先日、シリコンバレー、特にサンフランシスコでは大変人気の、食品をはじめとした日用品のお買い物代行サービスであるインスタカートというスタートアップがその顧客の購買データを名前などプライベートなデータは匿名にした上で公開しました。
このデータから顧客ID、購買日時、場所、商品の名前など、いわゆる購買情報(POSデータ)が得られるのですが、実際にサンフランシスコ界隈の今の情報がこれほどの規模で公開されたということで、民間、アカデミアを問わず、AI、機械学習、統計学のエキスパートたちの間では特に大変話題になっております。
今回はこのデータをもとにAssociation Rulesというアルゴリズムを使って、典型的なマーケットバスケット分析を行ってみたいと思います。こういった分析によって、どういった商品が一緒に買われる(同じバスケットに入っている)ことが多いのかを発見してみようというのが今回の目的ですが、さらにそこから得られた情報をもとに、実際に顧客が買いたくなるようなものをレコメンドするといった形でも使うことができます。アマゾンや楽天などでよく見るレコメンデーションがそれに当たります。
ツール
Association RulesのアルゴリズムはarulesというRのパッケージを使います。データのインポート、加工、分析のインターフェースとしては、RのUIとして世界中でよくつかわれているExploratoryを使います。
データのインポート
まず、データをインポートします。左のData Framesの横の+アイコンをクリックし、csvファイルの選択から、order_products__prior.csvというファイルを選びます。

インポートが終わりますと、このデータのサマリー情報が表示されます。3200万行ほどのデータが一気にインポートされたのがわかります。
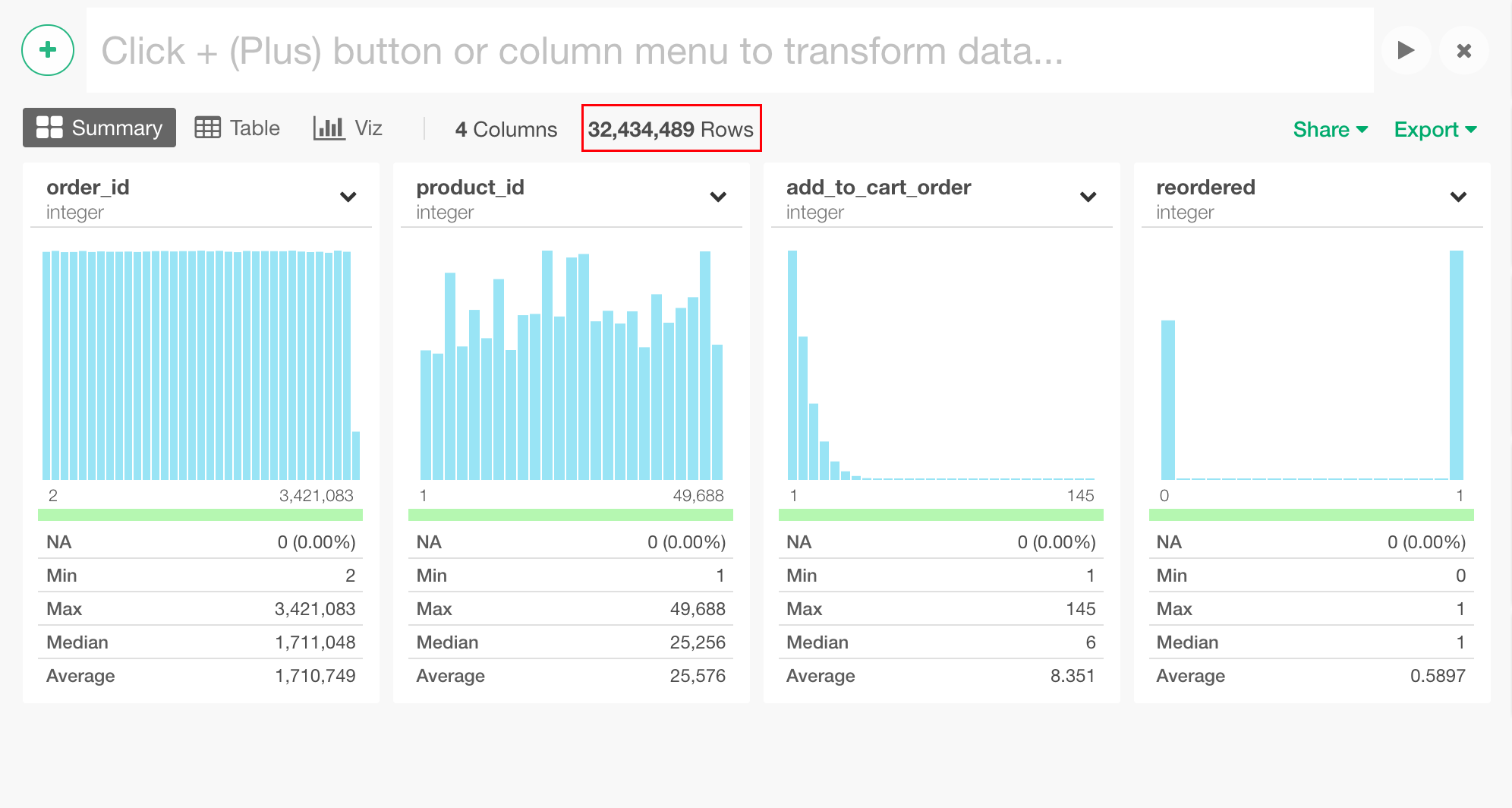
このデータをメインに見ていくのですが、このデータには、製品の名前がないので、products.csv をインポートし、結合します。
インポートしてテーブルビューに移ると、プロダクトのIDと、プロダクトの名前がマッピングされていることがわかります。

これらのデータを組み合わせて、どの商品が一緒に買われているのかという情報が得られるので、必要なデータが揃いました。
データの結合
order_products__priorのデータに戻り、Left Joinを実行します。product_idのカラムメニューから、Joinメニューをクリックします。
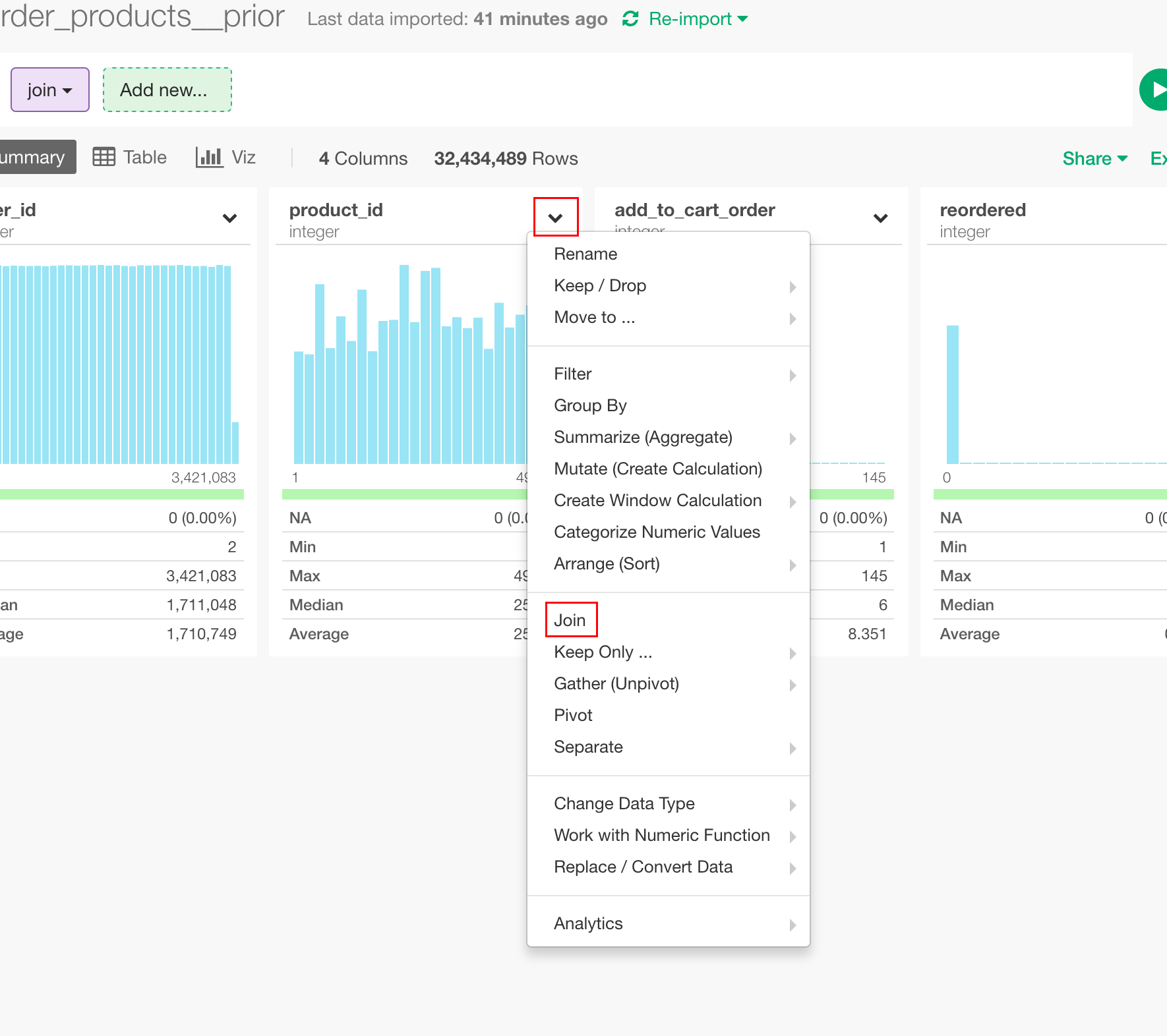
すると、ダイアログが開くので、Join Typeに"Left Join"、Target Data Frameに"products"、Current Column、Target Columnともに"product_id"を指定します。これで、現在のデータに対して、product_idがマッチするようにproductsテーブルが結合されます。

テーブルビューにうつると、データが結合され、どの注文で何が買われたのか、わかるようになっていることがわかります。

マーケットバスケット分析の実行
データが準備できたので、いよいよマーケットバスケット分析の実行に移ります。+ボタンのメニューから"Run Analytics" -> "Run Association Rules"を選択します。
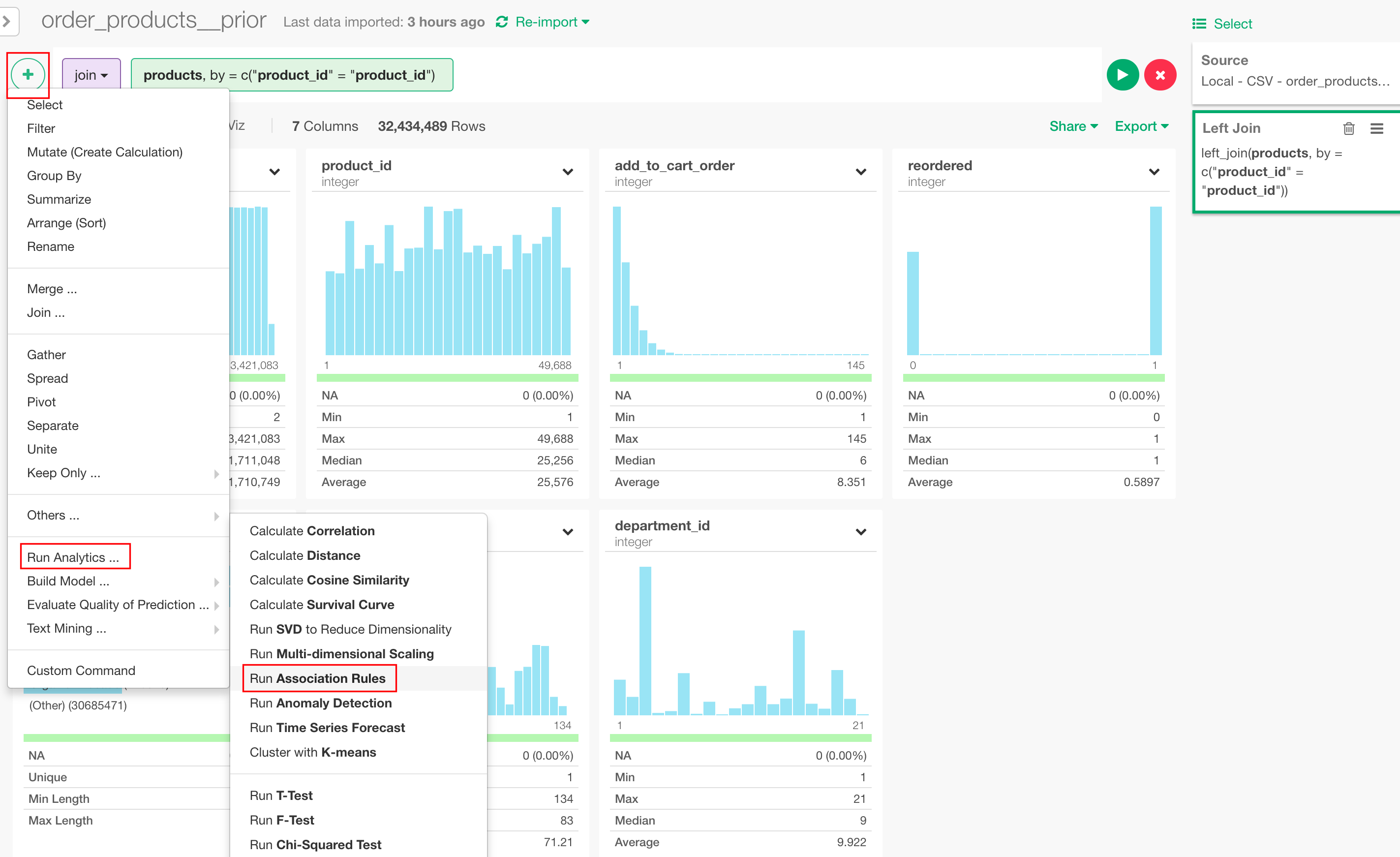
以下のようにパラメーターを設定します。Product (Subject Column)には、製品の名称の列(今回はproduct_name)、Basket (Key Column)には、注文のID(今回はorder_id)の列を選択します。Minimum Support Valueには、0.0001と入れてください。このパラメーターの意味については、結果の解釈のところで詳しく解説します。
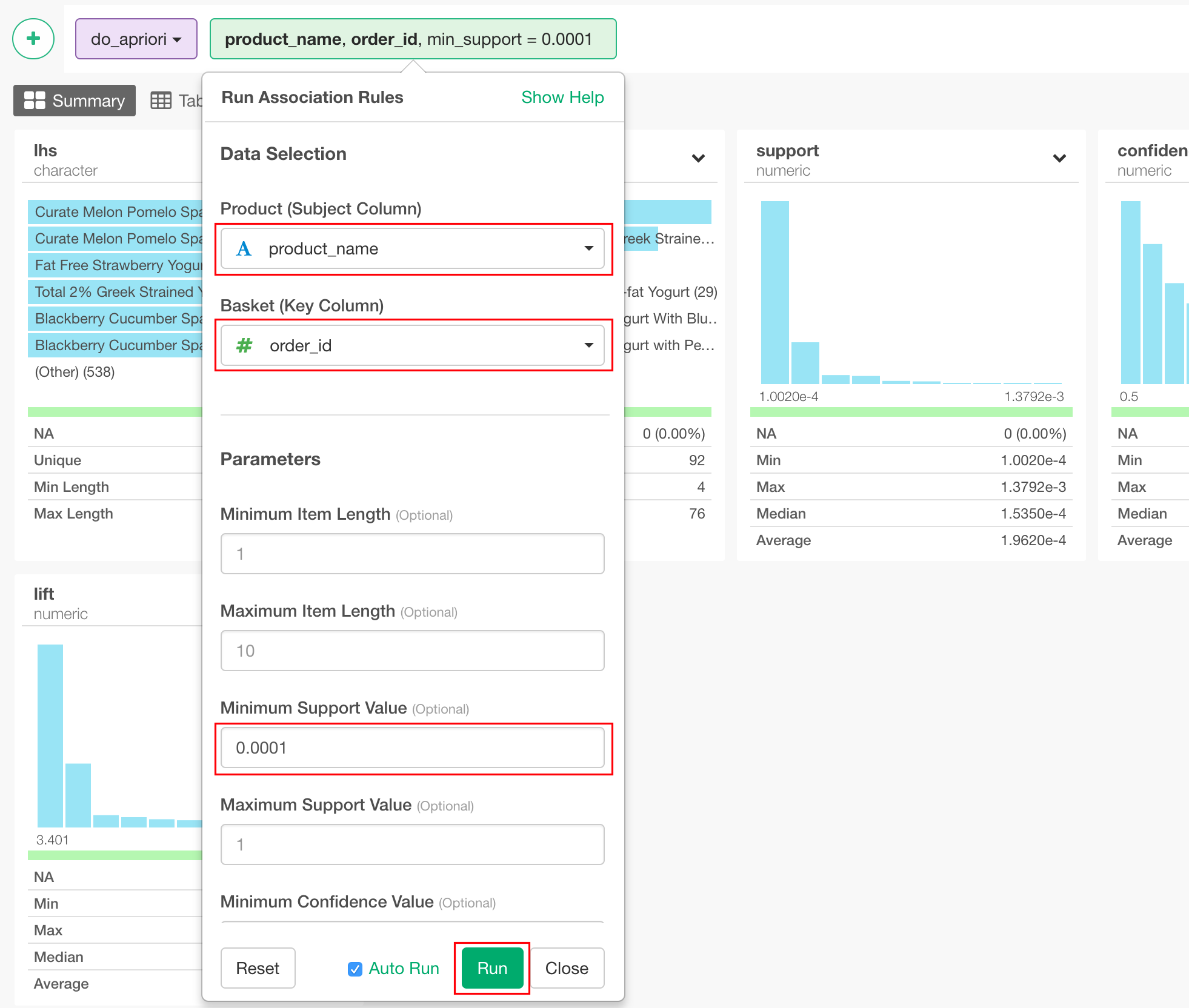
すると、このような結果が出てきます。
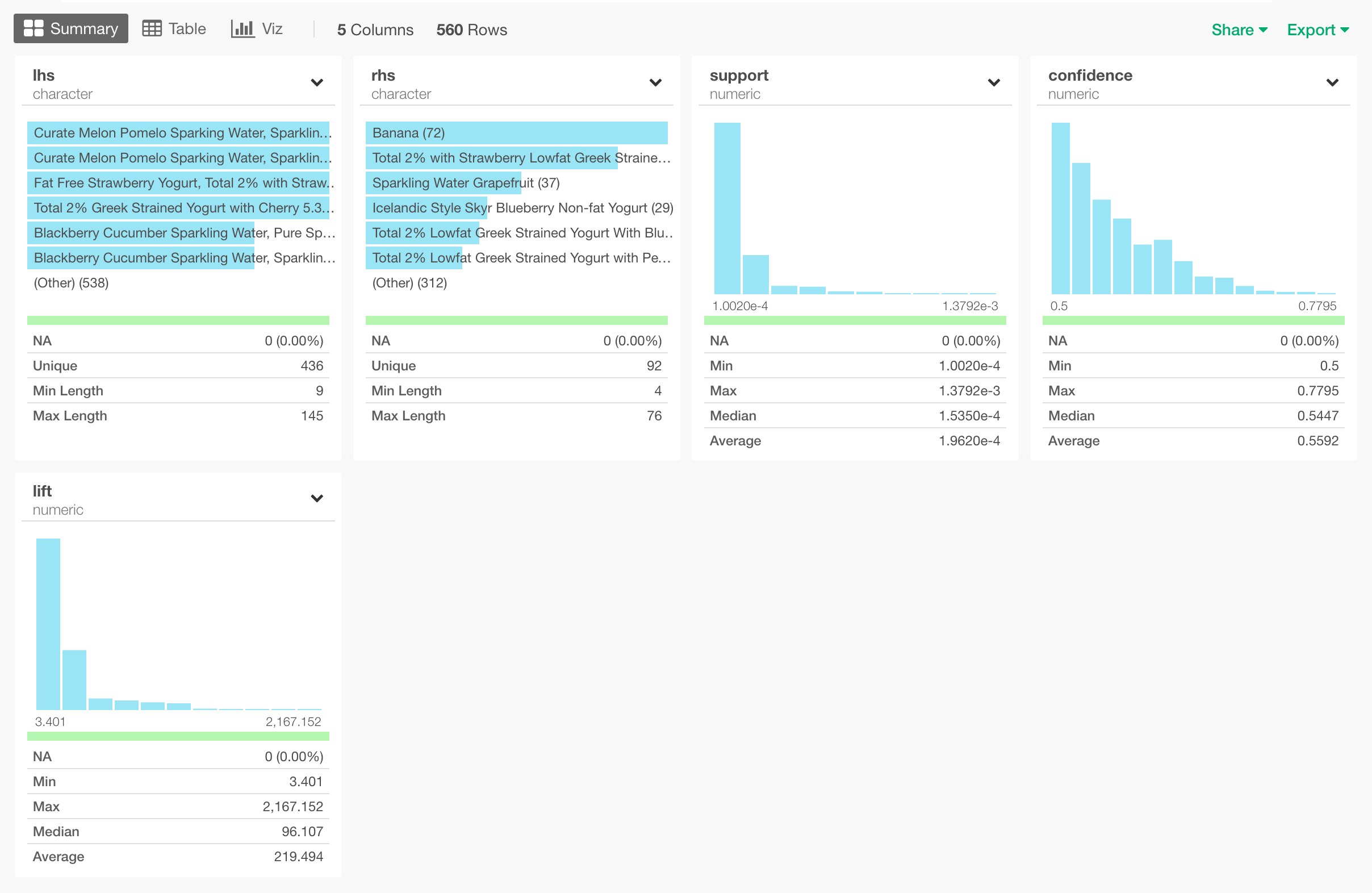
テーブルビューで見ると、lhs、rhsが商品名、support、confidence、liftが数値で、一行になっていることがわかります。

結果の解釈
各カラムの意味は、以下のようになります。
- lhs - Left-Hand-Side (左手側)の略。ルールの「条件」にあたる商品。これらの商品をすでに買うことを決めた時の相関ルールになります。
- rhs - Right-Hand-Side (右手側)の略。ルールの「結果」にあたる商品。これらの商品を買うことになるという相関ルールになります。なので、一行が、lhsの商品を買うことを決めた人たちが、rhsの商品を買ってくれるというルールを表します。
- support - どれだけの割合の購買に、そのルールが当てはまっているかという指標になります。
- confidence - そのルールが正しく当てはまった割合になります。lhsを買っているのに、rhsを買っていないケースが多いと小さくなります。
- lift - lhsを買ったという条件によって、rhsを買うという可能性がどれだけ上がるかという指標になります。実際には、どちらもよく買われている商品だと、商品同士に強い結びつきがあるわけではないのに、supportやconfidenceが高くなることがあります。例えば、ある店では、ビールが9割の人に買われていて、歯磨き粉も9割の人に買われているとすると、ビールを買う人が特に歯磨き粉を買いやすいというルールが無いとしてもsupportが0.9 * 0.9 = 0.81、confidenceが0.9という高い値をとってしまう可能性があります。しかし、ここでliftが1に近いとすると、supportとconfidenceが高くても、ビールを買う人が特に歯磨き粉を買いやすいというルールは無いということに気づくことが出来ます。
因みに、このsupport値の下限が、先程のRun Association Rulesのダイアログにあった、Minimum Support Valueのパラメーターの意味になります。
では、実際の結果を見てみるのに、可視化をしてみましょう。
Vizに移り、TypeにHeatmap、X axisにlhs、Y axisにrhs、Colorにconfidenceをセットします。
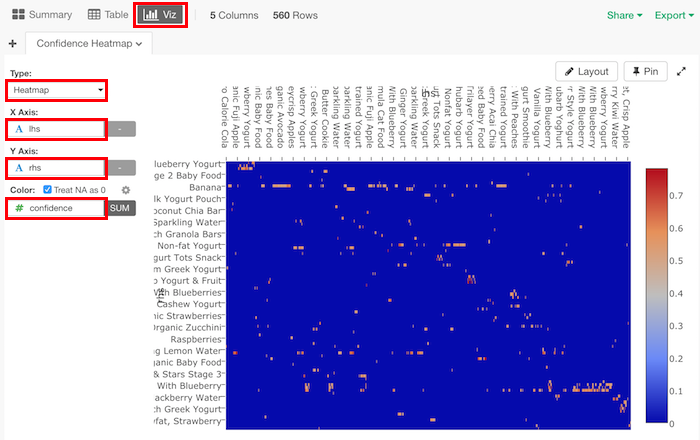
すると、高いconfidenceをもつルールが赤くなります。
赤くなっているところの一つに、
lhs- Oh My Yog! Madagascar Vanilla Trilayer Yogyurt, Oh My Yog! Organic Wild Quebec Blueberry Cream Top Yogurt & Fruit
rhs - Oh My Yog! Pacific Coast Strawberry Trilayer Yogurt
confidence - 0.78
というのがあります。

Oh My Yogというのは、このようなカップヨーグルトの製品です。このルールは、バニラ味、ブルーベリー味のOh My Yogを買っていたら、0.7795の確率でストロベリー味を買うであろうというということになります。supportが0.0002ということは、0.02%の購買で、バニラ味、ブルーベリー味、ストロベリー味を買っていたということになります。そして、liftも877と高い値なので、これがたまたま起きていることなのではなく、バニラ味、ブルーベリー味のOh My Yogとストロベリー味のOh My Yogには、強い結びつき(相関)があるということになります。直感的にも、同じタイプのヨーグルト同士であるため、結びつきが強いことに納得がいくかと思います。
このことから、バニラ味、ブルーベリー味のOh My Yogを買っていたら、そのカスタマーはストロベリー味も求めている可能性がとても高いので、それを推薦することに効果があるはずだということになります。
また、出て来るルールの中に、
lhs - Baby Food Meals(離乳食)
rhs - Wholesome Breakfast Blueberry Banana(ブルーベリーとバナナの入った朝食用の液体食品)
というのもあります。
これだと、言われてみると、たしかに子供用に買うことが納得できますが、情報なしに、一緒に買われそうだと予測することは難しそうです。
このようにアルゴリズムを活用することによって、人の頭だけで想像する範囲を超えて商品の結びつきを見つけ出すことが可能になります。
まとめ
今回、Exploratoryとinstacartのデータを用いて、マーケットバスケット分析の紹介を行いました。
- 購買データから、傾向を見つけ出すための手法の一つとして、マーケットバスケット分析がある。
- 購買のIDと、商品の名前またはIDから実行できる。
- それによって、何が何と一緒に買われる傾向があるのかが結果として出て来る。
- それを、顧客に提示することで、購買を促せる可能性が高い。
もし、何か質問やご要望などありましたら、support@exploratory.ioにご連絡ください。
データ分析をさらに学んでみたいという方へ
只今、Exploratory社でデータサイエンス・ブートキャンプへの参加を募集しております。さらに、ビジネスに活かせるデータ分析手法を学んでみたいという方、是非ご覧になってみてください。
自分で試してみる
こちらに、データと分析ステップを共にシェアしてあります。それをお手元のExploratoryにインポートすることで、今回の分析のステップ、グラフが再現できます。もしExploratoryを持っていなければ、こちらから無料のトライアルをはじめてみてください。
こちらのページのDownloadボタンから、EDFをダウンロードします。
それをこちらからデスクトップにインポートします。
Rで再現する
エクスポートされたR Scriptは以下になります。
再現するには、exploratoryパッケージのインストールが必要になりますが、こちらからダウンロードできます。
readrと、arulesというパッケージのインストールも必要になるので、されていない方は、そのインストールもしてください。
install.packages("readr")
install.packages("arules")
# Load required packages.
library(dplyr)
library(exploratory)
# products.csvのファイルパス
products_path <- "{your directory}/products.csv"
# order_products__prior.csvのファイルパス
order_products__prior_path <- "{your directory}/order_products__prior.csv"
# Steps to produce products
`products` <- exploratory::read_delim_file(products_path , ",", quote = "\"", skip = 0 , col_names = TRUE , na = c("","NA") , locale=readr::locale(encoding = "UTF-8", decimal_mark = "."), trim_ws = FALSE , progress = FALSE) %>% exploratory::clean_data_frame()
# Steps to produce the output
exploratory::read_delim_file(order_products__prior_path , ",", quote = "\"", skip = 0 , col_names = TRUE , na = c("","NA") , locale=readr::locale(encoding = "UTF-8", decimal_mark = "."), trim_ws = FALSE , progress = FALSE) %>% exploratory::clean_data_frame() %>%
left_join(products, by = c("product_id" = "product_id")) %>%
do_apriori(product_name, order_id, min_support = 0.0001) %>%
arrange(desc(confidence))