1.やりたいこと
献立の食品カロリー算出のために画像認識を行って食品を特定します。
(本記事はQiita「IoTでカロリー自動計算システムを作る」の一部です。本編の方もご覧ください。)
画像認識ライブラリやサービスには多くの種類が有りますが、ライブラリだけ入手して構築する作業には、学習モデルとデータの準備やチューニングなど、時間と労力とスキルが必要になります。(例えばこんな感じ。)
初心者としては、まずは用途に合った出来合いの画像認識サービスを探します。必要な要件をリストアップします。
| 項目 | 必須 (MUST) |
出来れば(NiceToHave) | 理由 |
|---|---|---|---|
| 認識 | 一般物体認識 | 食品に強い | 食品画像認識で品目入力を省力化するため |
| 学習 | 基本モデル 学習済 |
追加学習できること | 手軽にスタートし自分献立の写真で認識精度UP (過去の自分献立画像が数百枚ある) |
| 推定 対象 |
食品単品認識 | 献立全品認識 | 利用時は食品単品をキッチンスケールに載せて量る (学習時は過去献立画像を切出さず使う) |
| 利用 環境 |
クラウドAPI | ローカル学習モデル構築はハードル高い 〆切的に完成が期待できない |
|
| その他 | 個人利用可 即納期 |
将来性が有り勉強価値高い 費用はもちろんお安い |
サービスをウェブコンソールで試しに少し使ってみて、適合する候補を選んでからプログラムすることにします。
2.事前調査
2.1. 認識アプリベンチマーク
最初に食品認識するスマホアプリをいくつか試してみました。カロミルがUIも操作フローもとても良い感じでした。推定された品目候補が表示されてその中から利用者が正しいと思う品目を選ぶ手順です。(これを正解にして追加学習をしている様子。)
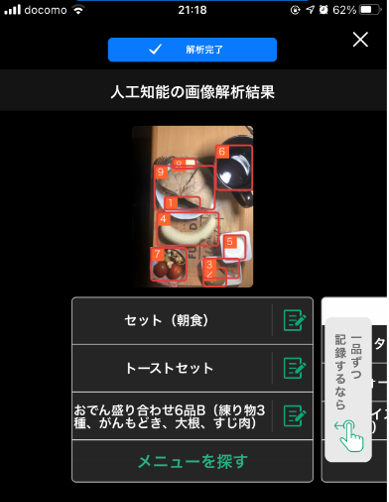
最終的にこのくらい出来たら楽です。残念ながら認識結果(ラベル)の個人カスタマイズは出来ませんが。(サラダチキン100kcalとかビヒダスヨーグルト50kcalとかの定番ダイエットメニューをラベルに出来たら入力が楽になるんですが。以下は自分のスマホに手動で献立を入力しているメモ例です。)

2.2. 候補サービスAPI選定
- 要件に合わなさそうな候補は、カロミル(法人向)、docomo(日本語食品名も有るが個人には障壁高め)など。
- 要件に合いそうな候補サービスは、Rekognition(AWS)、CloudVision(google)、IBM、Azure(MS)
- IBMは食品の認識クラスが有るのが良い。Rekognition Custom Labels(AWS)とAutoML Vision(google)は追加学習可能。BoundingBoxの座標も返り品目選択に便利そう。アカウントを持っているので短納期で手が出しやすい。
- 参考:「3大パブリッククラウドAWS GCP Azure の画像認識AIを価格や機能、精度の観点で比較! 」
(結論)RekognitionとCloud Visonをウェブコンソール認識で比較する。
2.3 AWS/GCPをウェブコンソールで比較
Webコンソールからプログラム無しで画像認識を試す。AWSはここから。(要サインイン)
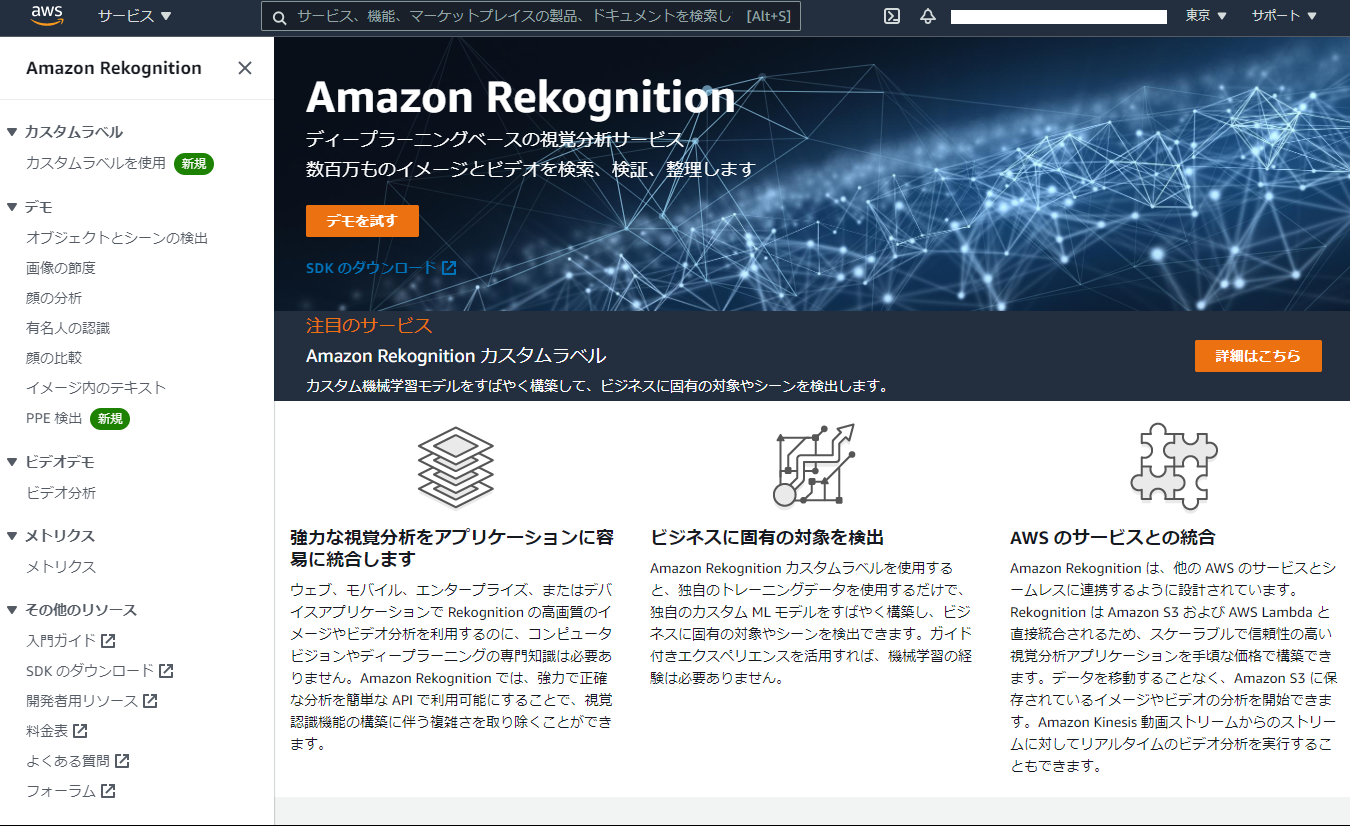
サインインしたら「デモを試す」ボタンを押してお試しページへ。「サンプルイメージを選択」すると認識結果とAPIレスポンスが表示される。ここまで中々いい感じ。
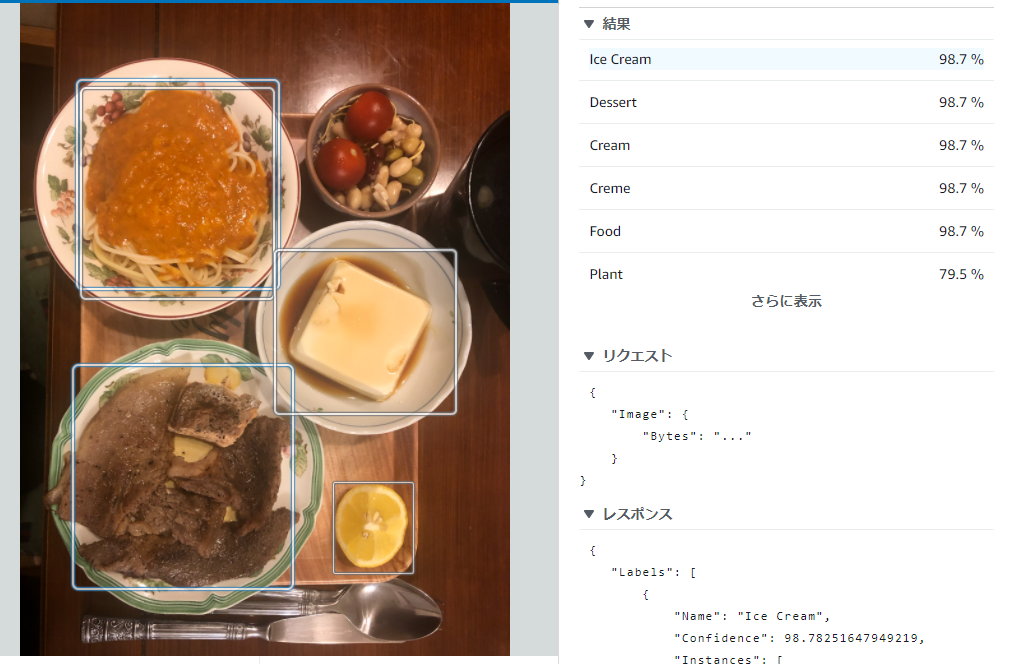
同じページ内に自分の献立写真をドラッグ&ドロップして試してみた。すぐ認識されるが、うーん、残念ながら精度は全然だ~。ice creamはともかくeggかもって。これは豆腐を知らんな。。。
ではgoogleはどうか。
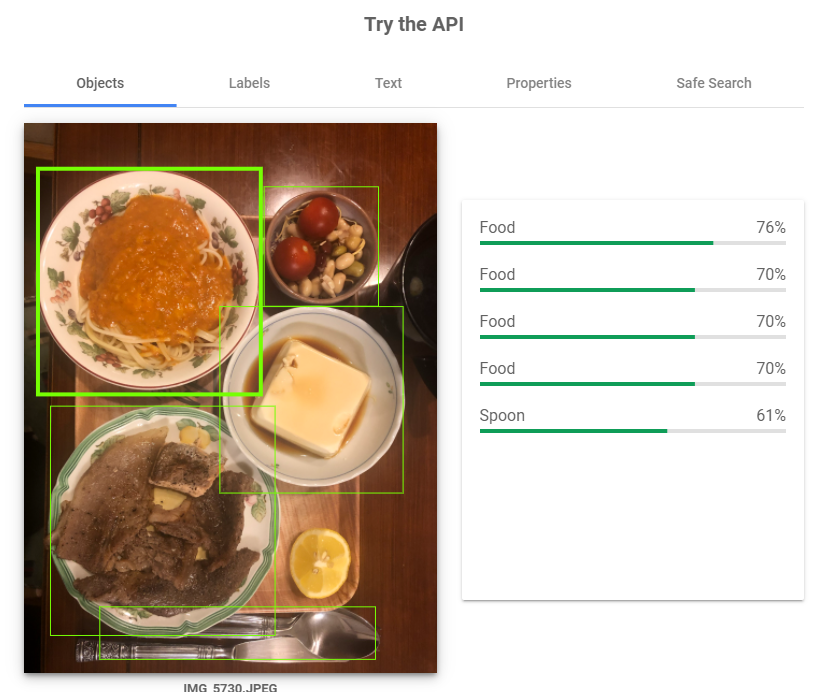
・・・同じようなもんでした。しかも推論結果のラベルが全部food。これは学習しないと使いもんにならん。。。
(結論)「学習」要件を変更し「追加学習」はMUSTに。そして使い勝手はどちらも似た様な感じ。
本試作ではRekognition Custom Labelsを使う。
3.Rekognition Custom Labelsのモデル学習
ここから以下サイトを参考にAWSのコンソール上で作業。
Rekognition Custom Labelsの「ご利用開始にあたって」を押すと初回はS3作成作業が始まる。

S3バケットを作る必要があると出るので作成を押すとバケット名は適当に作成してくれる。
次にプロジェクトを作る。(ここではmy-foodとしました。)
次にデータセットを作成する。(ここではmy-food-2021-mayとしました。)
データセットに用意した食品写真(5月分の献立)から28枚をアップロード。(一括アップが30枚までらしい。学習時間も考えてこの程度で。)

次はラベル付け(アノテーション)をラフに実施。(全ての食品へラベルをつけなくてもOK。)
(反省:無糖の紅茶認識はカロリー計算に不要だった。対象外の食品の学習有無で認識精度が上がるか下がるかは後日試したい。)
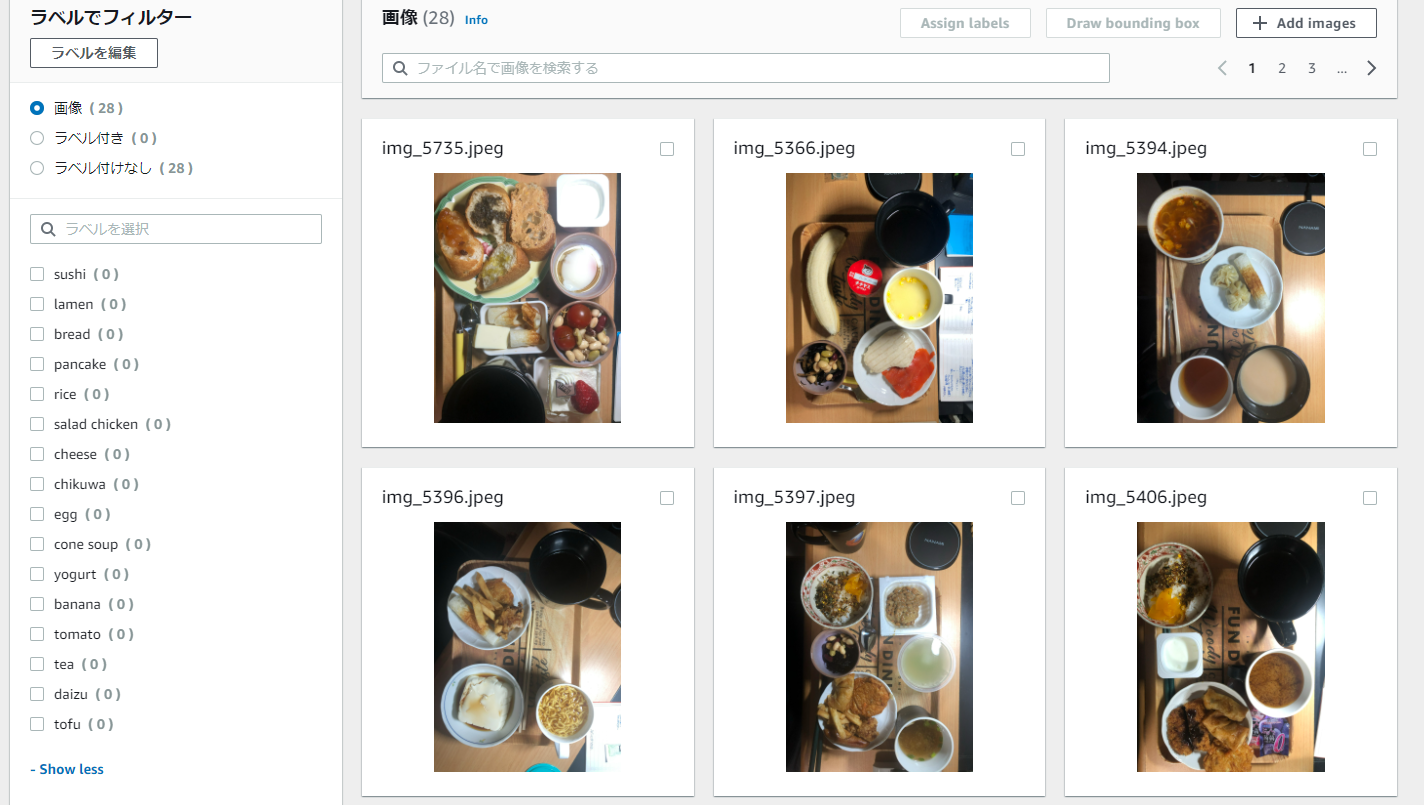
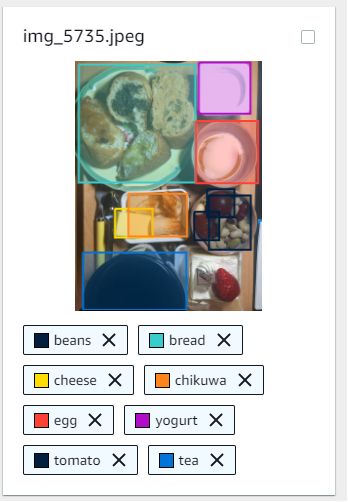
使ってみた感じ中々学習コストが低くて作業効率の良いUIでした。認識する対象領域の切り出しもラベル付けも全て直観でUIポチポチ。(ローカルでもこんな便利なフリーツールは有るのでしょうか。)出来た教師データは以下の様な感じ。
上記でラベル付けが済んだデータセットで、新しいモデルを作ってトレーニングする。この時、学習データはSplitを指定。(お任せで検証データを分けてくれる。今回は8割で学習して2割で検証してくれる模様。)
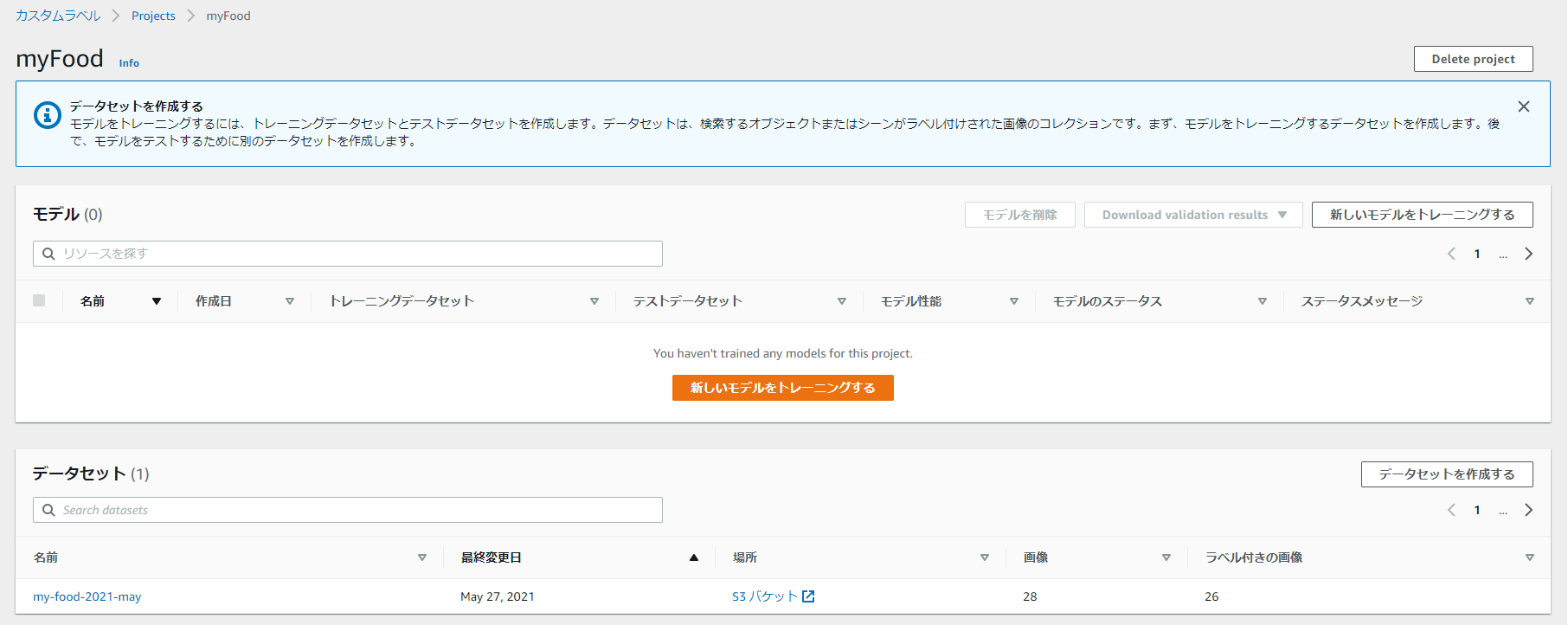
「トレーニングする」を押すと、学習がInprogressになった。翌朝ステータスを見ると終わっている。かかった時間は1.5hでバナナのスコアが0.5程の様子(これは良い方なのだろうか?)さらにViewResultでビジュアルに詳細を確認すると以下の様な感じ。
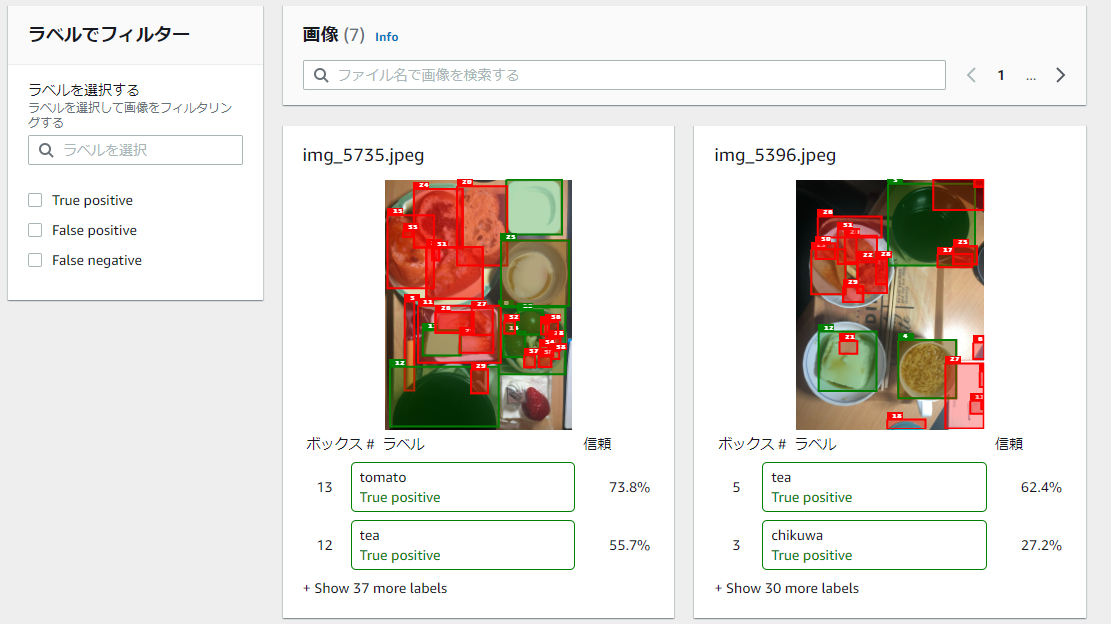
ノイズが多くて実用には苦しそうに見えるけど、品目候補に使う分には悪く無いか。。。(今後はカロミルの様に利用中のアノテーションを使って追加学習で精度あげる方向にいかないとね。)
4.プログラムからAPIを呼ぶ
4.1. モデルを使って推論
現在、myFoodプロジェクトには先程作ったトレーニング済みのモデルが1つあるので、これを使う。
モデルは開始・停止が出来、停止している間は費用が掛からない模様。

モデルをクリックして開いて「モデルを使用」タブを選ぶと、ここに開始ボタンが有るのだが、さらに下の方にはAWS CLIのコマンドとPythonのコードが載っている。
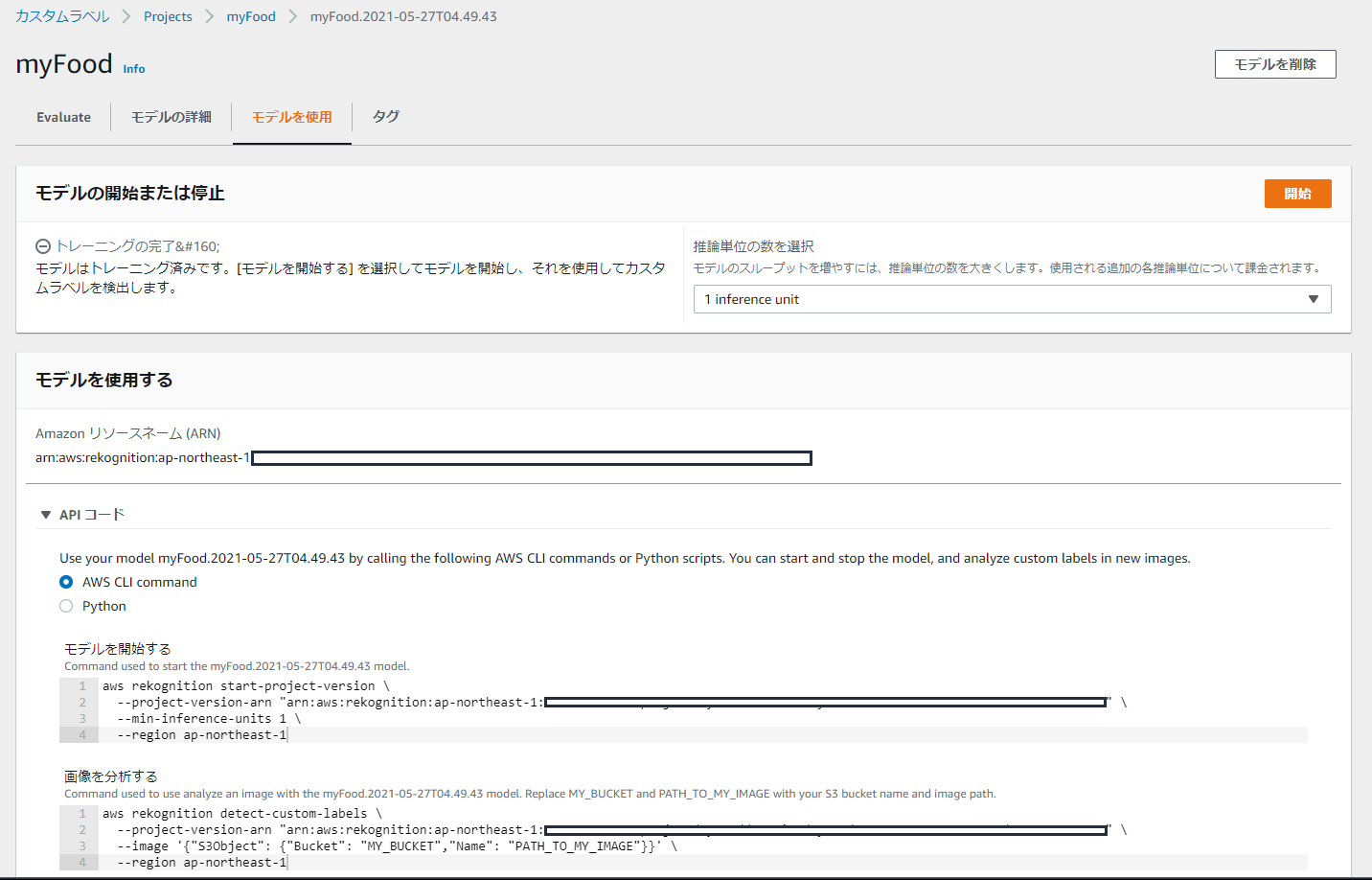
どの手段で起動しても良い筈だが、まずはAWS CLIのコマンドでモデルを起動してみる。
$ aws rekognition start-project-version \
--project-version-arn "arn:aws:rekognition:ap-northeast-1:*********************************" \
--min-inference-units 1 \
--region ap-northeast-1
よし起動中。

え~。。。その後数分待って開始されたので続き。学習に使った5月画像と異なる4月画像をS3にアップロードしました。AWS CLIコマンドでこれを指定して推定させました。
$ aws rekognition detect-custom-labels \
--project-version-arn "arn:aws:rekognition:ap-northeast-1:*********************************" \
--image '{"S3Object": {"Bucket": "custom-labels-console-ap-northeast-1-***********","Name": "assets/my-food-2021-april/IMG_4635.JPEG"}}' \
--region ap-northeast-1 > result.json
$ less result.json で結果を斜めに見る。おお、上位は良い線いってる? "banana", "cheese","salad chicken","cone soup","sushi","egg","pancake"... 良く判らない楕円は皆寿司かもと思ってるきらいはあるけど。(寿司ネタをひとまとめに認識する学習は無理が有るな。)なお、AWS CLIの先頭にtimeコマンドを追加して測ったAPI実行時間は4.03秒でした。(使わない時は忘れずモデルを停止しよう。)
4.2. Python実行と結果表示
今度はAWSの公式サイトのPython Sampleプログラムを使って推論APIを呼びます。モデルで「モデルを使用」タブを選んで「APIコード」を開くと本モデルを指定済みのPythonコードが入手できます。推論して得られた結果を元の画像上に重畳表示するところまでやってくれるとても優れもののサンプルコードです。
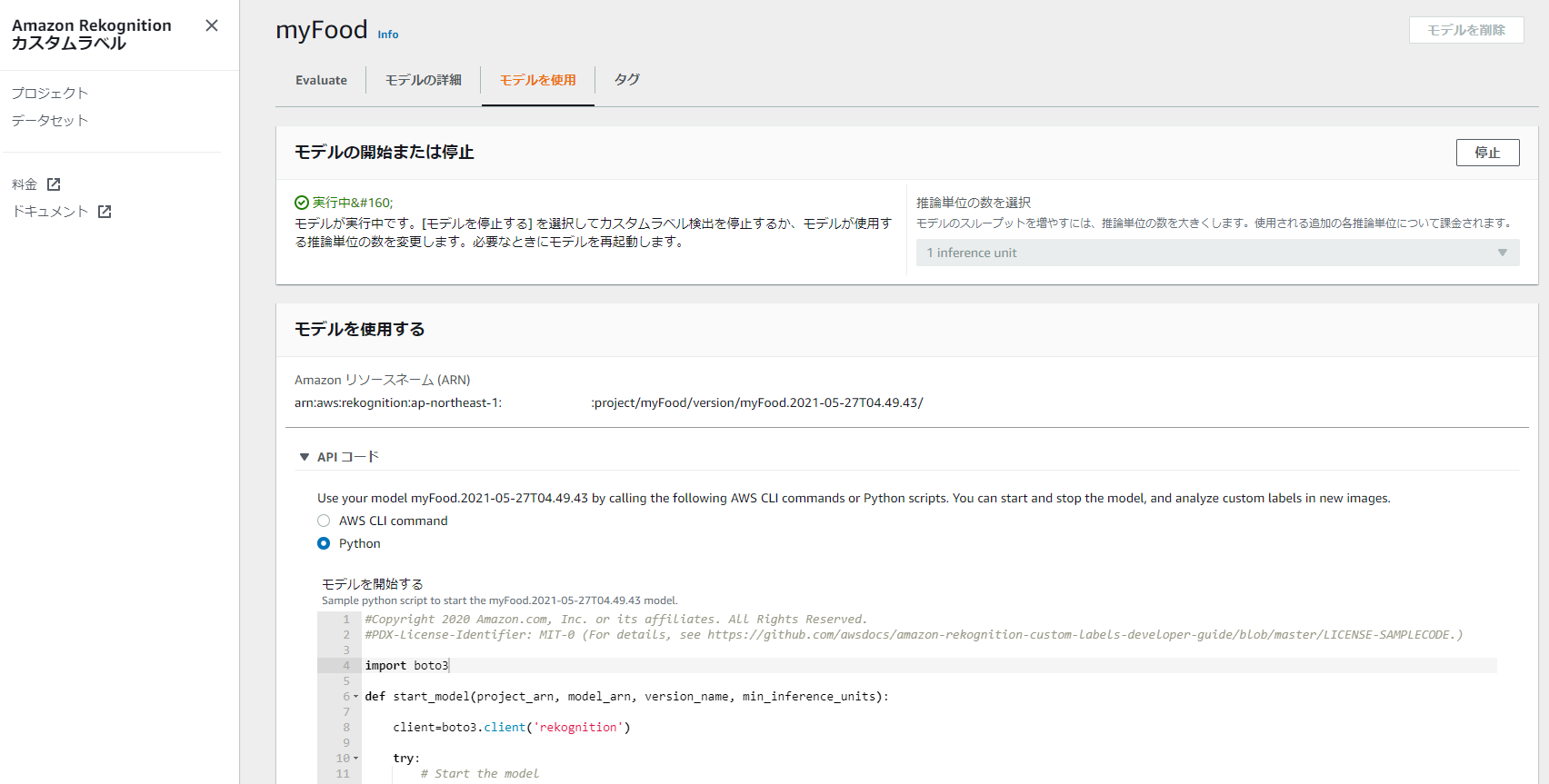
これを適宜自分用に書き換えます。pythonコードの実行環境はEC2インスタンスを前提とします。EC2にはGUIが無いので画像表示部分を画像保存にしました。改変箇所は下記です。
# image.show()
image.save('rekognition/result.jpg', quality=95)
EC2環境は通常ラベル表示用のフォントもインストールされていません。今回はIPAフォントを追加インストールしました。フォント読み込みパスを環境にあわせて改変します。(フォント参考)
$ sudo yum install ipa-gothic-fonts ipa-pgothic-fonts
$ ls /usr/share/fonts
ipa-gothic ipa-pgothic
# fnt = ImageFont.truetype('/Library/Fonts/Arial.ttf', 50)
fnt = ImageFont.truetype('/usr/share/fonts/ipa-pgothic/ipagp.ttf', 50)
min_confidenceを書き換えると、どの程度以上自信が有る結果まで表示させるか決められます。50%以上にしたい場合は下記。
# min_confidence=95
min_confidence=50
保存した画像を表示してやると

おおっおっ?おっ⁉・・・主要な食材を認識しとる。ミルクティーはteaかcorn soupかで迷っとる・・・
これは中々可愛いんじゃないか?
自信のなさそうな推論(15%以上)まで表示させた結果が下記。
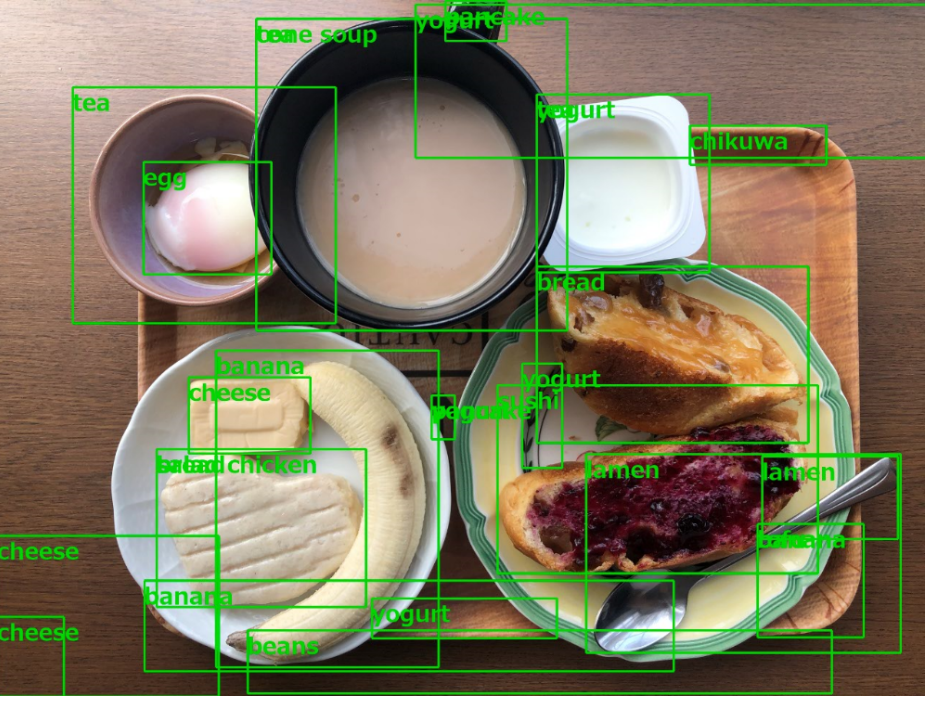
自信度低いながらeggも見つけてる。。。
5.ラムダのサンプルコード
上記Pythonコードが充分機能することが判ったので、システムに適切に組み込んでやればOKです。
ラムダコード例を下記に載せます。(S3(/assets)に食品画像がアップされたら、ラムダが起動して食品認識させ、結果画像をS3(/results)に書き戻します。ラムダレイヤーでPIL(Pillow)パッケージとIPAフォントの導入が必要です。)
import json
import boto3
import urllib.parse
import re
import io
from PIL import Image, ImageDraw, ImageFont
s3 = boto3.resource('s3')
client = boto3.client('rekognition')
model_name = 'arn:aws:rekognition:xxxxxxxxxxx'
min_confidence = 15
def rekognition(bucket_name, photo_name, model_name):
""" rekognize photo on S3 bucket """
responce = client.detect_custom_labels(Image={'S3Object': {'Bucket': bucket_name, 'Name': photo_name}},
MinConfidence=min_confidence,
ProjectVersionArn=model_name)
return responce
def load_image(bucket_name, image_name):
""" load image from S3 bucket """
s3_object = s3.Object(bucket_name, image_name)
s3_response = s3_object.get()
stream = io.BytesIO(s3_response['Body'].read())
image=Image.open(stream)
return image
def save_image(bucket_name, image_name, image):
""" save image to S3 bucket """
image_bytes = io.BytesIO()
image.save(image_bytes, format='JPEG')
image_bytes = image_bytes.getvalue()
obj = s3.Object(bucket_name, image_name)
obj.put( Body=image_bytes )
return True
def draw_result_on_image(result, image):
""" draw bounding boxes onto image for each detected custom label """
# Ready image to draw bounding boxes on it.
imgWidth, imgHeight = image.size
draw = ImageDraw.Draw(image)
# calculate and display bounding boxes for each detected custom label
for customLabel in result['CustomLabels']:
if 'Geometry' in customLabel:
box = customLabel['Geometry']['BoundingBox']
left = imgWidth * box['Left']
top = imgHeight * box['Top']
width = imgWidth * box['Width']
height = imgHeight * box['Height']
print('Label: ' + str(customLabel['Name']) + ', Confidence: ' + str(customLabel['Confidence']) \
+ ', Left: ' + '{0:.0f}'.format(left) + ', Top: ' + '{0:.0f}'.format(top) \
+ ', Label Width: ' + "{0:.0f}".format(width) + ', Label Height: ' + "{0:.0f}".format(height))
fnt = ImageFont.truetype('/opt/fonts/ipa-pgothic/ipagp.ttf', 10)
draw.text((left,top), customLabel['Name'], fill='#00d400', font=fnt)
points = (
(left,top),
(left + width, top),
(left + width, top + height),
(left , top + height),
(left, top))
draw.line(points, fill='#00d400', width=2)
return image
def lambda_handler(event, context):
# 1: check event
bucket_name = event['Records'][0]['s3']['bucket']['name']
src_jpeg_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') # ex. assets/my-food-2021-august/photo1.jpeg
result_json_key = re.sub('^assets/(.*)jpeg$', "results/\\1json", src_jpeg_key) # ex. results/my-food-2021-august/photo1.json
result_jpeg_key = re.sub('^assets/', "results/", src_jpeg_key) # ex. results/my-food-2021-august/photo1.jpeg
print("model_name:" + model_name)
print("bucket_name: " + bucket_name)
print("source_jpeg: " + src_jpeg_key)
print("result_json: " + result_json_key)
print("result_jpeg: " + result_jpeg_key)
# 2: rekognize
result_json = rekognition(bucket_name, src_jpeg_key, model_name)
print("Result: " + json.dumps(result_json))
# 3: save result json into S3
obj = s3.Object(bucket_name, result_json_key)
obj.put( Body=json.dumps(result_json) )
# 4: load original image
image = load_image(bucket_name, src_jpeg_key)
# 5: draw results on the image
image = draw_result_on_image(result_json, image)
# 6: save the image to S3
save_image(bucket_name, result_jpeg_key, image)
6.結果まとめ
AWS Rekognition Custom Labelsが食品認識に利用できそうなことは判りました。
任意でラベルを定義し、推定させた画像をデータセットに追加して定期的にモデルの学習をすれば、想定していたフローが実現できそうです。精度向上と費用はこれから検証です。
7.参考資料