AWS DataSync(以下、DataSync)と Azure File Sync(以下、File Sync)シリーズの4本目の記事です。
1本目は記事はこちら
AWS DataSyncとAzure File Sync 比較 ~共通点と相違点~
2本目は記事はこちら
AWS DataSyncとAzure File Sync 比較 ~前提条件定義編~
3本目は記事はこちら
AWS DataSyncとAzure File Sync 比較 ~AWS DataSync構築事前準備編~
本記事からいよいよ構築を開始します。
構成の確認
全体の構成はこのようになります。
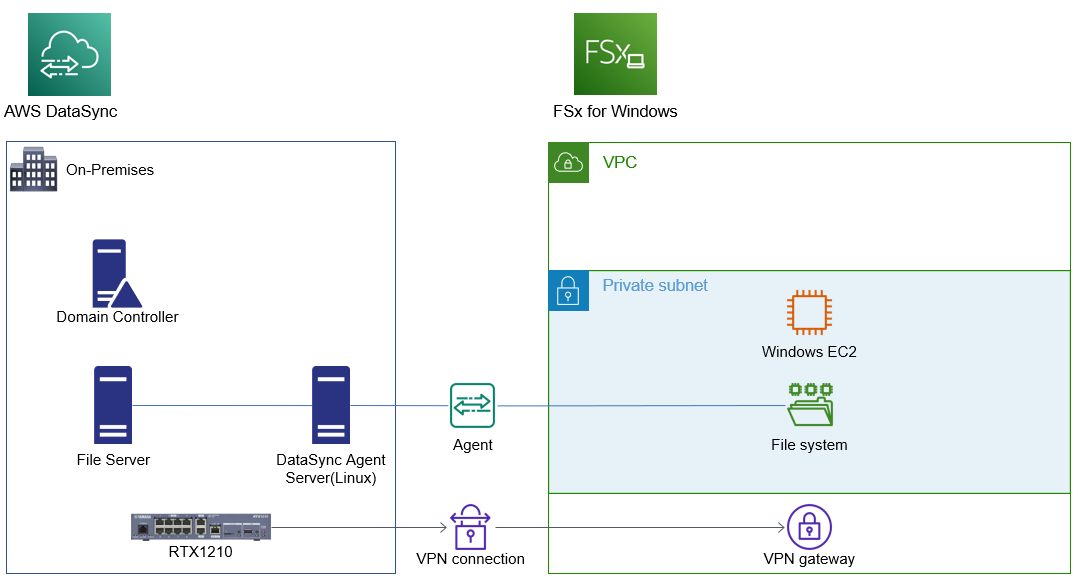
FSx for Windowsについて
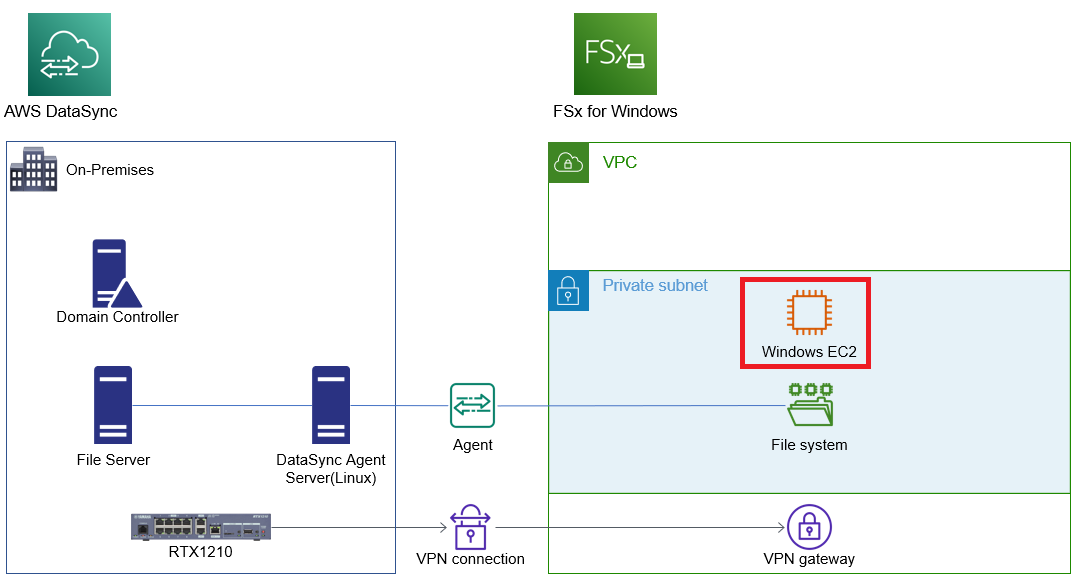
赤枠のWindows EC2はFSx for Windowsを作成時にWindowsのコンピューターアカウントとしてAD参加させるのですが、ストレージであるFSx for Windows単体だけでなく、管理用のWindowsのコンピューターアカウントも登録されます。
更にFailover用でコンピューターアカウントが登録され、合計3つのWindowsのコンピューターアカウントが登録されます。
具体的には以下のようになっています。
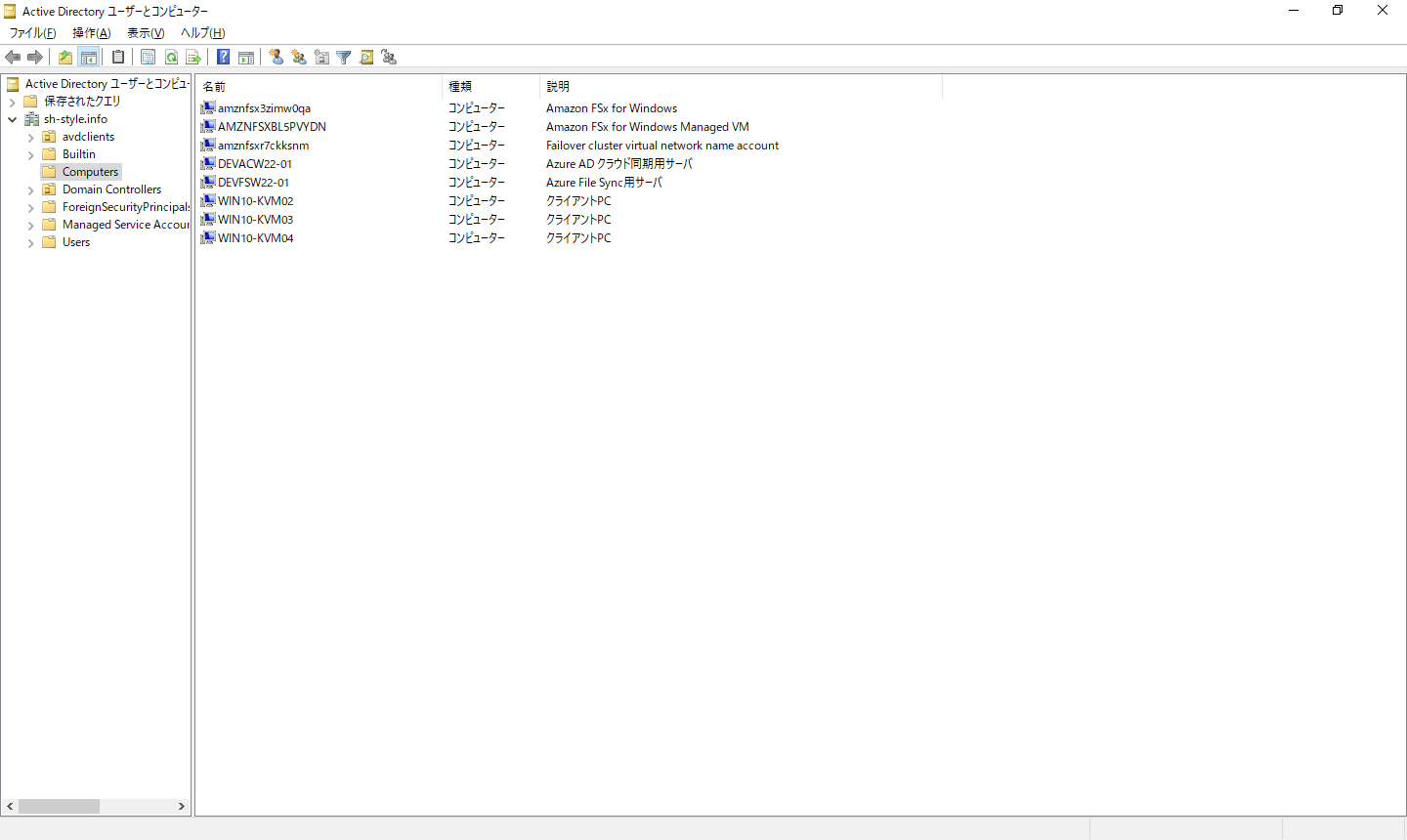
どれがどれなんだ、っていうと、
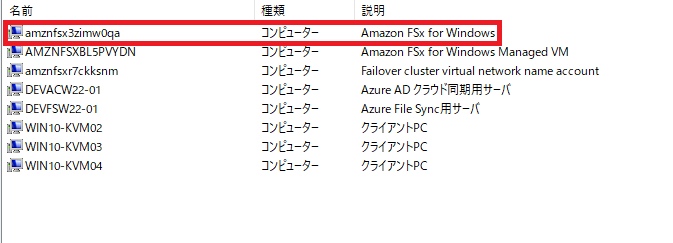
この一番上のものがFSx for Windowsのストレージ部分です。
[説明]の部分には私が手動で記載したので自動で入力されるものではありません。
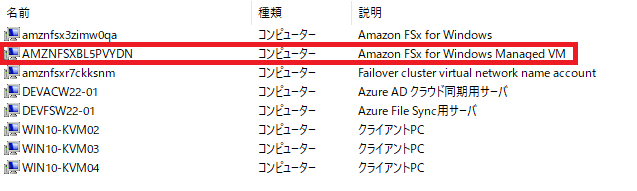
この二番目のものが構成図の赤枠内のWindows EC2だと思います。
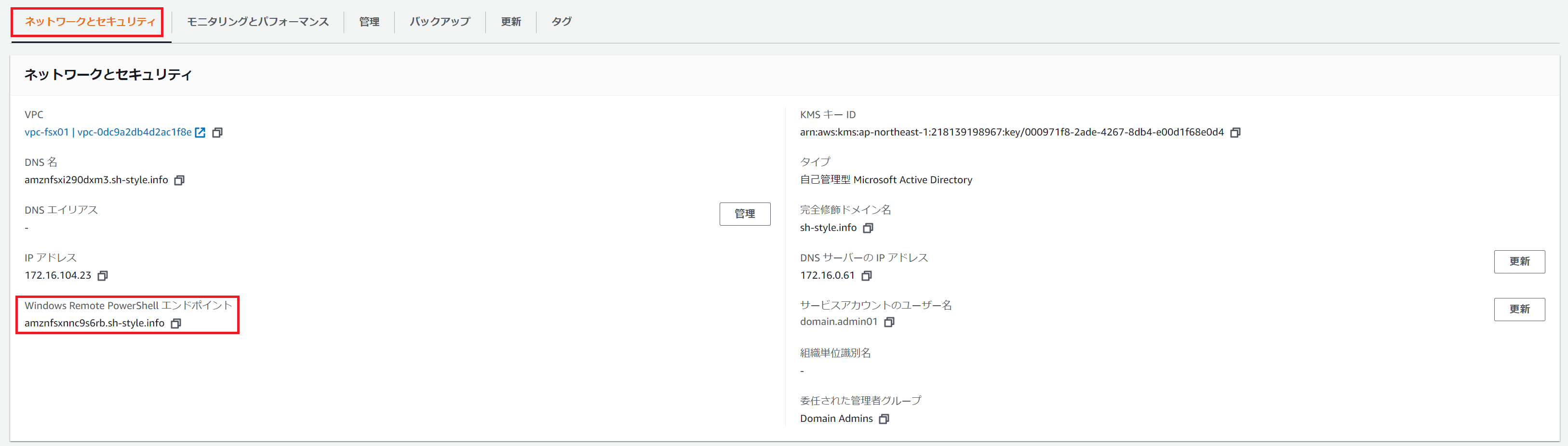
これはなぜそう思うのかというと当然理由があり、AWS管理コンソール内のFSx for Windowsの管理画面、[ネットワークとセキュリティ]にこのコンピューター名と同じ設定値が存在し、これがPowerShellを受け付けるエンドポイントの役割、[Windows Remote PowerShell エンドポイント]を担っているからです。
具体的な画面としては以下の赤枠部分です。
構築時期がずれているのでAWS管理コンソール画面とドメインコントローラー内の[ユーザーとコンピューター]の画面の設定値が一致していませんが、構築中に何度も確認したので間違いないです。
これらの証跡から恐らくこのフルマネージドのWindows EC2がこのコンピューターアカウントであろうと結論付けました。
これもドメインコントローラー内のコンピューターアカウントの[説明]部分は私が手動で記載しています。
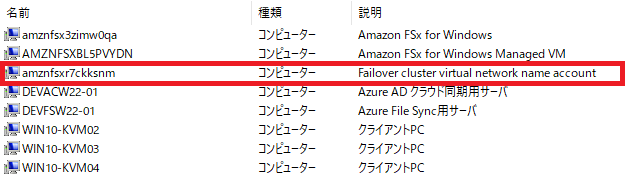
そして3番目のコンピューターアカウントがFailover Cluster用のアカウントになっています。
これはドメインコントローラー内のコンピューターアカウントの[説明]部分は自動で入力されます。
恐らく2番目の[Windows Remote PowerShell エンドポイント]としてのコンピューターアカウントと併せて冗長構成になっているのでしょうか?
この辺は細かな仕様はわかりません。
ただ1つ言えるのは、この3番目のコンピューターアカウントのように[説明]部分をFSx for Windows構築時に自動で入力してくれるのであれば、1番目、2番目のコンピューターアカウント生成時にも自動で明示的に入力して欲しいですね。
エンタープライズユーザーの場合、ストレージ管理者とドメイン内のコンピューターアカウント管理者が別人、別組織である可能性は十分考えられ、情報共有不足で現場で無用な混乱が起きる可能性があります。
ストレージ管理者とコンピューターアカウント管理者が別人であると仮定した場合、FSx for Windowsの登録で1つのコンピューターアカウントが登録されると予想していたら3つも登録された、となると情報システム部の現場が混乱することが十分考えられます。
初めて触るFSx for Windowsでここまで細かな情報共有をAWSの全ユーザーに求めるのは酷だと思います。
これも私が一人で全部自前の環境で検証して導き出し推論した結果なので、できれば公式ドキュメントに分かりやすく記載して欲しいです。
正直ユーザーフレンドリーではないと感じました。
FSx for Windowsを複数登録した場合、この3つのアカウントがそれぞれ作成されました。
少なくとも2つのFSx for Windowsを登録すると、コンピューターアカウントが3つ登録され、計6アカウントになりました。
これも仕様でしょうか。
公式ドキュメント内にある記載を私が見逃している可能性は否めませんが、もう少し分かりやすくして欲しいです。
構成図の説明、しかも肝心のDataSyncでなくてストレージ部分のFSx for Windows部分の説明にかなり紙面を割いてしまいましたが、大事な部分なので記載しました。
DataSyncの構成図内での説明
構成図でいうと以下の赤枠部分ですね。
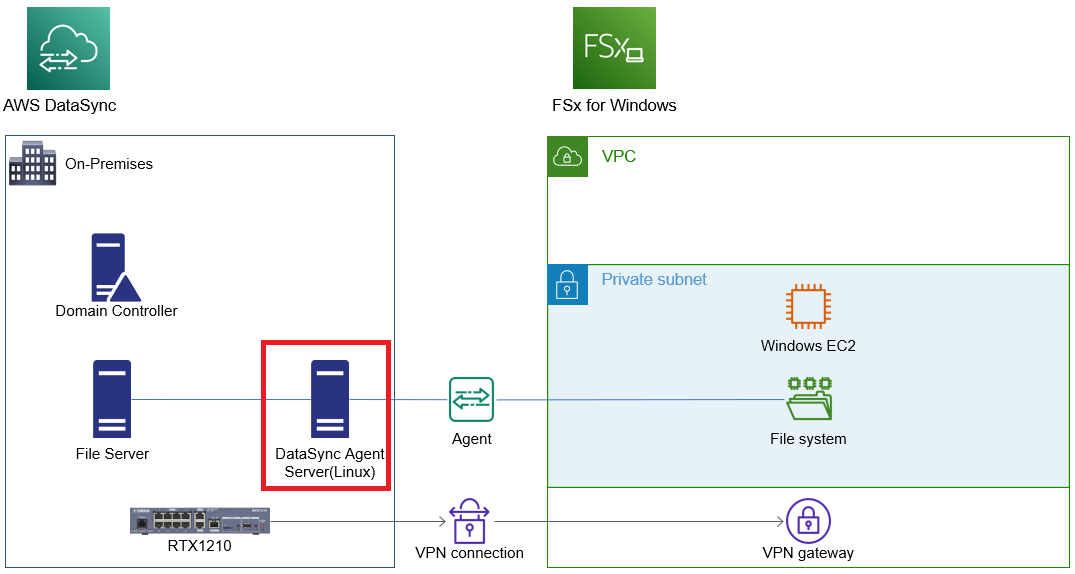
これなんですが、まぁまぁ敷居が高いと感じました。
File Syncの場合だとエージェントのインストールのみで完了するんでわざわざVM1台たてなくて良いんですが、DataSyncはわざわざVM1台立てなくてはいけません。
AWS上に立ててもいいんですが、オンプレミスに立てる場合はKVM上かVM Ware上か、Hyper-V上かでそれぞれVMのイメージが用意されているんでオンプレミスにVMわざわざ1台立てます。
いや、ホンマなんべんも言いますけど、そういうとこっすよAWS!
めっちゃめんどくさいですやん!
いや、ホンマ、ユーザーに手間かけさせすぎですわ。
私の少ない経験上のお話なのでどこまで読者の皆様に当てはまるかわかりませんが、AWSやAzureへの移行を検討している、既に一部のシステムは移行済みでAWSやAzureの既存ユーザである場合、オンプレミスの仮想基盤に投資を控えている場合が多い、というかほとんどです。
しかもオンプレミスの仮想基盤は既に現行システムでほぼ100%使い切っているような状態でこれ以上VMを構築することができず、仮に構築できたとしてもCPU、メモリ、ディスクがオーバーコミット状態となり、新たに追加するDataSyncエージェントどころかオンプレミスの仮想基盤上で稼働中の現行システムの安定性が担保されなくなる可能性があります。
仮にこのDataSyncのVMをオンプレミス仮想基盤に構築することで現行の仮想基盤上で動作している他のシステムに影響があった場合、AWSさんはどこまで責任とってくれるんでしょうね?
絶対何の責任も取ってくれませんよね。
ユーザーに手間だけでなくリスクまで背負わせるのはどうなんでしょうか?
私が提案する立場だとDataSyncは提案から外します。
提案したとしても当て馬ですね。
その分選択しとしてAWS上にこのDataSyncのエージェントVMを構築するということなんでしょうが、これだとVMの利用料がかかりますしね。
よく考えられていますが、ユーザーフレンドリーかどうかは私にはよくわかりません。
DataSync 構築
では順を追って構築していきましょう。
1.DataSyncの構築~エージェントの展開1~
DataSyncを個人で検証しようとしたらAWS上に構築することが多いかもしれませんが、私はたまたまKVMの仮想基盤を自宅に持っているのでそこにこのDataSyncのイメージを展開します。
AWS管理コンソールにログインし、[検索]にDataSyncと入力します。

DataSyncのトップ画面が出てきますので、[データ転送タスクを作成する]で[設定するデータ転送を選択します]から[オンプレミスストレージとAWSの間]を選択します。
[今すぐ始める]をクリックします。
私の環境では上述のようにKVM環境があるのでKVMを選択します。
[イメージをダウンロードする]ってありますけど、当然圧縮されてるんで展開して、KVM環境にコピーして、って手間がかかるんですよね・・・
考えただけでも面倒すぎ・・・
KVMのホストOSからwgetなりcurlなりでダウンロードして解凍もコマンドでやりますやん・・・
その方が早いですやん・・・
って思ったのでここにURL記載しておきます。
https://d8vjazrbkazun.cloudfront.net/AWS-DataSync-Agent-KVM.zip
これAWS側がこのイメージのバージョンアップするとURL変わるんですかね。
こんなん考えるともうめんどくさすぎますね。
いや、ホンマ面倒ですわ・・・
自宅回線10Gbpsに変更したんでこういう作業の時に恩恵を被るんですが、こんなしょうもない作業のために回線増速したんじゃないんですよね。
最新版のイメージが常にアップロードされているURLで、イメージが修正されてもユーザは常に同じURLにアクセスすれば良い環境にして欲しいです。
そしてその旨ちゃんと記載して、どこか公式ドキュメントでURL記載して欲しいです。
なんでこんな手間かけさせる仕様なのか・・・
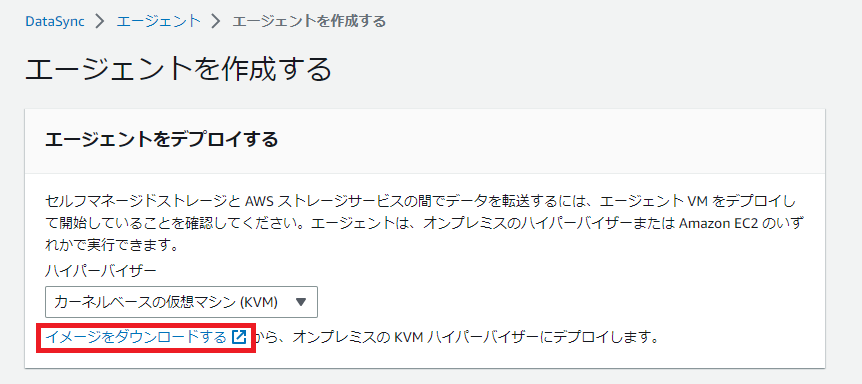
サービスエンドポイントはこのまま[アジアパシフィック(東京)の公開サービスエンドポイント]でOKなんですが、[アクティベーションキー]がまた面倒ですね。
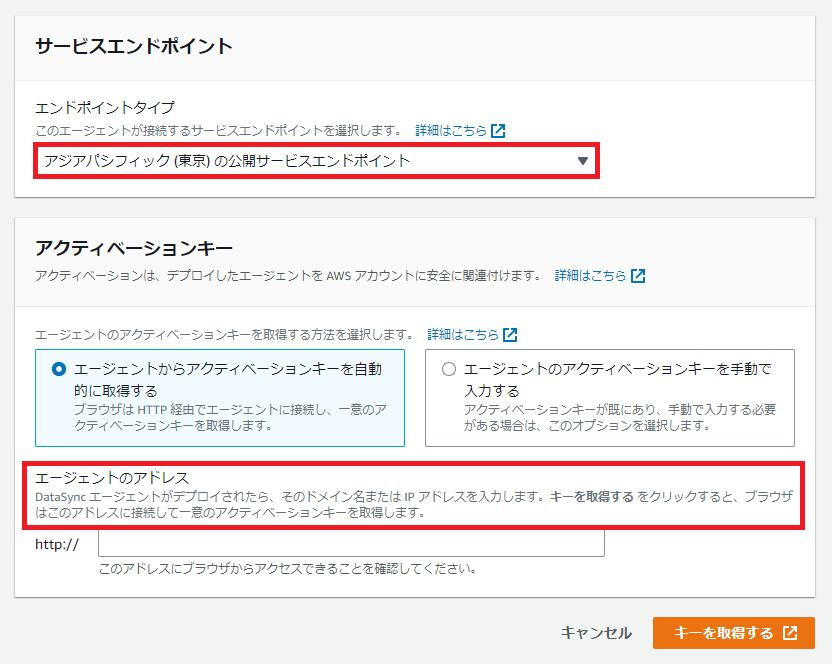
[エージェントのアドレス]ってところ、赤枠の部分ですが、[DataSyncがデプロイされたら、そのドメイン名、またはIPアドレスを入力します]やと?
なに?オンプレミスのKVM環境に展開したDataSyncのエージェントのVMをインターネットに公開しろやと?
ルーターの設定変更して、KVMの仮想NICの設定やらも考慮して他のVMに影響与えないように、しかもURL見るとhttpsじゃなくてhttpで?
ヤバいっすね。
面倒すぎます。
リスク高すぎます。
あり得ないです。
はい。
エンタープライズユーザーだとこの時点でNGの可能性が高いですね。
AWSさん、せめてアクセス元グローバルIPアドレスくらいは公開してください。
何がアカンのか確認していきましょう。
前述の例の通り、ストレージ担当者とドメインのアカウント管理者が別人、別組織の場合を今回も考えた場合、ネットワーク担当者も当然別人、別組織である可能性が非常に高いです。
ネットワーク担当者にストレージ担当者から「どこからアクセス来るかわからないんですが、http、TPC80番ポートなので暗号化されていない通信を現行システムが色々動いている仮想基盤上に新たに構築するDataSyncエージェント用のVM宛にインバウンド方向でFirewall設定で通信許可してください」って言うことになるんですよね。
日本語にするとなかなかインパクトありますね。
私も曲がりなりにもネットワークエンジニア名乗ってますが、こんなこと言われたら
「顔洗って出直してこい」
って言いますね。
当然ユーザー側は組織なので担当者個別の口頭のやりとりで許可が出るわけもなく、恐らくネットワーク設定変更申請書とか記載することになると思うんですが、この仕様でネットワーク設定変更申請が許可されるとも思わないですよね。
はい。
賢明な読者の皆様方は既に十分お気付きだと思いますが、念のためアカンかったポイントを1つ1つ確認します。
アカンポイント1.
社内の仮想環境上にインバウンド方向で通信許可しなければならない
この一点目のポイントで一発KOなくらい強烈なんで他のポイント見る必要ないくらいなんですが一応見ていきましょう。
アカンポイント2.
通信がhttpで暗号化されていない
平文通信ですね。
このサービス、DataSyncの仕様策定した人が何考えてたかちょっと聞きたいですよね。
マジで。
アカンポイント3.
送信元が指定できない
インターネットに広く80番ポートを公開します。
マジっすか・・・
結局このエージェントのアクティベーションは自動取得ではなくて手動取得にするのが良い(というかそれしか選択肢が無い)ので私も自動取得では実装してません。
ですのでこの先は予想ですが、恐らくこのインバウンドTPC80番ポートは、DataSyncのサービス使い続ける限り開け続けないといけないんじゃないでしょうか・・・
閉じると認証効かなくなるんじゃないですかね?
認証効かなくなった結果DataSyncの同期サービスも止まる、なんて仕様だったらもう、目も当てられません
ここまで見てきてまだ構築もできてませんが、DataSyncはさてはエンタープライズユーザー想定していないんじゃないか説が私の中で浮かんできました。
せっかく自腹で検証したのに・・・
DataSyncの動作そのものは良い動きなのに・・・
インフラ部分がボロボロ・・・
気を取り直してエージェントのアクティベーションキーを手動で入力するを選択します。
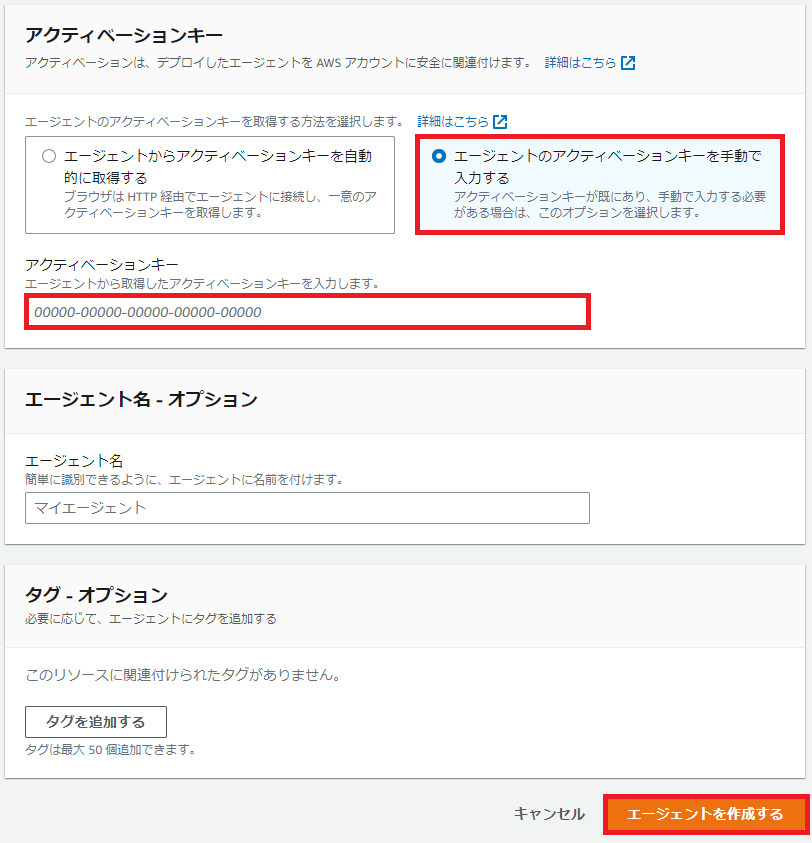
ここからの手順もまぁ面倒なんですよね。
DataSyncのエージェントがマネージドVMとしてKVMに展開されますが、マネージドVMなんでSSHでDataSyncのVMへ同一セグメント外部セグメント問わずアクセスできません。
そもそもSSHのプロセス動いてるのか不明でした。
実行できるコマンドも絞られていますので、わかんないです。
KVM基盤上にイメージ展開してDataSyncのエージェントの設定を行います。
2.DataSyncエージェントの設定
KVMのホストOSにダウンロードしたZip化されたイメージを移動し、解凍し、Bootしました。
問題なくデプロイできて起動できました。
もうここまでで既にかなり面倒ですが、実はまだこのエージェントのアクティベーションすらできていませんからね。
作業全体で考えても序盤も序盤です。
まぁでも素直にBootできたんで良しとしましょう。
これでカーネルパニックでも起こしてBootしなかったらもうその時点でこの記事が企画倒れですからね
DataSyncのエージェントVMのログインIDとパスワードは
ID:admin
パスワード:password
です。
ログインしましょう。
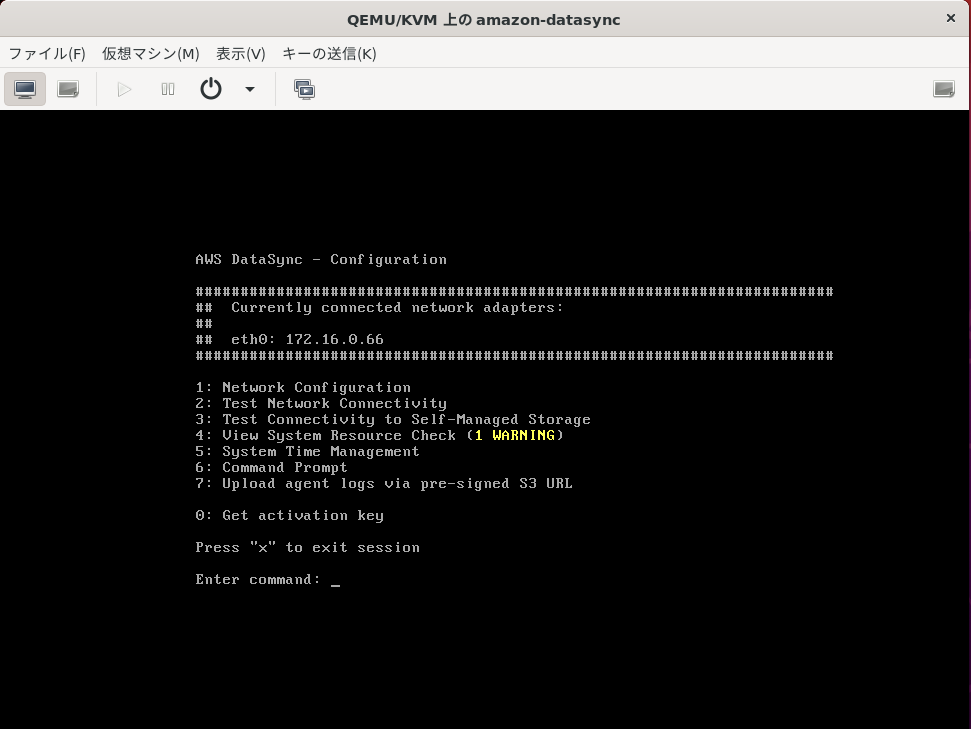
はい。
なんか4番のシステムリソースチェックでワーニング出てますね。
無視しましょう。
VMの稼働に必要な最低スペック満たしてないよ、って言ってます。
CPU4コアに同期するオブジェクト数が2,000万以下であればメモリ32GiB、2,000万以上であれば64GiBを要求してきます。
IPアドレスもDHCPサーバが動いていれば自動で取得しれくれますが、[1: Network Configuration]で固定IPアドレスでも設定可能です。
インターネットに出れて、AWSの各種リージョンと通信できるようになると[0: Get activation key]を選択しましょう。
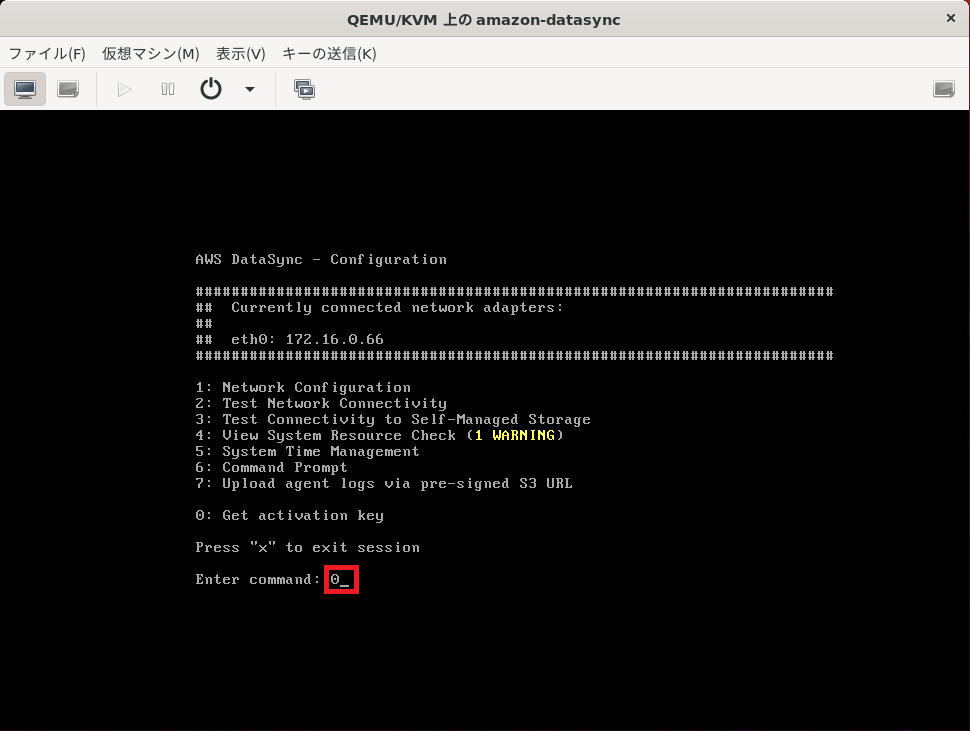
ここで0を入力してエンターキー押しましょう。
もうKVMのコンソールでやんなきゃいけない時点で面倒なんですけど、作業そのものは少ないです。
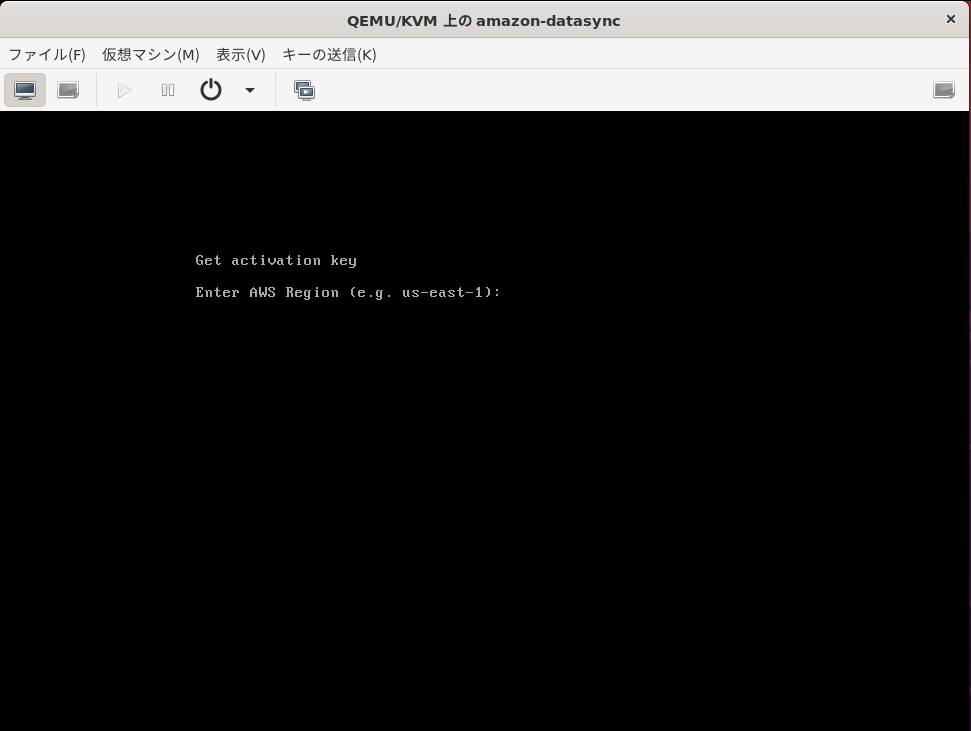
[Get activation key]の画面に切り替わりました。
[Enter AWS Region]となっていますが、DataSyncのエージェントをデプロイして利用するリージョンの入力を求められてます。
いちいち説明が不十分でイラっとしますが、意を汲んであげましょう。
東京リージョンの場合は
ap-northeast-1
と入力してエンターキーを押しましょう。
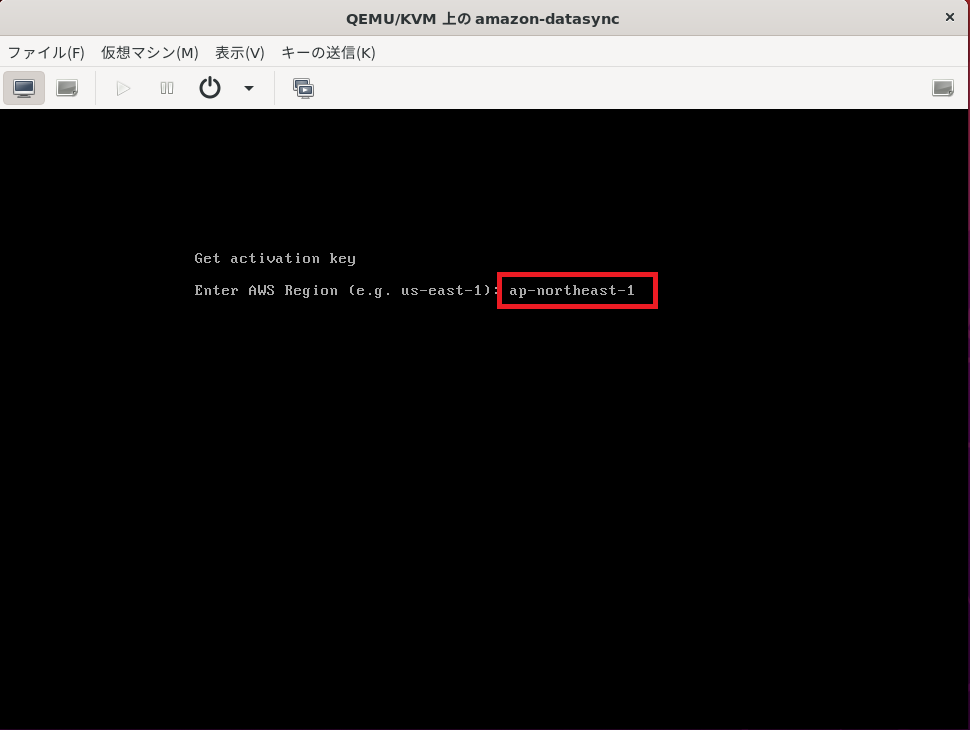
先ほど指定したリージョンで、どのエンドポイントを利用するのか指定します。
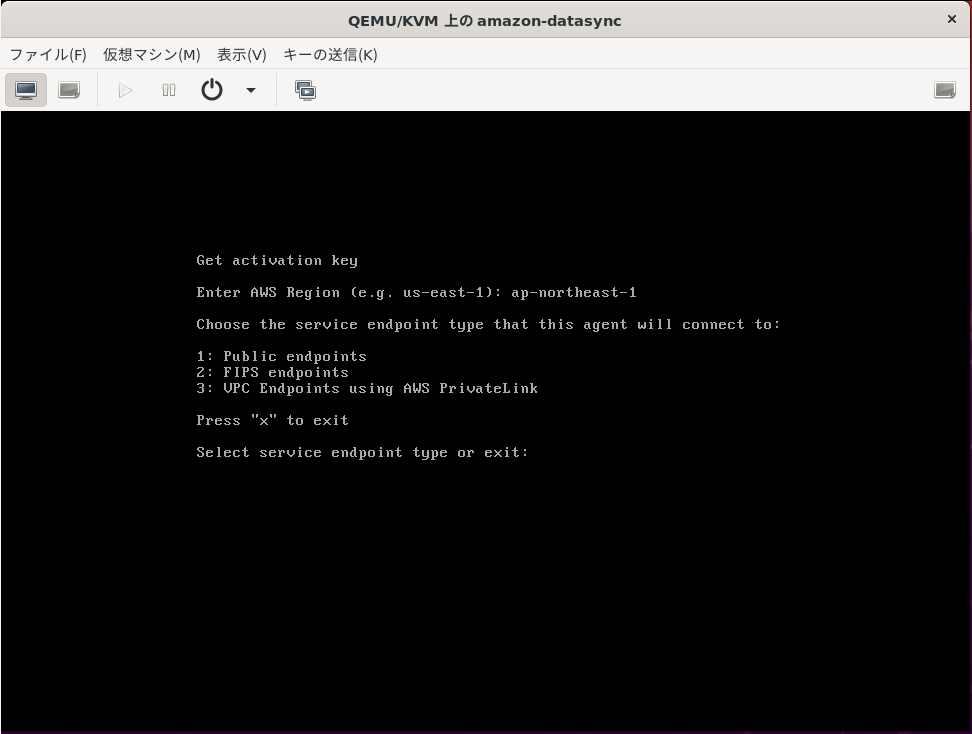
今回はPrivateLinkを構築しておらず、金融機関でもないのでFIPS利用する必要もないので1.のPublic endpointを選択します。
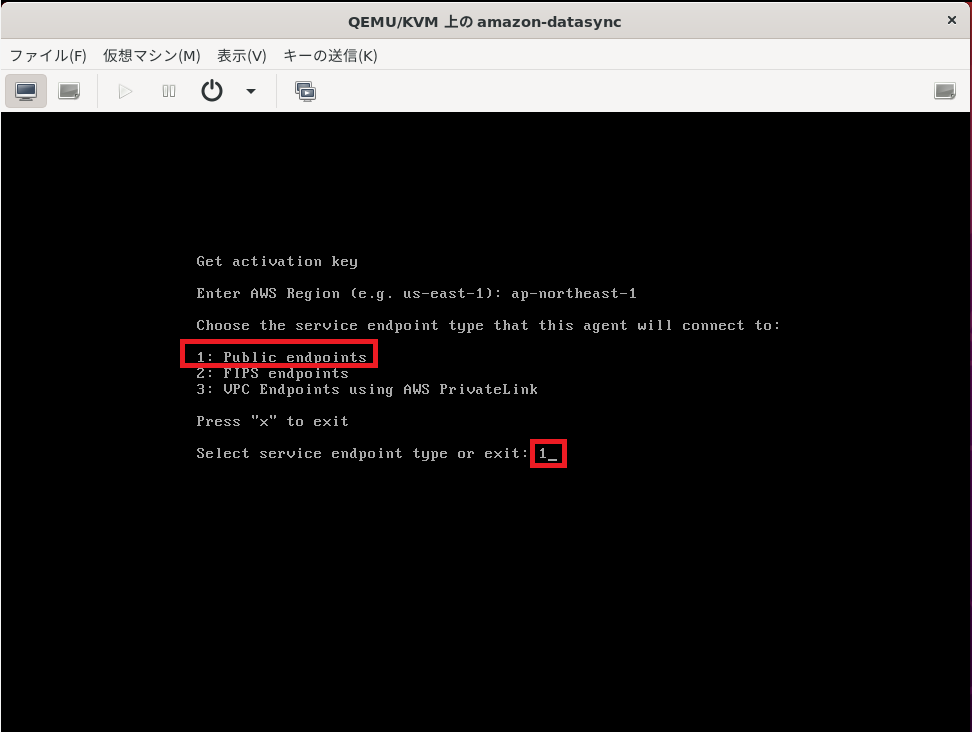
1を選択してエンターキーを押します。
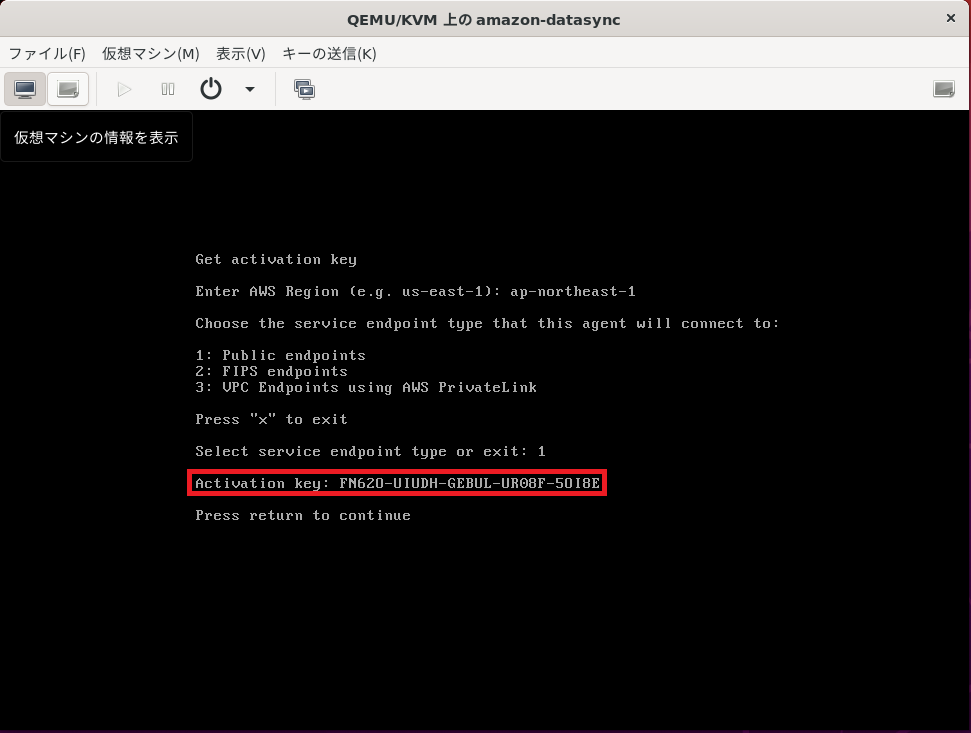
はい。
無事アクティベーションキーがでましたね。
作業そのものは簡単ですが、KVMのコンソール経由でこの作業を行わないといけないので面倒ですね。
仮想基盤の担当者とストレージの担当者、クラウドの担当者が違う場合は連携が必要です。
まったくもってユーザーフレンドリーではないですね。
3.DataSyncの構築~エージェントの展開2~
やっとAWS管理コンソールの画面に戻ってこれました。
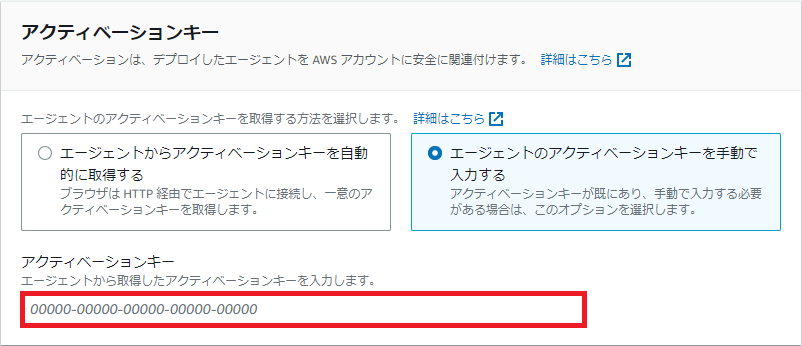
赤枠内に先ほど取得したアクティベーションキーを入力します。
アルファベット大文字は大文字で入力しないといけません。
全部大文字なんだからどっちでもええんやないですかとも思うんですが、大人しく大文字で入力しましょう。
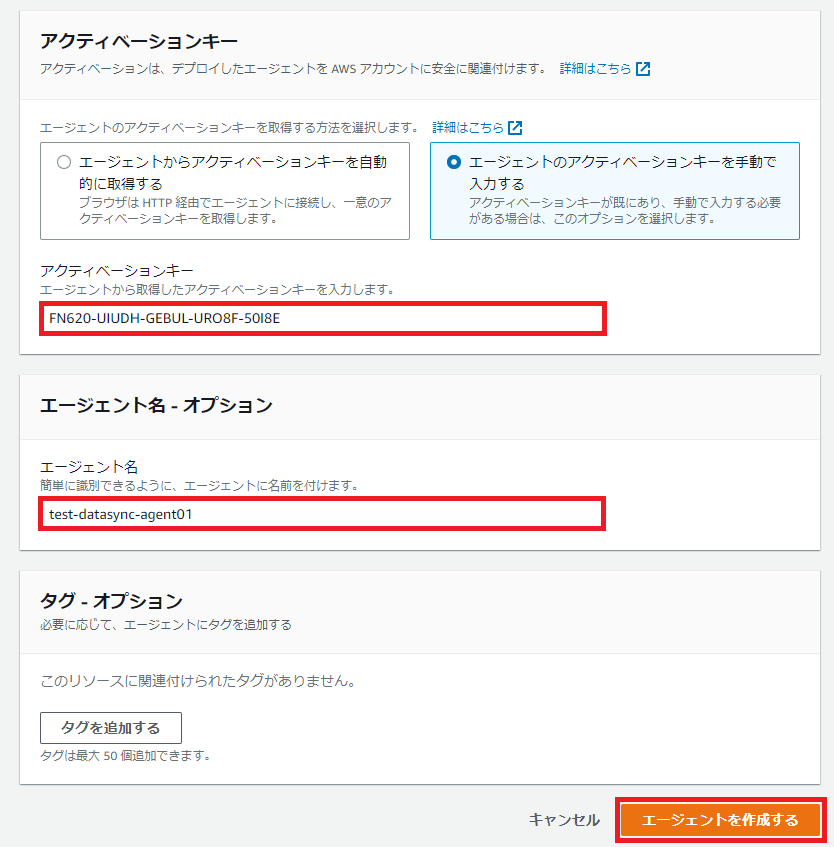
アクティベーションキーを入力し、エージェントの識別名を付けて、[エージェントを作成する]をクリックします。
このアクティベーションキー
FN620-UIUDH-GEBUL-URO8F-50I8E
だと思ってたら
FN62O-UIUDH-GEBUL-UR08F-5OI8E
でした。
やっとこれでエージェント作成できました。
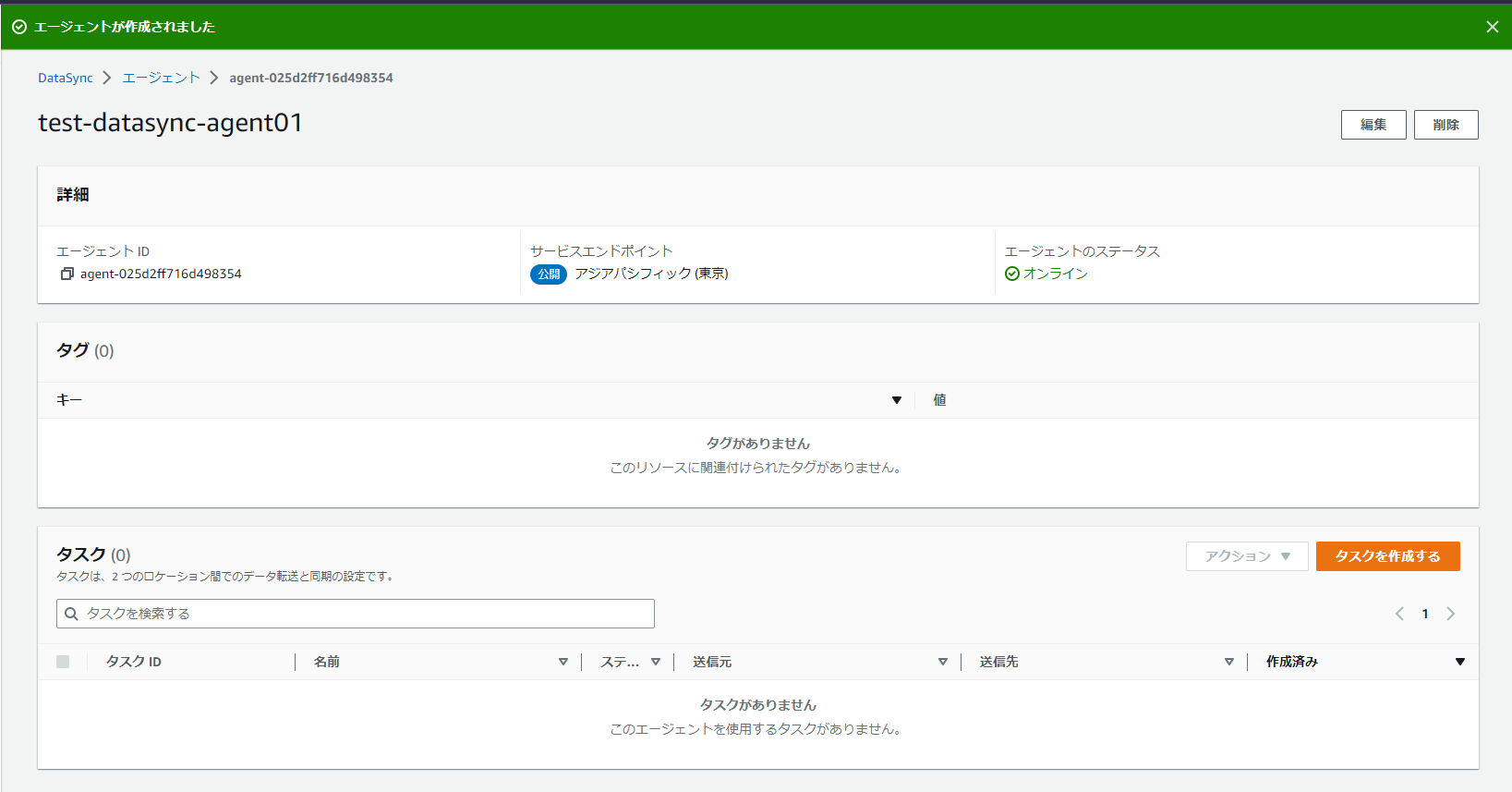
ここまでできてもまだデータ同期はできません。
ここから同期元と同期先の設定が必要です。
AWSさんの構築は毎回手間がかかりますね。
私のサービス選定が悪くてたまたま手間のかかるサービスばかり選択しているのか、全部こうなのかわかりませんが、とにかく手間がかかります。
記事を書くのも手間がかかりますね。
4.同期元と同期先の設定
同期エージェントの設定ができたので、同期元と同期先を設定します。
AWSでは同期先も同期元も[ロケーション]として設定します。
[DataSync]をAWS管理コンソールから選択し、[ロケーションを作成する]を選択します。
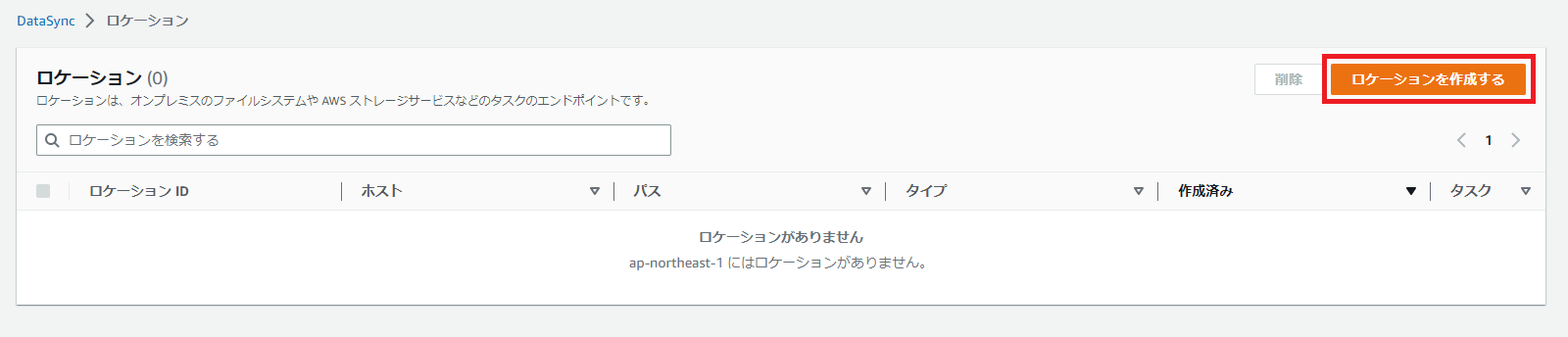
まずは同期先のFSx for Windowsから設定していきましょう。
[ロケーションタイプ]のプルダウンから
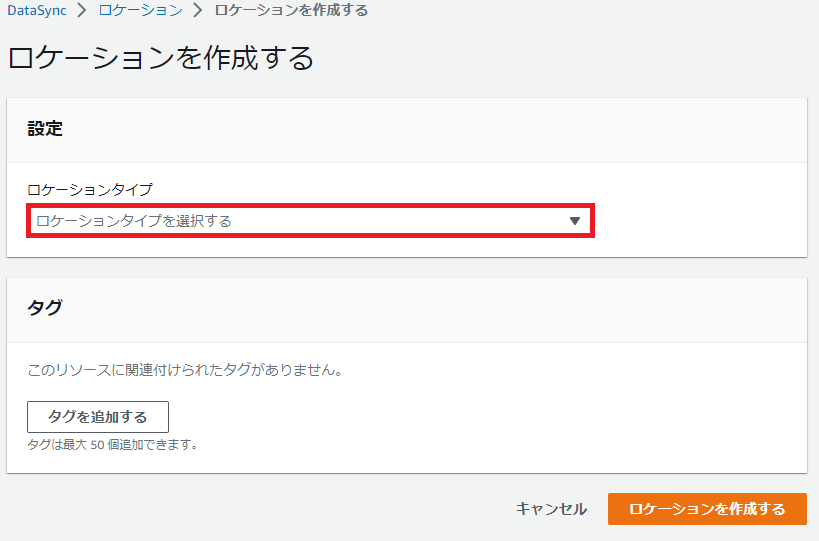
を[Amazon FSx]を選択します。
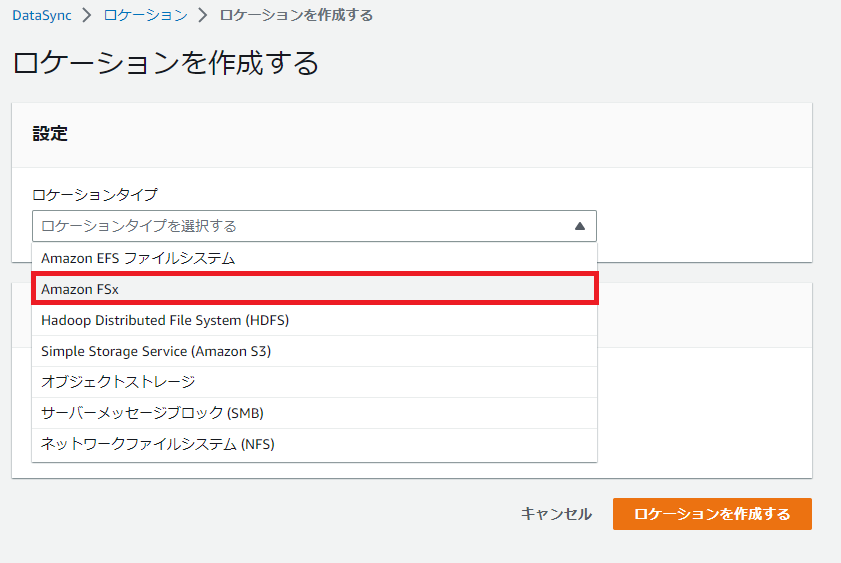
作成済みのFSx for Windowsを選択します。
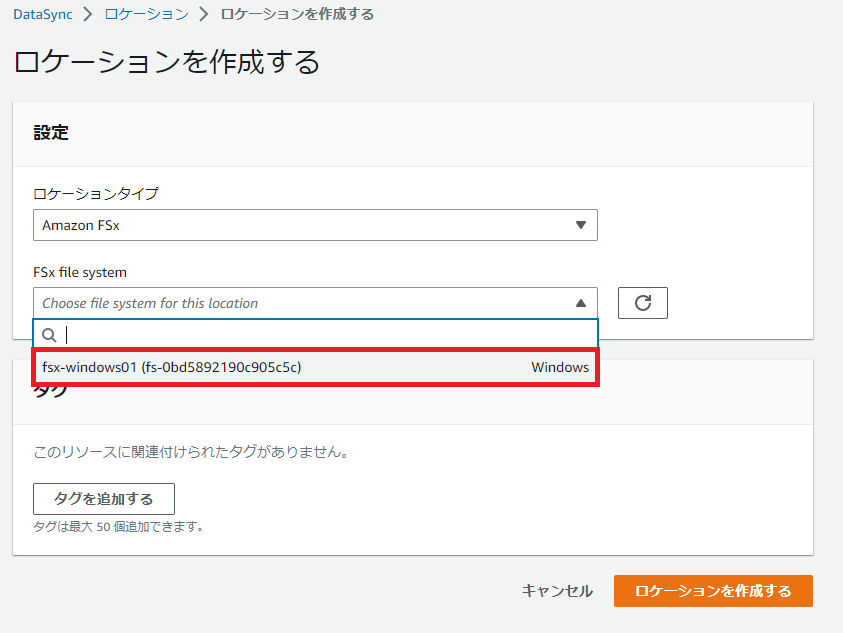
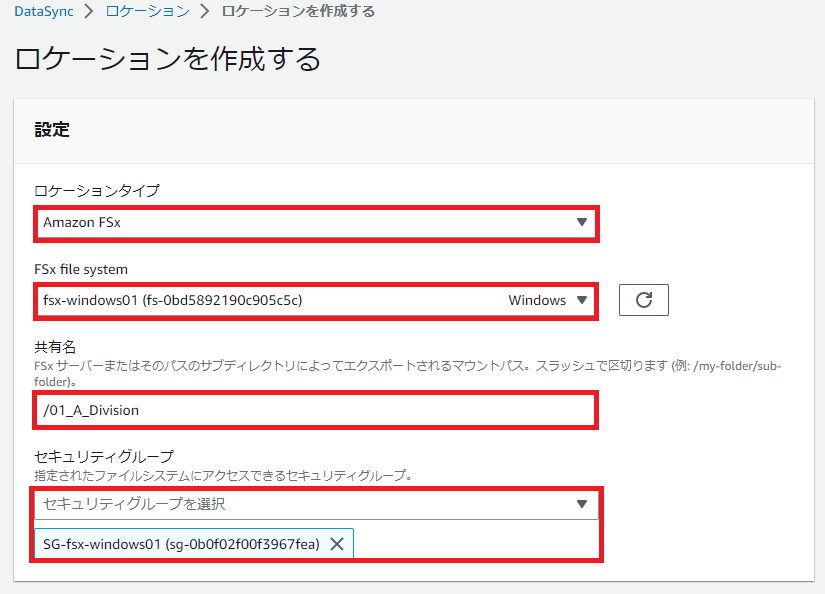
ここで急に設定が増えます。
まったく面倒ですね。
2本目の記事のこの部分で設定済みの共有フォルダを指定します。
セキュリティグループはFSx for Windowsと同じものを選択しましょう。
[ユーザー]はFSx for Windows作成時に指定したユーザ名、[パスワード]はこのユーザのパスワードです。
このFSx for Windowsは既にオンプレミスのドメイン配下に存在するので、オンプレミスドメイン内の管理者権限を指定しています。
[ドメイン - オプション]は無視してもOKです。
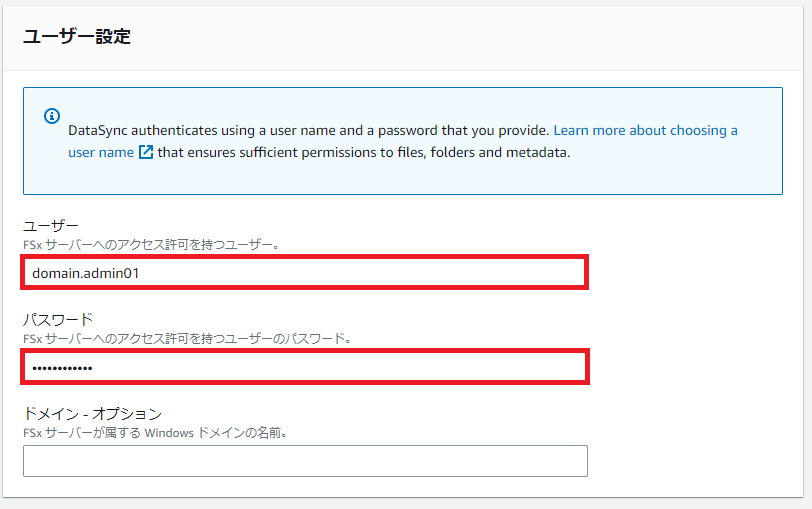
はい。
これで無事に同期先にあたるFSx for Windows側の設定ができました。
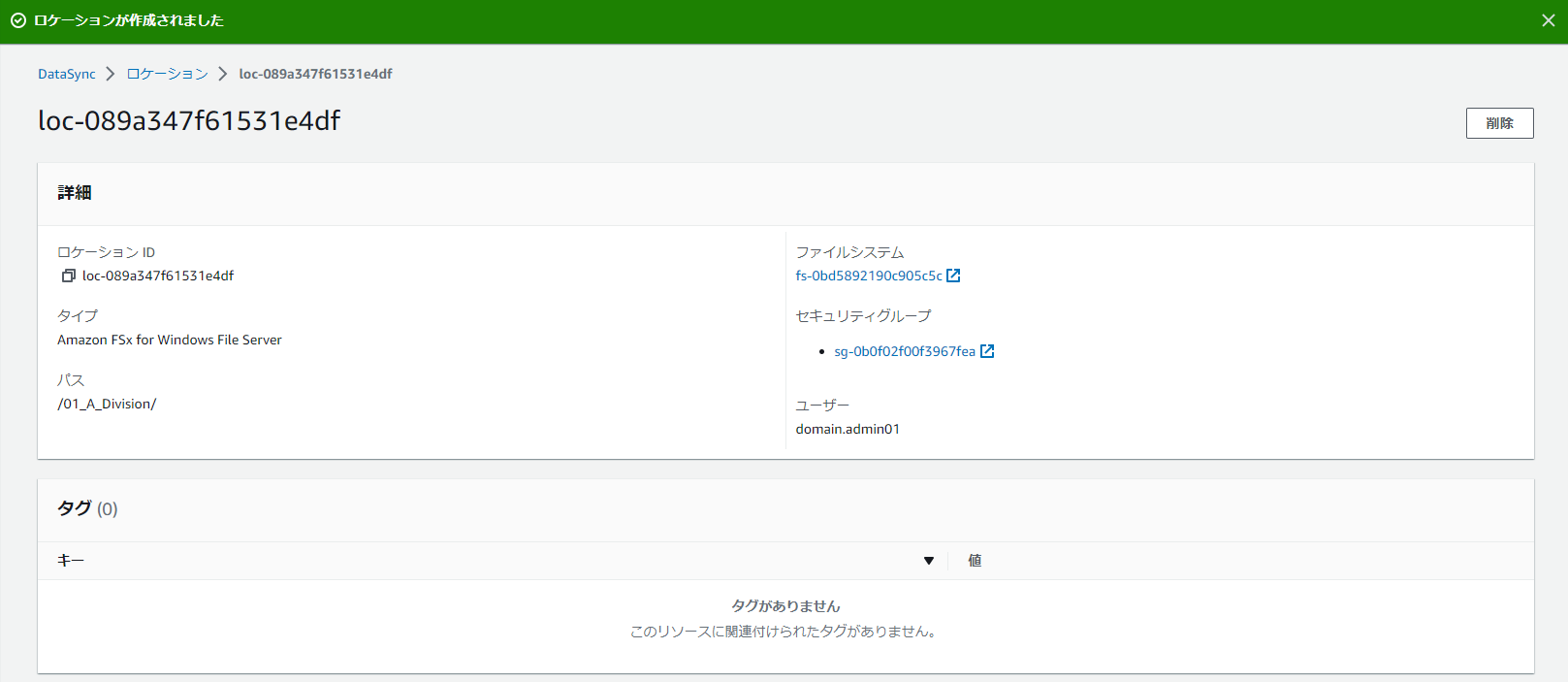
続いて同期元にあたるオンプレミスファイルサーバ側の設定です。
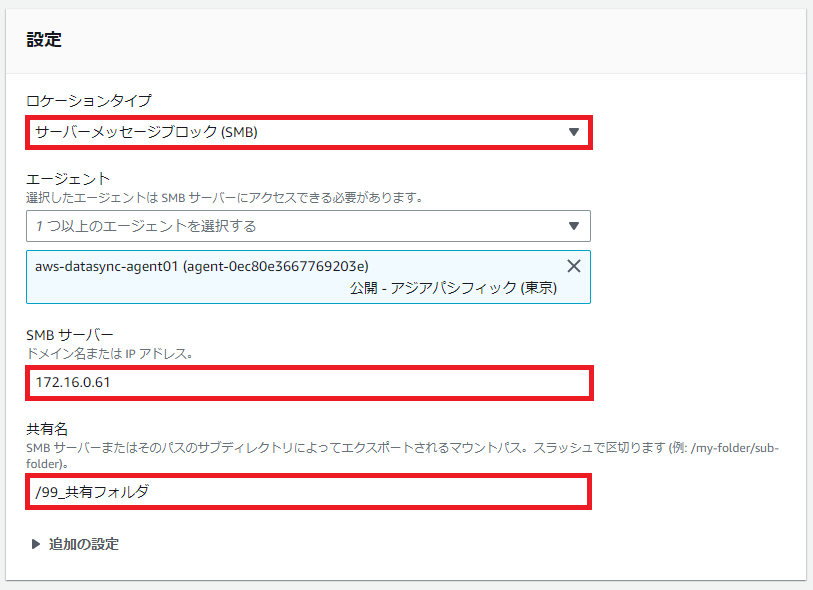
同期先のFSx for Windowsと同じく[ロケーションを作成する]の[ロケーションタイプ]で[サーバーメッセージブロック(SMB)]を選択します。
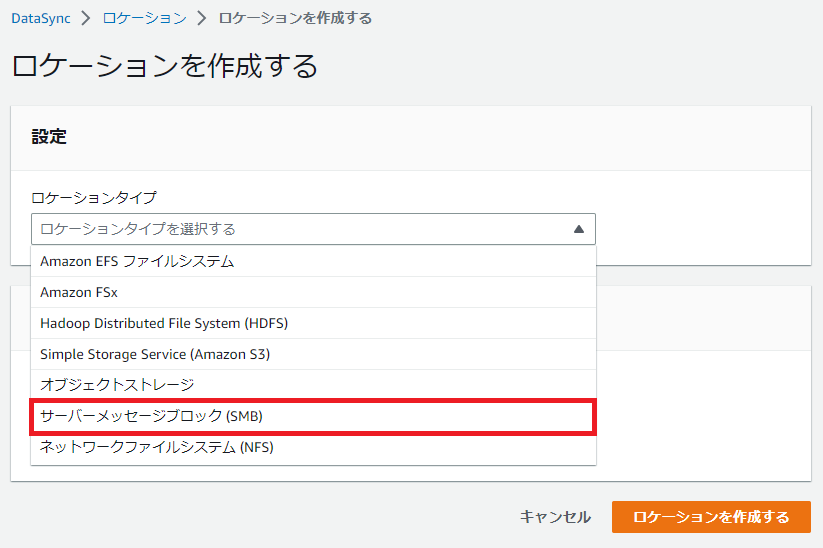
また設定値がワラワラ出てきます。
まぁ仕方ないですね。
エージェントは先ほど設定したエージェントを選択します。
[SMBサーバー]はオンプレミスの同期元ファイルサーバを指定します。
[共有名]はファイルサーバの直下の事業部単位のフォルダを指定します。
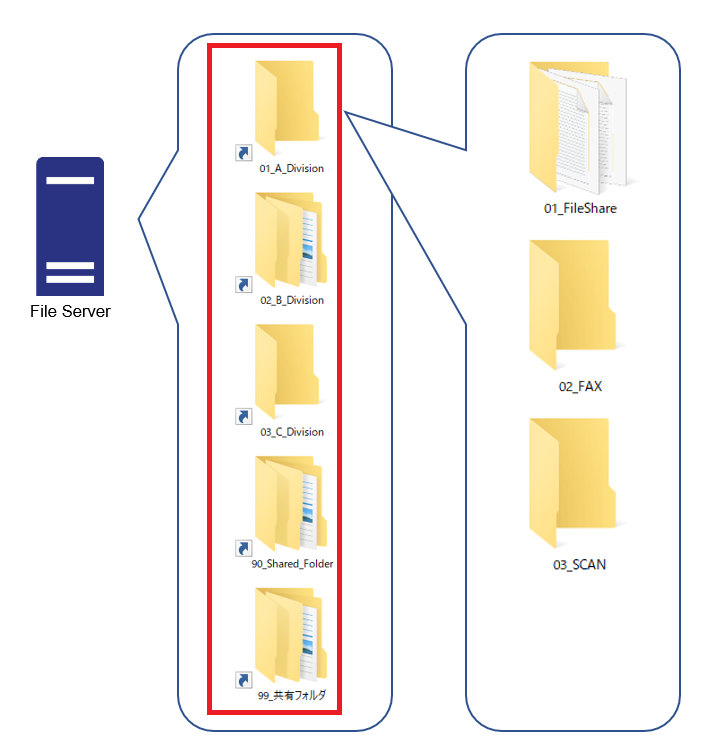
この構成図の赤枠部分ですね。
設定すると以下のような画面になります。
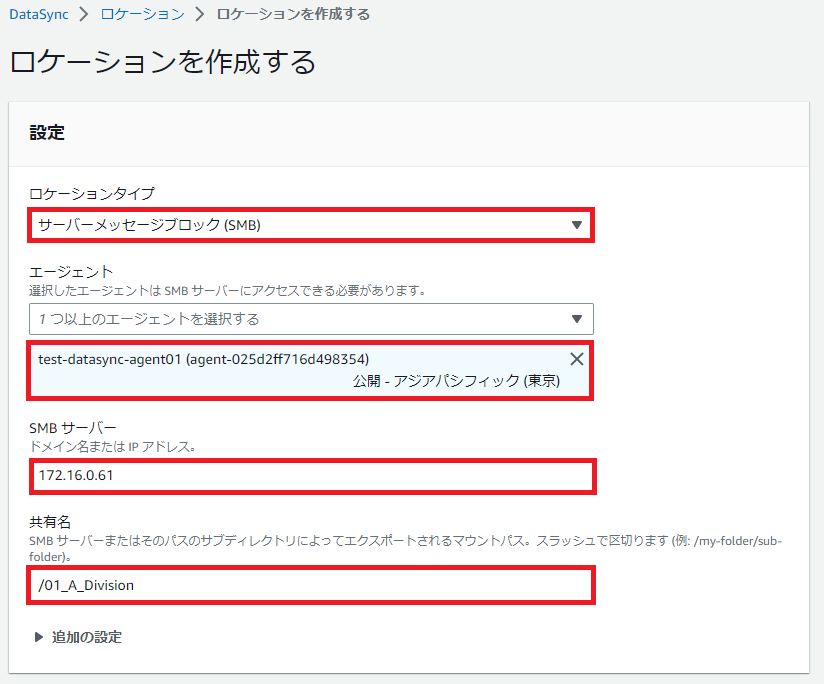
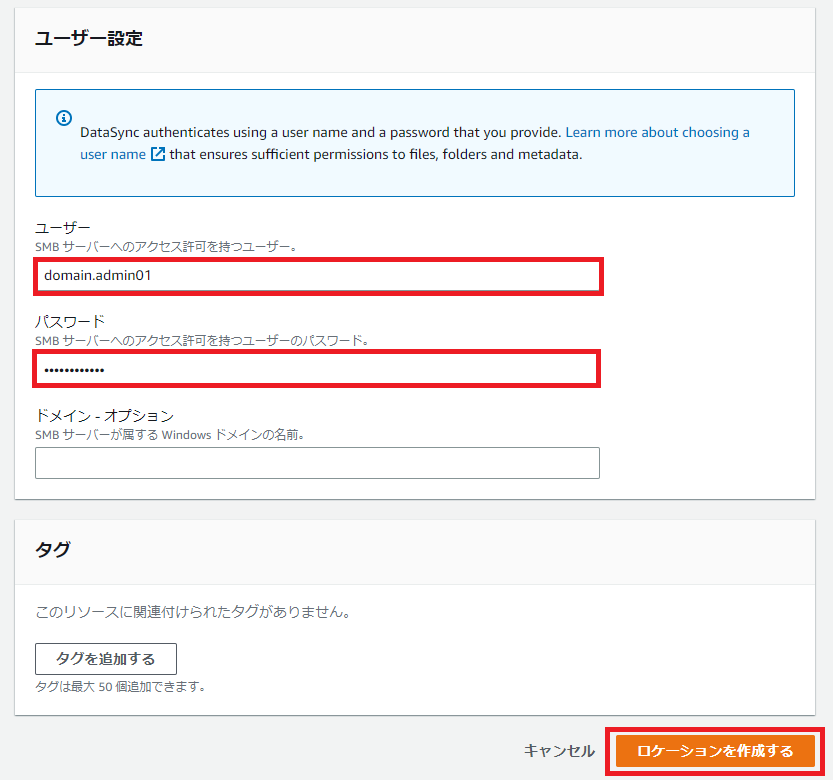
続いてオンプレミスファイルサーバへのアクセス権を持ったドメインユーザを指定します。
FSx for Windowsと同じ要領、仕組みですね。
というかこちらの方がむしろわかりやすいですね。
[ドメイン - オプション]はFSx for Windowsと同じく無視してもOKです。
[ロケーションを作成する]をクリックします。
これと同様の作業を事業部のフォルダ単位で設定を行います。
5.致命的な仕様上の問題
サクサク設定していると、日本企業では致命的な仕様を見つけました。
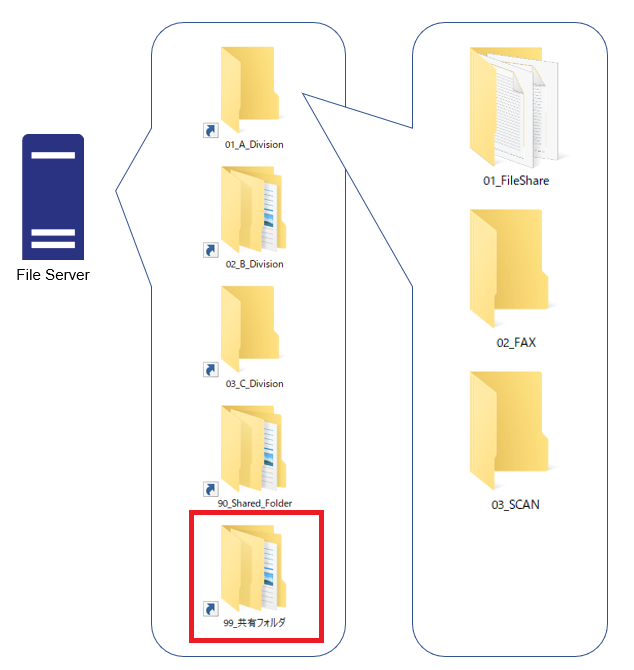
既存のファイルサーバのフォルダで日本語名が使われている場合どなるか検証しようと、上述のフォルダ構成の一番最後のフォルダ、[99_共有フォルダ]というフォルダを設定していました。
具体的には以下の赤枠部分です。
これを[ロケーション]設定しようとすると
こうなるわけですが、最後に[ロケーションを作成する]をクリックすると
なんとエラーが出て設定できません。
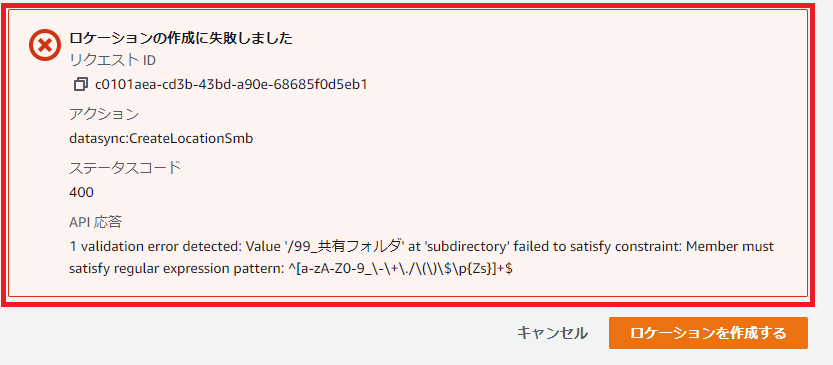
エラーメッセージを読み下してみると、
日本語名で指定した[99_共有フォルダ]が、正規表現でいうa-zA-Z0-0や各種記号などに含まれていないので設定できません。
という内容になっています。
はい。
日本企業にとってはめちゃくちゃ厳しいですね。
致命的です。
もはやエンタープライズユーザーという括りではなく、同期対象のフォルダ名に日本語を使っている企業がDataSync利用できない仕様です。
フォルダ名変更なんてした日には、ユーザー影響が大き過ぎてデータ移行なんてできないんじゃないでしょうか。
そこを何とかするのがSIerの腕の見せ所だと言われればまぁ、その通りですし幾通りかの具体的な解決策は考え付きますが、その方法を考案する工数と検証する工数は残念ながらユーザー企業に請求するしかありません。
・・・これってユーザーフレンドリーなんでしょうか?・・・
6.タスクの設定
続いて同期を行うタスクの設定です。
やっと同期設定ですね。
AWS管理コンソールから[DataSync]を選択し、[タスク]から[タスクを作成する]をクリックします。
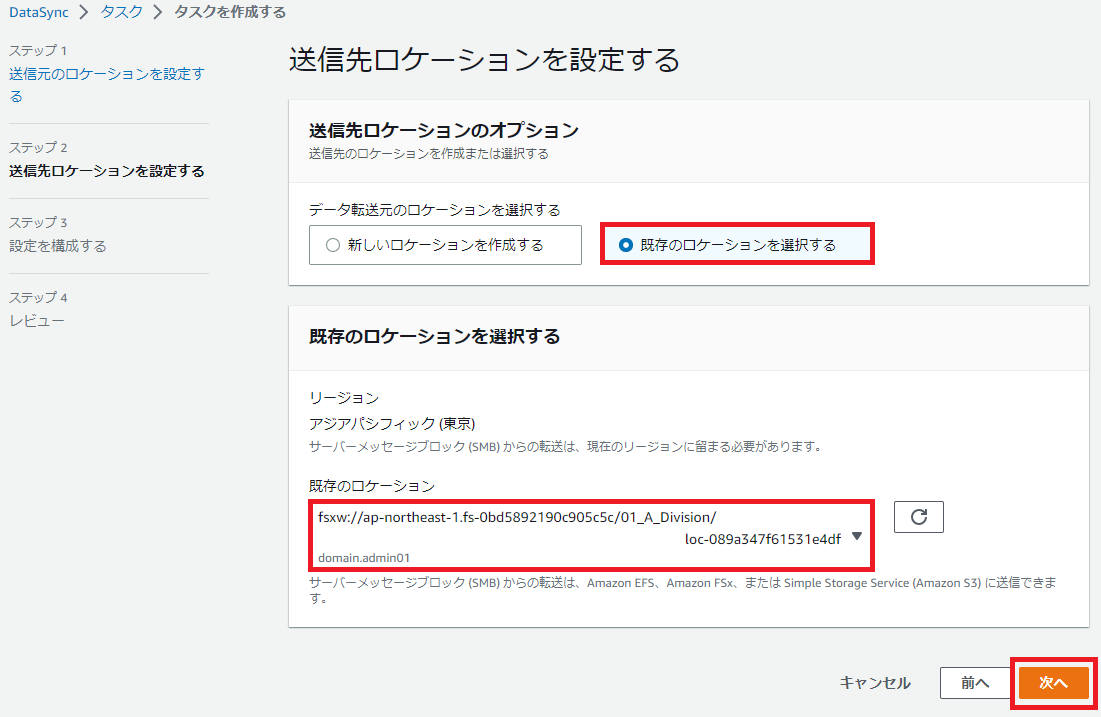
[既存のロケーションを選択する]を選択し、
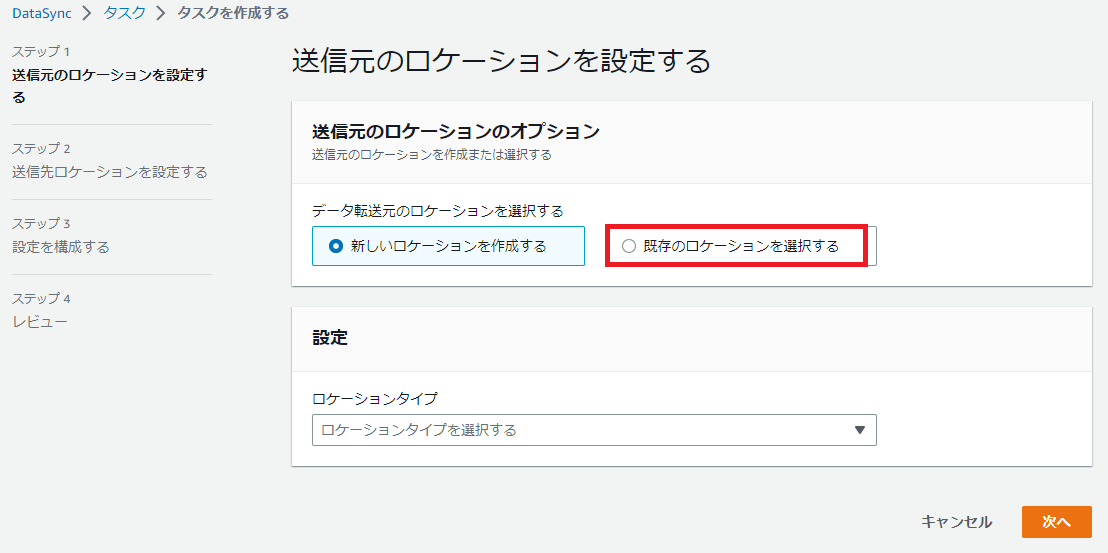
[リージョン]は[アジアパシフィック(東京)]を選択し、[既存のロケーション]はこの設定値は同期元なのでFSx for Windowsではなくオンプレミスのファイルサーバであるsmbを選択します。
今回だと[smb://172.16.0.61/01_A_Division/]になります。
最後に[次へ]をクリックします。
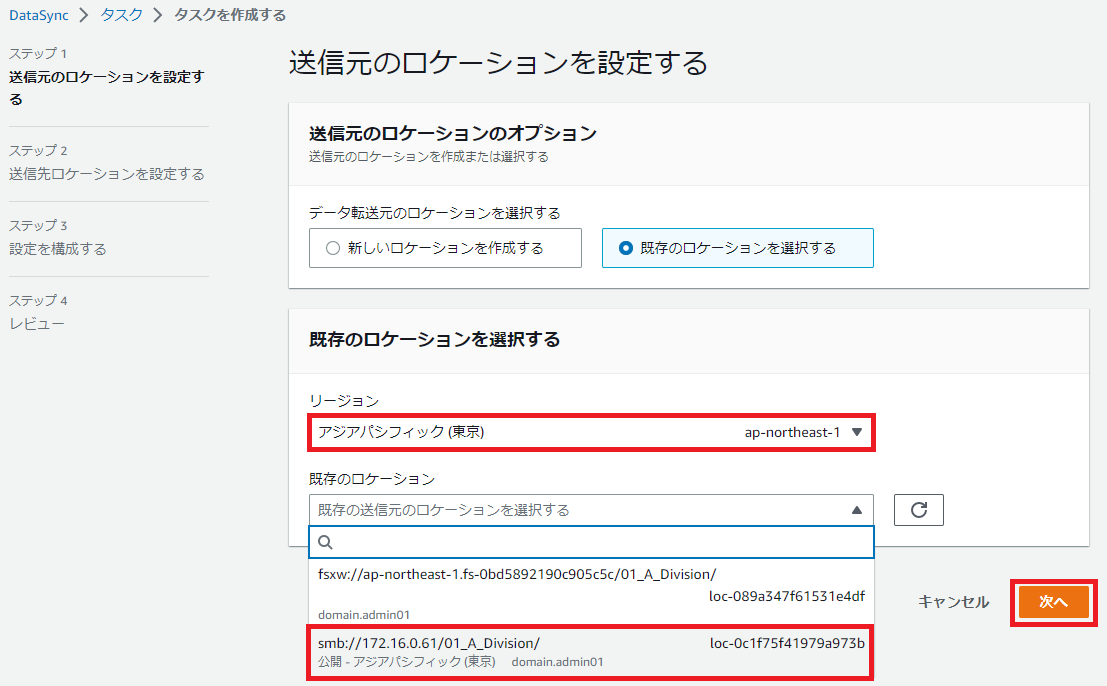
次は同期先なので、FSx for Windowsを選択して、最後に[次へ]をクリックします。
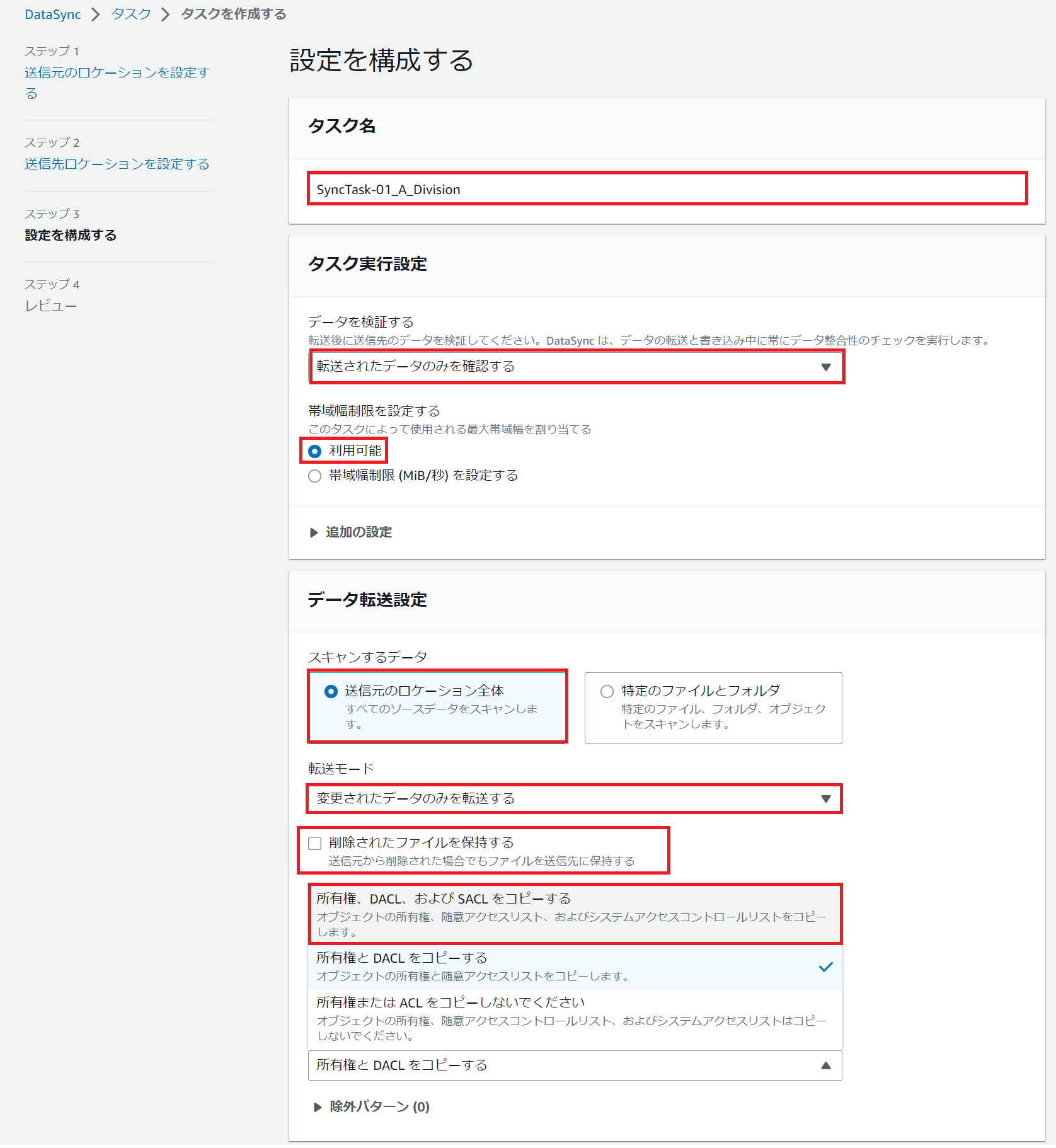
タスクの設定ができるようになります。
[タスク名]はどこのフォルダを同期しているのかわかる名前にしましょう。
[データを検証する]は[転送されたデータのみを確認する]を選択しましょう。
帯域制限はできますが、今回は[利用可能]、つまり全帯域利用可能、という状態に設定します。
[削除されたファイルを保持する]ですが、これはAzureには無い設定で、同期元、今回であればオンプレミスのファイルサーバで削除されたファイルをAWS側のFSx for Windowsでは保持するかどうか、という設定です。
選択肢があるというのは個人的には結構嬉しくて、恐らくオンプレミスのストレージ逼迫時にVSS的な使い方もできるのかな、という印象です。
しかし今回は完全同期を行った後に切替を行う想定ですのでここのチェックは外しておきます。
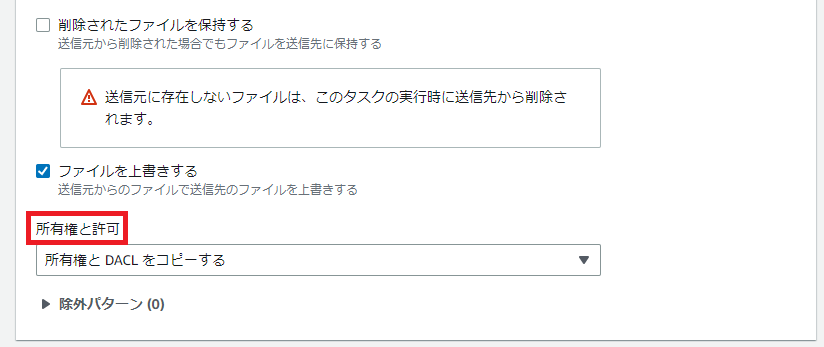
そして肝心の設定、[所有権と許可]ですが、[所有権、DACL、およびSACLをコピーする]を選択します。
ちょっと設定画面は隠れてしまってるんで改めて画面を出しときました。
[スケジュール]ですが実際の設定値を見てみると
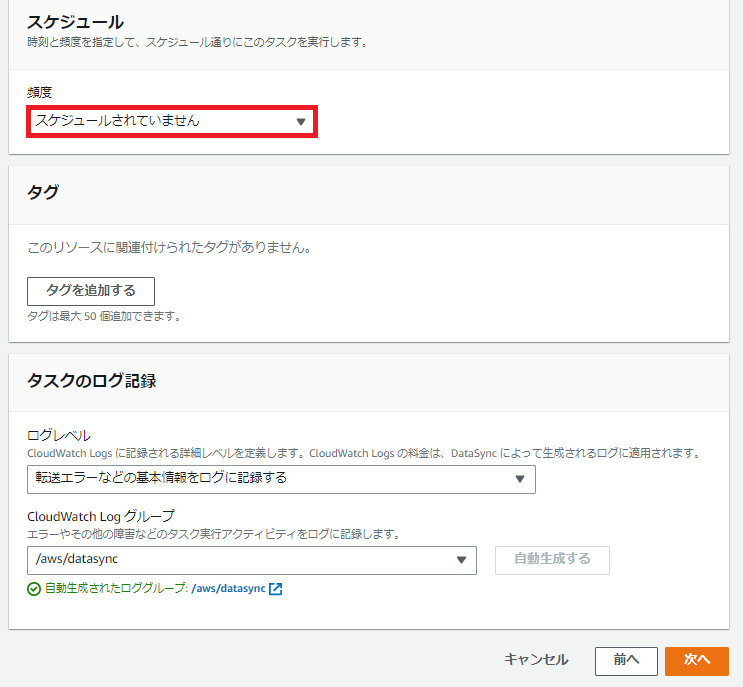
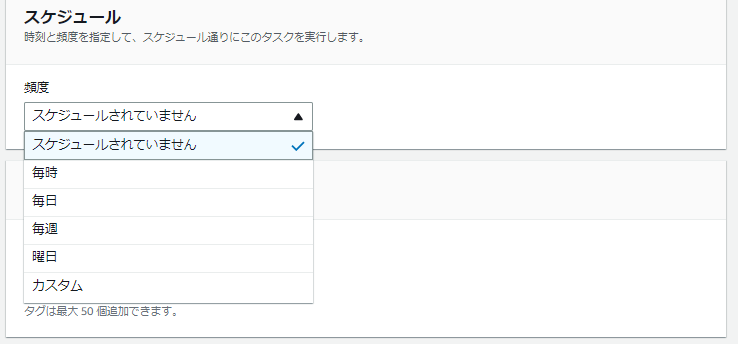
こんな感じになっています。
最短同期間隔は1時間です。
これは公式サイトに載ってました。
なので常時同期は設定できません。
1本目の記事の共通点と相違点にも記載していますね。
[タグ]は設定せず、[タスクのログ記録]もCloudWatchにログを吐いてくれるんですが大したログは吐かないので吐くだけ無駄なので吐かないでおきます。
最後に[次へ]で設定そのものは終わりです。
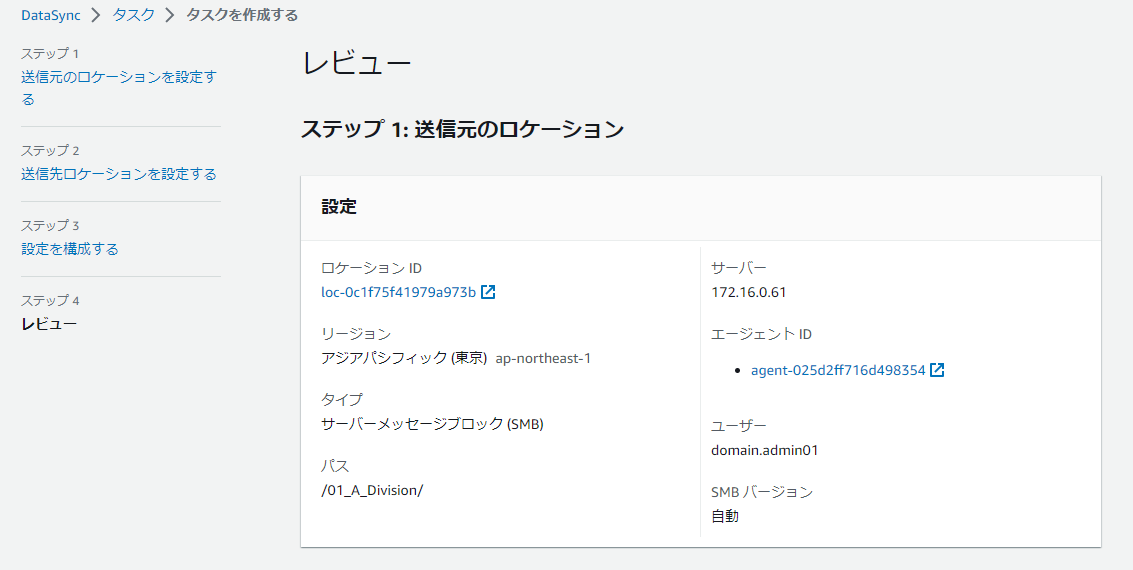
最後に[レビュー]画面が出てきますので、
[タスクを作成する]をクリックします。
はい。
やっとDataSyncの構築が終わりました。
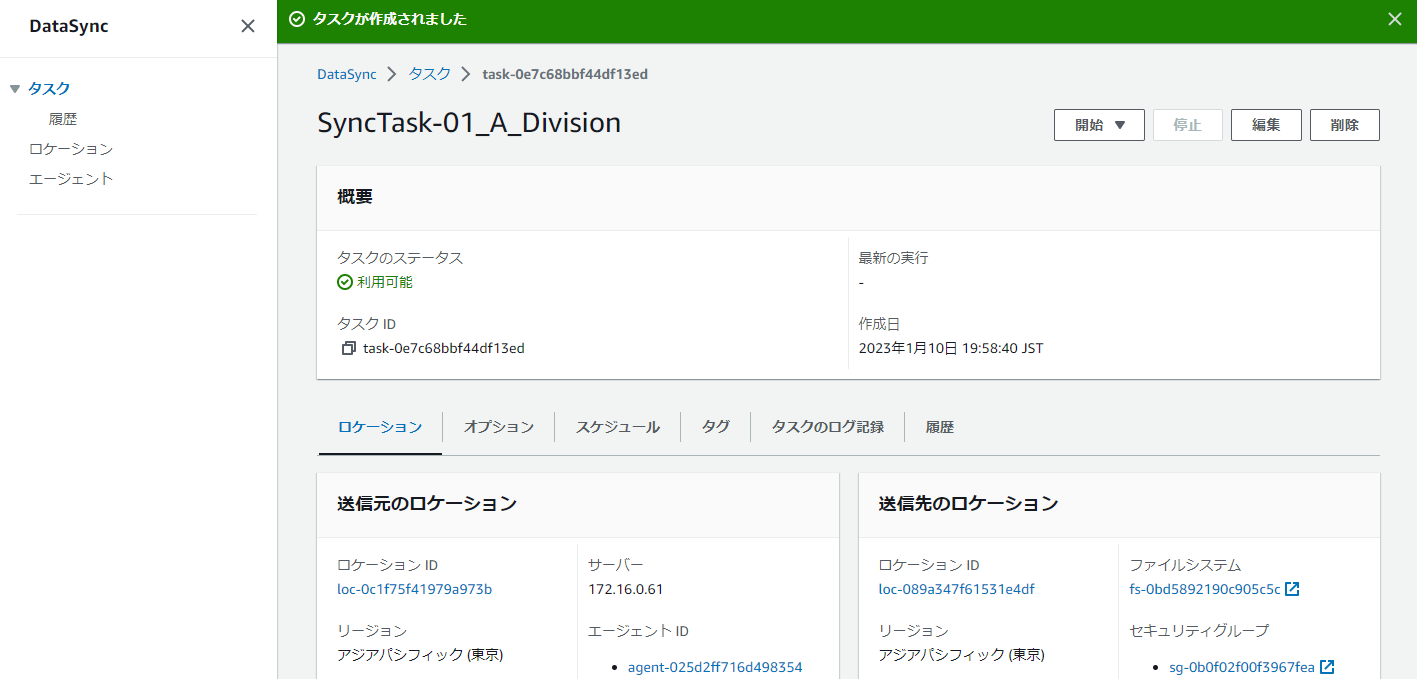
長かった。
三連休と更にプラス1日使ってこの記事書きました。
めちゃくちゃ時間かかりました。
まとめはちゃんとやろうと思いますが、File Syncの方が簡単です。
今回はここまで。