データ活用によって新たな顧客価値を提供したいというニーズが高まっているように思います。
AWSではデータ活用向けのサービスがいくつもあり、ソフトウェアエンジニアはそれらを適切に選択し、データ活用の土台となるデータ基盤を作る必要があります。
本投稿では、Global Mobility Serviceのデータ基盤を例にし、AWSで実現するデータ基盤について紹介します。
コストとパフォーマンスのバランスが取れていて、スタートアップにちょうど良いデータ基盤だと思います。
今回の内容を通して、技術選定のヒントになれば幸いです。
概要
データ基盤の構築にあたっては、データを収集する、変換する、可視化するといったプロセスに応じてデータを扱う環境を分けることをオススメします。
環境を適切に分けることで、データの出どころが分かりやすくなるため、データの品質をコントロールしやすくなります。
全体のシステム構成イメージとしては以下の通りです。
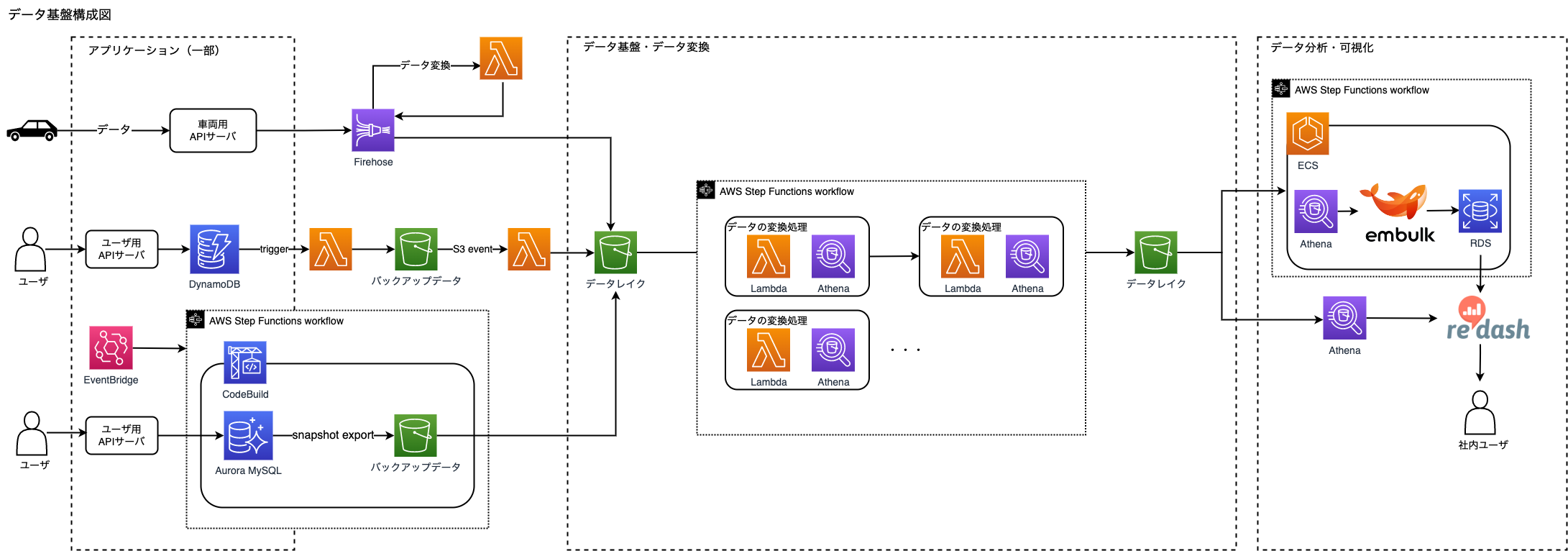
プロセスごとのデータ環境の作り方について紹介をしていきます。
データ収集環境を作る
データを収集する環境とは一般的にはデータレイクと呼ばれます。
AWSにおいては、あらゆるデータ形式をそのまま保存することができるため、S3が適しています。
データを収集するにあたっては、様々なデータソースからデータを取得するために、各データソースに応じたデータの取り込みを個別に実装していく必要があります。
以降は、各データの取り込み部分について解説します。
Firehoseを使ったリアルタイムデータ収集
RDBにデータを保存せずに、リアルタイムに生のデータを収集したいケースがあると思います。
これにはアプリケーションの修正が伴います。
ゼロからそのような仕掛けを作る場合に、オススメの方法はFirehoseを使うことです。
Firehoseの利点は以下の通りです。
- Lambdaを使ったデータの前処理を行うことができる
- レコードの形式をParquet形式に変換できる
- データをバックアップすることができる
特にデータをバックアップする機能は、データの前処理に失敗した場合に役立ちます。
このようにデータ分析をするにあたって役立つ機能が揃っています。
アプリケーションで扱うデータをFirehoseに送信することができます。
https://docs.aws.amazon.com/ja_jp/firehose/latest/dev/writing-with-sdk.html
Lambdaのデータ前処理では、JSONデータの多階層部分をフラットな一階層にする処理を行います。
DynamoDBからのデータ収集
DynamoDBからの実行には、DynamoDBストリームの機能を使っています。DynamoDB内のデータに変更があった場合に、その内容を含めて、Lambdaにトリガーできます。
上記Lambdaによって、データが書き込まれるS3バケットの階層には、書き込まれたときに発生するイベント通知が設定されています。
このイベント通知をトリガーにして、データの前処理を行うDynamoDBのデータ用のLambdaを実行します。
このLambdaの処理では、JSONデータの多階層部分をフラットな一階層にする処理を行います。
最終的にデータレイクにデータが書かれます。
参考
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Streams.Lambda.html
Aurora MySQLからのデータ収集
Aurora MySQLからは、スナップショットのデータをS3にエクスポートする機能を利用しています。そのままAthenaでデータを分析できるので便利です。エクスポートと同時にParquet形式というデータ分析に適したファイル形式に変換されます。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_ExportSnapshot.html
実行タイミングは、データ処理のフローになるStep Functionsのワークフローで制御されています。処理自体はCodeBuildで実行されていて、Step Functions自体のスケジュール実行はEventBridgeで行われています。
データ変換環境を作る
ここでのデータ変換環境とは、データレイク環境のデータに対してデータ変換処理を行い、データ分析をしやすい形にデータを配置した環境のことです。
また、分析の過程でデータレイクのデータをそのまま参照するといったことも行います。
S3上のデータを扱う
S3上のデータを扱うには、まずデータカタログを作成します。
データカタログを作成することで、S3上のデータをAthenaを使って扱うことができます。
データカタログを作るには、Glueクローラを使います。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/console-crawlers.html
データカタログを作る方法はいくつかありますが、Glueクローラで作るとデータ型をデータの内容によって自動で決めてくれるため簡単にデータカタログを作成できます。
データ変換処理
データカタログを作った後、そのままのデータでは扱いづらい場合にデータの変換処理を行います。
Athenaの機能であるCREATE TABLE AS SELECT(CTAS)を使うと、SELECTクエリを使用してS3上にデータを作成して新規にAthenaのテーブルを作成することができます。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/ctas-insert-into-etl.html
データ分析のパフォーマンスを良くするためには、扱うデータの範囲、サイズをできるだけ小さくする必要があります。
そのために以下の点を考慮してテーブルを作成するとよいです。
- データを圧縮する
- Parquet、ORCといった列指向形式のデータに変換する
- パーティション分割を行う
データ変換のコスト
データ変換はAthenaだけでなく、Glue ETLジョブでも行うことができます。むしろサービス的にはGlue ETLジョブの方がデータ変換に対応したサービスという位置付けです。
ただし、Glue ETLジョブはコストが割高になる可能性があります。
データ基盤を作り始めてまもないころはクエリ実行ごとの課金となるAthenaの方がGlue ETLジョブよりも安くなると思います。
当社のケースでは、1/4以上のコスト削減ができました。
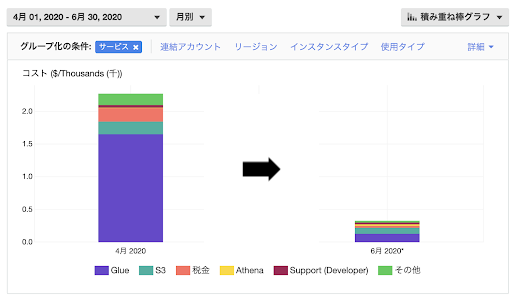
パーティション分割について
パーティション分割をすることでデータを扱う範囲を限定することができるため、クエリのパフォーマンス向上につながります。
どのようにパーティション分割するかは、どのようなクエリを実行するかが関係します。
例えば、時系列データの場合には、データの作成日時がクエリの条件になることが多いため、作成日時でパーティションを区切ると良いです。
FirehoseでデータをS3に配置すると、フォルダが日時毎に作られるので、パーティションを作りやすいです。
Glueクローラを使うとパーティション分割を行ってくれます。
ただ既にデータを収集する仕組みがある状態でパーティション分割するだけの場合、コストが見合わないです。
その場合、パーティション射影という機能を使います。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/partition-projection.html
こちらを使うと毎回パーティションを作る処理を実行することなく、自動的にパーティションを作ることが可能になります。
データ可視化環境を作る
ここでのデータ可視化環境とは、変換したデータをBIツールで可視化する部分とデータを集計処理して、頻繁に利用される集計値を格納する部分のことです。
BIツールを使って、データを可視化・分析するのが主なユースケースになります。
なお、本環境ではBIツールとしてRedashを使用しています。
集計値をRDBにロードする
データ可視化環境では、集計値を扱いやすい環境を作ります。
Athenaの場合、データを新規に作成することしかできません1。集計値は後で再集計を行うことがあるため、更新処理をサポートしているRDBなどのデータベースを使用するのが良いです。
このデータ可視化環境を作るには、Embulkを利用します。Embulkはバッチ実行に対応したETLツールです。
各種データソースに合わせてプラグインが存在し、プラグインを介した統一的な設定によって、ETL処理を行うことができます。
Embulkを使うと、Athenaのクエリを使用してデータを取得し、RDBにデータをロードすることができます。
Embulkの使い方
ここでは、AthenaからMySQLにデータをロードするという前提でのやり方を紹介します。
インストール
Embulkを利用するには、Dockerイメージ化しておくと楽です。
Embulkを実行可能にするまでの環境をDockerで作ります。
FROM openjdk:8-jre-alpine
RUN wget -q https://dl.embulk.org/embulk-0.9.23.jar -O /bin/embulk \
&& chmod +x /bin/embulk
RUN apk add --no-cache libc6-compat
RUN embulk gem install embulk-input-athena
RUN embulk gem install embulk-output-mysql
WORKDIR /work
ENTRYPOINT ["java", "-jar", "/bin/embulk"]
Embulk設定ファイル例
Embulkでは、データの取得元とロード先を設定ファイルに記述します。
下記は、AthenaからMysqlにデータをロードする設定ファイルの例です。
in:
type: athena
database: {{ env.ATHENA_DATABASE }}
athena_url: jdbc:awsathena://athena.ap-northeast-1.amazonaws.com:443
s3_staging_dir: {{ env.ATHENA_DIR }}
access_key: {{ env.ATHENA_AWS_ACCESS_KEY }}
secret_key: {{ env.ATHENA_AWS_SECRET_KEY }}
query: |
SELECT * FROM alb_logs
columns:
- {name: type, type: string}
- {name: time, type: string}
- {name: elb, type: string}
- {name: client_ip, type: string}
- {name: client_port, type: long}
- {name: target_ip, type: string}
- {name: target_port, type: long}
- {name: request_processing_time, type: double}
- {name: target_processing_time, type: double}
- {name: response_processing_time, type: double}
out:
type: mysql
host: {{ env.MYSQL_HOST }}
user: {{ env.MYSQL_USER }}
password: {{ env.MYSQL_PASSWORD }}
database: {{ env.MYSQL_DATABASE }}
port: {{ env.MYSQL_PORT }}
table: log
mode: merge
liquidファイルにすることで、{{env.XXX}}の記述で環境変数を埋め込むことができます。
各プラグインの設定値については、下記プラグインのドキュメントを参考にしてください。
- https://github.com/shinji19/embulk-input-athena
- https://github.com/embulk/embulk-output-jdbc/tree/master/embulk-output-mysql
実行
Embulkを実行します。
Dockerイメージをビルドします。
$ docker build -t embulk .
embulk run 設定ファイル名で実行できます。
$ docker run --rm -it -v $(pwd):/work --env-file .env embulk run athena2mysql.yml.liquid
--env-fileオプションで環境変数を定義したファイルを読み込みます。
各環境を連携する
特定の用途向けにデータの加工方法が固まるにつれて、データを収集する、変換する、可視化するといったプロセスを経ていきます。
これを制御するためにワークフローを定義します。
EventBridgeとStep Functionsを使用する
AWSでは、スケジュール実行や各種AWSサービスのイベントを検知して実行をトリガーするEventBridgeがあります。
また、各種AWSサービスを連携してワークフローとして処理ができるStep Functionsがあります。
この2つを組み合わせることで、データのプロセスを適切に制御することができます。
EventBridgeはスケジュール実行でStep Functionsを実行します。
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/create-eventbridge-scheduled-rule.html
Athenaの実行をStep Functionsに組み込むには、LambdaでAthenaのクエリを実行します。
EmbulkはDockerイメージ化しているので、ECSで実行できます。
Step Functionsでは、JSONでワークフローを定義します。
LambdaとECSを連携するワークフローは以下のように記述できます。
{
"Comment": "workflow",
"StartAt": "lambda-example",
"States": {
"lambda-example": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-1:000000000000:function:example",
"ResultPath": "$.lambda-example",
"Next": "ecs-example"
},
"ecs-example": {
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
"Parameters": {
"LaunchType": "FARGATE",
"Cluster": "arn:aws:ecs:ap-northeast-1:000000000000:cluster/default",
"TaskDefinition": "arn:aws:ecs:ap-northeast-1:000000000000:task-definition/example:1",
"NetworkConfiguration": {
"AwsvpcConfiguration": {
"Subnets": [
"subnet-00000000000000000",
"subnet-00000000000000001"
],
"SecurityGroups": [
"sg-00000000000000000"
],
"AssignPublicIp": "ENABLED"
}
}
},
"ResultPath": "$.ecs-example",
"End": true
}
}
}
このようにワークフローを定義することで、データのETL処理から集計処理に処理をつなげることができます。
Step FunctionsはRetryやCatchという構文を使うことで、ワークフローが失敗したときの例外処理にも対応できます。
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/concepts-error-handling.html
まとめ
データ基盤では、データの内容を確認する、データを統計処理するといったことを行います。
このようなデータの探索を通して、本当に役立つデータを見つけ出し、利用者のアクションを改善することがデータを活用するということだと思います。そのような状態を多くの利用者に提供することが大事だと思います。
そのためには今回紹介したようなデータ基盤を作ることが必要です。
-
現在はIceberg対応がありますので、この限りではありません ↩