目次
- アソシエーション分析とは何か?
- マーケット・バスケット・トランザクション
- 相関ルール
- 設問の形式
- 水平展開形式のデータ
- 集計データ
- R言語用のスクリプトをJava等で生成する
- パッケージarules
- データの型
- データの型の変換
- transaction形式に変換
- matrix形式に変換
- data.frame形式に変換
- アイテムの頻度の棒グラフを作成する
- 棒グラフ~もうひとつのアプローチ
- 円グラフ
- 3D円グラフ
- 基本統計量
- 相関ルールを抽出する関数 apriori
- デフォルト指定で出力
- support=0.01,confidence=0.5,maxlen=4 指定
- 支持度(support)を基準としてソートした上位6位のルールを呼び出すinspect
- support=0.03,confidence=00.5 指定
- lift>=1.5
- Association Ruleの評価指標の用語の簡単な解説
- 前提確率
- 支持度(support):同時確率
- 確信度(confidence):条件付き確率
- リフト値(lift):改善率
概要
アソシエーション分析とは何か?
有名な例として「おむつとビール」の同時購入があげられます。
ある店の売り上げを調べてみると、商品購入の組み合わせとして最も多かった例が「おむつとビール」の組み合わせであり、この地域の購買層として、夕方に会社帰りで「ビール」と「おつまみ」以外に小さな子供のための「おむつ」を買ってゆくサラリーマン生活像まで浮き彫りになった分析手法です。
マーケット・バスケット・トランザクション
購入者が買った商品のリストがバスケットの中身に相当します。
アンケートで言えば、チェックボックス系の複数回答形式の設問の回答データが、扱いやすいです。
例)
| SAMPLE_ID | Contents |
|---|---|
| 1 | {パン、牛乳、ハム、果物} |
| 2 | {パン、オムツ、ビール、ハム} |
| 3 | {ソーセージ、ビール、オムツ} |
| 4 | {弁当、ビール、オムツ、タバコ} |
| 5 | {弁当、ビール、オレンジジュース、果物} |
相関ルール
頻出するアイテム間の何らかの組み合わせの規則をアソシエーションルールと呼ぶ。アソシエーションルールは連関ルール、関連ルール、相関ルールなどと呼ばれます。
「商品Aを買うと商品Bも買う」のようなルールを見つけ出すことを目標としています。
今回の例は、掃除機の購買動機に繋がる不満要素の組み合わせです。
これを特定し、その中でも特に強い不満点を解明して、商品開発に貢献させることを目標とします。
アンケートの設問
設問の形式
チェックボックス系の複数回答形式の設問

回答データ
水平展開形式のデータ
サンプル毎に複数の設問への回答が存在し、1サンプル1レコードの形式であること。
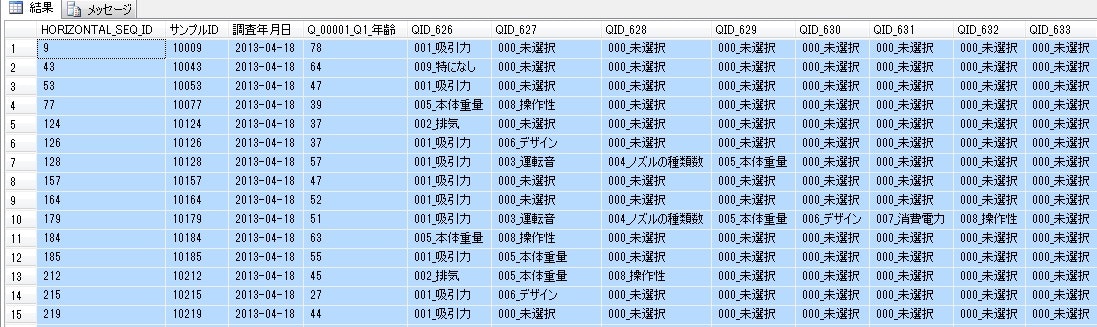
集計データ
予め用意できるのであれば、SQLなどで集計データを作成しておくとグラフが描きやすくなります。
(※そこまで準備しなくとも、Rで図を出すことは可能です。)
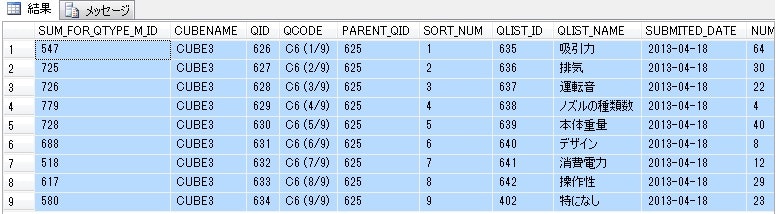
※しかし、この表では集計されてしまっているのでアソシエーション分析まではできない。
R言語用のスクリプトの生成
R言語を使用しますが、環境として RStudioなどを事前に準備しておくこと。
R言語用のスクリプトをJava等で生成する
スクリプトを作成できるのであれば、どの手法を使っても構いませんが、ここではJavaで作成してみます。
・【IN】情報源としてSQL等でダンプしたCSVファイルを準備しておきます。(※1)
・【OUT】生成するファイル名はここで任意に決めます。
※こうした情報はプロパティファイルなどに外だししておくのが基本ですが、ここでは本題ではないので割愛します。
private void C6_Analysis(String[] args) {
// TODO 自動生成されたメソッド・スタブ
String FN_CUBE3_QID626_QID634_csv = "C:\\eclipse\\workspace\\HogeConvert\\csv\\CUBE3_QID626_QID634.csv";
String RS_QID626_QID634_R = "C:\\eclipse\\workspace\\HogeConvert\\csv\\RS_QID626_QID634.R";
String keyword = "000_未選択";
QID_625 qid_625 = new QID_625();
try {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FN_CUBE3_QID626_QID634_csv),"MS932"));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(RS_QID626_QID634_R),"MS932"));
String rec;
String recCnv;
int cnt = 0;
ArrayList<String[]> lines_list = new ArrayList<String[]>();
while((rec = br.readLine()) != null) {
if(cnt == 0){
// header部はそのままコピーする。
}else{
String[] cnv_rec = qid_625.convert(rec);
lines_list.add(cnv_rec);
}
cnt++;
}
br.close();
//
String rListString = qid_625.getRListString(lines_list);
//1行で出力したものをRで実行するとなぜかマルチバイト文字エラーになる。
//System.out.println(rListString);
//
//
bw.write("library(arules)" + "\r\n",0,"library(arules)".length()+1);
String[] strArray = rListString.split("c\\(",-1);
for(int i = 0 ; i < strArray.length ; i++){
if(i == 0){
System.out.println(strArray[i]);
bw.write(strArray[i] + "\r\n",0,strArray[i].length()+1);
}else{
String tmp = "c(" + strArray[i];
System.out.println("c(" + strArray[i]);
bw.write(tmp + "\r\n",0,tmp.length()+1);
}
}
String tmp2 = "head(" + qid_625.r_listname + ")";
bw.write(tmp2 + "\r\n",0,tmp2.length()+1);
String tmp3 = qid_625.r_listname + ".tran<-as(" + qid_625.r_listname + ",\"transactions\")";
bw.write(tmp3 + "\r\n",0,tmp3.length()+1);
String tmp4 = "class(" + qid_625.r_listname + ".tran)";
bw.write(tmp4 + "\r\n",0,tmp4.length()+1);
String tmp5 = "itemFrequencyPlot(" + qid_625.r_listname + ".tran" + ",type = \"absolute\")";
bw.write(tmp5 + "\r\n",0,tmp5.length()+1);
bw.close();
} catch (UnsupportedEncodingException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
} catch (IOException e) {
// TODO 自動生成された catch ブロック
e.printStackTrace();
}
}
用意するファイルと出力されるファイル
| 項目 | ファイルパス | 備考 |
|---|---|---|
| 利用するCSVデータ | C:\eclipse\workspace\HogeConvert\csv\CUBE3_QID626_QID634.csv | ※使用環境に合わせてください。 |
| 生成するRスクリプトファイル | C:\eclipse\workspace\HogeConvert\csv\RS_QID626_QID634.R | ※使用環境に合わせてください。 |
クラス
| class name | 備考 |
|---|---|
| AssociationsAnalysis | アソシエーション分析スクリプト |
| QID_625 | QID_625:C6設問用のクラス |
メソッド
| class name | method name | 備考 |
|---|---|---|
| AssociationsAnalysis | private void C6_Analysis(String[] args) | RScriptファイルの生成処理 |
| QID_625 | public String[] convert(String rec) | 1レコード単位でRのlistの形式に変換 |
| QID_625 | public String getRListString(ArrayList lines_list) | さらに編集してRのlistの形式に変換 |
※GitHubにソースをアップしておきます。
https://github.com/hidetarou2013/SupportRAssociation
生成されたRスクリプトファイル(一部抜粋)
library(arules)
QID_625_data1 <- list(
c("001_吸引力"),
c("009_特になし"),
c("001_吸引力"),
c("005_本体重量","008_操作性"),
c("002_排気"),
c("001_吸引力","006_デザイン"),
c("001_吸引力","003_運転音","004_ノズルの種類数","005_本体重量"),
c("001_吸引力"),
c("001_吸引力"),
c("001_吸引力","003_運転音","004_ノズルの種類数","005_本体重量","006_デザイン","007_消費電力","008_操作性"),
c("005_本体重量","008_操作性"),
c("001_吸引力","005_本体重量"),
c("002_排気","005_本体重量","008_操作性"),
...
c("001_吸引力","002_排気","005_本体重量","007_消費電力"),
c("001_吸引力"),
c("002_排気"))
head(QID_625_data1)
QID_625_data1.tran<-as(QID_625_data1,"transactions")
class(QID_625_data1.tran)
itemFrequencyPlot(QID_625_data1.tran,type = "absolute")
命名規則
| QID_625_data1 | list形式のオブジェクト |
|---|---|
| QID_625_data1.tran | transaction形式のオブジェクト |
Rでアソシエーション分析
パッケージarules
Rで相関ルールを抽出するには,パッケージarulesを使います。
初回はimportします。
> install.packages("arules", dependencies=T)
そしてパッケージをロードします。
> library(arules)
データの型
Rのデータは基本的にデータフレーム型ですが、今回はそのままでは利用できないようです。
(※通常CSVデータをインポートしたものは、基本的にデータフレーム型になります。)
参考
http://mjin.doshisha.ac.jp/R/40/40.html
そこで、対象となる質問項目だけに絞り込んで、リスト形式にします。
(※このために、CSVデータをそのままインポートせず、Javaのツール経由でlist型にして流し込みました。)
> class(QID_625_data1)
[1] "list"
参考
http://commojun.blog.fc2.com/blog-entry-2.html
理由
transactionsに変換するためには,data.frameのすべてのカラムがfactor型でないといけません.
データの型の変換
※以下の例は水平展開データのダンプアウトであるCSVデータをRのデータフレーム型変数「QLIST_NAME_CUBE3.data」に取り込んだ場合の説明です。
環境はLinux環境でのRStudioの例です。(もちろんWindowsでもOKです。)
QLIST_NAME_CUBE3.data <- read.csv("/home/hidetarou/QLIST_NAME_CUBE3.csv",header=T)
まず、そのままデータフレームをtransactionsしてみるとエラーメッセージが出る。
> class(QLIST_NAME_CUBE3.data)
[1] "data.frame"
> QLIST_NAME_CUBE3.data.tran <- as(QLIST_NAME_CUBE3.data, "transactions")
Error in asMethod(object) :
column(s) 1, 2, 4, 194, 195 not logical or a factor. Use as.factor or categorize first.
> class(QLIST_NAME_CUBE3.data[,1])
[1] "integer"
> class(QLIST_NAME_CUBE3.data[,2])
[1] "integer"
> class(QLIST_NAME_CUBE3.data[,4])
[1] "integer"
> class(QLIST_NAME_CUBE3.data[,194])
[1] "integer"
> class(QLIST_NAME_CUBE3.data[,195])
[1] "integer"
エラーメッセージを頼りにして、該当の列の型をfactor型にする。
> QLIST_NAME_CUBE3.data[,1]<-factor(QLIST_NAME_CUBE3.data[,1])
> QLIST_NAME_CUBE3.data[,2]<-factor(QLIST_NAME_CUBE3.data[,2])
> QLIST_NAME_CUBE3.data[,4]<-factor(QLIST_NAME_CUBE3.data[,4])
> QLIST_NAME_CUBE3.data[,194]<-factor(QLIST_NAME_CUBE3.data[,194])
> QLIST_NAME_CUBE3.data[,195]<-factor(QLIST_NAME_CUBE3.data[,195])
> class(QLIST_NAME_CUBE3.data[,1])
[1] "factor"
> class(QLIST_NAME_CUBE3.data[,2])
[1] "factor"
> class(QLIST_NAME_CUBE3.data[,4])
[1] "factor"
> class(QLIST_NAME_CUBE3.data[,194])
[1] "factor"
> class(QLIST_NAME_CUBE3.data[,195])
[1] "factor"
ここまでいけば、transactions変換ができるようです。
> QLIST_NAME_CUBE3.data.tran <- as(QLIST_NAME_CUBE3.data, "transactions")
>
transaction形式に変換
リスト形式のデータは関数asを用いて、transaction、あるいはitemMatrixなどの形式に変換することができる。
> QID_625_data1.tran<-as(QID_625_data1,"transactions")
> QID_625_data1.tran
transactions in sparse format with
242 transactions (rows) and
10 items (columns)
matrix形式に変換
1010形式のデータが出来上がります。
> tmp1<-as(QID_625_data1.tran,"matrix")
> head(tmp1)
001_吸引力 002_排気 003_運転音 004_ノズルの種類数 005_本体重量 006_デザイン 007_消費電力 008_操作性 009_特になし 010_その他
1 1 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 1 0
3 1 0 0 0 0 0 0 0 0 0
4 0 0 0 0 1 0 0 1 0 0
5 0 1 0 0 0 0 0 0 0 0
6 1 0 0 0 0 1 0 0 0 0
data.frame形式に変換
> tmp2<-as(QID_625_data1.tran,"data.frame")
> head(tmp2)
items
1 {001_吸引力}
2 {009_特になし}
3 {001_吸引力}
4 {005_本体重量,008_操作性}
5 {002_排気}
6 {001_吸引力,006_デザイン}
アイテムの頻度の棒グラフを作成する
> itemFrequencyPlot(QID_625_data1.tran,type = "absolute")
>
(ちなみに、この例ではダミーの2か月分のデータをロードしているため、単純に倍の数値になっています。比率は1か月分と同じはずです。)
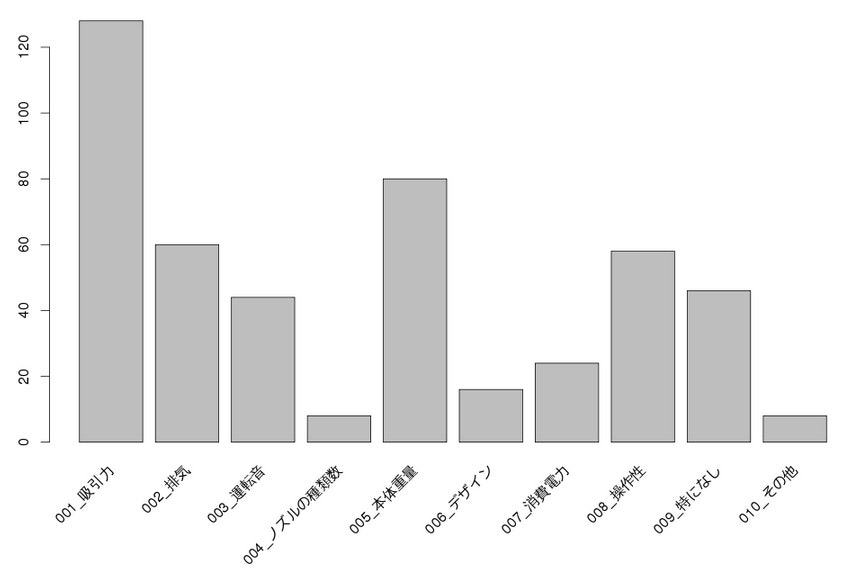
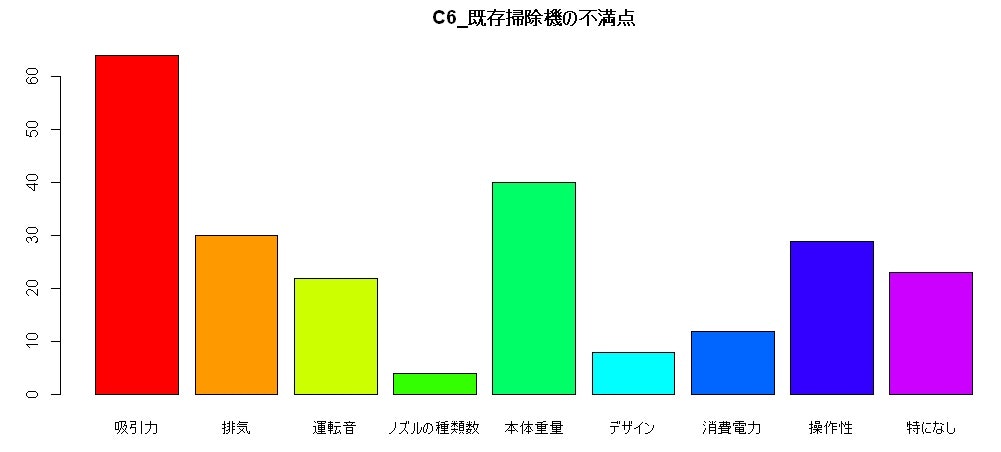
棒グラフ~もうひとつのアプローチ
集計用のテーブルの結果を使っても表現できそうです。
(集計のプロセスを事前にお膳立てしていた場合のケースです。)
(その他は出てきません。)
※以下は、Windows環境でSQLServerへのODBC接続設定をした上でRStudioにRODBC経由で直接DBからデータを取得する手法です。
※CSVデータをわざわざ作成してロードせずに直接DBのデータを利用できるメリットがあります。
※デメリットは、SQLServerのR用ドライバが存在しないため、ODBC接続しか選べないこと。
※クライアントのプラットフォームはWindowsでしか接続できないこと。
SQLで直接データを取り込み、棒グラフを描いてみます。
install.packages("RODBC")
library(RODBC)
connMSSQL <- odbcConnect("MSSQL_HIDELICO_GFKGCI_20130816","sa","password")
ds_QID_625<- sqlQuery(connMSSQL,"SELECT [SUM_FOR_QTYPE_M_ID] ,[CUBENAME] ,[QID] ,[QCODE] ,[PARENT_QID] ,[SORT_NUM] ,[QLIST_ID] ,[QLIST_NAME] ,[SUBMITED_DATE] ,[NUM] FROM [GFKGCI_20130816].[dbo].[SUM_FOR_QTYPE_M_CUBE_COMMON] WHERE SUBMITED_DATE = '2013-04-18' AND PARENT_QID = 625 ORDER BY QID")
ds_QID_625
close(connMSSQL)
barplot(ds_QID_625[,10],horiz=F,beside=T,names = ds_QID_625[,8],col=rainbow(10),main="C6_既存掃除機の不満点")
※ X軸のラベルを斜めにしたいのだが、やり方がわからない。
※ X軸のラベル名を全部出すには十分な大きさを確保しないといけない。
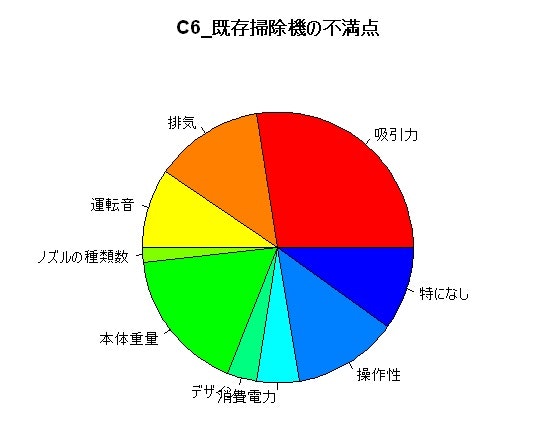
円グラフ
install.packages("RODBC")
library(RODBC)
connMSSQL <- odbcConnect("MSSQL_HIDELICO_GFKGCI_20130816","sa","password")
ds_QID_625<- sqlQuery(connMSSQL,"SELECT [SUM_FOR_QTYPE_M_ID] ,[CUBENAME] ,[QID] ,[QCODE] ,[PARENT_QID] ,[SORT_NUM] ,[QLIST_ID] ,[QLIST_NAME] ,[SUBMITED_DATE] ,[NUM] FROM [GFKGCI_20130816].[dbo].[SUM_FOR_QTYPE_M_CUBE_COMMON] WHERE SUBMITED_DATE = '2013-04-18' AND PARENT_QID = 625 ORDER BY QID")
ds_QID_625
close(connMSSQL)
pie(ds_QID_625[,10],labels=ds_QID_625[,8],col=rainbow(12),main="C6_既存掃除機の不満点")
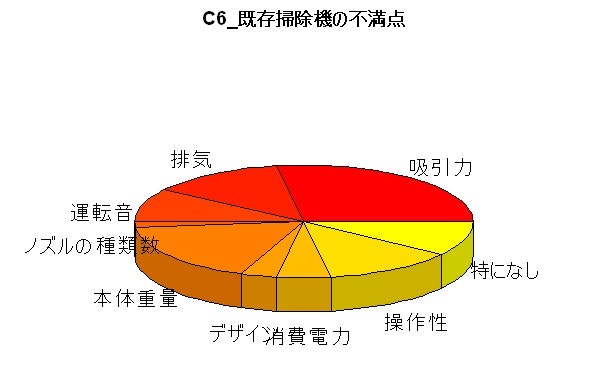
3D円グラフ
library(plotrix)
pie3D(ds_QID_625[,10],labels=ds_QID_625[,8],col=heat.colors(12),main="C6_既存掃除機の不満点")
基本統計量
> summary(QID_625_data1.tran)
transactions as itemMatrix in sparse format with
242 rows (elements/itemsets/transactions) and
10 columns (items) and a density of 0.1950413
most frequent items:
001_吸引力 005_本体重量 002_排気 008_操作性 009_特になし (Other)
128 80 60 58 46 100
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 7
116 70 22 24 8 2
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 1.00 2.00 1.95 2.00 7.00
includes extended item information - examples:
labels
1 001_吸引力
2 002_排気
3 003_運転音
相関ルールを抽出する関数 apriori
書式
apriori(data, parameter = NULL, appearance = NULL, control = NULL)
引数
| parameter | 備考 |
|---|---|
| parameter | 支持度(support)、確信度(confidence)、頻出アイテムの最大数(maxlen: maximum size of mined frequent item sets)をリスト形式で指定する。 |
| appearance | アイテムの扱いを指定することができる |
| control | アルゴリズムのパフォーマンスを制御する。 |
参考
http://rss.acs.unt.edu/Rdoc/library/arules/html/apriori.html
デフォルト指定で出力
デフォルト値はsupport =0.1, confidence=0.8, maxlen=5
> grule1 <- apriori(QID_625_data1.tran)
parameter specification:
confidence minval smax arem aval originalSupport support minlen maxlen target ext
0.8 0.1 1 none FALSE TRUE 0.1 1 10 rules FALSE
algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[10 item(s), 242 transaction(s)] done [0.00s].
sorting and recoding items ... [6 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 done [0.00s].
writing ... [0 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
writing ... [0 rule(s)] done [0.00s].
ルールがひとつもない。
support=0.01,confidence=0.5,maxlen=4 指定
返された結果は、アルゴリズム実行のパラメータ仕様、抽出されたルールの数など基本的な情報である。検出されたルールの数は86である。
> grule2 <- apriori(QID_625_data1.tran,p=list(support=0.01,confidence=0.5,maxlen=4,ext=TRUE))
parameter specification:
confidence minval smax arem aval originalSupport support minlen maxlen target ext
0.5 0.1 1 none FALSE TRUE 0.01 1 4 rules TRUE
algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[10 item(s), 242 transaction(s)] done [0.00s].
sorting and recoding items ... [10 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [86 rule(s)] done [0.01s].
creating S4 object ... done [0.00s].
writing ... [86 rule(s)] done [0.01s].
ルールが86個できた。
関数 inspect
検出されたルールは、関数inspectを用いて呼び出す。
ルールの条件部(lhs)、結論部(rhs)、支持度(support)、確信度(confidence)、リフト(lift)
> inspect(grule2)
lhs rhs support confidence lhs.support lift
1 {} => {001_吸引力} 0.52892562 0.5289256 1.00000000 1.0000000
2 {004_ノズルの種類数} => {003_運転音} 0.02479339 0.7500000 0.03305785 4.1250000
3 {004_ノズルの種類数} => {008_操作性} 0.01652893 0.5000000 0.03305785 2.0862069
4 {004_ノズルの種類数} => {005_本体重量} 0.02479339 0.7500000 0.03305785 2.2687500
5 {004_ノズルの種類数} => {001_吸引力} 0.01652893 0.5000000 0.03305785 0.9453125
6 {006_デザイン} => {001_吸引力} 0.05785124 0.8750000 0.06611570 1.6542969
7 {007_消費電力} => {008_操作性} 0.05785124 0.5833333 0.09917355 2.4339080
8 {007_消費電力} => {005_本体重量} 0.06611570 0.6666667 0.09917355 2.0166667
9 {007_消費電力} => {001_吸引力} 0.08264463 0.8333333 0.09917355 1.5755208
10 {003_運転音} => {001_吸引力} 0.10743802 0.5909091 0.18181818 1.1171875
支持度(support)を基準としてソートした上位6位のルールを呼び出すinspect
> inspect(head(SORT(grule2, by = "support"),n=6))
lhs rhs support confidence lhs.support lift
1 {} => {001_吸引力} 0.5289256 0.5289256 1.0000000 1.000000
2 {005_本体重量} => {001_吸引力} 0.1818182 0.5500000 0.3305785 1.039844
3 {002_排気} => {001_吸引力} 0.1735537 0.7000000 0.2479339 1.323437
4 {008_操作性} => {005_本体重量} 0.1570248 0.6551724 0.2396694 1.981897
5 {008_操作性} => {001_吸引力} 0.1404959 0.5862069 0.2396694 1.108297
6 {003_運転音} => {001_吸引力} 0.1074380 0.5909091 0.1818182 1.117188
Warning message:
In .local(x, ...) : arules: SORT is deprecated use sort instead.
【分析結果】
支持度が最も高いアイテムは{001_吸引力}で、支持度が最も高い相関ルールは「{005_本体重量} => {001_吸引力}」である。
support=0.03,confidence=00.5 指定
> grulesX <- apriori(QID_625_data1.tran,p=list(support=0.03,confidence=0.05,ext=TRUE))
parameter specification:
confidence minval smax arem aval originalSupport support minlen maxlen target ext
0.05 0.1 1 none FALSE TRUE 0.03 1 10 rules TRUE
algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[10 item(s), 242 transaction(s)] done [0.00s].
sorting and recoding items ... [10 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [81 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
writing ... [81 rule(s)] done [0.00s].
lift>=1.5
gruleX2 <- subset(grulesX,subset=(lift>=1.5))
gruleX2
plot(gruleX2,method="graph")

Association Ruleの評価指標の用語の簡単な解説
前提確率
全体の中でアイテムXを含むトランザクションの比率
前提確率が高いルールは良いルールとされる。
支持度(support):同時確率
全体の中でアイテムXとアイテムYの両方を含むトランザクションの比率
支持度の高いルールは良いルールとされる。
確信度(confidence):条件付き確率
アイテムXを含むトランザクションのうち、アイテムYを含む比率
確信度の高いルールは良いルール
リフト値(lift):改善率
確信度を前提確率で割ったもの
アイテムXを買ってアイテムYを買う確率は、普通にアイテムYが買われる確立の何倍あるのか?
リフト値が1を越えるかどうかが、有効なルールの判断基準のひとつ