この記事は Redash Advent Calendar 2017 20日目の記事です。
18日目のRedashのmetadataから便利な情報を取ってくる話と似たような内容になっています。
概要
Redashのデータソースとなるようなデータベース(Redshiftなど)を運用していると、まれに酷いクエリ(実行に時間のかかるクエリや、エラーになるクエリ)も定期的に打たれるようになってきて辛い思いをするようにもなります。
特にRedshiftを運用していると、厳密にどのクエリがエラーを発生させたのかを後から追跡することが難しかったり、STL_ERRORに結構な勢いでエラーログが溜まっていくということがあったりします。
ここでは、そんな辛い思いをするときによく確認するクエリを整理しておきます。
バージョンとしてはschedule_failures が導入された2.0以降の利用を想定しています。
利用するテーブル
Redashのデータが格納されるPostgreSQLをデータソースとして登録し、主に以下の2つのテーブルを利用します。
| テーブル名 | 概要 |
|---|---|
| query_results | Queryの実行結果が格納される |
| queries | Queryの情報が格納される |
注意点
- この2つのテーブルをJoinする場合は QUERY_HASH を使う。
Queryを変更してしまうと別物となるので注意が必要です。 - query_resultsには、実行に失敗した情報は格納されません。
- queriesの SCHEDULE_FAILURES にはエラーが発生した回数が累計で登録されていますが、実行が成功すると0になります。
Redashで確認できることはそこまで多くは無いので別途データソース側のシステムテーブルなども確認は必要なります。
スケジュール実行していてエラーになっているクエリを探す
今日発生したエラーの確認をします。
どんなエラーが発生したのかはDBには保存されないので注意が必要です。
SELECT
id,
name,
query,
query_hash,
schedule,
schedule_failures
FROM
queries
WHERE
schedule_failures != 0
AND updated_at >= CURRENT_DATE
ORDER BY
schedule_failures DESC
;

queries.schedule_failures はクエリの実行に成功した際に0に戻るので、成功と失敗が混在するようなケース※だとクエリを実行するタイミングによってはこのクエリで確認することはできないかもしれません。
※ 例えばデータの件数が0件だとdivision by zeroが発生するが、常に0件という場合では無いような場合。
当日の実行回数の多いクエリーを探す
当日の実行回数の多いクエリを確認します。
以下の例では、10回以上実行しされているクエリのみを抽出しています。
(ただし実行に失敗した場合はカウントされません。)
WITH q_r AS (
SELECT
query_hash AS q_r_hash,
COUNT(query_hash) AS run_count,
MAX(retrieved_at) AS recent_exec
FROM
query_results
WHERE
retrieved_at >= CURRENT_DATE -- 当日のデータのみを対象にする
GROUP BY
query_hash
)
SELECT
q.id,
q.query_hash,
q_r.run_count,
q_r.recent_exec,
q.schedule
FROM
queries as q
JOIN q_r
ON query_hash = q_r_hash
WHERE
run_count > 10 -- 10回より多く実行されたクエリのみ取得
ORDER BY
run_count DESC
;
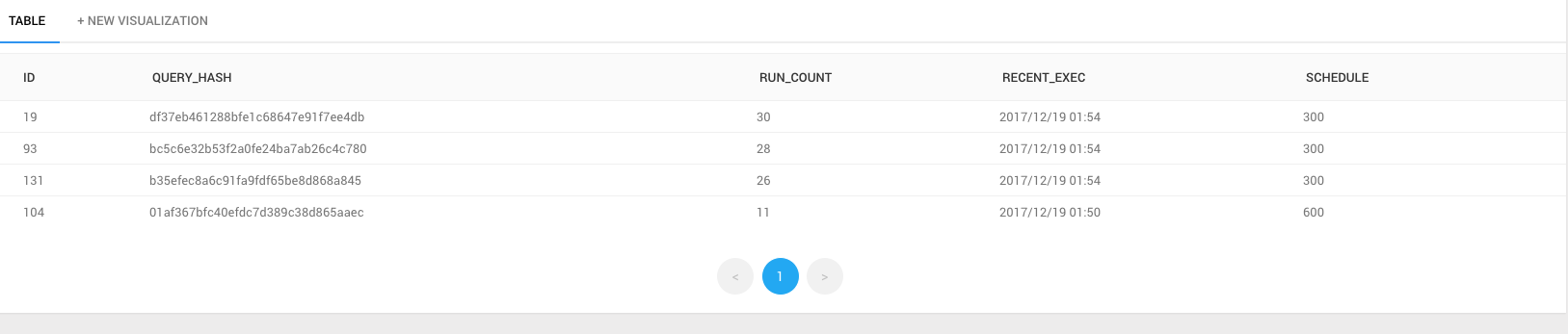
このクエリや、下記の実行時間のかかっているクエリを利用し、DATA_SOURCE_ID で絞り込んで QUERY の内容をみて不必要に頻繁に実行され負荷をかけているクエリを洗い出したりします。
(実際は、nameやqueryなど出力する形で利用するかと思います。)
SCHEDULEを見ると、Every day at xx:xxのようなクエリが比較的上位に上がってきたりして、若干?となりますがある程度の傾向は見えるかと思います。
実行時間のかかっているクエリを探す
過去1週間で、平均的に時間のかかっているクエリを探すには以下のようにします。
実際には、この情報を元に接続先のデータソースでSlow Queryとなっていないか別途確認するなどが必要になるかと思います。
WITH q_r AS (
SELECT
query_hash AS q_r_hash,
COUNT(query_hash) AS run_count,
AVG(runtime) AS avg_spend -- 単位はsec
FROM
query_results
WHERE
retrieved_at >= CURRENT_DATE - integer '7' -- 過去1週間に実行されたクエリを対象にする
GROUP BY
query_hash
)
SELECT
q.id,
q.query_hash,
q_r.run_count,
q_r.avg_spend,
q.schedule
FROM
queries as q
JOIN q_r
ON query_hash = q_r_hash
WHERE
run_count > 7
ORDER BY
avg_spend DESC
;