1. 超解像の基本概念
超解像 (Super-Resolution, SR) とは、低解像度 (Low-Resolution, LR) の画像や映像から、より高解像度 (High-Resolution, HR) の画像を生成・復元する技術のことです。

単純にピクセルを引き伸ばして補間するのではなく、失われたディテールを「推定・生成」する点が本質的な特徴です。

カテゴリ分類
超解像は大きく2つのカテゴリに分類されます。
| カテゴリ | 略称 | 概要 |
|---|---|---|
| 単一画像超解像 | SISR (Single Image SR) | 1 枚の LR 画像のみから HR を復元。研究の主流 |
| 複数画像超解像 | MISR (Multi-Image SR) | 同一シーンの複数 LR 画像を利用して復元 |
数学的定式化
超解像の基本的な枠組みは次の式で表されます。
$$
\widehat{HR} = f(LR)
$$
ここで $f$ は超解像モデル (学習したい写像) です。一方、HR から LR への劣化モデルは次のように定義されます。
$$
LR = D(HR) + n
$$
- $D(\cdot)$:ダウンサンプリング演算子 (ブラーを含む)
- $n$:加法的ノイズ (センサーノイズ等)
超解像の目標は、この $D$ の逆写像 $f$ を求めることです。
$$
f \approx D^{-1} \quad \Longrightarrow \quad \hat{HR} \approx HR
$$
ポイントは、$D$ の逆写像 $f$ を求める問題であるということです。これは後述するように「不良設定問題 (Ill-posed Problem) 」であり、難しさの根本となっています。
2. 超解像が難しい理由
超解像が難しい根本的な理由は、不良設定問題 (Ill-posed Problem) であるからです。
1 枚の LR 画像に対して、それに対応しうる HR 画像は無数に存在します。つまり、唯一の「正解」が定まらない問題です。
例えば、スケールファクタ × 4 の超解像では、4 × 4 = 16 ピクセル分の情報を 1 ピクセルから生成する必要があります。これは情報の「創造」であり、単なる補間とは本質的に異なります。
画像の劣化プロセス
実際の画像には、以下の劣化が複合的に重なります。
- ダウンサンプリング:解像度の縮小 (Bicubic, Bilinear など)
- ブラー:カメラのぼかし、モーションブラー
- ノイズ:センサーノイズ、ガウスノイズ
- 圧縮アーティファクト:JPEG ブロックノイズ、リンギング
これらを同時に逆転させることが超解像の課題です。
3. 古典的アプローチ
深層学習が登場する以前から、様々な手法が研究されてきました。
- 補間法 (Interpolation)
- 再構成ベース法
- 辞書学習 (Sparse Coding)
- Example-based 法
古典的手法の限界:
古典的手法はハードコードされた仮定 (滑らかさ、スパース性など) に依存するため、複雑な自然画像では限界があります。深層学習はこれらの仮定をデータから自動的に学習します。
3.1. 補間法 (Interpolation)
深層学習ベースの超解像が登場する以前は、数学的な補間手法が画像の拡大に広く使われてきました。これらの手法はシンプルで高速ですが、新しい詳細情報を生成することはできず、ぼやけた画像になりやすいという特徴があります。
| Nearest Neighbor (最近傍補間) |
Bilinear Interpolation (双線形補間) |
Bicubic Interpolation (双三次補間) |
|---|---|---|
最も近いピクセルの値をそのまま使用する最もシンプルな手法。計算コストは最小だが、ブロック状のアーティファクトが発生しやすい。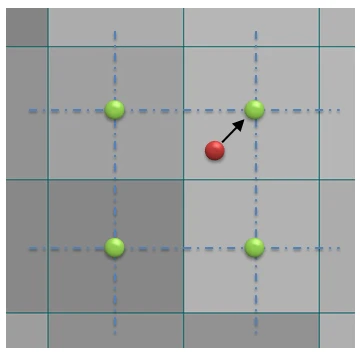 画像出典: 画像出典:画像処理ソリューション |
周囲 4 ピクセルの値を線形補間して新しいピクセル値を計算。Nearest Neighbor よりも滑らかだが、エッジがぼやける。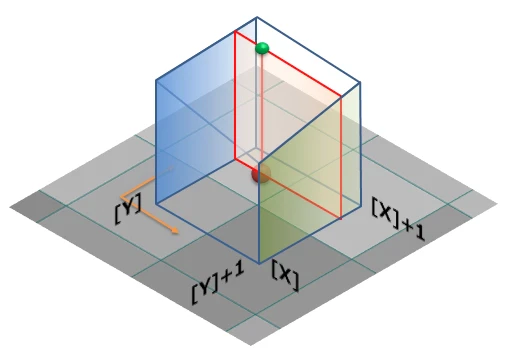 画像出典: 画像出典:画像処理ソリューション |
周囲 16 ピクセルの値を三次関数で補間。より滑らかで自然な結果が得られるが、やはり新しい詳細は生成できない。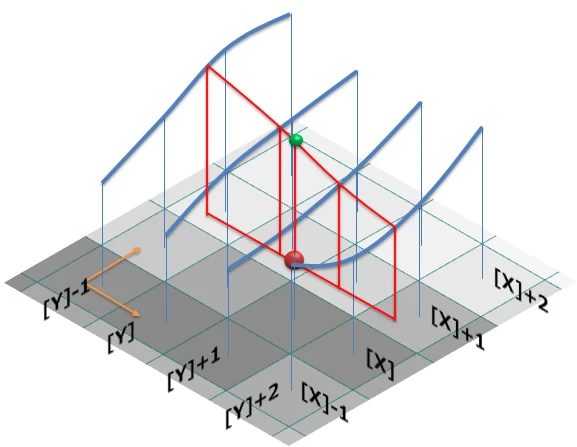 画像出典: 画像出典:画像処理ソリューション |
Bicubic は今でもベースラインとして広く使われています。
3.2. 再構成ベース法
事前知識 (画像の滑らかさなど) を正則化として組み込み、最適化問題として定式化します。
代表的な手法に Total Variation (TV) 正則化 があり、エッジ保持に優れます。
\hat{\mathbf{x}} = \arg\min_{\mathbf{x}} \left\{
\|\mathbf{y} - \mathbf{D}\mathbf{x}\|_2^2 + \lambda\cdot\mathrm{TV}(\mathbf{x})
\right\}
- $\lambda$ :正則化パラメータ(トレードオフを制御)
- $|\mathbf{y} - \mathbf{D}\mathbf{x}|_2^2$:データ整合性項
→ 観測データとの誤差を小さくする - $\lambda\cdot\mathrm{TV}(\mathbf{x})$:正則化項
→ 事前知識を反映(自然画像らしい解に誘導)
isotropic TV(等方性 TV):
\mathrm{TV}(\mathbf{x}) = \sum_{i,j} \sqrt{
(x_{i+1,j} - x_{i,j})^2 + (x_{i,j+1} - x_{i,j})^2
}
anisotropic TV(異方性 TV):
\mathrm{TV}(\mathbf{x}) = \sum_{i,j} \Bigl(
|x_{i+1,j} - x_{i,j}| + |x_{i,j+1} - x_{i,j}|
\Bigr)
3.3. 辞書学習 / スパース表現
LR パッチと HR パッチの対応辞書を事前学習し、テスト時に LR パッチをスパースに表現して対応する HR パッチを合成します。Yang et al. (2010) が先駆的な研究を発表しました。
4. 深層学習による超解像
2014年に Dong et al. が提案した SRCNN (Super-Resolution CNN) が転換点となり、以降、深層学習ベースの手法が超解像の主流となりました。

主要な技術の流れ:
- 1990 年代以前:Bicubic 補間などの古典的補間手法
- 2000 年代前半:統計的手法、Example-based 手法
- 2010 年頃:Sparse coding、辞書学習ベースの手法
- 2014 年:SRCNN 登場 - 深層学習の超解像への初適用
- 2015-2016 年:VDSR、DRCN、ESPCN 等の CNN 改良
- 2016 年:ResNet 応用 - より深いネットワークが可能に
- 2017 年:SRGAN 登場 - GAN による知覚的品質の向上
- 2018 年以降:EDSR、RCAN、Transformer ベースの手法など、さらなる高度化
4.1. 損失関数の進化
深層学習 SR の発展は、損失関数の進化と密接に関係しています。
| 損失関数 | 計算式 | 特徴・問題点 |
|---|---|---|
| Pixel-wise L2 (MSE) | $$|HR - \hat{H}|^2$$ | 最適化しやすいが過度に平滑化された画像になる。 |
| L1 Loss | $$|HR - \hat{H}|_1$$ | L2 より鮮鋭だが、依然ぼける傾向あり。 |
| Perceptual Loss | $$|\phi(HR) - \phi(\hat{H})|^2$$ | VGG 特徴空間で比較。知覚的品質が大幅に向上。 |
| Adversarial Loss (GAN) | $$-\log D(\hat{H})$$ | フォトリアルなテクスチャを生成。幻覚のリスクあり。 |
- $\phi$:VGG などの事前学習済みネットワーク
- $D$:判別器
4.2. アップサンプリングの位置
ネットワーク内のどこでアップサンプリングするかは、設計上の重要な選択です。
-
Pre-upsampling (事前拡大)
最初に Bicubic で HR サイズに拡大してから特徴抽出。SRCNN が採用。演算コストが高い。 -
Post-upsampling (後処理拡大)
LR のまま処理し、最後にアップサンプル (Sub-pixel convolution など) 。計算効率が良く、EDSR・ESPCN が採用。 -
Iterative (段階的拡大)
段階的にアップサンプルしながら精緻化。大スケールファクタに有効。LapSRN が代表例。
5. 主要モデルのアーキテクチャ
5.1. SRCNN (2014) — 深層学習SRの原点
3層の畳み込みニューラルネットワーク。 パッチ抽出→非線形写像→再構成という3段階の処理を学習。 シンプルながら古典的手法を大幅に凌駕しました。

5.2. ESRGAN (2018) — GAN 時代の到来
SRGAN を発展させた ESRGAN (Enhanced SRGAN) は、 Residual-in-Residual Dense Block (RRDB) と 相対的 GAN 損失 (Relativistic GAN) を採用し、フォトリアルな超解像を実現しました。PSNR 指標よりも視覚的品質を優先する設計思想が特徴です。

5.3. Real-ESRGAN (2021) — 実世界劣化への対応
実際の写真は複数の劣化が組み合わさっています。 Real-ESRGAN は高次劣化モデル (High-order Degradation) を採用し、 ランダムなブラー、ダウンサンプリング、ノイズ、JPEG 圧縮を確率的に組み合わせた 学習データを生成することで、実世界の劣化に堅牢なモデルを実現しました。
5.4. SwinIR (2021) — Transformer の台頭
CNN に代わり Swin Transformer をバックボーンとして採用。 Self-Attention 機構により長距離依存関係を捉えられるため、 広い受容野を必要とする SR 問題に適しています。 PSNR/SSIM の両指標で SR 分野の SOTA を更新しました。
5.5 Diffusion Model SR (2022〜)
Stable Diffusion の成功を受け、拡散モデルを超解像に応用する研究が急増しています。 StableSR や SeeSR などは、 拡散モデルの強力な生成能力を活かして、 細かいテクスチャや現実的なディテールを生成できます。 ただし推論コストが高いのが課題です。
# 拡散モデルによる超解像の基本フロー
import torch
from diffusers import StableDiffusionUpscalePipeline
# モデルのロード
pipeline = StableDiffusionUpscalePipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler",
torch_dtype=torch.float16,
)
# 超解像の実行 (×4 アップスケール)
result = pipeline(
prompt="a high resolution photograph, detailed",
image=low_res_image, # LR 画像 (PIL Image)
num_inference_steps=20,
guidance_scale=7.5,
).images[0]
6. 評価指標
超解像モデルの品質評価には、主に以下の4つの指標が使われています。
| 指標 | 良い値の方向 | 主に見ている点 | 超解像での位置づけ |
|---|---|---|---|
| PSNR | 高い | ピクセルレベルの忠実度 | 古典的で信頼性が高いが、見た目の良さとはズレやすい |
| SSIM | 高い | 構造・エッジの保存 | PSNRの弱点を補う、現役の標準指標 |
| LPIPS | 低い | 人間の知覚的な類似度 | 最近のトレンドの中心。視覚品質を重視するなら必須 |
| FID | 低い | 画像分布の現実味 | 生成モデルで特に有効。枚数が必要 |
6.1. PSNR (Peak Signal-to-Noise Ratio; ピーク信号対雑音比)
ピクセルレベルの誤差を測る最も基本的な指標です。値が高いほど良いとされます。
\text{PSNR} = 10 \cdot \log_{10} \left( \frac{\text{MAX}^2}{\text{MSE}} \right)
- $\text{MAX}$:画素の最大値(通常 8-bit 画像では 255)
- $\text{MSE}$:Mean Squared Error(平均二乗誤差)
$\text{MSE} = \frac{1}{H W} \sum_{i=1}^{H} \sum_{j=1}^{W} \left( I_{i,j} - \hat{I}_{i,j} \right)^2$
($H$、$W$ は画像の高さと幅、$I$ は元画像、$\hat{I}$ は再構成画像)
6.2. SSIM (Structural Similarity Index; 構造的類似度)
輝度・コントラスト・構造の3つの観点から類似性を評価します。値は 0〜1 の範囲で、1 に近いほど良いです。
\text{SSIM}(x,y) = \frac{(2\mu_x \mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}
- $\mu_x, \mu_y$:局所領域内の平均輝度
- $\sigma_x, \sigma_y$:局所領域内の標準偏差
- $\sigma_{xy}$:局所領域内の共分散
- $C_1, C_2$:安定化のための小さな定数
(一般的な値の例:$C_1 = (0.01 \times 255)^2$、$C_2 = (0.03 \times 255)^2$)
実際の評価では、11×11 程度のガウス窓でスライディングしながら計算し、全領域の平均値(MSSIM)を使用することが一般的です。
6.3. LPIPS (Learned Perceptual Image Patch Similarity; 知覚的類似度)
人間の知覚に近い距離指標です。値が小さいほど良いとされます。
厳密な単一の閉形式式は存在しませんが、計算の流れは以下の通りです:
- 元画像 $I$ と再構成画像 $\hat{I}$ を、事前学習済みの CNN(主に VGG または AlexNet)に通す
- 複数の中間層から特徴マップ $\phi_l(\cdot)$ を抽出する
- 各層でチャンネル方向に L2 正規化を行い、学習された重み $w_l$ をかけて L2 距離を計算する
- 全層の距離を合計(または平均)する
\text{LPIPS} \approx \sum_{\ell} w_{\ell} \cdot \left\| \hat{\phi}_{\ell}(I) - \hat{\phi}_{\ell}(\hat{I}) \right\|_2 \quad \text{(空間平均済み)}
6.4. FID (Fréchet Inception Distance)
生成画像の分布と実画像の分布の距離を測ります。値が小さいほど良いとされます。
計算式:
\text{FID} = \|\mu_r - \mu_g\|^2 + \operatorname{Tr}\left( \Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2} \right)
- $\mu_r, \Sigma_r$:実画像セットの Inception-v3 特徴(pool3 層、2048 次元)の平均ベクトルと共分散行列
- $\mu_g, \Sigma_g$:生成画像セットの同じ特徴の平均ベクトルと共分散行列
通常、数千枚以上の画像を用いて統計的に安定した値を求めます。
Perception-Distortion Tradeoff (Blau et al., 2018)
ピクセルレベルで正確に再現しようとすると(PSNR や SSIM を高くしようとすると)、逆に自然で魅力的な画像から遠ざかってしまうというトレードオフが理論的に証明されています。
そのため、最近の優れた超解像モデル(特に GAN や拡散モデルを用いたもの)は、PSNR を多少犠牲にしても LPIPS や FID を改善する方向を選ぶことが多くなっています。