今さらながら、拙作のオープンソースWindowsアプリに、パスワード強度メーターでも導入してみようかと検討していたところ、Dropbox社製のオープンソース zxcvbn を見つけ、その仕組みを知るついでに解説ブログ記事を訳してみました。
そのページは、コチラです。
https://blogs.dropbox.com/tech/2012/04/zxcvbn-realistic-password-strength-estimation/
実装例(JavaScript)
実際に実装した例は、以下の別の投稿記事に詳しく書いてあります。
パスワード強度推定メーター(zxcvbn.js)を実装してみる
https://qiita.com/hibara/items/fbd26704b8ab7fd74fb1
zxcvbn ってなに?
Dropbox社が開発した、ユーザーによって入力されたパスワード文字列の強度(クラックされやすいか否か)を推定するオープンソースライブラリ。もとはJavaScript(CoffeeScript)で、GitHubに公開されています。汎用性が高く、他の言語にもフォークされていて、他の言語では、
- zxcvbn-python (Python)
- zxcvbn-cpp (C/C++/Python/JS)
- zxcvbn-c (C/C++)
- zxcvbn-rs (Rust)
- zxcvbn-go (Go)
- zxcvbn4j (Java)
- nbvcxz (Java)
- zxcvbn-ruby (Ruby)
- zxcvbn-js (Ruby [via ExecJS])
- zxcvbn-ios (Objective-C)
- zxcvbn-cs (C#/.NET)
- szxcvbn (Scala)
- zxcvbn-php (PHP)
- zxcvbn-api (REST)
- ocaml-zxcvbn (OCaml bindings for zxcvbn-c)
などあります。
詳しくはググってください。解説記事は山ほど出てきます。
ただ、もうね・・・結論から言うと、
- 記事は、2012年のもので超古い
- 辞書リストはアメリカ英語の用法とスペルに偏っていて、姓名なども米国の国税調査に偏っている
- つまり、日本人向けにカスタマイズされていない(別途日本人向けの辞書セットを用意した方が良いかも)
- けっきょく日本語をパスワードにすれば最強なんじゃね?
ブログ記事の「結論」にほぼ書かれていた。先に気づけよ>自分。。。
まあでも、せっかくなのでシェアしておきます。誤訳、補足などあれば、コメントいただけると嬉しいです。
zxcvbn: 現実的なパスワード強度の推定(全訳)
ここ数カ月間、私は出会ったほぼすべてのサインアップフォームにパスワード強度メーターがありました。パスワード強度メータが流行っているようです。

ここで質問:このメーターは実際にユーザーのアカウントを保護するのに役立っているのか? Webセキュリティ上の他の分野ほど重要ではありません。その他の重要な部分をざっと言えば、
- スロットリングまたはCAPTCHAによるオンラインクラッキングの防止
- ユーザー固有のsaltを持つ適切なslow hashを選択することによって、オフラインクラッキングを防止する
- パスワードハッシュの保護
それらを免責事項としたとしても――はい。パスワード強度メーターが役立つ可能性があると確信しています。マーク・バーネットの2006年の本、"Perfect Passwords: Selection, Protection, Authentication(完璧なパスワード:選択、保護、認証)"には、さまざまな漏洩によって流出した数百万のパスワードの出現頻度を数えたもので、9人に1人がこの上位500のリストに載っているパスワードを使っていました。これらのパスワードは、実際に厄介なものを含んでいます。「password1」や「compaq」「7777777」「merlin」「rosebud」など。バーネットの、より最近の研究によれば、600万のパスワードのうち、実に99.8%という馬鹿げた数のパスワードが、上位1万のリストに入っていて、その内、91%が上位1,000のリストに入っています。その方法論とバイアスは重要な良い形容です--たとえば、これらのパスワードのほとんどは、(いろいろな場所で)クラックされたパスワードハッシュから来ているので、リストは最初から解読可能なパスワードに偏っていることが分かります。
これらは、ただ実際に簡単で推測しやすいパスワードです。残りは、かなりの割合でまだ中程度のオンライン攻撃の影響を受けやすいほど十分に予測可能であると断言します。ですので、ダイレクトなフィードバックを通してより強度なパスワードの決定を推奨することで、これらのパスワード強度メーターは役立つと思っています。しかし現状、いくつかのクローズドなソースにおいて、推奨されるパスワードのほとんどに問題があると考えています。ここで理由を述べます。
パスワードの強度は、ビットのエントロピーの測定により、ベストなものとなります。つまり、パスワードのスペースを半分入れることができる回数です。だいたいの強度の計算は下記のように行います:
# n: パスワードの長さ
# c: パスワードのカーディナリティ:記号スペースのサイズ
# (英字26文字の小文字だけ、大文字+小文字+数字を混ぜた62文字)
entropy = n * lg(C) # 基本 2 log
この総当たり攻撃的な分析は、文字、数字、記号を使ったランダムな書き方を選択する人々にとっては正しいといえます。しかし、いくつかの例外(1Password / KeePass への敬意を込めて)があるものの、もちろん人が選択するパターンとしては、辞書の単語、qwertyや、asdf、zxcvbnといった空間的なパターン、aaaaaaaaのような繰り返し、abcdef、654321のような連続したものや、上記を組み合わせたものがあります。大文字を含むパスワードでは、その最初の文字が大文字になる可能性が高いです。数字と記号であっても予測可能なこともあります。いわゆるl33t speakは「3がe」で「0が、o」「@は、4またはa」と替えるもの、また、年号、日付、郵便番号などがあります。
結果として、単純化された強度推定は悪いアドバイスを与えます。共通のパターンをチェックすることなく、数字や記号を奨励することは、コンピュータをクラックすることをわずかに難しくするかもしれませんが、まだ人間にとって覚えるには、もどかしいくらい難しいかもしれません。ここに、xkcdサイトから画像を貼り付けておきましょう。
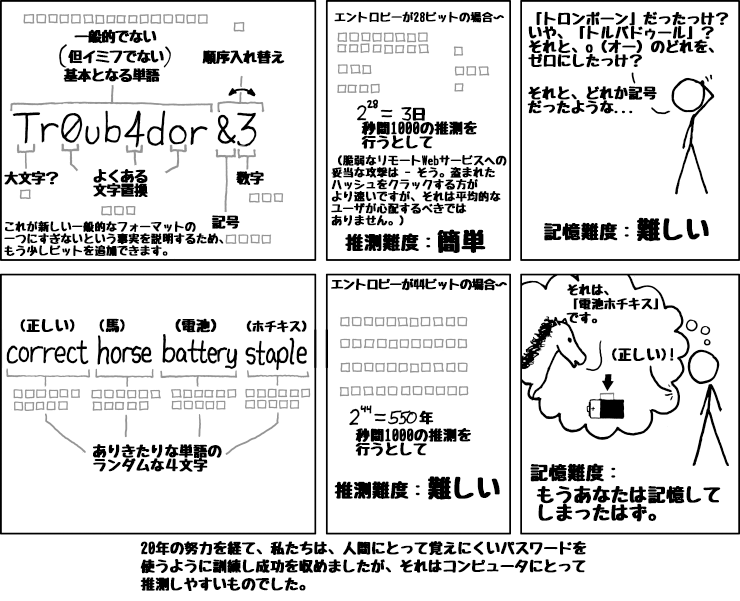
私は、独自の「Dropboxのハックウィーク」プロジェクトとして、オープンソースの強度推定ツールを作るのは面白そうだと思いました。それは、よくあるパターンを判断したりするのは、もちろんのこと、「正しい馬電池ホチキス」のような十分複雑なパスフレーズが不当な扱いを受けないようなことがないようなものを。今は、実際の動作をdropbox.com/registerで見ることができますし、GitHubで使用できるようになっています。いくつかの強度推定の例を実験、デモで確認できます。
下の表は、zxcvbnから他の強度推定を比較したものです。ポイントは、他のもの(パスワードポリシーは非常に主観的です)を無視することではありません。むしろ、zxcvbnがどのように異なるのかをよりよく理解するためです。
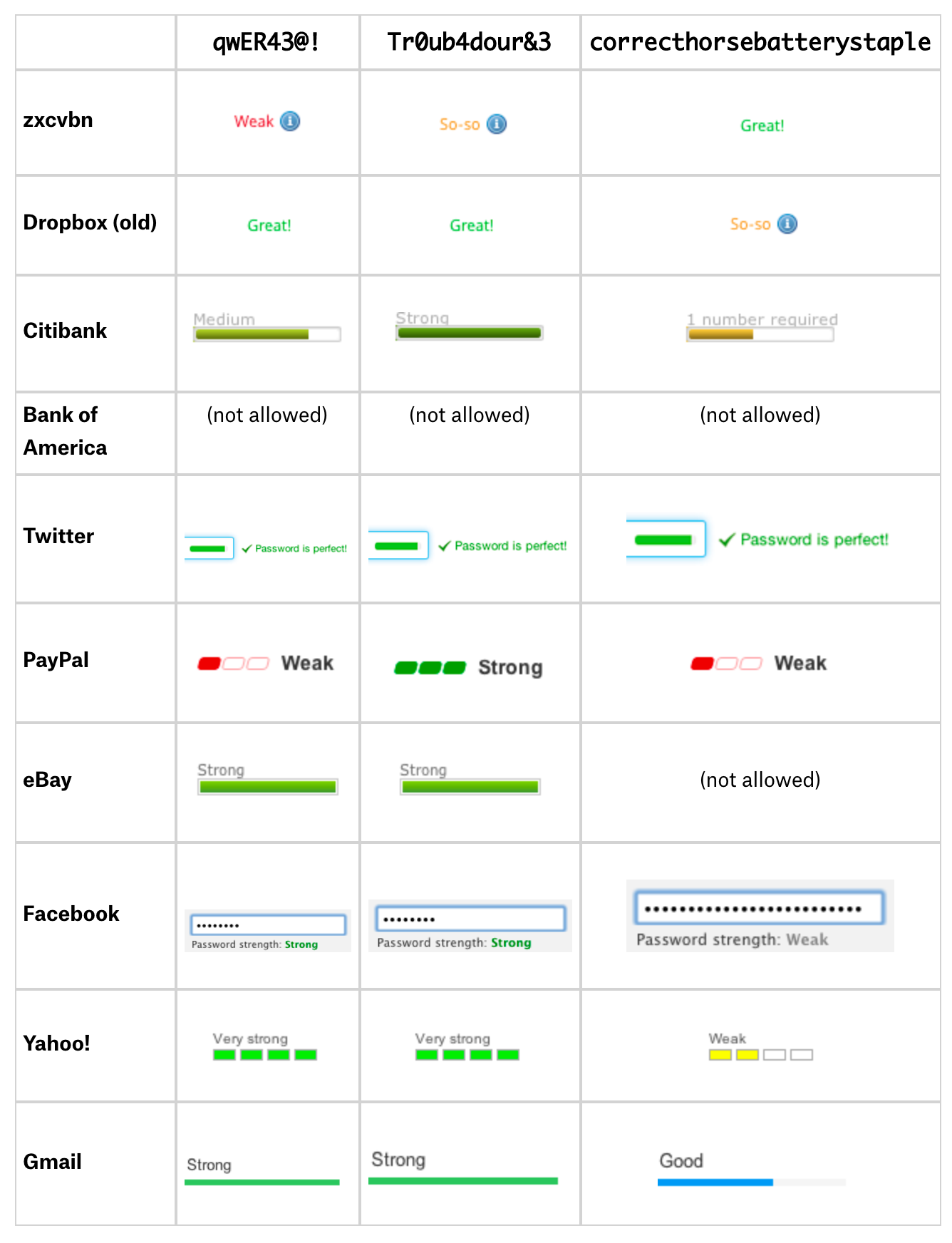
いくつかメモ:
- 2012年4月3日にこれらのスクリーンショットを撮りました。テーブルに収まるようにgmailの申し込みフォームからバーを切り取る必要がありました。相対幅の違いはフォーム自体よりもとても大きくなりました。
- zxcvbn は、correcthorsebatterystapleを3の最強のパスワードと見なします。残りは、それを最も弱いと見なすか、または却下されます。 (Twitterはそれぞれにほぼ同じ強度スコアを与えますが、細かく見れば、スコアはわずかに異なります。)
- zxcvbn は、qwER43@! は、短い QWERTY パターンと見るので、弱いと見なします。
- PayPal の強度推定は、qwER43@! を弱いと見なしますが、aaAA11!! を強いと判定します。
- バンクオブアメリカは、20桁以上の文字をパスワードにすることを許可しません。つまり、correcthorsebatterystaple は認められません。パスワードには、いくつかの記号を含めることができますが、& または、! だけで、この2つ以外のパスワードは認められません。eBay もまた、20文字以上のパスワードを許可してません。
- 私が試した、これらのうちのいくつかの強度推定は、単純なものが使われているように思われます。そうでなければ、correcthorsebatterystaple は、その文字列の長さから高い強度を示すはずです。Dropbox では、固有の小文字や、大文字、数字、記号のそれぞれが、それぞれのちがうグループの先頭文字が現れるまでのポイントを加えていました。それはまた一般的なパスワード辞書に対してチェックされたものですが、これはほとんど総当たり攻撃のためだけの措置と同じです。私は他の強度推定の背後にある詳細は分かりませんが、スコアリングチェックリストは他の一般的なアプローチです(これもまた多くのパターンでチェックされません)。
- 私は二つ目の基本単語として、Troubadour を選びましたが、xkcd サイトの画像にある Troubador では起きていない。この単語は、あまり一般的ではないスペルです。
インストール
zxcvbn の動作には依存するものはなく、ie7+/opera/ff/safari/chrome 上で動作します。一番良い方法は、あなたのページにそれを以下のように加えることです。
<script type="text/javascript" src="zxcvbn-async.js">
</script>
zxcvbn-async.js は、たった350バイトです。window.load で、あなたのページがロードされ、レンダリングされた後に、それは、zxcvbn.js をロードします。大きいもので680kで(gzip圧縮されたものでは320k)です。そのほとんどは、辞書の容量です。このスクリプトサイズが問題になるとは思いませんでした。なぜならパスワードは、たいていサインアップフォームはユーザーが入力する最初のことではないからで、ロードする時間がたっぷりあります。ここに、クロスブラウザでの非同期スクリプトローディングの広範囲に渡る概要があります。
zxcvbn は、グローバルな名前空間に一つの関数を書き加えます。
zxcvbn(password, user_inputs)
引数の一つにパスワードが必須で、結果オブジェクトを返すようになっています。その結果には、いくつかのプロパティを含みます。
result.entropy # ビット
result.crack_time # 実際のクラック推定時間(秒数)
result.crack_time_display # 同じクラック時間。より扱いやすい形式で:
# "instant", "6 minutes", "centuries", などなど。
result.score # もしクラック時間がそれ以下の場合、0, 1, 2, 3 or 4
# 10**2, 10**4, 10**6, 10**8, Infinity.
# (強度バー表示を行う場合に役立つ)
result.match_sequence # 検出されたパターンはエントロピーの計算に使用されます。
result.calculation_time # 答えの計算に要した時間(ミリ秒),
# たいていの場合は、ほんの数ミリ秒。
オプションの optional user_inputs 引数は、zxcvbn がその内部辞書に追加したい文字配列です。これは、どんなリストであってもかまいませんが、名前やE-mailのようなフォームの他のフィールドから入力された内容のためにあります。そのようにしてユーザーの個人情報を含むパスワードは、非常に弱くなる可能性があります。このリストは、サイト固有の語彙にも適しています。たとえば私たちで言えば、dropboxという文字列を含みます。
zxcvbnは、CoffeeScriptでで書かれています。zxcvbn.jsと、zxcvbn-async.jsは、closureでコンパイルされ、解読できないようになっていますが、もしあなたが展開された zxcvbnがよく、私たちにプルリクエストを送ってくれるのなら、READMEにある開発環境のセットアップに従って行ってください。
この記事の残りは、zxcvbn のデザインについての詳細を書いていきたいと思います。
モデル
zxcvbn は、3つのステージから成っています。マッチ、スコア、そしてサーチです。
- マッチ は、検知できるすべてのパターン(可能な限り重なったもの)を列挙します。現行の zxcvbn は、いくつかの辞書(英単語、名前、姓、バーネットによる10,000共通パスワードリスト)、空間的なキーボードパターン(QWERTY、 Dvorak や、キーパッドパターン)、繰り返し(aaa)、連続文字(123, gfedcba)、1900から2019の年号や、日付(3-13-1997, 13.3.1997, 1331997)に対して、マッチングを行います。すべての辞書において、大文字や共通した l33t 置換などを含みます。
- スコア は、攻撃者がそのパターンを知っていると仮定して、パスワードの他の部分とは無関係に、一致した各パターンのエントロピーを計算します。シンプルな例でいえば、rrrrr です。この場合、攻撃者は、小文字で始まる1から5までの長さの反復をすべて繰り返す必要があります。
entropy = lg(26*5) # 約7ビット
- サーチ は、「オッカムの剃刀」の考えが入っています。できるかぎり一致するフルセットを与えられとき、サーチはもっともシンプルな(もっとも低いエントロピーの)一致しない連続性を探します。たとえば、もしパスワードが damnation だとして、それは2つの単語として分析できるかもしれないし、dam と nation そのどちらか一つが、分析できるかもしれません。重要なのは、一つとして分析されることです。なぜなら辞書を使った攻撃者は二つの単語の前に、長い一つの単語としてクラックするからです。(余談ですが、重なるパターンもまた、childrens-laughter.com の、ハイフンがないような悲劇的なドメイン名を登録する主な要因です。)
サーチは、モデルの核心です。私は、そこからスタートして、遡るように作業していきたいと思います。
- 最小限のエントロピーサーチ
zxcvbn は、その単語を構成するパターンの合計値になるまでのパスワードのエントロピーを計算します。マッチするパターンの間にあるどのような不一致であっても、総当たり攻撃的な「パターン」として扱います。そしてそのパターンはまた、総エントロピーの構成に役立ちます。たとえば、
entropy("stockwell4$eR123698745") == surname_entropy("stockwell") +
bruteforce_entropy("4$eR") +
keypad_entropy("123698745")
パスワードのエントロピーが、それらの部分の合計であることが大きな前提です。しかしながら、それは保守的な前提です。「エントロピーの調整」--数や一つ一つの配置からくるエントロピー--を無視して、zxcvbn は、パスワード構造を自由に渡すことによって、わざと過小評価するようにしています。つまり、攻撃者がその構造をすでに知っていると仮定しています(たとえば、名字の総当たりキーパッド攻撃)。そして、そこから彼らが何度も繰り返す必要があると推測するかを計算します。これは複雑な構造に対して、かなりの過小評価です。correcthorsebatterystaple つまり、単語-単語-単語-単語を考慮して、L0phtCrack あるいは、John the Ripper のようなプログラムを走らせる攻撃者は、単語-単語-単語-単語の前に、おおむね最初は多くのより単純な構造、単語や、単語-数字、単語-単語のようなものを試します。私は、以下の3つの理由から問題ないとしています。
- 構造的なエントロピーの適切なモデルを定式化することは困難です。統計上、私は人々がどのような構造を最も選択しているのか知りません。だから、私はむしろ安全で、過小評価したいと考えます。
- 複雑な構造の場合、「優れた」評価を得るには、断片の合計だけで十分な場合があります。たとえば、correcthorsebatterystaple のような、単語-単語-単語-単語構造をたとえ知っていたとしても、攻撃者は何世紀にもわたってそれをクラックする必要があるしょう。
- ほとんどの人々は、複雑なパスワード構造を使っていません。構造を無視することは、一般的なケースでは、ほんの数ビットで過小評価されるだけです。
この異常な仮定で、ここではCoffeeScriptの効率的な動的プログラミングアルゴリズムで、重複しない最小の一致シーケンスを見つけるためのものです。それは、一致する候補(重複する可能性)を mとして、パスワードの長さ(n)に対して、かかる時間 O(n・m)として、動作します。
# matches: パスワードが一致するすべての候補配列
# 最初のインデックス(match.i)と最後のインデックス(match.j)を含んだパスワードを持つ候補。
minimum_entropy_match_sequence = (password, matches) ->
# たとえば、26文字の小文字だけ
bruteforce_cardinality = calc_bruteforce_cardinality password
up_to_k = [] # 最小値のエントロピーがk。
backpointers = [] # kに一致するオプションのシーケンスで、
# 最後に一致するものを持つ(match.j == k)。
# nullは、シーケンスが総当たり文字で終了することを意味します。
for k in [0...password.length]
# 叩き出すシナリオを開始:
# k-1にある総当たり攻撃文字から最小値のエントロピーシーケンスを追加。
up_to_k[k] = (up_to_k[k-1] or 0) + lg bruteforce_cardinality
backpointers[k] = null
for match in matches when match.j == k
[i, j] = [match.i, match.j]
# もし最小値のエントロピーから i-1 まで + この候補のエントロピーが j にある今の最小値より以下かを見る
candidate_entropy = (up_to_k[i-1] or 0) + calc_entropy(match)
if candidate_entropy < up_to_k[j]
up_to_k[j] = candidate_entropy
backpointers[j] = match
# 逆方向へ最適なシーケンスをデコードする
match_sequence = []
k = password.length - 1
while k >= 0
match = backpointers[k]
if match
match_sequence.push match
k = match.i - 1
else
k -= 1
match_sequence.reverse()
# 総当たり攻撃の「matches」に対してパターン一致の間に空白を埋めて、
# マッチシーケンスが完全にパスワードをカバーするようにします。
# すべての隣接する match1、match2に対して、match1.j == match2.i - 1
make_bruteforce_match = (i, j) ->
pattern: 'bruteforce'
i: i
j: j
token: password[i..j]
entropy: lg Math.pow(bruteforce_cardinality, j - i + 1)
cardinality: bruteforce_cardinality
k = 0
match_sequence_copy = []
for match in match_sequence # 真ん中にある隙間を埋める
[i, j] = [match.i, match.j]
if i - k > 0
match_sequence_copy.push make_bruteforce_match(k, i - 1)
k = j + 1
match_sequence_copy.push match
if k < password.length # 最後の隙間を埋める
match_sequence_copy.push make_bruteforce_match(k, password.length - 1)
match_sequence = match_sequence_copy
# または、めったに発生しないケースで 0 は、空のパスワード''です
min_entropy = up_to_k[password.length - 1] or 0
crack_time = entropy_to_crack_time min_entropy
# 最後の結果オブジェクト
password: password
entropy: round_to_x_digits min_entropy, 3
match_sequence: match_sequence
crack_time: round_to_x_digits crack_time, 3
crack_time_display: display_time crack_time
score: crack_time_to_score crack_time
backpointers[j] には、パスワードの文字位置 j にこのシーケンスの終わりにある一致したものを保持しています。あるいは、もしそのシーケンスが一致するようなものを含まない場合は、null が入っています。典型的な動的プログラミングでは、最適なシーケンスを構成するには、最後から始めて逆方向へ作業する必要があります。
特に、これはユーザーの入力に応じてブラウザ側で実行されているため、効率が重要です。何かを稼働させるために、私はオーバーラップしない可能性のあるサブセットごとに合計を計算するという、よりシンプルな O(2m)アプローチから始めましたが、それはすぐに遅くなりました。現在のところ、zxcvbn はほとんどのパスワードに対しても数ミリ秒以上かかることはありません。かなりおおよその概算として、2.4 GHz Intel Xeon 上で動作する Chrome で走らせたところ、 correcthorsebatterystaple は平均約3msかかりました。coRrecth0rseba++ery9/23/2007staple$ については、平均約12msかかりました。
脅威モデル:エントロピーからのクラック時間
エントロピーは直感的ではありません。もし 28ビットだとして、それが強いのか弱いのかをどうやって私は知ることができるでしょうか? エントロピーから正確な推定クラック時間を得るまでどうすればいいでしょうか? これは脅威モデルの形でより多くの仮定を必要とします。以下で仮定しましょう。
- パスワードは、ソルトによるハッシュ化された状態で保存されています。それも実行不可能なレインボー攻撃を使いユーザー毎にランダムなソルトを付与します。
- 攻撃者はあらゆるハッシュとソルトを盗んで管理しています。その攻撃者はいままさに最大レートでオフラインにおいて推測を行っています。
- その攻撃者は、自由に自分のいくつものCPUを使うことができます。
以下には、いくつかの大ざっぱな計算が行われた数字があります。
# bcrypt / scrypt / PBKDF2のようなハッシュ関数では、10msが一つの推測にとって安全な下限です。
# 通常、推測にはもっと時間がかかるでしょう --これは速いハードウェアと小さな作業内容を前提としています。
# あなたが他のハッシュ関数を使用する場合は、それに応じてサイトを調整してください。
SINGLE_GUESS = .010 # 秒数
NUM_ATTACKERS = 100 # 並列で推測するコアの数
SECONDS_PER_GUESS = SINGLE_GUESS / NUM_ATTACKERS
entropy_to_crack_time = (entropy) ->
.5 * Math.pow(2, entropy) * SECONDS_PER_GUESS
私は、.5 を追加しました。なぜなから私たちは平均クラック時間を計っているためであって、すべての空白を推測する時間は含まれません。
この計算は、おそらく過度に安全です。大規模ハッシュの盗難はまれな大惨事です。そしてもしあなたが特に標的にされていない限り、攻撃者があなたの一つのパスワードに100コアを捧げることはありそうもないです。通常、攻撃者はオンラインで推測し、ネットワークのレイテンシー、集積回路のスロットリング、およびCAPTCHAを解決する必要があります。
エントロピーの計算
次に、zxcvbn が各構成パターンのエントロピーを計算する方法を説明します。calc_entropy() は、エントリーポイントです。それはシンプルな動作割り当てを行います。
calc_entropy = (match) ->
return match.entropy if match.entropy?
entropy_func = switch match.pattern
when 'repeat' then repeat_entropy
when 'sequence' then sequence_entropy
when 'digits' then digits_entropy
when 'year' then year_entropy
when 'date' then date_entropy
when 'spatial' then spatial_entropy
when 'dictionary' then dictionary_entropy
match.entropy = entropy_func match
repeat_entropy がどのように機能するかについて、概要を先に示しました。あなたは github で完全なスコアリングコードを見ることができますが、私は違う方法として、ここで二つの他のスコリアング関数を説明します:spatial_entropy と、dictionary_entropy です。
qwertyhnm の空間的なパターンを検証します。その単語は、q からスタートして、その長さは9文字、3つだけ変わります。最初に変わった文字から右、そのまま右、さらに右へと動きます。パラメータ化すると、
s # 考え得る開始文字の数。
# QWERTY / Dvorak の 47文字、PCのキーパッド 15文字、macのキーパッド 15 文字。
L # パスワード文字列の長さ。 L >= 2
t # 折り返す数。 t <= L - 1
# 例えば、length-3 のパスワードは、 「qaw」のようにもっとも大きいと2つ折り返すことができます。
d # それぞれのキーの平均的な「度合い」 -- 隣接するキーの数です。
# QWERTY / Dvorak だと平均的には、4.6。(g は、6つの隣接したキーがあり、チルダはたった一つです。)
それから、合計した可能性のある空間は、t で変わったかそれ以下の長さ L かそれ以下のすべての可能性がある空間パターンです。
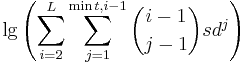
(i – 1) は、変わる j に空間的パターン length-i として、変わるポイントの可能な限り配置を数える (j - 1) を選びます。-1 は、両方の条件に追加されないといけません。なぜなら最初の変化は最初の文字では常に起こるからです。それぞれの変化位置 j において、配列ごとに可能性 dj の合計があるため、行く方向の可能性 d があります。攻撃者は、それぞれの開始文字を取りかかる必要があるかもしれません。したがって、それは s となります。この一致は、単なる大まかな近似値です。たとえば、方程式の中に数えられる多くの選択肢は、実際にはキーボード上から打ち込むのは不可能です。1だけ変わるlength-5 のパターンには、「q から左へ動き始める」ことで数えていきますが、実際には不可能です。
CoffeeScriptでは、上記の自然な表現を可能にします。
lg = (n) -> Math.log(n) / Math.log(2)
nPk = (n, k) ->
return 0 if k > n
result = 1
result *= m for m in [n-k+1..n]
result
nCk = (n, k) ->
return 1 if k == 0
k_fact = 1
k_fact *= m for m in [1..k]
nPk(n, k) / k_fact
spatial_entropy = (match) ->
if match.graph in ['qwerty', 'dvorak']
s = KEYBOARD_STARTING_POSITIONS
d = KEYBOARD_AVERAGE_DEGREE
else
s = KEYPAD_STARTING_POSITIONS
d = KEYPAD_AVERAGE_DEGREE
possibilities = 0
L = match.token.length
t = match.turns
# 長さ L またはそれ以下、そして変わる位置 t またはそれ以下の数のパターンを見積もります。
for i in [2..L]
possible_turns = Math.min(t, i - 1)
for j in [1..possible_turns]
possibilities += nCk(i - 1, j - 1) * s * Math.pow(d, j)
entropy = lg possibilities
# シフトキーによる追加のエントロピー( 5 は % 、 a は A)。
# 計算は、辞書一致の大文字からの追加エントロピーと近似値です。
# 下記のスニペットを参照してください。
if match.shifted_count
S = match.shifted_count
U = match.token.length - match.shifted_count # シフトキーが押されていない数
possibilities = 0
possibilities += nCk(S + U, i) for i in [0..Math.min(S, U)]
entropy += lg possibilities
entropy
辞書のエントロピーについて:
dictionary_entropy = (match) ->
entropy = lg match.rank
entropy += extra_uppercasing_entropy match
entropy += extra_l33t_entropy match
entropy
最初の行が一番重要です。その一致には頻度ランクが関連付けられています。ここで、the や good のような単語はランクが低く、photojournalist や maelstrom のような単語はランクが高くなっています。これにより、zxcvbnは、その場で適切な辞書サイズに計算を拡縮して行えます。なぜなら、もしパスワードが一般的な単語だけ含まれていたならば、クラッカーはより小さい辞書で成功することができます。これは、xkcd と zxcvbn が、correcthorsebatterystaple (45.2ビット vs 44)のエントロピー上で、わずかに合わない理由です。xkcd の例では、211(約2000語)の辞書サイズに限定されたものを使ったからで、その一方で、zxcvbn は適応性があります。サイズ適応されるのはまた、zxcvbn.js が空間効率の良いブルームフィルタの代わりに辞書全体を含む理由です。-- メンバシップテスト演算に加えてランクが必要です。
最後にデータセクションで頻度ランクがどのように導出されるかを説明します。
大文字エントロピーはこのようになります。:
extra_uppercase_entropy = (match) ->
word = match.token
return 0 if word.match ALL_LOWER
# 大文字の単語は最も一般的な大文字体系です。
# だから、検索する空間は二倍になるだけです(大文字+小文字)。
# 1ビット余計のエントロピーになります。
# すべての大文字と最後の文字だけ大文字にするのは一般的によくあるもので、
# 安全にするための余分な1ビットとして過小評価しています。
for regex in [START_UPPER, END_UPPER, ALL_UPPER]
return 1 if word.match regex
# それ以外の場合は、U+Lの、大文字+小文字は、
# Uの大文字かそうでないかを大文字化する方法の数を計算します。
# または、小文字よりも大文字が多い場合(たとえばPASSwORD)、
# L以下の小文字でU + L文字を小文字にする方法の数。
U = (chr for chr in word.split('') when chr.match /[A-Z]/).length
L = (chr for chr in word.split('') when chr.match /[a-z]/).length
possibilities = 0
possibilities += nCk(U + L, i) for i in [0..Math.min(U, L)]
lg possibilities
つまり、最初の文字が大文字になることと、他の一般的な大文字の使用については、1ビット余分になります。もし大文字にすることが、これらの一般的な型に合わない場合は、次のように付け加えます。
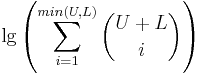
l33t 置換の式と似ていますが、上限と下限の代わりに置換文字と非置換文字を数える変数があります。
パターンマッチング
これまではパターンエントロピーについて説明してきましたが、zxcvbn が最初にパターンを見つける方法については説明しませんでした。辞書の一致は簡単です。パスワードのすべての部分文字列を調べて、辞書に含まれているかどうかを確認します。
dictionary_match = (password, ranked_dict) ->
result = []
len = password.length
password_lower = password.toLowerCase()
for i in [0...len]
for j in [i...len]
if password_lower[i..j] of ranked_dict
word = password_lower[i..j]
rank = ranked_dict[word]
result.push(
pattern: 'dictionary'
i: i
j: j
token: password[i..j]
matched_word: word
rank: rank
)
result
rank_dict は、単語からその頻度ランクにマッピングします。これは、頻度の高い順に並べられた単語の配列のようですが、インデックスと値が反転しています。l33t 置換は、dictionary_match をプリミティブとして使用する別の一致する仕組みで検出されます。bvcxz のような空間パターンは、文字列に沿って折り返しとシフトを数える隣接グラフアプローチで一致させます。日付と西暦は正規表現と一致します。詳しくはGitHubにあるmatching.coffeeを見てください。
データ
前述のように、10kのパスワードリストは2011年に公表されたマーク・バーネットからのものです。姓名の頻度ランクは、無料で入手可能な2000年米国国勢調査から来ています。zxcvbn が ie7 をクラッシュしないようにするために、私は長い末尾を持つ姓の辞書を80パーセンタイルで切り取ります(アメリカ人の80%がリストの姓の1つを持っていることを意味します)。一般的な名は90パーセンタイルを含みます。
英単語の40kの頻度リストはウィクショナリーでのプロジェクトから来ています。それは米国のテレビと映画から約29Mの単語を数えました。私の感覚としては、オンライン、テレビ、映画のスクリプトが、他の英語の素材よりも一般的な用法(ひいてはパスワードで使用される可能性のある語句)を捉えることができると思いますが、これはテストをしていない仮説です。このリストは少し古くなっています。たとえば、Frasier は824番目に一般的な単語です。
結論
一見すると、優れた推定量を構築することは、優れたクラッカーを育生することと同じくらい難しくなります。もしそのゴールが的確であるならば、これはトートロジー的な方法においては正しいです。なぜなら、「理想的なエントロピー」-- 完全なモデルに従ったエントロピー -- は、(その背後に賢い方法を知っている)クラッカーがパスワードを盗むのに必要な推測をどれくらいあるかを計測できるでしょう。だけれども、そのゴールは的確ではありません。ゴールは、音によるパスワードアドバイスを使うことです。そして、これは実際に仕事を少し簡単にします。たとえば、必要以上に強いパスワードを推奨するという唯一の欠点として、エントロピーを過小評価するという自由を採ることができます。それはフラストレーションが溜まるものの、危険ではありません。
良い推定を行うには、まだ難しく、その主な理由は、人間が使うかもしれないかなり多くの異なるパターンがあるからです。zxcvbn は、最初の文字や母音のない単語、スペルの間違った単語、何グラム、人口の多いエリアの郵便番号、qzwxec のような切り離された空間的なパターン、などの多くをなくして、単語を調べてはいません。(カタロニア語の数字のような)曖昧なパターンは、推定するのに重要ではありませんが、zxcvbn が見逃してクラッカーが知っている可能性がある一般的なパターンごとに、zxcvbn はエントロピーを過大評価し、それが最悪の種類のバグになります。考えられる改善点としては、
- zxcvbn は、基本的に英単語のみをサポートし、頻度リストはアメリカ英語の用法とスペルに偏っています。姓名も米国の国税調査に偏っています。世界中にある多くのキーボードレイアウトのうち、zxcvbn が認識できるものはわずかです。国によって固有のデータセットをダウンロードできるように選択するオプションがあれば、大きな改善になります。
- ジョセフ・ボノーによるこの研究が証明するように、人々は一般的な単語に加えて一般的なフレーズを選ぶことがよくあります。zxcvbn は、「Harry Potter」を準一般的な名前や姓よりも一般的なフレーズとして認識していれば、より良いでしょう。Google の n-gram コーパスは1テラバイトに収まり、良いバイグラムリストでもブラウザサイドのダウンロードには実用的ではないため、この機能を使用するにはサーバーサイドの要求とインフラストラクチャのコストが必要になります。サーバーサイドの要求では、Googleのユニグラムセットのように、もっと大きな一単語辞書を使うこともできます。
- zxcvbn が、特定の編集距離までの単語のスペルミスを許容するのであれば、もっと良くなるかもしれません。それは最初の文字をスキップするような、多くの単語ベースのパターンをもたらすかもしれません。単語のセグメンテーションが複雑になるため、特にl33t置換を認識することの複雑さが増すため、難しいのです。
これらの欠点があっても、私は、zxcvbn が悪いパスワードの選択が広まっている世界でより良いパスワードアドバイスを与えることに成功すると信じています。私は、あなたにとって有用であることを望みます。 では github でフォークして楽しんでください!
この記事のレビューのために尽力してくれた、Chris Varenhorst、 Gautam Jayaraman、 Ben Darnell、 Alicia Chen、 Todd Eisenberger、 Kannan Goundan、 Chris Beckmann、 Rian Hunter、 Brian Smith、 Martin Baker、 Ivan Kirigin、 Julie Tung、 Tido the Great、 Ramsey Homsany、 Bart Volkmer と、 Sarah Niyogi に多大な感謝を送ります。
以上が全訳となります。