前提:記事中におけるグラフは、次の頂点 = f(現在の頂点) の形でグラフが定義される、いわゆる functional graph と呼ばれるものを想定しています。
大量のシミュレーションが必要で、愚直に実装すると TLE するけど、実はある部分はループ(閉路)を繰り返すだけで本当にシミュレーションが必要な部分は少ないという問題は時々出ます。同じことを少し前に書きました。その時は「SCC(強連結成分分解)を使うとクールだぜ!」という思いでいたのですが、その後、ダブリング(参考リンク)を覚えると「やはりダブリングが最強では……?」となりました。しかし、私はこの度、新たな結論にたどり着きました。
queue を使う解法こそが最強である、と。
なんだか、しゃくとり法でも同じことを言った気がします。ちなみに、記事を書いた甲斐もあって賛同者も増えているようです(ありがとうございます)。これに続き、この度、私は新しい委員会「ループ(閉路)を一括処理する問題は queue を使おう委員」を発足しようと思います。
なぜループの処理は面倒なのか?
なぜループの処理が面倒なのかというと、「ループにいつ入ったかの検出」「ループサイズの検出」「ループの手前で止まっているかの判定」が必要だからです。これらをすべてカーソル位置基準で考えると、慣れていないと頭がバグります。以前提案した、SCC を使った手法では、これらをステップバイステップで処理できるため、コードの見通しやデバッグのしやすさが向上します。今回提案する queue を使う手法では、外部ライブラリのインクルードも必要なく、よりコードが簡潔になります。
具体的に言うと、
- ループにいつ入ったかの検出を、カーソル位置を気にせず行うことができる
- ループサイズの検出を、カーソル位置を気にせず行うことができる
- ループの手前で止まる場合も自然にシミュレーションできる
というメリットがあります。
具体的な問題とコード
int main()
{
int n;
ll k;
cin >> n >> k;
vector<int> a(n);
cin >> a;
rep(i, n)
{
a[i]--;
}
queue<int> q;
int now = 0;
vector<bool> seen(n);
while (!seen[now])
{
q.push(now);
seen[now] = true;
now = a[now];
}
while (q.front() != now && k)
{
q.pop();
k--;
}
k %= q.size();
while (k--)
{
q.pop();
}
cout << q.front() + 1 << endl;
}
図解
具体的な図で考えてみましょう。
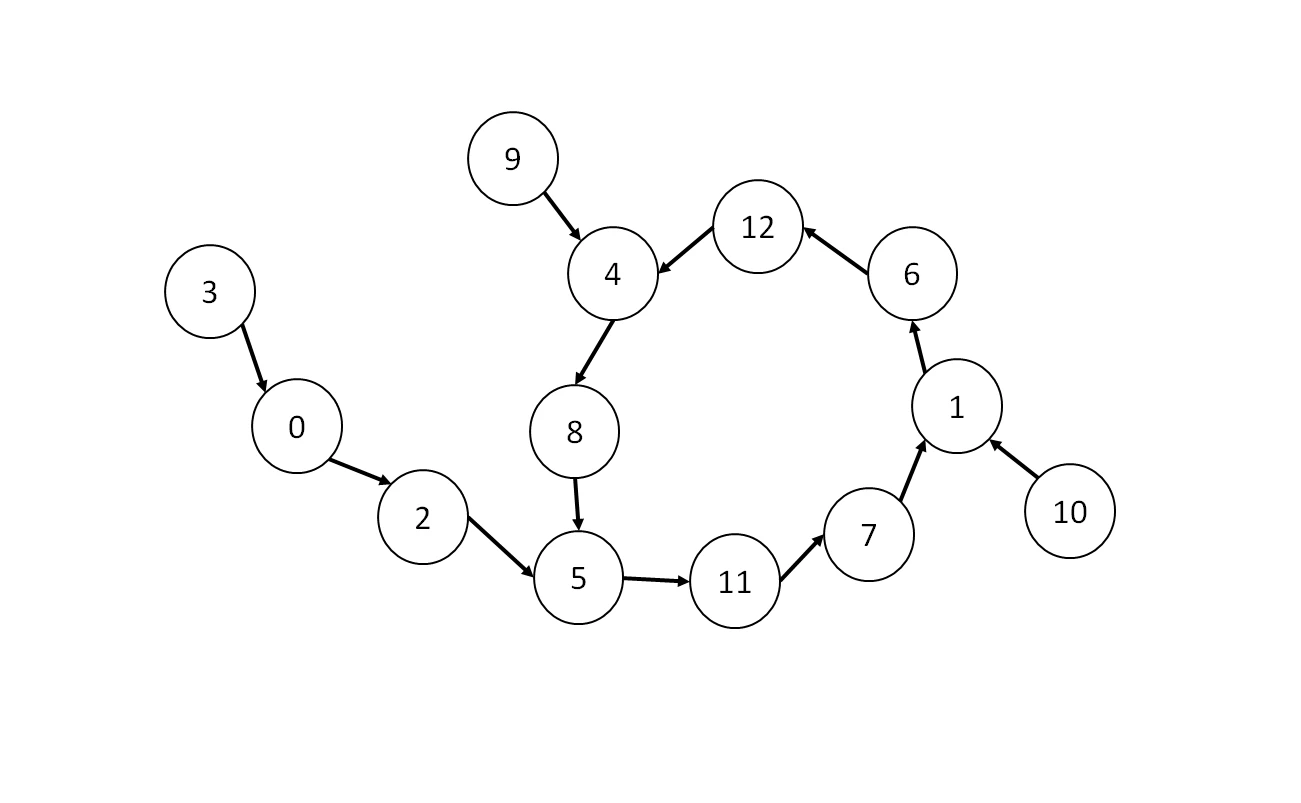
このような有向グラフを考えます。
「0」のノードから始まり、一度訪れた点に再び訪れるまでキューを埋めます。
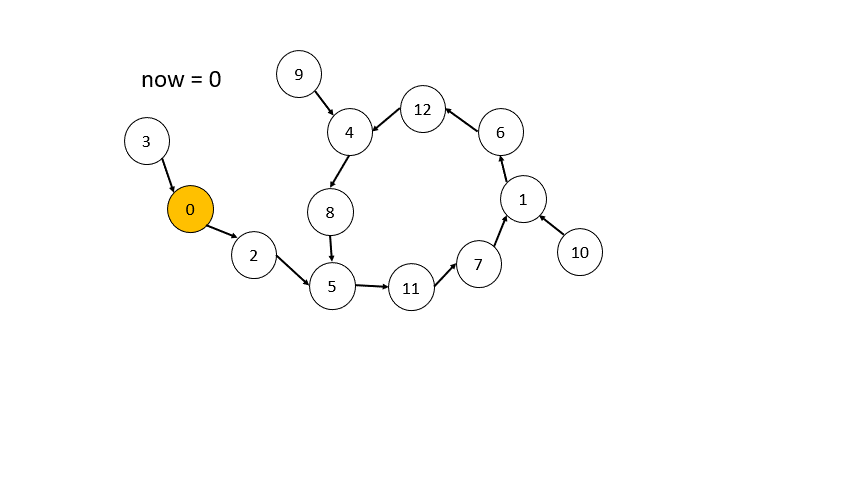
この結果、
now = 5
q = {0,2,5,11,7,1,6,12,4,8}
という、ふたつの情報が得られます。
ループにそもそも入らない場合
移動回数が少なくてそもそもループに入らない場合、例えば 1 回だけ移動する場合を考えます。この場合は、普通に移動回数分だけ queue を pop すれば、残された queue の先頭が答えになります。これはほぼ自明かと思います。

この例では「2」のノードが答えになります。
ループに入る場合
次に、移動回数が多くてループに入る場合を考えます。まず、ループに入る直前までをシミュレーションします。now(=ループの開始地点)が「5」という情報があるので、これが queue の先頭に来るまで、回数を減らしながら pop を繰り返します。

この時、重要な事実として、queue の配列はループの要素だけを含みます。つまり、以下のことが言えます。
- ループに入るまでの導入となる移動回数を使い切ったこと
-
queueの長さがそのままループの長さとなること
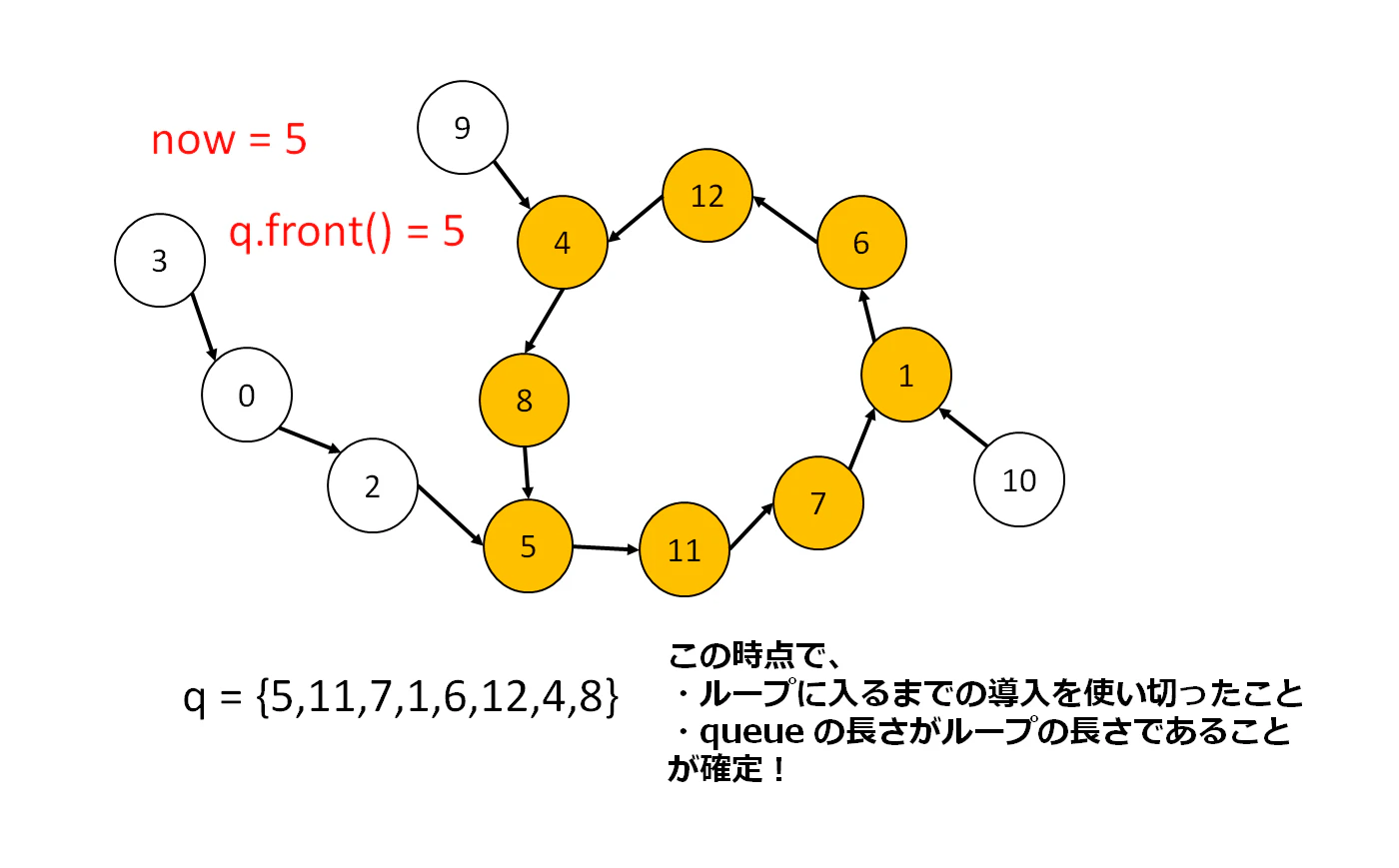
これらの情報を、カーソルの位置や場合分けを一切気にせずに知ることができます。
あとは、単純に操作回数をループ長で割ったあまりをシミュレーションすれば良いだけです。
これらをコードでまとめると
以上のステップは、コードではこれだけの部分で表現することができます。
while (q.front() != now && k)
{
q.pop();
k--;
}
k %= q.size();
while (k--)
{
q.pop();
}
ループに入る場合もそうでない場合も、この操作の後の q.front() が答えになります。シンプル~~。