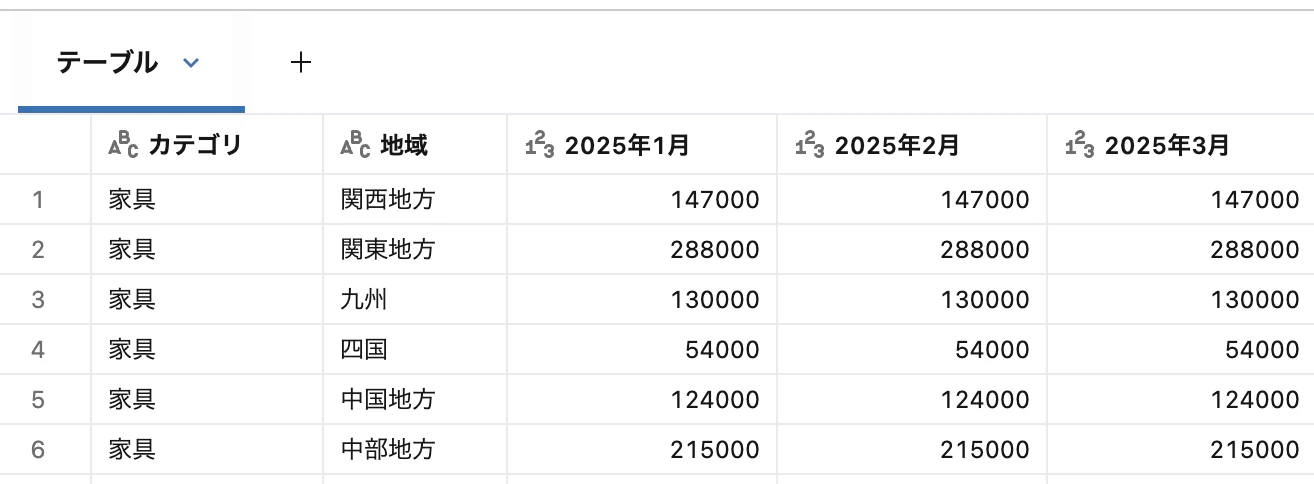
前提
・利用環境:Databricks
・ユースケース
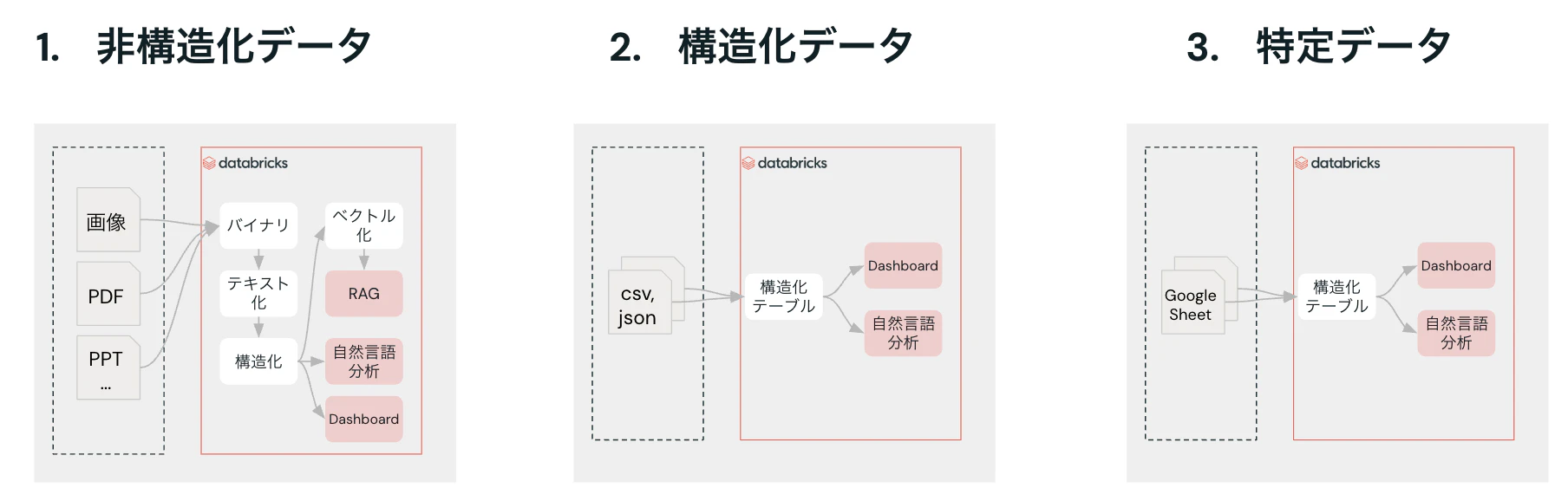
手順
- プレビューを有効化
- OAuth 2.0を構成
- Databricks上でGoogle Driveの接続を作成
- Google Driveからファイルを取り込む
①非構造ファイル
②複数csv
③Worksheet
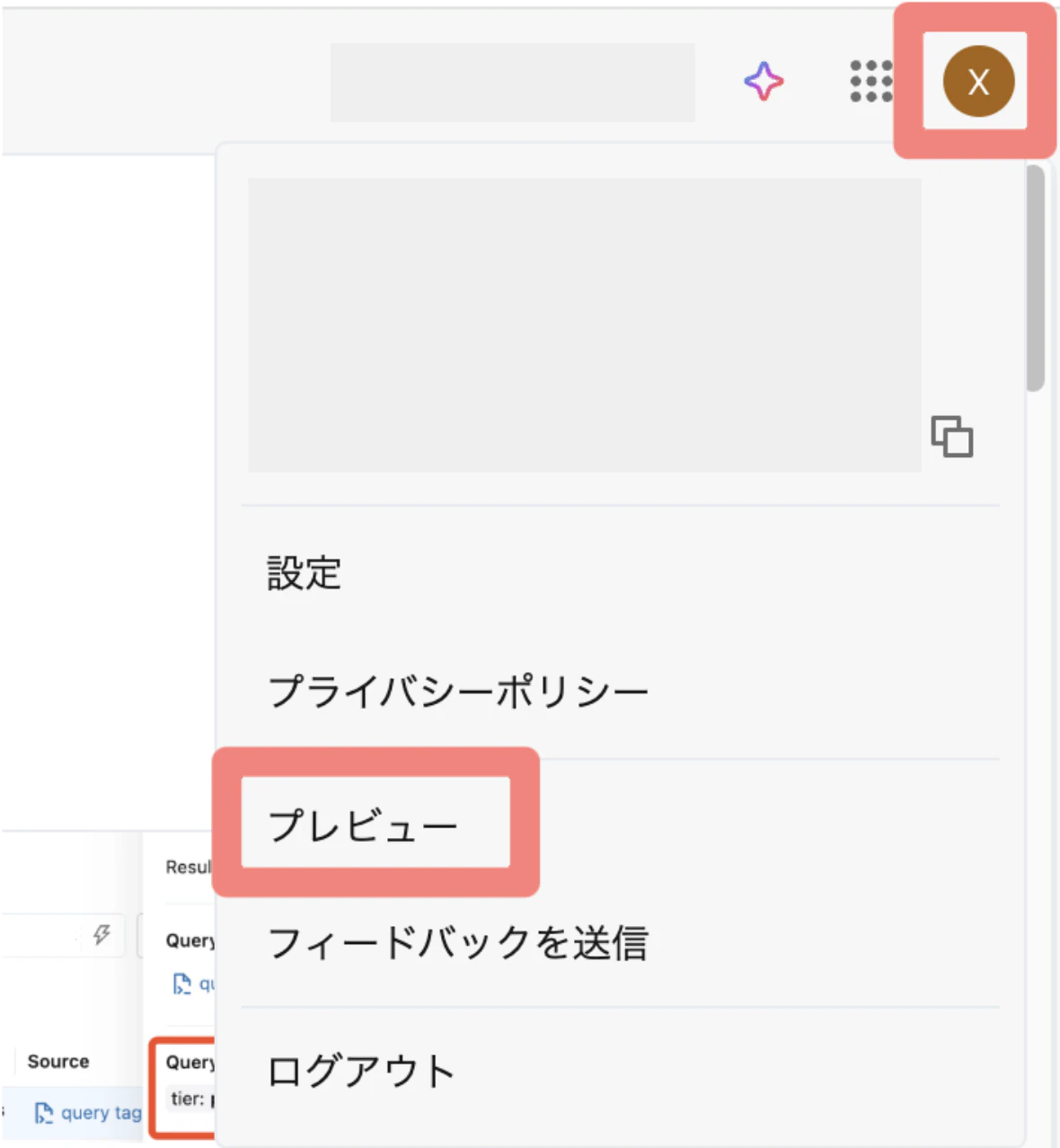
1.プレビューを有効化
①「プロフィールアイコン」→「プレビュー」をクリック
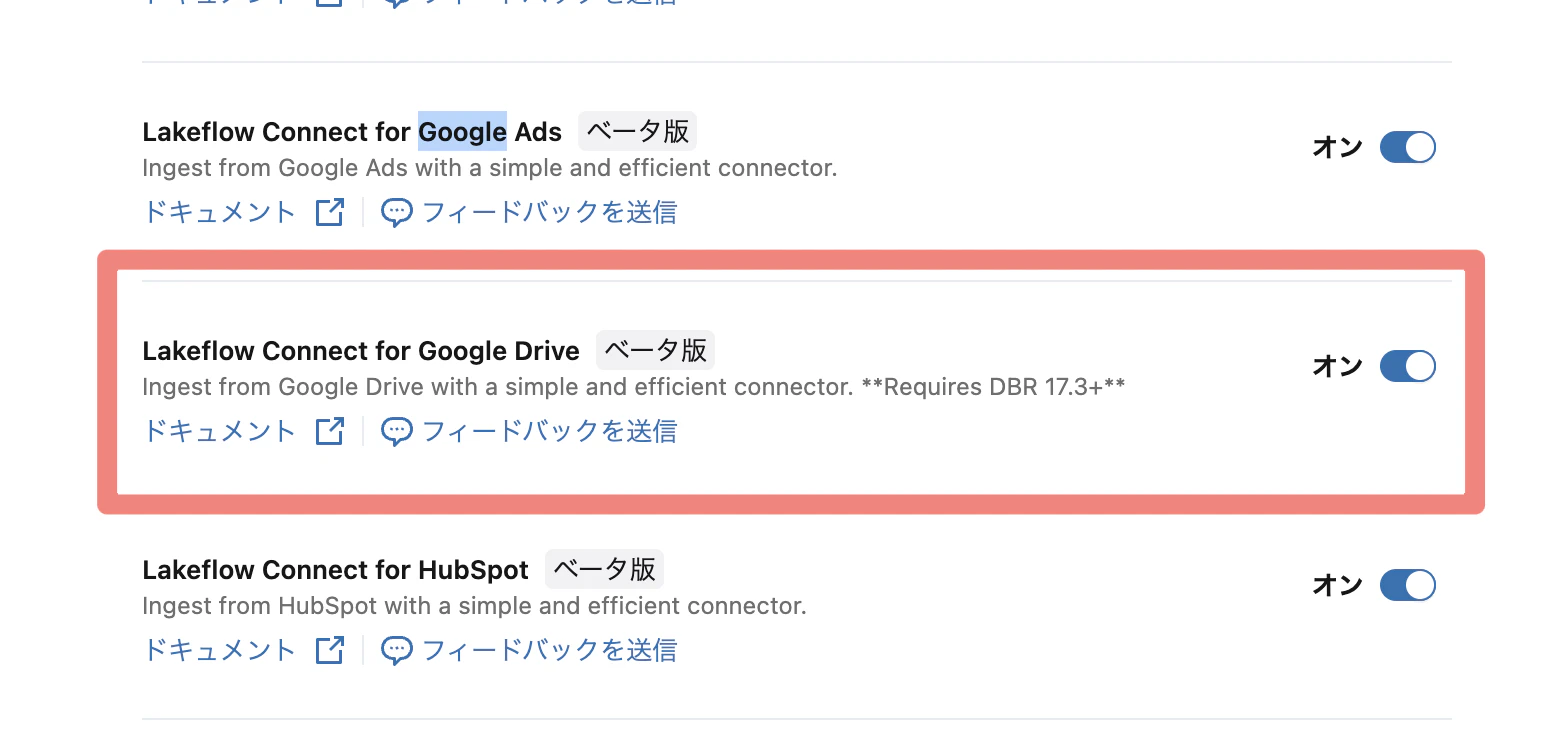
②「Lakeflow Connect for Google Drive」をOnにする
2.OAuth 2.0を構成
1)Google クラウド プロジェクトをセットアップし、Google Drive APIをアクティブ化
① Googleクラウドコンソールにログイン
② 新しいプロジェクトを作成

③ ナビゲーションメニューから「APIとサービス」→「ライブラリ」をクリック
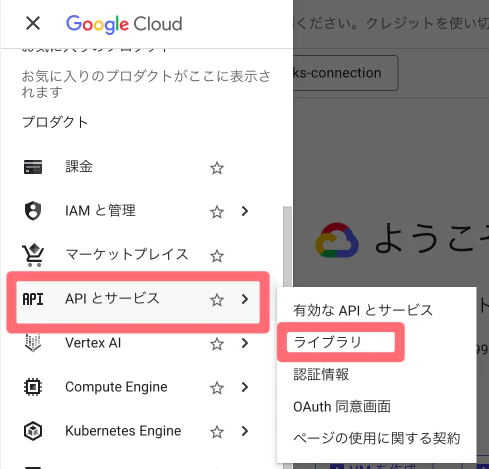
④ 「Google Drive API」を選択して、「有効にする」をクリック

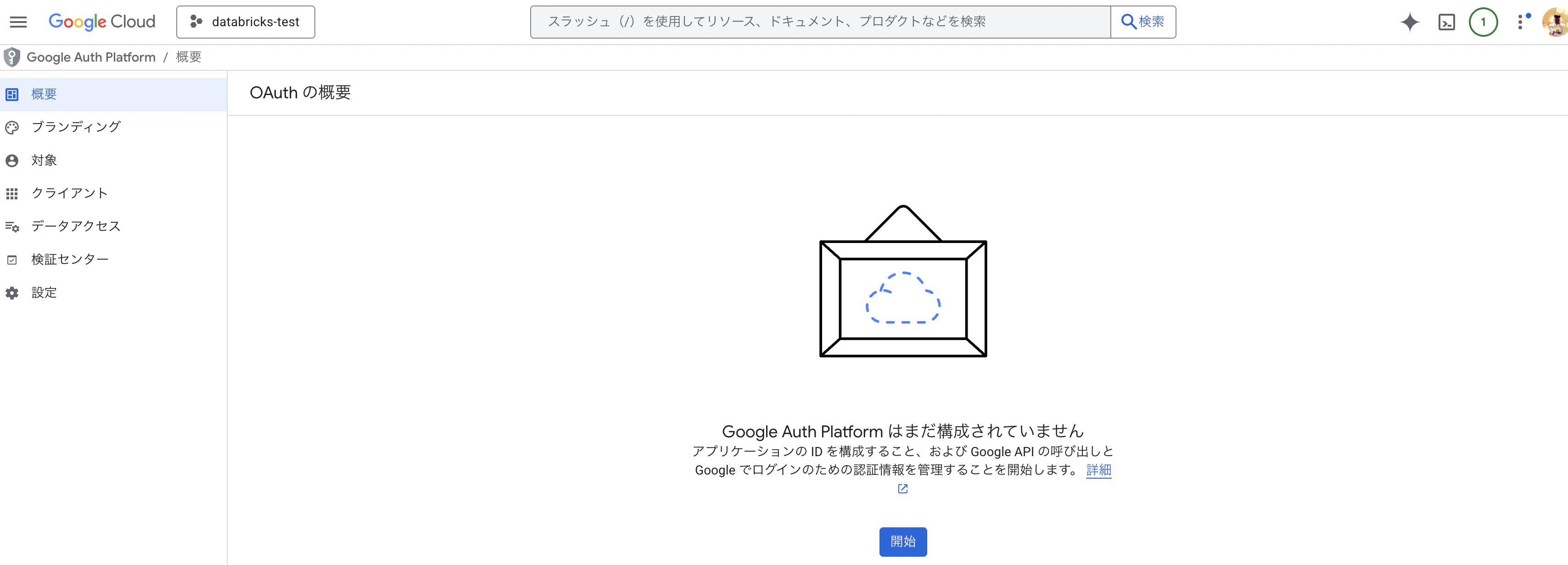
2)プロジェクトのOAuth同意画面を設定
① Googleクラウドコンソールのホーム画面で、「APIsとサービス」→「OAuth同意画面」に移動
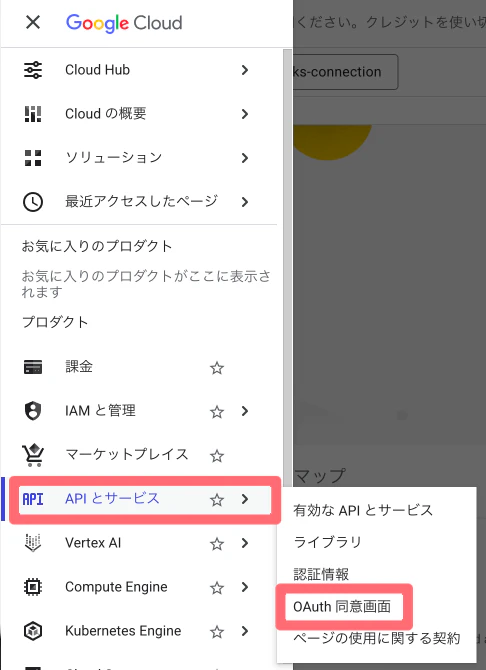
② 「開始」をクリック
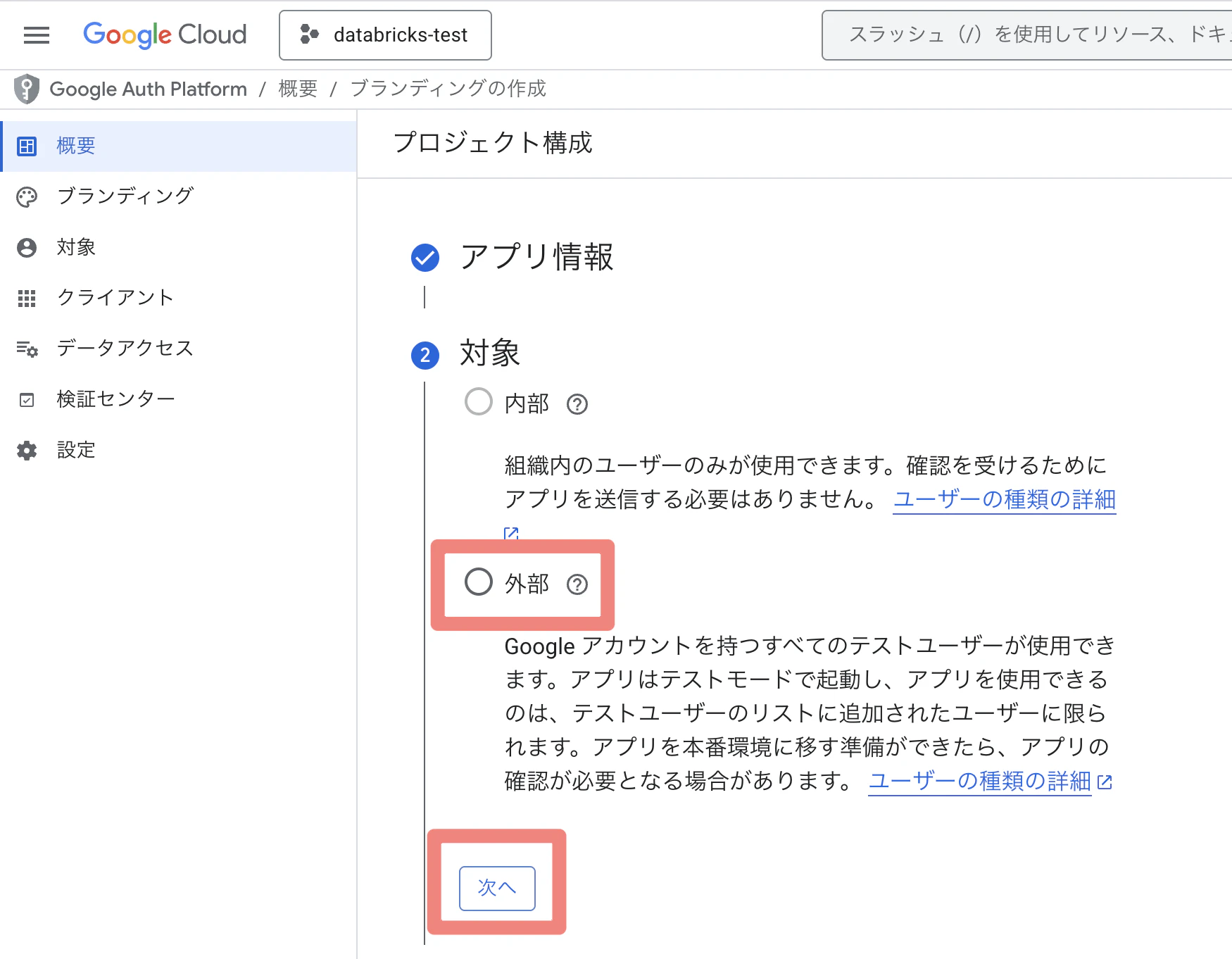
③ アプリ情報セッションで、アプリ名とメールを選択し、次へ

④ 「対象」セッションで「外部」を選択し、次へ
⑤ 連絡先情報を入力し、次へ
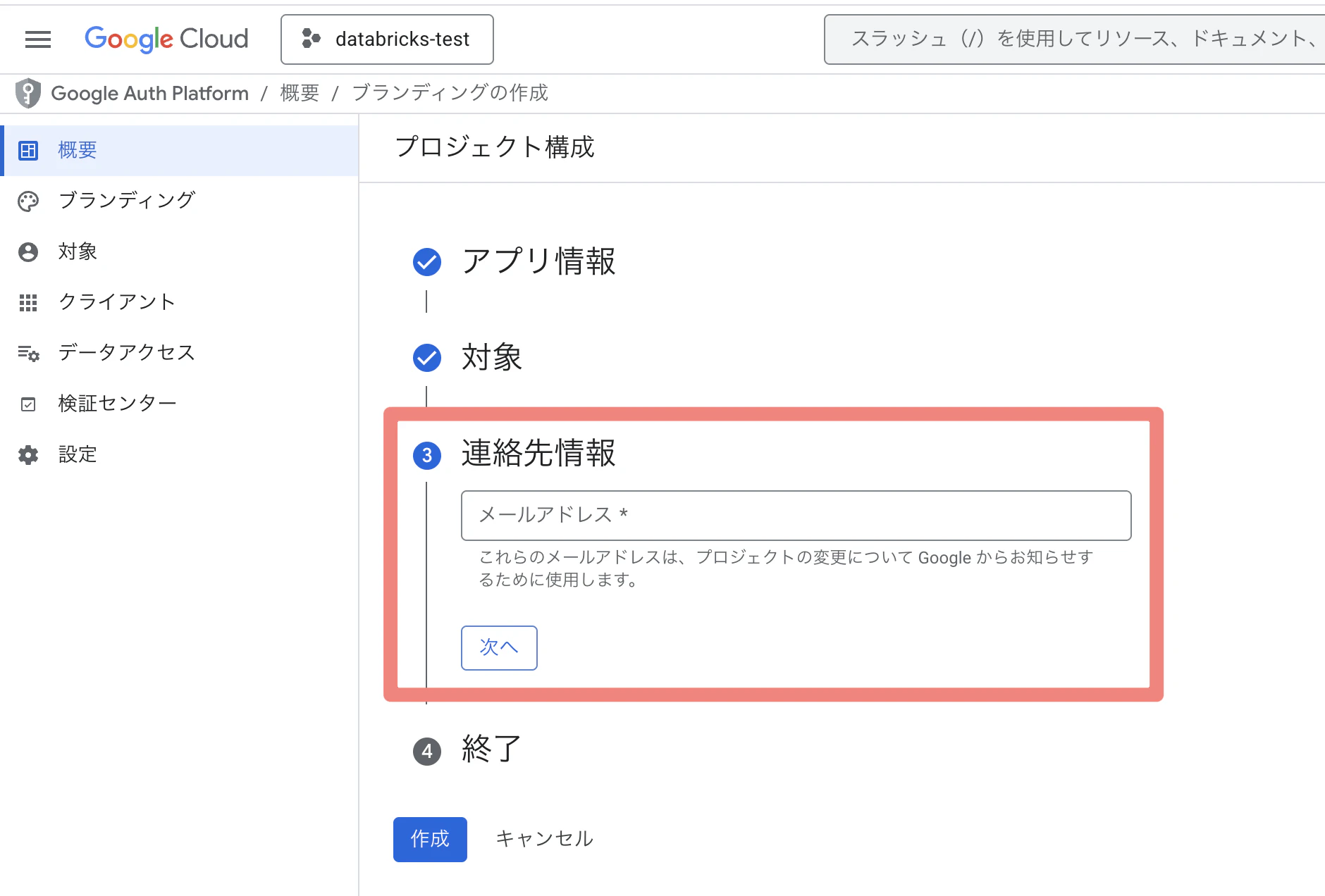
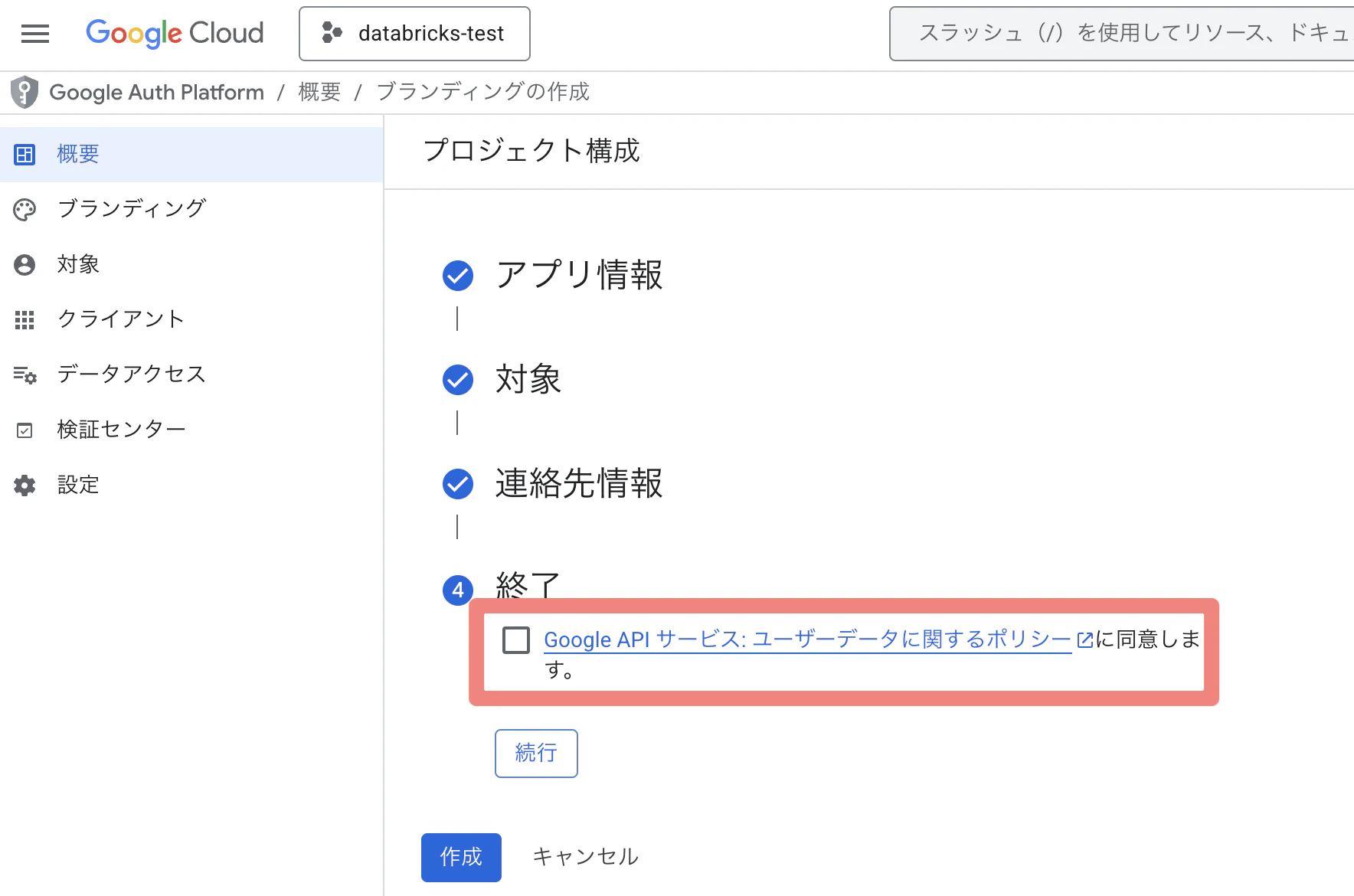
⑥ Google APIサービス:ユーザーデータに関するポリシーを確認し、 チェック→続行→作成
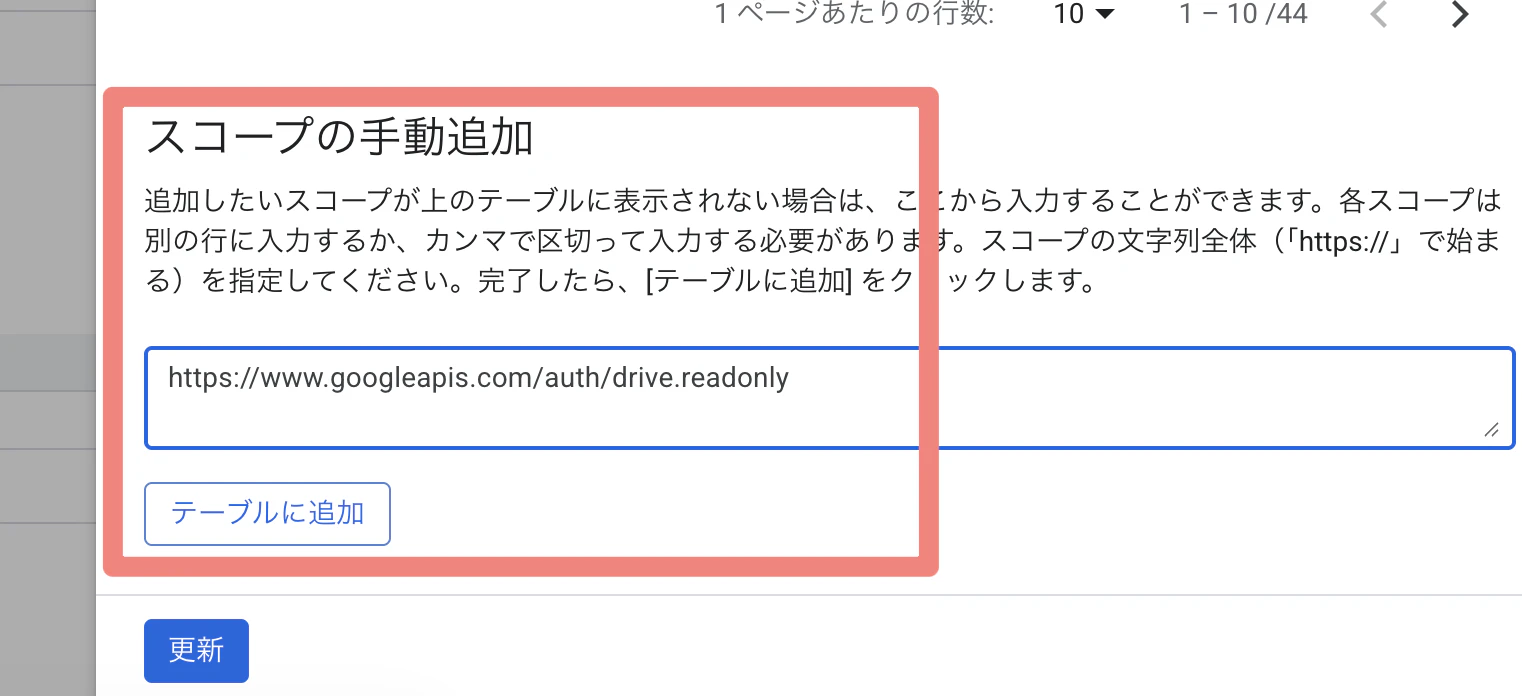
⑦ 「データアクセス」→「スコープを追加または削除」をクリック

⑧ 「スコープの手動追加」で以下のスコープを追加し、「テーブルに追加」→「更新」→「保存」をクリック
https://www.googleapis.com/auth/drive.readonly
3)OAuth 2.0クライアント資格情報を作成
① 「APIとサービス」→「認証情報」をクリック

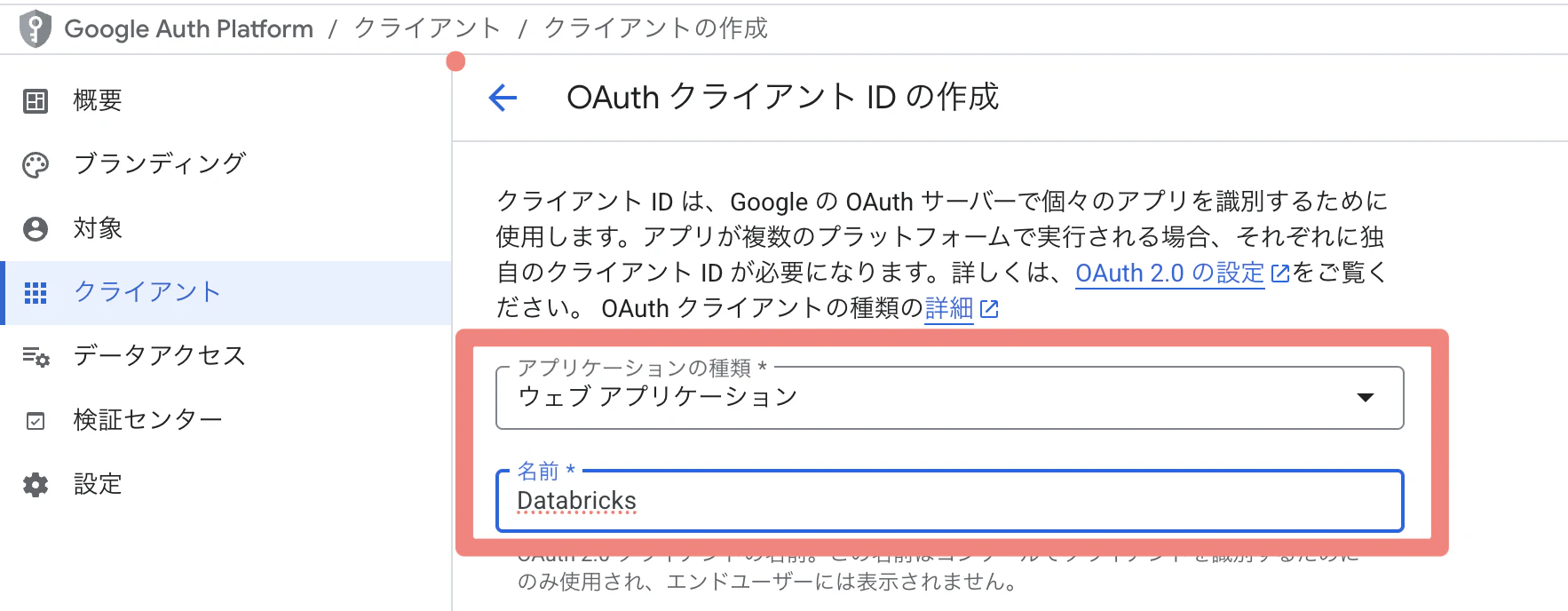
② 「認証情報を作成」→「OAuthクライアントID」をクリック

③ 「ウェブアプリケーション」を選択、名前を入力
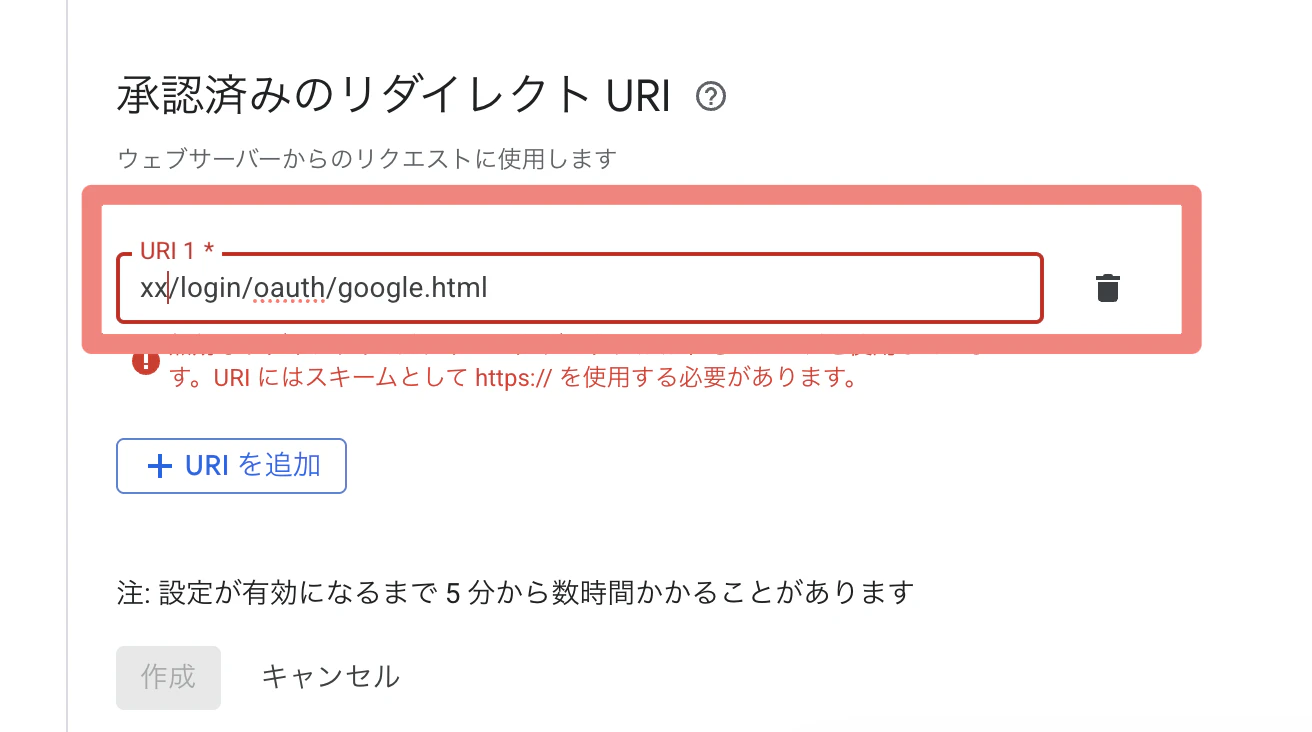
④ 「承認済みリダイレクト URI」で、 以下のURLを追加
<databricks-instance-url>/login/oauth/google.html
Databricks インスタンス URL に置き換えます。例えば: https://instance-name.databricks.com/login/oauth/google.html
⑤ 「作成」をクリックし、資格情報を含むポップアップの値を記録 or 次の情報が含まれるOAuth クライアント JSONファイルをダウンロード
クライアント ID (形式: 0123******-***.apps.googleusercontent.com)
クライアント シークレット (形式: ABCD-****************************)
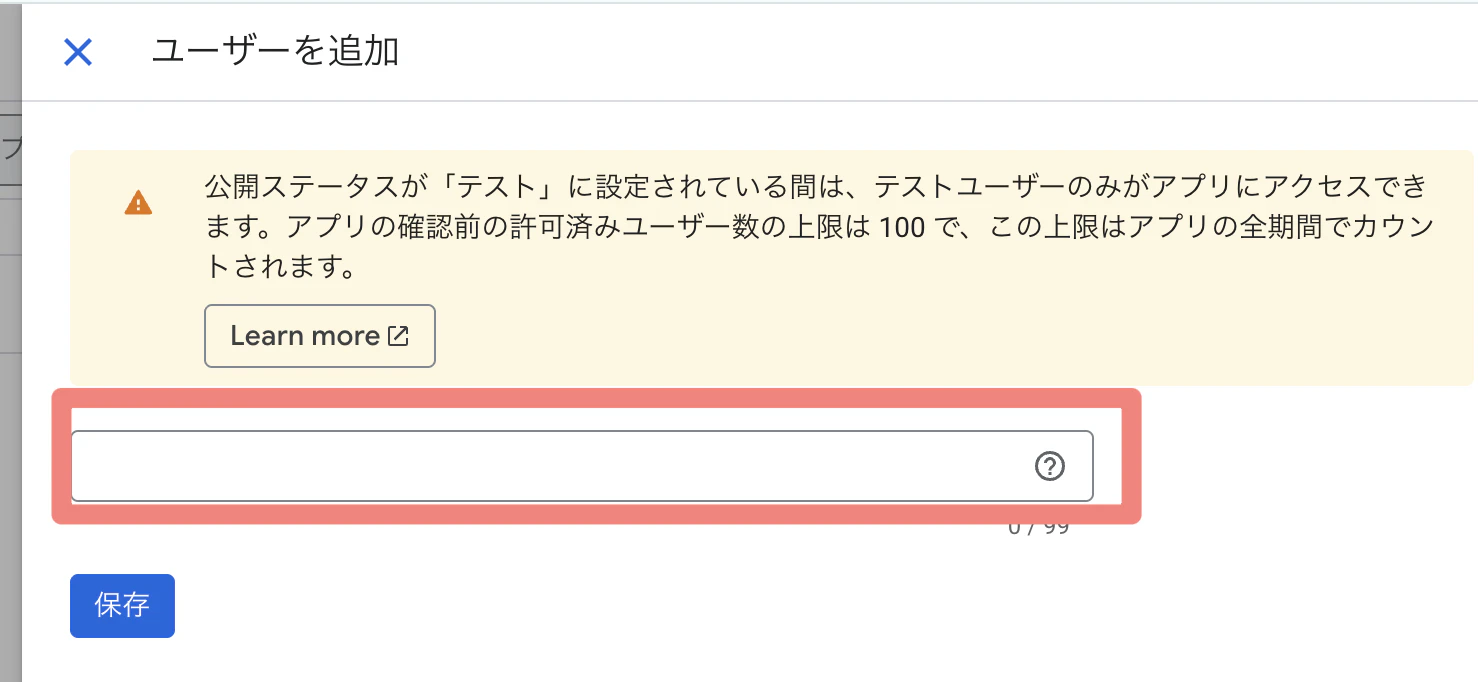
4)プロジェクトにテストユーザーを追加
① 「対象」→テストユーザーの「Add users」をクリック

② 接続の作成に使用するGoogleアカウントの電子メールアドレスを追加し、保存
3.Databricks上でGoogle Driveの接続を作成
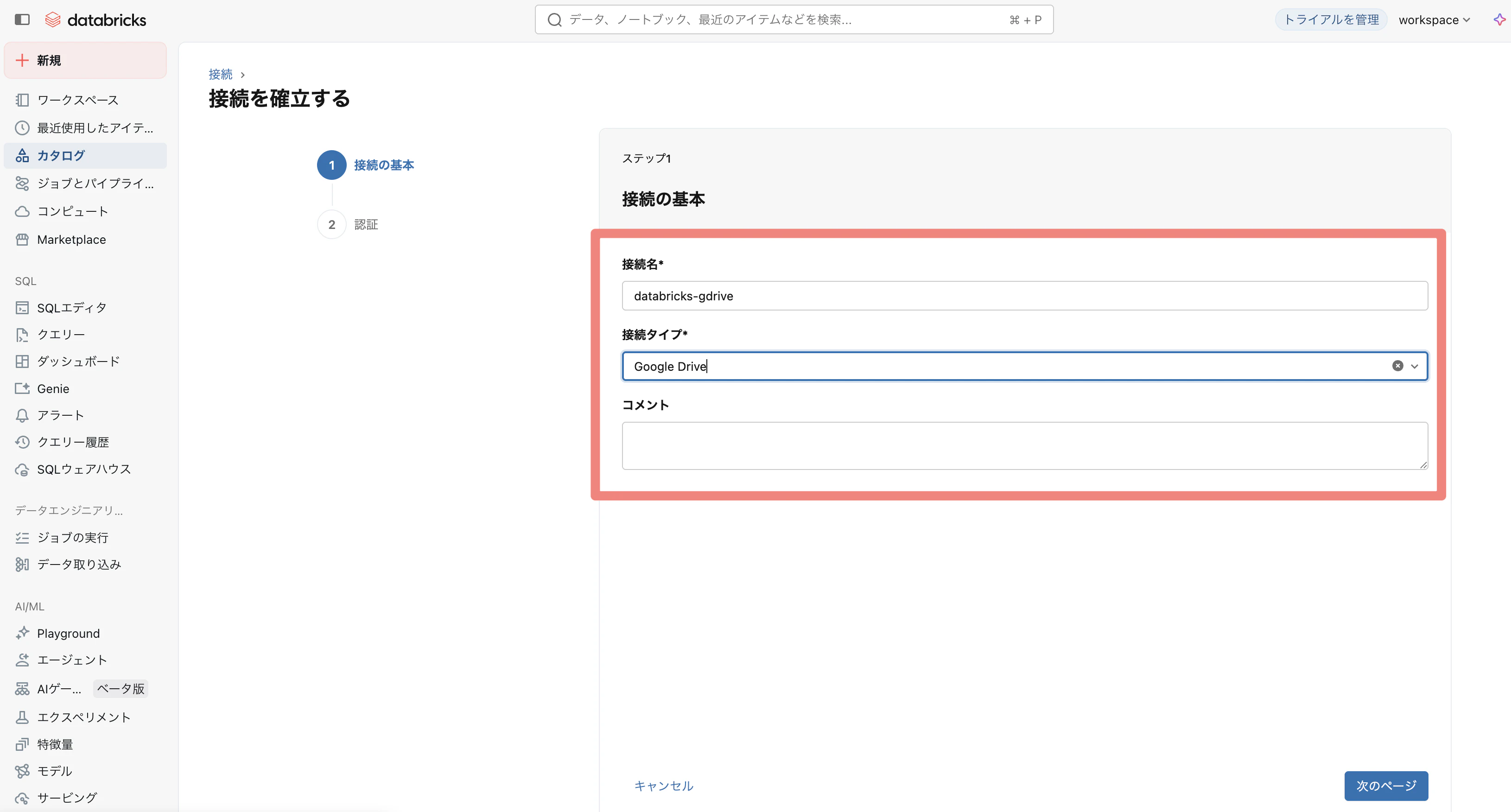
① Databricksワークスペースで、 「カタログ」→「接続」→「接続」をクリック

② 「接続の作成」をクリック

③ 接続名:任意、接続タイプ:Google Drive、コメント:任意、「次のページ」をクリック
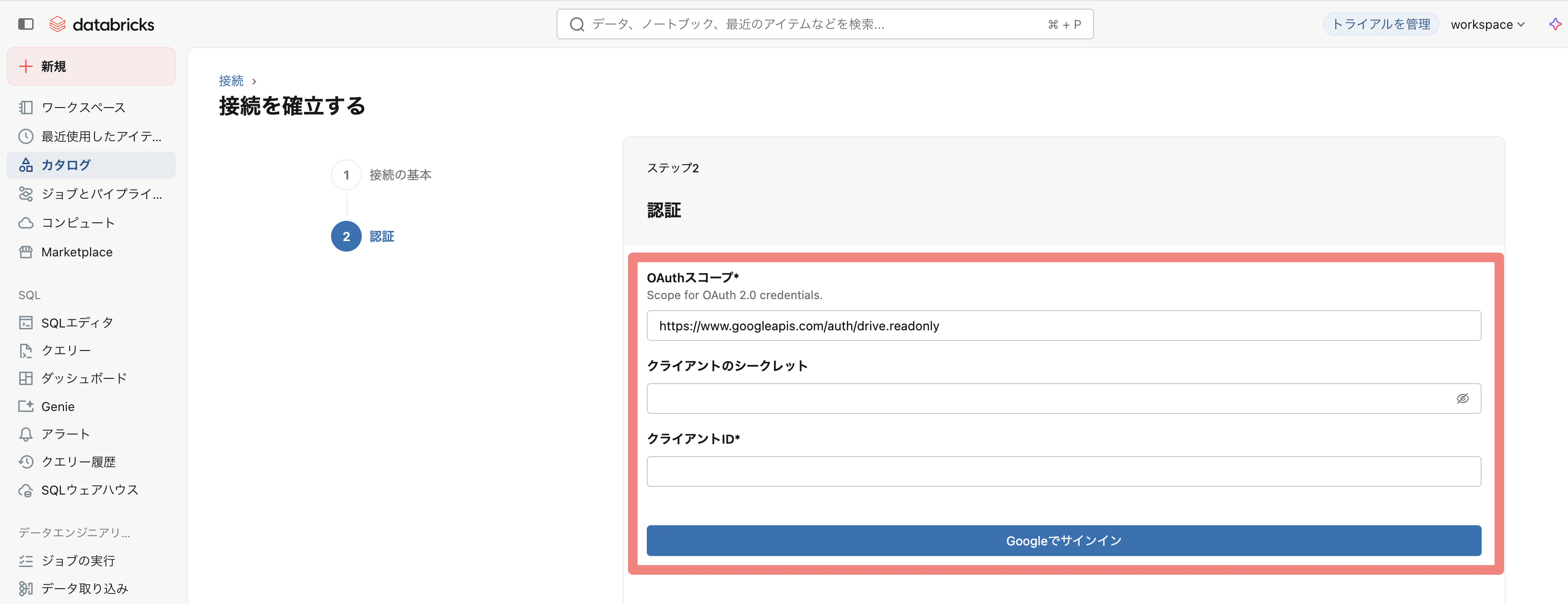
④ 以下の情報を入力し、「Googleでサインイン」をクリック
OAuthスコープ :
https://www.googleapis.com/auth/drive.readonly
クライアントのシークレット : OAuth 2.0クライアント資格情報の作成からのクライアントシークレット
クライアントID : OAuth 2.0 クライアント資格情報の作成からのクライアントID
⑤ 「プロジェクトにテストユーザーを追加する」手順で追加したGoogl アカウントでサインイン
⑥ 「続行」→「続行」→「接続の作成」をクリック
4.Google Driveからファイルを取り込む
1)非構造ファイル

① 非構造データをバイナリデータとして、読み込む
# Google Driveからバイナリデータを取得し、生データを保存
df = (spark.read
.format("binaryFile")
.option("databricks.connection", "<google driveの接続名>")
.option("recursiveFileLookup", True)
.load("<google driveから読み取りするファイル or フォルダのURL>"))
df.write.mode("overwrite").saveAsTable("<rawテーブル名>");
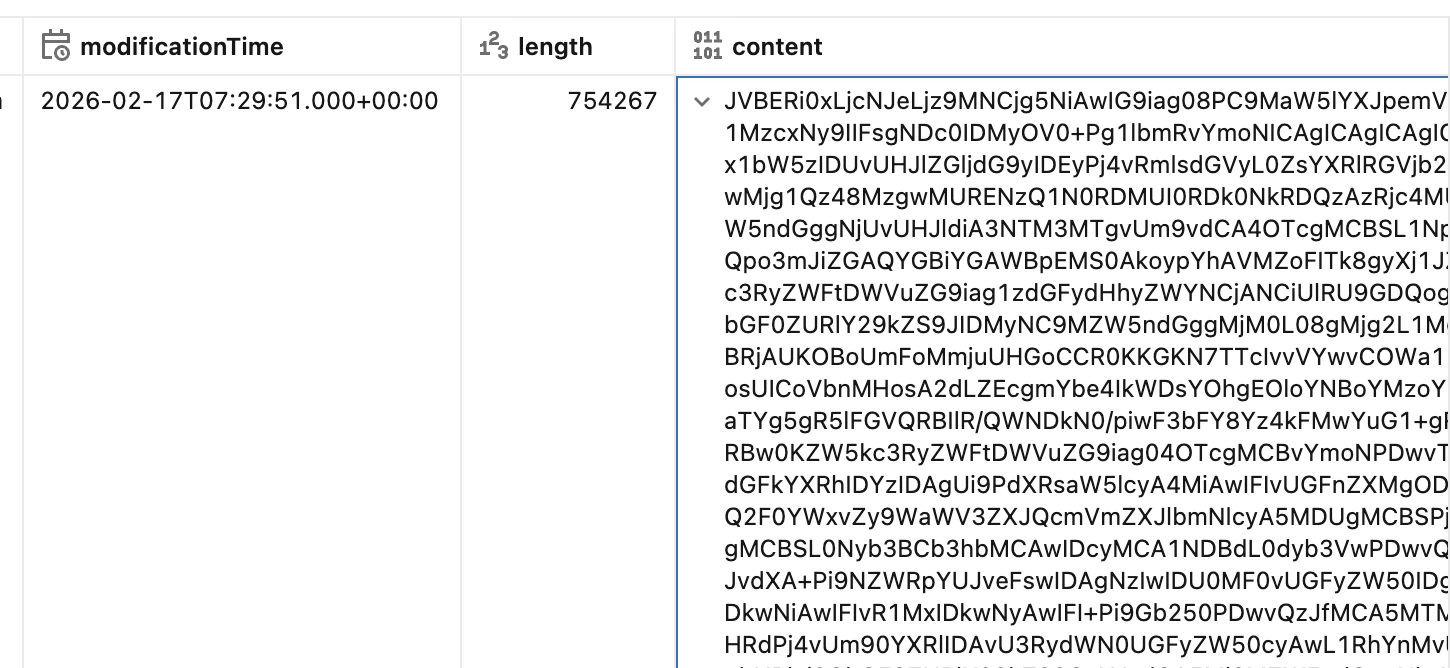
② ai parse関数を利用して、バイナリデータ→テキスト化
# ai parse関数を利用して、バイナリデータ→テキスト化
%sql
CREATE OR REPLACE TABLE <bronzeテーブル名> AS
SELECT
path,
ai_parse_document(content) AS content
FROM <rawテーブル名>;
SELECT * FROM <bronzeテーブル名>
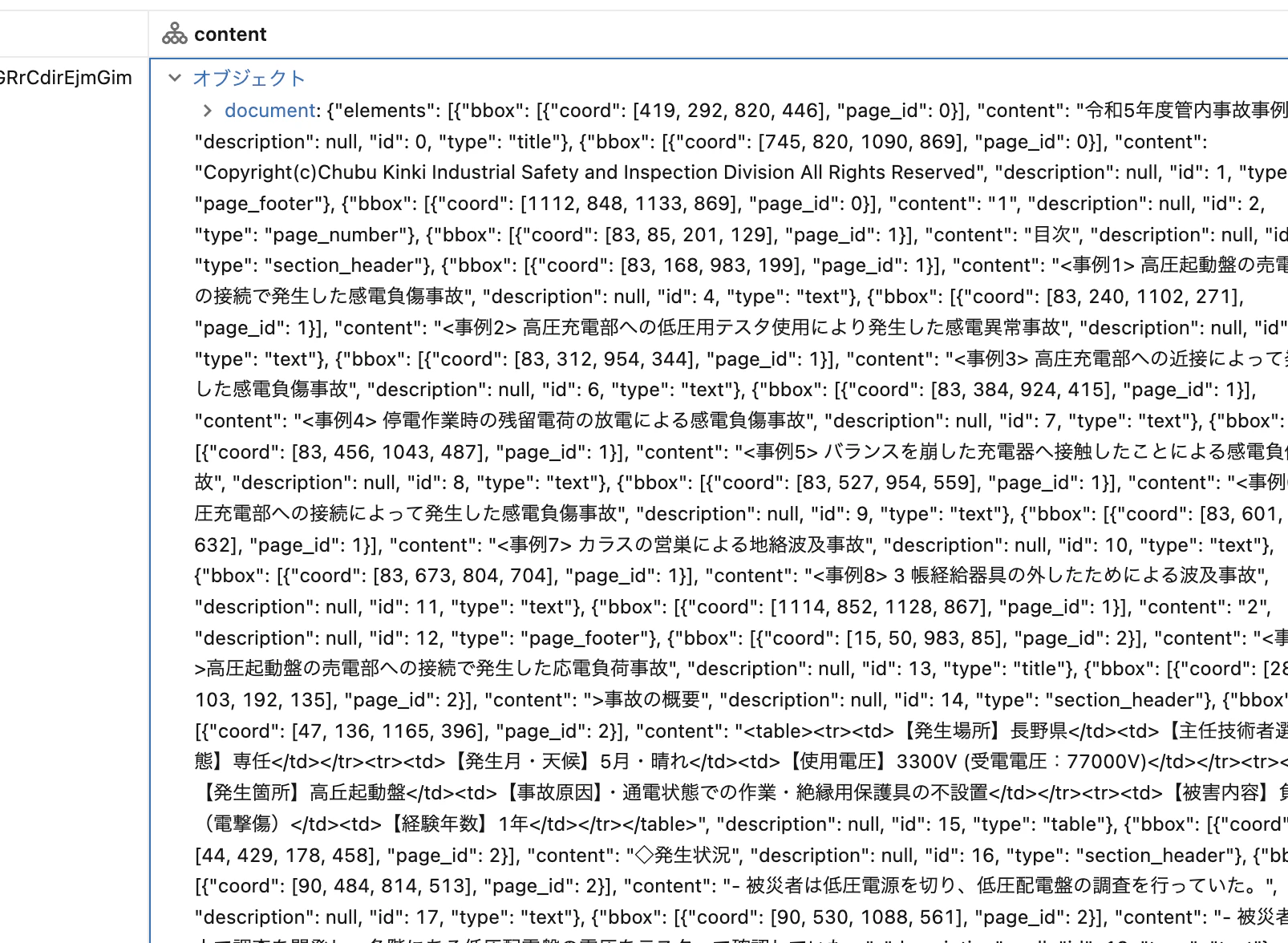
③ ai_query関数で必要な情報抽出
%sql
CREATE OR REPLACE TABLE <silverテーブル名> AS
SELECT
path,
ai_query(
"databricks-gpt-oss-120b",
"貴方はテキスト整理のプロフェッショナルです。事例についてJSON形式でまとめてください。parse_jsonできるように余計な文字列は入れないでください。
それぞれのooのaaごとにbb、cc、dd、ee、ffをまとめて一つのテキストに整形してください。
Keyはそれぞれ\"oo\"と\"gg\"でお願いします。
[で始まり、]で終わるJSONで返してください。```json```という文字列は抜いてください。
" || content
) AS summary
FROM
<bronzeテーブル名>;
select *from <silverテーブル名>;

④ 構造化
%sql
CREATE OR REPLACE TABLE <goldテーブル名> AS
SELECT
GET_JSON_OBJECT(case_element, '$.事例番号') AS `accident_no`, -- 事例番号を抽出
GET_JSON_OBJECT(case_element, '$.事例サマリ') AS `summary` -- 発生状況をサマリとして抽出
FROM
<silverテーブル名>
LATERAL VIEW
EXPLODE(from_json(summary, 'ARRAY<STRING>')) exploded_cases AS case_element; -- cases配列を展開
select *from <goldテーブル名>;

2)複数csv
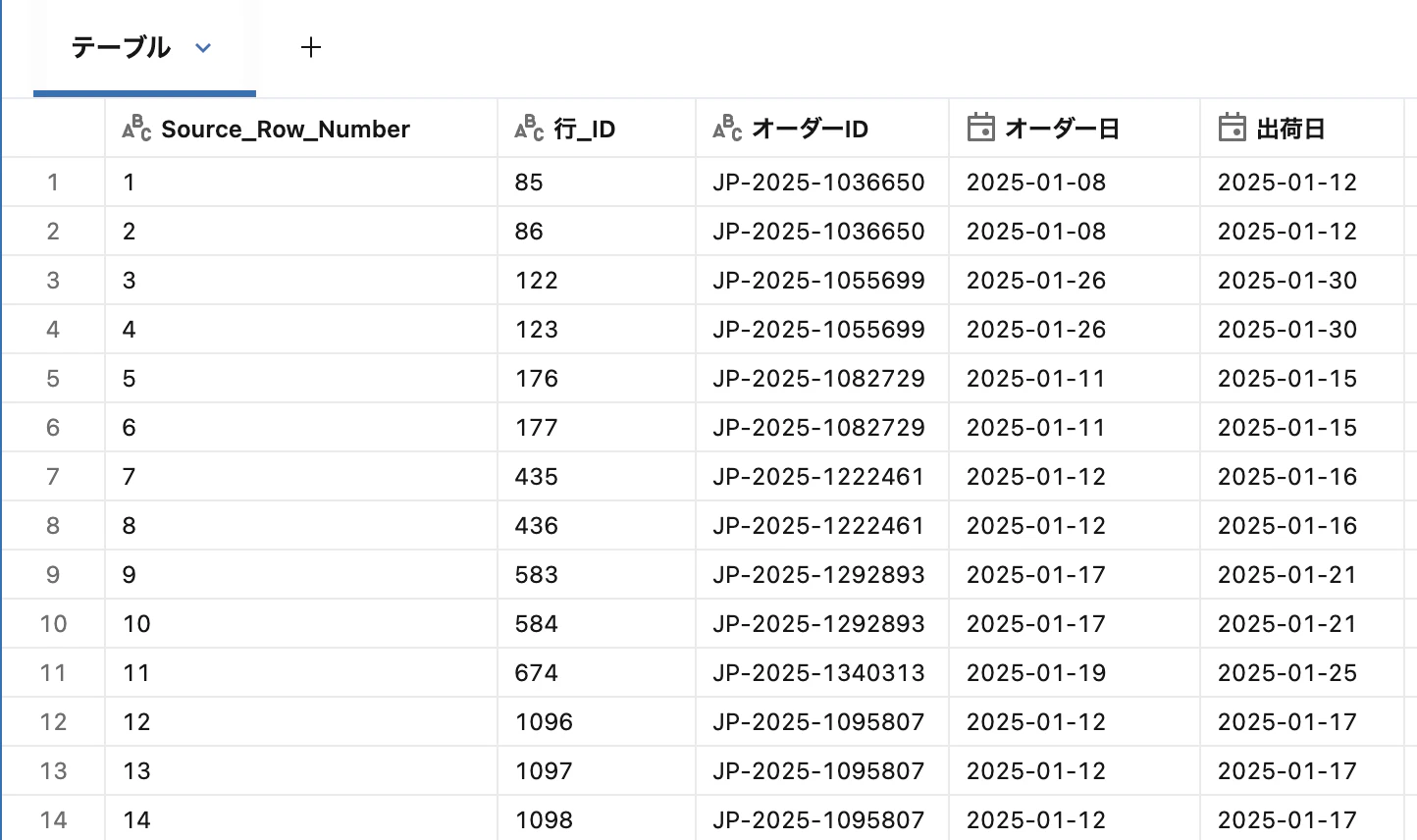
① 複数csvが入っているGdriveフォルダからデータを読み込む
from pyspark.sql.functions import col, to_date
df_raw = (spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("databricks.connection", "<Google Drive接続名>")
.option("cloudFiles.schemaLocation", "<schema_locationのボリューム名")
.option("pathGlobFilter", "*.csv")
.option("inferColumnTypes", True)
.option("header", True)
.load("<複数csvが入っているGoogle DriveのURL>")
)
df = df_raw.select(
*[col(c).alias(c.replace(" ", "_")) for c in df_raw.columns]
)
df = df.withColumn("オーダー日", to_date(col("オーダー日"), "yyyy/M/d")) \
.withColumn("出荷日", to_date(col("出荷日"), "yyyy/M/d"))
display(df)
② テーブルに書き込む
q = (df.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "<checkpointのボリューム>")
.trigger(availableNow=True)
.toTable("<書き込むテーブル名>")
)
3) Worksheet
① excelとしてGoogle DriveのWorksheetを読み込む
df = (spark.read
.format("excel") # use 'excel' for Google Sheets
.option("databricks.connection", "<Google Drive接続名>")
.option("headerRows", 1) # optional
.option("inferColumns", True) # optional
.load("<Google DriveのWorksheetのURL>"))
display(df)
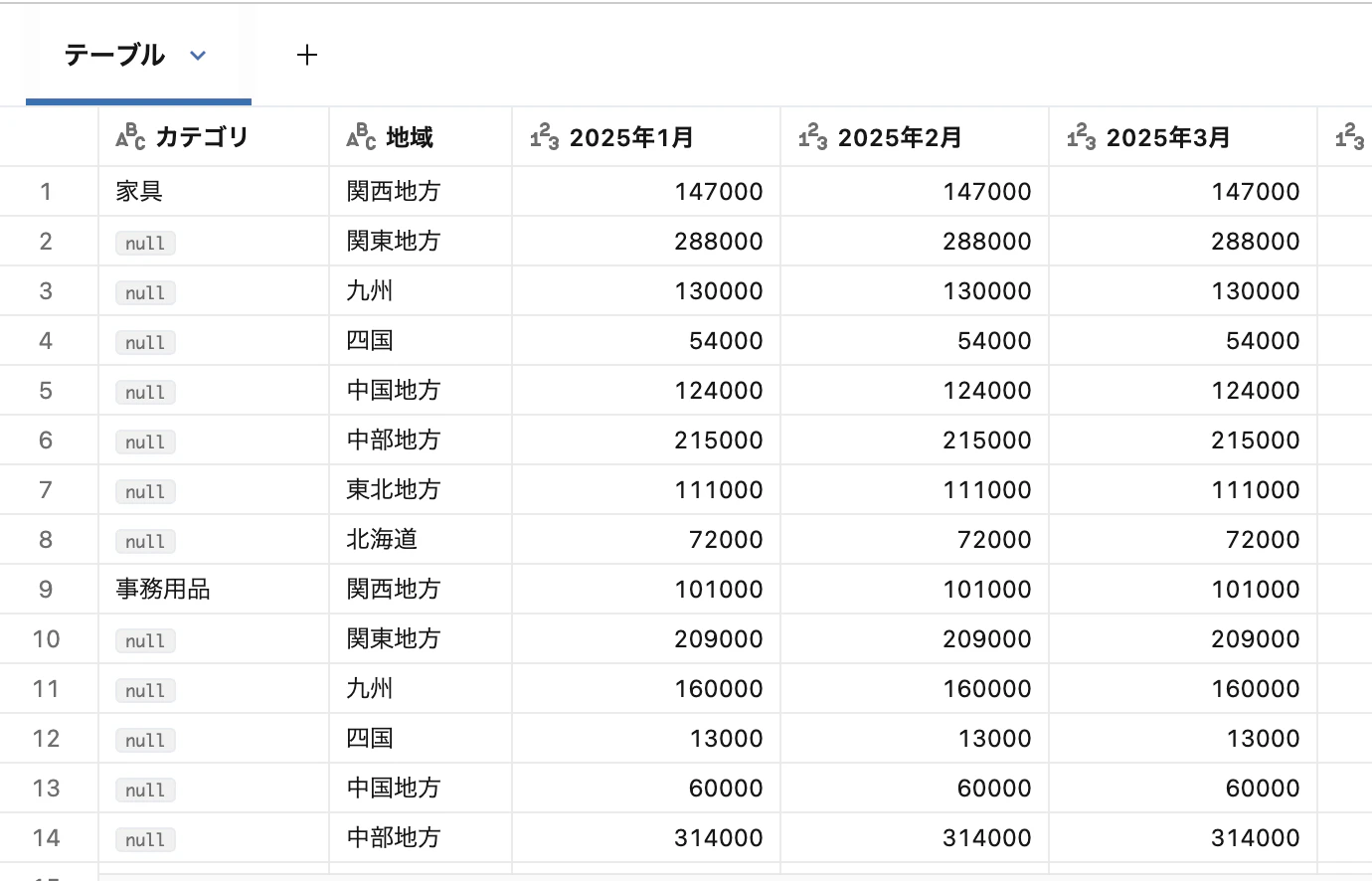
② セル結合によって生じてるnull値を埋める
from pyspark.sql import Window
from pyspark.sql.functions import last, col, monotonically_increasing_id
# 元の行順序を保持するためにIDを追加
df_with_id = df.withColumn("row_id", monotonically_increasing_id())
# 行順序でWindowを定義し、カテゴリ列のnullを上の行の値で埋める
window_spec = Window.orderBy("row_id").rowsBetween(Window.unboundedPreceding, 0)
df_filled = df_with_id.withColumn("カテゴリ", last(col("カテゴリ"), ignorenulls=True).over(window_spec))
# row_id列を削除
df_filled = df_filled.drop("row_id")
display(df_filled)