はじめに
今回は AWSの 画像、動画分析サービスである Amazon Rekognition の Custom Labels 利用が開始となったため、アーモンドとピーナッツが判別できるか、検証いたします。
Amazon Rekognition Custom Labels とは
Amazon Rekognition とは AWS の提供する 画像、動画分析サービスです。シーン検出や顔認識、テキスト認識や動線検出など多くのAPI が存在します。
今回この Rekognition が Custom Labels に対応しました。
今までは AWS の用意した学習済みモデルを利用した物体検出しか利用できませんでしたが、自前で用意した画像で画像検出モデルを作成し、利用できるようになりました。
今回の目的
Amazon Rekognition Custom Labels で、ちょうど家にあったピーナッツとアーモンドの判別モデルを作ってみます。
今回はデータ準備、ラベリング、モデル作成、推論API利用までやってみます。
データ準備
今回は画像をピーナッツとアーモンドでそれぞれ21枚ずつ用意しました。
画像はこんな感じ。
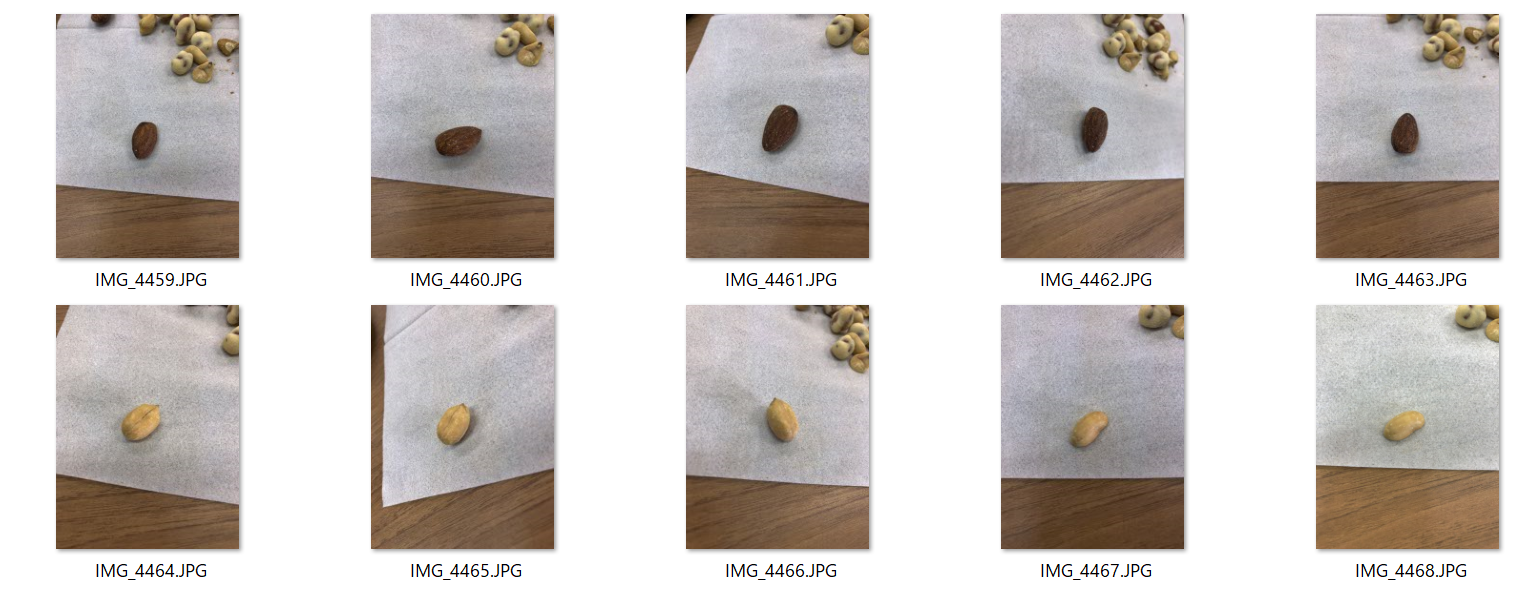
データの準備は完了です。
早速 AWS コンソールから、ラベリングに進みましょう。
ラベリング
作成したデータのラベリングは、AWSのコンソール上で行います。
現在(2019年12月10日時点)は、Amazon Rekognition Custom Labels は以下のリージョンでのみ利用可能です。
- バージニア北部
- オハイオ
- オレゴン
- アイルランド
AWS コンソール上でリージョンを変更してから以降の手順を行ってください。
まず、AWS コンソールから Amazon Rekognition を開きます。
次に、サイドバー上部から Use Custom Labels を開きます。

※2019年12月10日時点では、表示言語を日本語にしていると、Custom Labels の項目が表示されません。
左下の言語欄から英語を選択し、次に進んでください。

Get Started をクリックします。

作成するデータセットや、モデルの保存先 S3 を作成します。
Create S3 bucket をクリックします。
次にプロジェクトを作成します。
任意のプロジェクト名を入力し、Create project をクリックします。
プロジェクトを作成したら、データセットを作成します。
Create datasetをクリックします。
任意のデータセット名を入力します。
データのアップロード方法を選択します。
今回はローカルからアップロードを選択します。
画像をアップロードします。
下にスクロールし、Add images をクリックします。
以下のように表示されるので画像を、Drag&Drops します。
※この時画像は一度に30枚までしかアップロードできません。分けて、アップロードしましょう。
画像を Drag&Drops したら、Add images をクリックします。
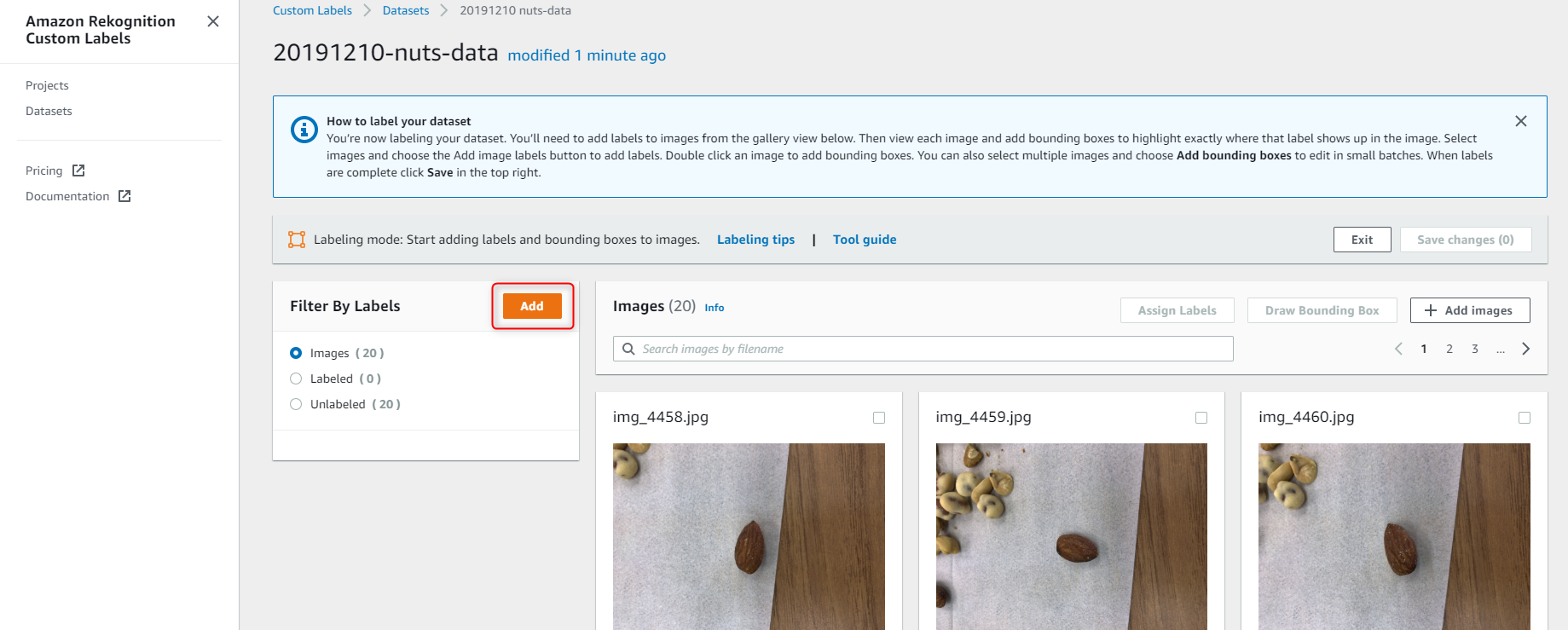
画像をアップロードしたら、画像に割り当てるラベルを登録します。
Filter by labels の Add をクリックします。
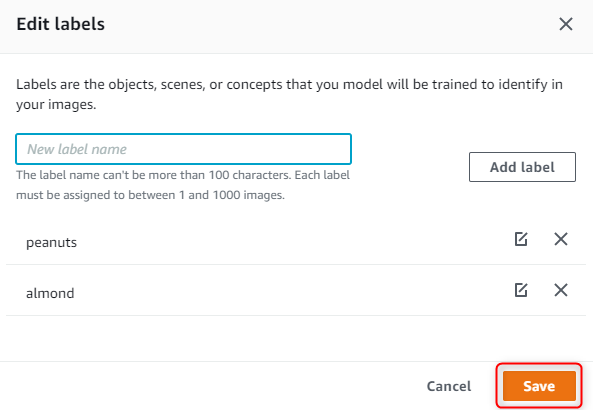
ラベルを追加し、Save をクリックします。
私の場合は、almond と peanuts を追加しました。
ラベリングしたい画像を選択して、Draw Bounding Box をクリックします。
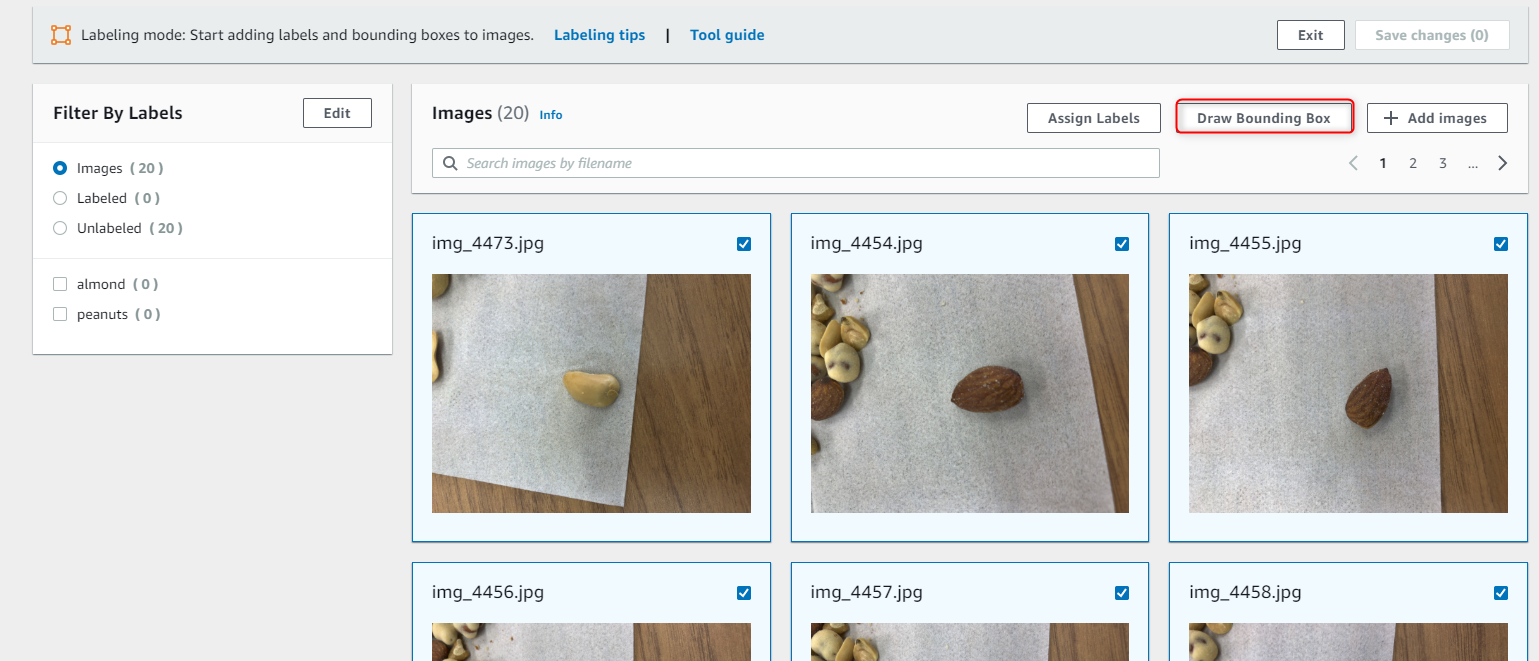
ラベリングを行います。
- まず、右側の Labels から対象のラベルを選択します。
- 次に、画像の対象物を Box で囲みます。
- 囲んだら、右上のNextをクリックします。
- 全ての画像に対してラベリングができたら右上の Done をクリックします。

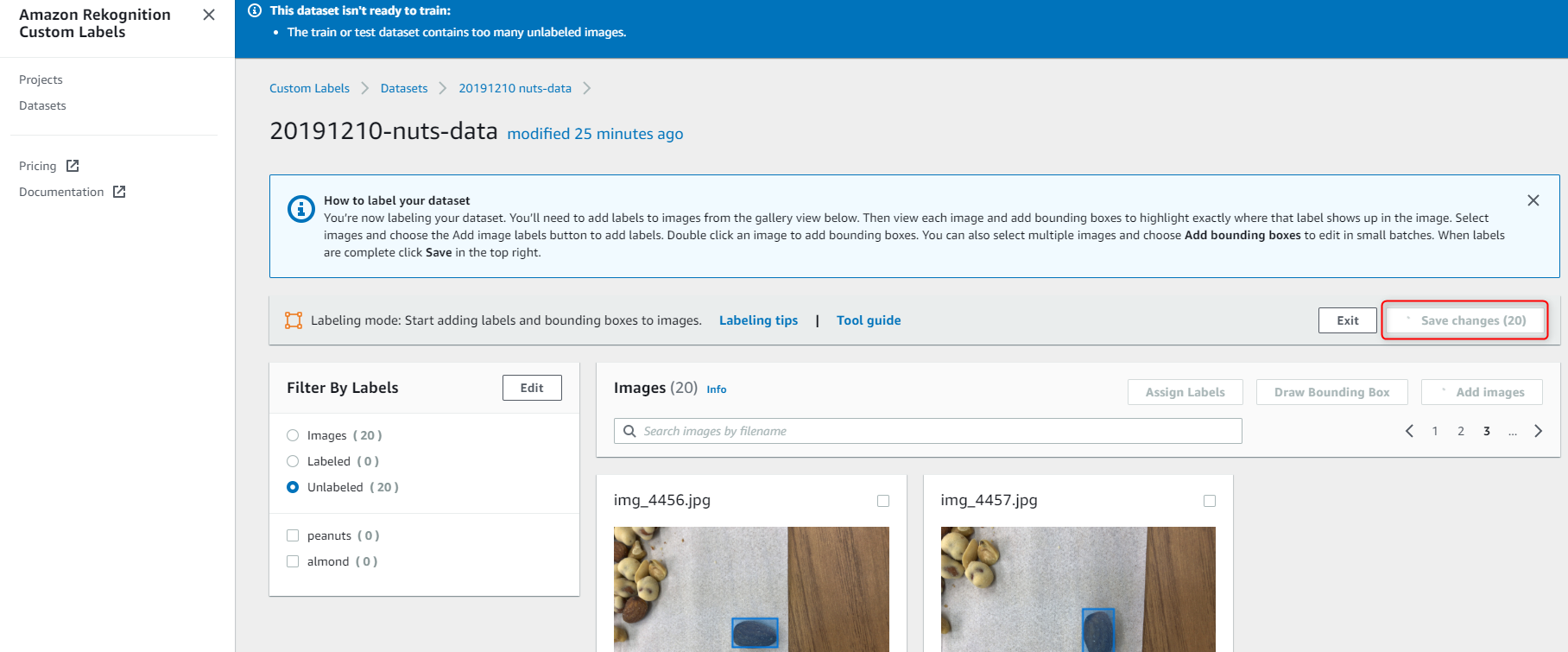
ラベリングが終わったら、右上の Save changes をクリックしてください。
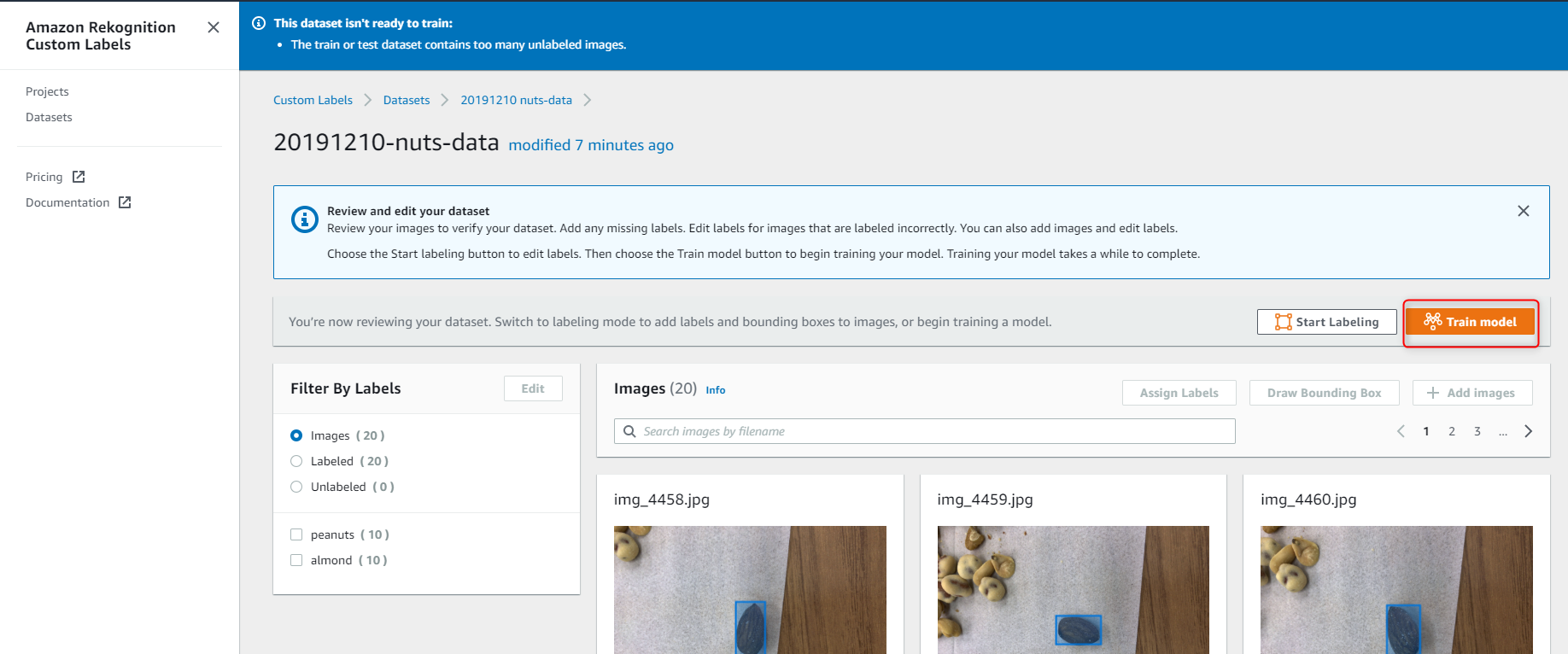
モデル作成
データセットのラベリングが完了したら、ついにモデルトレーニングです。
Train model をクリックします。
各項目を設定します。
- Choose project : 最初に作成したプロジェクトを選択します。
- Choose training set : 作成したデータセットを選択します。
- Create test set : テストデータの作成方法を選択します。今回は、学習データの中から20%を自動でテストデータとして抽出する Split training dataset を選択します。
全て設定したら、右下の Train をクリックします。

これでモデルトレーニングが始まります。
Status が TRAINING_COMPLETED になるまで待ちます。
学習画像32枚、テスト画像10枚で1時間弱ぐらいかかりました。
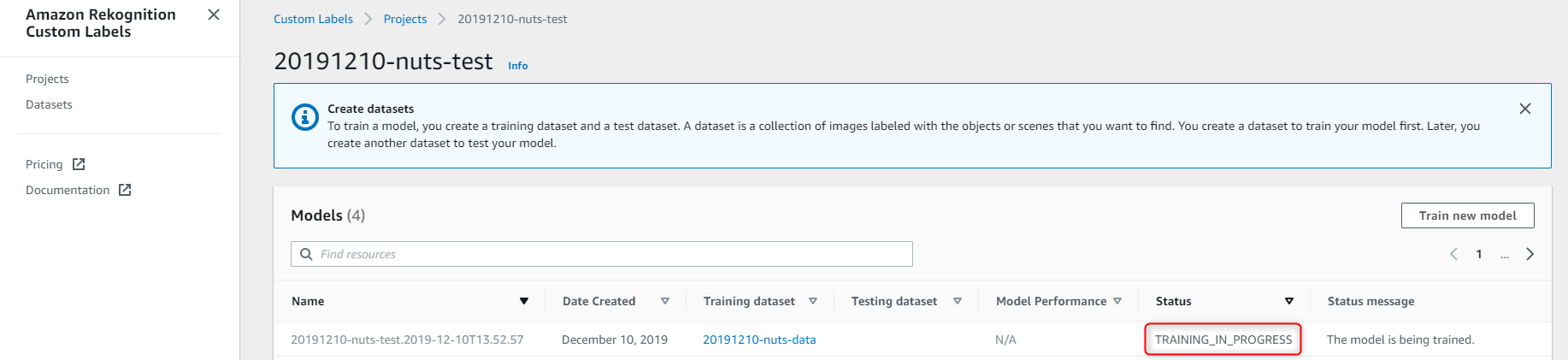
モデルトレーニングが完了しました。
ジョブ名をクリックして、トレーニングの詳細を見てみましょう。
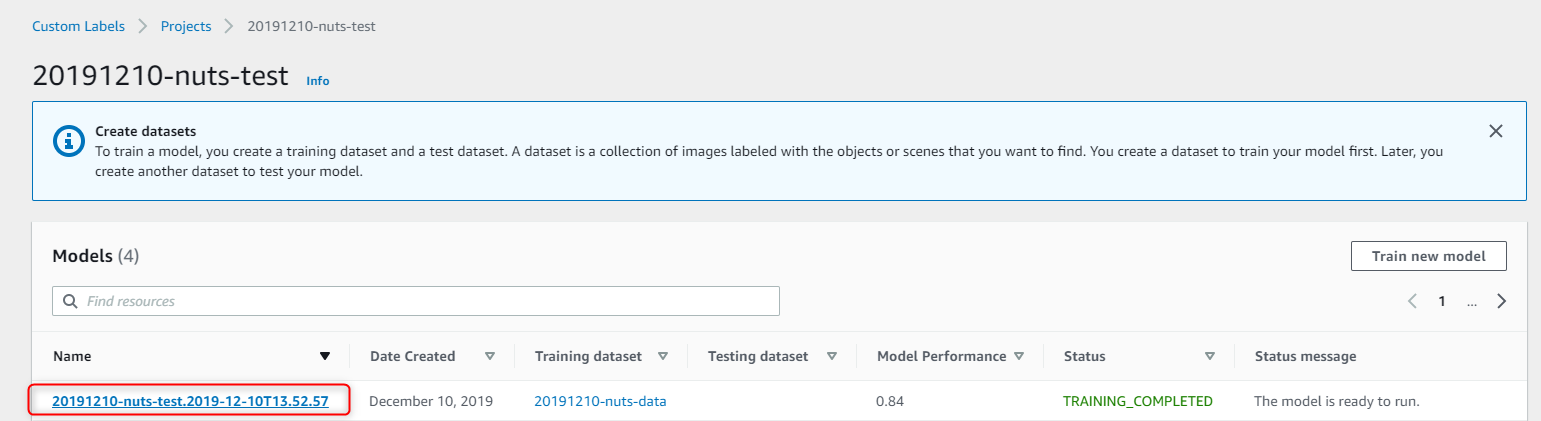
モデルのスコアが載っています、精度90%、再現率80%となかなかいい感じですね。

推論 API の利用
実際に作成したモデルをデプロイして、推論してみましょう。
下にスクロールすると、モデルデプロイ、推論、デプロイ終了の API 利用コマンドがあるので順に実行してみましょう。
※古いバージョンの AWS CLI にはコマンドが存在しないため、以下から、AWS CLI のアップデート方法を確認し、実行してから次に進んでください。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv1.html#post-install-upgrade

まず、Start APIを実行すると、以下の様にレスポンスがあります。
{
"Status": "STARTING"
}
実行後コンソールを確認してみると、対象のモデルステータスが STARTING となります。

Status が RUNNING になったのを確認したら、Detect API を実行しましょう。
推論に利用する画像は、あらかじめ S3 にアップロードしておきましょう。

今回は以下の画像を推論してみます。

Detect API を実行すると、以下のように推論結果が返されます。
{
"CustomLabels": [
{
"Name": " almond",
"Confidence": 96.87999725341797,
"Geometry": {
"BoundingBox": {
"Width": 0.3379000127315521,
"Height": 0.14917999505996704,
"Left": 0.31453999876976013,
"Top": 0.385919988155365
}
}
}
]
}
実際に可視化するとこんな感じです。
うまく推論できているようです。

推論を終えたら、Stop API でデプロイしているモデルを停止します。
以下のようにレスポンスがあります。
{
"Status": "STOPPING"
}
コンソールを確認してみると既に Status が STOPPED になっていました。
おわりに
今回は Amazon Rekognition Custom Labels を検証しました。
画像を用意するだけで簡単に画像検出ができてしまい、感動しております。
今回はピーナッツとアーモンドの2種類でしたが、もう少し似通ったカシューナッツとか入れてもやってみたいと思います。
※料金は2019年12月10日現在、確認中です。わかり次第追記いたしますので、お待ちください。