この記事は、JAWS-UG DEIにて2024/5/11に開催した、AWS AppFlow と Amazon Bedrockを使ったオリジナルなAIチャットを作ろう!ワークショップ資料です。
利用するAWSサービスの一部に、課金の発生するものが存在します。ワークショップではAWSクーポンを配布しますが、個人的に挑戦される方は、ご利用予定のAWSアカウントについて、無料枠やトライアルの有無について事前にご確認をお願いします。
また、AWSマネージメントコンソールのスクリーンショットは、2024/05時点で撮影されたものを利用しています。今後のAWSアップデートによって、UIやフローが変更される場合もありますので、ご了承ください。
Q: 前のワークショップは終了しましたか?
このワークショップは、2つの記事で構成されています。BedrockナレッジベースやS3バケットの作成については、前のステップで紹介していますので、まずはこちらをお試しください。
ワークショップのゴール
前回のワークショップでは、Amazon Bedrockのナレッジベースを使ったAIチャット(RAGアプリ)をノーコードで作成しました。Amazon S3に任意のデータをアップロードすることで、アップロードされたファイルの内容に基づいた回答文章の生成を行うことができます。
こちらのワークショップでは、RAGアプリが参照するデータの追加・更新についても、ノーコードで自動化する方法を体験します。Amazon AppFlowを利用した定期的なデータのインポート方法を、Stripeを例にして学びます。このワークショップを完了することで、AWS外部のサービスで管理しているデータをAmazon Bedrock ナレッジベースが参照できるようにする方法と、そのデータの同期方法を知ることができます。これによってコードを書かずにRAGやAIチャットとよばれるアプリケーションのPoCやデモを、コードを書かずに構築・提供することが可能になります。
準備するもの
前回のワークショップで作成したリソース( Amazon S3バケット / Amazon Bedrock ナレッジベース / Amazon OpenSearch Serverless )を引き続き利用します。作成がまだという方は、以下の資料を参考に作成しましょう。
ワークショップの流れ
このワークショップでは、作成済みのS3バケットにデータをインポートし、ナレッジベースが変更を同期する仕組みを構築します。
作業の流れは、おおよそ次のとおりです。
- Step1: Amazon AppFlow で 外部のデータをインポートするワークフローを作成
- Step2: Amazon Bedrock ナレッジベースで、データソースを更新する
Step1: Amazon AppFlow で 外部のデータをインポートするワークフローを作成
Amazon AppFlowは、様々なSaaSとAWS間で安全にデータを転送することができるサービスです。今回紹介するStripe以外にも、AsanaやGoogle Ads / Analytics / HubSpotにMarketoなど、非常に多くのサービスとデータを連携することができます。利用しているサービスとも接続できるかは、サポートしているサービスの一覧をご覧ください。
AppFlowを利用するには、検索フォームに appflow と入力し、Amazon AppFlowを選択しましょう。
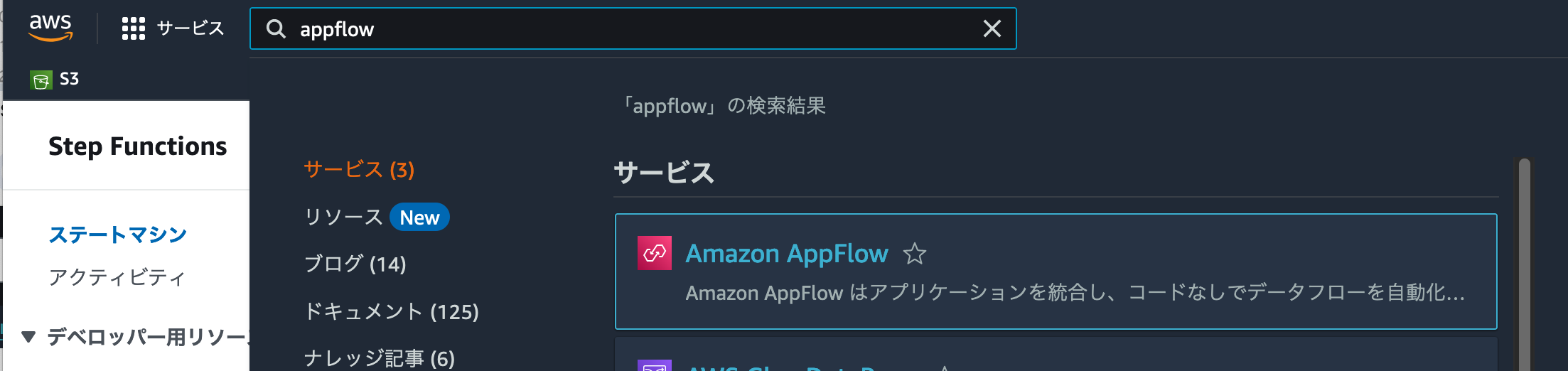
Amazon AppFlowのトップページが表示されました。[フローを作成]をクリックすることで、新しいデータ転送ワークフローを作ることができます。

AppFlowでのフロー作成手順は、5ステップにわかれています。まずはフローの名前や説明文・データ暗号化の設定と、コスト管理などで利用するためのタグ付けを設定しましょう。今回はワークショップですので、フロー名 にworkshop-import-stripe-productsと入力して、[次へ] ボタンをクリックしてください。

手順2では、「どこからどこへデータを転送するか」のフロー設定を行います。ここで設定した内容に基づいて、AppFlowがデータの転送処理を実行するようになります。
ワークフローで転送するデータの送信元を設定する
まずデータの送信元を設定しましょう。[送信元の詳細]セクションにある送信元名をクリックします。今回はデータソースにStripeを利用しますので、stripe と入力しましょう。下の画像のように[Strpie]が表示されますので、これをクリックします。
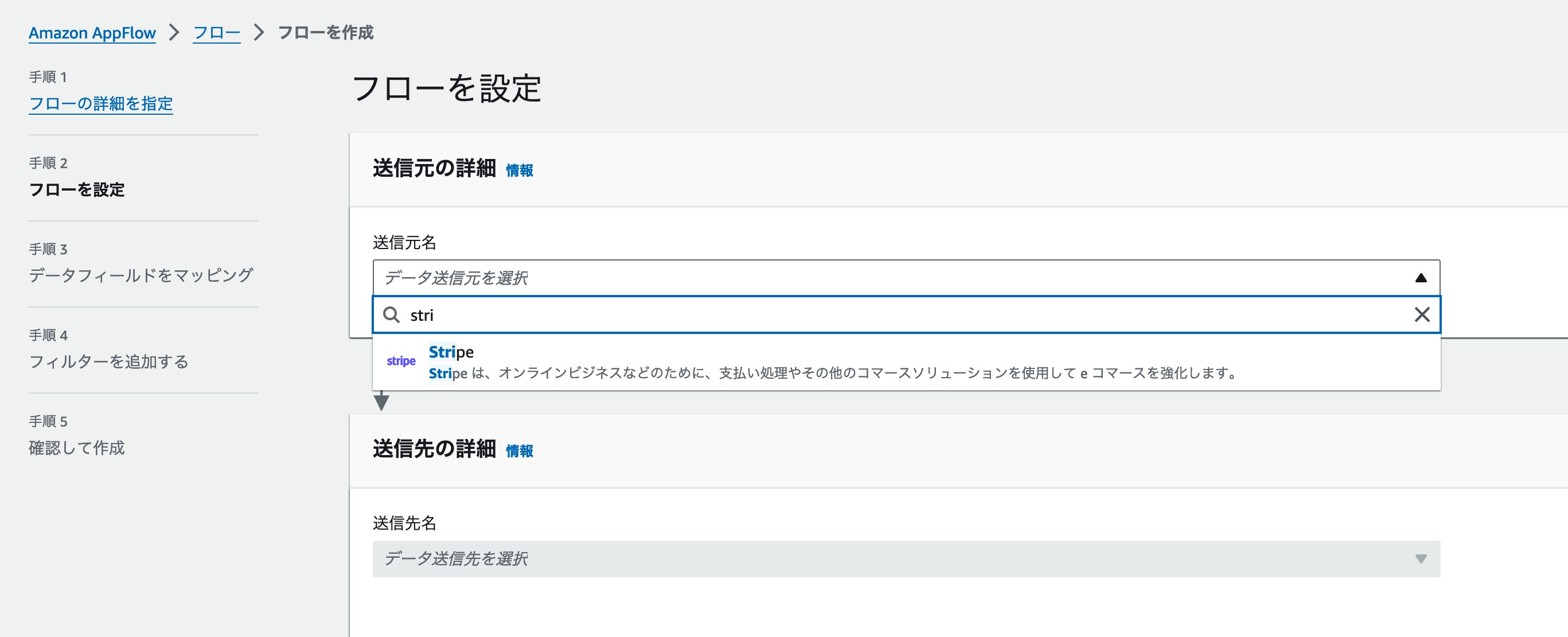
クリックすると、 [送信元の詳細] セクション内にStripe 接続を選択が追加で表示されます。ここでStripeなどの外部サービスとAppFlowを接続するための設定を行います。[新規接続を作成] をクリックしましょう。

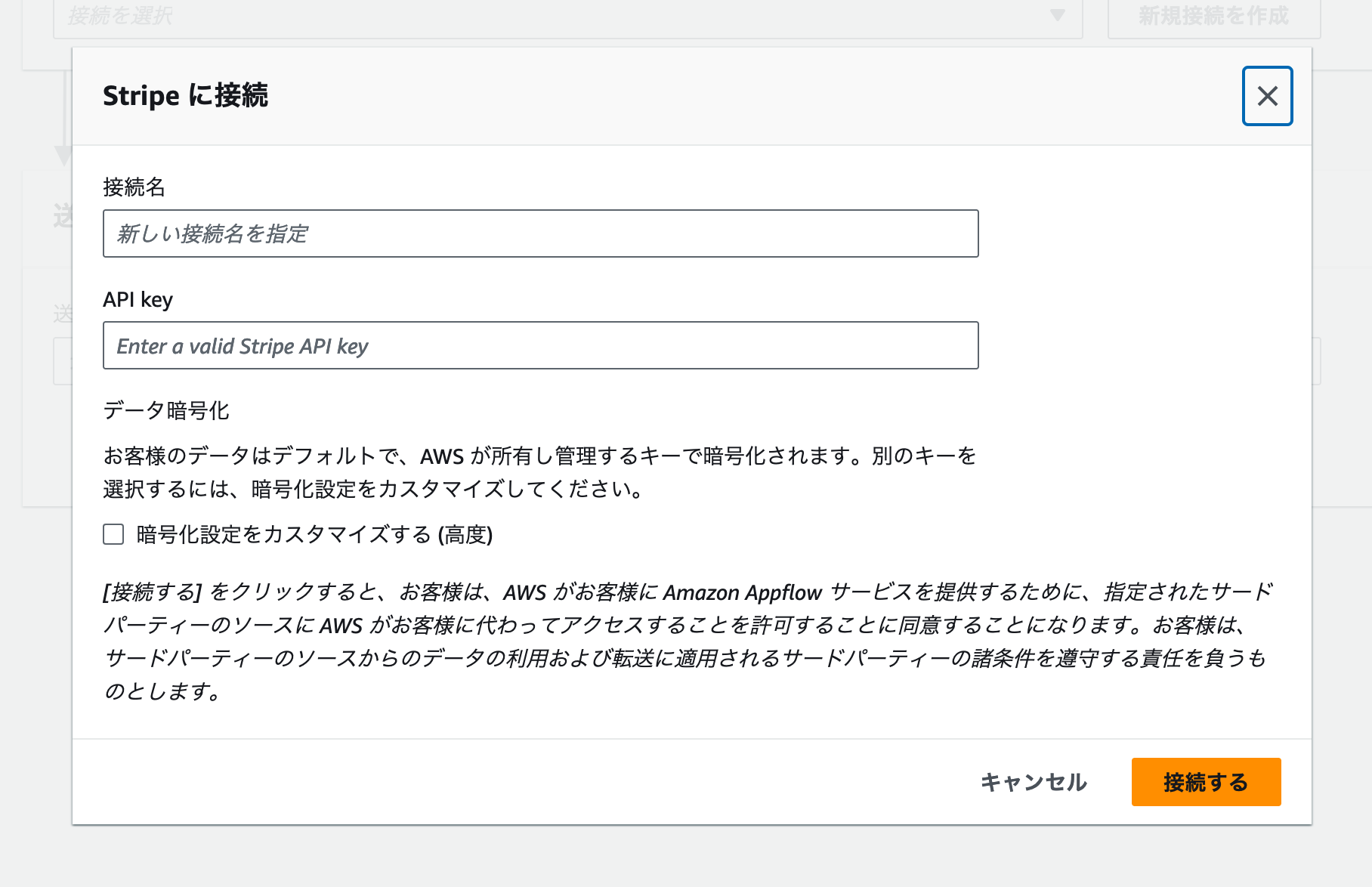
外部サービスとの接続設定を行うためのモーダルが表示されました。Stripeと連携する場合は、シークレットキーまたは制限付きAPIキーをAPI keyに入力します。
StripeのシークレットAPIキーを取得する方法
StripeのAPIキーはStripeダッシュボードから取得できます。検索フォームにapiと入力すると、 [開発者 > APIキー] ページのリンクが検索結果に表示されます。これをクリックしてページに移動しましょう。

APIキー管理ページでは、3つのAPIキーを管理できます。今回はワークショップですので、シークレットキーを取得しましょう。[トークン] 行にある [テストキーを表示] をクリックして、APIキーを取得しましょう。

Stripeダッシュボードで取得したsk_test_xxx始まるシークレットキーをAPI keyに入力しましょう。[接続名] には、今回のワークショップで作成したことがわかるように、stripe-workshopなどの名前をいれましょう。最後に [接続する] ボタンをクリックして、変更を保存します。

モーダルが閉じられて、成功メッセージが出れば作成成功です。Stripe 接続を選択に作成した名前が表示されていることを確認しましょう。
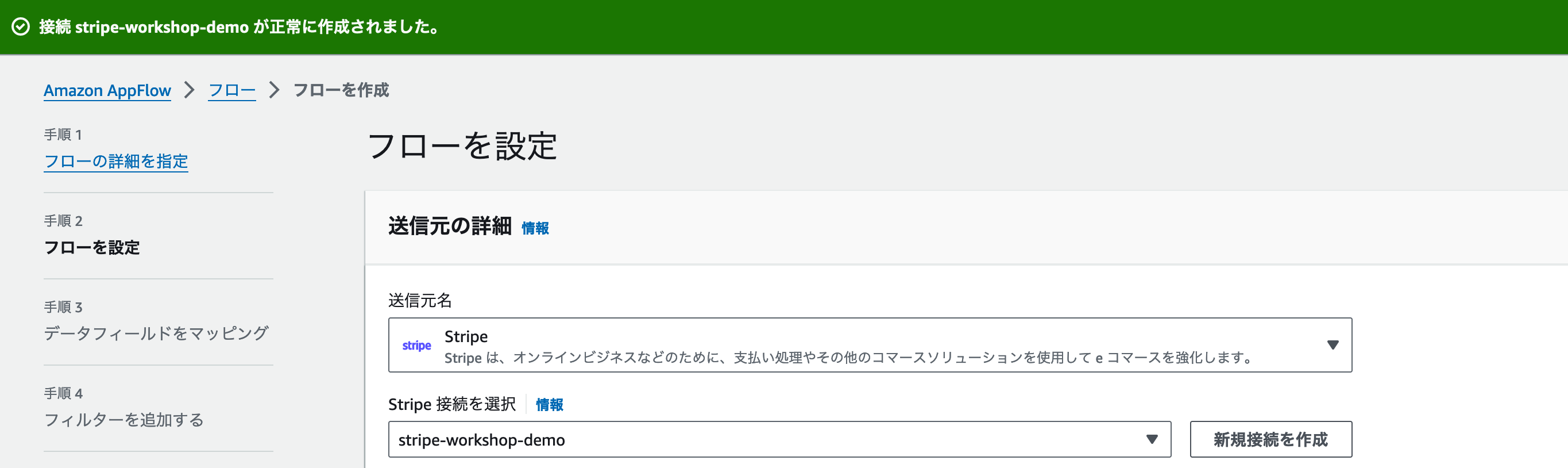
Stripeへの接続に成功していれば、[Stripe オブジェクトを選択] が新しく表示されています。ここでは外部サービスがもつ「どのデータを転送したいか」の設定を行います。今回はStripe上に保存されている商品情報をS3に送信しますので、Product を選択しましょう。

これで送信元の設定は完了です。続いて送信先のサービスについて設定を行いましょう。
データの送信先を設定する
続いてデータの転送先を設定しましょう。今回はBedrock ナレッジベースが同期できる場所にファイルを送信する必要がありますので、Amazon S3を転送先にします。[送信先名] を選択し、[Amazon S3] を選択してください。すると「どのバケットに送信するか」を設定するフィールドが表示されます。

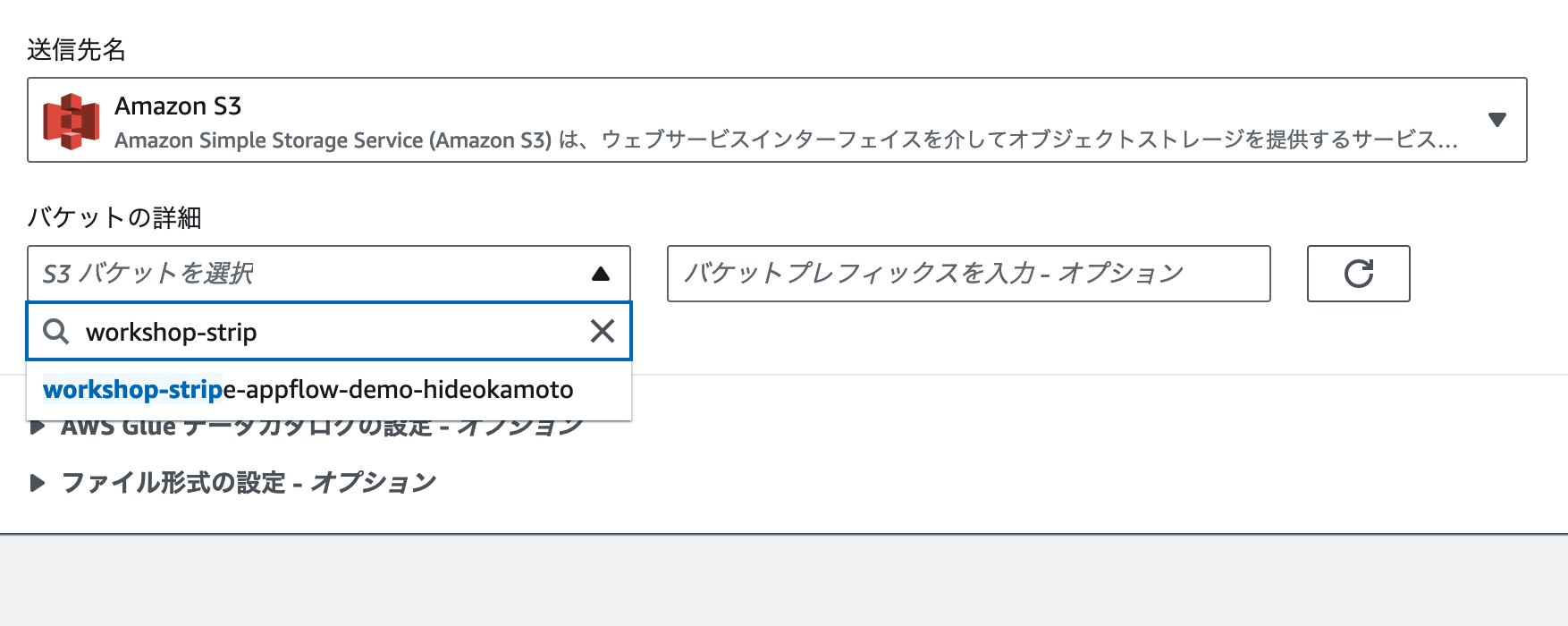
[バケットの詳細] にあるバケットを選択 をクリックすると、そのAWSアカウントにあるS3バケットを表示・検索できます。前のワークショップで作成したS3バケットの名前 を検索して、選択しましょう。バケットプレフィックス やその他の設定項目については、デフォルトの状態のままにしておきます。
データの取り込み頻度を設定する
最後に取り込み頻度を設定します。AppFlowは任意のタイミングでデータを取り込むワークフローを実行できます。今回はワークショップですので、[オンデマンドで実行] を選択しましょう。
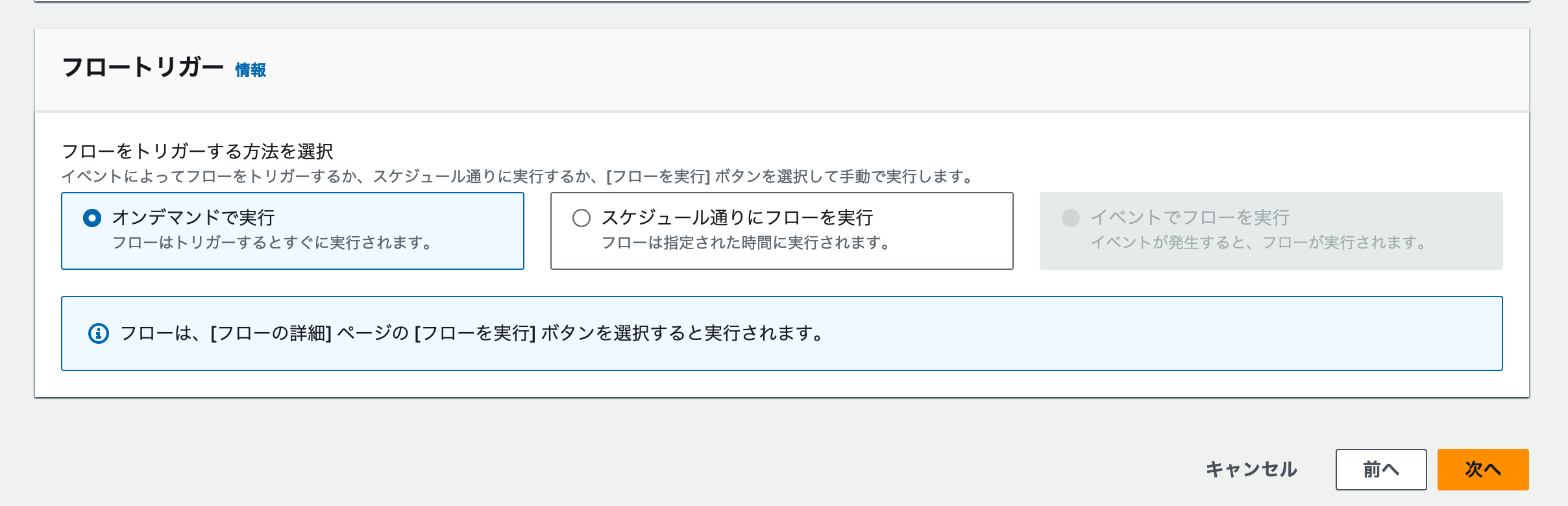
実際のプロジェクトで利用する場合は、[スケジュール通りにフローを実行] を選択しましょう。これによって、定期的なデータの取得と更新をAppFlow上の設定だけで定期実行できるようになります。
ここまでの設定が完了したら、[次へ] をクリックしましょう。
どんなデータを送信するかをマッピングする
AppFlowでは、送信元から取得したデータのマッピングも行うことができます。必要なデータだけ送信することによって、S3のストレージコストを削減したり、Bedrock ナレッジベースが参照するデータのノイズを減らすことができます。
マッピング方法は2種類あり、ワークショップは動作確認であれば [手動でフィールドをマッピングする] の選択をお勧めします。マッピング内容が複雑な場合や、複数のワークフローで同じ設定を行いたい場合などでは、CSVファイルを作成して読み込ませる方法がより便利です。

[手動でフィールドをマッピングする] を選択した場合、このページでマッピング操作を行います。送信元がどのようなデータを送信するかについては、AppFlow側が認識していますので、チェックボックスのオンオフで利用するフィールドを選択しましょう。今回のワークショップでは、以下のフィールドにチェックをつけましょう。
| name | description |
|---|---|
| id | Stripe上の商品ID |
| name | 商品の名前 |
| active | その商品が利用可能か否か |
| description | 商品の説明文 |
| metadata | 商品に登録されたメタデータ |

送信したいフィールドを選択した後、 [フィールドを直接マッピングする] をクリックしましょう。
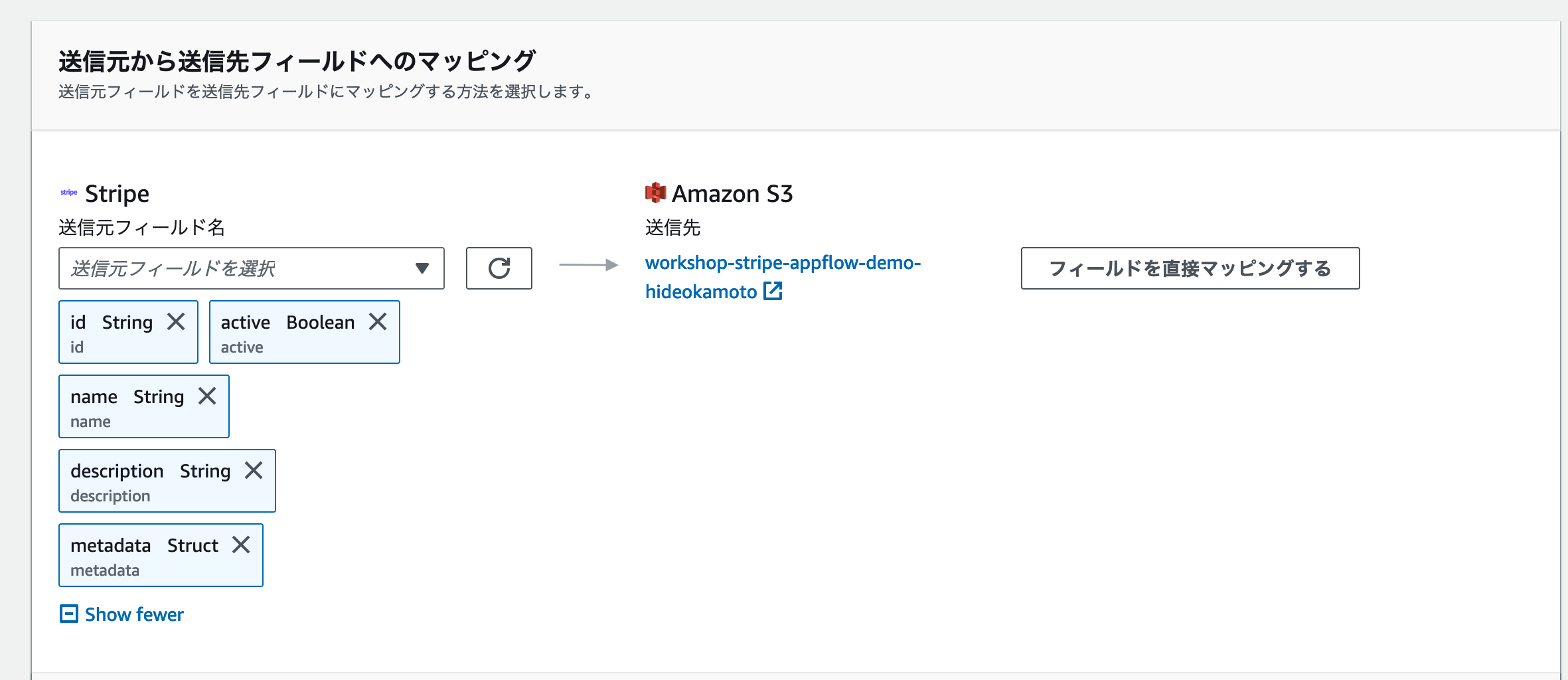
送信元でのフィールド名やデータの簡単な加工を行う式の設定が、マッピング画面では設定できます。今回はデータをそのままS3バケットに送信しますので、 デフォルトで表示されている設定 をそのまま使いましょう。

このページでは、他にパーティションや集約の設定と無効なデータの処理のセクションもあります。「欠損しているデータがある場合に、ワークフローを中断する or そのデータを除外する」のような設定が行えます。今回はワークショップですので、操作はせずに、次に進みましょう。

除外したいデータのフィルター設定を行う
サービス連携では、「欠損データではないが、取り込みたくないデータではある」ケースも存在します。その場合はこの [フィルターを追加する] ステップで設定しましょう。 [フィルターを追加する] ボタンをクリックすると、「特定のフィールドが条件を満たした場合に、転送しないようにフィルターする」設定が行えます。
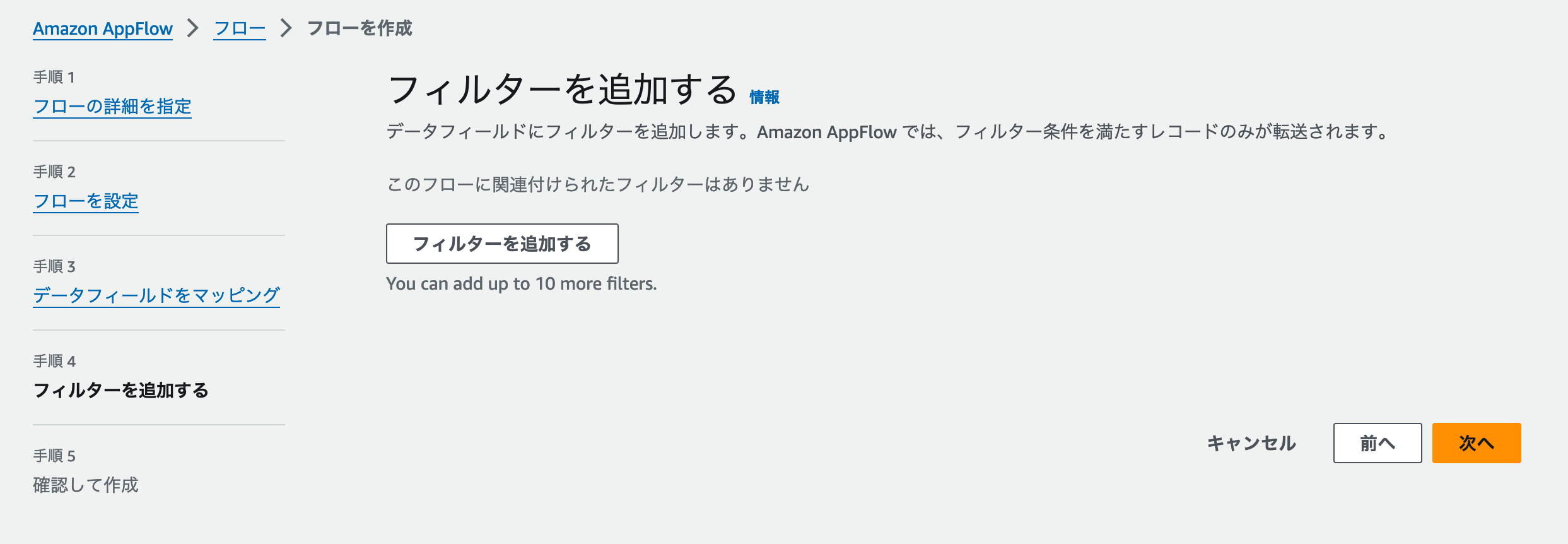
Stripeの商品データの場合、activeフィールドを使って「販売停止している商品データは、除外する」設定が行えます。以下の表とスクリーンショットを参考に設定してみましょう。
| フィールド名 | 条件 | 条件1 |
|---|---|---|
| active | が次の値と完全に一致する | true |

これでBedrock ナレッジベースによる商品のレコメンドの際に、販売終了している商品をお勧めされないようにできました。[次へ] をクリックして、確認画面に進みましょう。
設定の確認と作成・データの取り込み
設定内容に問題がないかを確認して、フローを作成します。
作成に成功すると、作成したフローの詳細画面に移動します。これでStripeの情報をS3に取り込む準備ができました。早速 [フローを実行] をボタンをクリックして、データの取り込みをはじめましょう。

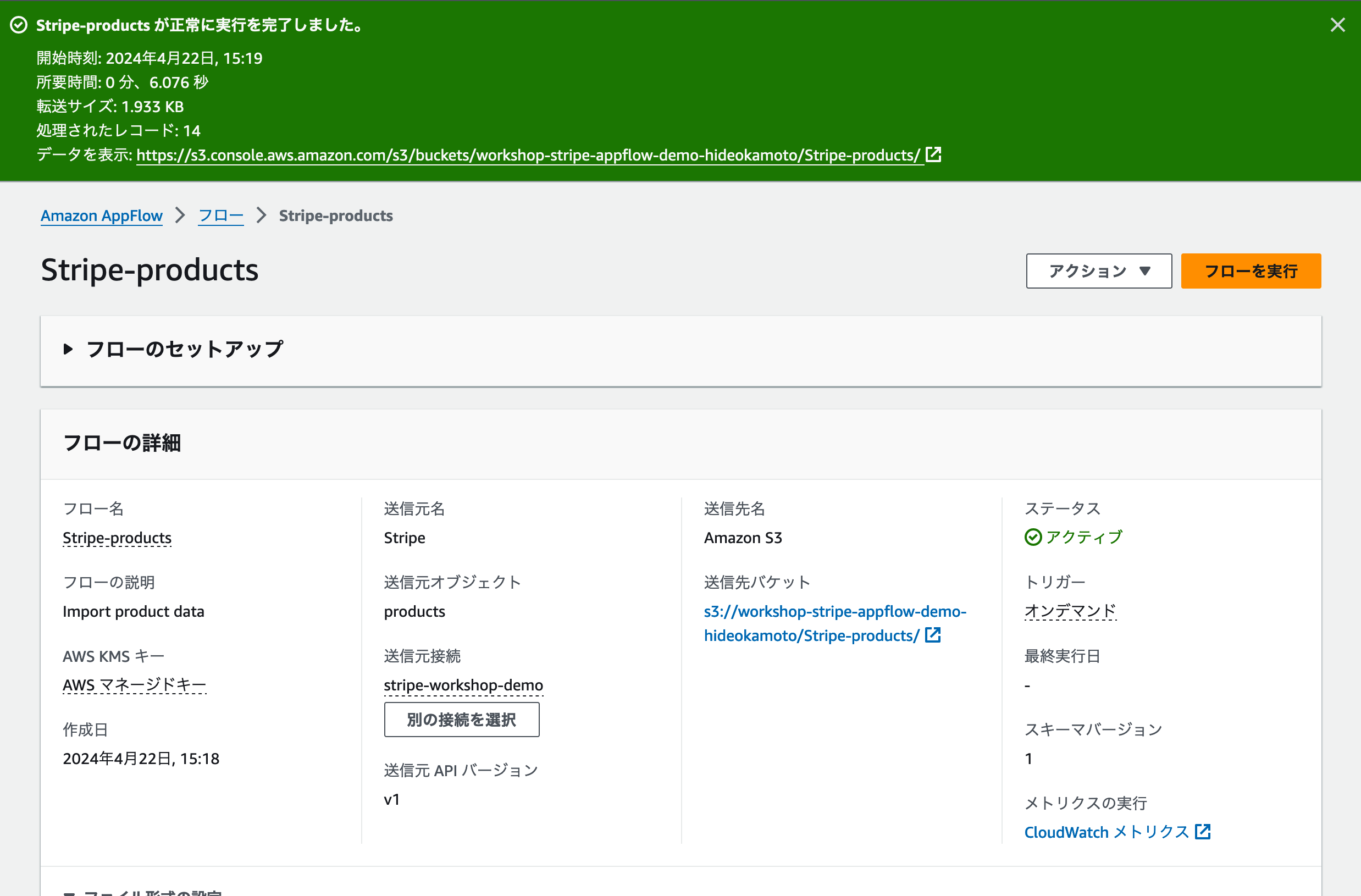
データの取り込みには少し時間がかかります。これはデータの量などで左右されますので、完了メッセージが出るまで気長に待ちましょう。

完了すると、下のスクリーンショットのように成功メッセージが表示されます。これでStripeからS3にデータを取り込むことができました。
取り込まれたデータを確認する
取り込みに成功したかどうかは、S3バケットをみることでも確認できます。AppFlowで送信先に設定したS3バケットに移動すると、新しいフォルダが追加されています。

この中にあるファイルをダウンロードして開くと、次のようなデータが保存されていることが確認できます。
{"id":"prod_PuX48cRgmHju58","active":true,"name":"定期サポート","description":null,"metadata":{}}
{"id":"prod_OnWY2V0PY6Nf9H","active":true,"name":"スタンダードプラン","description":null,"metadata":{}}
{"id":"prod_OFnvbuUUnOze0I","active":true,"name":"ファイルストレージ","description":null,"metadata":{}}
{"id":"prod_OFnppeR9bkPzHx","active":true,"name":"エンタープライズプラン","description":null,"metadata":{}}
{"id":"prod_NxtZPS50saFlGM","active":true,"name":"コーヒー豆定期お届け便","description":"厳選したコーヒー豆を、定期的にお届けします。","metadata":{}}
{"id":"prod_Nx9ej4SShtL26Q","active":true,"name":"test","description":null,"metadata":{}}
{"id":"prod_Nuq0TmGran7dKW","active":true,"name":"プレミアムコーヒー豆セット","description":null,"metadata":{}}
{"id":"prod_LXIoekhGy8a6RX","active":true,"name":"コーヒードリッパー(布)","description":"布製のコーヒードリッパーです。","metadata":{}}
{"id":"prod_LXImKA63G85Om5","active":true,"name":"焙煎済みコーヒー豆","description":"焙煎済みのコーヒー豆です。","metadata":{}}
{"id":"prod_LXIlPCBm2Sm9qG","active":true,"name":"あまおう(小粒)","description":"小粒のあまおうを1パックにまとめました","metadata":{}}
{"id":"prod_LXIkjGhz3qmLmO","active":true,"name":"季節の野菜セット","description":"季節に応じた野菜を厳選してお届けします","metadata":{}}
{"id":"prod_LXIfs7eTYBzJwi","active":true,"name":"とうもろこし","description":"産地直送のとうもろこしです。","metadata":{}}
{"id":"prod_LXIVIHcf3KeEBk","active":true,"name":"松坂牛ステーキ2枚セット","description":"松坂牛のステーキ2枚セットを毎月お届けします。*冷凍","metadata":{}}
Step2: Amazon Bedrock ナレッジベースで、データソースを更新する
StripeのデータをS3に転送することができました。このデータをBedrock ナレッジベースで利用するには、データを同期する必要があります。検索フォームに [Bedrock] と入力し、Amazon Bedrockの管理画面に移動しましょう。
前のワークショップで作成したBedrock ナレッジベースの詳細画面に移動しましょう。前回のワークショップで操作した際と同様にデータの取り込み操作を行います。
ナレッジベース詳細画面でページをスクロールし、ページ中段にある[データソース]セクションへ移動します。同期したいデータソースを選択し、 [同期] ボタンをクリックしましょう。
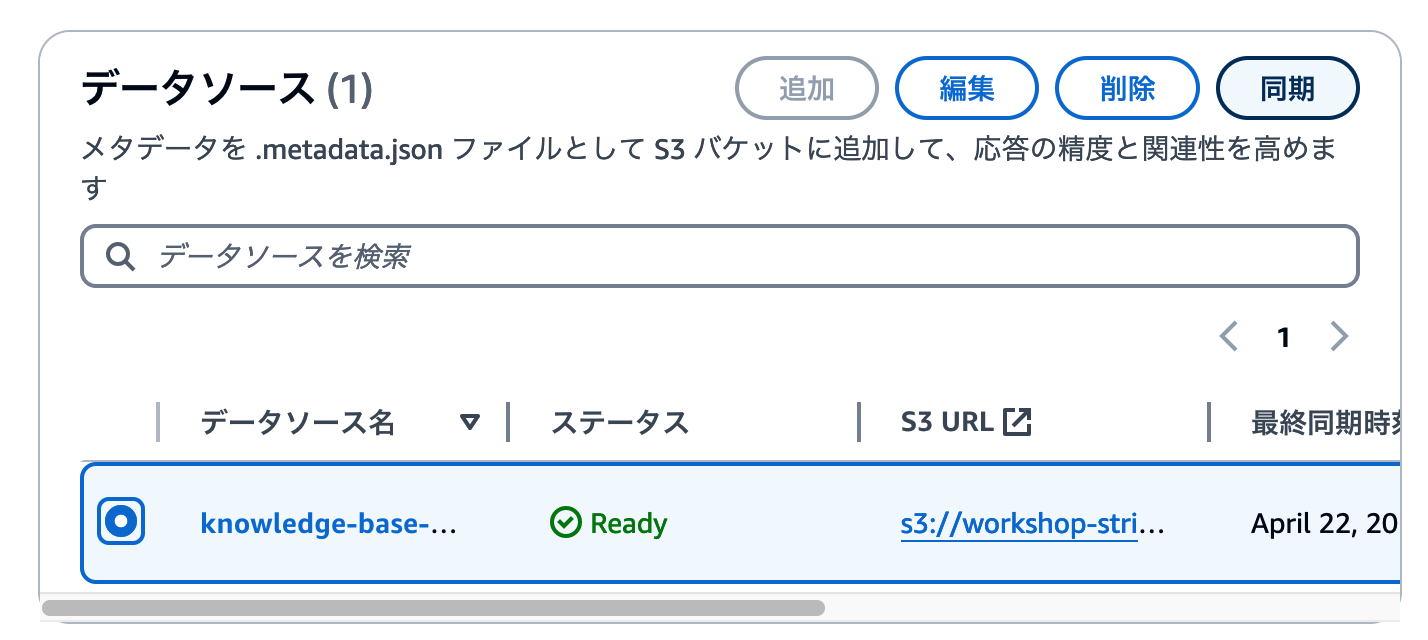
ページ上部に同期を開始したメッセージが表示されます。1・2分程度で同期が完了しますので、下のスクリーンショットのように完了画面が出るのを待ちましょう。
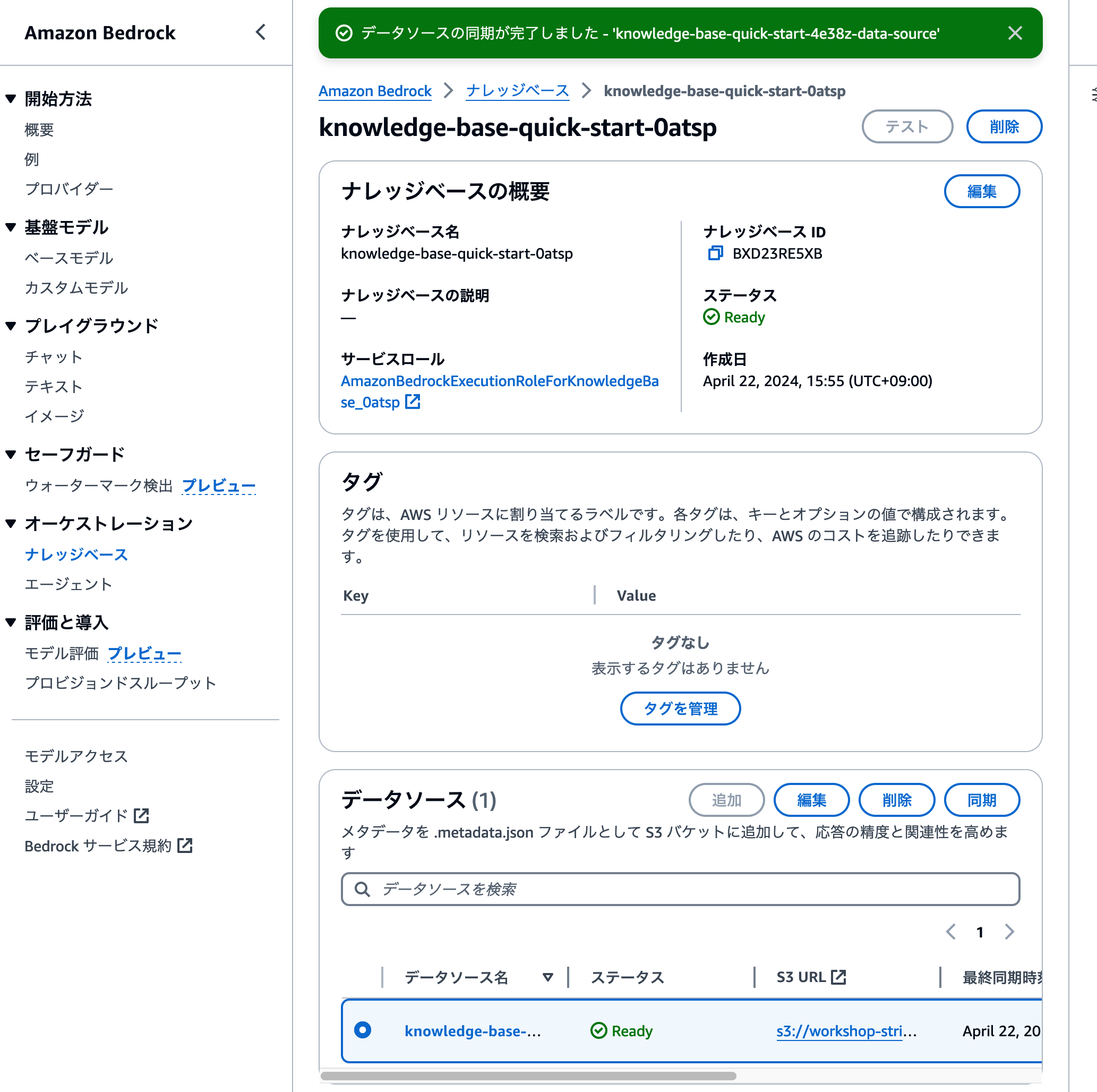
これでデータの取り込みが完了しました。ナレッジベースのテスト機能を利用して、商品のおすすめができているかを確認しましょう。

Stripeに登録している商品情報について紹介する回答文章が生成されていれば、連携成功です。
おまけ: CloudShell と AWS CLIで、Bedrock ナレッジベースに質問を送信してみる
せっかくですので、実際の組み込みをイメージしてプログラムから質問を送信してみましょう。AWSでは、ブラウザ上でAWS CLIを利用してAWSのAPIを呼び出すことができる、AWS CloudShellが提供されています。

検索フォームに [Shell] と入力し、 CloudShell の管理画面に移動しましょう。

CloudShellの紹介モーダルが表示されることもありますが、 [閉じる] を押してもらえればOKです。

CloudShellでは、文字通りブラウザ上でシェルコマンドを実行できます。

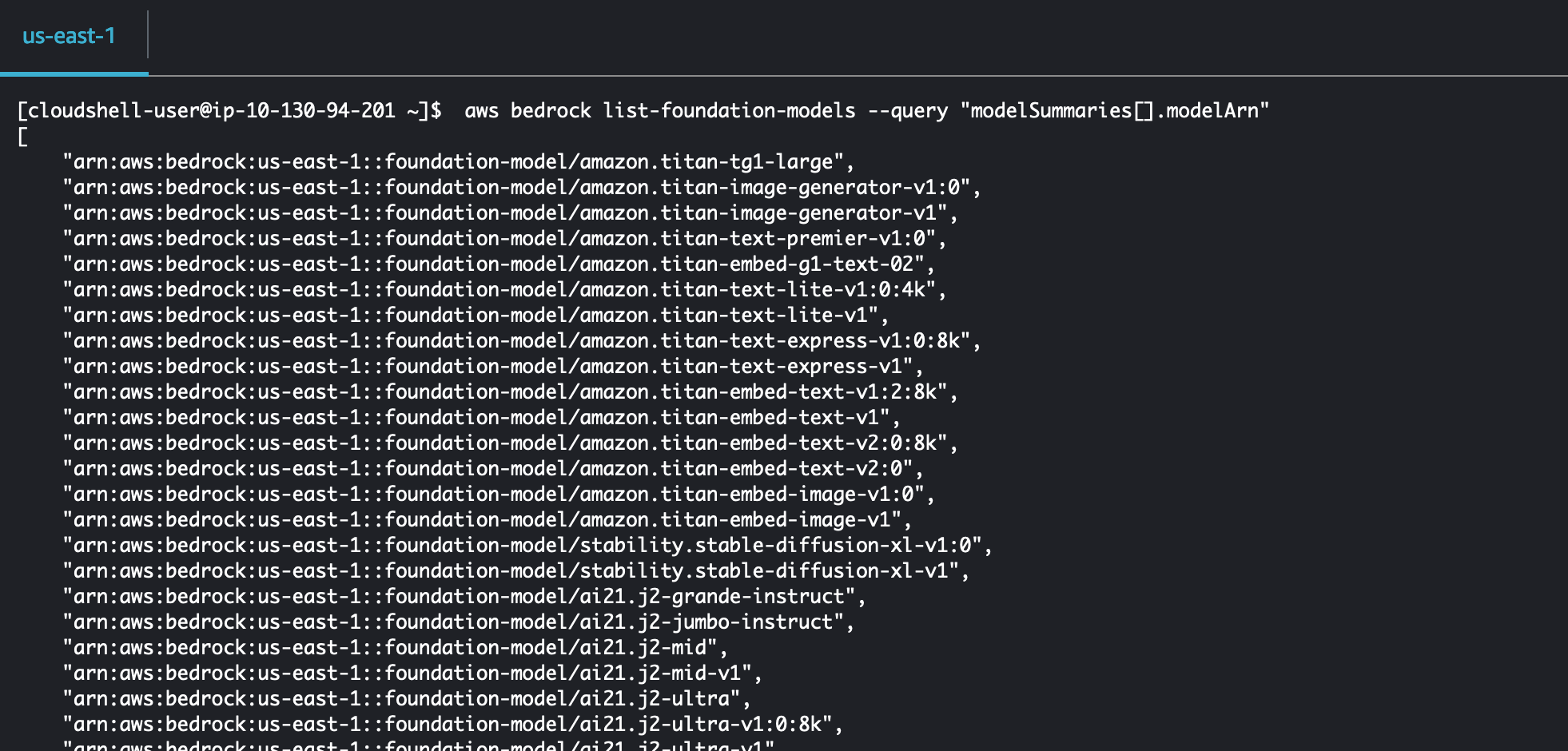
試しにaws bedrock list-foundation-models --query "modelSummaries[].modelArn"をコピーアンドペースとして実行してみましょう。実行すると、利用可能なLLMのARNが一覧で表示されます。
AWS CLIでナレッジベースに質問を送信する場合、aws bedrock-agent-runtime retrieve-and-generateコマンドを実行します。このコマンドは、次のような値を設定して実行します。
aws bedrock-agent-runtime retrieve-and-generate \
--input text="質問文をここに入れる" \
--retrieve-and-generate-configuration type=KNOWLEDGE_BASE,knowledgeBaseConfiguration="{knowledgeBaseId={Knowledge baseのID},modelArn={利用するモデルのARN}}"
{Knowledge baseのID}は、作成したナレッジベースの詳細画面から確認できます。ナレッジベースの概要 セクションに表示されているナレッジベースID をコピーしてコマンドの{Knowledge baseのID}部分に設定しましょう。
また、{利用するモデルのARN}については、先ほどaws bedrock list-foundation-models --query "modelSummaries[].modelArn"を実行して表示された結果から、利用したいモデルのARNをコピーして設定しましょう。例えばAnthropicのClaude3 Sonnetを、us-east-1リージョンで使うのであれば、arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0を設定します。
aws bedrock-agent-runtime retrieve-and-generate \
--input text="質問文をここに入れる" \
--retrieve-and-generate-configuration type=KNOWLEDGE_BASE,knowledgeBaseConfiguration="{knowledgeBaseId=ABCDEFGH,modelArn=arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0}"
あとは質問文をtext部分に設定すればOKです。例えばコーヒー豆のサブスクリプションがあるかどうかを聞いてみましょう。
aws bedrock-agent-runtime retrieve-and-generate \
--input text="コーヒー豆のサブスクリプションはありますか?" \
--retrieve-and-generate-configuration type=KNOWLEDGE_BASE,knowledgeBaseConfiguration="{knowledgeBaseId=ABCDEFGH,modelArn=arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0}"
このコマンドをCloudShellで実行すると、生成されたテキストがJSON形式で表示されます。

$ aws bedrock-agent-runtime retrieve-and-generate \
> --input text="コーヒー豆のサブスクリプションはありますか?" \
> --retrieve-and-generate-configuration type=KNOWLEDGE_BASE,knowledgeBaseConfiguration="{knowledgeBaseId=XXXXX,modelArn=arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2}"
{
"citations": [
{
"generatedResponsePart": {
"textResponsePart": {
"span": {
"end": 27,
"start": 0
},
"text": "はい、コーヒー豆のサブスクリプションサービスがあります。"
}
},
"retrievedReferences": [
{
"content": {
"text": "{\"id\":\"prod_PuX48cRgmHju58\",\"active\":true,\"name\":\"定期サポート\",\"description\":null,\"metadata\":{}} {\"id\":\"prod_OnWY2V0PY6Nf9H\",\"active\":true,\"name\":\"スタンダードプラン\",\"description\":null,\"metadata\":{}} {\"id\":\"0001\",\"active\":true,\"name\":\"kintoneプラグイン開発\",\"description\":null,\"metadata\":{}} {\"id\":\"prod_OFnvbuUUnOze0I\",\"active\":true,\"name\":\"ファイルストレージ\",\"description\":null,\"metadata\":{}} {\"id\":\"prod_OFnppeR9bkPzHx\",\"active\":true,\"name\":\"エンタープライズプラン\",\"description\":null,\"metadata\":{}} {\"id\":\"prod_NxtZPS50saFlGM\",\"active\":true,\"name\":\"コーヒー豆定期お届け便\",\"description\":\"厳選したコーヒー豆を、定期的にお届けします。\""
},
"location": {
"s3Location": {
"uri": "s3://workshop-stripe-appflow-demo-XXXXX/Stripe-products/d2c6935c-a837-497f-af32-bb2341363465/634703275-2024-04-22T06:19:47"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-uri": "s3://workshop-stripe-appflow-demo-XXXXX/Stripe-products/d2c6935c-a837-497f-af32-bb2341363465/634703275-2024-04-22T06:19:47"
}
}
]
}
],
"output": {
"text": "はい、コーヒー豆のサブスクリプションサービスがあります。"
},
"sessionId": "2c32e729-df85-46aa-98b2-4fd243cf7ae9"
}
実際の開発では、このAWS CLIコマンドをAWS SDKやLangChainなどのフレームワークから利用して実装します。
このようにCloudShellを利用することで、組み込み時のパラメータやレスポンスの確認も、ブラウザ上で完結できます。
リソースの削除
最後にワークショップで作成した資料を削除しましょう。
ナレッジベースの削除
ナレッジベースの削除は、ナレッジベース詳細画面で行います。[削除] ボタンをクリックしましょう。

削除操作用のモーダル画面が表示されます。Delete underlying vector dataのチェックボックスをオンにして、deleteと入力しましょう。
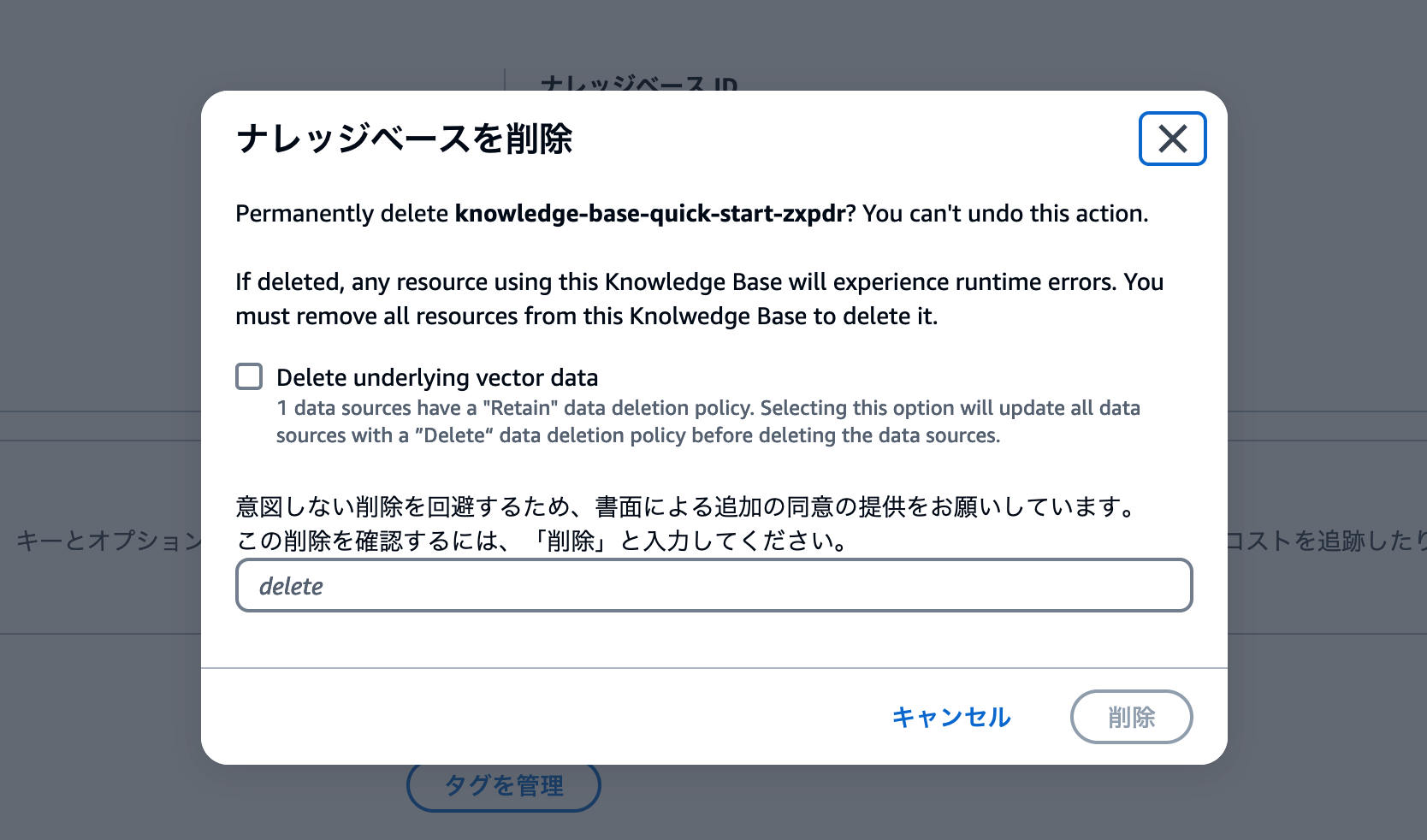
以下のスクリーンショットと同じ状態になっていることを確認して、削除 ボタンをクリックします。
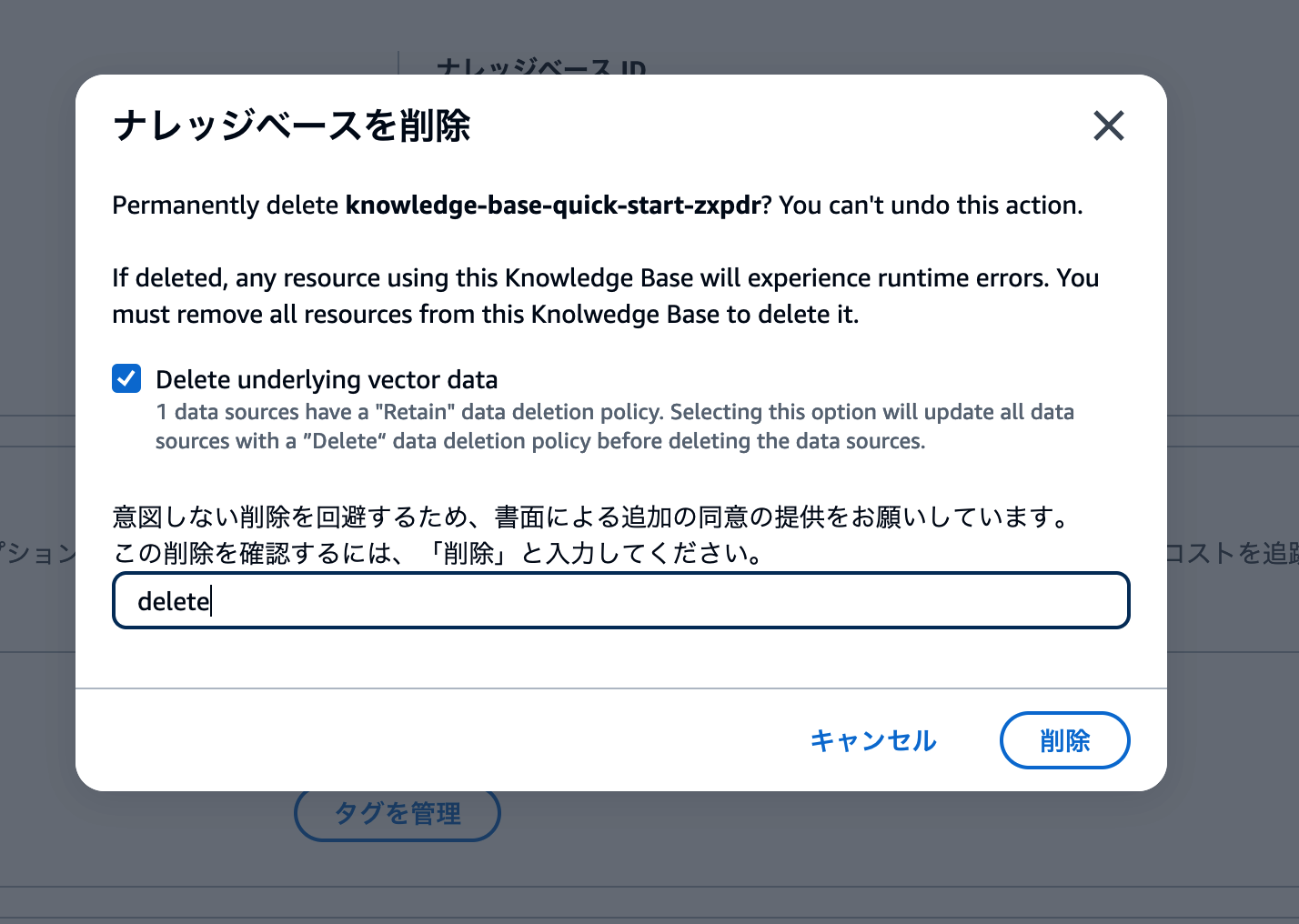
削除に成功したメッセージを確認して、削除作業終了です。
OpenSearch Serviceの削除
つづいてOpenSearch Serviceも削除しましょう。検索フォームにOpenSearchと入力して、Amazon OpenSearch Serviceに移動しましょう。
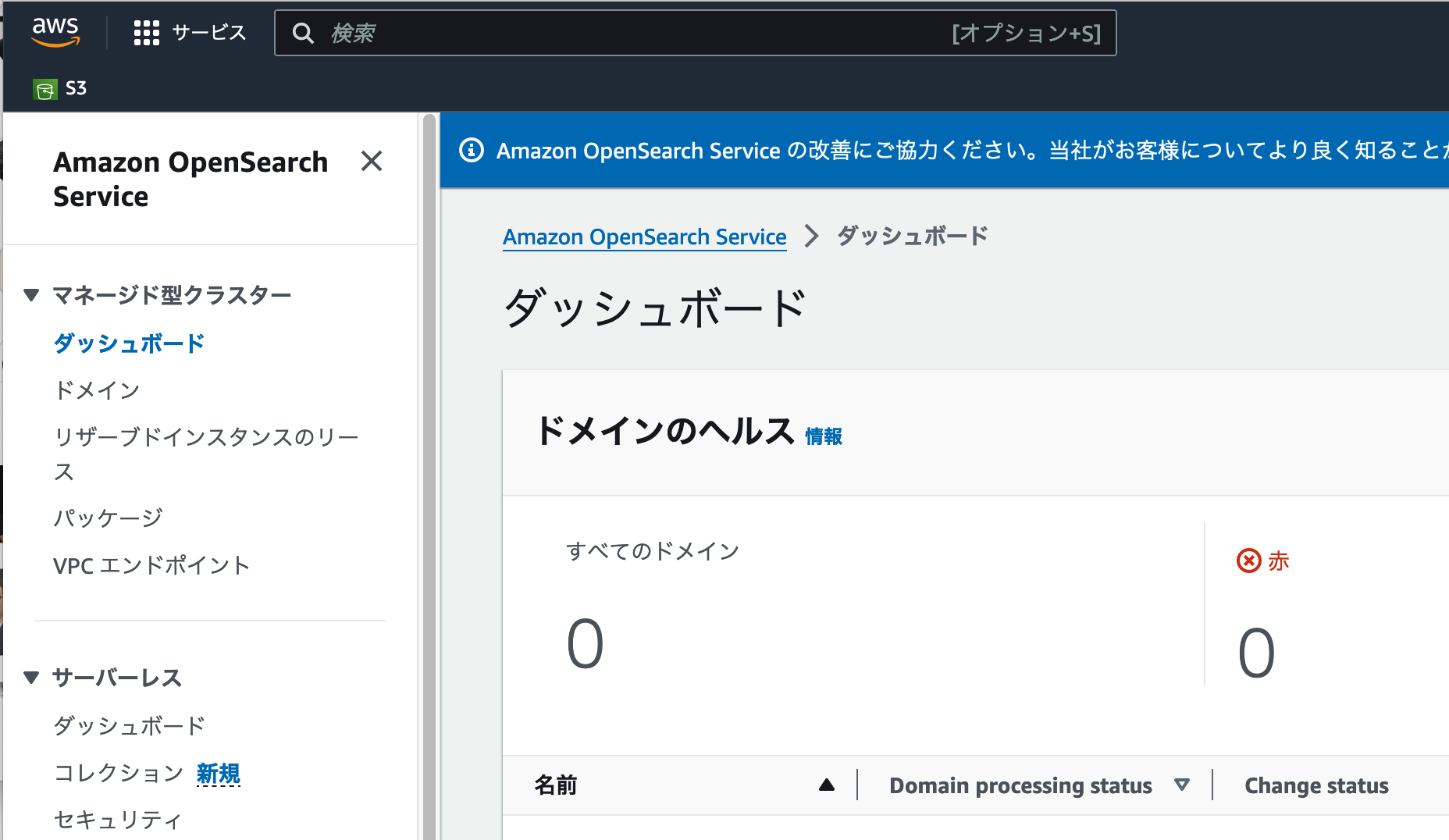
ダッシュボードに移動すると、一見リソースが何もないように見えます。しかしBedrockナレッジベースが生成するのは、サーバーレスなOpenSearch Serviceです。左側のメニューで**[サーバーレス > ダッシュボード]** をクリックしましょう。
サーバーレスのダッシュボードに移動すると、コレクションセクションにリソースが表示されました。
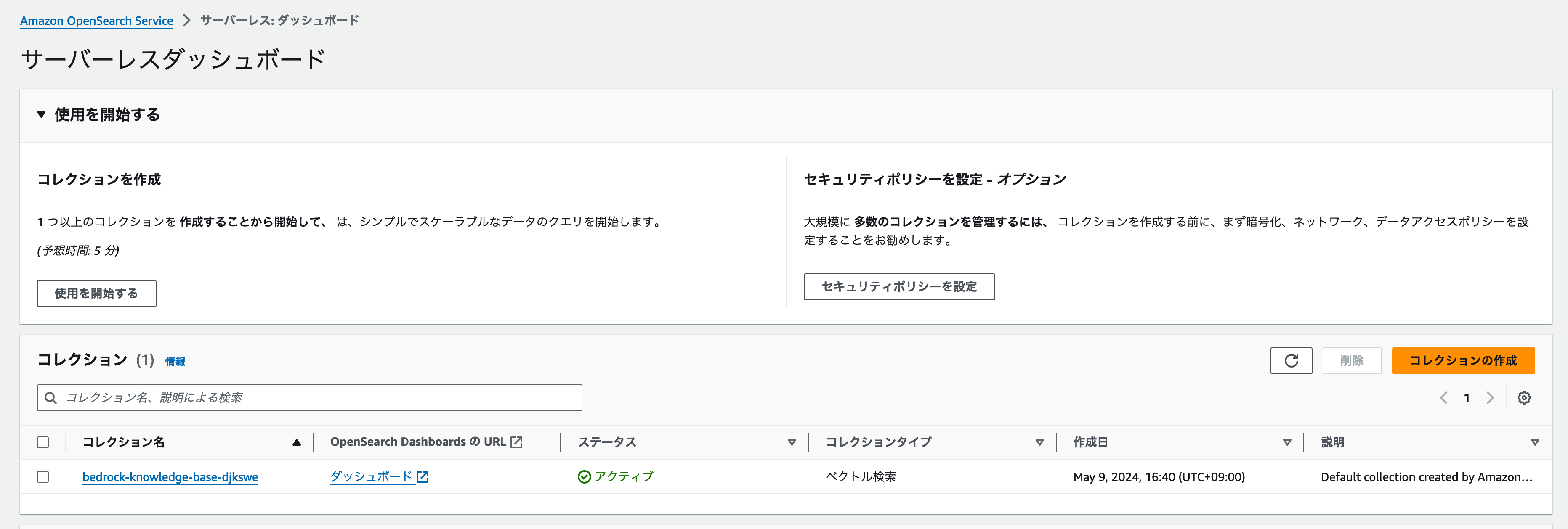
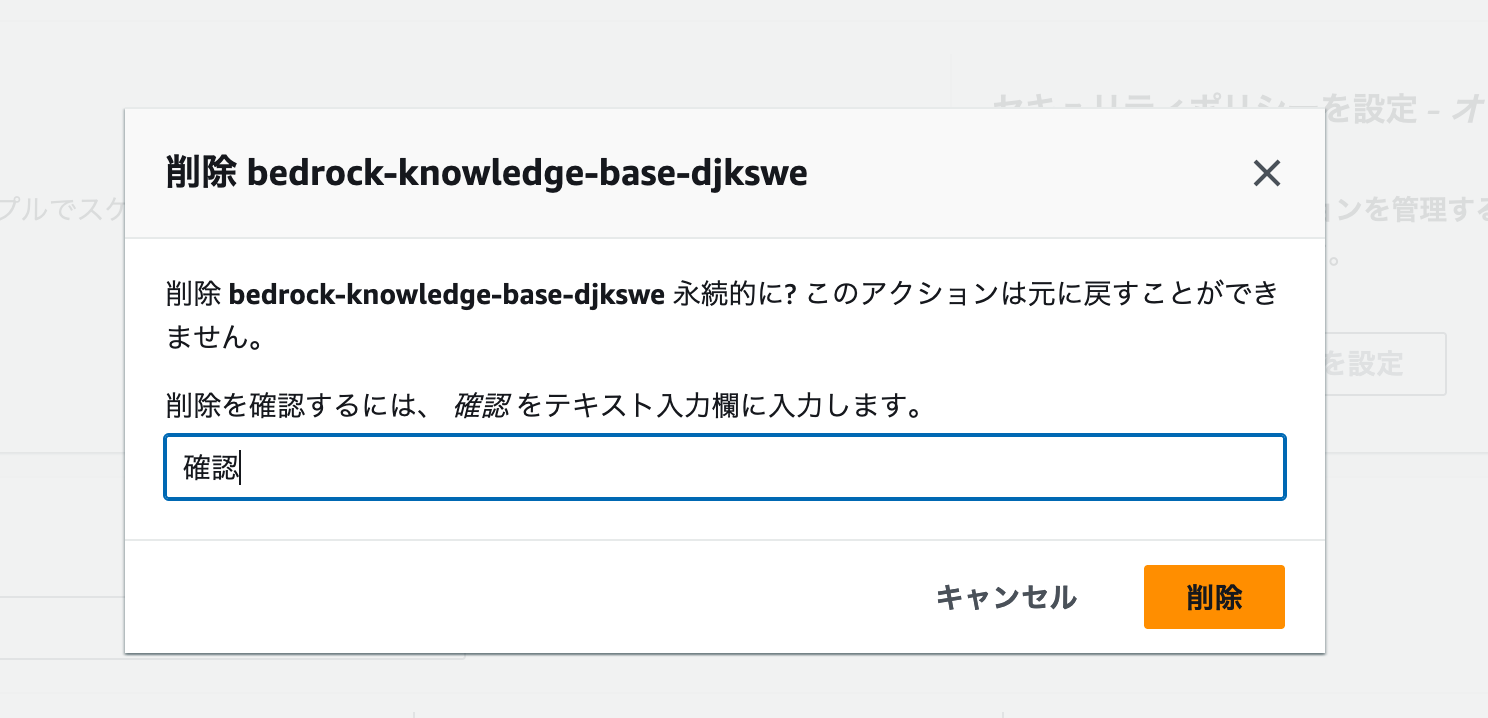
削除するコレクションにチェックを入れて、**[削除]**ボタンをクリックしましょう。

削除前の確認画面が開きます。ここでは確認 とフォームに入力します。
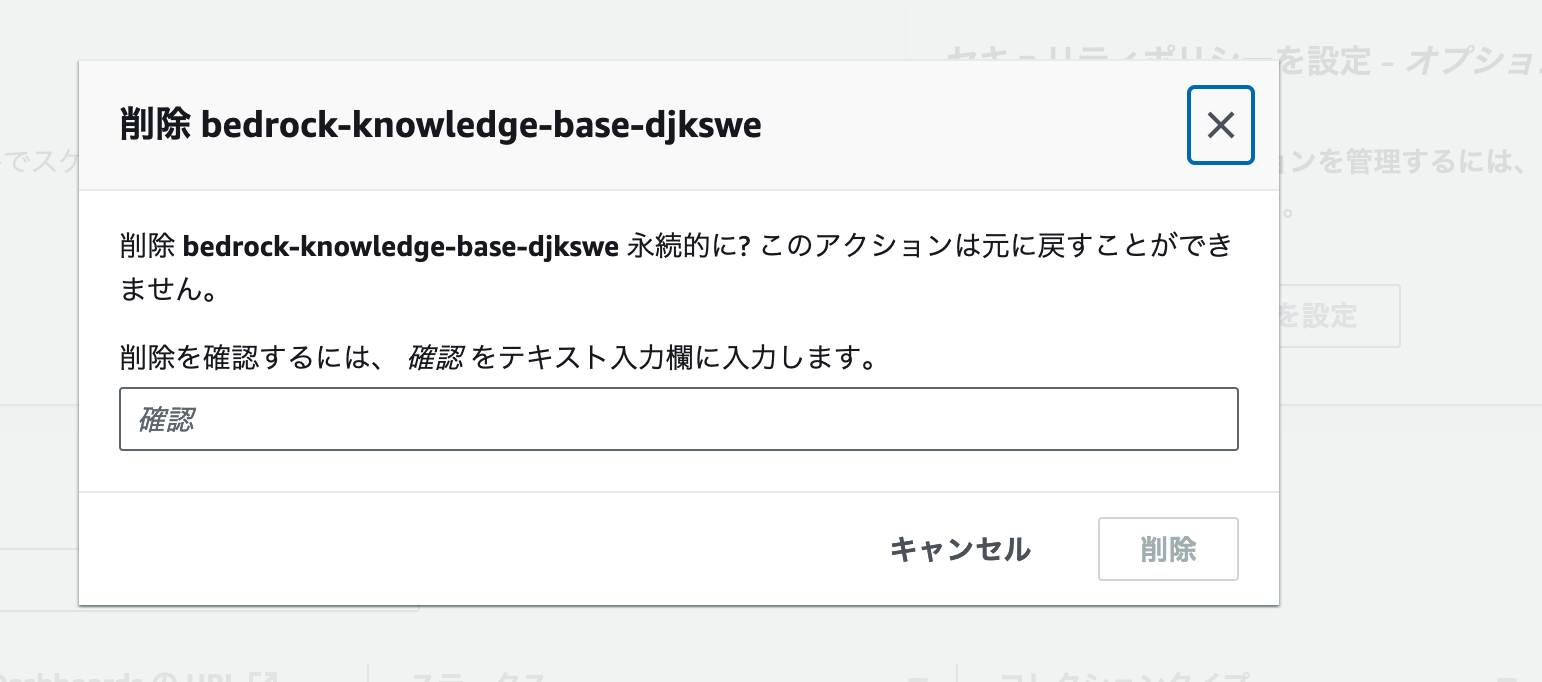
以下のスクリーンショットと同じ状態になっていることを確認して、削除 ボタンをクリックします。
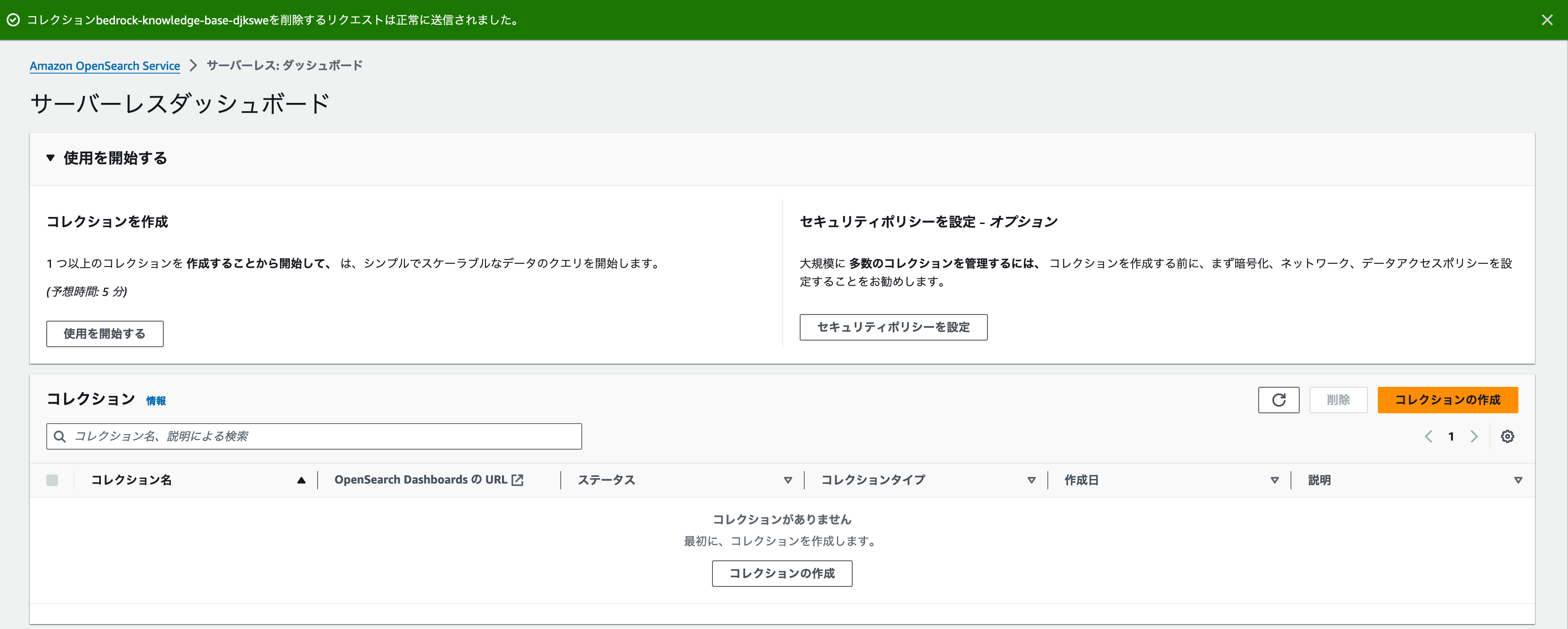
削除に成功したメッセージが表示され、コレクションセクションにリソースがなくなれば、削除成功です。
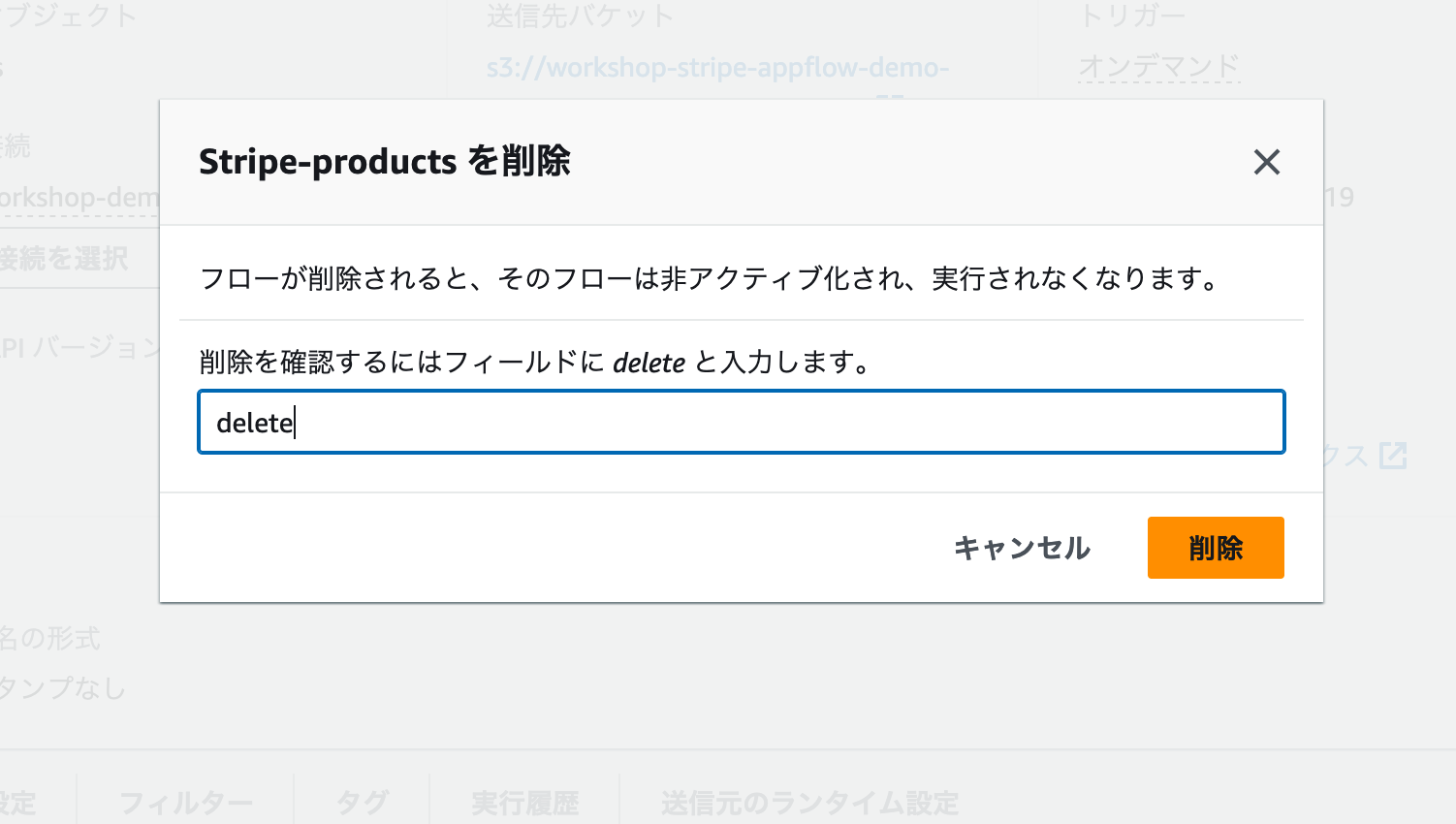
AppFlowワークフローの削除
AppFlowのワークフローを削除する場合、作成したワークフローの詳細画面を開きましょう。[アクション] の中にフローを削除 がありますので、これをクリックします。

削除確認のモーダルが開きますので、delete と入力して削除しましょう。
Secrets Managerの削除
AppFlowで外部サービスに接続する設定を追加した場合、APIキーなどの情報はSecrets Managerに保存されています。このデータが削除されているかを確認しておきましょう。検索フォームにSecrets と入力して、Secrets Manager管理画面に移動します。

AppFlowが作成したシークレットは、appflow!から始まる名前で保存されています。検索フォームにappflowと入力して、今回のワークショップで追加したワークフロー・接続名と同じものがないか確認してください。

もしシークレットが残っている場合は、そのシークレットの詳細ページに移動します。 [アクション] の中に シークレットを削除する がありますので、これで削除します。

S3バケットの削除
S3バケットも削除しましょう。管理画面で削除したいバケットを選択し、[削除] ボタンをクリックします。

S3バケットを削除するには、バケットの中身が完全に空である必要があります。削除画面にバケットを空にする ボタンが表示されている場合は、これをクリックして中身を空にしましょう。
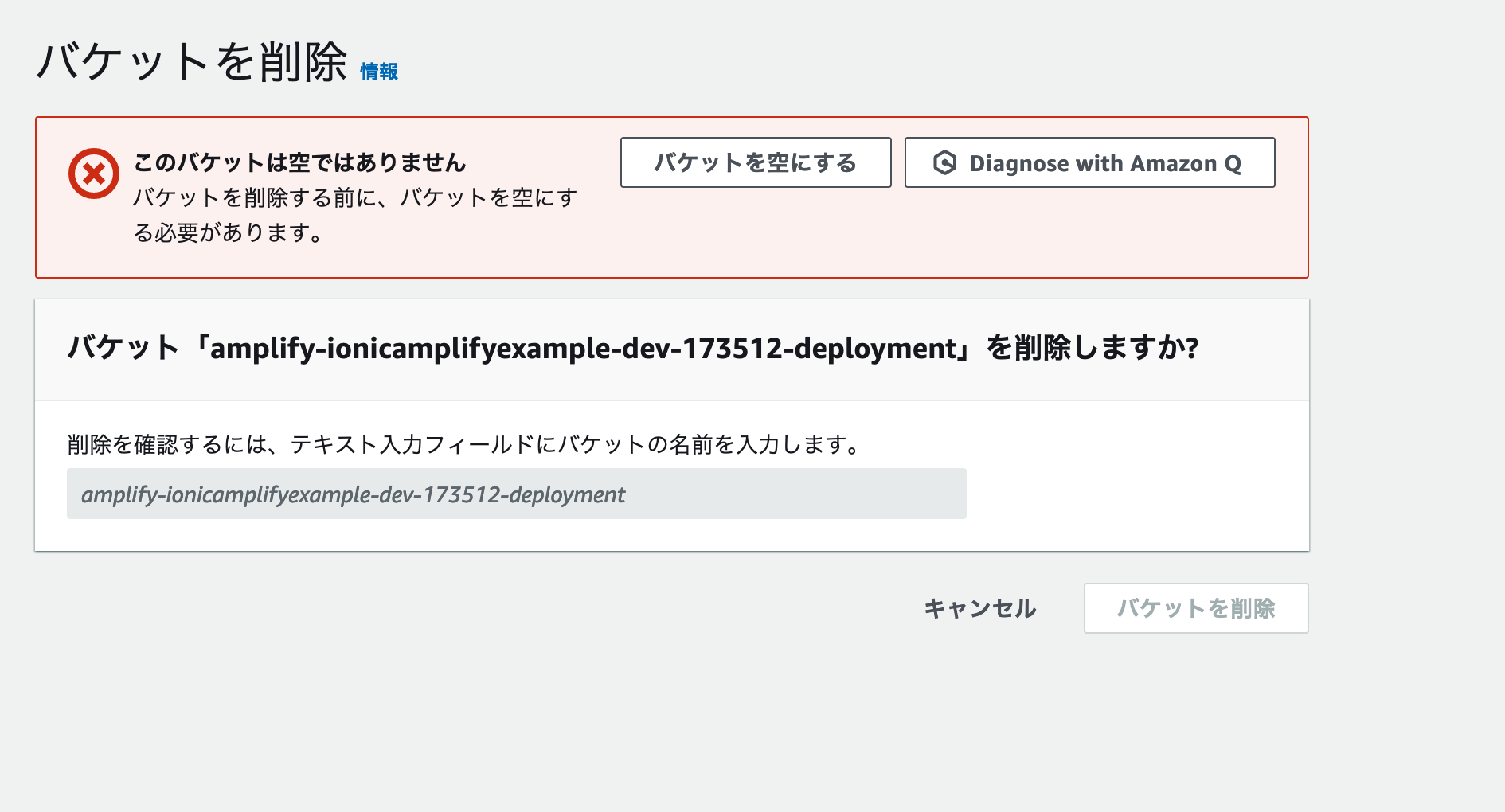
バケットを空にした状態で、完全に削除 とフィールドに入力すると、削除ができます。

終わりに
AppFlowを利用することで、Bedrockナレッジベースを利用したRAG / AIチャットアプリが利用するデータソースを外部からノーコードで取り込むことができます。実際の運用では、ワークフローを定期実行にすることで、情報の更新も自動化することができるでしょう。ただしその場合、S3バケットに転送された新しいデータをナレッジベースに同期させるためのワークフローが必要になります。Amazon EventBridgeでAppFlowのワークフローが完了したイベントを受け取り、Step FunctionsからBedrockナレッジベースのStartIngestionJobを実行することで、こちらもコードを書かずに実現できます。具体的な手順については、後日別記事で紹介します。
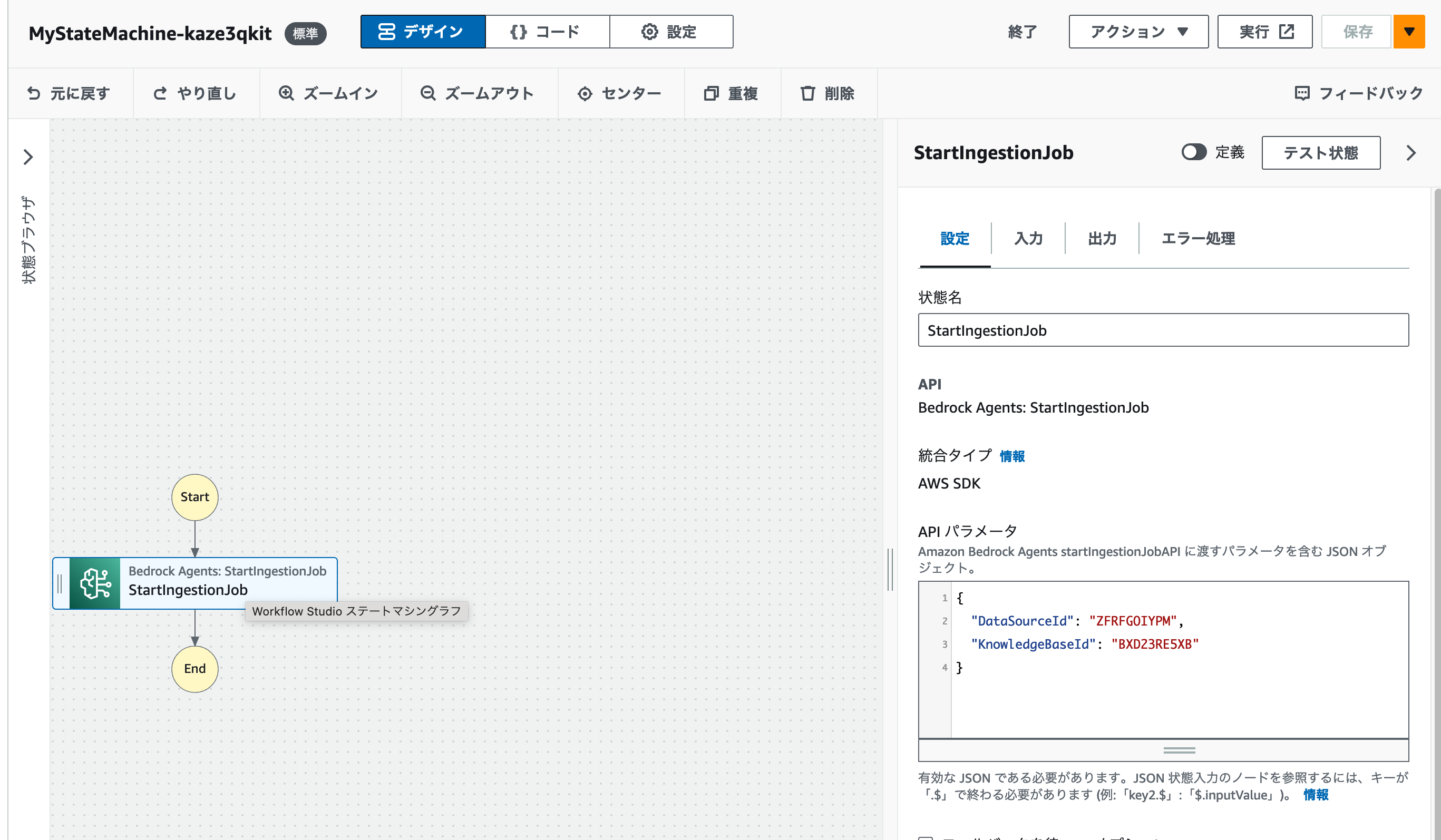
このように、AWSのマネージドサービスを組み合わせることで、LLMを利用したRAGについてもほとんどコードを書かずに作ることができます。まずは動くデモをこのような形で作ってみて、回答の精度を高める方法やデータソースの拡充などをどのように実現するかの議論を始めてみましょう。もしノーコードでは厳しくなった場合も問題ありません。Step FunctionsやAWS Lambdaを部分的に活用して、最小限のコードでカスタマイズを目指してみましょう。