BOOTHはたくさんの販売アバターが売られていることで知られています。2019/12/09時点で、「3Dモデル」タグには11,527点のモデルがあります。もちろんこれはアバターに関係ない素材なども大量に含まれているので、これがそのままアバターの数という訳ではありません。KingYoSunさんが公開してくださっているVRCモデルデータベースには約1,600体のモデルが登録されていますが、現状これが最も妥当だと思います。
これを、サムネイルの画像から判別することはできないでしょうか。顔を認識させることでできそうですが、顔だけを独立した画像として取得することはできないでしょうか。
スクレイピング
という訳でまずはスクレイピングします。さすがにコピペで動くコードを載せるのはアレなのでURLだけ隠蔽しています。
import urllib.request as ur
from bs4 import BeautifulSoup
import requests
images = []
def img_save(img_url,title):
url = img_url
file_name = str(len(images)) + ".jpg"
labeled_name = str(len(images)) + "___" + title + ".jpg"
response = requests.get(url)
image = response.content
#こっちはただの連番
with open("data/" + file_name, "wb") as o:
o.write(image)
#こっちはタイトルつき
with open("labeled_data/" + labeled_name, "wb") as o:
o.write(image)
def img_search(url_data):
url = url_data
html = ur.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
title = str(soup.title.text)
char_list = ["/","'",'"',"*","|","<",">","?","\\"," - BOOTH"]
for c in char_list:
title = title.replace(c,"")
print(title)
for s in soup.find_all("img"):
if str(s).find("market") > 0:
img_url = s.get("src")
if img_url is not None:
print(img_url)
images.append(img_url)
img_save(img_url,title)
break
def page_access(page_number):
url = page_number
html = ur.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
for s in soup.find_all("a"):
if str(s).find("item-card__title-anchor") > 0:
print (s.get("href"))
url = s.get("href")
img_search(url)
for i in range(1,240):
url = "***載せられないよ***" + str(i)
page_access(url)
こうして得られた結果が以下です。
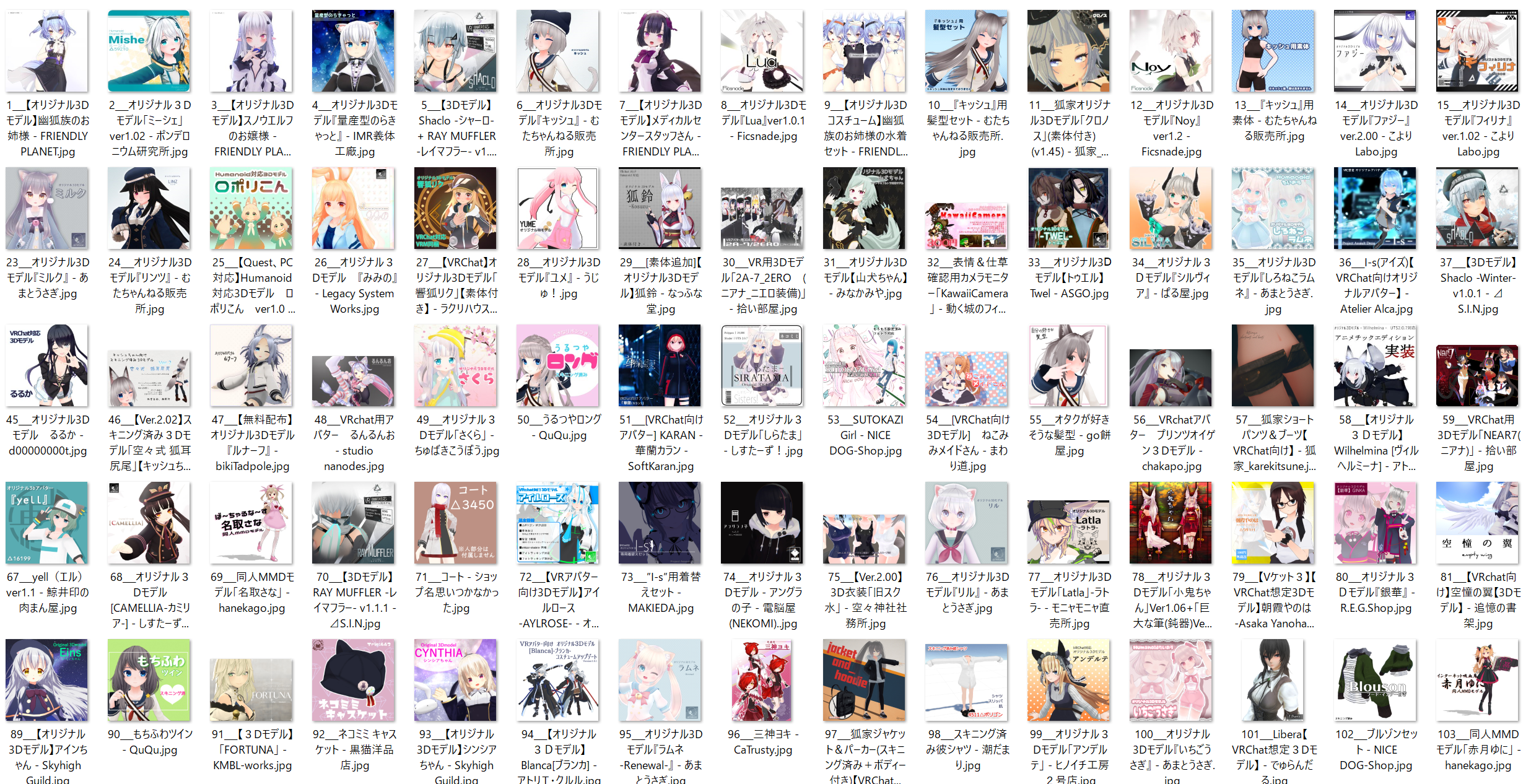
約11,000枚あります。
顔検出
OpenCVのライブラリを使って顔検出をします。
import cv2
sample = 11000
for i in range(sample):
file_name = 'data/' + str(i+1) + '.jpg'
img = cv2.imread(file_name)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
faces = cascade.detectMultiScale(img_gray,minSize=(100, 100))
color = (0, 0, 0)
print(faces)
if len(faces) > 0:
for rect in faces:
cv2.rectangle(img, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=10)
output_path = "face_detect/" + str(i+1) + ".jpg"
cv2.imwrite(output_path, img)
顔検出モデルは別途DLしてローカルに並べる必要があります。上のコードでいうhaarcascade_frontalface_default.xmlですね。OpenCVのgithubからDLできます。
結果は以下です。
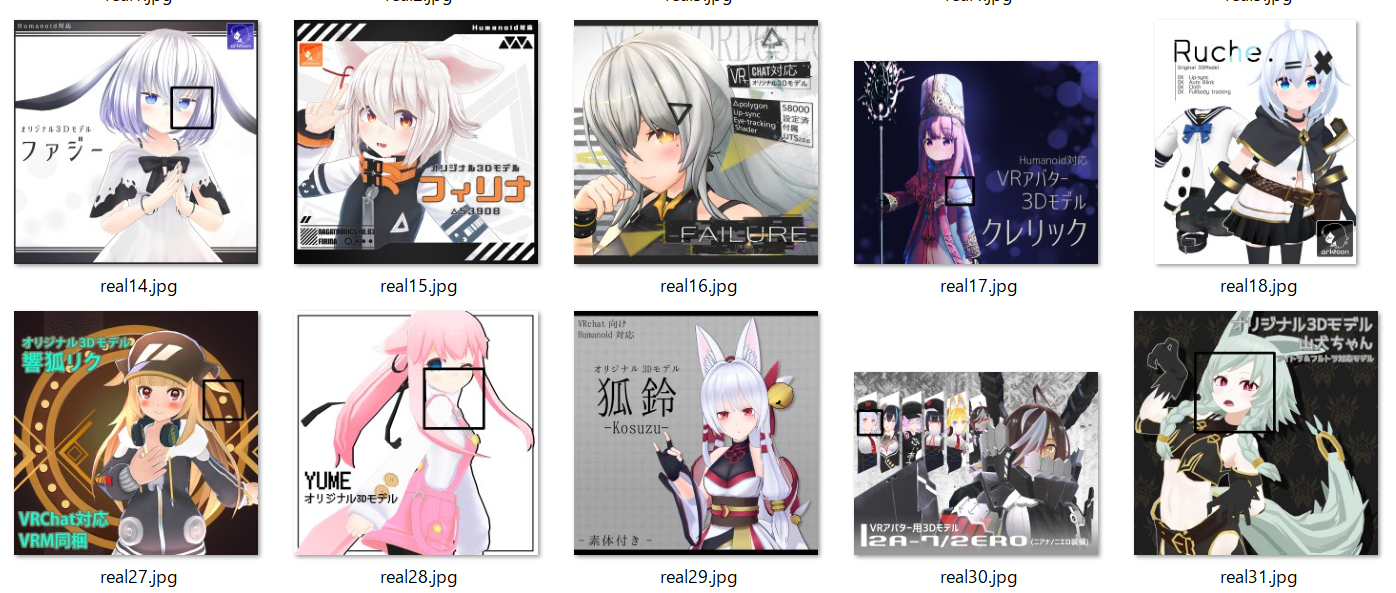
全然精度が良くないよ! 顔を見逃していたり、逆に違うものを誤認識していたりしています。
アニメ顔専用モデル
これは顔検出モデルが実写の顔を想定したものであるためです。探してみるとアニメ顔検出用モデルを作成されている方がいました。神か。それで再実行してみます。
import cv2
sample = 11000
for i in range(sample):
file_name = 'data/' + str(i+1) + '.jpg'
img = cv2.imread(file_name)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("lbpcascade_animeface.xml") #ここが変わっている
faces = cascade.detectMultiScale(img_gray,minSize=(100, 100))
color = (0, 0, 0)
print(faces)
if len(faces) > 0:
for rect in faces:
cv2.rectangle(img, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=10)
output_path = "face_detect/real" + str(i+1) + ".jpg"
cv2.imwrite(output_path, img)
実行結果。
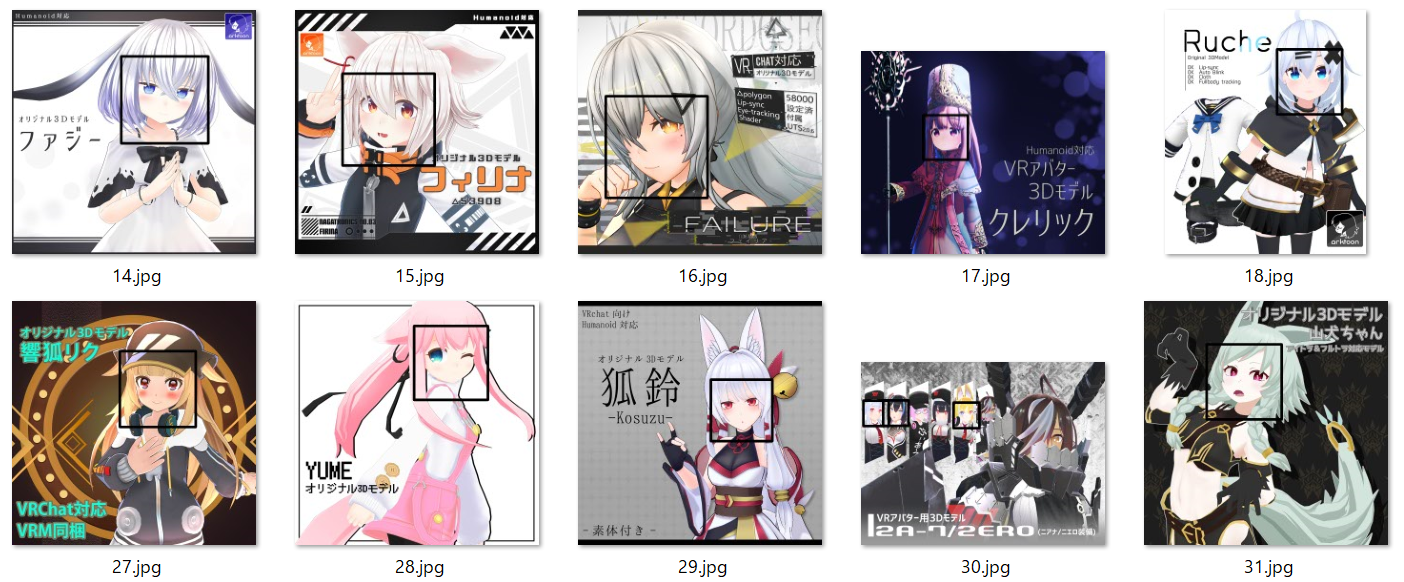
精度高すぎィ!
この検出結果を元にトリミングします。
import cv2
sample = 11000
count = 1
for i in range(sample):
file_name = 'data/' + str(i+1) + '.jpg'
img = cv2.imread(file_name)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
classifier = cv2.CascadeClassifier("lbpcascade_animeface.xml")
faces = classifier.detectMultiScale(img_gray, minSize=(100, 100))
print(faces)
if len(faces) > 0:
for x,y,w,h in faces:
face_image = img[y:y+h, x:x+w]
output_path = 'face_trim/' + str(count) + '.jpg'
cv2.imwrite(output_path,face_image)
count += 1
実行結果。

……アバターが多すぎてめまいがしてきた。
今後の展望
せっかく大量の顔アイコンが得られたので、先日やった手法を用いたらやはり亡霊しかできなかったので、GAN等の手法を使わないと面白い絵は出てこなさそうです。勉強します。

画像は約3,000枚ほど生成されましたが、1つのサムネに複数の顔があったり、結構な数の専用服(つまりサムネには顔がある)が売られていたりするので、実際のアバターはもっと少ないはずです。約半分として、冒頭に述べた約1,600点というのが妥当な数値かなと思われます。文字認識(サムネには売り文句とかも結構かかれています)と組み合わせたら面白そうだなと思いましたが、将来の課題としたいです。
あと、ランダムに顔だけを表示して、大量の販売アバターの中から好みの顔のアバターを検索しやすいWebサービスとか作れたら面白いかもしれないですね。