
H2Oは、ハイパフォーマンスなオンメモリー機械学習プラットフォームとして最近特に人気があります。
こちらのquoraでの回答によると、とにかく速い!ということのようです。
実は、このライブラリを作っているH2O社が、RユーザーがH2Oのアルゴリズムを使って機械学習しやすいようにと"h2o" というRパッケージを出しているので、Exploratoryの中からも使えるんです。
今日はその使い方を紹介してみたいと思います。
H2Oにはいろいろなアルゴリムがありますが、今日はExploratoryの中でももともサポートされているRandomForestを使ってみたいと思います。例として100万件のUSのフライトデータを元に、飛行機の出発遅れの予測をするモデルを作ります。
セットアップ
H2Oのインストールと起動
こちらのH2Oのページから、H2Oをダウンロードしてきて、シェルから、以下のようにスタートしておきます。
cd ~/Downloads
unzip h2o-3.14.0.3.zip
cd h2o-3.14.0.3
# memoryを多めに8GB取って、起動しておきます。
java -Xmx8g -jar h2o.jar
"h2o" Rパッケージのインストール
CRANに上がっているのh2oパッケージは少し古くて、先ほどインストールした最新安定版のH2Oにつながらないようですので、今回はh2o RパッケージもH2O社のサイトからダウンロードしてインストールしましょう。
こちらのリンクからh2oパッケージをダウンロードしておきます。
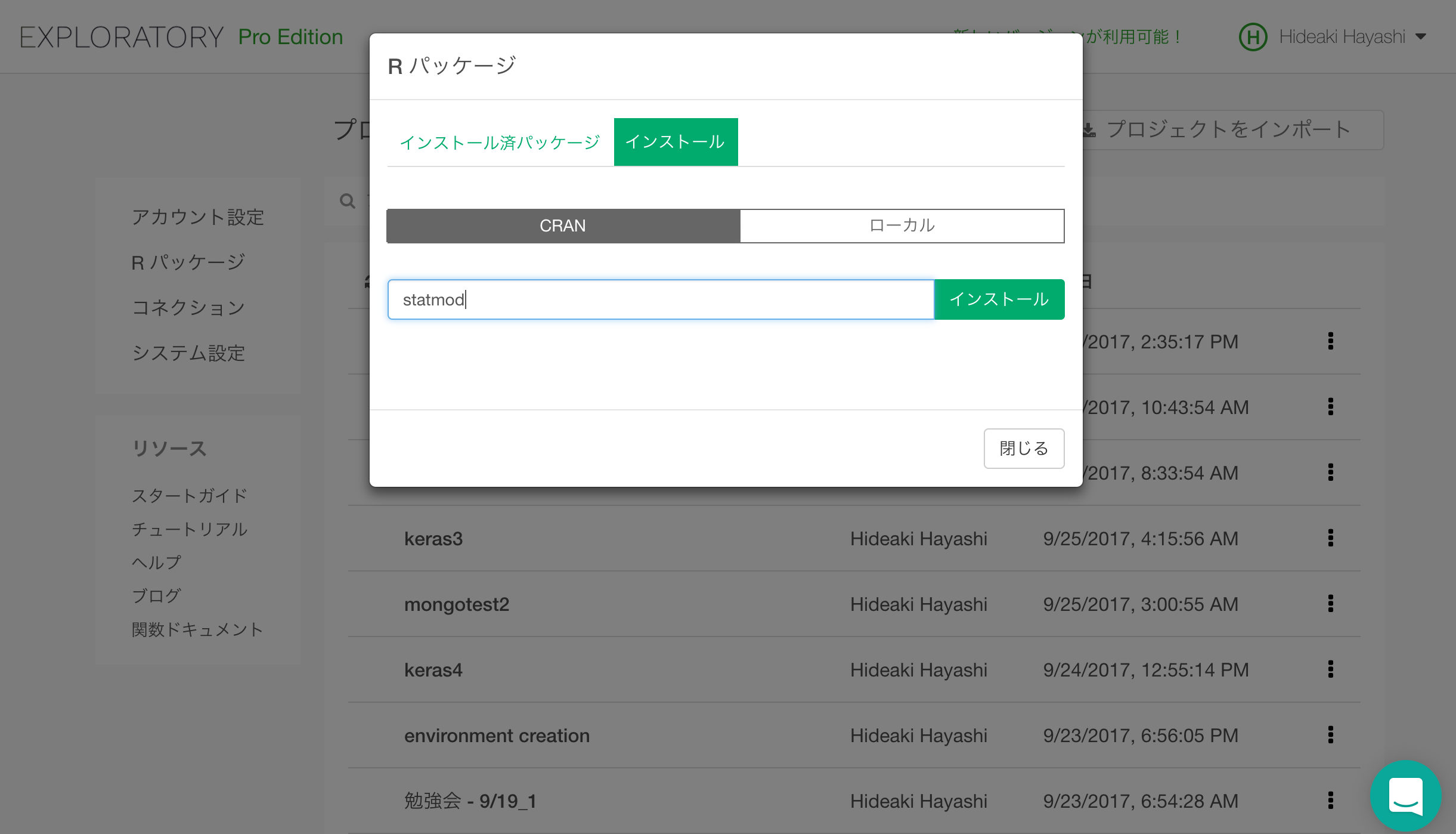
h2oをインストールする前に、statmodとRCurlの二つのパッケージをインストールしておく必要があります。
プロジェクトリストページから、Rパッケージメニューを選びます。
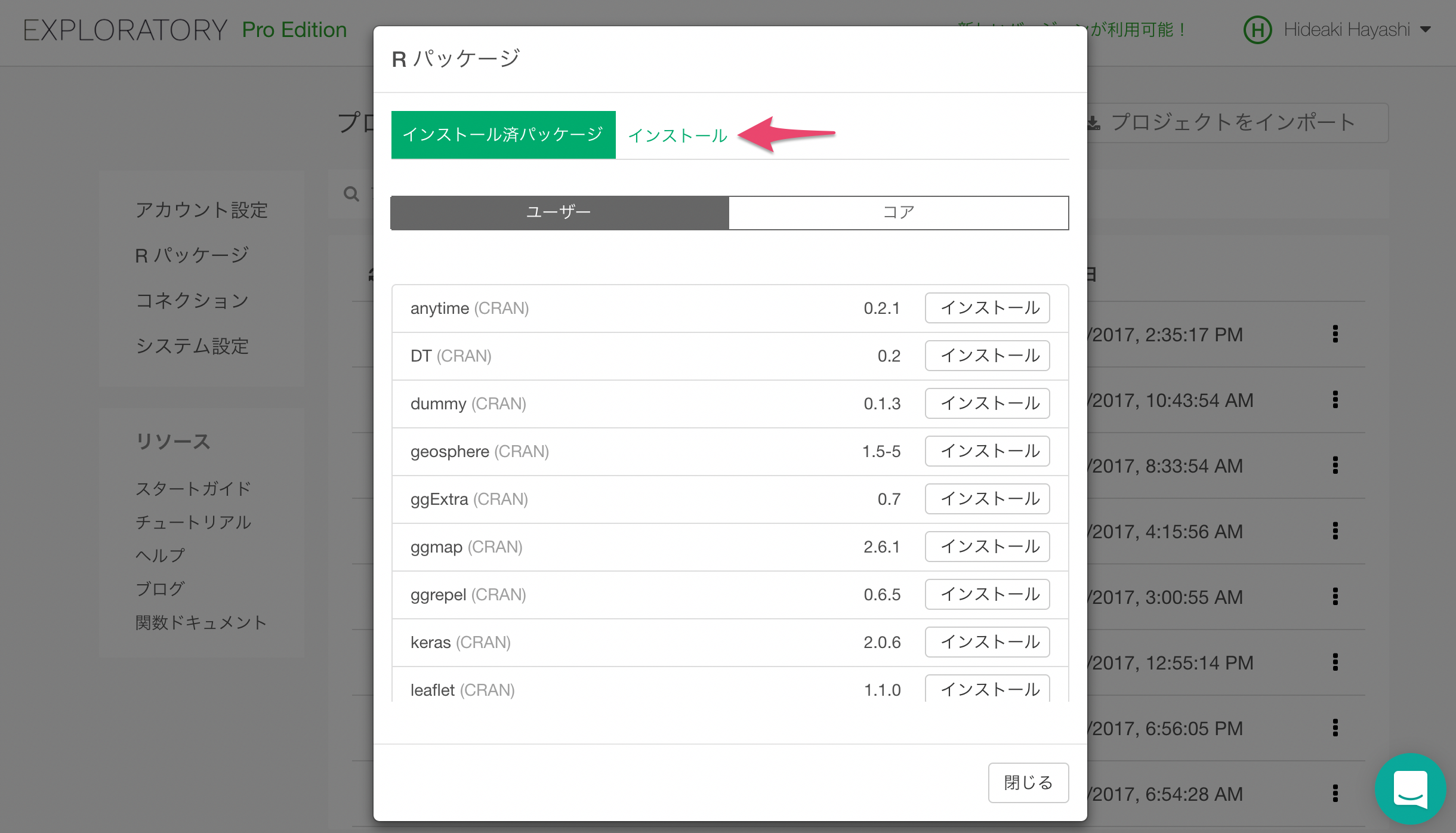
インストールタブを選びます。
statmodと入力して、インストールボタンをクリックすると、statmodがインストールされます。
同様にして、RCurlもインストールしておきます。
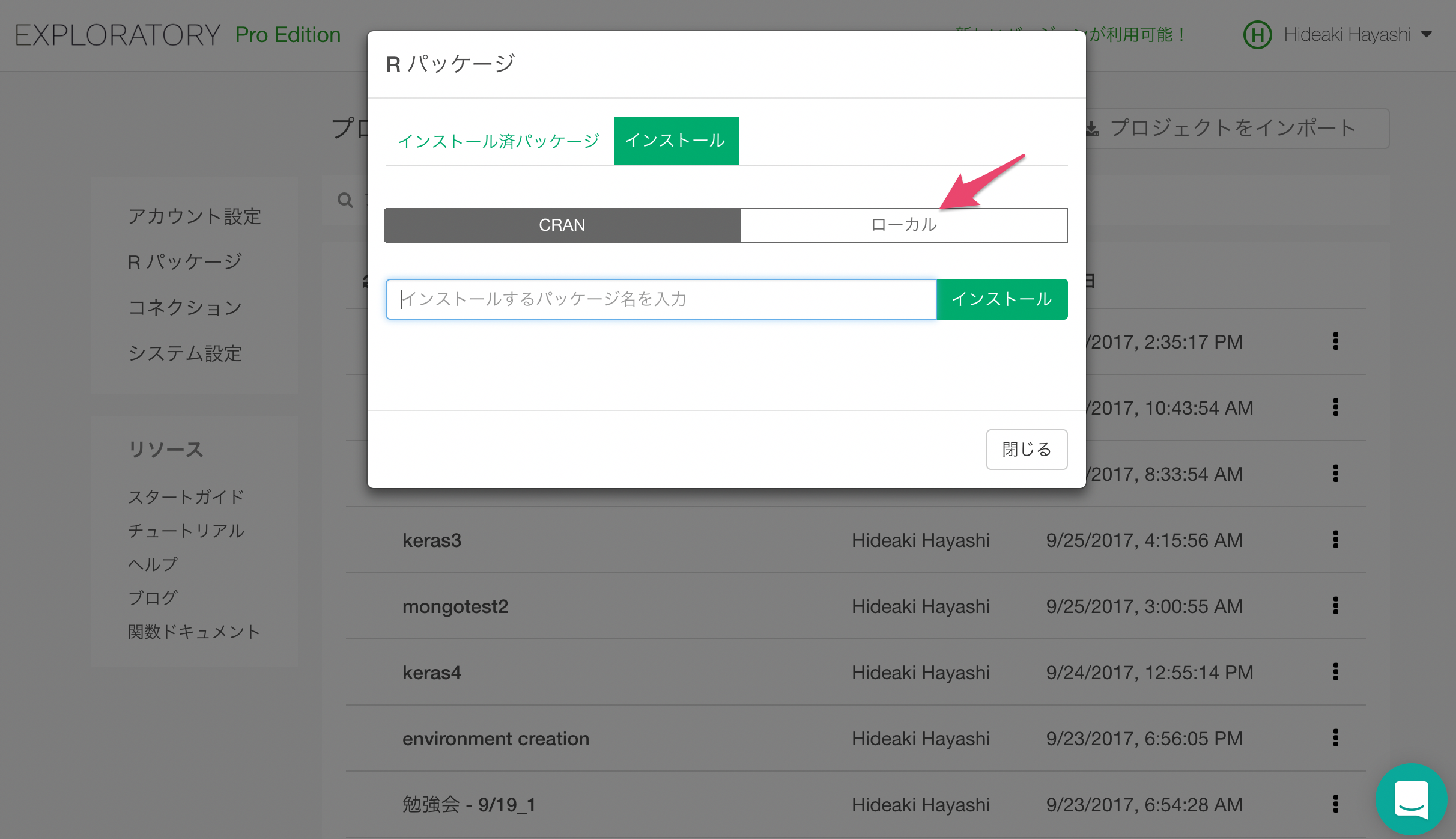
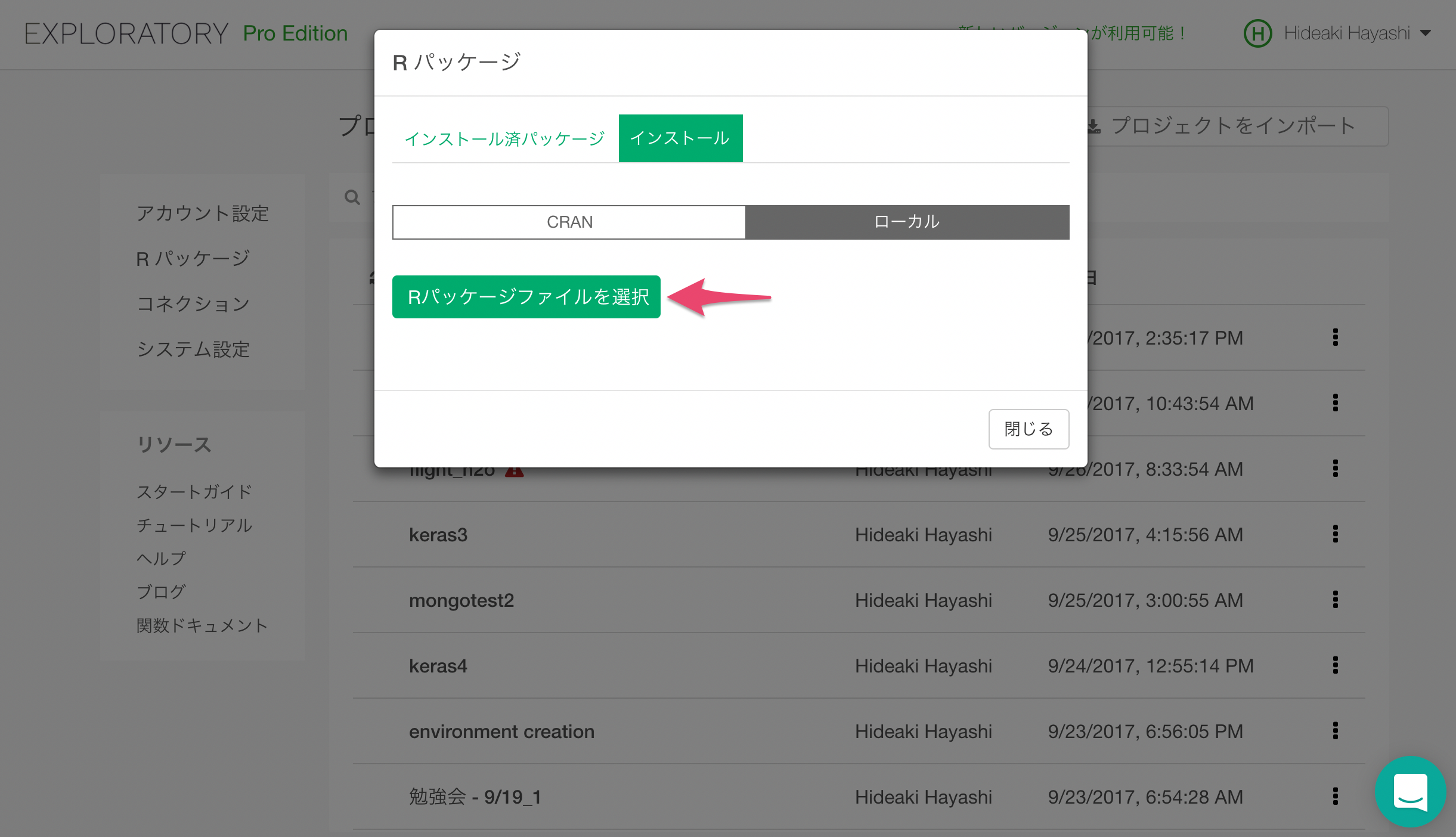
さて、さきほどダウンロードしてきたh2oパッケージをインストールしましょう。ローカルインストールタブをクリックします。
「Rパッケージファイルを選択」ボタンをクリックするとファイルピッカーが開きますので、先ほどダウンロードしてきたh2o_3.14.0.3.tar.gzファイルを選択すると、h2oパッケージがインストールされます。
ExploratoryのカスタムモデルとしてH2Oを使用出来るようにする
Exploratoryの中では、すでに多くの機械学習モデルがUIを通して使えるようサポートされていますが、それ以外にも自分の使いたいものをカスタムのRスクリプトを書くことによって追加できるフレームワークが用意されています。
こちらのフレームワークを使って、H2OのRandomForestアルゴリズムを使用するためのコードが以下になります。
以下のコードをコピーして、Exploratoryプロジェクト内にスクリプトを作成します。
# H2Oによる二値予測ランダムフォレストモデルを作成するfunctionを、
# ExploratoryのCustom Model Functionとして実装。
# https://docs.exploratory.io/user-defined-model-function.html
# h2oの初期化
library(h2o)
h2o.init(max_mem_size="60g", nthreads=-1)
# 普通のdata.frameをH2OFrame (データフレームのH2O版)に変換するユーティリティー関数
as_h2o <- function(df) {
# ramdom forestで使えるように、characterを全てfactorにする。
for (colname in colnames(df)) {
if (class(df[[colname]]) == "character") {
df[[colname]] <- as.factor(df[[colname]])
}
}
df <- as.h2o(df)
df
}
# H2Oのrandom forest modelを作成する関数。
build_h2o_rf_model <- function(formula, data, ntrees = 5) {
training_data <- data
lhs_cols <- all.vars(lazyeval::f_lhs(formula)) #予測される変数
rhs_cols <- all.vars(lazyeval::f_rhs(formula)) #予測の元となる変数
if (rhs_cols == ".") { # .が指定されたときは、全ての列で予測する。
rhs_cols <- colnames(training_data)[colnames(training_data) != lhs_cols]
}
training_data <- as_h2o(training_data) #学習データをH2OFrameに変換。
# random forest modelを作成して学習。
md <- h2o.randomForest(x = rhs_cols, y = lhs_cols, training_frame = training_data, ntrees = ntrees)
# モデル、formulaを一つのオブジェクトとして返す。
ret <- list(model = md, formula = formula)
class(ret) <- c("h2o_rf_model")
ret
}
# 学習済みのモデルに新しいデータを渡して予測させるfunction
augment.h2o_rf_model <- function(x, data = NULL, newdata = NULL, ...) {
if (is.null(data)) {
data <- newdata
}
formula <- x$formula
h2o_data <- as_h2o(data) #データをH2OFrameに変換。
predicted_data <- h2o.predict(x$model, h2o_data) #モデルによってデータを予測。
predicted_data <- as.data.frame(predicted_data) #予測データをdata.frameに戻す。
ret <- bind_cols(data, predicted_data) #予測データを元データにくっつけて返す。
ret
}
# モデルからデータフレームとしてモデルサマリビューで表示する情報を抽出するfunction
# ここでは学習データでの予測性能を出力する。
glance.h2o_rf_model <- function(x, ...){
mdperf<-h2o.performance(x$model)
h2o.metric(mdperf)
}
# モデルからデータフレームとしてモデルサマリビューで表示する情報を抽出するfunction
# ここでは変数重要度を出力する。
tidy.h2o_rf_model <- function(x, ...){
h2o.varimp(x$model)
}
H2Oが起動している状態で、Saveボタンをクリックして実行しておきます。

これで、ExploratoryからH2OのRandomForestアルゴリズムを呼び出して使えるようになりました。
さっそく、使ってみましょう。
データの準備
データの取得
さまざまな機械学習プラットフォームのベンチマークを行っている、こちらのgithubレポでまとめられている、飛行機のフライトデータを使いましょう。
100万件のフライトデータがまとまった、train-1m.csvを今回の実験のためにこちらに用意しましたので、ダウンロードしてください。
一行を一フライトとして、そのフライトに関する、出発日、出発時刻、出発地の空港、目的地の空港、また、出発到着がどれくらい遅れたのか、または早かったのかといった情報が入っています。
これをもとに、飛行機の出発が、15分以上遅れたかどうかの二値の予測をしてみましょう。
データの読み込み
ダウンロードしたtrain-1m.csv.zipを展開して、train-1m.csvを読み込みます。
Random Forestモデルの作成
フライトが15分以上遅れたかどうかを表すdep_delayed_15min列を、以下の変数から予測するrandom forestモデルを作成します。
- Month 月
- DayofMonth 月の何日目か
- DayOfWeek 曜日
- DepTime 出発時刻
- UniqueCarrier 航空会社
- Origin 出発地の空港
- Dest 目的地の空港
- Distance 目的地までの距離
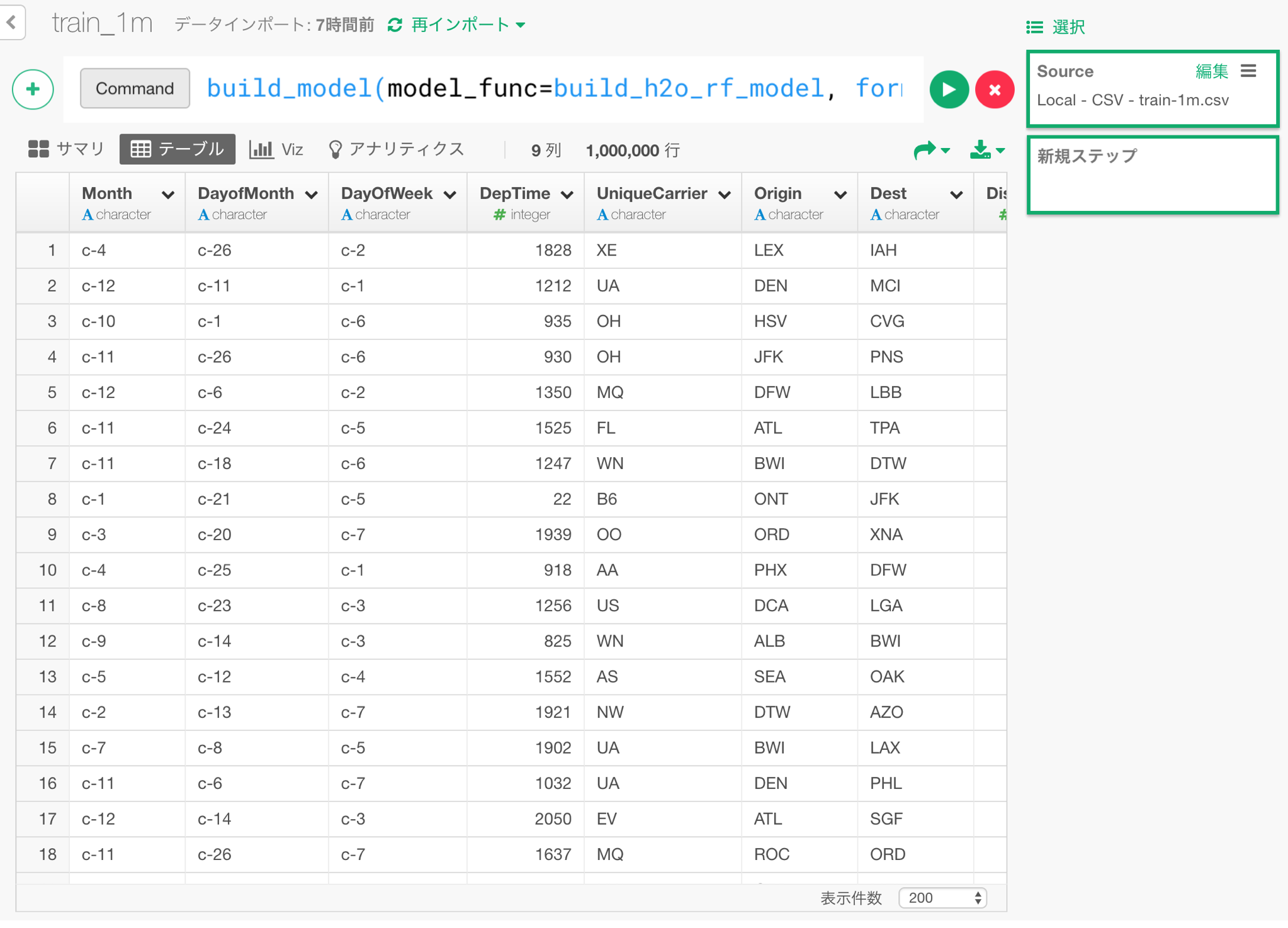
これを、以下のカスタムコマンドで行うことが出来ます。
1%にあたる、10000行をテスト用に残しておくために、test_rate=0.01を指定しています。
build_model(model_func=build_h2o_rf_model, formula=dep_delayed_15min~., test_rate=0.01, ntrees=50)
以下のようにコマンドを打ち込んで、緑の実行ボタンをクリックします。
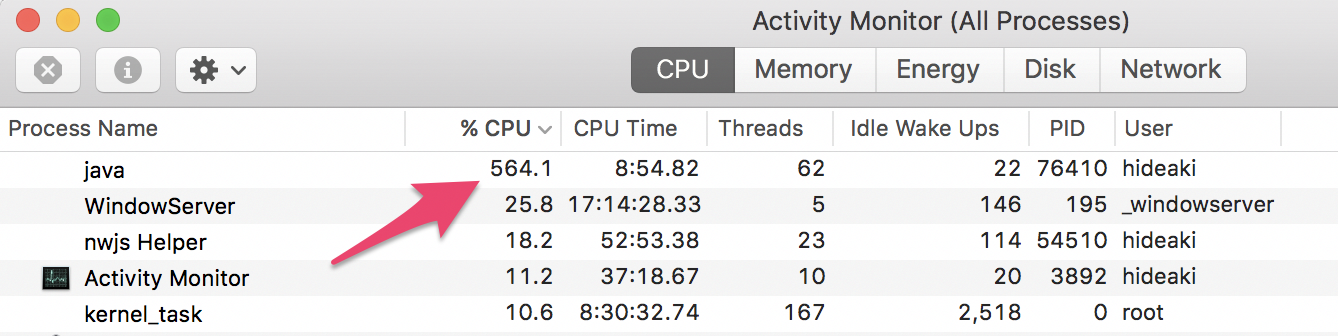
私の手元のMacBook Proでは、2分少々でモデルが完成します。この間にActivity Monitorを開けると、H2Oを走らせているjavaのプロセスがCPU使用率のトップに来ています。
564%ということは、CPUコアを約5.64個分並行して使うことによって、学習の計算速度を高めているということになります。
モデルの作成が完了した画面が以下になります。
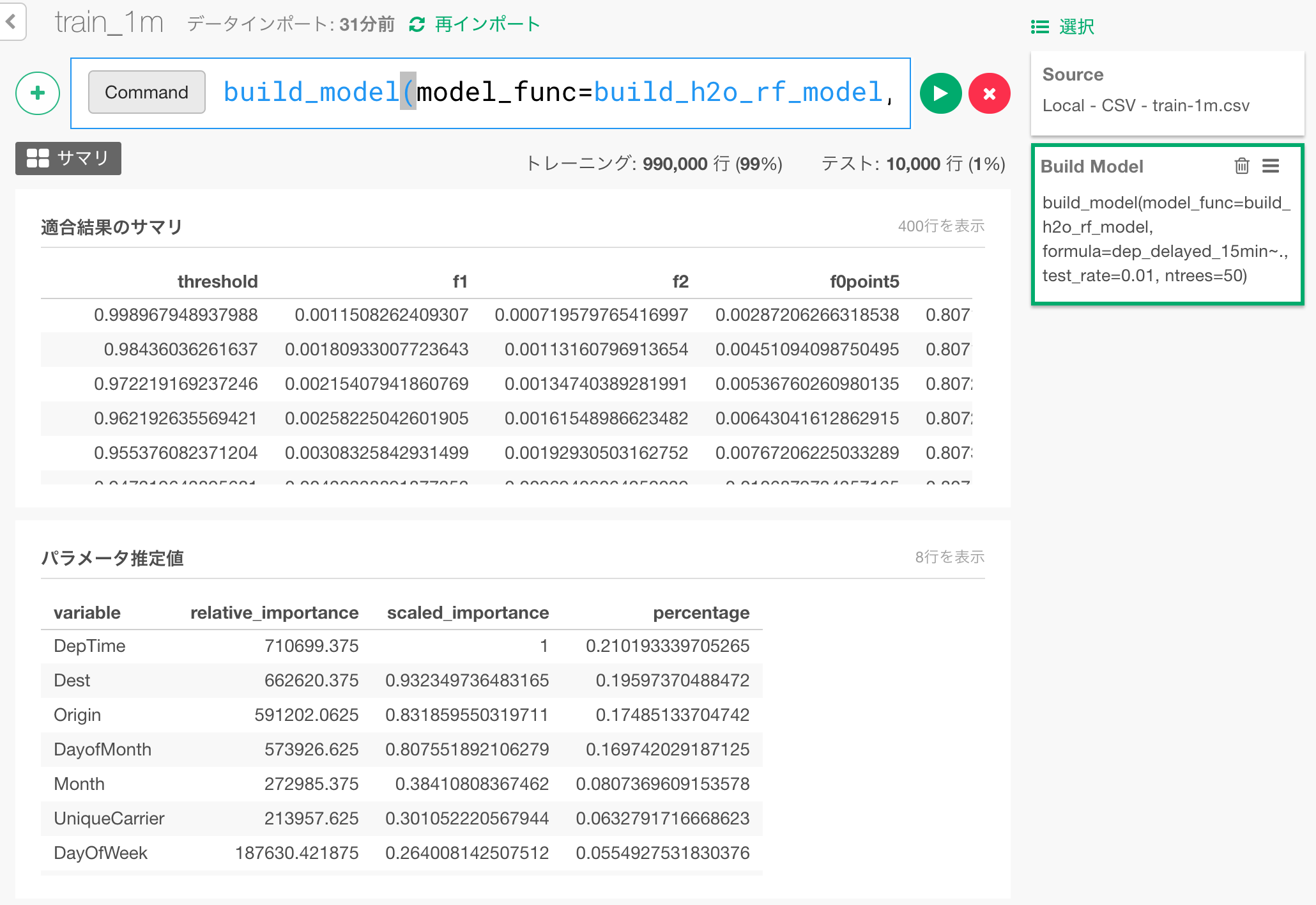
適合結果のサマリの欄には、学習データ自体での予測性能、パラメータ推定値の欄には、変数重要度が出ています。こちらの変数重要度は、最近のExploratoryを使っている方はご存知だと思いますが、アナリティクスUIにあるものといっしょです。詳しくはこちらの方に、ビデオでの説明と、ドキュメントがあります。
予測
先ほど、学習に使わずに取っておいた1%のテストデータで、フライトが15分以上遅れるかどうかの予測をしてみましょう。予測ダイアログで、「テスト」を選んで、テストデータでの予測をします。
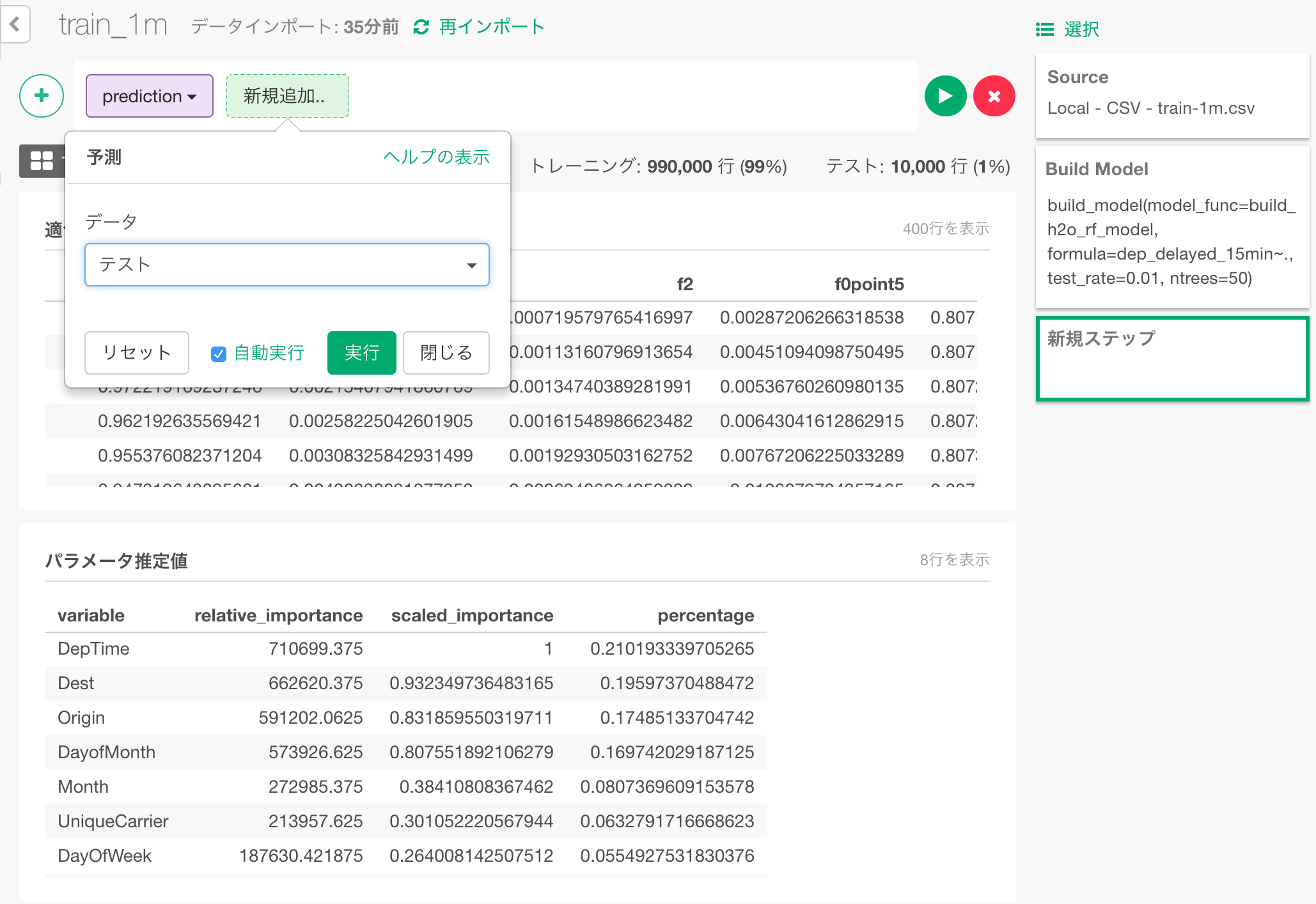
以下のように予測結果が出力されます。
Y、Nはそれぞれ、15分以上遅れたか、遅れなかったかの、予測された確率になります。
predictは、この確率が大きい方で、遅れたのか遅れなかったのかの具体的な予測値となります。

予測性能の評価
この予測がどの程度正しいのか評価してみましょう。まずは、予測結果(predict列)と実際に15分以上遅れたかどうか(dep_delayed_15min列)を比較して、混同行列を作成してみましょう。
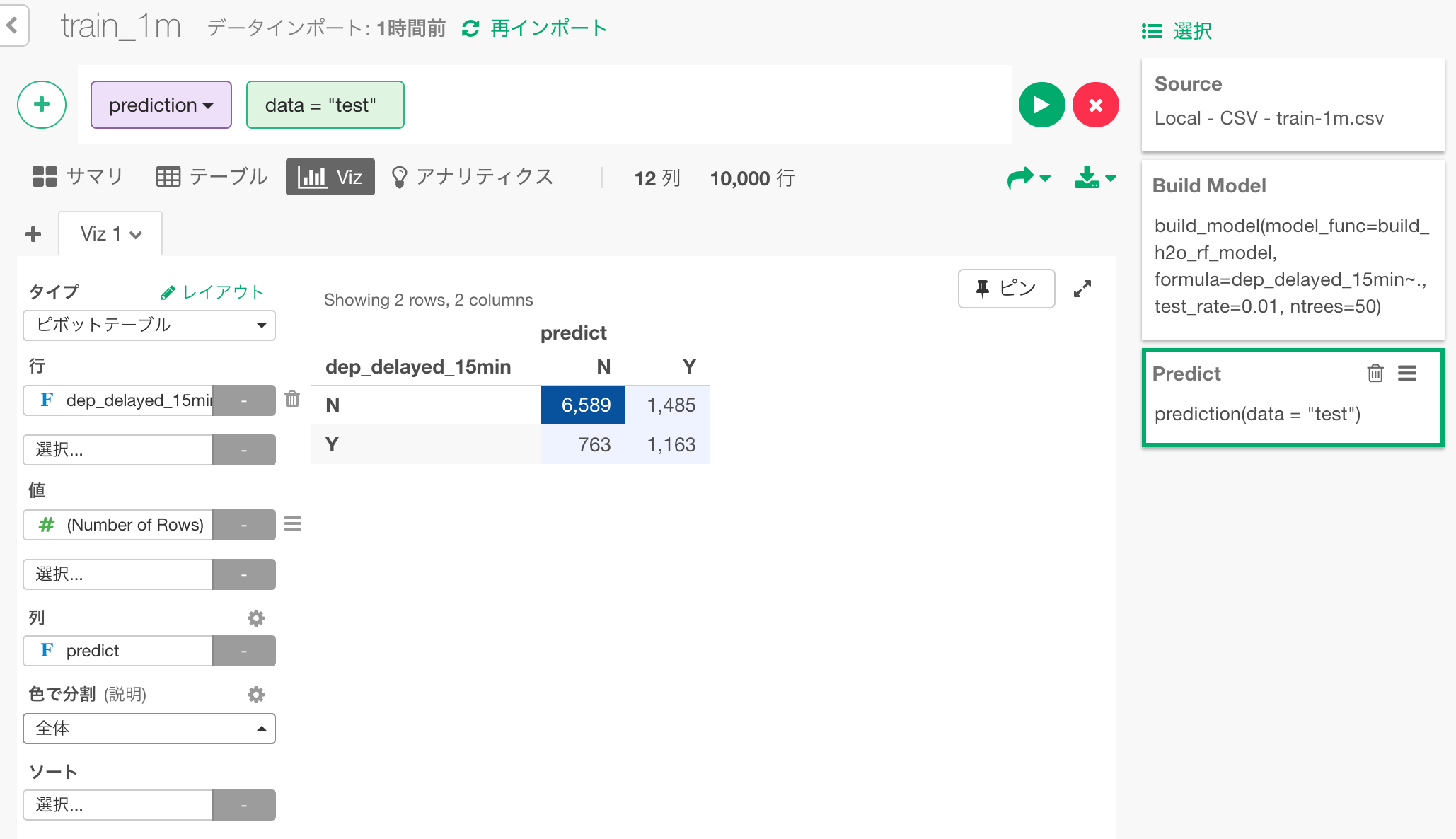
各行単位で見ていくと、実際に遅れた中でも、遅れなかった中でも、正解の方が不正解より多くなっています。
列単位で見ると、遅れると予測されたとしても、遅れないケースの方が多いということになってしまっていますが、これはそもそも母集団数として遅れないケースのほうが多いということの影響が強いと思われます。
次に、予測性能を評価する各種の指標を見るために、「二項分類 - 指標」のメニューを選びます。
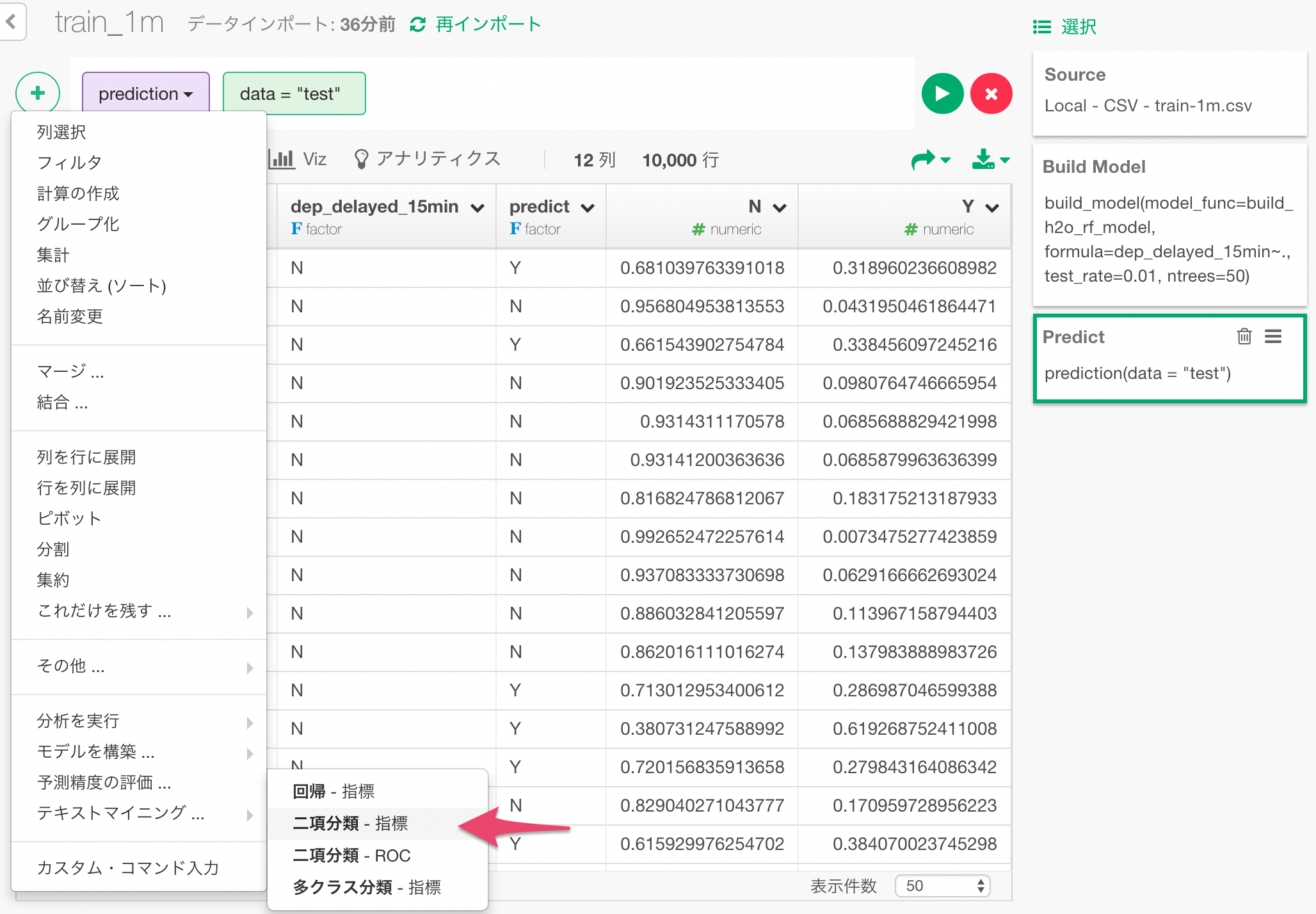
ダイアログの中で、予測された15分以上遅れる確率と、実際に15分以上遅れたかどうかの列を指定して、これを比較して答え合わせをすることにより、予測性能を評価します。
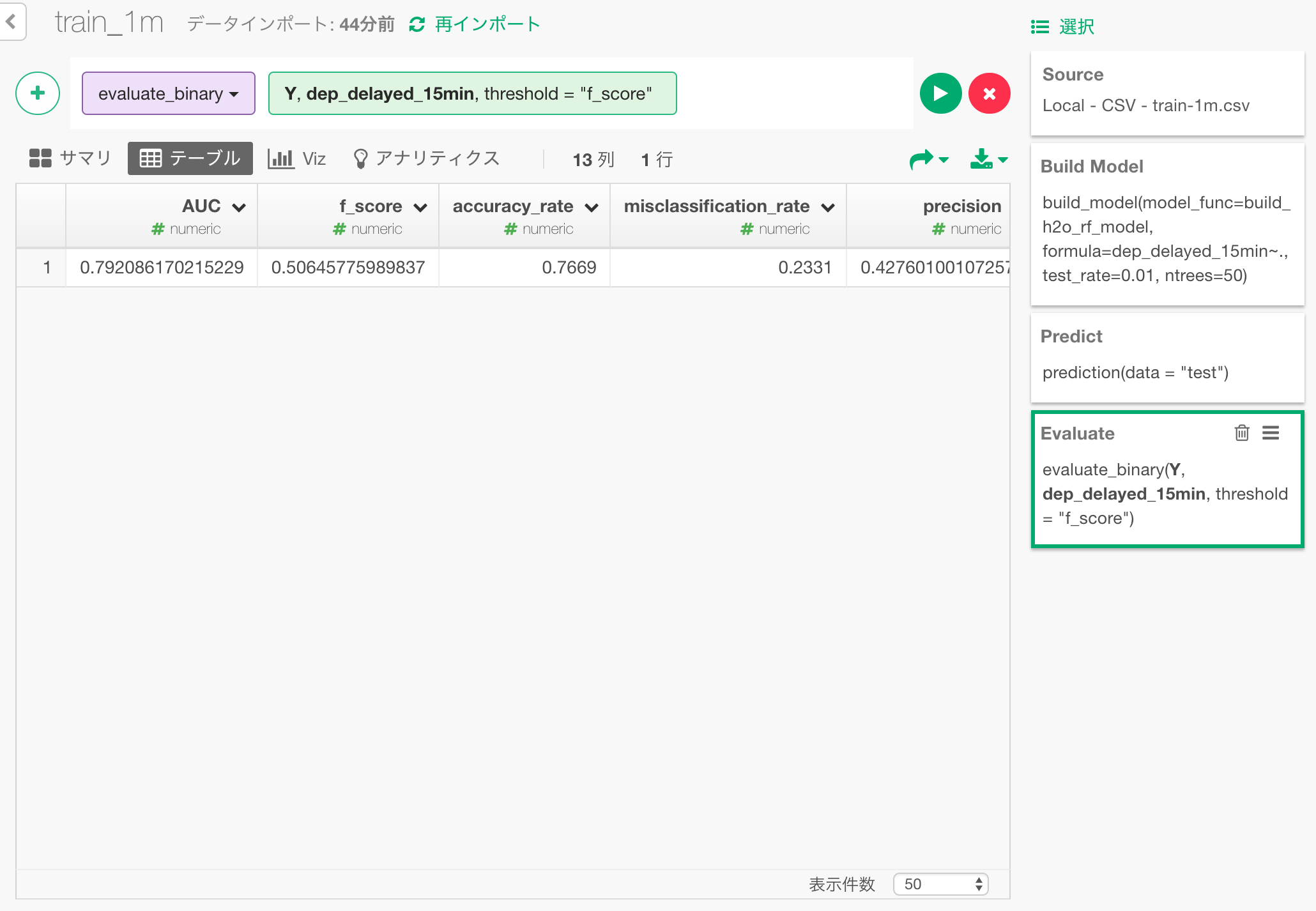
評価の結果が以下のようになります。accuracy rateを見ると、約76.7%ほどのケースで正解だったことが分かります。
また、モデルが予測する確率が、15分以上遅れたケースと遅れなかったケースをどれだけ明確に分離出来ているかを示す、AUCという指標は0.79となっています。これは0から1までの数字で、まずますの結果と言えます。
このAUCは、ROCカーブという、予測確率と実際の結果をもとに描くことができる曲線をもとに計算されます。その様子を可視化してみましょう。
「二項分類 - ROC」のメニューを選びます。

ダイアログの中に、予測確率と実際の結果の列を指定します。
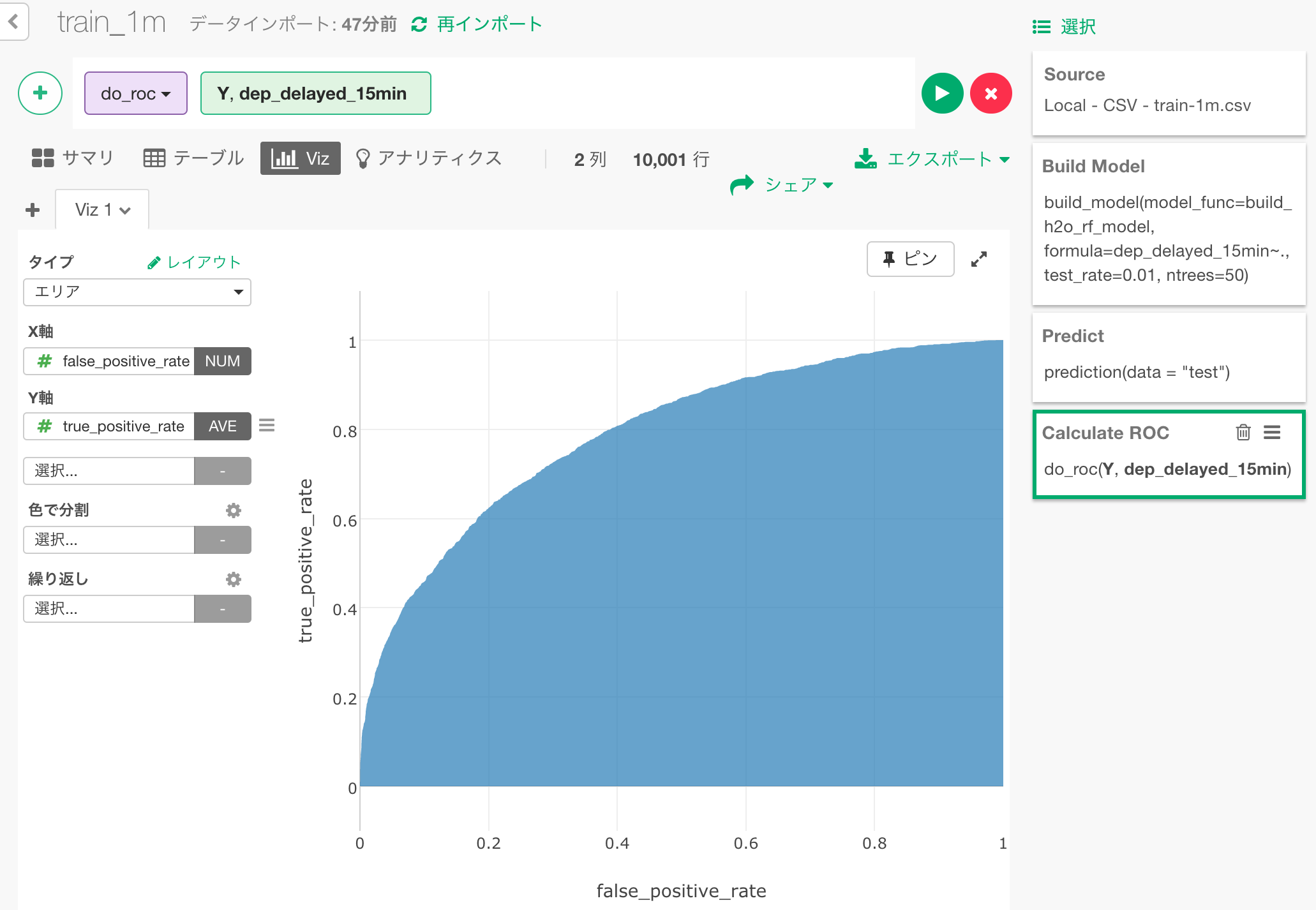
こちらが計算されたROCカーブのデータです。これをプロットした面グラフを作成してみましょう。

面グラフとして可視化した結果が、以下のチャートです。この青い部分の面積が、先ほど見たAUCの数値(0.79)となります。
まとめ
H2OをRから呼び出す"h2o"パッケージをとおして、ExploratoryからH2OのRandomForestアルゴリズムによる機械学習、予測、予測性能の評価を行いました。
RandomForestは、有名な強力なアルゴリズムで、多くの実装があります。次回以降では、H2Oが本当にそんなに早いのか、他の実装とのパフォーマンスの比較などもしてみたいと思います。
データ分析をさらに学んでみたいという方へ
今年10月に、Exploratory社がシリコンバレーで行っている研修プログラムを日本向けにした、データサイエンス・ブートキャンプの第3回目が東京で行われます。本格的に上記のようなデータサイエンスの手法を、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。