この記事は、MATLAB/Simulink Advent Calendar 2022の21日目の記事として書かれています。
また, 本記事に記したMATLABスクリプトは,
を用いて実行しております.
2023/4/18 GitHubにてコードを公開しました. (GitHubのコードは本記事に載っているスクリプトとは異なりますが, 機能等は全く同じです. 詳しくはREADMEをご参照ください.)
序論
MATLABは世界中のエンジニアや研究者が利用する数値計算プラットフォームです. その活用範囲はToolboxの増加とともに広がり続けており, 学生にとっても使いやすい機能がたくさんあります. では, 専攻等に関わらず, 学生に共通してMATLABを活用できる場面とはどのような状況でしょう? 本記事では, その一例として, 「大学での英語学習における活用を目的としたMATLABによる英単語帳の作成」について紹介します.
私は, MATLAB Student Ambassador(所属機関でMATLAB&Simulinkの普及活動を行う学生)の電気通信大学大学院修士課程1年生です. スウェーデン留学中にMATLABを使い始めて以来, 「MATLABというスキルは, 専攻等に関わらず, 学生生活の中で身に着けておいて損はない」という確信を持っています. その一方で, 普及活動を行う中で, 学生全員が共通してMATLABを使える状況を常に探していますが, 見つけるのは容易ではありません. そんな悩みを抱えていた時に, 偶然, MATLABを英語学習に用いてみる研究を行いました.
英語は研究を行う際の論文読解や学会にて必須のスキルであり, 多くの大学生が学習しています. しかし, 高校での英語学習と大学での英語学習はまるで別物です. 日本の高校までの英語学習においては, 習得するべき語彙がある程度定まっています. 加えて, ほとんどの高校での英語学習の目的は受験を突破することであるため, 本屋さんに行けばたくさんの単語帳が売られており, 「どの単語を覚えておくべきなのか?」という疑問はありません. しかし, 大学の英語の講義においては, 全員が覚えるべき単語という概念はなくなります. そして, 学位取得のための卒業研究等で必要となる語彙は, 基本的に, 論文をたくさん読むことでしかわかりません. これは, 各学生の研究テーマにより必要となる語彙が大きく異なることに起因しています. また, ほとんどの大学では4年間かけて研究を行うわけではないため, 卒業研究のために読める論文の本数は限られています. さらに, 学生が修得すべき単語が提示できないという問題は, 学生自身だけでなく, 効果的な講義を提供しようとする英語の先生にとっても大きな問題です.
上記問題を解決するために, 電気通信大学の上原准教授の下で「研究を行う学生にとって有益な単語リストを作成する」ことを目的とした研究$^{[1]}$が行われています. 私自身は, MATLABを用いて先生のアイデアや行おうとしていることの自動化に携わりました. そこで, この研究で行った内容の一部を紹介します.
手法
実施した研究$^{[1]}$では, 以下の部分をMATLAB等により自動化して, 単語リストを作成しています.
- 論文等の文書ファイルから英単語を抽出
- 各単語が使用された頻度を計算
- 抽出された単語リストの中から, 日常的に使用される単語や重要でない単語を削除
実際には, AntConc等を用いた解析も行っているのですが, せっかくなので, 今回はMATLABだけを用いて自動的に単語リストを作成することを目指します(そのため, 解析の手順は研究$^{[1]}$で行ったものとは若干異なります).
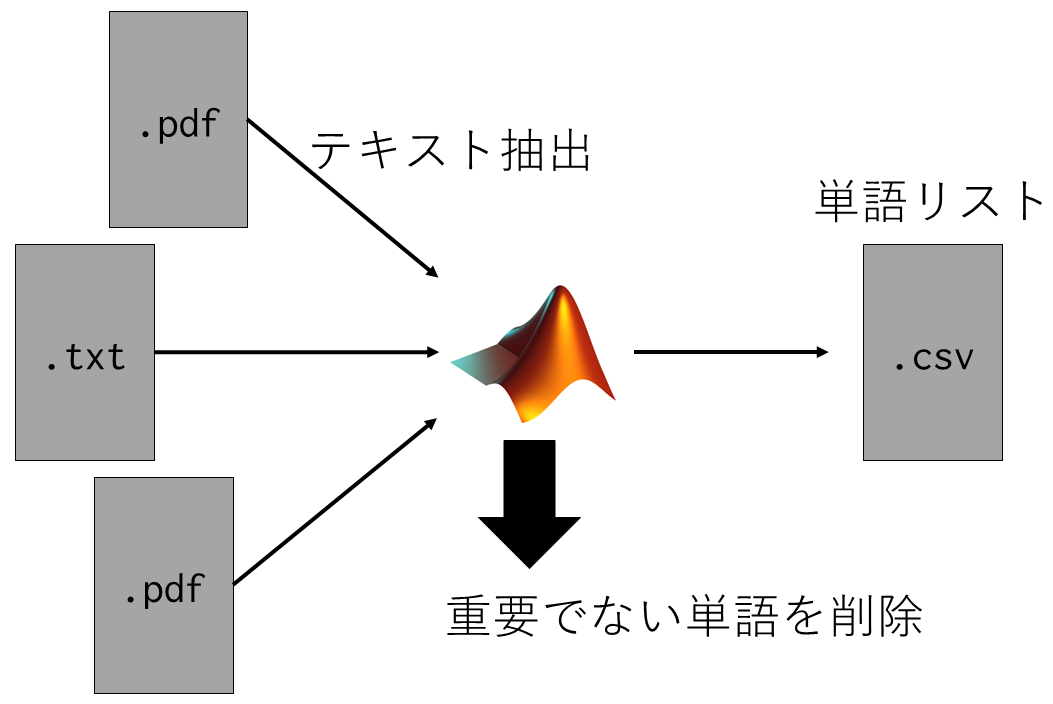
今回の解析の手順は以下の通りです.
文書ファイルから英単語を抽出
まずは, 入力された文書ファイルからテキストデータを抽出します. ここでは, MATLABのファイルデータストアとText Analytics ToolboxのextractFileText関数を使用します.
doc_folder_name = "path/to/input/documents/folder";
doc_ds = fileDatastore(doc_folder_name, ...
'ReadFcn',@MyReadFcn, ...
"FileExtensions",[".pdf",".txt",".html",".docx"]);
input_text_data = readall(doc_ds);
% Read function in file data store
function textdata = MyReadFcn(filename)
try
textdata = extractFileText(filename);
catch
textdata = '';
end
end
解析のためのテキストデータの前処理
次に, 得られたテキストデータに前処理を施します. extractFileText関数で得られたテキストデータには, 英単語でないものも多く含まれるため, ここで削除します.
original_string_data = join(string(input_text_data),1); % Convert cell to string
preprocessed_doc_data = text_preprocess(original_string_data);
作成した前処理関数text_preprocessは, Prepare Text Data for Analysisに記載されているスクリプトを基に作成しました.
- eraseURLs
- tokenizedDocument
- correctSpelling
- addPartOfSpeechDetails
- removeStopWords
- normalizeWords
- erasePunctuation
% Function for preprocessing
function cleanedDocuments = text_preprocess(string_data)
% Create Tokenized data
string_data = eraseURLs(string_data);
string_data = replace(string_data,' '+digitsPattern+' ',' ');
Documents = tokenizedDocument(string_data);
% Clean the tokenized data
cleanedDocuments = correctSpelling(Documents);
cleanedDocuments = addPartOfSpeechDetails(cleanedDocuments);
cleanedDocuments = removeStopWords(cleanedDocuments);
cleanedDocuments = normalizeWords(cleanedDocuments,'Style','lemma');
cleanedDocuments = erasePunctuation(cleanedDocuments);
end
Uni-gramの作成
次に, 前処理が終わったデータを用いて, 各単語が使用された回数(Uni-gram)を求めます. ここでは, Text Analytics ToolboxのbagOfWords関数を用います.
processed_data = bagOfWords(preprocessed_doc_data);
日常的に使用される単語の削除
得られたUni-gramの中から日常的に使用される単語を削除して, 研究を行う上で必要となる英単語のみを抽出します. その際に, 日常的に使用する単語はNew General Service List Projectにより作成された単語リストを用います. この単語リストには, 先行研究において行われた調査を基に, 日常的に使用される英単語が記載されています. また, 単語リストにも複数の種類があり, 基本的な日常会話で使われる単語が含まれているリストや学校で必ず習う単語が含まれているリスト等があります(各単語リストにどのような単語が含まれているかについては, New General Service List Projectを参照ください). まずは, これらのデータをMATLABにインポートします.
.matファイル作成のためのスクリプト
必要となるファイルは以下です. これらは, New General Service List Projectでダウンロードできます.
- NGSL+1.01+by+band.xlsx
- NGSL+Spoken+1.01.xlsx
- NAWL_1.0_lemmatized_for_research.csv
- TSL_1.1_lemmatized_for_research.csv
- BSL_1.01_lemmatized_for_research.csv
- NDL_1.0_lemmatized_for_research.csv
- FEL_1.0_lemmatized_for_research.csv
%% NGSL
% NGSL Word list file name
NGSL_inputFileName = "NGSL+1.01+by+band.xlsx";
% Read 1st 1000 words in NGSL word list
NGSL1000_table = readtable(NGSL_inputFileName,'Sheet','1st 1000');
% Get Lemmatized word list
NGSL1000 = lower(string(NGSL1000_table.(1)));
fprintf("NGSL 1st 1000 word list includes %d words.\n",length(NGSL1000));
% Read 2nd 1000 words in NGSL word list
NGSL2000_table = readtable(NGSL_inputFileName,'Sheet','2nd 1000');
% Get Lemmatized word list
NGSL2000 = lower(string(NGSL2000_table.(1)));
fprintf("NGSL 2nd 1000 word list includes %d words.\n",length(NGSL2000));
% Read 3rd 1000 words in NGSL word list
NGSL3000_table = readtable(NGSL_inputFileName,'Sheet','3rd 1000');
% Get Lemmatized word list
NGSL3000 = lower(string(NGSL3000_table.(1)));
fprintf("NGSL 3rd 1000 word list includes %d words.\n",length(NGSL3000));
% Read Supplemental words in NGSL word list
NGSLSupplemental_table = readtable(NGSL_inputFileName,'Sheet','Supplemental');
% Get Lemmatized word list
NGSLSupplemental = lower(string(NGSLSupplemental_table.(1)));
fprintf("NGSL Supplemental word list includes %d words.\n",length(NGSLSupplemental));
NGSLAll = [NGSL1000;NGSL2000;NGSL3000;NGSLSupplemental];
fprintf("Total NGSL word list includes %d words.\n",length(NGSLAll));
%% NGSL-S
% NGSL-S Word list file name
NGSL_S_inputFileName = "NGSL+Spoken+1.01.xlsx";
% Read NGSL-S word list
NGSL_S_table = readtable(NGSL_S_inputFileName,'Sheet','Freq');
% Get Lemmatized Word List
NGSL_S = lower(string(NGSL_S_table.(1)));
fprintf("NGSL-S word list includes %d words.\n",length(NGSL_S));
%%NAWL
% NAWL Word list file name
NAWL_inputFileName = "NAWL_1.0_lemmatized_for_research.csv";
% Read NAWL word list
NAWL_table = readtable(NAWL_inputFileName,'ReadVariableNames',false);
% Get Lemmatized Word List
NAWL = lower(string(NAWL_table.(1)));
fprintf("NAWL word list includes %d words.\n",length(NAWL));
%% TOEIC Eord list
% TOEIC Word list file name
TSL_inputFileName = "TSL_1.1_lemmatized_for_research.csv";
% Read TOEIC word list
TSL_table = readtable(TSL_inputFileName,'ReadVariableNames',false);
% Get Lemmatized Word List
TSL = lower(string(TSL_table.(1)(8:end)));
fprintf("TSL word list includes %d words.\n",length(TSL));
%% Business Service Word list
% Business Service Word list file name
BSL_inputFileName = "BSL_1.01_lemmatized_for_research.csv";
% Read Business Service Word list
BSL_table = readtable(BSL_inputFileName,'ReadVariableNames',false);
% Get Lemmatized Word List
BSL = lower(string(BSL_table.(1)(8:end)));
fprintf("BSL word list includes %d words.\n",length(BSL));
% New Dolche Word list file name
NDL_inputFileName = "NDL_1.0_lemmatized_for_research.csv";
% Read Business Service Word list
NDL_table = readtable(NDL_inputFileName,'ReadVariableNames',false);
% Get Lemmatized Word List
NDL = lower(string(NDL_table.(1)));
fprintf("NDL word list includes %d words.\n",length(NDL));
%% FEL Word list
% FEL Word list file name
FEL_inputFileName = "FEL_1.0_lemmatized_for_research.csv";
% Read Business Service Word list
FEL_table = readtable(FEL_inputFileName,'ReadVariableNames',false);
% Get Lemmatized Word List
FEL = lower(string(FEL_table.(1)(8:end)));
fprintf("FEL word list includes %d words.\n",length(FEL));
%% Abbreviation
abbreviations_table = abbreviations;
abbreviation = lower(string(abbreviations_table.(1)));
%% Save
save wordList NGSL1000 NGSL2000 NGSL3000 NGSLSupplemental NGSLAll NGSL_S NAWL TSL BSL NDL FEL abbreviation
そして, Uni-gramに含まれる単語のうち, インポートした単語リストに含まれる単語をText Analytics ToolboxのremoveWords関数を用いて削除します. この際, 英語力の個人差を考慮できるように, 削除する単語のリストを設定できるようにしておきます.
日常的に使用される単語を削除するプログラム
削除する単語リストの設定
% Setting
delete_NGSL1000 = true; % NGSL 1st 1000 wordsを削除する?
delete_NGSL2000 = true; % NGSL 2nd 1000 wordsを削除する?
delete_NGSL3000 = false; % NGSL 3rd 1000 wordsを削除する?
delete_NGSLSupplemental = true; % NGSL Supplemental wordsを削除する?
delete_NGSL_S = false; % NGSL + Spoken wordsを削除する?
delete_NAWL = false; % NAWL wordsを削除する?
delete_TSL = false; % TOEIC wordsを削除する?
delete_BSL = false; % Business service wordsを削除する?
delete_NDL = false; % NDL wordsを削除する?
delete_FEL = false; % Fitness English wordsを削除する?
delete_abbreviation = true; % Abbreviationを削除する?
if (delete_NGSL1000)
processed_data = removeWords(processed_data,NGSL1000,'IgnoreCase',true);
end
% Delete NGSL 2nd 1000 words
if (delete_NGSL2000)
processed_data = removeWords(processed_data,NGSL2000,'IgnoreCase',true);
end
% Delete NGSL 3rd 1000 words
if (delete_NGSL3000)
processed_data = removeWords(processed_data,NGSL3000,'IgnoreCase',true);
end
% Delete NGSL Supplemental words
if (delete_NGSLSupplemental)
processed_data = removeWords(processed_data,NGSLSupplemental,'IgnoreCase',true);
end
% Delete NGSL-S words
if (delete_NGSL_S)
processed_data = removeWords(processed_data,NGSL_S,'IgnoreCase',true);
end
% Delete NAWL words
if (delete_NAWL)
processed_data = removeWords(processed_data,NAWL,'IgnoreCase',true);
end
% Delete TSL words
if (delete_TSL)
processed_data = removeWords(processed_data,TSL,'IgnoreCase',true);
end
% Delete BSL words
if (delete_BSL)
processed_data = removeWords(processed_data,BSL,'IgnoreCase',true);
end
% Delete NDL words
if (delete_NDL)
processed_data = removeWords(processed_data,NDL,'IgnoreCase',true);
end
% Delete FEL words
if (delete_FEL)
processed_data = removeWords(processed_data,FEL,'IgnoreCase',true);
end
% Delete Abbreviation
if (delete_abbreviation)
processed_data = removeWords(processed_data,abbreviation,'IgnoreCase',true);
end
閾値による単語の削除とリストの作成
リストの作成と同時に, 日常的に使用されない単語であっても, あまり重要ではないと考えられる単語の削除を行います. 例えば,
- 単語として文字数が短すぎるものや長すぎるもの
- 論文の中で数回しか使われていない単語
- ある特定の論文のみでしか使われていない単語
- 数字
を削除します.
% Set threshold
minimum_freq = 100;
minimum_range = 15;
minimum_character = 2;
maximum_character = 30;
% Get doc data
Vocabulary = processed_data.Vocaburary';
Freq = full(sum(processed_data.Counts,1))';
Range = zeros(processed_data.NumWords,1);
for ii = 1:processed_data.NumWords
Range(ii) = nnz(processed_data.Counts(:,ii)>0);
end
% Create table
new_wordList = table(Vocabulary,Freq,Range);
% Delete numbers
new_wordList(~isnan(str2double(new_wordList.Vocabulary)),:) = [];
% Delete words by frequency
new_wordList(new_wordList.Freq < minimum_freq,:) = [];
% Delete words by range
new_wordList(new_wordList.Range < minimum_range,:) = [];
% Delete too long and too short words
new_wordList(strlength(new_wordList.Vocabulary) <= minimum_character,:) = [];
new_wordList(strlength(new_wordList.Vocabulary) >= maximum_character,:) = [];
全体スクリプト
ここまで手順をまとめると以下に示すスクリプトができます.
全体スクリプト
clear; close all; clc;
%% Setting
output_fileName = "path/to/output/file";
doc_folder_name = "path/to/input/documents/folder";
% Threshold for deleting words
minimum_freq = 100;
minimum_range = 15;
minimum_character = 2;
maximum_character = 30;
% Delete word list
delete_NGSL1000 = true; % NGSL 1st 1000 wordsを削除する?
delete_NGSL2000 = true; % NGSL 2nd 1000 wordsを削除する?
delete_NGSL3000 = false; % NGSL 3rd 1000 wordsを削除する?
delete_NGSLSupplemental = true; % NGSL Supplemental wordsを削除する?
delete_NGSL_S = false; % NGSL + Spoken wordsを削除する?
delete_NAWL = false; % NAWL wordsを削除する?
delete_TSL = false; % TOEIC wordsを削除する?
delete_BSL = false; % Business service wordsを削除する?
delete_NDL = false; % NDL wordsを削除する?
delete_FEL = false; % Fitness English wordsを削除する?
delete_abbreviation = true; % Abbreviationを削除する?
% Get word list for deleting
load("WordList/wordList.mat");
%% Extract Document
% Get all PDFs
doc_ds = fileDatastore(doc_folder_name, ...
'ReadFcn',@MyReadFcn, ...
"FileExtensions",[".pdf",".txt",".html",".docx"]);
num_PDF = length(doc_ds.Files);
input_text_data = readall(doc_ds);
original_string_data = string(input_text_data);
preprocessed_doc_data = text_preprocess(original_string_data);
data_before_deleting = preprocessed_doc_data;
%% Count words
% Process word information
processed_data = bagOfWords(preprocessed_doc_data);
%% Delete words by importing word list
% Delete by using word lists
% Delete NGSL 1st 1000 words
if (delete_NGSL1000)
processed_data = removeWords(processed_data,NGSL1000,'IgnoreCase',true);
end
% Delete NGSL 2nd 1000 words
if (delete_NGSL2000)
processed_data = removeWords(processed_data,NGSL2000,'IgnoreCase',true);
end
% Delete NGSL 3rd 1000 words
if (delete_NGSL3000)
processed_data = removeWords(processed_data,NGSL3000,'IgnoreCase',true);
end
% Delete NGSL Supplemental words
if (delete_NGSLSupplemental)
processed_data = removeWords(processed_data,NGSLSupplemental,'IgnoreCase',true);
end
% Delete NGSL-S words
if (delete_NGSL_S)
processed_data = removeWords(processed_data,NGSL_S,'IgnoreCase',true);
end
% Delete NAWL words
if (delete_NAWL)
processed_data = removeWords(processed_data,NAWL,'IgnoreCase',true);
end
% Delete TSL words
if (delete_TSL)
processed_data = removeWords(processed_data,TSL,'IgnoreCase',true);
end
% Delete BSL words
if (delete_BSL)
processed_data = removeWords(processed_data,BSL,'IgnoreCase',true);
end
% Delete NDL words
if (delete_NDL)
processed_data = removeWords(processed_data,NDL,'IgnoreCase',true);
end
% Delete FEL words
if (delete_FEL)
processed_data = removeWords(processed_data,FEL,'IgnoreCase',true);
end
% Delete Abbreviation
if (delete_abbreviation)
processed_data = removeWords(processed_data,abbreviation,'IgnoreCase',true);
end
%% Delete words by threshold
% Get doc data
Vocabulary = processed_data.Vocabulary';
Freq = full(sum(processed_data.Counts,1))';
Range = zeros(processed_data.NumWords,1);
for ii = 1:processed_data.NumWords
Range(ii) = nnz(processed_data.Counts(:,ii)>0);
end
% Create table
new_wordList = table(Vocabulary,Freq,Range);
% Delete numbers
new_wordList(~isnan(str2double(new_wordList.Vocabulary)),:) = [];
% Delete words by frequency
new_wordList(new_wordList.Freq < minimum_freq,:) = [];
% Delete words by range
new_wordList(new_wordList.Range < minimum_range,:) = [];
% Delete too long and too short words
new_wordList(strlength(new_wordList.Vocabulary) <= minimum_character,:) = [];
new_wordList(strlength(new_wordList.Vocabulary) >= maximum_character,:) = [];
%% Output
new_wordList = sortrows(new_wordList,'Freq','descend');
writetable(new_wordList,output_fileName);
%% Functions
function textdata = MyReadFcn(filename)
try
% Get Text Data from PDF
textdata = extractFileText(filename);
catch
textdata = '';
end
end
function cleanedDocuments = text_preprocess(string_data)
% Create Tokenized data
string_data = eraseURLs(string_data);
string_data = replace(string_data,' '+digitsPattern+' ',' ');
Documents = tokenizedDocument(string_data);
% Clean the tokenized data
cleanedDocuments = correctSpelling(Documents);
cleanedDocuments = addPartOfSpeechDetails(cleanedDocuments);
cleanedDocuments = removeStopWords(cleanedDocuments);
cleanedDocuments = normalizeWords(cleanedDocuments,'Style','lemma');
cleanedDocuments = erasePunctuation(cleanedDocuments);
end
試しに解析
ここまでに説明した方法を用いて, 単語リストを実際に作ってみました. 今回は私の研究テーマである「点群データを用いた有限要素法解析」に関するオープンアクセス論文をいくつか利用して単語リストを作成してみました.
実験に用いた論文はこちら
- Castellazzi, Giovanni and D'Altri, Antonio Maria and Bitelli, Gabriele and Selvaggi, Ilenia and Lambertini, Alessandro. From Laser Scanning to Finite Element Analysis of Complex Buildings by Using a Semi-Automatic Procedure. Sensors, vol. 15, no. 8, pp. 18360-18380, 2015.
- Moravcik, L'ubos and Vincur, Radko and Rozova, Zdenka. Analysis of the Static Behavior of a Single Tree on a Finite Element Model. PLANTS-BASEL, vol. 10, no. 7, 2021.
- Xu, Wei and Neumann, Ingo. Finite Element Analysis based on A Parametric Model by Approximating Point Clouds. REMOTE SENSING, vol. 12, no. 3, 2020.
- Pepe, Massimiliano and Costantino, Domenica and Garofalo, Alfredo Restuccia. An Efficient Pipeline to Obtain 3D Model for HBIM and Structural Analysis Purposes from 3D Point Clouds. APPLIED SCIENCES-BASEL, vol. 10, no. 4, 2020.
- Bitelli, G. and Castellazzi, G. and D'Altri, A. M. and De Miranda, S. and Lambertini, A. and Selvaggi, I. AUTOMATED VOXEL MODEL FROM POINT CLOUDS FOR STRUCTURAL ANALYSIS OF CULTURAL HERITAGE. XXIII ISPRS Congress, Commission V, International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, vol. 41, no. B5, pp. 191-197. 2016
- Xu, Xiangyang and Yang, Hao. Network method for deformation analysis of three-dimensional point cloud with terrestrial laser scanning sensor. INTERNATIONAL JOURNAL OF DISTRIBUTED SENSOR NETWORKS, vol. 14, no. 11, 2018.
- Barazzetti, L. and Banfi, F. and Brumana, R. and Gusmeroli, G. and Oreni, D. and Previtali, M. and Roncoroni, F. and Schiantarelli, G. BIM FROM LASER CLOUDS AND FINITE ELEMENT ANALYSIS: COMBINING STRUCTURAL ANALYSIS AND GEOMETRIC COMPLEXITY. 3D-ARCH 2015 - 3D VIRTUAL RECONSTRUCTION AND VISUALIZATION OF COMPLEX ARCHITECTURES, International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, vol. 40-5, no. W4, pp. 345-350, 2015.
まずは, 以下の画像に示すように, 論文のPDFファイルをpaperフォルダー内に置きます.
そして, 今回使うスクリプトが格納されたcreate_wordList_for_qiita.mと同じ場所に, .matファイル作成のためのスクリプトにより作成された日常的に使用される単語のリストが格納されているファイルwordList.matを置きます.
また, 今回の実験では削除する単語の閾値を以下のように設定しました.
% Threshold for deleting words
minimum_freq = 10; % 最低でも10回以上使われている
minimum_range = 2; % 最低でも2ファイル以上で使われいている
minimum_character = 3; % 単語は3文字以上のアルファベットで構成される
maximum_character = 50; % 単語は50文字以下のアルファベットで構成される
% Delete word list
delete_NGSL1000 = true; % NGSL 1st 1000 wordsを削除する
delete_NGSL2000 = true; % NGSL 2nd 1000 wordsを削除する
delete_NGSL3000 = true; % NGSL 3rd 1000 wordsを削除する
delete_NGSLSupplemental = true; % NGSL Supplemental wordsを削除する
delete_NGSL_S = true; % NGSL + Spoken wordsを削除する
delete_NAWL = true; % NAWL wordsを削除する
delete_TSL = false; % TOEIC wordsを削除しない
delete_BSL = false; % Business service wordsを削除しない
delete_NDL = false; % NDL wordsを削除しない
delete_FEL = false; % Fitness English wordsを削除しない
delete_abbreviation = true; % Abbreviationを削除する
この結果, 以下のような単語リストが作成されました.
作成された単語リスト
以下の表において,
- Vocaburary: 語彙
- Frequency: 入力ファイル全体で使用された回数
- Range : いくつの入力ファイルにおいて使用されたか
を示す.
| Vocaburary | Frequency | Range |
|---|---|---|
| datum | 156 | 7 |
| building | 139 | 7 |
| threedimensional | 59 | 6 |
| modeling | 59 | 7 |
| bspline | 59 | 4 |
| simplified | 47 | 2 |
| scanning | 44 | 7 |
| detailed | 36 | 7 |
| selfweight | 28 | 3 |
| engineering | 23 | 7 |
| italy | 23 | 4 |
| yang | 19 | 2 |
| felice | 18 | 3 |
| parana | 17 | 2 |
| processing | 16 | 6 |
| geomagnetic | 16 | 3 |
| modulus | 15 | 4 |
| bsplines | 15 | 2 |
| tomography | 15 | 4 |
| castellated | 14 | 3 |
| rennin | 14 | 3 |
| workflow | 13 | 4 |
| cadbased | 13 | 2 |
| polygonal | 12 | 3 |
| midas | 12 | 2 |
| stacking | 12 | 3 |
| related | 11 | 4 |
| barbarize | 11 | 4 |
| advanced | 11 | 4 |
| monitoring | 10 | 4 |
| closed | 10 | 3 |
| twodimensional | 10 | 3 |
| tetrahedral | 10 | 4 |
| axial | 10 | 2 |
考察
今回, MATLABで開発したシステムには研究$^{[1]}$で行われている手動での単語リストの確認作業がないため, 結果として得られた単語リストの中には省略形や固有名詞が残っており, すべての単語が精確であるわけではないことが分かりました. しかし, 私が研究でよく目にする単語も含まれることから, ある程度信用できる単語リストが作成されているのではないかと考えています.
また, 今回の解析では, 7つのファイルを入力した結果を載せましたが, 専門家が選んだ多くのファイルを入力として用いることにより, より有益な単語リストが作成されることが期待できるのではないかと考えています.
結論
本記事では, 大学で研究を行っている学生にとって有益な単語リストを自動的に作成するためのスクリプトの開発とそれを利用した単語リストの作成について紹介しました. 今後は, 自分で実際に使うと同時に, アプリ化等によりもっと使いやすくしていこうと思います.