この記事は、ニフティグループ Advent Calendar 2020 最終日の記事です🎄
昨日は、@RPcat さんの 即フォーマットチェックにincronを使う でした。
ファイルの変更や操作を監視してくれるコマンドが用意されていることを知らなかったので、非常に勉強になりました。
はじめに
皆さん、サーバレスアプリケーションを作ろうと考えたときに選択するデータストアとして何を思い浮かべますか?
多くの人が思い浮かべるのは、
- Amazon DynamoDB
- Amazon RDS + Amazon RDS Proxy
だと思います。
ただ、DynamoDBを使っているときに**「使い慣れているSQLを使いたいなあ」と感じたり、個人でRDSを使うには「金額が高すぎるなあ」**と感じることがあると思います。自分がそう感じていました。
そこで、これらの問題を解決する一つの選択肢として Amazon S3 Select が存在することを以下のスライドで知ったので共有します。

今回は以下の内容で構成されています。
- S3 Selectの概要
- コンパネから使ってみる
- pythonから使ってみる
- 実際に使ってみて感じた、良かった点・辛かった点
S3 Selectの概要
S3 Selectとは、S3に存在するファイルに対して、SQL文を用いてデータのフィルタリングができるサービスです。
対応ファイルタイプ
対応するファイルタイプとしては、csv、json,
Apache Parquetがあり、csvの区切り記号としてカンマやタブ、自分で設定した文字列を選択することができます。
GZIPなどの圧縮タイプにも対応しています。
対応するSQL文
S3 Selectと言う名前だけあって利用できるのはselect文になり、以下のようなSQL文を実行することができます。
SELECT * FROM s3object s
1,john,18
2,thomas,20
3,daniel,19
どんなSQLが書けるかは、以下の記事に詳しく書いてありますのでここでは省きます。
S3 SelectでどんなSQLが書けるか検証 | AWSやシステム・アプリ開発の最新情報|クロスパワーブログ
insert文やupdate文などのデータを更新する機能はありません。
S3からダウンロード→ファイルに追記→アップロードする必要があります。
なので、同時に複数箇所から書き込みがあるアプリケーションへの利用には向いていません。
コンパネから使う
S3 Selectはコンパネから簡単に始めることができます。
まずは、バケットに任意のcsvファイルを配置します。今回は、以下のcsvファイルを配置します。
id,name,age
1,john,18
2,thomas,20
3,daniel,19
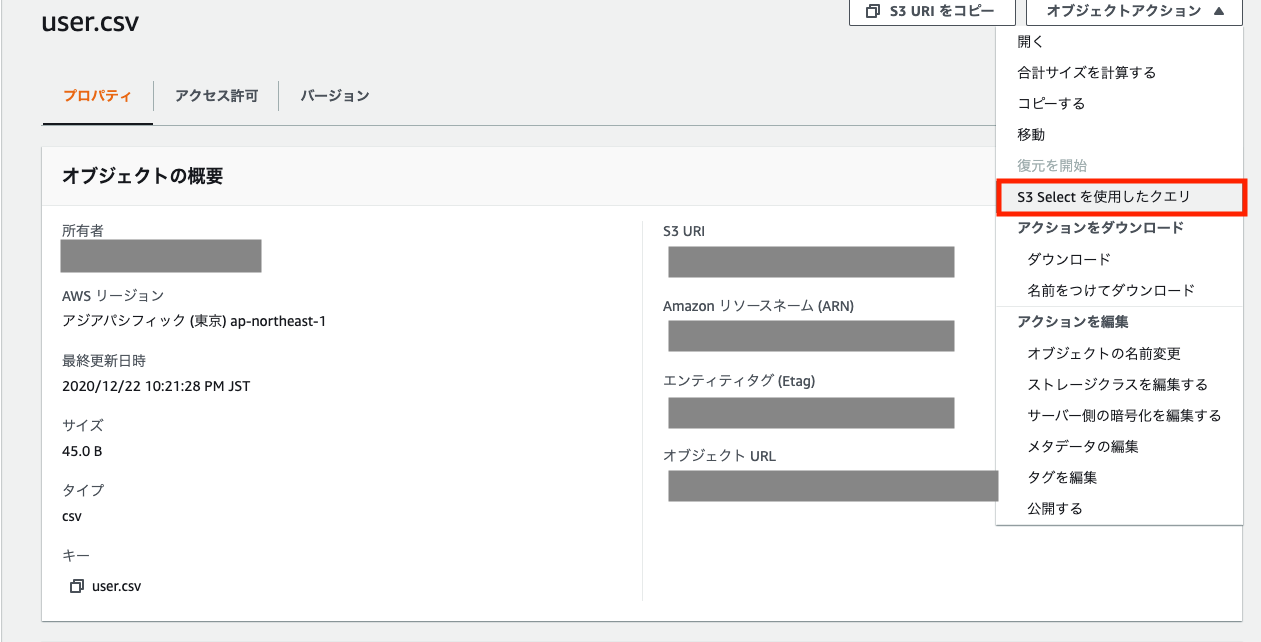
ファイルを選択し、S3 Selectを使用したクエリを選択します。
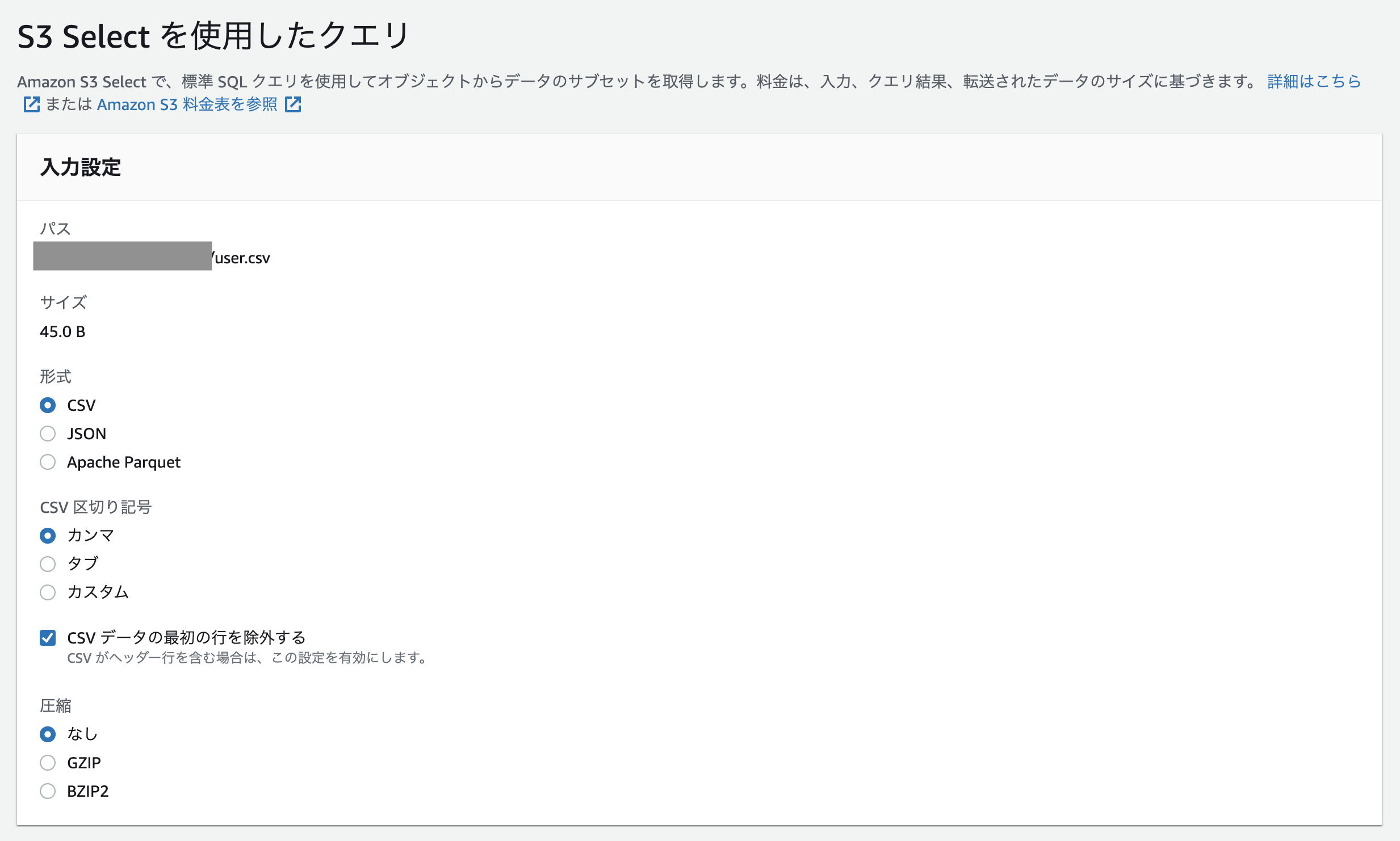
アップロードしたファイルに合わせてファイル形式や区切り文字の設定を行います。
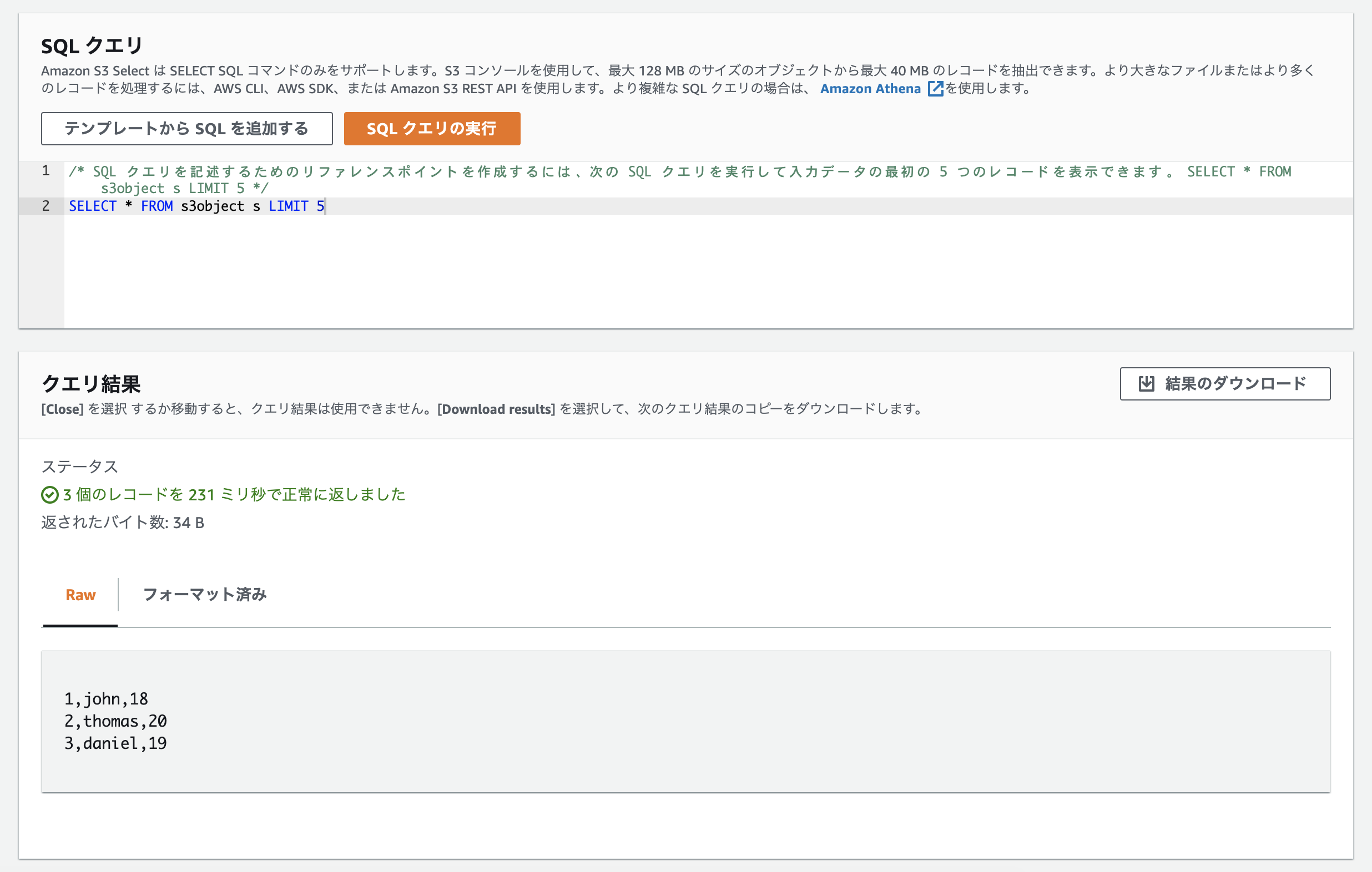
今回はテンプレートで用意されているSQL文を使用します。
SQLクエリの実行をクリックするとcsvファイル上のデータを出力することができます。
pythonから使ってみる
以下のコードで実行できます。profileとbucketを任意のものに書き換えてください。
import boto3
from boto3.session import Session
profile = "{profile_name}"
session = Session(profile_name=profile)
s3 = session.client("s3")
response = s3.select_object_content(
Bucket="{bucket_name}",
Key="user.csv",
ExpressionType="SQL",
Expression="SELECT * FROM s3object limit 5",
InputSerialization={"CSV": {"FileHeaderInfo": "Use"},
"CompressionType": "NONE"},
OutputSerialization={"CSV": {}},
)
for event in response["Payload"]:
if "Records" in event:
records = event["Records"]["Payload"].decode("utf-8")
print(records)
1,john,18
2,thomas,20
3,daniel,19
実際に使ってみて感じた、良かった点・辛かった点
良かった点
- 安い
- 3分で始められる
- SQL文で動く
- S3の恩恵を受けられる(手軽にバージョニング機能が使えたり)
辛かった点
-
order byとoffsetが使えないため、下からレコードを取得しづらい
例えば、ニュース記事テーブルが存在したとして、最新記事を日付で並び替えて取得することができません。
また、idが新しいレコードから取得するにもoffsetが使えないため取得することができません。
stack overflowでは、以下のようにwhere文でidの範囲を指定する方法が紹介されており、自分も現在はこの方法を使用しています。(良い方法があったら教えて欲しいです。)
Select * from s3 where row_index >= 1 and row_index <= 4
- joinができないのでファイル(テーブル)を分けづらい
joinができなため、可能な限り1つのテーブルに抑えたくなります。
結果的に、大きなアプリケーションで利用はしづくなると感じています。
まとめ
今回は、サーバレスの扱うデータストアとしてS3 Selectもあるかもよ、という内容で
S3 Selectの使い方や、実際に使ってみて感じたことについて書きました。
ファイルに書き込む機能がないため、
複数箇所からの書き込みがない読み込みメインのアプリケーションでなら選択肢に入るのでは考えています。
ここまで閲覧していただきありがとうございました!
そして、ニフティグループの皆さんお疲れ様でした!
参考
Amazon S3 Select を使用して、サーバーまたはデータベースなしでデータをクエリする | Amazon Web Services ブログ
JAWS DAYS 2020 | サーバレスの新しいデータストアの選択肢 S3 Select の魅力 - Speaker Deck
S3 SelectでどんなSQLが書けるか検証 | AWSやシステム・アプリ開発の最新情報|クロスパワーブログ