株価データを取得
pythonで株価取得して、10年間、毎年同じ月にあがる株はあるのかを調べる記事を書きました。
前回の記事は、この中の「銘柄コード取得」として、上場銘柄一覧をWebから取得し、CSVに保存する方法を解説しました。
今回は、その銘柄コードのcsvファイルを使って、各銘柄の株価データをダウンロードし、csvに保存する処理について見ていきます。
サンプルコード
import yfinance as yf
import pandas as pd
import os
# 10年分のデータが欲しいので、開始日は2015/08/28に固定
start="2015-08-28"
def download_stock_data():
script_dir = os.path.dirname(os.path.abspath(__file__))
# 銘柄コードが書かれたcsvファイルのパス
load_path = os.path.join(script_dir, "stock_code.csv")
# 各銘柄の株価の保存フォルダ
save_dir = os.path.join(script_dir, "stock_data")
os.makedirs(save_dir, exist_ok=True)
# CSVを読み込む
df = pd.read_csv(load_path)
start_date = pd.Timestamp(start)
end_date = pd.Timestamp.now().normalize() # 今日
total = len(df['コード'])
for idx, code in enumerate(df['コード'], 1):
ticker_symbol = code + ".T"
safe_symbol = ticker_symbol.replace(".", "_")
file_name_path = os.path.join(save_dir, f"stock_data_{safe_symbol}.csv")
stock_data = yf.download(
ticker_symbol,
start=start_date.strftime('%Y-%m-%d'),
end=end_date.strftime('%Y-%m-%d'),
auto_adjust=False,
progress=False
)
if stock_data is None or stock_data.empty:
continue
first_date = stock_data.index[0]
# 開始日が10年前より後ならスキップ
if first_date > start_date:
continue
stock_data.index.name = 'Date'
stock_data['Ticker'] = ticker_symbol
stock_data.to_csv(file_name_path, encoding="utf-8-sig")
print(f"進捗: {idx}/{total} 完了", end='\r')
if __name__ == "__main__":
download_stock_data()
プログラムの構成
このプログラムは大きく分けて以下の流れです。
- 銘柄コードCSVを読み込む
- yfinanceで株価データを取得
- CSVファイルとして保存
関数 download_stock_data() に処理をまとめてあり、
ファイルを直接実行 → download_stock_data() が動く
別ファイルからインポート → download_stock_data() を再利用できるというメリットがあります。
処理の流れを詳しく解説
保存フォルダの準備
script_dir = os.path.dirname(os.path.abspath(__file__))
load_path = os.path.join(script_dir, "stock_code.csv")
save_dir = os.path.join(script_dir, "stock_data")
os.makedirs(save_dir, exist_ok=True)
実行中のPythonファイルの場所を基準に、CSVファイルと保存先フォルダを指定します。
os.makedirs(..., exist_ok=True) により、フォルダがなければ新しく作成されます。
銘柄コードの読み込み
# CSVを読み込む
df = pd.read_csv(load_path)
CSVをDataFrameとして取り込みます。
例えば print(df.head()) すると、次のように冒頭5行が表示されます。
日付 コード 銘柄名 市場・商品区分 ...
0 20250829 1301 極洋 プライム(内国株式)
1 20250829 1305 iFreeETF TOPIX ...
...
株価取得に使うのは「コード」列です。
forループで各銘柄の株価取得
for idx, code in enumerate(df['コード'], 1):
ticker_symbol = code + ".T"
- 日本株は 末尾に .T を付ける必要があります(例: 7203.T → トヨタ自動車)
- enumerate(..., 1) とすることで、idx は 1, 2, 3... と進み、進捗表示にも使えます
yfinanceで株価データを取得
stock_data = yf.download(
ticker_symbol,
start=start_date.strftime('%Y-%m-%d'),
end=end_date.strftime('%Y-%m-%d'),
auto_adjust=False,
progress=False
)
ここで株価データを取得します。結果はDataFrameとして stock_data に入ります。
データのチェックと保存
first_date = stock_data.index[0]
if first_date > start_date:
continue # 10年分ない銘柄はスキップ
stock_data.index.name = 'Date'
stock_data['Ticker'] = ticker_symbol
stock_data.to_csv(file_name_path, encoding="utf-8-sig")
開始日が十分古くない場合はスキップし、そうでなければCSVに保存します。
ファイル名に銘柄コードを入れているので、あとで判別しやすいです。
まとめ
- yfinance を使って株価データを取得
- 銘柄ごとに株価データをCSVファイルに保存
<例> stock_data_7203_T.csv
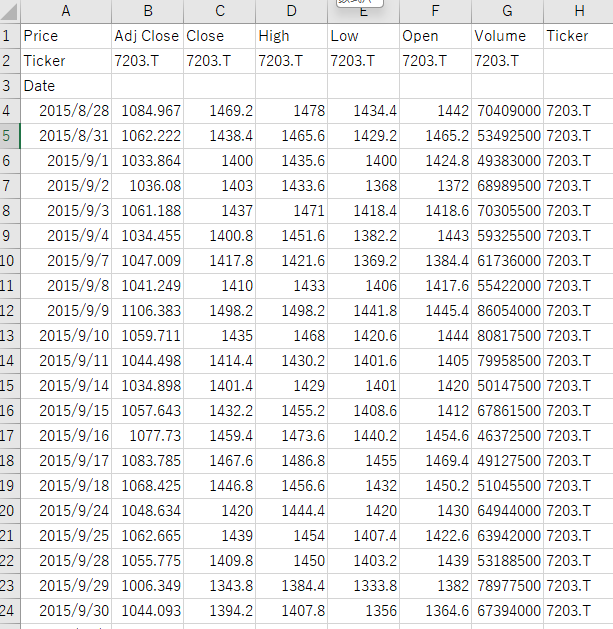
これで 銘柄コード一覧 → 株価データの取得 までの流れがつながりました。