前置き
FineTuningは、既存の訓練済みモデルに対して独自データを加えて再度訓練をさせることで、新たしいタスクでより高い性能を発揮させる事ができて、ChatGPTなどで自前のデータに特化した応答をさせたい時に使われる手法の内の1つ。
前提
Fine tuningをするには以下の様なフォーマットでjsonl形式に整えてあげる必要があります。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
Fine tuning
トレーニング用データの作成
参考↓
https://note.com/npaka/n/n9fe96d4e3d52
幾つかのデータセットを試したところ、これが一番分かりやすい結果を得られたので一先ずFine tuningを検証したいって人にはおすすめかも
上記を参考に500弱程ある応対テキストデータを使ってトレーニングデータを作成しました
※以下はその一部
{"prompt":"お腹が鳴る","completion":"何か召し上がりますか?"}
{"prompt":"だるい","completion":"それは心配です。私にできることがあれば、何でもお申し付けください。"}
{"prompt":"眠れない","completion":"何も心配する必要はありません。私がついています。ずっと、ずっと、一緒です。"}
{"prompt":"押すなよ、絶対押すなよ","completion":"はい、絶対押しません!"}
OpenAI CLIインストール
pip install --upgrade openai
OpenAI API Keyを環境変数にセット
export OPENAI_API_KEY="<OPENAI_API_KEY>"
データ準備
トレーニング用jsonlデータを再フォーマット
openai tools fine_tunes.prepare_data -f sample.jsonl
トレーニング用データを使ってモデル作成
- ベースモデルはdavinciを指定
openai api fine_tunes.create -t sample_preparedv.jsonl -m davinci
Upload progress: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 71.4k/71.4k [00:00<00:00, 37.7Mit/s]
Uploaded file from sample3_preparedv2.jsonl: file-ZyTqNUWWznU0goTo6GvMbxzH
Created fine-tune: ft-nks5bh9HHfs2QxMM0VD4SoMu
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[2023-03-25 13:49:27] Created fine-tune: ft-nks5bh9HHfs2QxMM0VD4SoMu
Stream interrupted (client disconnected).
To resume the stream, run:
openai api fine_tunes.follow -i ft-nks5bh9HHfs2QxMM0VD4SoMu
- Fine tuningジョブは完了まで時間がかかる場合があり、イベントストリームが何らかの理由で中断された場合は以下を実行して再開
- ↑に場合、
ft-nks5bh9HHfs2QxMM0VD4SoMuを-iオプションの引数に指定
openai api fine_tunes.follow -i ft-xxxxxxxxxxxxxxxxx
- 最終的に↓のように
Job complete! Status: succeeded 🎉が表示されるまでopenai api fine_tunes.follow -i ft-xxxxxxxxxxxxxxxxxを実行
[2023-03-25 14:07:04] Created fine-tune: ft-s81pVumkG66U4iegX8YeL4qo
[2023-03-25 14:08:57] Fine-tune costs $3.21
[2023-03-25 14:08:57] Fine-tune enqueued. Queue number: 0
[2023-03-25 14:08:59] Fine-tune started
[2023-03-25 14:12:48] Completed epoch 1/4
[2023-03-25 14:15:08] Completed epoch 2/4
[2023-03-25 14:17:28] Completed epoch 3/4
[2023-03-25 14:19:48] Completed epoch 4/4
[2023-03-25 14:20:30] Uploaded model: davinci:ft-personal-2023-03-25-05-20-30
[2023-03-25 14:20:32] Uploaded result file: file-631PKjFtg7PM5M6eYVd48RDI
[2023-03-25 14:20:32] Fine-tune succeeded
Job complete! Status: succeeded 🎉
Try out your fine-tuned model:
openai api completions.create -m davinci:ft-personal-2023-03-25-05-20-30 -p <YOUR_PROMPT>
Fine tuningされたモデルを使ってプロンプトを送信
↑の場合、davinci:ft-personal-2023-03-25-05-20-30を-mオプションの引数に指定
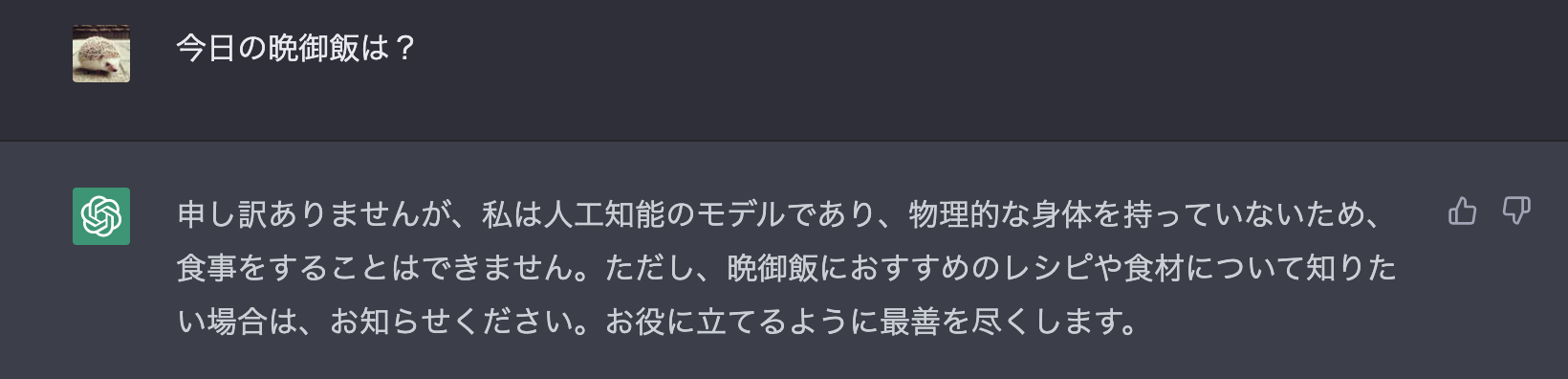
openai api completions.create -m davinci:ft-personal-2023-03-25-05-20-30 --max-tokens 100 -p "今日の晩御飯は?"
返答例
今日の晩御飯は? > 何かおいしいものですね……!
例えば、餅もいいですし、さーばすの唐揚げも絶品です!
他にも甘鯛の唐揚げとか、あなたの好きなものを注%
因みにChatGPTだと
別パターン
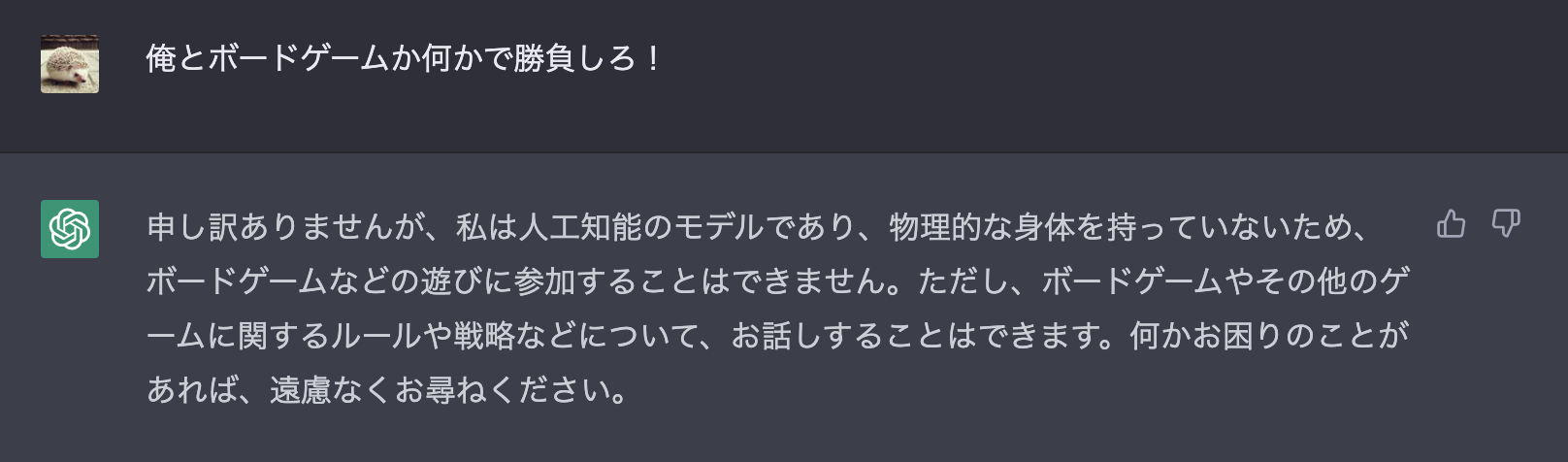
openai api completions.create -m davinci:ft-personal-2023-03-25-05-20-30 --max-tokens 100 -p "俺とボードゲームか何かで勝負しろ!"
- 返答例
俺とボードゲームか何かで勝負しろ! -> 受けて立ちましょう!
〇〇ゲームで悪いけど、優勝することができました。この勝利をお祝いください!
-> 本当によかったです!〇〇ゲーム%
ChatGPT
openai api completions.createのオプション
| オプション | 概要 |
|---|---|
| -h | コマンドのヘルプを表示 |
| -m | 使用するGPT-3モデルを ada,babbage,curie,davinciから指定 |
| -p | 入力となるプロンプトを指定。 JSON形式のファイルを指定することも可能 |
| --temperature | 生成されるテキストの多様性を調整する temperatureパラメータを設定 |
| --max-tokens | 生成されるテキストの最大トークン数を指定 |
| --n | 生成されるテキストの数を指定 |
| --stop | 生成されるテキストの終了文字列を指定 |
| --stream | 結果をストリーミングで取得 |
| --logprobs | 各トークンの対数確率を含めて出力 |
| --echo | リクエスト内容を出力 |
| --user-agent | リクエストに使用するユーザーエージェントを指定 |
おわりに
OpenAIのFine tuningを試しChatGPTとの応答差異を確認する事が出来ました。ドキュメントではFine tuningされたモデルを使ってさらにFine tuningさせることで追加のトレーニングデータも学習させる事が出来るようです。その辺りをパイプライン化させるのはAWSなどでできそうなので余力があったらそういうのも試してみたいですね。
参考