はじめに
- 最近 Llama 3 やら Phi-3 やら Gemma 2 やらでローカルLLM界隈が盛り上がってきています。
- 「自分でもローカルLLMを試したい!けどGPU搭載のマシンが手元にない!」 という方のために、AWSやAzureでローカルLLMを動かすのための手順をまとめてみました。
- またOllama APIをPython, REST API, UiPath Studioからコールする方法についても紹介したいと思います。
大まかな流れは次の通りです。
- 仮想マシン構築 : Amazon EC2またはAzure Virtual MachineでGPU搭載の仮想マシンを立てる
- ドライバーなどのインストール : NVIDIAのドライバーとCUDAライブラリーをインストールする
- Dockerコンテナとモデルのデプロイ : DockerをインストールしてOllama・モデルとOpen WebUIをコンテナをデプロイする
- Open WebUI でアクセス : ブラウザー経由でローカルLLMを切り替えて問い合わせる
- APIコール : Ollama APIをPython, REST API, UiPath Studioからコールする
1. 仮想マシン構築
- ローカルLLMを動かすための仮想マシンを構築します。GPUなしでも一応動作しますが応答がかなり遅くなるのでGPU搭載の仮想マシンを用意した方が賢明です。
- AWSでは P3/G5インスタンスなど、Azureでは NCファミリーなど がGPU搭載になります。手持ちのアカウント・サブスクリプションなどに応じて選択しましょう。
- 動作させるモデルのパラメーター数などに応じてインスタンスタイプを選定します。GPU 16GBでもLlama3 8BやGemma2 9Bクラスであれば動作させられます。Llama3 70Bを動かすためにはスケールアップが必要になります。どのモデルが動作するかは皆さん自身でお試しいただければと思います。
AWS
Amazon EC2インスタンスをデプロイします。事前にVPCなどは構築しておきます。
下記スペックのEC2インスタンスを作成します。
-
OS: Ubuntu 22.04 LTS (
ami-0595d6e81396a9efb) -
インスタンスタイプ:
g4dn.xlarge -
ストレージ: 256 GiB (ボリュームタイプ
gp3)- ※ ローカルLLMの各モデルサイズが数GB程度あるのでディスク容量がそれなりに必要です。あとでボリューム追加したり拡張したりが面倒なので多めに取っておきます。
- 運用コスト(オンデマンド): 2024年7月時点、東京リージョンでは $0.71/h、オハイオリージョンでは $0.526/h です。またストレージのコストが別途かかります。
今回はパブリックサブネットにインスタンスを作成します。セキュリティグループでMyIPのアクセスのみ許可しておきましょう。もちろんセキュリティを高めるにはプライベートサブネットに構築して踏み台サーバーからアクセスした方が良いですが、簡略化のためその手順は割愛します。
Azure
Azure VMインスタンスをデプロイします。事前にリソースグループなどは作成しておきます。
下記スペックのAzure VMインスタンスを作成します。
- OS: Ubuntu Minimal 22.04 LTS - x64 Gen2
-
セキュリティの種類:
Standard -
インスタンスタイプ:
NC4as_T4_v3- ※ クォータ制限がかかっているときには 緩和申請 を上げます
- ストレージ: 256 GiB
-
運用コスト(従量課金制): 2024年7月時点、東日本リージョンでは $0.71/h、米国東部リージョンでは $0.526/h です。またストレージのコストが別途かかります。
- たまたまかもしれませんが AWSの
g4dn.xlargeインスタンスと同じ価格ですね。
- たまたまかもしれませんが AWSの

今回はパブリックIPを割り当ててインスタンスを作成します。ネットワークセキュリティグループでMyIPのアクセスのみ許可しておきましょう。もちろんセキュリティを高めるにはプライベートIPのみで構築して踏み台サーバーからアクセスした方が良いですが、簡略化のためその手順は割愛します。
2. ドライバーなどのインストール
- インスタンスが作成できましたらSSHクライアントでアクセスしてドライバーなどをインストールします。
NVIDIAドライバーのインストール
- まずはNVIDIAドライバーなどをインストールします。次のコマンドを順次実行します。
sudo apt-get update sudo apt install -y ubuntu-drivers-common sudo ubuntu-drivers devices
== /sys/devices/LNXSYSTM:00/LNXSYBUS:00/ACPI0004:00/VMBUS:00/47505500-0001-0000-3130-444531454238/pci0001:00/0001:00:00.0 ==
modalias : pci:v000010DEd00001EB8sv000010DEsd000012A2bc03sc02i00
vendor : NVIDIA Corporation
model : TU104GL [Tesla T4]
driver : nvidia-driver-545 - distro non-free
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-535 - distro non-free recommended
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
- recommendedとなっている
nvidia-driver-535をインストールし、OS再起動します。sudo apt install -y nvidia-driver-535 sudo reboot - 再度SSH接続してドライバーロードを確認します。
sudo dmesg | grep -i nvidia
[ 8.396041] nvidia: loading out-of-tree module taints kernel.
[ 8.396058] nvidia: module license 'NVIDIA' taints kernel.
[ 8.396064] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 8.396066] nvidia: module license taints kernel.
[ 8.639292] nvidia-nvlink: Nvlink Core is being initialized, major device number 238
[ 8.660366] nvidia 0001:00:00.0: enabling device (0000 -> 0002)
[ 8.976123] nvidia 0001:00:00.0: can't derive routing for PCI INT A
[ 8.976127] nvidia 0001:00:00.0: PCI INT A: no GSI
[ 8.994223] audit: type=1400 audit(1719968699.363:2): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe" pid=325 comm="apparmor_parser"
[ 8.994229] audit: type=1400 audit(1719968699.363:3): apparmor="STATUS" operation="profile_load" profile="unconfined" name="nvidia_modprobe//kmod" pid=325 comm="apparmor_parser"
[ 9.029938] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 535.183.01 Sun May 12 19:39:15 UTC 2024
[ 9.058591] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 535.183.01 Sun May 12 19:31:08 UTC 2024
[ 9.061593] [drm] [nvidia-drm] [GPU ID 0x00010000] Loading driver
[ 12.189391] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0001:00:00.0 on minor 1
[ 12.261708] nvidia_uvm: module uses symbols nvUvmInterfaceDisableAccessCntr from proprietary module nvidia, inheriting taint.
[ 12.298209] nvidia-uvm: Loaded the UVM driver, major device number 235.
-
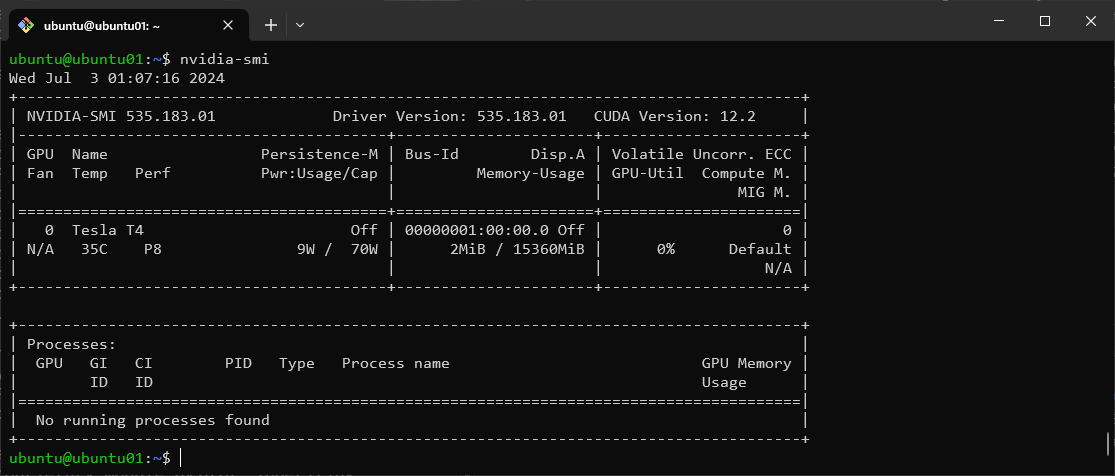
nvidia-smiを実行して次のように表示されればNVIDIAドライバーのインストールは完了です。
CUDAツールキットのインストール
- CUDAツールキットをインストールします。ここでは 12.4 Update 1 をインストールします。次のコマンドを順次実行します。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb sudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt install -y cuda-toolkit-12-4 sudo apt install -y cuda-drivers
3. Dockerコンテナとモデルのデプロイ
Dockerインストール
- Dockerをインストールします。現在のユーザーでも
dockerコマンドを実行できるようにdockerグループに自分自身を含めます。curl -fsSL https://get.docker.com | sh sudo usermod -aG docker $(whoami)
Ollamaコンテナをデプロイ
- Ollama DockerイメージをGPU実行できるように
nvidia-container-toolkitをインストールしてOS再起動します。(参考情報)curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \ | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \ | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \ | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt install -y nvidia-container-toolkit sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker sudo reboot - SSHで再接続後、OllamaコンテナをGPU指定して起動します。OS再起動時の自動起動をオンにします。
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always ollama/ollama -
docker ps -aコマンドでコンテナ実行を確認します。

モデルのデプロイ
-
https://ollama.com/library でデプロイしたいモデルを検索します。代表的なモデルは こちら に一覧があります。
-
Ollamaでモデルをダウンロードして実行するには
docker exec -it ollama ollama run {model}:{tag}を実行します。- モデル実行後の >>> のプロンプトは一旦
/byeで抜けます。

- モデル実行後の >>> のプロンプトは一旦
-
コマンド実行例:
- Llama 3:
docker exec -it ollama ollama run llama3 - Phi-3:
docker exec -it ollama ollama run phi3 - Gemma 2:
docker exec -it ollama ollama run gemma2
- Llama 3:
-
※ もし不要なモデルを削除したい場合には
docker exec -it ollama ollama rm {model-name}を実行しましょう。
Ollama Libraryにないモデルのデプロイ
- Hugging Faceなどに公開されているモデルも動かすこともできます。ファイルフォーマットは
ggufが前提になります。 - たとえば Llama-3-ELYZA-JP-8B を動かすには次のコマンドを順次実行します。(参考情報)
sudo docker exec -it ollama bash # コンテナの中に入る apt install -y wget wget -O Llama-3-ELYZA-JP-8B-q4_k_m.gguf https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/resolve/main/Llama-3-ELYZA-JP-8B-q4_k_m.gguf?download=true cat << 'EOF' > Modelfile FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|> {{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|> {{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|> {{ .Response }}<|eot_id|>""" PARAMETER stop "<|start_header_id|>" PARAMETER stop "<|end_header_id|>" PARAMETER stop "<|eot_id|>" PARAMETER stop "<|reserved_special_token" EOF ollama create elyza:jp8b -f Modelfile ollama run elyza:jp8b exit # コンテナから出る
Open WebUI コンテナをデプロイ
- Ollama で実行中のモデルにWebインターフェースから問い合わせできるように Open WebUI のコンテナをデプロイします。
docker run -d -p 8080:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
4. Open WebUI でアクセス
- ブラウザーで
http://{Ollama-ip}:8080にアクセスします。あらかじめファイアウォールを通しておきましょう。 - 初回サインインにはサインアップが必要になります。
-
[Select a model] で先ほど
ollama runでデプロイしたLLMを選択できます。早速プロンプトを実行してみましょう! - GPU 16GBで
Llama-3-ELYZA-JP-8Bを動かすと、こんな感じで動作します。

- ※ 応答が遅い場合にはGPUが使用されていない可能性があります。
nvidia-smiでGPUメモリが消費されているか確認しましょう。
5. APIコール
- エンドポイント
http://{Ollama-ip}:11434でOllama APIをコールできます。あらかじめファイアウォールを通しておきましょう。
Python
-
Ollama Python Library を使って、PythonコードでOllama APIをコールしてみましょう。
ollama-chat.pyfrom ollama import Client client = Client(host='http://{Ollama-ip}:11434') response = client.chat(model='llama3', messages=[ { 'role': 'user', 'content': 'Why is the sky blue?', }, ]) print(response['message']['content']) -
実行すると質問(Why is the sky blue?)に対する回答が表示されます。

REST API
-
Ollama APIの使用方法は こちら をご覧ください。
-
Postmanを使って Generate a chat completion (
POST http://{Ollama-ip}:11434/api/chat)を実行してみましょう。{ "model": "llama3", "messages": [ { "role": "user", "content": "Why is the sky blue?" } ], "stream": false, "options": { "temperature": 0.2, "top_p": 0.8 } }

UiPath Studio
UiPath StudioにてHTTP要求アクティビティを使用してAPIコールしてみます。実装手順としては Azure OpenAI Serviceなどと連携する場合 と同様ですが、OllamaはAPIキーなど認証の仕組みはありません。
-
UiPath Studioを起動してワークフローを作成します。今回はクロスプラットフォームのプロジェクトを使用します。

-
リクエストボディのためのJSON形式のテンプレートを使用します。あらかじめテキストファイル
request.jsonとして保存しておきます。request.json{ "model": "{{model}}", "messages": [ { "role": "user", "content": "{{prompt}}" } ], "stream": false, "options": { "temperature": 0.2, "top_p": 0.8 } } -
ワークフロー内ではJSON形式のテンプレートを読み込みます。
- {{model}} 部分を入力引数として受け取ったモデル
in_modelで置換します。 - {{prompt}} 部分を入力引数として受け取った質問内容
in_questionで置換します。 - 置換した文字列を
req_body変数にセットします
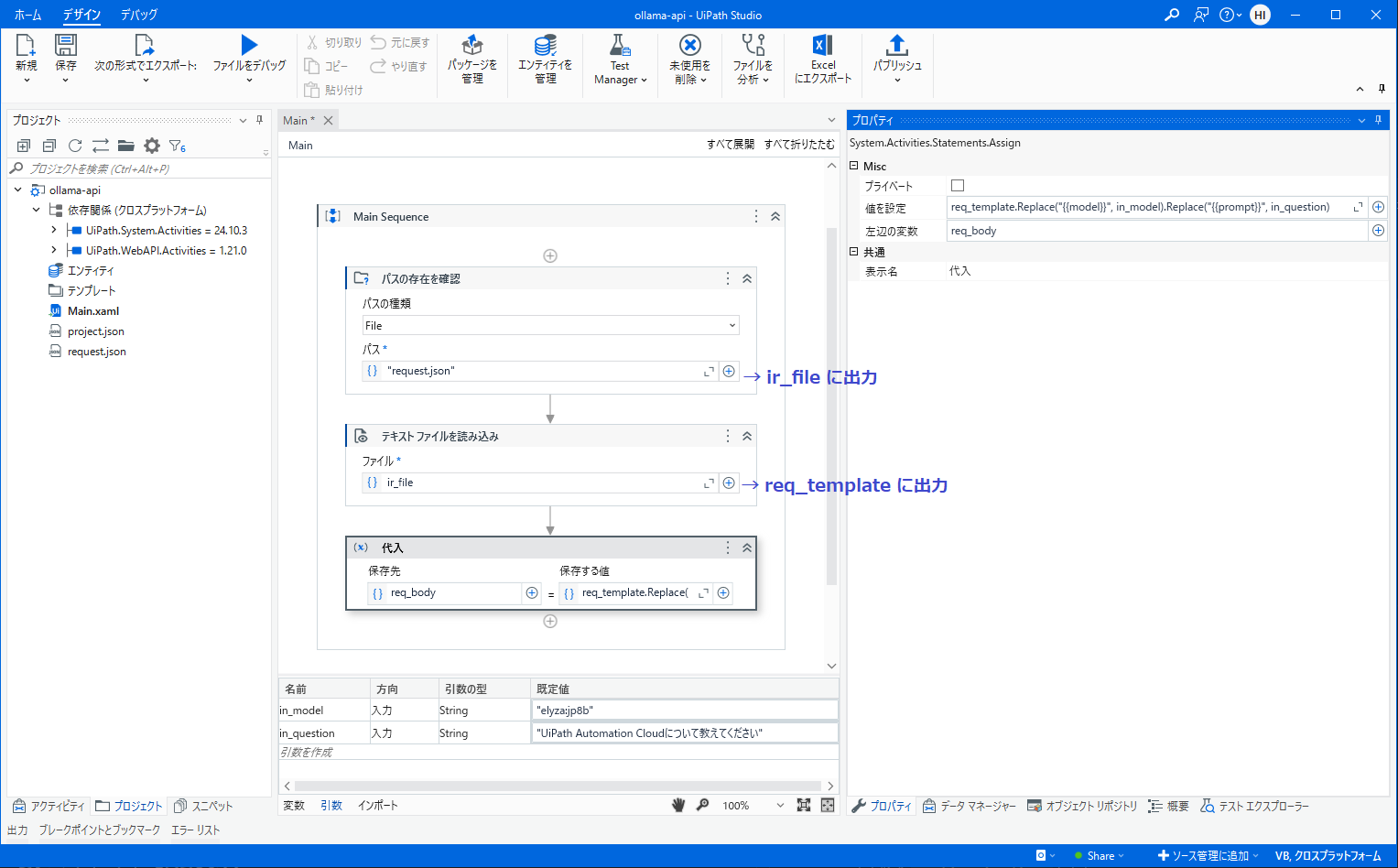
- {{model}} 部分を入力引数として受け取ったモデル
-
HTTP要求アクティビティ を実装します。
- 要求メソッド: POST を指定
- エンドポイント:
http://{Ollama-ip}:11434/api/chatを指定 - ヘッダー:
Content-Type: application/jsonを指定 - ボディ: 上の手順で組み立てた
req_body変数を指定 - タイムアウト: 120000 (2分間) に変更
- 本文形式:
application/jsonに変更 - 応答コンテンツ:
res_content変数にセット - 応答ステータスコード:
res_status変数にセット

-
後続の処理は次の通りです。
- ステータスコード
res_statusをチェックし、200であれば処理を継続し、200以外であればエラーを返します。 - 応答のコンテンツ
res_contentを逆シリアル化してJSONオブジェクトjson_contentにセットします。 -
json_content("message")("content").ToStringによってJSONオブジェクトから応答メッセージ部分を取り出してString型に変換します。 - 出力パラメーター
out_answerにセットします。

- ステータスコード
-
デバッグ実行して正常に実行されることを確認します。
おわりに
今回はAWS/Azure仮想マシンでローカルLLM環境を構築し、Open WebUIやAPIを使用してLLMに問い合わせる手順について説明しました。
これからもいろいろなモデルがリリースされることが期待されますので、手元にこのような環境があると手軽に検証できて便利だと思います。ぜひお試しください!