前提
・利用環境:Databricks、AWS
・参考アーキテクチャ
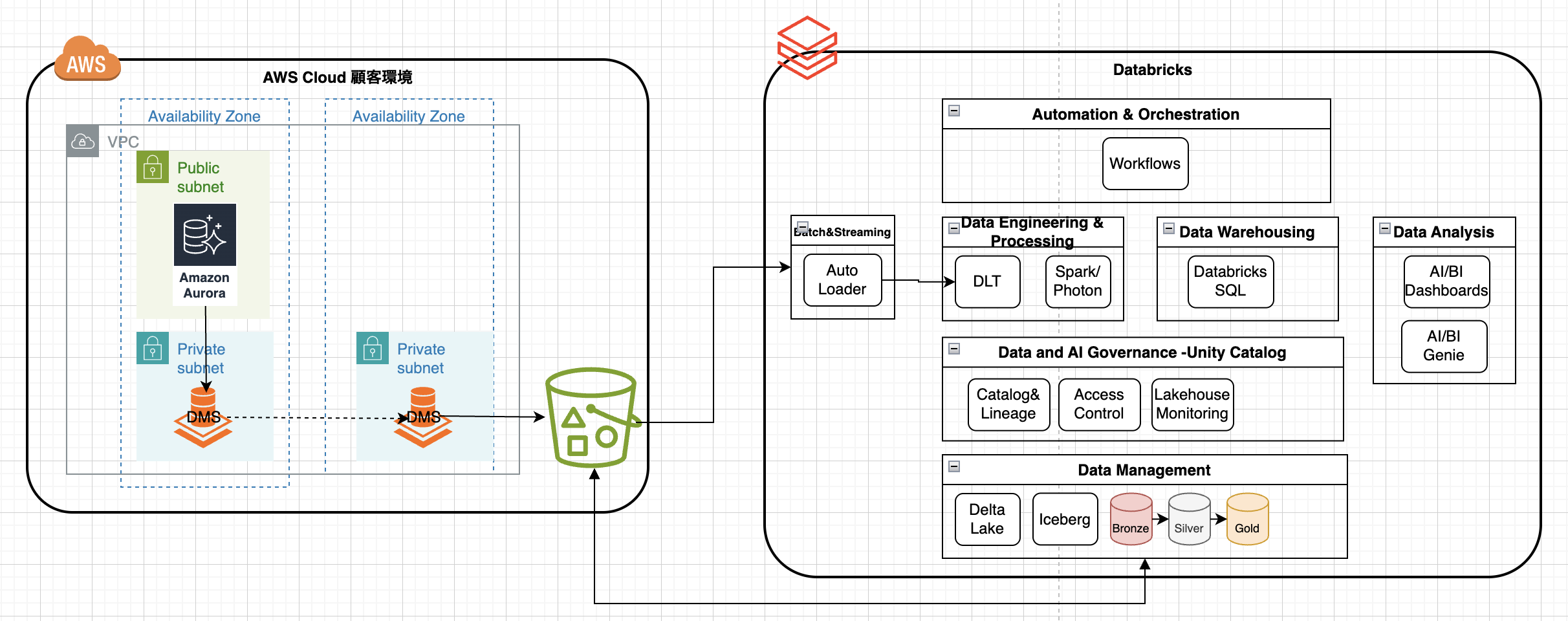
参考ドキュメント & Blog
目次
- Databricksで外部ボリュームを作成
- Databricksのカタログを作成し、ストレージを設定
- Notebookでメダリオンアーキテクチャ処理を作成
- ETLパイプラインを作成
- ワークフローを作成
手順
1.Databricksで外部ボリュームを作成
1)「カタログ」→「外部データ」をクリック

2)「外部ロケーションを作成」をクリック

3)「AWSクイックスタート」→「次のページ」をクリック
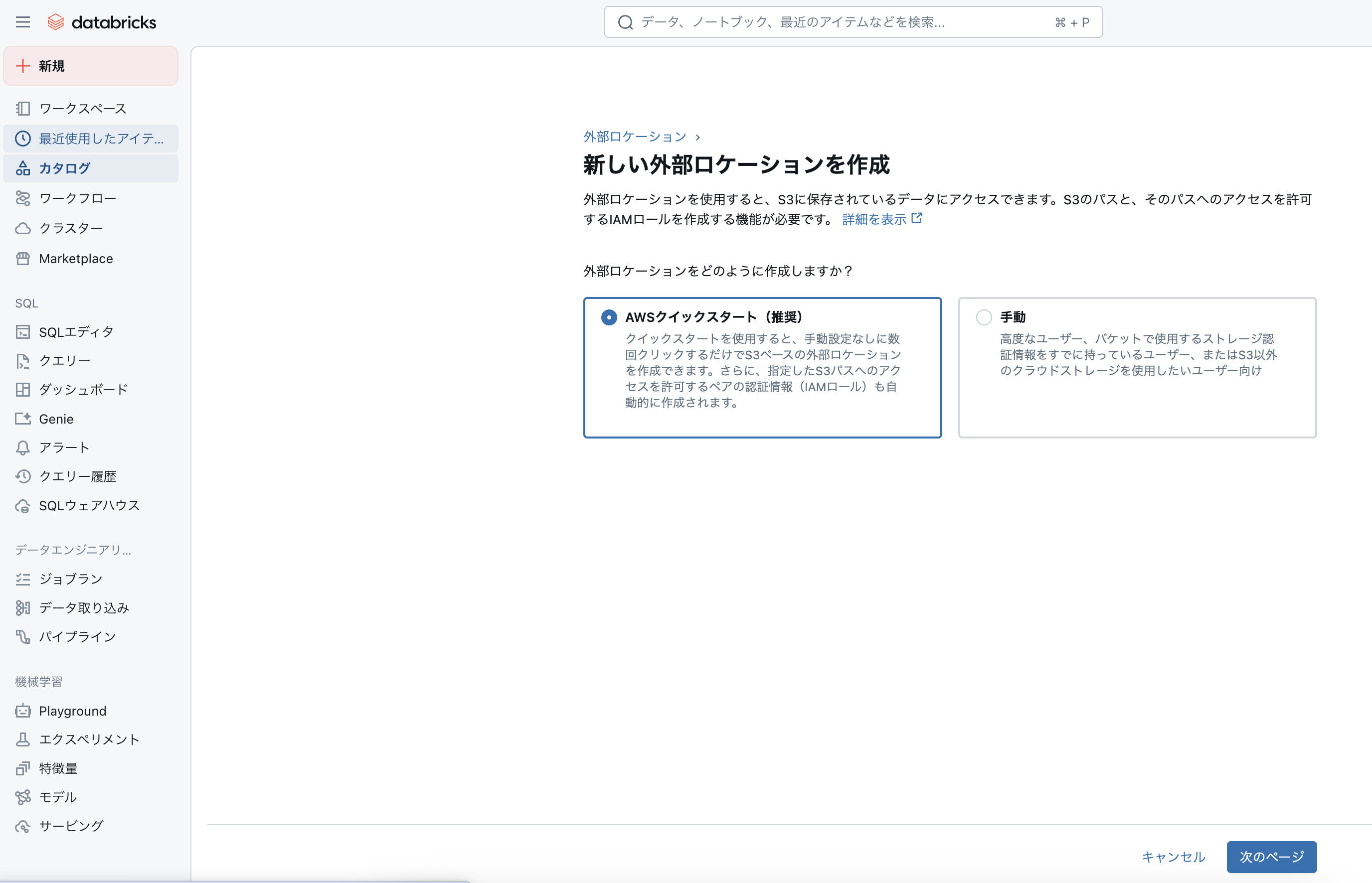
4)S3のパケット名を入力し、「新規トークンを生成」をクリック
例:
パケット名:s3://ho-iceberg(親パケット)
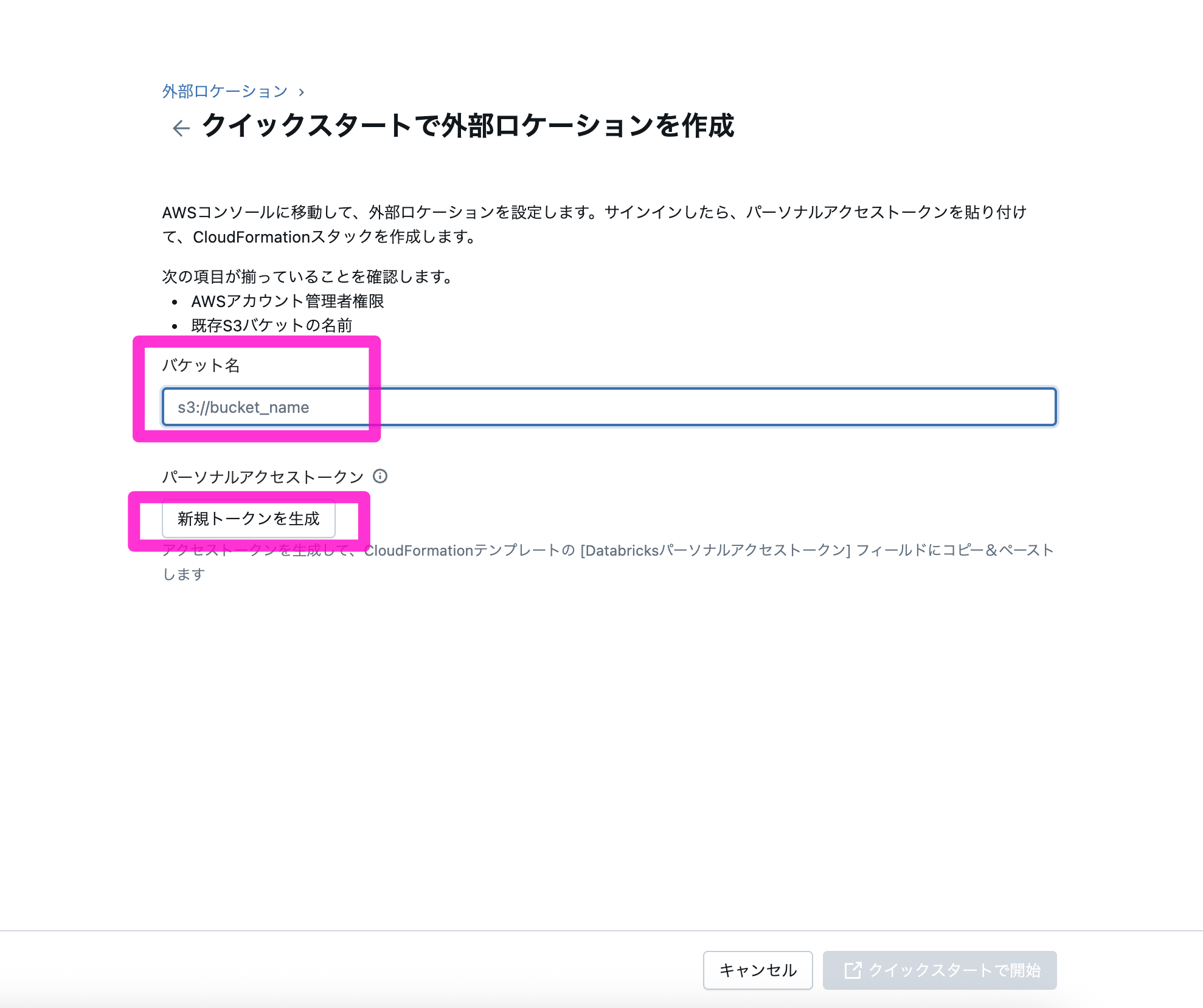
5)表示されるトークンをコピーし、「クイックスタートで開始」をクリック
6)遷移されたAWSのスタックのクイック作成画面のDatabricks Personal Access Token欄にコピーしたトークンを貼り付ける

7)スタック名を適宜変更し、最後の以下をチェックし、「スタックの作成」をクリック
☑︎AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。

8)Statusが「Create_Complete」になったら、Databricksの外部ロケーション一覧にも反映されてることを確認できる


9)外部ロケーションの詳細画面に入り、「接続テスト」をクリックし、成功できるか確認
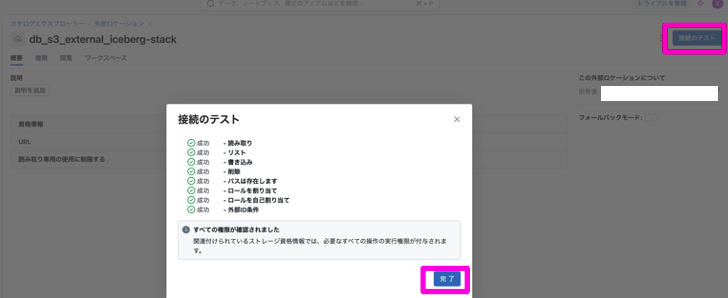
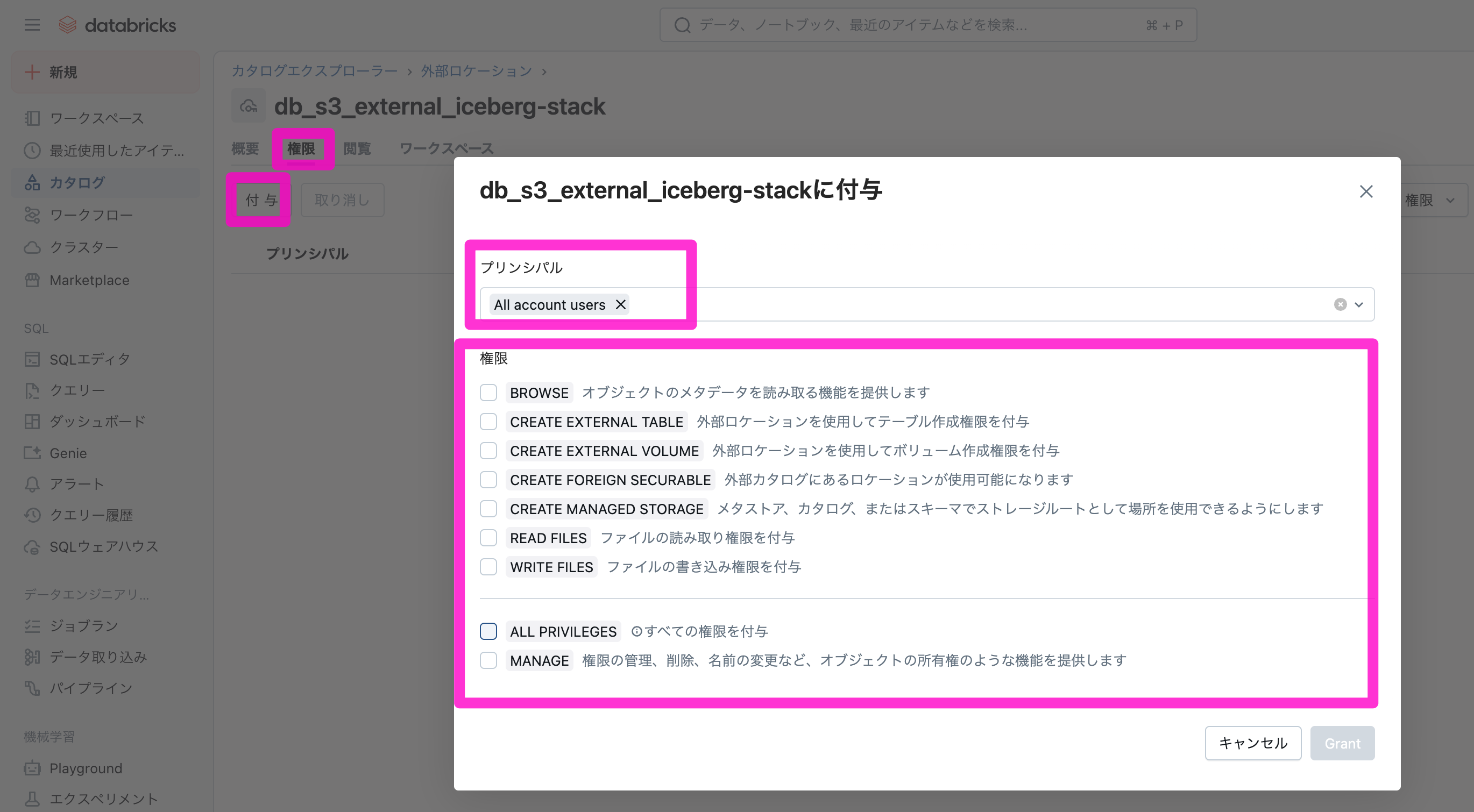
10)「権限」→「付与」をクリックし、対象ユーザー、グループに必要な権限を付与
2.Databricksのカタログを作成し、ストレージを設定
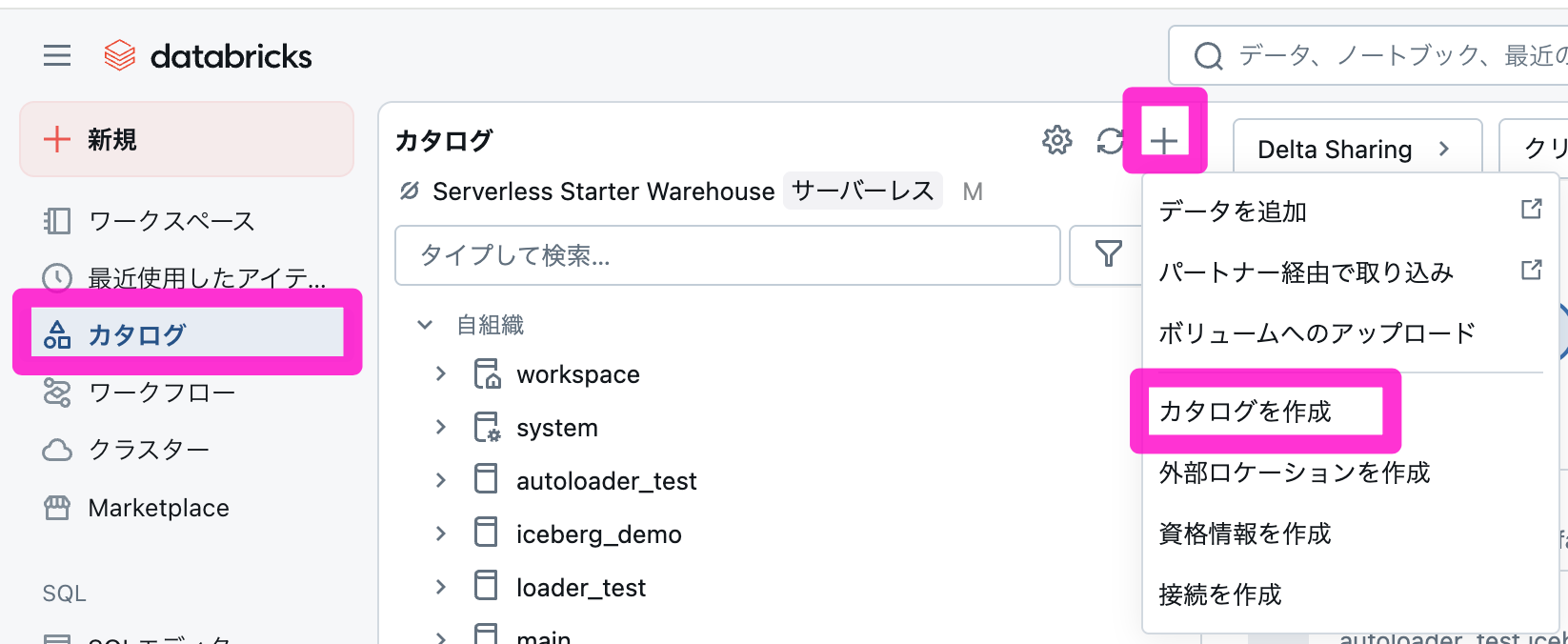
1)「カタログ」→「+」→「カタログを作成」をクリック
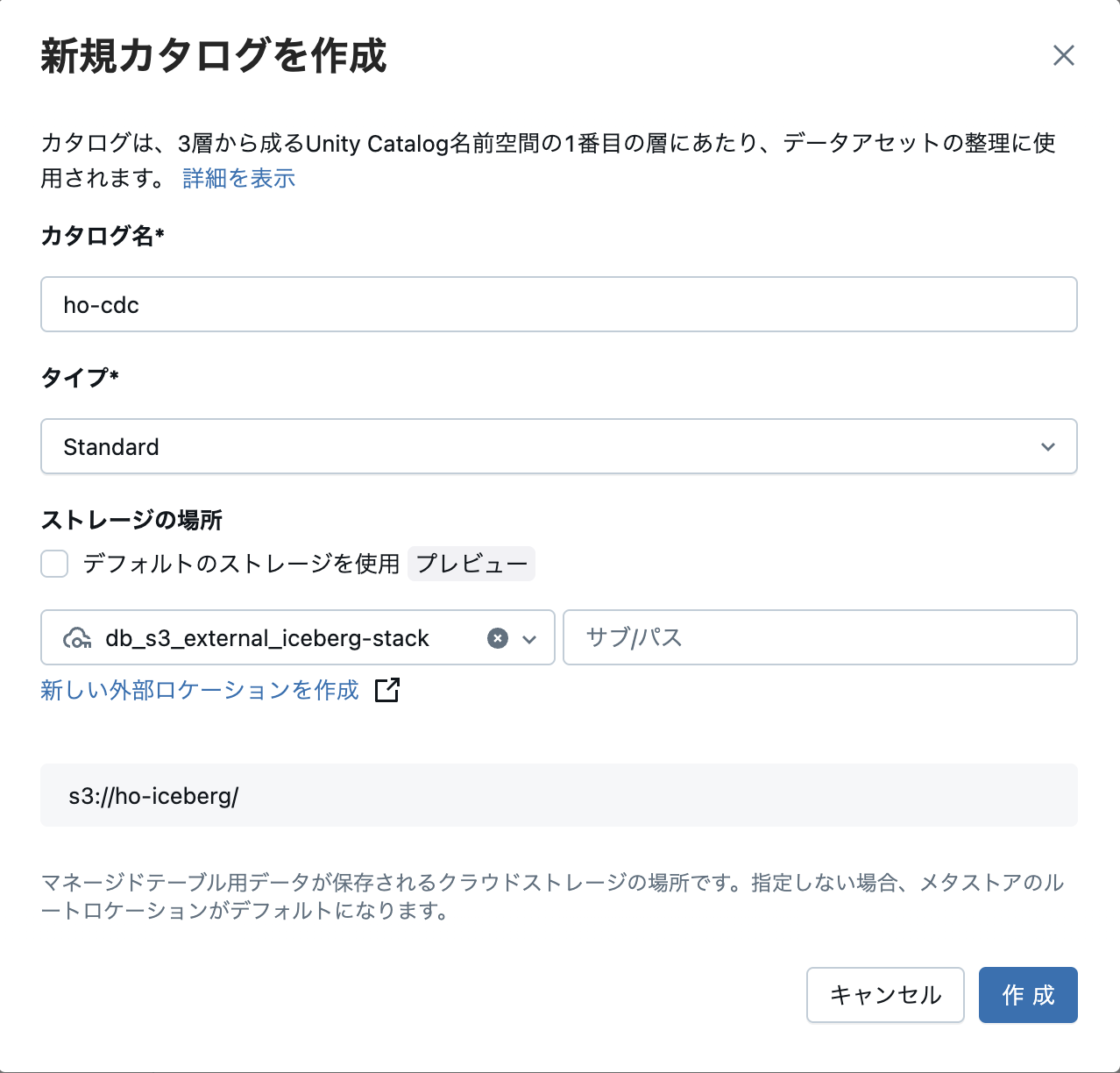
2)上で作成した外部ロケーションを指定して、カタログを作成
例:
カタログ名:ho-cdc
タイプ:Standard
ストレージの場所:上で作成した外部ロケーション
3)カタログを表示し、「詳細」タブからストレージルートと場所を確認

4)「スキーマを作成」をクリック

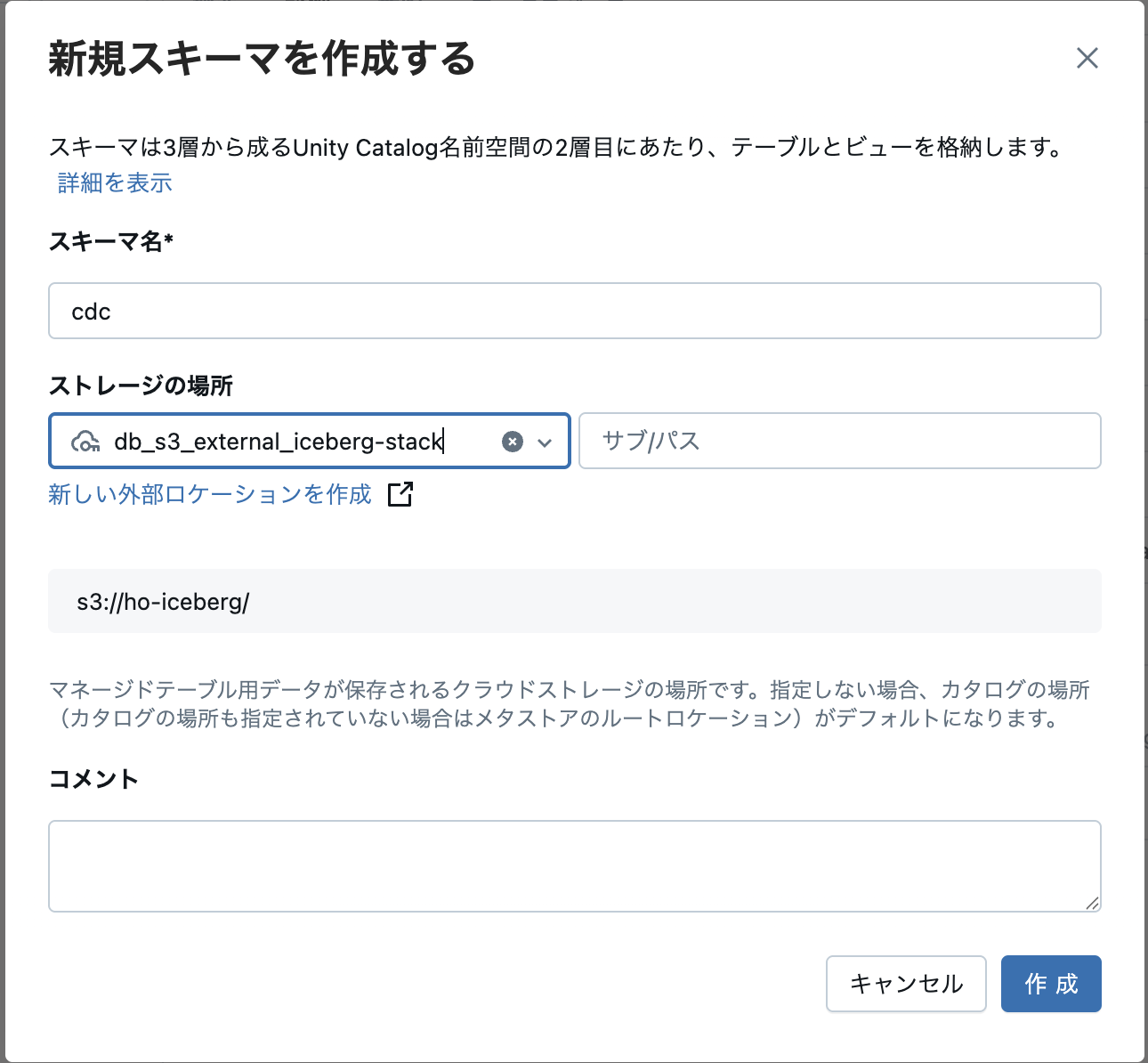
5)スキーマ名とストレージの場所を指定し、「作成」をクリック
6)スキーマの詳細画面で、「作成」→「ボリュームを作成」をクリック

7)下記を参考のS3の外部ボリュームを作成
例:
ボリューム名:raw
ボリュームタイプ:外部ボリューム
外部ロケーション:上で作成したもの
パス:s3://ho-iceberg/raw

8)AWSのrawパケットに入ってるファイルが同期されてることを確認できる
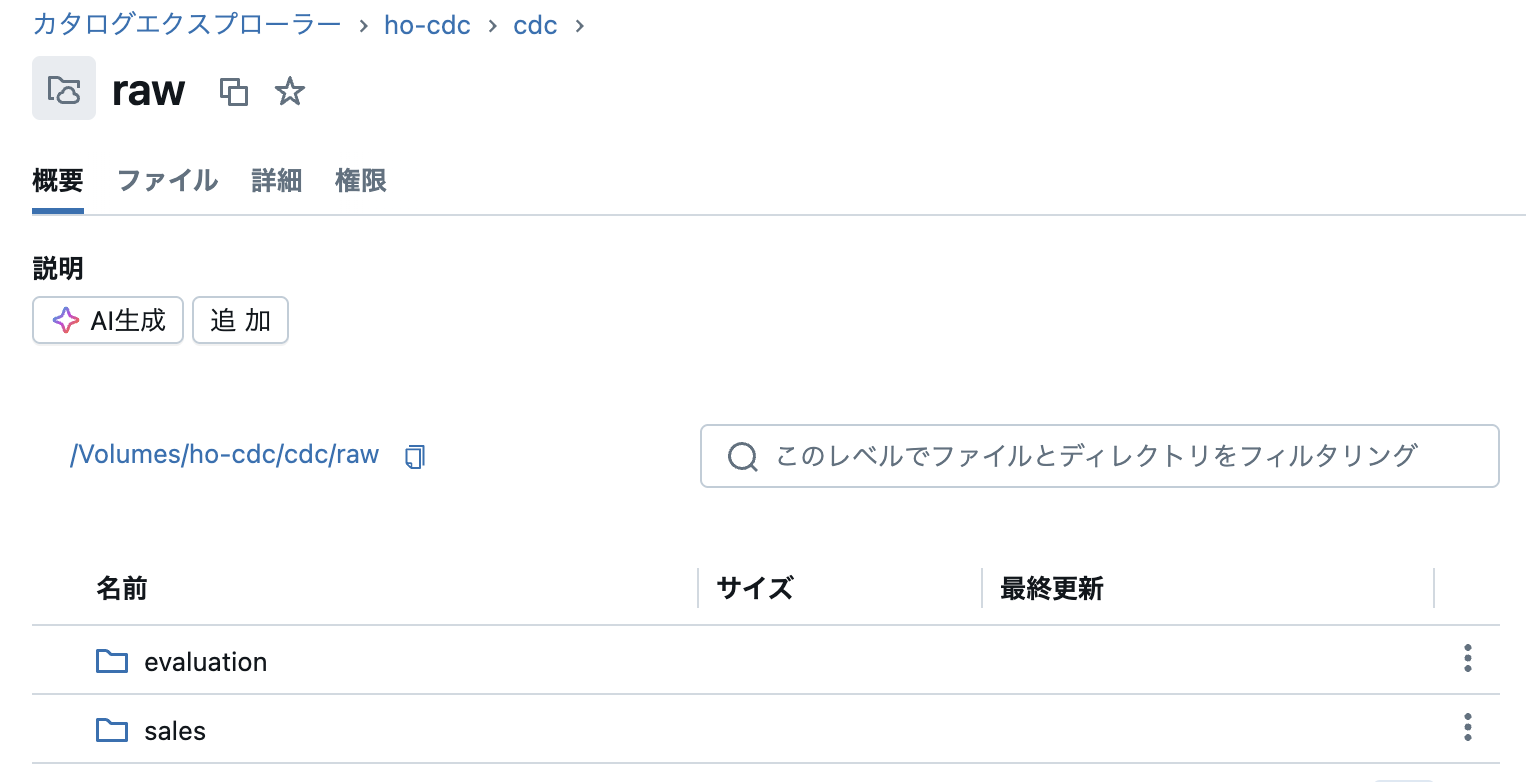
3.NotebookでDLTを作成
1)「ワークスペース」→「作成」→「ノートブック」をクリック

2)デフォルトの言語をSQLに変更し、メダリオンアーキテクチャ用のSQL文を作成
例:
-- Bronzeテーブルに生データを読み込む
CREATE STREAMING TABLE customer_bronze AS SELECT * FROM cloud_files( "/Volumes/ho-cdc/cdc/raw/sales/customer/", "parquet")
-- Bronzeテーブルをクレンジングして、Silverテーブルを作成
CREATE LIVE TABLE customer_silver( CONSTRAINT non_null_name EXPECT (name IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM live.customer_bronze
-- ユースケース別にGoldテーブルを作成
CREATE LIVE TABLE customer_gold AS SELECT * FROM live.customer_silver WHERE name = 'John'

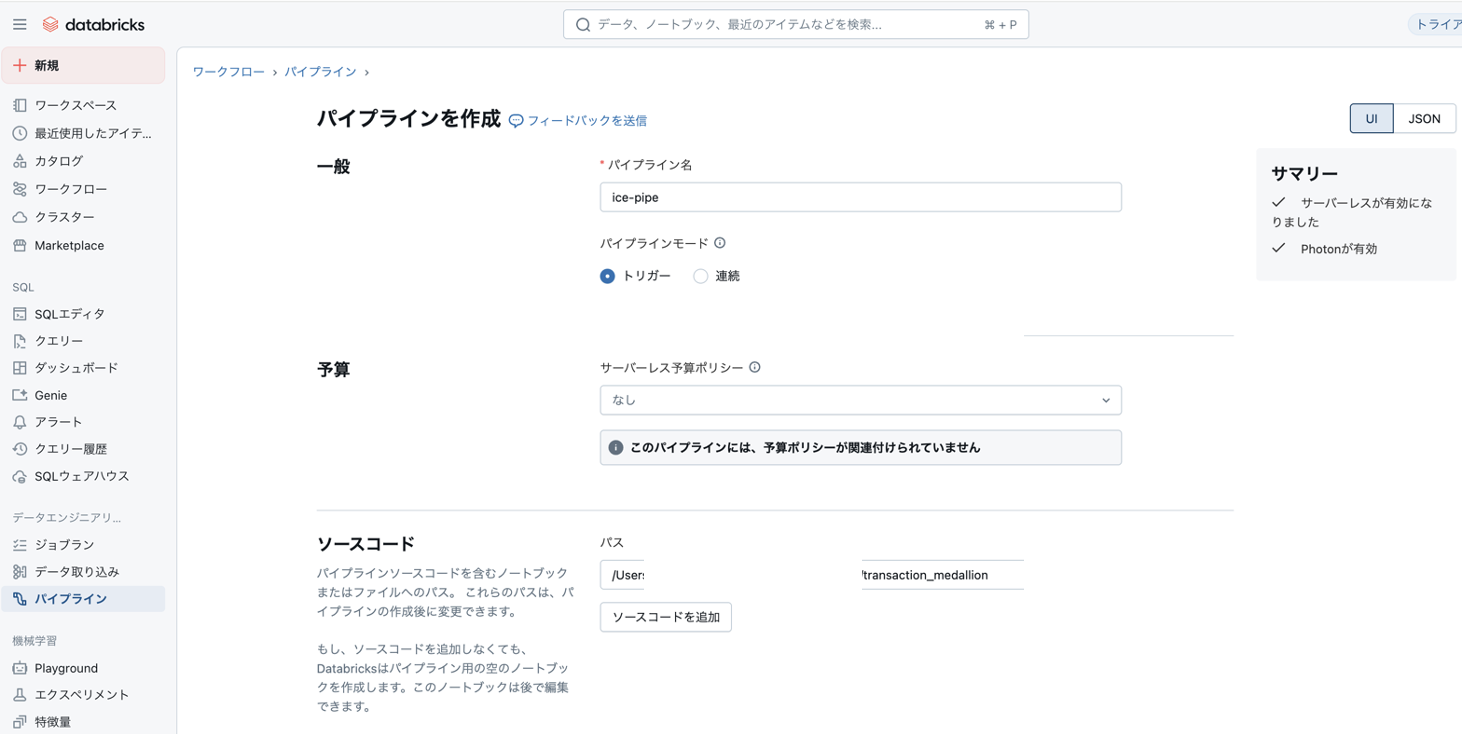
4.パイプラインを作成
1)「パイプライン」→「パイプラインを作成」→「ETLパイプライン」をクリック

2)下記を参考に設定し、パイプラインを作成
例:
・パイプライン名:ho-pipe
・ソースコード:上で作成したノートブックを選択
・デフォルトカタログ:上で作成したカタログ
・デフォルトスキーマ:上で作成したスキーマ

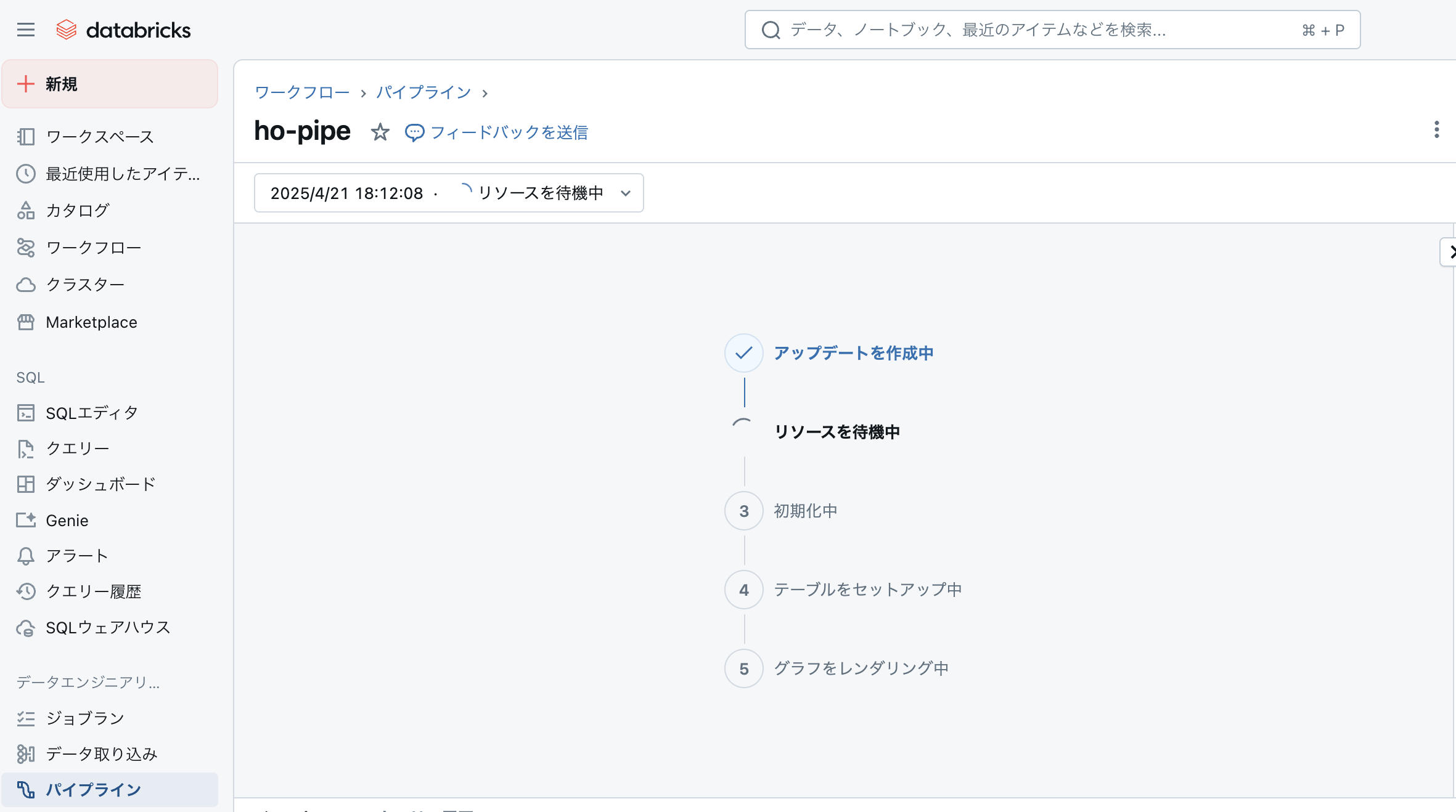
3.「開始」をクリック

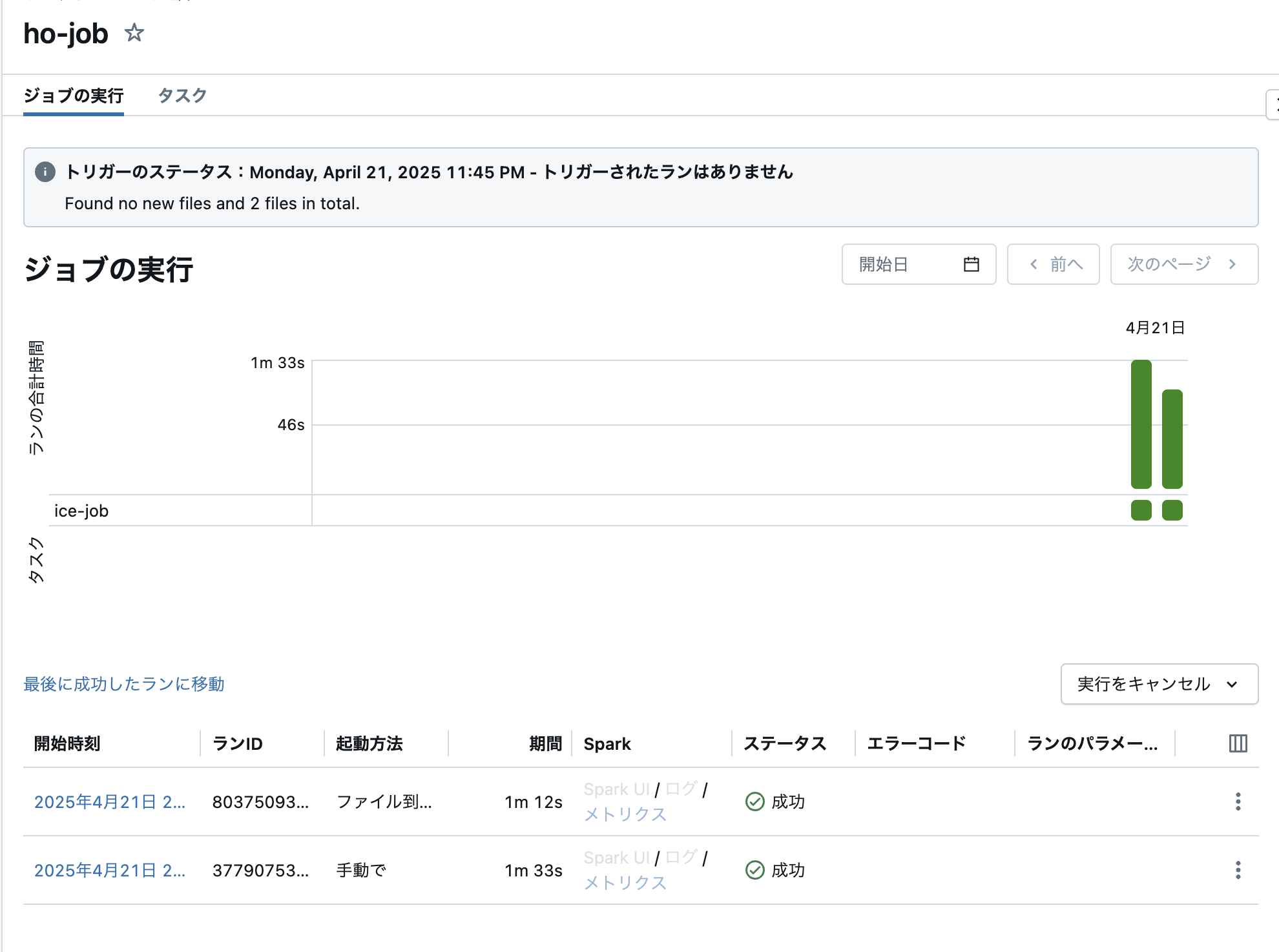
5.ワークフローを作成
1)「ワークフロー」→「ジョブを作成」をクリック

2)以下を参考にジョブを設定
例:
・タスク名:ice-job
・種類:パイプライン
・パイプライン:ho-pipe

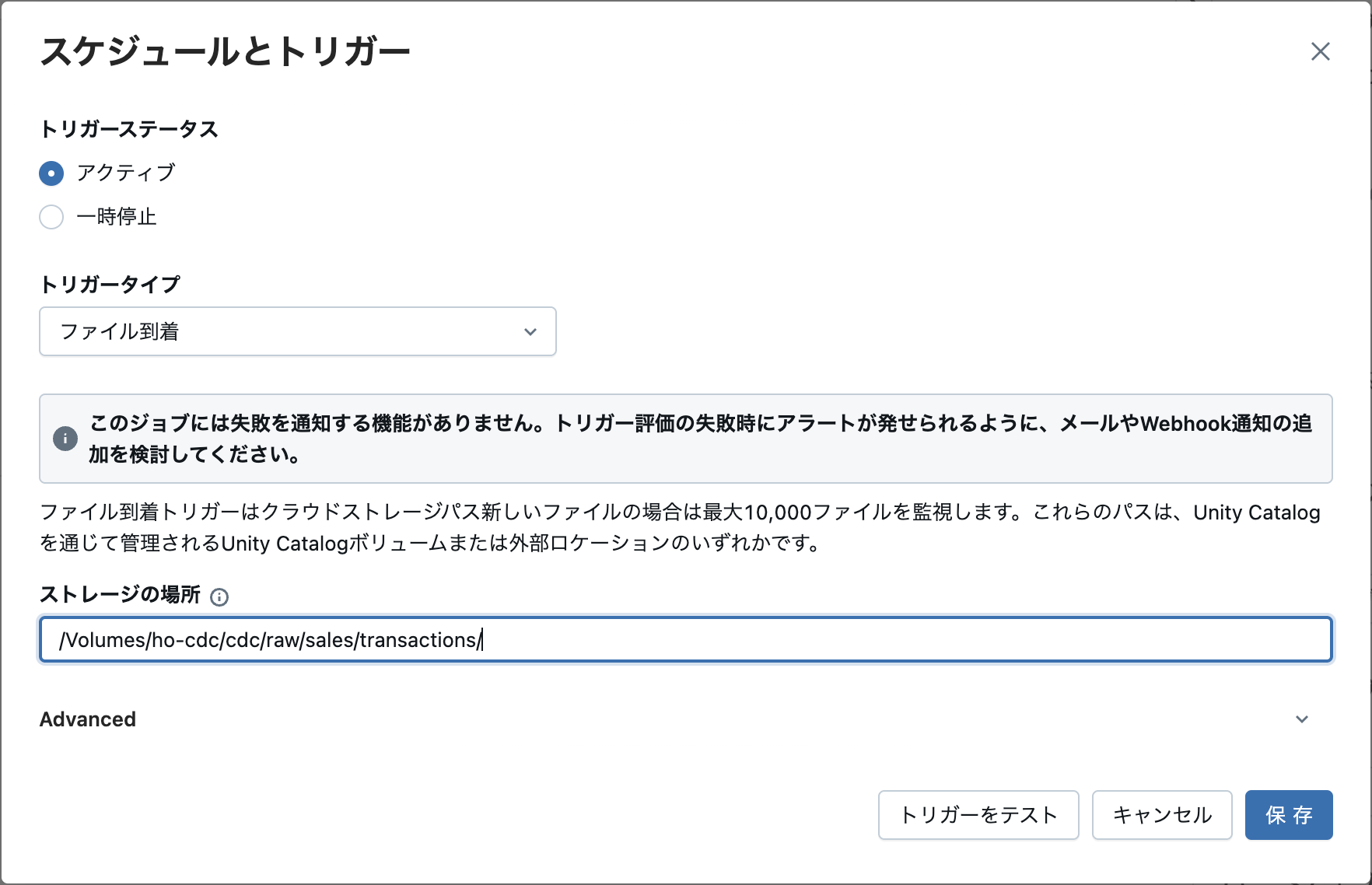
3)スケジュールとトリガーを追加
例:
・トリガーステータス:アクティブ
・トリガータイプ:ファイル到着
・ストレージ場所:外部ボリュームのファイルが追加される場所
4)「今すぐ実行」をクリック

5)ファイルがS3に到着すると、ジョブが自動的に実行されることを確認できる
以上