はじめに
前回の記事で、
Excelに整理した「アンケート自由記述」をTF-IDFでグルーピング を紹介しました。
自由記述=文章をベクトル化してグルーピングするなら、Doc2Vecを試さないわけにはいかないということで、早速やってみました。
コードの実装、実行は、案外すんなりいけたのですが、どうもしっくりこない。
アンケートの自由記述に、微妙に表現は異なる「特になし」が以下4通りありました。TF-IDFでは以下4通りとも同じグループに分けられましたが、Doc2Vecを試した直後はバラバラのグループに分かれたからです。
1.特にありません。
2.特になし。
3.特に無し。
4.今のところ特に無し。
う~ん。。。ほぼあきらめていたのですが、以下のYoutubeで紹介されているコードをほぼ完コピさせていただいたところ、わ~ぉ、うまくいきました。
ということで、今回はExcelに整理した「アンケート自由記述」をDoc2Vecでグルーピング を備忘を兼ね、紹介します。
実行条件など
・Google colabで実行
・**手元の表形式データ(アンケート自由記述結果)**で実行
※使用したデータは開示できませんが、データ形式は以下です。カラムはUserID、comment、csの3つ。commentは自由記述回答、csは満足度(1~6)です。
| userID | comment | cs |
|---|---|---|
| U001 | 総合的には満足してますが、○○が細かく調整できたらもっと使いやすいと思います。 | 4 |
| U002 | ○○ボタンが押しにくいです。 | 2 |
| U003 | 特にありません。 | 3 |
| U004 | 既存品と取付位置が合わないことがつらいです。 | 1 |
語彙のベクトル化について
Userの訴えかけを語彙傾向で分けるためには、語彙をベクトル化しないといけません。
私はTF-IDF、word2vec、doc2vecを試しました。
この記事では、Doc2Vecによる方法を扱っています。
各Userの声、形態素の結果、グループ分け(クラスタ分け)の結果をデータフレームに格納、csvデータに変換し、ローカルファイルに出力するようにしています。
グループ分けした結果は、EXCELで並べ替えるなどして見たほうがよいでしょう。
備忘
- 実行内容は前回の記事のコードにDoc2Vecの実行コードを追加した形です。
- コード操作を不要にするため、ファイル指定やフォームなど、GoogleColabの機能を活用。
- 品詞は名詞・動詞・形容詞(動詞と形容詞は基礎型)を抽出対象とした。
事前準備
- ライブラリのインストールなどは前回の記事と同じなので省略します。
- 以下のサイトの「dbow300d:distributed bag of words (PV-DBOW)」(学習済モデル)をダウンロードします。
- 解凍後のjawiki.doc2vec.dbow300d📂を/content/drive/My Drive/NLPに保存。(私はMy Driveの下にNLPフォルダを作成し、その中に保存しました。)
Doc2Vec
GoogleDriveにアクセスするためのコードです。初回のみ、セル実行するとURLのクリックを促されますので、クリック⇒ログインするとコードが表示されますので、コピーし、セルに戻ってペーストでアクセスできます。
# @title Doc2Vec 学習済モデル保存先指定
# GoogleDriveへのアクセス
from google.colab import drive
drive.mount('/content/drive')
# 学習済モデル保存フォルダ指定
%cd /content/drive/My Drive/NLP
学習済モデルのロードに2分程度要します。
# @title Doc2Vec ベクトル化
m = MeCab.Tagger("-Ochasen")
def mecab_sep(text):
node = m.parseToNode(text)
words_list = []
while node:
if node.feature.split(",")[0] == "名詞":
words_list.append(node.surface)
elif node.feature.split(",")[0] == "動詞":
words_list.append(node.feature.split(",")[6])
elif node.feature.split(",")[0] == "形容詞":
words_list.append(node.feature.split(",")[6])
node = node.next
return words_list
### Bag-of-words / tf-idf
def calc_vecs(docs):
vectorizer = TfidfVectorizer(analyzer=mecab_sep)
vecs = vectorizer.fit_transform(docs)
return vecs.toarray()
### Doc2Vec
from gensim.models.doc2vec import Doc2Vec
model = Doc2Vec.load("jawiki.doc2vec.dbow300d/jawiki.doc2vec.dbow300d.model")
def calc_vecs_d2v(docs):
vecs = []
for d in docs:
vecs.append(model.infer_vector(mecab_sep(d)))
return vecs
all_docs_vecs = calc_vecs_d2v(df['comment'])
前回の記事では、User毎の自由記述内容をデータフレームに格納。
その後、形態素、TF-IDFによるグルーピングもデータフレームに追加しました。
以下では、Doc2Vecによるベクトルをk-meansでグルーピングし、その結果をデータフレームに格納します。
※前回記事の続きなので、前回記事のコードありきです。
# @title Doc2Vec_k-meansによる各意見のクラス分け
from sklearn.cluster import KMeans
vec = KMeans(n_clusters=9)
vec.fit(all_docs_vecs)
df["cluster_d2v"] = vec.labels_
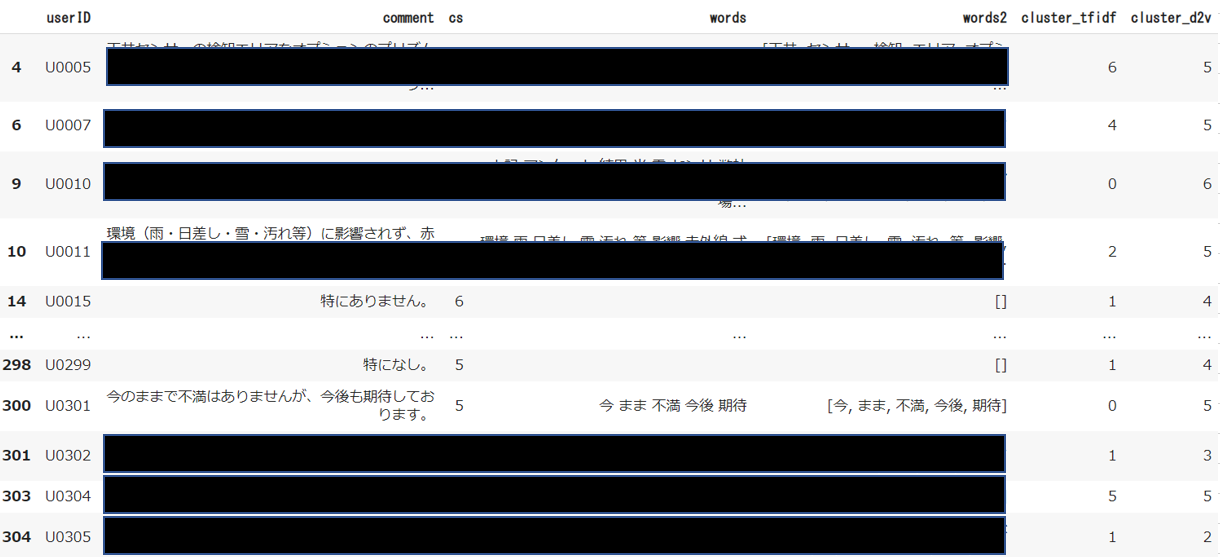
df
フルでは見せられませんが、「cluster_tfidf」がTF-IDFによるグルーピング、「cluster_d2v」がDoc2Vecによるグルーピングです。
”特にありません。”と”特になし”が、いずれのグルーピングでも同じグループに分けることができています。
# @title データフレームをcsvに変換し、ローカルファイルに保存
from google.colab import files
filename = 'cluster.csv'
df.to_csv(filename, encoding = 'utf-8-sig')
files.download(filename)
最後に
アンケート分析で苦労するのは、「自由記述」など、自然言語です。
量がおおいと、ただただ圧倒されます。
まずは、全体をWord Cloudで眺めたり、満足度別に描いて眺めたりして、Userの訴えの全体感に思いを巡らせ、
その上で、語彙でグループ分け(クラスタ分け)した単位でUserの声に触れることで、より我がごととして染み込んできやすくなるように思います。
Pythonやその他ツールは分析の手助けはしてくれますが、答えを教えてくれるものではありません。
ダイレクトに答えは得られないまでも、できるだけ先の答えにつなげやすいであろう見方やまとめ方はできると思いますし、これらによって答えに近づくことができるのだと思います。
参考サイト