はじめに
以前のエントリーで Adobe Analytics の計算指標機能を用いた統計量の求め方について紹介しました。
取得したデータの特徴を把握することはマーケティングを行う上で非常に重要となるにも関わらず、利用する統計量が、平均値や中央値といった代表値がほとんど、というケースが多いのではないでしょうか。今回はデータの特徴を把握する上で代表値と同じくらい重要な「散らばり」の統計量を、Adobe Analytics でどのように求めるか、を想定利用シーンに沿いながら説明させていただきます。
この記事の内容は 2022年12月時点の情報に基づいて執筆しています。 計算指標の追加・変更等、適宜変更されている場合があります。
想定読者
本エントリーは初歩的な統計の知識、ならびに、Adobe Analytics の分析ワークスペース作成、計算指標作成、といった知識をお持ちの読者を想定し作成しております。
以下参考資料となります。適宜ご確認ください。
Adobe Analytics で算出可能な散らばりの統計量の例
散らばりの統計量にはいくつか存在しますが、Adobe Analytics で簡易に算出可能な統計量を下記にまとめました。
| 統計量 | 指標名 | 利用できる分布 |
|---|---|---|
| 標準偏差 | 関数「標準偏差」をそのまま利用 | データが正規分布に従うと認められ、かつ、外れ値が少ない場合に活用 |
| 分散 | 関数「標準偏差」と関数「平方根」を利用して算出 | 「標準偏差」と同じ |
| 四分位範囲 | 関数「四分位数」を利用して算出(※) | 正規分布以外のデータや外れ値がある場合でも活用可能 |
| 範囲 | 関数「最大値」、関数「最小値」を利用して算出 | 「四分位範囲」と同じ |
※四分位範囲(IQR)は下記で求められます。
IQR = Q3(第3四分位数) - Q1(第1四分位数)
2. 活用例
散らばりを利用することで、代表値だけではわからなかった特徴をより詳しく把握することができます。以下に簡単にまとめました。
その1. リスク管理
データの特徴を代表値だけに頼ってしまった結果、誤った施策や目標設定を行ってしまう恐れがあります。具体的には以下のようなパターンです。
過去3ヶ月のデータを元に来月の目標を立てる事になった。過去3ヶ月の日別の平均ページビュー数が5,000であったため、来月の目標もそれを基準に立て、運用することにした。結果、結果は当初目標の半分以下となった
上記は散らばりの度合いが大きいデータであるにも関わらず、それを考慮に入れなかったのが原因です。
その2. コンテンツの品質管理
散らばりの度合いを利用することで、提供している製品・コンテンツの品質管理(ターゲットに正しく届けられているか)を把握することができます。具体的には以下のようなパターンです。
あるサイトにて新しくオウンドメディアを構築することになった。メインの読者は決まっており、この読者が好みそうな記事を約50程度作成しリリースした。リリース後1ヶ月ほど経過したので、これらコンテンツが正しくターゲットに届いているか確認したい。
この場合、散らばりの統計量を利用することで、下記のようなことがわかります。
- 散らばりを表す統計量が大きい場合
- 読まれている記事、読まれていない記事の間で差が小さい事を意味します。すなわち、ターゲットにきちんと製品・コンテンツを提供できている事がわかります。
- 散らばりを表す統計量が小さい場合
- 読まれている記事、読まれていない記事の間で差が大きい事を意味します。すなわち、ターゲットにきちんと製品・コンテンツを提供できていない事がわかります。
以上、散らばりを利用することで確認できることの例を挙げていきました。
3. Adobe Analytics を利用した散らばりの統計量の算出方法
ここまで、Adobe Analytics で算出できる散らばりの統計量の求め方、そして、その活用例について述べていきました。では実際に Adobe Analytics を使い、散らばりの統計量を求めていきます。尚、今回は上記その2のパターンを例に勧めていきます。
流れ
散らばりの統計量を求めていく流れは下記となります。
- データの分布を把握し、利用する散らばりの統計量を決める
- 計算指標ビルダーを使い、指標を作る
- 散らばりを確認したいデータに、2を当てはめる
- (補足)結果をビジュアライズする
- 結果を読み取る
1. データの分布を把握し、利用する散らばりの統計量を決める
まずは今回対象のデータがどのような分布、具体的には正規分布か否か、を把握する必要があります。この分布を把握することで、複数ある散らばりの統計量のうちどれが適切かが確認できます。正規分布の特徴の1つに、データの平均値、中央値、最頻値が近い値を取る、が挙げられますので、この特徴を利用してまずは分布を把握していきましょう。
今回想定のオウンドメディアを実施しているサイトは、ディレクトリは「blog」の配下となるため、これに該当するようなセグメントを作成しておきます。また、デスクトップとモバイル両方で同じコンテンツを提供していますが、UI/UXが大きく異なることから、今回はモバイルのみの設定とします。
以下その結果です。
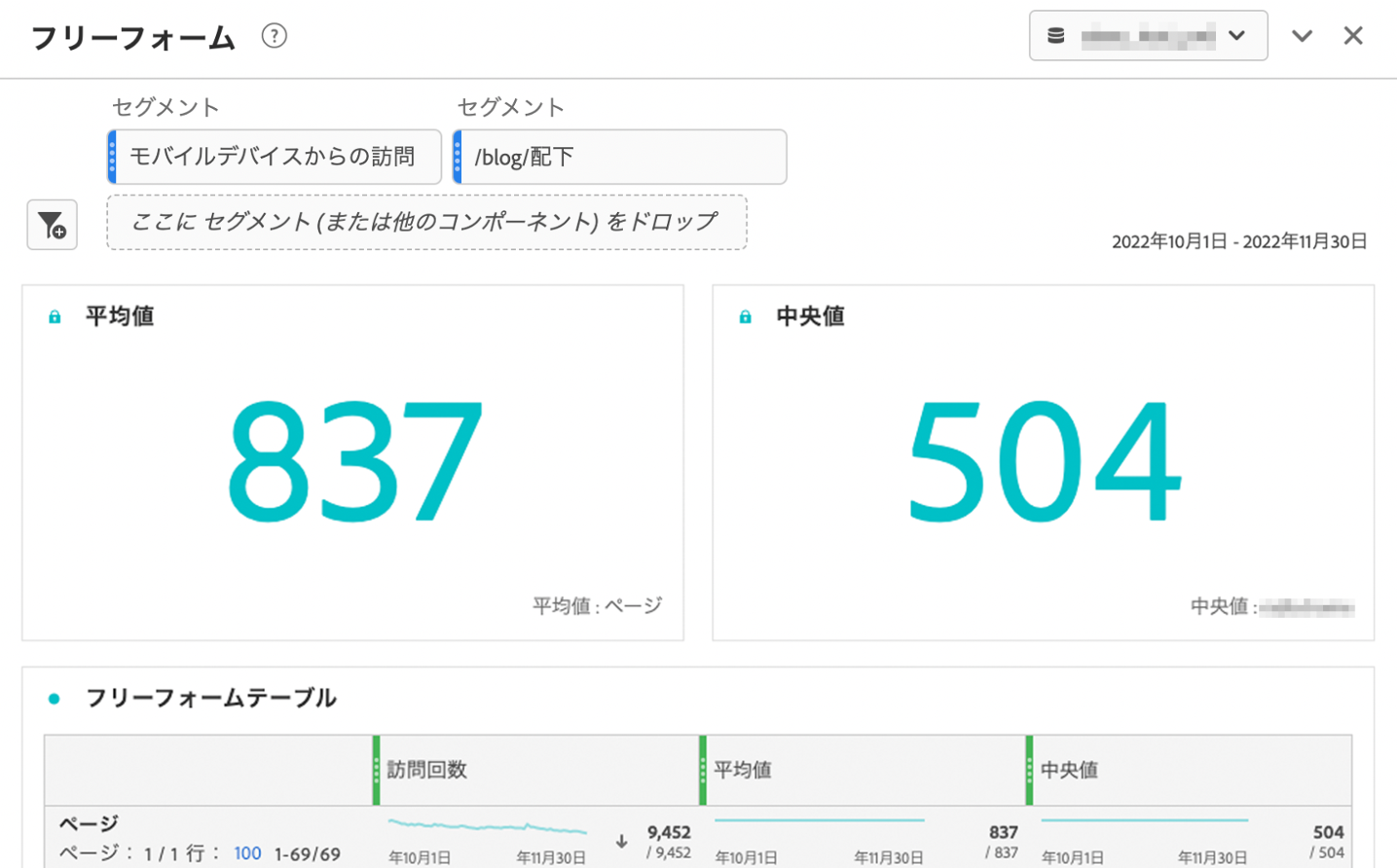
今回は平均値が837,中央値が504と大きな開きが認められるため、正規分布とは言い難い分布となる事がわかりました。すなわち今回のケースでは四分位範囲を利用して散らばりの度合いを求めていきます。
2.計算指標ビルダーを使い、指標を作る
利用する統計量が決まりましたので、早速指標を作成していきましょう。今回は四分位範囲となるため、計算指標「四分位数」を利用し、第1四分位数、第3四分位数を作成します。その後、改めて計算指標を利用して第3四分位数、第1四分位数の差を求めます。
2-1. 第1四分位数、第3四分位数の作成
-
ワークスペースから、「コンポーネント」 -> 「指標」を作成を選択します。
-
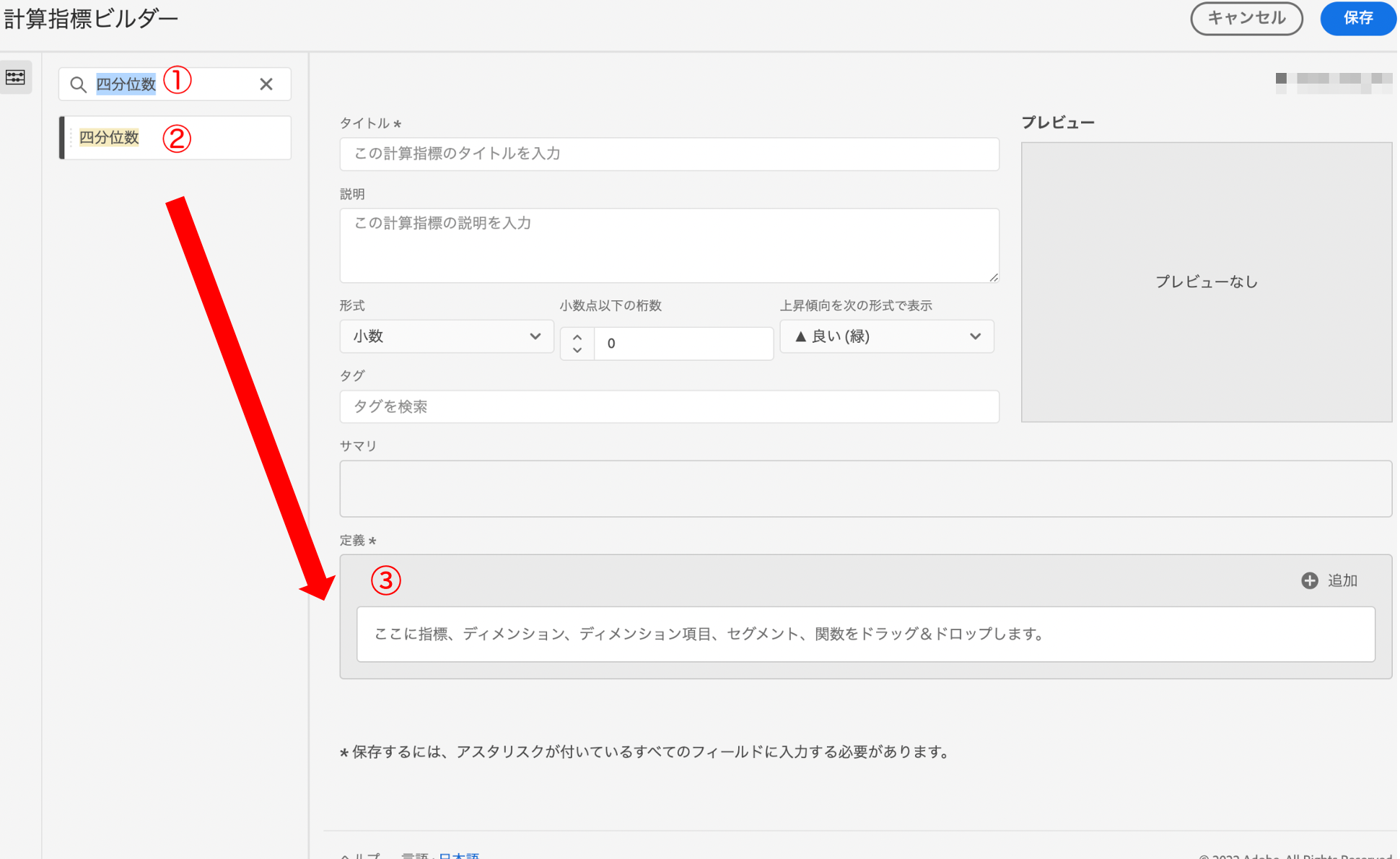
計算指標から直接探すか、下記のように「四分位数」と検索し(①)た後、右の「定義」箇所に追加します(③)。
-
第1四分位数を作ります。「四分位数」を作るには、定義内「四分位数」の箇所に1と入力します。ちなみに第2四分位数(中央値と一緒)を作る場合は、「2」、同じく第3四分位数を作るには「3」と入力し作成します。
※ちなみに、「0」の場合は、最小値、「4」の場合は最大値となります。

-
次に、指標を選択します。今回は「訪問回数」を利用します。
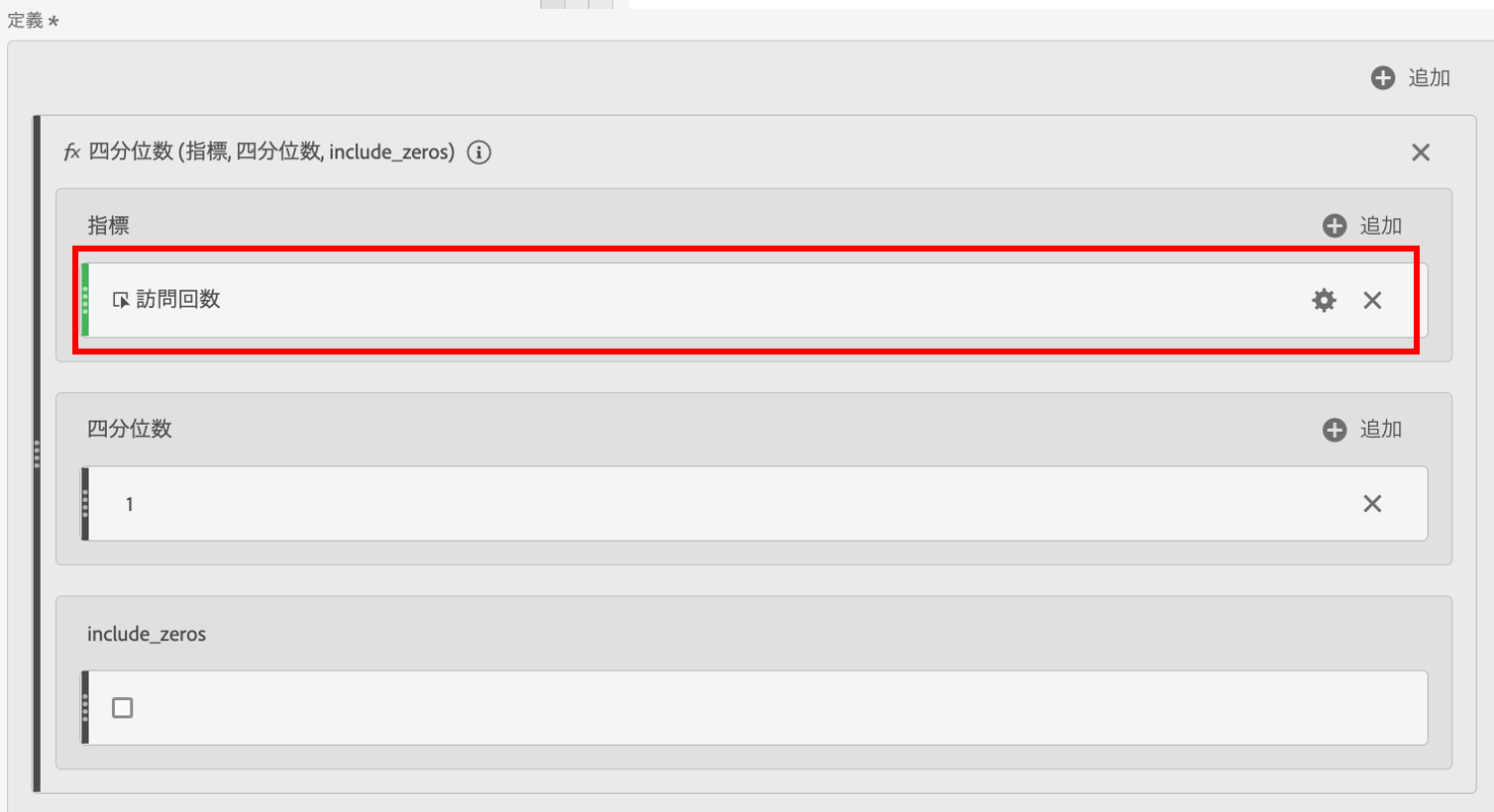
これで第1四分位数が完成しました。名称をつけ保存しておきます。続けて、同じ方法で最小値、第3四分位数、最大値を作っておきましょう。最小値、最大値はIQR算出には利用しませんが、散らばり具合を把握する際に活用できます。
最後に、「include_zero」 にはチェックボックスをチェックを外しておきます。これは計算に0を追加するか否かのチェックボックスとなります(※3)が、今回は利用しないため外しておきます。
2-2. 四分位範囲(IQR)を作成
計算指標ビルダーを利用して第3四分位数と第1四分位数の差を下記のような方法で算出し保存します。
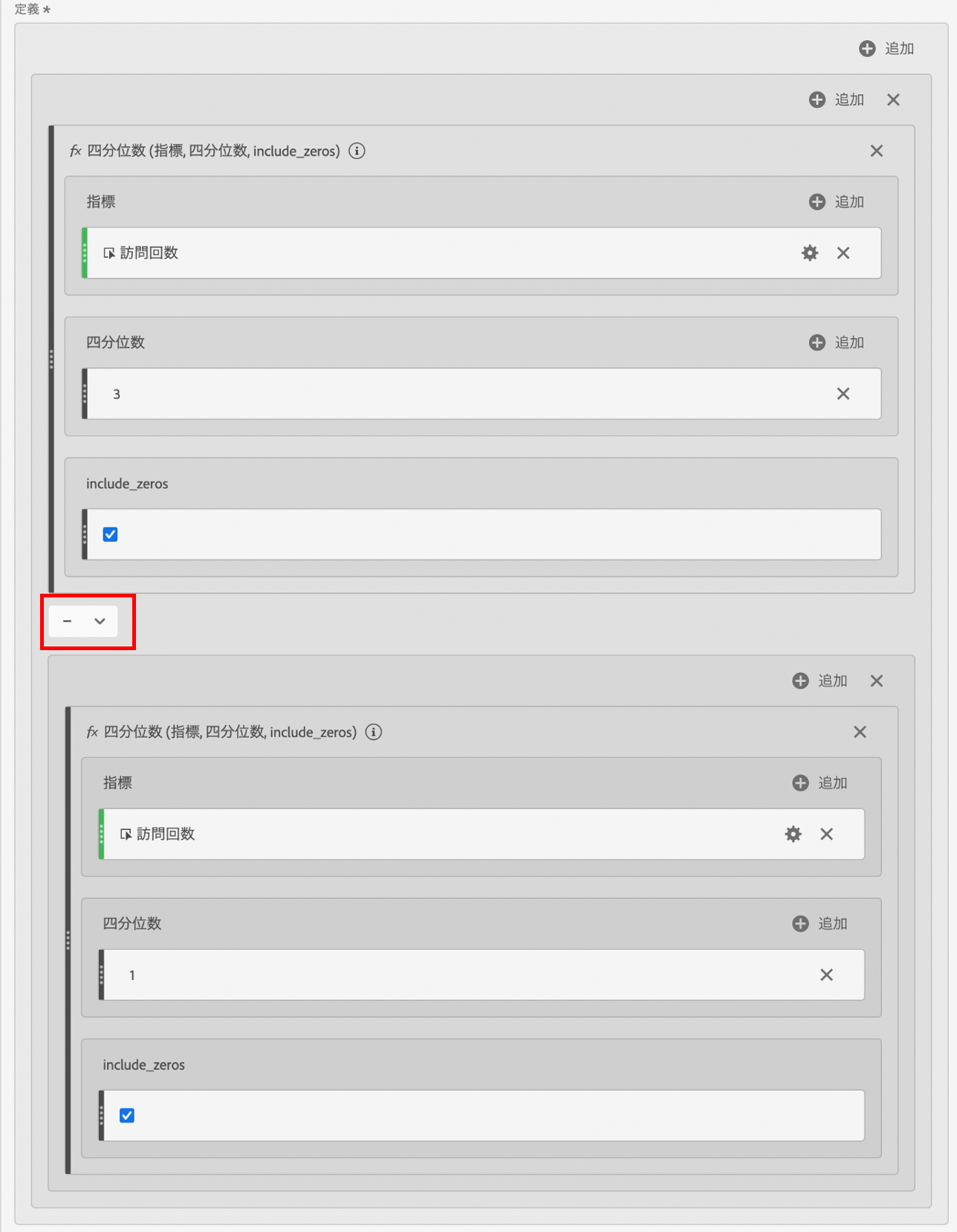
3.散らばり度合いを確認する
IQRが作成できたので、早速散らばりの度合いを確認していきましょう。
3−1. 散らばりを確認したいデータに、2を当てはめる
散らばりの度合いを、散らばりを確認したいデータに、2で作成したIQR、最小値、第1四分位数、第3四分位数、最大値の5つを適用していきましょう。以下結果となります。
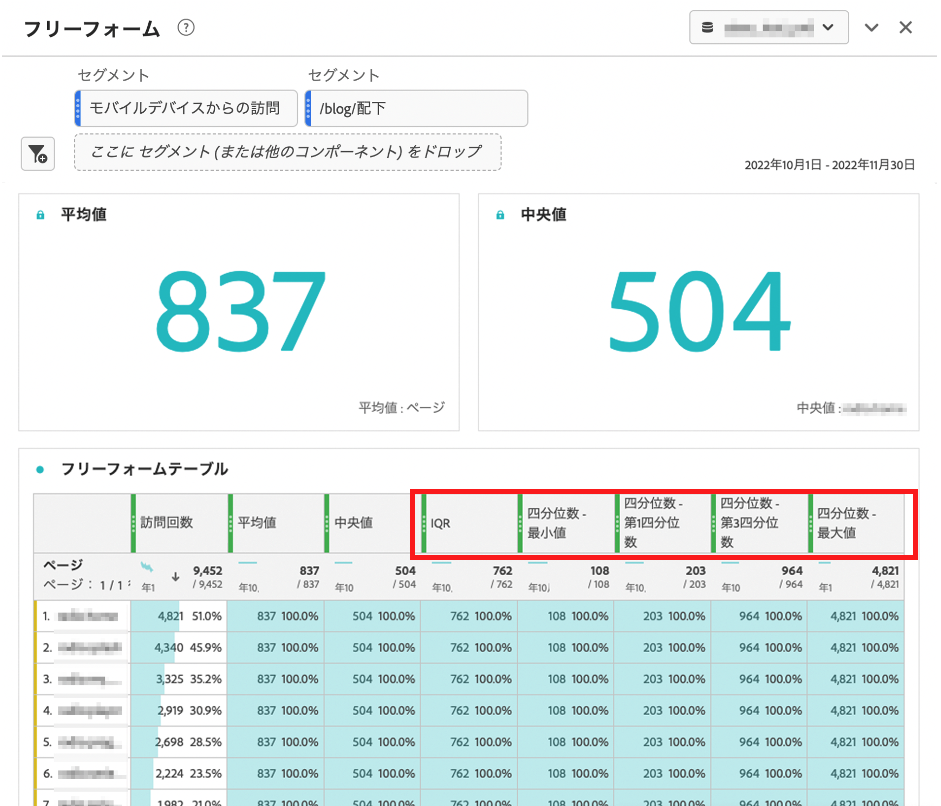
計算指標、四分位数は「表関数」となります。表関数とは、表のどの行についても出力が同じになる関数です。一方、行関数というものも用意しており、こちらは表の各行で出力が異なる関数です。
これで結果が確認することができましたが、ビジュアライゼーション機能を利用してよりわかりやすくしましょう。
(補足)4.結果をビジュアライズする
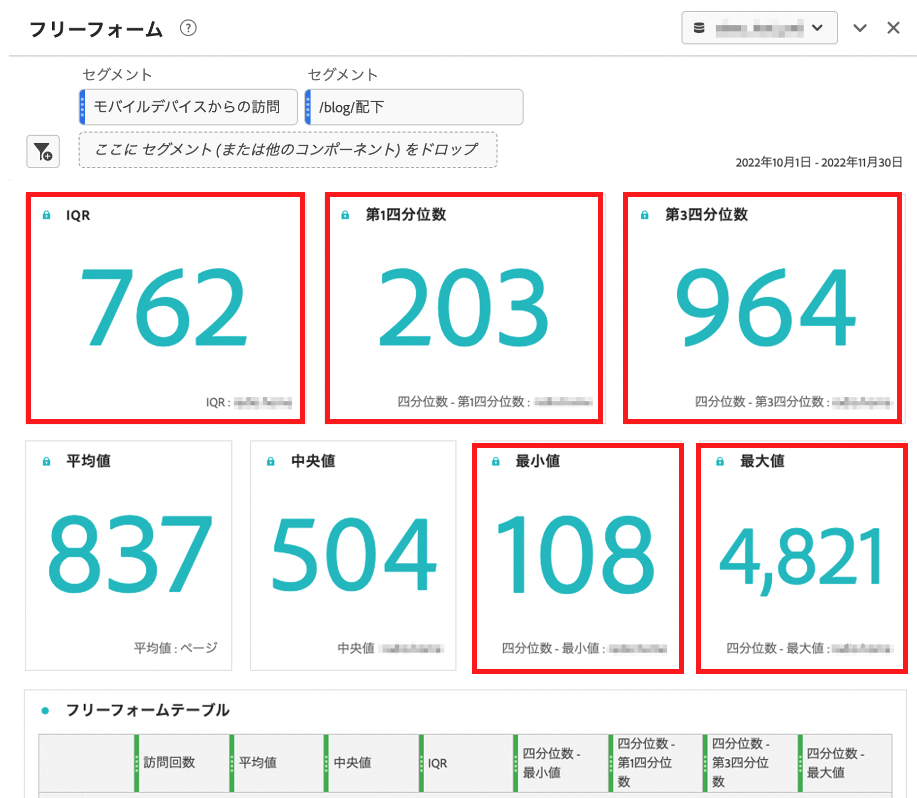
今回はビジュアライゼーション「数値の概要」を利用して、必要な数字を配置しました。
5.結果を理解する
最後に結果を確認していきます。
IQR単体では散らばり具合を読み取れないため、他指標を見ながら確認していきます。IQRが762、第1四分位数が203、第3四分位数が964、最小値が108、最大値が4821となりました。
IQRが762であるにも関わらず、最大値が4821と大きくなっていることから、かなり散らばり具合を大きいように思えます。
すなわち、ターゲットにきちんと製品・コンテンツを提供できていない可能性がある事がわかりました。
まとめ
今回は四分位数を使った散らばりの出力方法について記載していきました。尚、分布が正規分布である場合は指標「標準偏差」を利用することで散らばり具合を確認することが可能となります。今回の例のように、代表値だけでなく、散らばりを把握することでデータの特徴をより把握することができるため、積極的に活用することをおすすめします。
今後も引き続き高度な計算指標を活用方法をお伝えできればと思います。