店舗などでの購買履歴のデータから、商品Aが買われたとには商品Bも買われる傾向がある、といったルールを抽出する分析は、Market Basket分析と呼ばれます。Exploratoryの中でも以下のメニューから簡単に行うことができます。
このアルゴリズムを流すと以下のような結果が得られます。
これは、左にある商品を買うと、右にある商品が買われるというルールについての情報になるのですが、これを一行一行読んで理解するのは時間がかかります。そこで、この情報をGraph(ネットワークダイアグラム)と呼ばれるチャートを使ってわかりやすく可視化する方法があります。
今日はExploratoryの中で、Graphチャートを作成するためのRのパッケージであるigraphをノートの中で直接使うことによって、マーケットバスケット分析の結果をわかりやすく可視化する方法を紹介します。ちなみに、ExploratoryのノートはRMarkdownなので、ふつうにRのパッケージを呼び出して、自由にRのスクリプトを書いて、レポートを書くことができます。
マーケットバスケット分析自体に関する詳細に興味のある方はこちらのポストを見てみてください。
Market Basket分析
以下のような、購買履歴のデータがあるとします。(このデータはこちらのページからダウンロードできます。)
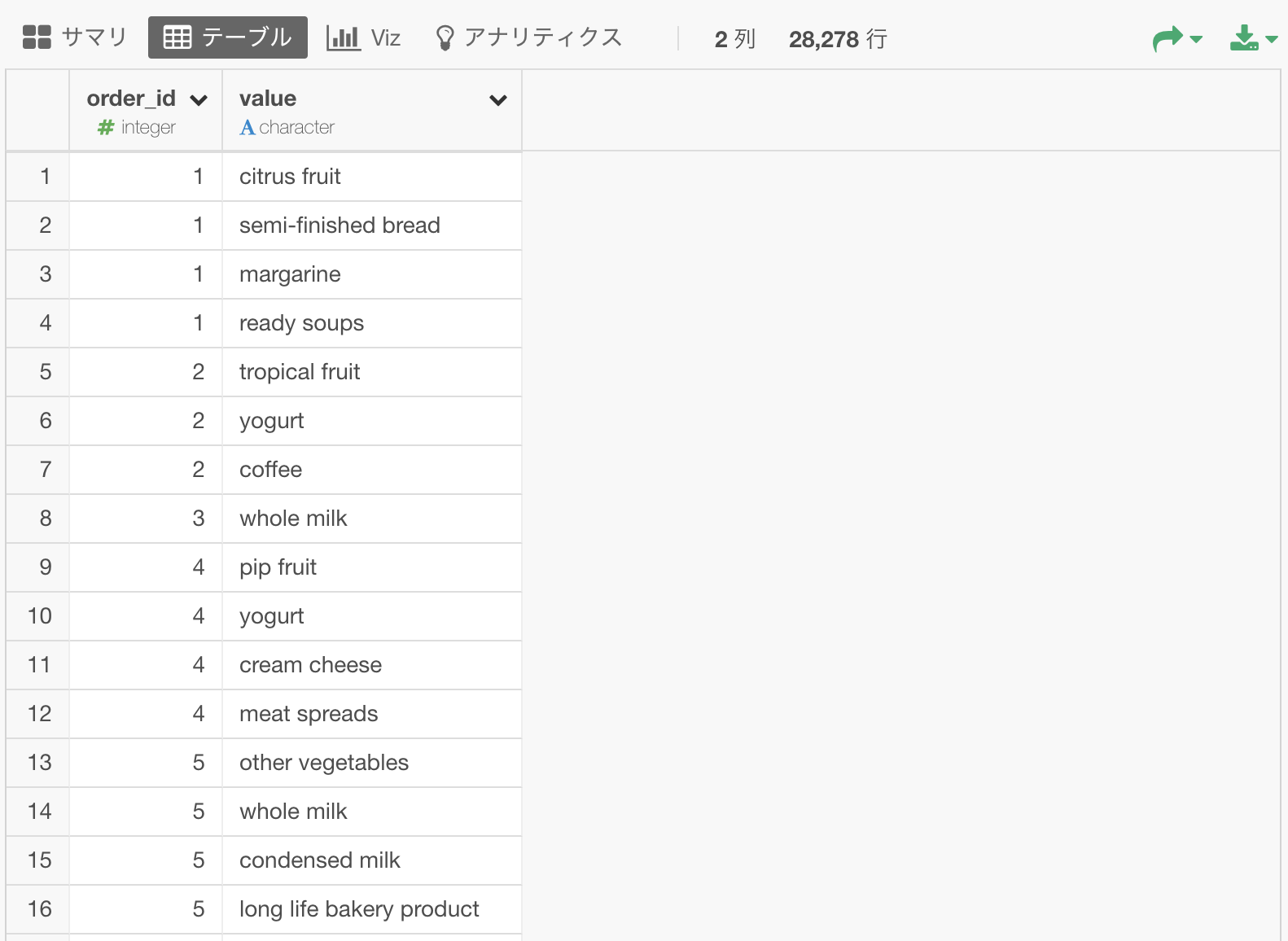
order_id列は、一度の買い物に対して一つづつ割り当てられたIDです。
value列は、何が買われたかを表しています。
例えば、この表の最初の4行を見ると、citrus fruit, semi-finished bread, margarine, ready soupsの4つの商品が、order_id列のID 1を共有しているので、この一回の買い物で、これら4つの商品が同時に買われたということがわかります。
さっそくMarket Basket分析をかけてみましょう。
以下のようにメニューをたどって、アソシエーション・ルールを実行のメニューアイテムを選択します。
すると以下のようなダイアログが表示されますので、Productにvalue列、Basketにorder_id列を割り当てます。
また、ルール検出の感度を上げるために、この分析ではMinimum Support Valueを0.001にセットします。
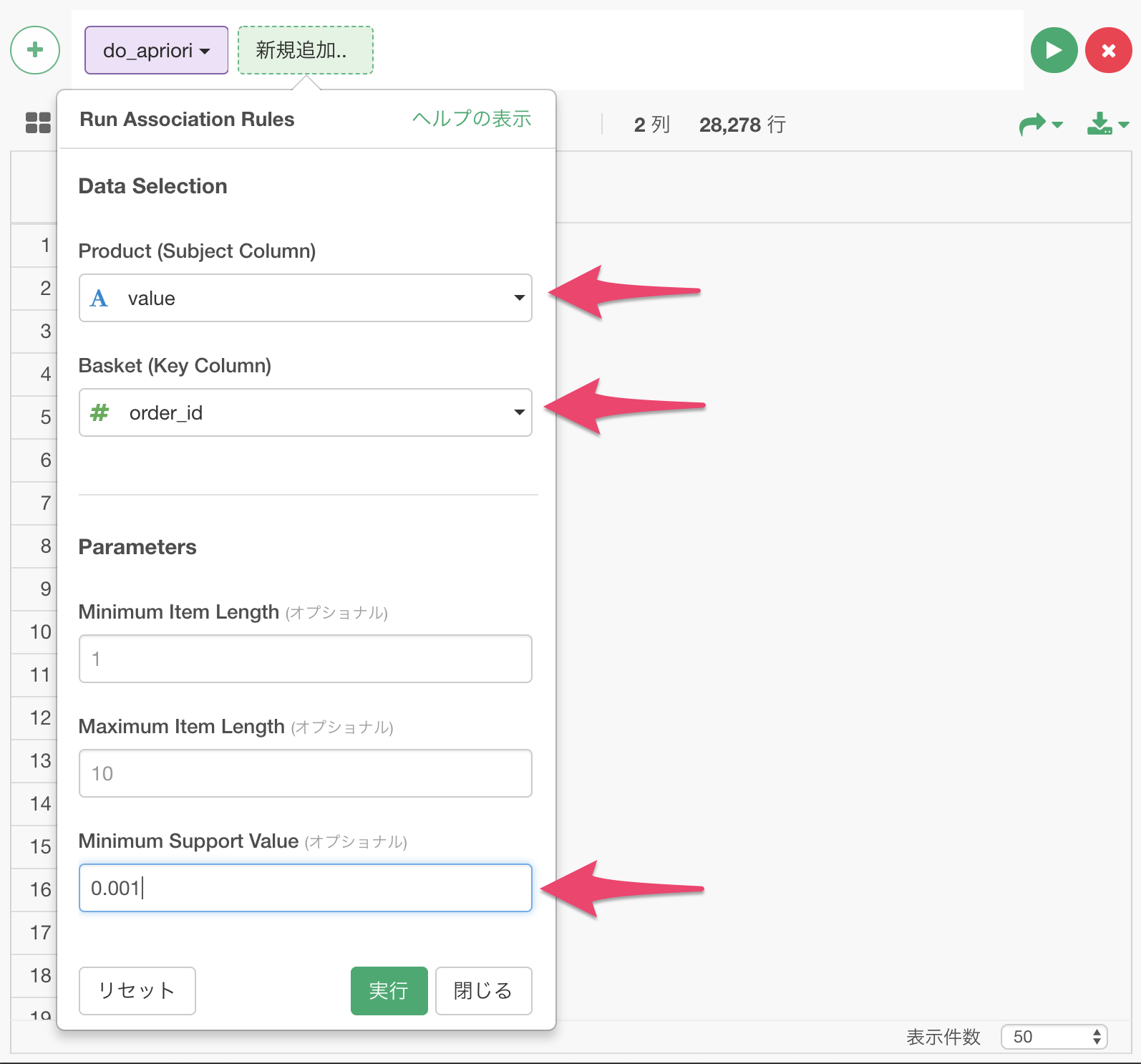
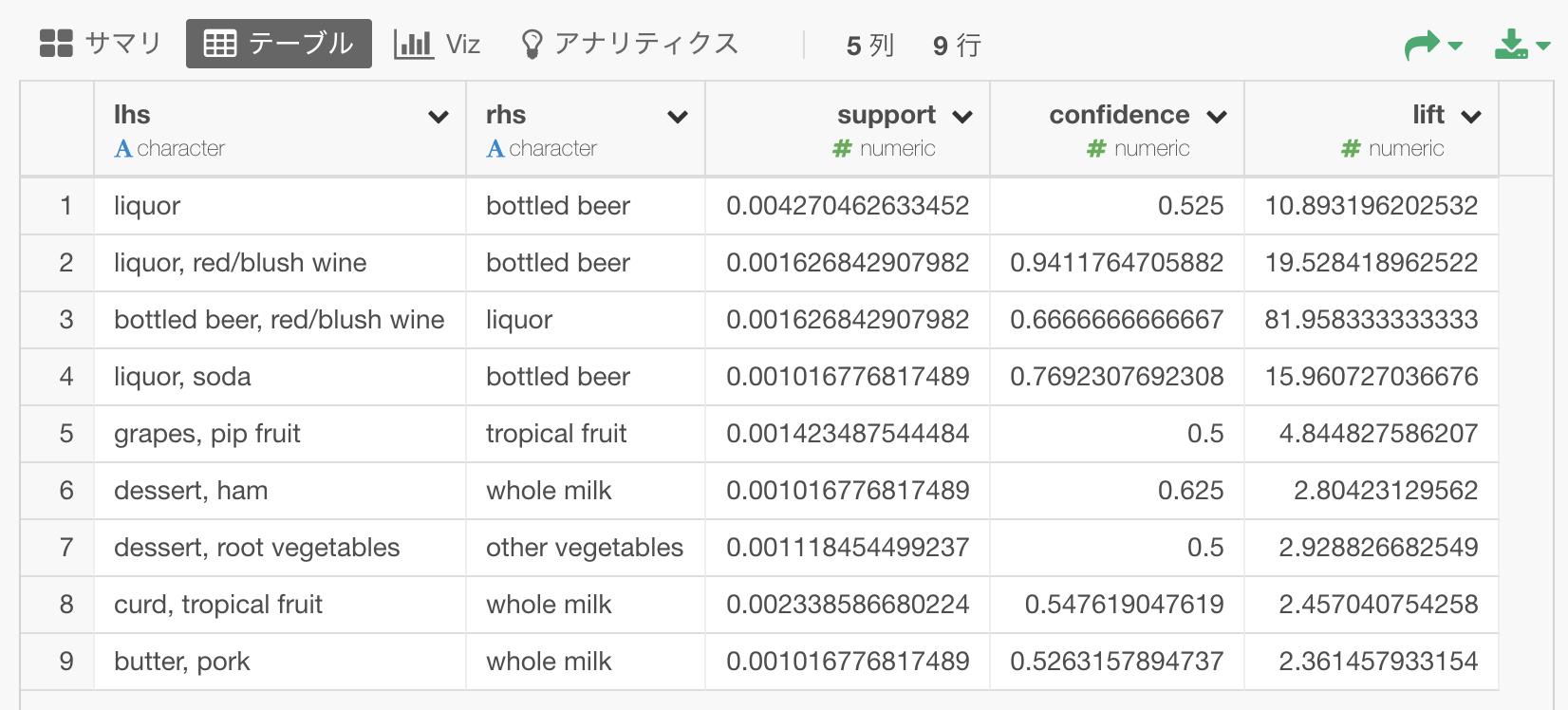
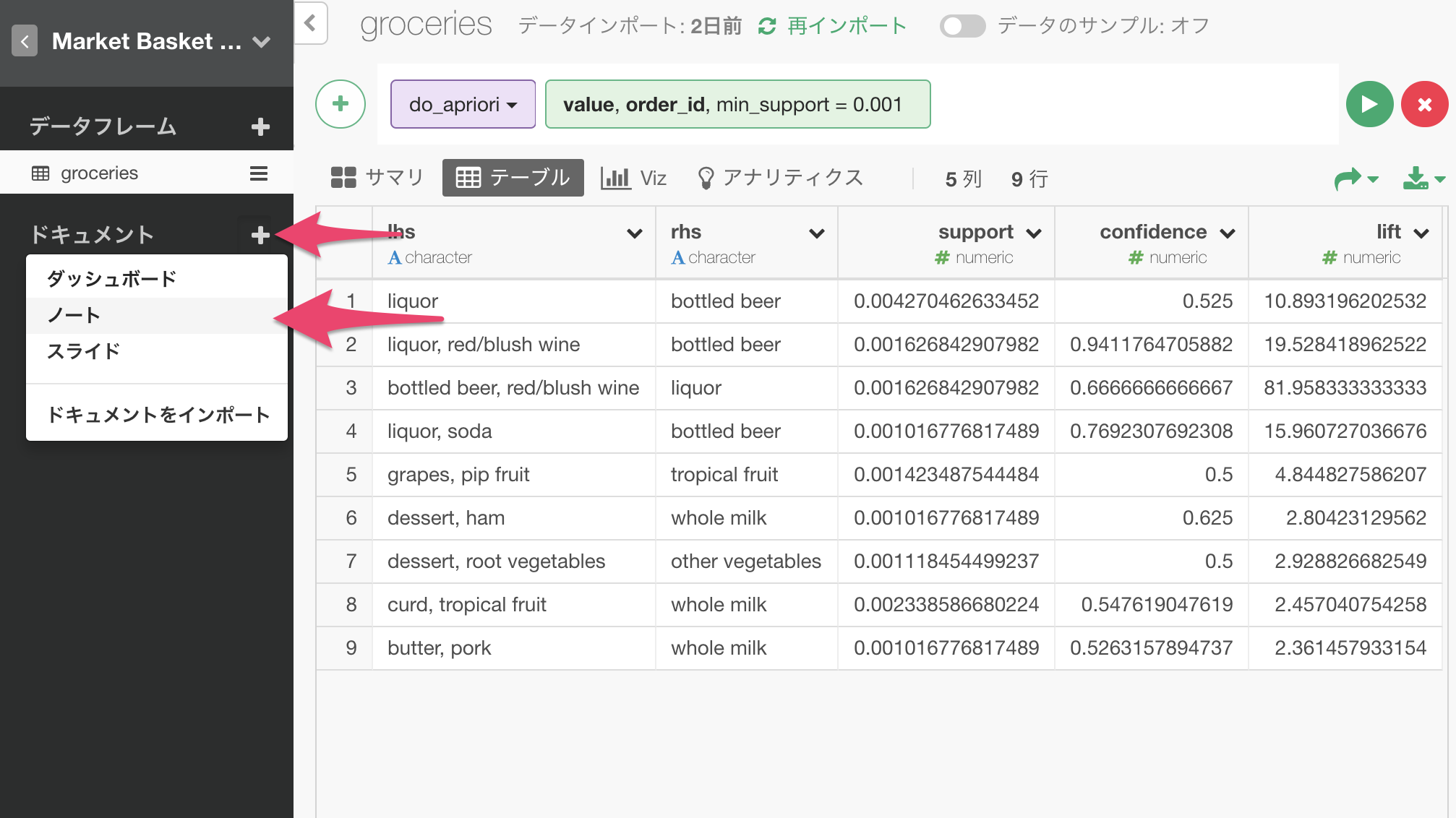
これを実行すると、以下のように9行のデータが出力されました。
この表の各行が一つのルールを表しています。
例えば、一行目は、liquorが買われるときには、bottled beerも一緒に買われることが多い、というルールです。このようなルールが九つ発見されたということになります。
このままでももちろんこれらのルールは理解出来るわけですが、ルール全体を一つのGraphで可視化して全体像を把握しやすいようにしてみましょう。
igraphのインストール
まずは一旦プロジェクトを閉じて、プロジェクト・リストの画面からRのパッケージであるigraphをインストールします。
画面左のRパッケージリンクをクリックしてRパッケージダイアログを開き、インストールタブの下でigraphとタイプして、インストールボタンをクリックします。
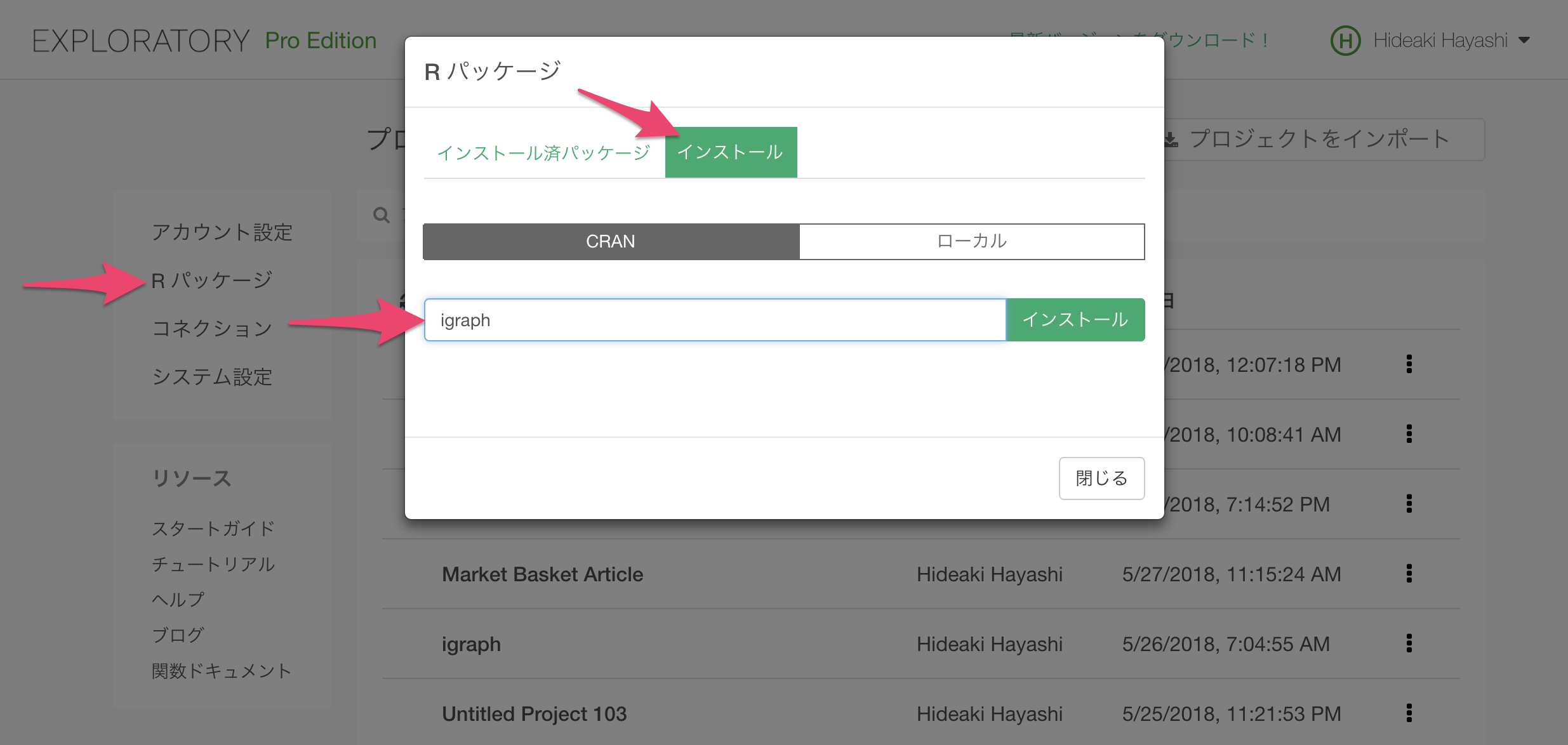
これでigraphがインストールされましたので、プロジェクトを再度開きます。
igraphによる可視化
以下のようにメニューをたどって、ノートを作成します。
以下のRのコードは、先ほどのMarket Basket分析で発見されたルールを、igraphを使って、Graphで可視化しています。
# Ruleに名前を付ける。groceriesは、マーケットバスケット分析の結果のデータフレーム。
rules <- groceries %>% mutate(rule = row_number(), rule = str_c("Rule ",parse_character(rule)))
# Ruleから右側の商品(rhs)への関係のデータフレームを作成
rule_rhs_edges <- rules %>%
select(rule, rhs) %>%
rename(from = rule, to = rhs)
# 左側の商品(rhs)からRuleへの関係のデータフレームを作成
lhs_rule_edges <- rules %>%
separate_rows(lhs, sep = "\\s*\\,\\s*") %>%
select(lhs, rule) %>%
rename(from = lhs, to = rule)
# 上の二つをあわせて、チャートに描く全ての関係のデータフレームを作成
edges <- lhs_rule_edges %>%
bind_rows(rule_rhs_edges)
require(igraph)
# チャートの再現性のためランダムシードを設定
set.seed(0)
# グラフオブジェクトを作成
g <- graph.data.frame(edges, directed=TRUE)
# グラフ上の点からsupportを得る関数
v_to_support_map <- setNames(rules$support*4000, rules$rule)
v_to_support <- function(name) {
if_else(name %in% names(v_to_support_map), v_to_support_map[name],0)
}
# グラフ上の点からliftを得る関数
v_to_lift_map <- setNames(rules$lift, rules$rule)
v_to_lift <- function(name) {
if_else(name %in% names(v_to_lift_map), v_to_lift_map[name],0)
}
# グラフ上の点からconfidenceを得る関数
v_to_confidence_map <- setNames(rules$confidence, rules$rule)
v_to_confidence <- function(name) {
if_else(name %in% names(v_to_confidence_map), v_to_confidence_map[name],0)
}
# confidenceを元に色を設定
c_scale <- colorRamp(c('white','red'))
V(g)$color <- apply(c_scale(v_to_confidence(V(g)$name)), 1, function(x) rgb(x[1]/255,x[2]/255,x[3]/255, alpha=0.8) )
# ruleの名前を非表示にする
modify_label <- function(x) {if_else(str_detect(x,"^Rule "), "", x)}
labels <- modify_label(V(g)$name)
# Graphを描画
par(mar=c(0,0,0,0))
plot(g, edge.arrow.size=0.5, vertex.size=v_to_support(V(g)$name), vertex.label=labels, vertex.label.family="sans", vertex.label.color=rgb(0.4,0.4,0.4), vertex.label.cex=0.9, vertex.frame.color=rgb(1,0.5,0.5))
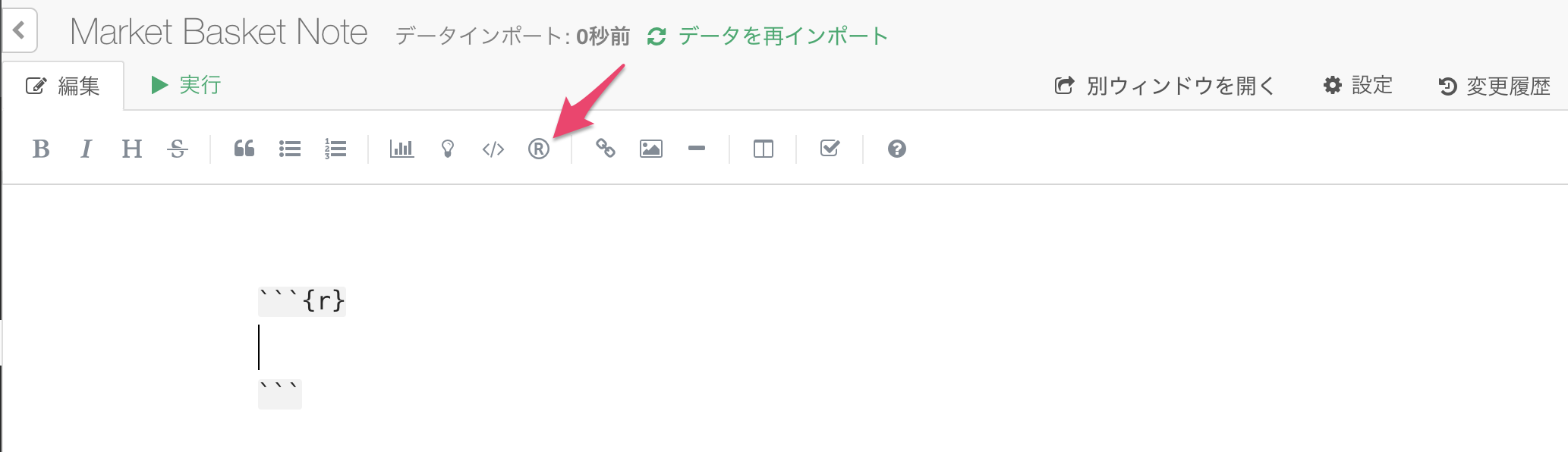
作成したノート中で、Rアイコンをクリックすると以下のような記法が現れますので、その中に上のコードをコピー・ペーストします。
ノートを実行すると、以下のようなチャートがノート中に表示されます。
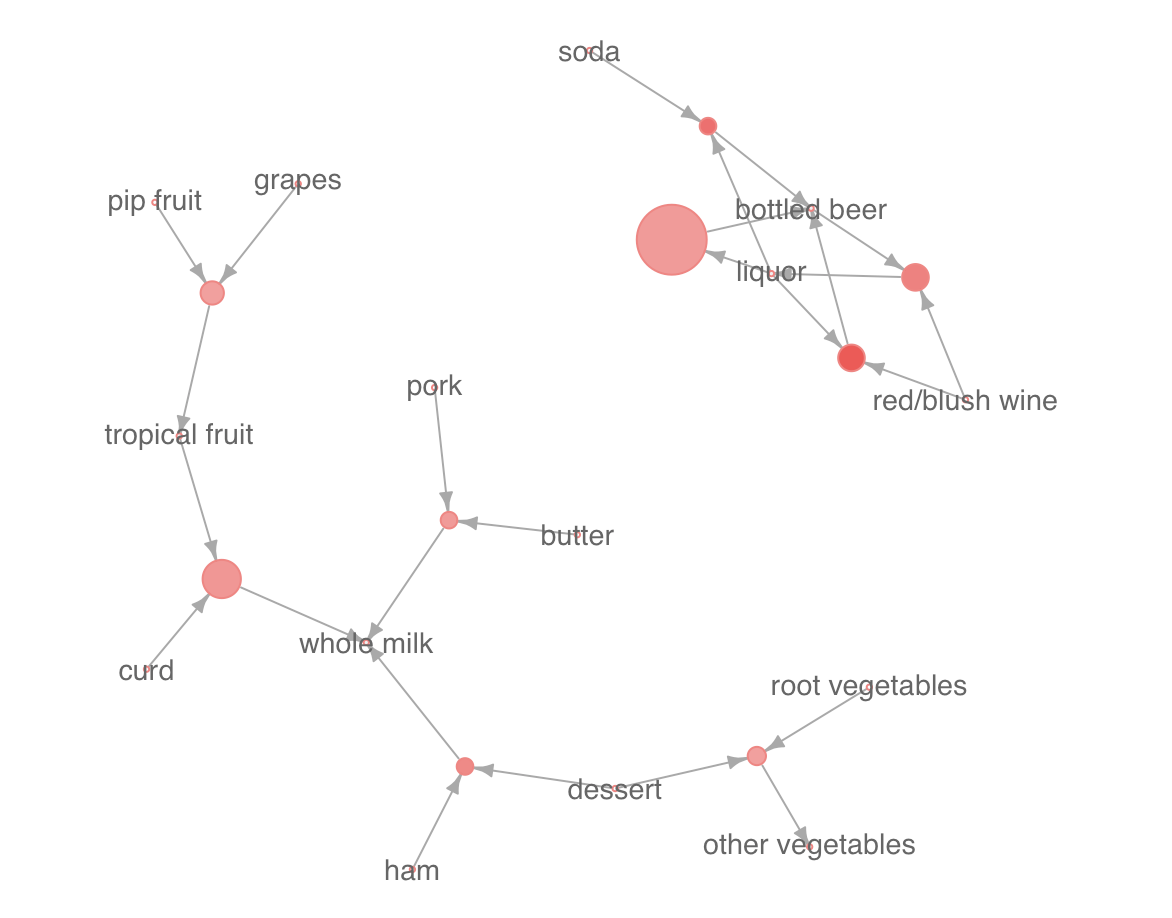
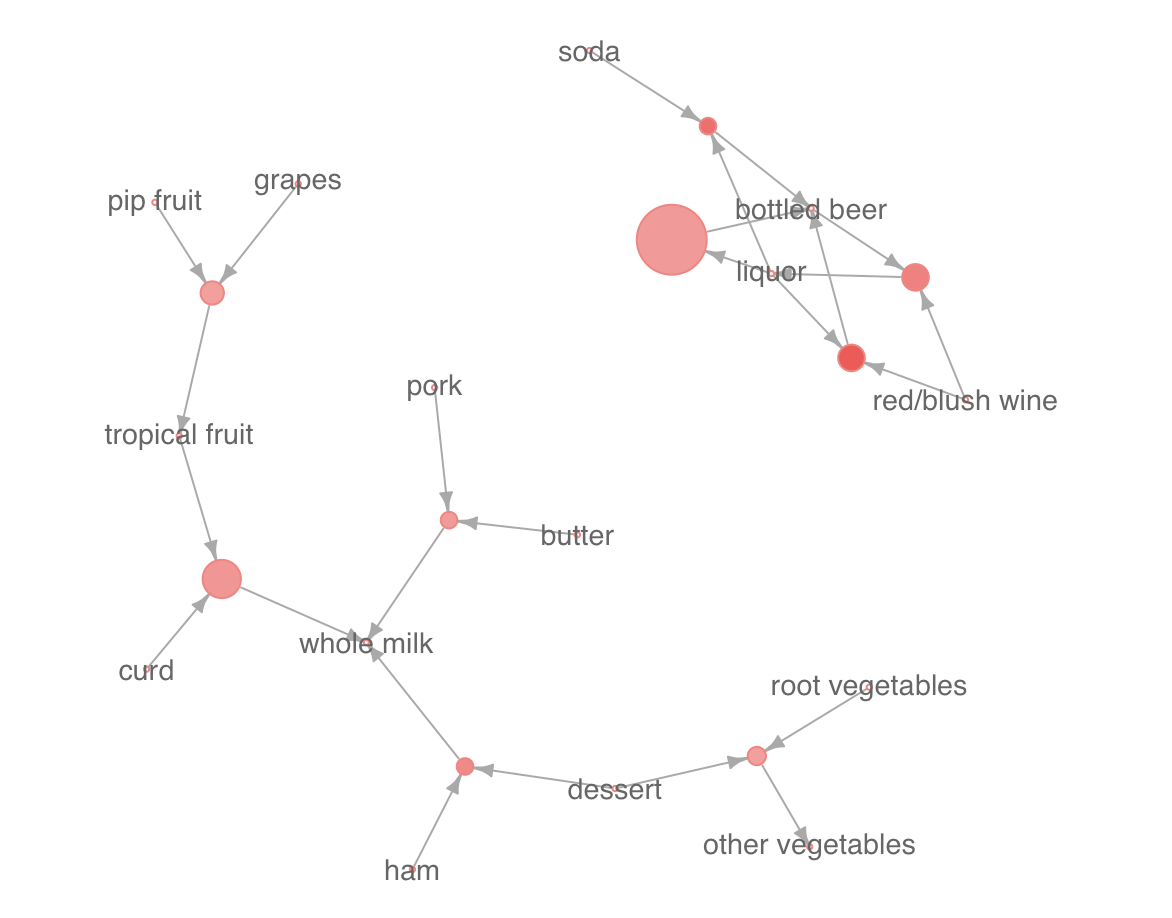
グラフ中の丸は一つのルールを表します。
丸の大きさはsupportと呼ばれる値で、このルールに当てはまる買い物(basket)の数を、全ての買い物の数で割ったものです。つまりこのルールの証拠となっている買い物の件数がどれくらいあるのかを示す指標です。
丸の赤色の濃さは、confidenceという値で、どれほどの割合でこのルールが的中しているかを表します。
商品名から丸に向かう矢印は、「これらの商品が買われると・・・」という条件を表し、丸から商品名に向かう矢印は「この商品が一緒に買われる傾向がある」という結果を表します。
例えば、以下の丸はliquorが買われるとbottled bearも買われることが多い、というルールを表します。
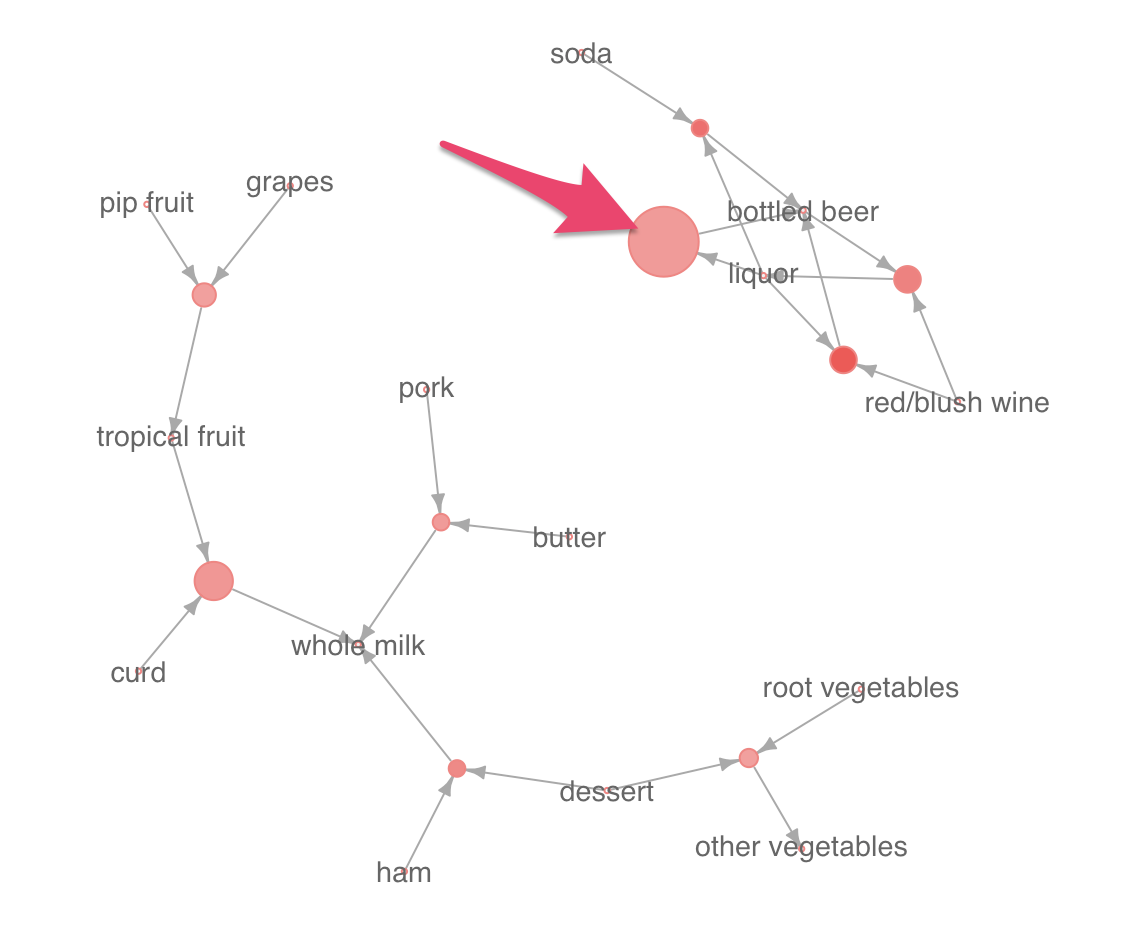
このルールは丸が大きいので、このルールの証拠となる買い物件数は、他と比較して多いということがわかります。
また、以下の丸は、red/blush wineとliquorの両方が買われるとbottled beerが買われるというルールを表します。
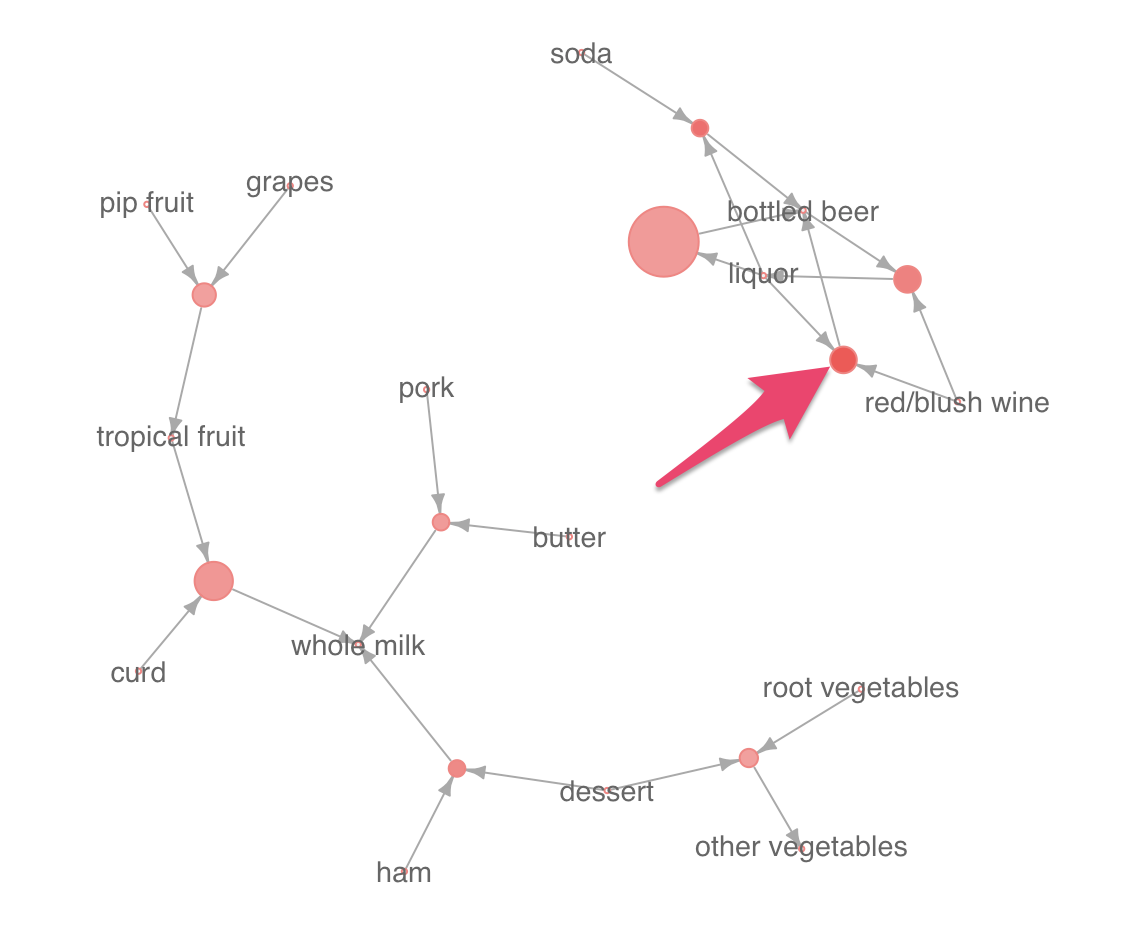
このルールは最も赤い色が濃く、confidenceが0.94と高くなっています。red/blush wineとliquorの両方が買われた場合の94%でbottled beerが一緒に買われている、ということになります。
こうして商品の間の関係性を全体として眺めてみると、右上のネットワークにかたまっている商品は全て飲み物で、左下のネットワークはwhole milkという例外はあるものの、全て食べ物であることなど、ルールを一行一行表として見ていたのでは気付かない様な傾向も見えてくることがあります。
まだ、Exploratory Desktopをお持ちでない方へ
まだExploratory Desktopをお持ちでない場合は、こちらから30日間無料でお試しいただけます。クレジットカード等の登録は必要ありません。ぜひ、お試しください。
データサイエンスをさらに学んでみたいという方へ
Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプを東京で開催しています。データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に参加を検討してみてください。詳しい情報はこちらをご覧ください!