対象読者:
- Ollamaの基本的な使い方がわかる
- Claude Codeを使ったことがある、または興味がある
- ローカルLLM環境を手元で試したい
- 本記事の検証内容は執筆時点(2026年4月)のものです。OllamaおよびClaude Codeはアップデートが活発なため、最新バージョンでは挙動が異なる場合があります
- 本記事の執筆には生成AIを使用しています
TL;DR
- OllamaをローカルLLMプロバイダーとしてClaude Codeを利用できる
-
ollama launchコマンドは Ollama v0.15以降 で使用可能 - スキル・MCPを使うにはツール呼び出し対応モデルが必要(非対応だと400エラーになる)
- 対応モデルは
qwen3系、gpt-oss系のほか、リリース直後のGemma 4でも動作確認済み - トグルパズル(Toggle Puzzle)の生成まで正常動作を確認
- Ollama v0.20.0でGemma 4ダウンロード中にAMD系NPUの動作をタスクマネージャーで確認
きっかけ
OllamaをGUI起動したらこんなものが目に飛び込んできました。
「OllamaをローカルLLMプロバイダーとしてClaude Codeが使えるってこと?!」

Anthropic公式のClaude Codeは通常、Anthropic APIを利用します。ところが、OllamaをLLMプロバイダーとして指定できるとしたら、ローカルで完結するAIコーディングアシスタント環境が作れるのでは、と思い立ちました。
環境
- OS: Windows11 Pro 25H2
- プロセッサー*: AMD Ryzen AI 9 HX 370 w/ Radeon 890M
- Ollama: v0.20.0(検証時点での最新版)
- Claude Code: v2.1.92
-
使用モデル:
gpt-oss系、gemma4系
事前準備
OllamaはいまだRadeonを効率よく動作させるROCmに対応しきっていないので、Vulkan1を使用することでGPUの機能を引き出します。
設定方法はWindows11の場合、環境変数を設定アプリを起動して、ユーザー環境変数としてOLLAMA_VULKANの値に1を設定します。

環境変数を設定アプリはコマンドrundll32 sysdm.cpl,EditEnvironmentVariablesを実行することで起動できます。
環境変数は一文字でも間違えると効果がなく、すでにある変数を削除したり、値を変更するとOllamaやClaude Code以外のプログラムも動作しなくなる場合があります。
環境変数の設定を変更する場合は自己責任でお願いします。
以上の設定を行ってからOllamaを起動します。
設定方法
Claude Code のインストール
まだインストールしていない場合は、公式ドキュメント(Claude Code | Getting Started)を参照してください。Windowsでは以下のコマンドでインストールできます。
winget install Anthropic.ClaudeCode
ollama launch コマンドについて
以下のコマンドを実行すると、Claude CodeがOllama経由で起動します。
ollama launch claude
バージョン要件: ollama launch コマンドは Ollama v0.15以降 で追加された機能です(参考: Ollama公式ブログ)。それ以前のバージョンでは Error: unknown command "launch" for "ollama" というエラーが出ます。必ずアップデートしてから実行してください。
ollama --version でバージョンを確認できます。
起動後、モデル選択画面が表示されるので、Ollamaが使用できるダウンロード済みのモデルからClaude Codeを実行するモデルを選択します。

ハマりポイント:ツール対応モデルを使わないとエラーになる
Claude CodeはスキルやMCP(Model Context Protocol)の利用時にツール呼び出し(Function Calling) を行います。
ツール呼び出しに対応していないモデル(Gemma3:4b-qat等)でこれを実行しようとすると、以下のようなエラーが発生します。
❯ トグルパズル(Toggle Puzzle)をhtml+css+jsで実装せよ
⎿ API Error: 400 {"type":"error","error":{"type":"invalid_request_error","message":"registry.ollama.ai/library/gemma3:4b-it-qat does not support
tools"},"request_id":"req_faa8645ab67f6c62c2ac94f5"}
解決策: ツール呼び出しに対応したモデルを選ぶ必要があります。
| モデル | ツール対応 | 備考 |
|---|---|---|
qwen3系 |
✅ 対応 | 安定して動作 |
gpt-oss系 |
✅ 対応 | 安定して動作 |
gemma4系 |
✅ 部分的に対応 |
gemma4:e系はツールが使えないので不可 |
| ツール非対応モデル全般 | 非対応 | ツールを使わないようにCLAUDE.mdなどで制御すれば使えるかも?(未検証) |
環境別の注意点
GPU・CPUの環境によってパフォーマンスが大きく変わります。
| 環境 | 動作 | 備考 |
|---|---|---|
| Radeon GPU(本記事の環境) | ✅ GPU推論 | ROCm未対応のためVulkan経由で使用(本文参照) |
| NVIDIA GPU | ✅ GPU推論(もっとも安定) | CUDAドライバーが必須。ドライバーが未インストールまたはバージョン不一致の場合、OllamaはCPUにフォールバックする |
| Apple Silicon (M系) | ✅ GPU/Neural Engine推論 | Unified Memoryを活かせるため大きめのモデルも動かしやすい |
| CPU のみ | ⚠️ 動作するが低速 | 1〜3トークン/秒程度。小さいモデルを選ぶのが現実的 |
GPUが使われているか確認する方法: ollama ps コマンドを実行し、PROCESSOR 欄が 100% GPU になっているか確認してください。100% CPU になっている場合はGPUドライバーの設定を見直す必要があります。
以下の例では、2つのモデルが100% GPUで動作していることがわかります。

リリース直後のGemma 4でもツール呼び出しが動いた
2026年4月3日(日本時間)、Google DeepMindがGemma 4をリリースしました。そのリリース当日中に、OllamaもGemma 4のサポートを含んだv0.20.0を公開しています。
Gemma 4はこれまでのGemmaシリーズから大きく進化しており、Function Callingをネイティブサポートしています。
| モデル | パラメーター(アクティブ) | 主な用途 |
|---|---|---|
gemma4:e2b |
実効2B | スマホ・エッジデバイス向け |
gemma4:e4b |
実効4B | エッジ向け・デフォルト |
gemma4:26b |
実効4B(MoE・総計26B) | ワークステーション向け(速度と品質のバランス◎) |
gemma4:31b |
31B(Dense) | ワークステーション向け最高品質 |
Ollamaでの各モデルの取得は通常通りコマンドで行えます。
# パラメーター数未指定だとe4bのモデルがダウンロードされる
ollama pull gemma4
# その他のサイズを明示的に指定する場合
ollama pull gemma4:e2b
ollama pull gemma4:26b
ollama pull gemma4:31b
このGemma 4をOllama経由でClaude Codeから利用したところ、gemma4:26bおよびgemma4:31bはスキル・MCPのツール呼び出しもエラーなく動作することを確認できました。
- Gemma 4はリリース直後のため、量子化バージョンやトークナイザーの実装に問題が発見される可能性も指摘されています(HackerNewsより)。ツール呼び出しがうまくいかない場合は、Ollamaおよびモデルのバージョンを確認してみてください
- 技術的な詳細については公式モデルカードを参照してください
実際に動かしてみた:トグルパズル(Toggle Puzzle)を生成する
動作確認として、トグルパズル(Toggle Puzzle) を生成させてみました。
トグルパズル(Toggle Puzzle)とは、グリッド上のセルをクリックすると自身と隣接するセルの点灯状態が反転するパズルで、「すべてのセルを消灯した状態にする」ことがゴールです。
ここでの動作確認の成功の定義は「クリックで隣接セルを含む点灯状態が正しく反転し、全消灯を目指してプレイできるインタラクティブなゲームが生成されること」としました。
できあがったもの:
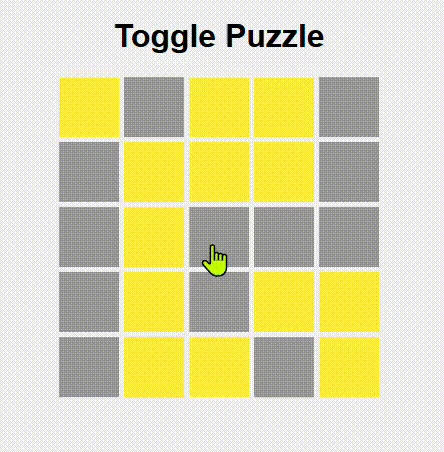
ちゃんとトグルパズル的なものになっています。よいですね。
Radeon GPU環境でも、ローカルLLMによるコード生成がある程度実用的に機能することを確認できました。タスクマネージャーを見ると、推論中はGPUがしっかり動いているのがわかります(うなる Radeon)。

おまけ:OllamaでNPUが動く日が近い?
Ollama v0.20.0でGemma 4のモデルをダウンロードしているとき、タスクマネージャーのパフォーマンスモニターでNPU(Neural Processing Unit)が動作しているのを確認しました。
なお、AMDはGemma 4リリース当日から、Radeon GPUを含むAMDハードウェア全体でのDay Zeroサポートを表明しています。ソフトウェア側の対応も着実に進んでいることが感じ取れます。
NPUがモデルの推論に実際に使われていたのか、ダウンロード処理の副作用として動いていたのかは未確認です。引き続き検証予定です。
2026/04/05 追記
本環境はCopilot+ PCに準じる環境であるため、OllamaがNPUを使っていたのではなく、Ollamaがファイルを書き込んだことをトリガーに、Windowsセマンティックインデックス2がNPUを使って差分インデックス処理を行っていたと推定されます。
今後OllamaがNPUを推論に本格活用するようになれば、ローカルLLM環境はさらに高速かつ低消費電力になりそうで楽しみです。
まとめ
| 確認内容 | 結果 |
|---|---|
ollama launch の利用に必要なバージョン |
Ollama v0.15以降 |
| OllamaをClaude CodeのLLMプロバイダーとして利用 | ✅ 可能 |
| ツール非対応モデルでのスキル・MCP利用 | ❌ 400エラー |
gemma4系・gpt-oss系でのツール呼び出し |
✅ 動作確認 |
| トグルパズル(Toggle Puzzle)の生成 | ✅ 正常動作 |
| NPU動作の確認(Gemma 4ダウンロード時) | ✅ 確認(推論利用かは未確認) |
| NVIDIA・CPU環境でのOllama動作 | ✅ 動作(CPUは低速) |
ローカルLLMでClaude Codeを動かすというニッチな構成ですが、プライバシーやコスト面を重視する場面ではおもしろい選択肢になりそうです。とくにGemma 4はリリース直後からOllamaで使えるうえにFunction CallingやVisionにも対応しており、今後の有力な選択肢になりそうです。
参考
- Ollama 公式サイト
- Ollama 公式ブログ: ollama launch
- Ollama gemma4 ライブラリ
- Gemma 4 モデルカード | Google AI for Developers
- Claude Code | Getting Started
- Claude Code | Anthropic