はじめに
はじめまして。Python学習の一環でアウトプットを投稿いたします。
初学者ゆえ、至らぬ点も多いと思いますが少しの間、お付き合いをいただけますと幸いです。
目的・環境
目的
ブロードウェイで上演されるミュージカル全体の過去実績から、平均単価の値上がりを予測するモデルの構築
環境
・言語:Python3
・OS:Windows 11
・Chrome
・Google Colaboratory
補足前提の説明~ブロードウェイ・ミュージカルとは?~
■「ブロードウェイ・ミュージカル」とは?
一般的に「ニューヨークでやっているミュージカル」のこと、とイメージされる方が多いのではないでしょうか?
こちらの実践前に定義を確認しておきたいと思います。
特に、ブロードウェイの41丁目から54丁目の間には劇場が多く集まっており、その中でも座席数が500席以上の劇場で公演される演目を「ブロードウェイ・ミュージカル」と呼びます。このような劇場は、ブロードウェイ界隈に約40あり、毎夜多くの演目が上演されています。
(引用元:あっとブロードウェイ)
■料金体系の特徴~ダイナミックプライシング制の採用 ブロードウェイの演劇産業では、基本的にダイナミックプライシング制が取られています。
ダイナミックプライシングとは、消費者の需要と供給を考慮して、商品やサービスの価格を変動させる手法です。商品やサービスの原価をもとに価格を決めるのではなく、販売する時期における消費者の需要を勘案して、価格の設定を変えていきます。
(引用元:ダイアモンド・チェーンストア)
日本の演劇だと「S席◯◯円」、「A席◯◯円」など席種ごとに料金が設定されていますが(2023年12月現在、曜日や開演時間によって料金を変えるところも多くなってきました)、基本的にはいつ買っても一律料金です。
こうした料金体系の違いも、今回平均単価の予測モデルを構築する上で事前に共有をさせていただきます。
■データの公開状況について
そんなブロードウェイでの上演ですが、下記のように毎週、週間の売上データが一般に公開されています。
ブロードウェイ全体の興行収入、総動員数だけでなく、各作品ごとの状況も表で可視化されており、売上や客席の埋まり具合などが公開されています。
ミュージカルにおいては、一部期間限定作品はあるものの、公演の終了日を決めずにロングラン上演をしていることが多いので「売れていれば継続、売れなければ打ち切り」というシビアな状況の中で日々公演を行っている…ということになり、それが一般にも公開されている、というのが上記のデータになります。
実践してみる
0.今回使用するデータの確認
■使用データ
kaggle「Broadway Show」のデータを使用させていただきました。
※上段のデータが使用できれば一番よいのですが、規約上難しそう+がっつりスクレイピングをする必要があるので、Kaggle上にありライセンス的にも問題がなさそうなものを使用させていただきました。
■データの内容について
・License:GPL 2
・1991年8月~2016年8月までの「週ごと」のデータが格納されています
・下記カラムの内容が格納されています
| カラム | 内容 |
|---|---|
| Data.Day | 日付(dd) |
| Data.Full | mm/dd/yyyy(テキスト形式で保存) |
| Data.Month | 月(mm) |
| Data.Year | 年(yyyy) |
| Show.Name | 作品タイトル |
| Show.Theatre | 劇場名 |
| Show.Type | 作品の種類(Musical/Play/Special) |
| Statistics.Attendance | 動員数(人) |
| Statistics.Capacity | 収容率(%) |
| Statistics.Gross | 興行収入($) |
| Statistics.Gross Potential | 総潜在収入に対する達成度(%) |
| Statistics.Performances | 公演回数 |
今回の目的は「平均単価」の予測なので、
- 新たに「平均単価」を入れる列が必要になってくる
- 日付ごとにデータをまとめる必要がある(現状だと作品×週ごとのデータなので、時系列データとしてそのまま扱うことができない)
の2点は分析の前段階で対処しておく必要があります。
また、現時点では、一旦オーソドックスに「平均単価」と「時系列」の関係だけで予測モデルを作ることを目標としてみます。
そのため、不要な要素を消しておく必要もありそうです。
これらを念頭におき、データのインポートと整理を進めていきたいと思います。
1.データをインポートする
今回使用する「broadway.csv」をPython上にインポートします。
pandasのDataFrameとして扱うため、pandasライブラリも合わせてインポートしておきます。
import numpy as np
import pandas as pd
bw_data=pd.read_csv('/content/drive/MyDrive/Colab Notebooks/broadway/broadway.csv')
2.不要な要素を削除する
まずは不要な要素の削除をしていきたいと思います。
行う処理としては下記の3つです。
-
Show.TipeがMusicalの行だけを抜き出す - 平均単価を考えるのに不要な列は削除する
-
Data.Fullを日付形式に変換
まずは「1.Show.TipeがMusicalの行だけを抜き出す」についてですが、このデータではMusicalの他にPlay(一般的なお芝居)、Special(コンサートなど特別興行)もまとめられています。
今回はあくまでも「ミュージカル」に限定をしたいので、Musicalの行だけを取り出したいと思います。
また「2.平均単価を考えるのに不要な列は削除する」については、先程記載した通り「現時点では、一旦オーソドックスに「平均単価」と「時系列」の関係だけで予測モデルを作ることを目標」とするので、それらには直接関係の無いデータは削除しておきます。
具体的には、時系列のData.Full、どの作品かを表すShow.Name、上述のShow.Type、そして平均単価を計算するための動員数・興行収入であるStatistics.Attendance、Statistics.Grossの5つを残す形を想定します。
「3.Data.Fullを日付形式に変換」については、事前にcsvデータの中身を確認したところ、日付形式ではなくテキスト形式になっていたため、to.datetimeline()を用いて変換しておきます。
これらを踏まえデータを加工していきたいと思います。
musical_data=bw_data[bw_data['Show.Type']=='Musical'] #Show.TypeのうちMusicalだけを抽出
drop_col = ['Date.Day','Date.Month','Date.Year','Show.Theatre','Statistics.Capacity', 'Statistics.Gross Potential','Statistics.Performances']
musical_data=musical_data.drop(drop_col,axis=1) #drop_colで指定したカラムを削除
musical_data['Date.Full']=pd.to_datetime(musical_data['Date.Full']) #Date.Fullの形式を日付形式に変換
このコードで出力してみると下記のようになっており、欲しい情報が正しく出力できていることがわかります。
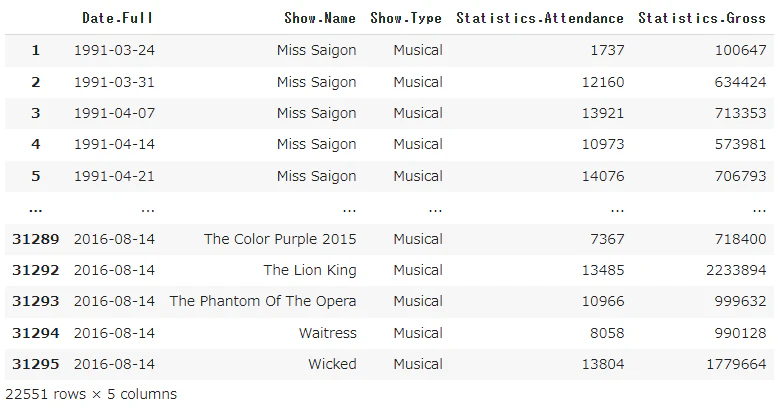
3.データの偏りをチェックしていく
出力されたデータを見ると「1991年は3\24~4\21までMiss Saigonの結果しか含まれていない」可能性が高いことがわかります。
今回は全体の平均単価を考えたいので、特定の1演目だけのデータで特定の週をまとめてしまうと正しいモデルとならない可能性があります。
そこで、各週ごとの演目数の偏りが無いかを、箱ひげ図を用いて確認していきたいと思います。
ここで行うこととしては下記の2点です。
- 週ごとの
Show.Nameの数をカウント - 箱ひげ図を作成し、外れ値の確認をする
#1.週ごとのShow.Nameの数をカウント
musical_data_check=musical_data.groupby('Date.Full')['Show.Name'].agg('count') #Date.Fullでグループ化し、Show.Nameの数をカウント
musical_data_check=musical_data_check.sort_index(ascending=True) #日付順(昇順)で並び替え
print(musical_data_check)
>>>出力結果
Date.Full
1991-03-24 1
1991-03-31 1
1991-04-07 1
1991-04-14 1
1991-04-21 1
..
2016-07-17 25
2016-07-24 25
2016-07-31 24
2016-08-07 23
2016-08-14 23
Name: Show.Name, Length: 1326, dtype: int64
一旦出力をしてみました。
先程確認した「1991年は3/24~4/21までMiss Saigonの結果しか含まれていない」は少なくとも正しいことがわかります。
次に、これからモデルを構築していく上で除外すべき数があるか(1を含めてもいいのか、1以外も外すべき数値はあるのか)を箱ひげ図を用いて確認します。
#2.箱ひげ図を作成し、外れ値の確認をする
import seaborn as sns
sns.boxplot(y=musical_data_check)
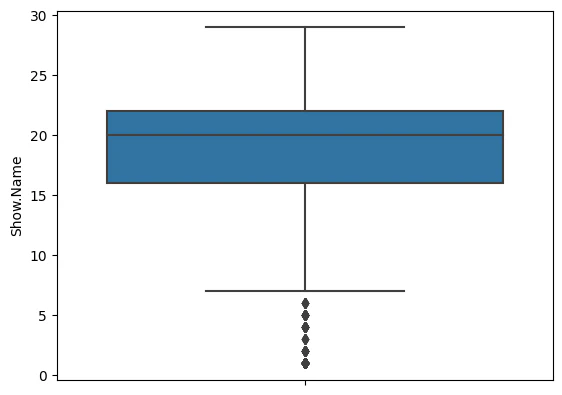
この箱ひげ図の結果から、「1~6までのタイトル数しかない週」は外れ値と考えることができます。
一方、今回扱っているのは時系列データなので、連続性を維持することも必要だと考えます。
そのため「1991-03-24週以降に連続している外れ値週」を除外する方針で、どこまでが外れ値週なのかをチェックしていきます。
print(musical_data_check[musical_data_check<=6]) #Show.Nameが6以下の週を出力
print()
print(musical_data_check.head(264)) #「6以下の週」で出力された個数と同じ個数分、頭から出力
print()
print(musical_data_check[musical_data_check>=7]) #Show.Nameが7以上の週を出力
>>>出力結果
Date.Full #外れ値のデータ…Ⅰ
1991-03-24 1
1991-03-31 1
1991-04-07 1
1991-04-14 1
1991-04-21 1
..
1996-03-24 5
1996-03-31 5
1996-04-07 5
2007-11-18 4 #冒頭から数えたときに明らかに非連続のデータが2件ある
2007-11-25 5
Name: Show.Name, Length: 264, dtype: int64
Date.Full #冒頭~264個分のデータ…Ⅱ
1991-03-24 1
1991-03-31 1
1991-04-07 1
1991-04-14 1
1991-04-21 1
..
1996-03-10 4
1996-03-17 4
1996-03-24 5
1996-03-31 5
1996-04-07 5 #外れ値のデータのうち最後から数えて3件目で止まっている→外れ値外のデータが2件ある
Name: Show.Name, Length: 264, dtype: int64
Date.Full #外れ値外のデータ…Ⅲ
1995-06-04 11
1995-10-15 7 Ⅱで存在がわかった2件の「外れ値外のデータ」が1995年にあった
1996-04-14 7
1996-04-21 7
1996-04-28 7
..
2016-07-17 25
2016-07-24 25
2016-07-31 24
2016-08-07 23
2016-08-14 23
Name: Show.Name, Length: 1062, dtype: int64
これらの結果を受けて、
- 外れ値週のほとんどが1991-03-24~1996-04-07までに含まれている(冒頭~264件分)
- 例外はそれぞれ2件ずつのみ(外れ値ではない1995-06-04,1995-10-15、外れ値となっている2007-11-18,2007-11-25)
ことがわかるため、「1991-04-21~1996-04-07までの264件」を外れ値とみなし除外する方針で進めていくこととします。
4.週ごとにグループ化し、平均単価を算出する
さて、ここまで情報の整理を行ってきました。ここからはモデル化するためにデータの成形を行いたいと思います。
今回行うべきこととしては、下記4点です。
- 週ごとでグループ化し、データをまとめる。
Statistics.AttendanceおよびStatistics.Grossはいずれも「合計値.sum()」を入れる - 日付順にソートをし直す。
- 連続する外れ値とみなした264件のデータを削除
- 平均単価を入れるカラム
AveragePriceを追加し、一人あたりの平均単価を計算
#1.週ごとでグループ化し、データをまとめ、合計値を出す
musical_data=musical_data.groupby('Date.Full').sum()
#2.日付順にソートをし直す
musical_data=musical_data.sort_index(ascending=True)
musical_data=musical_data.reset_index() #indexの振り直し1
#3.連続する外れ値とみなした264件のデータを削除
musical_data=musical_data.drop(range(264))
musical_data=musical_data.reset_index() #indexの振り直し2
musical_data=musical_data.drop('index',axis=1) #一回目のindex振り直しが「index」カラムとして残ってしまっているため削除
#4.平均単価を入れるカラム追加し、一人あたりの平均単価を計算
musical_data['AveragePrice']=musical_data['Statistics.Gross']/musical_data['Statistics.Attendance']
del musical_data['Statistics.Attendance']
del musical_data['Statistics.Gross']
musical_avg_data=musical_data.set_index('Date.Full')
musical_avg_data
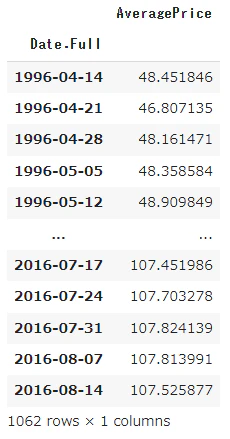
このように、時系列と平均単価のみのデータにまとめることができました。
ここからモデル構築に向けた作業に移っていきます。
5.平均単価の流れを可視化する
モデル構築にあたり、周期性やトレンドの確認をしていきます。
さきほどの表を見る限り、正のトレンドはありそうですが、グラフ化することで可視化を試みます。
from matplotlib import pyplot as plt
musical_avg_data['AveragePrice'].plot(kind='line', figsize=(8, 4), title='AveragePrice')
plt.gca().spines[['top', 'right']].set_visible(False)
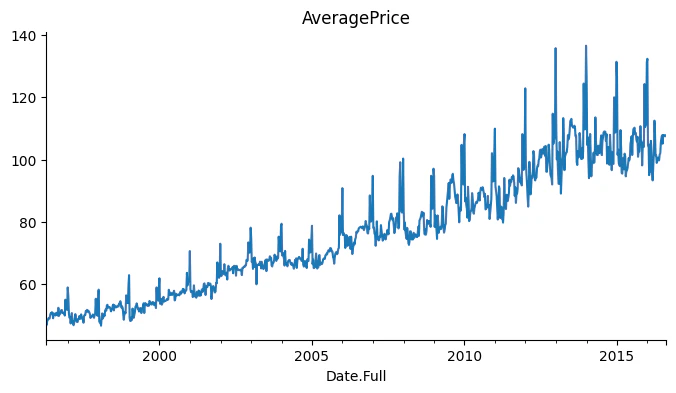
このグラフから、正のトレンドと季節変動の傾向が見られます。
これらの除去し、定常性のある時系列データに変換していきたいと思います。
6.周期の測定を行う
ここまでの結果を踏まえて、SARIMAモデルを用いた予測モデル構築を目指したいと思います(お、っと思った方がいらっしゃいましても恐れ入りますがお付き合いくださいませ)。
それに先立ち、季節変動の周期を考えてみたいと思います。
先程のグラフもそうですが、6月の大きな授賞式に向けた春の開幕シーズンや、11月~12月にかけたホリデーシーズン、冬が厳しくなり観光的にもローシーズンになる1,2月と、季節的な影響を大きく受けるため、1年≒51週を1つの周期とするのでは?という仮説を持ちつつ臨んでみます。
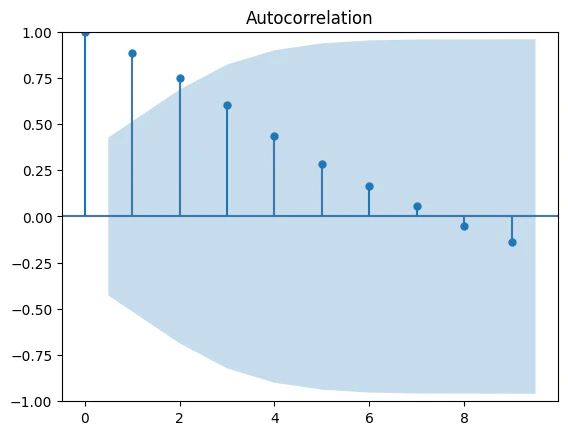
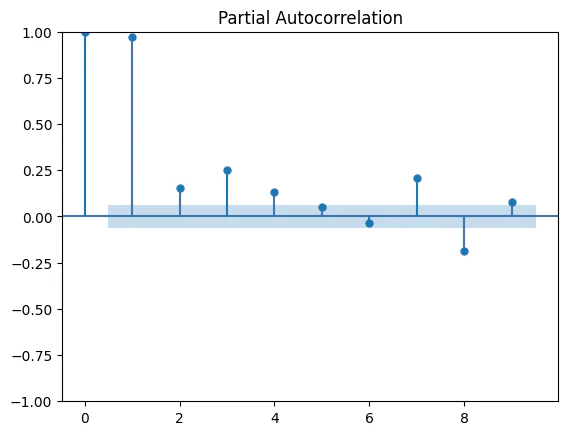
ここではコレログラムを作成し、可視化してみます。
import statsmodels.api as sm
fig_acf = sm.graphics.tsa.plot_acf(musical_avg_data, lags=102) #1年=51週×2=102
plt.show()
fig_pacf =sm.graphics.tsa.plot_pacf(musical_avg_data, lags=102) #1年=51週×2=102
plt.show()
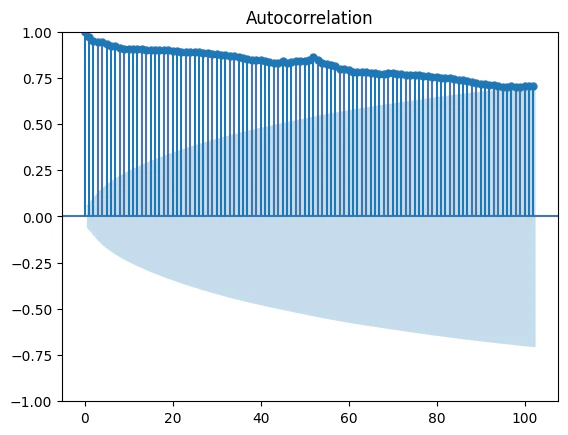
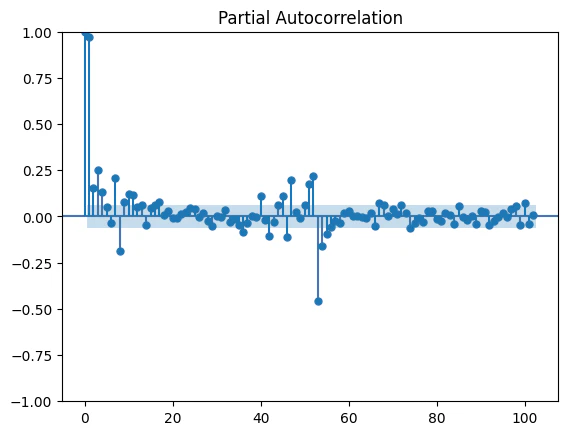
※何度か試した末、lags=102で出しています。
当初の目論見ではlags=51で良い感じになるのでは、と思っていたのですが、あまりうまく行かなかったので、2年≒102週周期で出して見たところそれっぽくなりました。
しかしながら、いかんせん数が大きすぎて「本当に…?」という気持ちになります。
そこで、もっと数を減らして全体的な傾向を把握したいと思います。
具体的には、「週」で見てきたデータを一度「年」で見直してみる作業をしていきます。
6(の補足作業).周期を確認するため「年」ベースでデータを見直す
一旦元データに立ち返り、Date.Year単位で同じことをしていきます。
基本的に繰り返しの作業なので、コードを一気に載せつつ、自分用として補足的にコメントを残していきます。
#元データから年単位でまとめるデータを作成
#musical_dataで削除したデータを再度こちらでも削除するためDate.Fullでグループ分け
musical_Year=bw_data[bw_data['Show.Type']=='Musical']
drop_col = ['Date.Day','Date.Month','Date.Year','Statistics.Capacity', 'Statistics.Gross Potential','Statistics.Performances']
musical_Year=musical_Year.drop(drop_col,axis=1)
musical_Year['Date.Full']=pd.to_datetime(musical_Year['Date.Full'])
musical_Year=musical_Year.groupby('Date.Full').sum()
musical_Year=musical_Year.sort_index(ascending=True)
musical_Year=musical_Year.reset_index() #indexの振り直し1
musical_Year=musical_Year.drop(range(264)) #musical_dataと同様のデータを削除
musical_Year=musical_Year.reset_index() #indexの振り直し2
#Date.Fullでグループ分けするためにYearを抜いたので、Date.Fullから年データを別カラムに反映(Year有りでグループ化すると、年の情報が合計されてしまうため)
musical_Year['Date.Year']=musical_Year['Date.Full'].dt.strftime('%Y')
musical_Year=musical_Year.groupby('Date.Year').sum()
musical_Year=musical_Year.drop('index',axis=1) #一回目のindex振り直しが「index」カラムとして残ってしまっていたので削除
# 平均単価カラムを追加
musical_Year['AveragePrice']=musical_Year['Statistics.Gross']/musical_Year['Statistics.Attendance']
del musical_Year['Statistics.Attendance']
del musical_Year['Statistics.Gross']
musical_Year_data=musical_Year
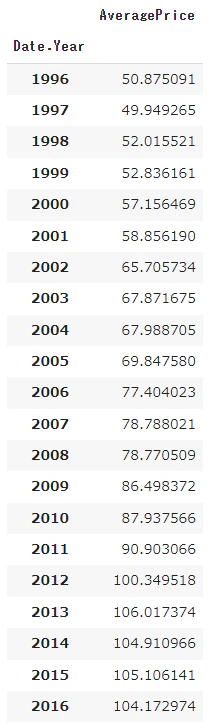
print(musical_Year_data)
#可視化(大まかな変遷に違いが無いかを確認)
from matplotlib import pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
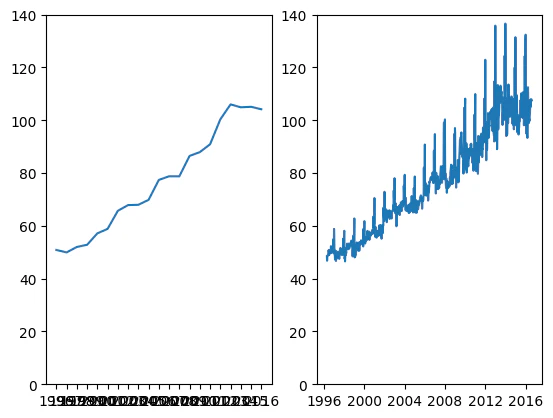
ax1.plot(musical_Year_data) #新たに作成した「年」単位の平均単価推移
ax1.set_ylim(0, 140)
ax2.plot(musical_avg_data) #今まで見てきた「週」単位の平均単価推移
ax2.set_ylim(0, 140)
plt.show()
#周期数の確認(「年」単位のグラフで確認)
fig_acf_year = sm.graphics.tsa.plot_acf(musical_Year_data, lags=9)
fig_pacf_year =sm.graphics.tsa.plot_pacf(musical_avg_data, lags=9)
plt.show()
1.年ごとの平均単価
2.平均単価推移(左:年ごと/右:週ごと)
3.コレログラム(年ごと)
年ごとの平均単価の推移が週ごとと同様の傾向にあるかを確認し、コレログラムにて周期を検討しました。
この内容から見ても、周期は2年≒102週と考えて問題なさそうです。
6(の補足作業その2).季節調整済み系列の作成
ここまでの結果から「2年≒102週」周期があることがわかったので、季節調整済み系列を作成してみます。
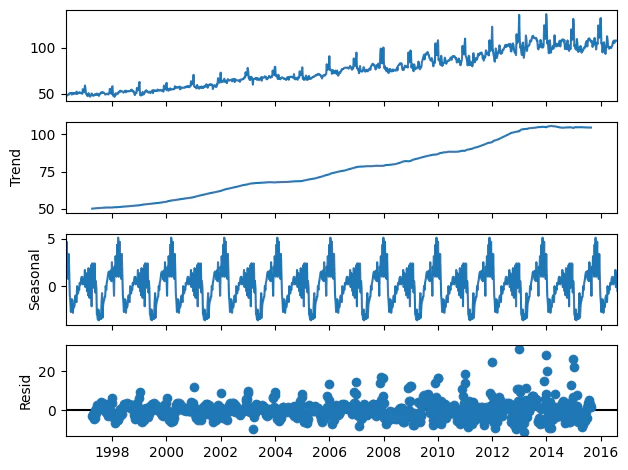
#季節調整済み系列を作成(2年周期=102週分)
res = sm.tsa.seasonal_decompose(musical_avg_data,period=102)
fig_seasonal = res.plot()
plt.show()
7.SARIMAモデルを用いた予測モデルの構築~パラメータの決定~
ここからやっと予測モデルの構築に作業を移していきます。
先述の通り、今回はSARIMAモデルを用いて時系列解析および予測モデルの構築を進めていきます。
SARIMAモデルを用いるにあたり、パラメータ(p,d,q),(sp,sd,sq)をBICによって適切な値を調べるプログラムで決定していきます。
パラメータs=102で引き続き進行します。
import warnings
import itertools
#パラメータ決定のための関数を定義
def selectparameter(DATA,s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs,results.bic)
except:
continue
return parameters[np.argmin(BICs)]
#関数をデータに適用
selectparameter(musical_avg_data,102)
…
……
………
計算が一向に終了しない…
周期数があまりにも大きすぎるため、計算が終わらないという事態が発生してしまいました。
後から学びましたが、そもそもSARIMAモデル自体が周期数が大きすぎるものには不向きとのこと。
このパターンだと機械学習を用いた分析がどうも良さそうです。
というわけで一旦暗礁に乗り上げてしまったのですが、ここまで検討してきたことももったいないので、これはこれでできる限り活かす形で最後まで行きたいと思います。
とはいえ週ごとの分析は事実上不可能に近いため、ちょうど先程比較用に作った「年単位でまとめているデータmusical_Year_data」を用い、そちらで予測モデルを組み上げることに方向転換をしてみたいと思います。
7のやり直し.SARIMAモデルを用いた予測モデルの構築~パラメータの決定:年ごとver.~
selectparameter(musical_Year_data,2)
musical_Year_dataについてs=2でパラメータを確認していきます。
出力結果は下記の通りとなりました(計算過程は省略いたします)。
[(0, 1, 0), (0, 1, 1, 2), 104.03668374627904]
(p,d,q)=(0,1,0)
(sp,sd,sq,s)=(0, 1, 1, 2)
という対応関係になっています。
こちらのパラメータを用いて、SARIMAモデルを適用していきます。
8.SARIMAモデルを用いた予測モデルの構築
モデルの精度を確認するため、訓練データとして使用する期間を切り分けてモデルに適用をさせてみます。
今回は後ろ3年間(2014~2016)確認用として残しておき、それ以前のデータで学習をさせてみます。
musical_Year_train=musical_Year_data['1996':'2015']
SARIMA_musical_Year_train= sm.tsa.statespace.SARIMAX(musical_Year_train,order=(0, 1, 0),seasonal_order=(0, 1, 1, 2)).fit()
train_pred_1 = SARIMA_musical_Year_train.predict('2000', '2014') #グラフでの比較用にモデルを適用した場合の2000年~2014年の結果も出してみます
train_pred_2 = SARIMA_musical_Year_train.predict('2014', '2016') #予測期間
print(train_pred_2)
# 出力結果(予測期間のみ)
2014-01-01 109.989653
2015-01-01 107.507053
2016-01-01 108.514106
Freq: AS-JAN, Name: predicted_mean, dtype: float64
このようにして、SARIMAモデルを適用し、予測結果を出力しました。
年ごとにまとめたこともあり、予測が少なくなったこともあり、グラフでより確認しやすいように、2000年~2014年までの期間にモデルを適用した場合の結果もtrain_pred_1として用意しておきます。
これらの結果を元データと組み合わせる形で可視化してみます。
※次のコードの最初の4行では、Date.Yearの表示を予測と同じyyyy-mm-ddに元データを揃える作業を行っています。
musical_Year_data.reset_index(inplace=True)
musical_Year_data['Date'] = pd.to_datetime(musical_Year_data['Date.Year'].astype(str) + '-01-01')
musical_Year_data.set_index('Date', inplace=True)
musical_Year_data = musical_Year_data.drop("Date.Year", axis=1)
plt.plot(musical_Year_data,label="original(1996-2016)")
plt.plot(train_pred_1, color="g",label="pred(2000-2014)")
plt.plot(train_pred_2, color="r",label="pred(2014-2022)")
plt.legend(loc='best')
plt.title('pred1&2')
plt.show()
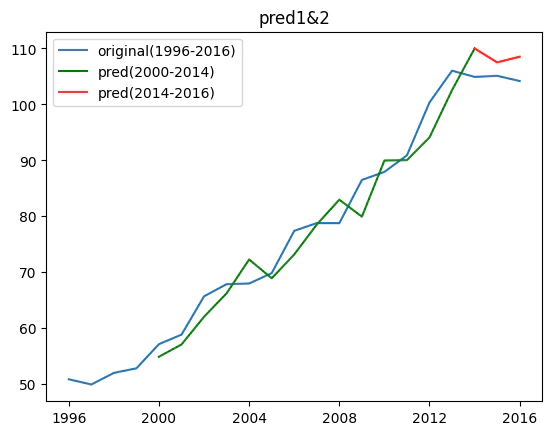
青が実際の推移、赤が今回の予測範囲です。
2014年は実際が104.9ドルに対し、予測値は109.9ドル、
2015年は実際が105.1ドルに対し、予測値は107.5ドルという結果となっています(小数点第2位以下切捨)。
このモデルを便宜上「pred1&2」と呼ぶことにします。
次に、精度が向上するかどうかSARIMAモデル適用時のパラメータを
(p,d,q)=(0,1,0)
(sp,sd,sq,s)=(0, 2, 2, 2)
に変更し、再度同様の予測をしてみたいと思います。
※経緯は省略いたしますが、事前に定義していたselectparameter()内でp = d = q のrangeをrange(0, 2)から range(0, 3)に変更し、出力されたパラメータとなります。
train_pred_3 = SARIMA_musical_Year_train_2.predict('2000', '2014')
train_pred_4 = SARIMA_musical_Year_train_2.predict('2014', '2016')
print(train_pred_4)
plt.plot(musical_Year_data,label="original(1996-2016)")
plt.plot(train_pred_3, color="g",label="pred(2000-2014)")
plt.plot(train_pred_4, color="r",label="pred(2014-2016)")
plt.legend(loc='best')
plt.title('pred3&4')
plt.show()
# 出力結果(予測期間のみ)
2014-01-01 110.163172
2015-01-01 111.169395
2016-01-01 107.768861
Freq: AS-JAN, Name: predicted_mean, dtype: float64
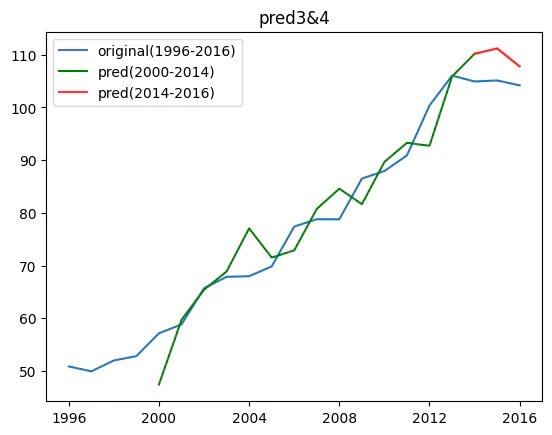
こちらも青が実際の推移、赤が今回の予測範囲です。
2014年は実際が104.9ドルに対し、予測値は110.1ドル、
2015年は実際が105.1ドルに対し、予測値は111.1ドルという結果となっています(小数点第2位以下切捨)。
このモデルを便宜上「pred3&4」と呼ぶことにします。
ここまでの結果をまとめたものが以下になります。
| 年 | 実際の値($) | pred1&2との誤差 | pred3&4との誤差 |
|---|---|---|---|
| 2014 | 104.9 | -5.0 | -5.2 |
| 2015 | 105.1 | -2.4 | -6.0 |
| 2016 | 104.1 | -4.4 | -3.6 |
これらを踏まえて、予測値と実績値の乖離がより少ない「pred1&2」をモデルとして採用したいと思います。
9.予測モデルによる将来の平均単価予測の試み
ここまででモデル作成自体は終了なので、最後に将来の予測を見て今回の試みは一旦終了したいと思います。
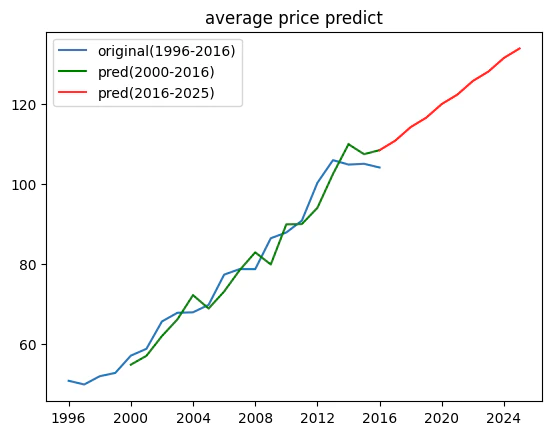
先ほどのグラフから更に伸ばして行く形で、2025年までの予測を見ていきたいと思います。
avgprice_pred = SARIMA_musical_Year_train.predict('2016', '2025')
print(avgprice_pred)
plt.plot(musical_Year_data,label="original(1996-2016)")
plt.plot(train_pred_1, color="g")
plt.plot(train_pred_2, color="g",label="pred(2000-2016)")
plt.plot(avgprice_pred, color="r",label="pred(2016-2025)")
plt.legend(loc='best')
plt.title('average price predict')
plt.show()
# 出力結果
2016-01-01 108.514106
2017-01-01 110.870094
2018-01-01 114.278060
2019-01-01 116.634048
2020-01-01 120.042013
2021-01-01 122.398002
2022-01-01 125.805967
2023-01-01 128.161955
2024-01-01 131.569921
2025-01-01 133.925909
Freq: AS-JAN, Name: predicted_mean, dtype: float64
終わりに
「平均単価の値上がりを予測するモデル構築」という当初の目的については一旦の形を見ることができました。
年ごとのデータに変換し、SARIMAモデルを適用することで予測モデルを構築し、将来の値上がり幅を確認しました。
一方で、今後に向けた課題も確認できました。
-
より細かいデータ(周期数が大きくなる)での予測モデルの構築ができていない
季節変動に関する項でも述べた通り時期ごとの浮き沈みが特に出ているデータでもあるため、それらを反映し週ごとに予測を立てられたらベストだと考えています。
この点については、LSTMによるモデル構築を今後試みていきたいと考えています。
-
その他の特徴による影響有無の考慮
今回は冒頭でも示したとおり、「時系列」と「平均単価」のみに絞り予測をしましたが、実際にはそれでは不十分だと考えています。
例えば元データを改めて見ても、順調に値上がりをしてきた中で2013年をピークに一旦落ち着きながら2年周期の下降に入っており、何か別の要素によって影響を受けている可能性もあります。その内容如何によっては、きれいな右肩上がりのモデルにも影響がありそうな気がしています。
また、「人気=需要が高まる=値段が上がる」という流れがある以上、人気作の登場が平均単価の底上げを行っているかなども本来考慮する必要があるのですが、かなり複雑(そもそもどうやって作品が「人気」と言えるかを考えるところから始めなければいけない)でしたので、その点にはあえて触れずに来ました。
また、3つ目の課題にも通じますが「社会的な要因」についても、どこかで考慮が必要かもしれないと思っています。
これらは今後の要検討課題です。
-
コロナ禍を踏まえた予測ができていない
今回、元データが2016年中頃までだった、ということもあり、その時点から先の予測を出しています。
そのため、当然2020年~2021年の予測も入っていますが、実際のブロードウェイではコロナ禍の影響により、2020年3月12日~2021年9月ごろまで公演が中止になっています1)。
この予測モデルは、あくまでも「コロナ禍がなかった場合の予測推移」となってしまっており、2021年公演再開以降のコロナ禍の影響について全く考慮がされていないものになっています。
この点については、アフターコロナの情報をもとに回帰モデルもしくは学習モデルを作成する必要があると考えています。
以上、まとめと反省点でした。
取り急ぎ次に取り掛かるべき課題はLSTMを用いたモデル作成となってくるので、引き続き学習をしながらまとめていきたいと思います。
長らくの間お付き合いをいただき、ありがとうございました。
- ^「新型コロナにより1年以上も閉鎖していたNYブロードウェイの劇場が9月からフルキャパシティで再開へ」(2023年12月13日閲覧)
このブログはAidemy Premiumのカリキュラムの一環で、受講修了要件を満たすために公開しています