AuroraDB
- 標準のMySQL、PostgreSQLと比べて、それぞれ最大5倍、最大3倍高速
- 高速なデータ同期・フェイルオーバー
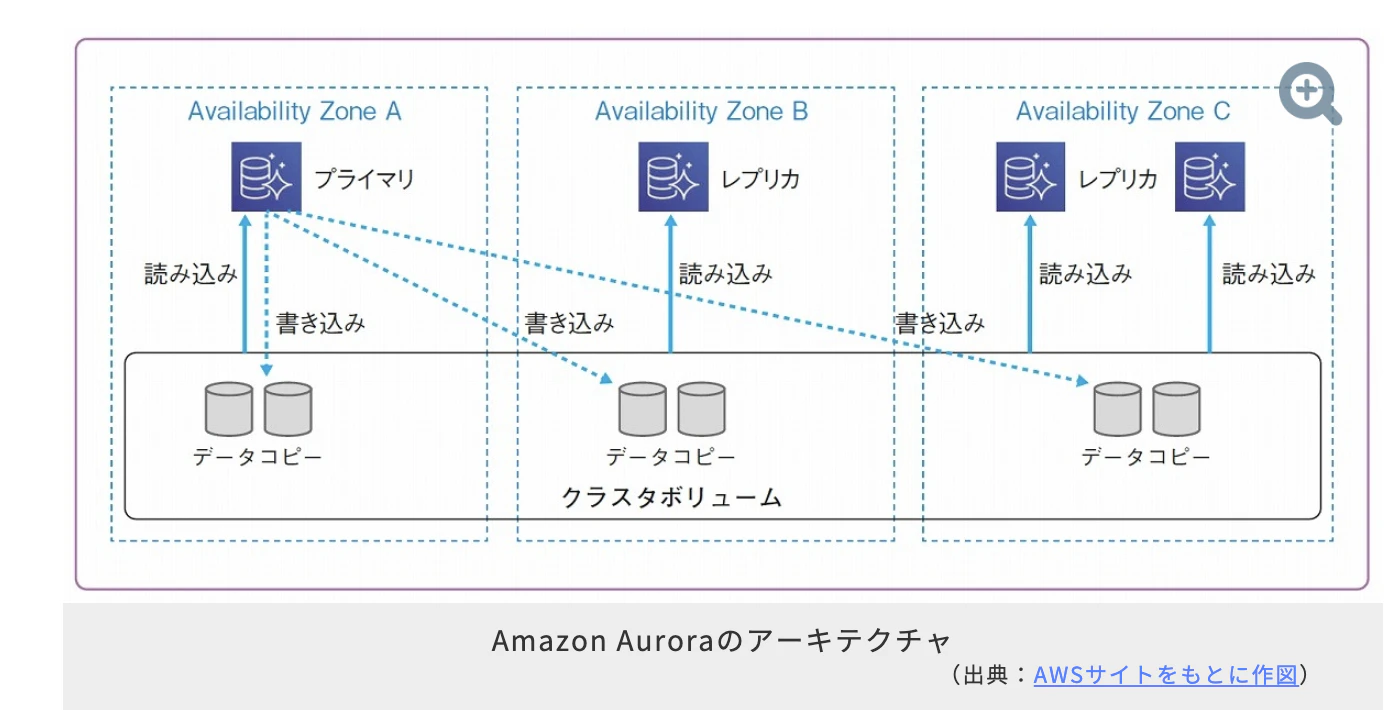
- プライマリインスタンス、リードレプリカともに、3つのアベイラビリティゾーンにレプリケートされた同じクラスタボリュームのデータコピーを参照するので、レプリカの非同期更新時間が小さくなる
- プライマリインスタンスに障害が発生した場合は、RDSより高速にリードレプリカへフェイルオーバーすることができます
- 自動ストレージ拡張
- データは10GBずつ「protection groups」と呼ばれる論理的なグループに保存され、64TBまで自動的にスケールアップすることができます
- リードレプリカのオートスケーリング
- メトリクスに応じて自動増減する「オートスケーリング」に対応しています。リードレプリカへの読み取りクエリの分散や、リクエストの増減分に応じたコスト最適化が可能
- DBバックアップ機能の拡充
- RDSと同様、自動バックアップが常に有効になります。バックアップでもパフォーマンスに影響を与えることなく、セグメントごとにS3へ継続的にスナップショットが保存され
AuroraDBとRDSの違い
| 特徴 | Aurora | RDS |
|---|---|---|
| アーキテクチャ | クラウドネイティブな分散ストレージエンジン | 単一のマスターインスタンスとスタンバイレプリカ |
| パフォーマンス | MySQLの最大5倍、PostgreSQLの最大3倍の高速性 | 標準的なパフォーマンス |
| スケーラビリティ | 事実上無制限(10GB単位で自動拡張) | 最大32 vCPUと244 GiBのメモリ |
| ストレージ容量 | 最大128 TiB | 最大64 TiB(SQL Serverは16 TiB) |
| レプリカ数 | 最大15個 | 最大5個 |
| 高可用性 | 複数のAZにわたる自動フェイルオーバー | マルチAZ配置可能 |
| バックアップ | 継続的バックアップ、35日間のポイントインタイムリカバリ | 自動バックアップ、手動スナップショット |
| サーバーレス | サポート | 非サポート |
| データベースエンジン | MySQL、PostgreSQLとの互換性 | より多様なエンジンをサポート |
| コスト | 比較的高価 | 比較的低コスト |
| モニタリング | より詳細な監視機能 | 標準的な監視機能 |
| 料金 | 1)DBインスタンスの起動時間 2)ストレージの容量に応じた料金 3)I/Oリクエスト数 | 1)DBインスタンスの起動時間 2)ストレージの容量に応じた料金 |
グローバルデータベースとクロスリージョンレプリケーションの違い
グローバルデータベース (Global Database)
- 目的: 複数のリージョンでの高可用性と低レイテンシのデータベースレプリケーションを提供。
-
特徴:
- プライマリリージョンとセカンダリリージョンの間でデータが同期される。
- 読み書きはプライマリリージョンで行い、セカンダリリージョンでは読み取り専用として運用される。
- セカンダリリージョンはプライマリリージョンがダウンした場合に、フェイルオーバーで自動的にプライマリとして昇格することが可能。
- 低レイテンシでのデータアクセスを提供し、グローバル規模でのアプリケーションをサポート。
クロスリージョンレプリケーション (Cross-Region Replication)
- 目的: 複数のリージョンでデータベースを複製して、レプリケーションを確立する。
-
特徴:
- クロスリージョンレプリケーションは、特にバックアップや災害復旧 (DR) に用いられる。
- 各リージョンのインスタンスは独立しているため、フェイルオーバーなどの自動化は手動で行う必要がある。
- セカンダリリージョンは読み取り専用であり、プライマリリージョンからの一方向レプリケーションでデータを同期。
- やってみた
主な違い:
- フェイルオーバーの可用性: グローバルデータベースではセカンダリリージョンがフェイルオーバーをサポートしますが、クロスリージョンレプリケーションでは手動でのフェイルオーバー設定が必要です。
- 使用用途: グローバルデータベースはグローバル規模のアプリケーションにおいて、低レイテンシを提供するために設計されています。クロスリージョンレプリケーションは主にバックアップと災害復旧を目的としています。
| 項目 | グローバルデータベース | クロスリージョンレプリケーション |
|---|---|---|
| 同期方式 | 専用リンクによる低レイテンシ同期 | 通常のネットワークを介した非同期レプリケーション |
| 読み取り専用のインスタンス | セカンダリリージョンに自動構成、昇格可能 | 手動設定が必要、昇格機能はなし |
| フェイルオーバー | 自動昇格が可能 | フェイルオーバーなし、手動対応 |
| 目的 | 高可用性・グローバル分散アクセス | 災害復旧 (DR)、バックアップ |
グローバルデータベースのプライマリークラス・セカンダリークラス・ライター・リーダーの違い
プライマリークラス (Primary Instance)
- 役割: グローバルデータベースの書き込み操作を処理するインスタンスです。
-
特徴:
- データベースに対するすべての書き込みリクエストを受け付けます。
- レプリケーションのソースとなるため、プライマリリージョンに存在します。
セカンダリークラス (Secondary Instance)
- 役割: グローバルデータベースの読み取り専用のインスタンスです。
-
特徴:
- データのレプリケーション先で、主に読み取り操作を担当します。
- セカンダリリージョンに配置されることが多いです。
- プライマリリージョンがダウンした場合、セカンダリリージョンが昇格し、フェイルオーバーが発生します。
ライター (Writer)
- 役割: 書き込み操作を受け付けるインスタンスです。
-
特徴:
- グローバルデータベース内でプライマリインスタンスまたはリーダーインスタンスに昇格することができます。
- 通常、プライマリインスタンスがライターとして機能しますが、セカンダリリージョンにもライターが設定できる場合があります。
リーダー (Reader)
- 役割: 読み取り操作専用のインスタンスです。
-
特徴:
- レプリケーションされたデータを基に、アプリケーションからの読み取りリクエストを処理します。
- 読み取り専用であり、書き込み操作は行えません。
まとめ
- プライマリークラスは書き込みを担当するインスタンスで、全体のデータ更新の責任を負います。
- セカンダリークラスはプライマリリージョンからデータを同期し、主に読み取り専用です。
- ライターはデータベースへの書き込みを行うインスタンスで、プライマリまたはセカンダリリージョンに設定されることがあります。
- リーダーはプライマリリージョンとセカンダリリージョンの両方で読み取り専用の操作を担当します。