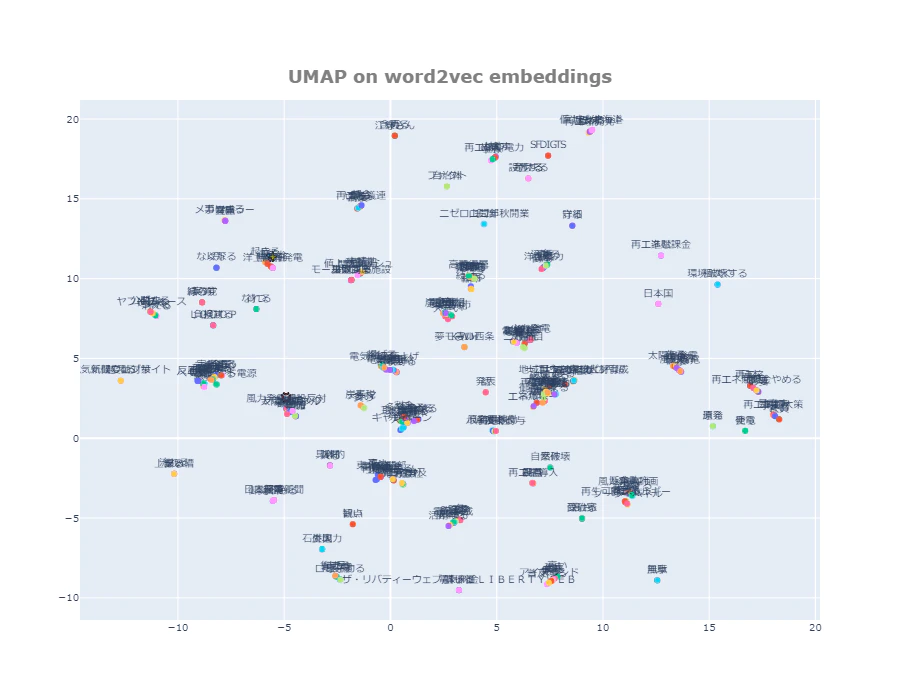
UMAP
!pip install umap-learn
#@title UMAP
#@markdown **<font color= "Crimson">ガイド</font>:n_neighbors によってクラスタリングの状況が変化します。例えば 2, 5, 10, 30, 50, 100 など振ってみてください。**
n_neighbors = 2 #@param {type:"slider", min:2, max:100, step:1}
UMAP_text_font_size = 10 #@param {type:"slider", min:8, max:24, step:1}
import umap.umap_ as umap
from scipy.sparse.csgraph import connected_components
import plotly.graph_objs as go
import plotly.express as px
import os
os.environ['OMP_NUM_THREADS'] = '1'
os.environ['PYTHONHASHSEED'] = '0'
np.set_printoptions(suppress=True)
values1 = umap.UMAP(n_components=2,n_neighbors=n_neighbors).fit_transform(model.wv.vectors)
#可視化
fig1 = go.Figure()
for value, word in zip(values1, model.wv.index2word):
fig1.add_trace(
go.Scatter(
x = pd.Series(value[0]),
y = pd.Series(value[1]),
mode = 'markers+text',
text = word,
textposition="top center"
)
)
fig1.update_layout(title=dict(text='<b>UMAP on word2vec embeddings',
font=dict(size=18,
color='grey'),
xref='paper', # container or paper
x=0.5,
y=0.9,
xanchor='center'
),
showlegend=False,
font = dict(size = 10),
width=900,
height=700
)
fig1.show()
最後に
テキスト文書から抽出したワードをword2vecでベクトル化し、PCA、t-SNE、UMAPに2次元平面上に可視化することができました。
「学問ノススメ」で実行したPCAでは、プロットがギュッと固まってしまい、うまくクラスタリングできませんでしたが、「tweetデータ」で実行したt-SNE、UMAPでは、ある程度クラスタリングすることができました。
t-SNE、UMAPはなかなかすごいですね。
PythonでのPCA・t-SNE・UMAPの実行コードはほとんど同じなので、同時比較が簡単にできます。
2次元平面をクラスタリング単位で確認し、類似ワードを把握 ⇒ 原文確認を行う・・・等、テキスト分析の手掛かりとして使えるのではないかと思います。
参考サイト