はじめに
大袈裟なタイトルですね笑
Action Classifierを利用して
withARハッカソン(https://withar.jp/) で「ストレッチを姿勢ごとに自動で数えてくれるアプリ」を作成しました!

ストレッチを自動カウントしてくれるアプリを作りました!
— ひびき@学生AR開発マン (@hibiking3456789) December 20, 2020
コンセプトは
「アプリを起動するだけ」
後はスマホの前でストレッチをするだけで種類ごとにカウントしてくれます!
継続することが大事なストレッチに
このハードルの低さは完璧...!#withARハッカソン#オガトレ pic.twitter.com/ePB6HWGLCI
これを作成するまでにしたことを書いていこうと思います。
自己紹介
静岡の大学3年生のひびきです。
もともとwebプログラミングをしていたんですが、ARに興味が出て半年ほど前から色々勉強しています。
最近は株式会社DENDOHでインターンをさせていただいています!
対象読者
- Action Classifier (coreml, vision)に興味がある人
- swift初心者
作成までにやったこと
1. swift入門
2. coreML触ってみる
3. vison frameworkの基礎を覚える
4. action classifilerのことを調べまくる
5. 実際にアプリを作る
vision自体そんなに日本語の記事がないのでそれも含めて書いていこうと思います!
また初心者ですので間違っている部分があったらご指摘お願いします。
1. swift入門

絶対に挫折しない iPhoneアプリ開発「超」入門
まず初めにこの本を読んで勉強しました。
これでswiftやxcodeの基本的な使い方を覚えます。
注意点としてはswiftUIで解説されているのでuikitの勉強が別で必要になります。
一通り本を読んだ後は慣れるために自分で簡単なアプリを作りました。
2. coreMLを触ってみる
apple公式でcoreMLなどの解説をしています。
https://developer.apple.com/jp/machine-learning/
ここで大雑把に理解したら実際にcoreMLのモデルを見てみます。
サンプルコードも公開されているので何個か動かしてみましょう!
https://developer.apple.com/jp/machine-learning/models/
3. vison frameworkの基礎を覚える
次にvision frameworkを触りました。
vision frameworkとは?
公式ドキュメント
Appleの画像処理をするフレームワークです。
特別な知識がなくてもcoreMLのモデルをiosアプリに組み込んだりできます。
vision frameworkの使い方
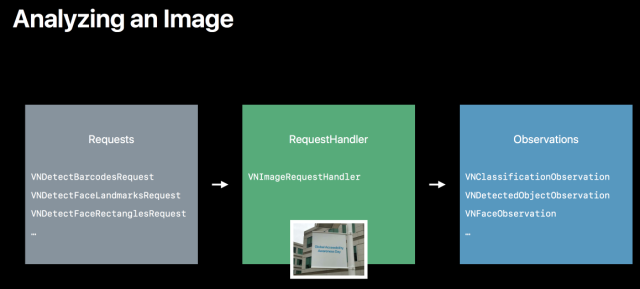
- モデルの読み込み
- Requestの作成
- RequestHandlerの作成
- RequestHandlerの実行、Observation(結果)の取得
使うときはこんな流れになります。
自分はこの流れを理解するまでに結構時間がかかりました笑
順に説明していきます。
1 モデルの読み込み
let model = try! VNCoreMLModel(for: モデル名().model)
または
let model = モデル名()
2 Requestの作成
let request = VNCoreMLRequest(model: model, completionHandler: estimation())
Requestは
「どんなモデルで何を実行するのか?」
っていうものだと解釈しました(ヨクワカラン)
completionHandlerは後述するRequestHandlerを実行した後に呼ばれる関数を指定します。
estimationは関数名です。
3 RequestHandlerの作成
let handler = VNImageRequestHandler(cvPixelBuffer: cuputureImage, options: [:])
RequestHandlerは
「処理したい画像(フレーム?)を保持するやつ」
っていう解釈にしておきます
cuputureImageは現在のフレームを指定します。
4 RequestHandlerの実行、Observation(結果)の取得
do {
try! handler.perform([request])
} catch {
print(error)
}
実行した後はcompletionHandlerで指定したestimation()が実行されます。
func estimation(request: VNRequest, error: Error?) {
guard let observations = request.results as? ["何かしらのObserbationの型"] else { return }
}
また、実行結果はrequest.resultsに入っています。
request.resultsの中身は**[Any]**ですのでモデルにあった型に変換します。
物体検出: [VNRecognizedObjectObservation]
画像分類: [VNClassificationObservation]
テキスト検出: [VNTextObservation]
これで大雑把にvision frameworkの流れを理解したので次はお待ちかねのAction Classifierを使っていきます!
4. Action Classifilerのことを調べまくる
といったもののAction Classifilerって全然日本語の記事がないんですよね...
それどころか日本語どころか英語の記事さえ大してありません...
ここで自分の解決策は
公式ドキュメントとサンプルコードを読みまくる!
- 公式ドキュメント(動画): https://developer.apple.com/videos/play/wwdc2020/10043/
- コード自体の解説は16:30~にしてます
- サンプルコード: https://developer.apple.com/documentation/vision/building_a_feature-rich_app_for_sports_analysis
- バッグ?を投げるゲームです。この中の1つの機能にAction Classifierが使われています。
動画のエクササイズするやつのサンプルコードがあればよかったんですが、なぜか↑のゲームのやつしかなくてめちゃくちゃ大変でした。
今回のことでapple公式ドキュメント&英語と仲良くなれたと思います()
5. 実際にアプリを作る
これは自分がAction Classifierを理解するために作った(おそらく)最小構成のコードです。
バンザイをしているかを判定してくれます。
カメラから現在のフレームを取得するのがAVFoundationよりARkitの方が楽だったのでARkitで書いています。
モデルの作成
CreateMLでスポーツビデオのAction Classifierをつくる(書きかけ)
Action Classifierのモデルの作り方はMLBoy だいすけさんが詳しい説明を書いてくれています。
自分も参考にさせていただきました。ありがとうございます!
サンプル全文
import UIKit
import SceneKit
import ARKit
import CoreML
import Vision
class ViewController: UIViewController, ARSCNViewDelegate {
@IBOutlet var sceneView: ARSCNView!
// ラベル背景
@IBOutlet weak var labelBack: UIView!
// 現在のポーズを表示するラベル
@IBOutlet weak var poseLabel: UILabel!
// 信頼度表示するラベル
@IBOutlet weak var confidenceLabel: UILabel!
// モデルの読み込み
let banzaiClassifier = banzai()
// モデルを作成した時の予測ウィンドウのサイズ。小さくすると予測頻度が上がる(良いのかはわからない)
var windowSize = 60
// 60ポーズ(フレーム)を保存する
var posewindows: [VNRecognizedPointsObservation?] = []
override func viewDidLoad() {
super.viewDidLoad()
sceneView.delegate = self
labelBack.alpha = 0.5
labelBack.backgroundColor = UIColor.gray
// 配列の初期化
posewindows.reserveCapacity(windowSize)
}
func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) {
// 現在のフレームを取得
guard let cuputureImage = self.sceneView.session.currentFrame?.capturedImage else {
return
}
// Requestの作成
let request = VNDetectHumanBodyPoseRequest(completionHandler: estimation)
// ReqesuHandlerの作成
let handler = VNImageRequestHandler(cvPixelBuffer: cuputureImage, options: [:])
do {
// RequestHandlerの実行
try handler.perform([request])
} catch {
print(error)
}
}
func estimation(request: VNRequest, error: Error?) {
// 実行結果を取得
guard let observations = request.results as? [VNRecognizedPointsObservation] else { return }
if posewindows.count < 60 {
posewindows.append(contentsOf: observations)
} else {
do {
// フレームを多次元配列に変換する
let poseMultiArray: [MLMultiArray] = try posewindows.map { person in
guard let person = person else {
// 人が検出されない場合
let zero:MLMultiArray = try! MLMultiArray(shape: [3, 100, 100], dataType: .float)
return zero
}
return try person.keypointsMultiArray()
}
// モデルに入力できるようにする。 (単一の配列に連結?)
let modelInput = MLMultiArray(concatenating: poseMultiArray, axis: 0, dataType: .float)
// モデルの予測
let predictions = try banzaiClassifier.prediction(poses: modelInput)
DispatchQueue.main.sync {
// ラベル名
poseLabel.text = predictions.label
// 信頼度 (切り捨て)
let confidence = floor(predictions.labelProbabilities[predictions.label]! * 100)
confidenceLabel.text = "\(confidence)%"
}
// 配列を初期化
posewindows.removeFirst(windowSize)
} catch {
print(error)
}
}
}
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
let configuration = ARWorldTrackingConfiguration()
sceneView.session.run(configuration)
}
override func viewWillDisappear(_ animated: Bool) {
super.viewWillDisappear(animated)
sceneView.session.pause()
}
}
一部コードの説明をしていきます。
モデルの読み込み
// モデルの読み込み
let banzaiClassifier = banzai()
ここでモデルを読み込んでいます。
例えば「jump.mlmodel」というモデルをcreatemlで作ったら、
let jumpClassifier = jump()
で読み込めます。
posewindowsの準備
// 60ポーズ(フレーム)を保存する
var posewindows: [VNRecognizedPointsObservation?] = []
Action Classifierは過去60ポーズ(フレーム?)を1つの入力として予測を実行します。
つまり、この配列に60ポーズが埋まったら予測を実行できます。
if posewindows.count < 60 {
// 配列に追加
posewindows.append(contentsOf: observations)
} else {
// 60ポーズ埋まったら実行される
〜〜〜
}
サンプルの60行目あたり
カメラから現在のフレームを取得
func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) {
// 現在のフレームを取得
guard let cuputureImage = self.sceneView.session.currentFrame?.capturedImage else {
return
}
〜〜〜
}
func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) {}
は毎フレーム呼ばれるarkitのメソッドです。
そこからself.sceneView.session.currentFrame?.capturedImageで現在のフレームを取得します。
モデルに入力する準備
// フレームを多次元配列に変換する
let poseMultiArray: [MLMultiArray] = try posewindows.map { person in
guard let person = person else {
// 人が検出されない場合
let zero:MLMultiArray = try! MLMultiArray(shape: [3, 100, 100], dataType: .float)
return zero
}
return try person.keypointsMultiArray()
}
// モデルに入力できるようにする。 (単一の配列に連結?)
let modelInput = MLMultiArray(concatenating: poseMultiArray, axis: 0, dataType: .float)
ここはwwdc2020のAction Classifierの動画
https://developer.apple.com/videos/play/wwdc2020/10043/
18:00〜あたりからの部分を参考にしています。
keypointsMultiArray()で多次元配列に変換しているようです。
ここに関しては自分もまだ勉強中です笑
モデルの予測
// モデルの予測
let predictions = try banzaiClassifier.prediction(poses: modelInput)
DispatchQueue.main.sync {
// ラベル名
poseLabel.text = predictions.label
// 信頼度 (切り捨て)
let confidence = floor(predictions.labelProbabilities[predictions.label]! * 100)
confidenceLabel.text = "\(confidence)%"
}
モデルの予測は**banzaiClassifier.prediction(poses: modelInput)**で実行します。
予測結果は
- ラベル名: predictions.label
- 信頼度 : predictions.labelProbabilities[predictions.label]!
で取得できます。
サンプルを動かしてみる

Action Classifierで
— ひびき@学生AR開発マン (@hibiking3456789) December 24, 2020
「バンザイを認識」
してみました!
バンザイして喜んでる時に何かエフェクトとかつけられたら面白そう#CoreML #AR #Vision #Apple pic.twitter.com/khwpmtObe5
さいごに
swiftを勉強時初めて1ヶ月ちょい、結構色んなことを覚えました。
ARをスマホで開発するならarkit/arcoreなどのようなAR用SDKでやるものだと思ってましたが、画像処理系の機械学習も組み合わせることでより面白い物が作れることがわかりました。
今は機械学習部分をcoreMLに頼っていますが、そのうち勉強してゴリゴリtensorflowとかopencvを書いてみたいですね!
もちろんcoreMLで他に試してみたいものもいっぱいあります笑!
あとgithubにサンプルコードをあげてあります
https://github.com/hibiking-0422/actionClassFilerTest/tree/main