自分用OpenCV備忘録(気が向けば今後追記していく)
本文中の各リンクはOpenCVチュートリアルページに飛ぶ。
画像は適当に拾ってきたフリー画像。
import cv2
import numpy as np
"""
ここに各コードを記述する
"""
# キー押したら描画画面を閉じる
cv2.waitKey(0)
cv2.destroyAllWindows()
描画関係
描画_opencv
線の太さは特に指定する必要ないが見やすさのため太くしている。
他にも線の種類などの設定もある。
# ベースの画像を作る(どちらでも)
#img = np.zeros((500, 500, 3),np.uint8)
img = np.full((500, 500, 3), 128, np.uint8)
# 線を引く(img, 始点座標, 終点座標, 色, 線の太さ)
cv2.line(img, (150, 50), (400, 400), (0, 0, 255), thickness = 3)
# 矩形(img, 左上頂点座標, 右下頂点座標, 色, 線の太さ)
cv2.rectangle(img, (100, 50), (400, 400), (255, 0, 0), 5)
# 円(img, 中心座標, 半径, 色, 線の太さ(-1:塗りつぶし))
cv2.circle(img, (250,250),80,(0,255,0), -1)
# 矢印(img, 始点座標, 終点座標, 色, 線の太さ)
cv2.arrowedLine(img, (50, 80), (125, 130), (0, 255, 0), 10)
# 楕円(img, 中心座標, 各方向の長さ(径), 色, 線の太さ)
cv2.ellipse(img, ((150, 150), (30, 160), 0), (0, 255, 255), 5)
# 円弧(img, 始点座標, 各方向半径, 円弧角度, 始まり角度, 終わり角度, 色, 線の太さ)
cv2.ellipse(img, (200, 400), (50, 30), 0, 0, 270, (255, 255, 255), 3)
# マーカー(img, マーカー中心座標, 色, マーカーのタイプ, マーカーサイズ)
cv2.drawMarker(img, (350, 200), (0, 255, 255), markerType = cv2.MARKER_STAR, markerSize = 30)
cv2.drawMarker(img, (350, 250), (0, 255, 255), markerType = cv2.MARKER_TILTED_CROSS, markerSize = 30)
# 折れ線(img, 各頂点座標, Trueで始点と終点を繋げる, 色, 線の太さ)
polylinecoord = np.array([[300, 100], [300, 150], [350, 125]])
cv2.polylines(img, [polylinecoord], False, (255, 255, 255), 2)
# 多角形(img, 各頂点座標, 色)
pts = np.array(((350, 50), (350, 100), (400, 75)))
cv2.fillPoly(img, [pts], (255, 255, 255))
# 凸な多角形を描画(fillPolyとほぼ同じ?だが凸面用)
pts = np.array([[80, 80], [100, 100], [120, 100], [150, 90], [120, 50]])
cv2.fillConvexPoly(img, pts, color = (0, 255, 0))
# テキストを書く(img, テキスト, フォント, サイズ, 色, 文字太さ)
cv2.putText(img, 'Deep Learning', (150, 450), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 255, 255), 2)
# 画像表示
cv2.imshow('img', img)
実行結果

画像を読み込めばその上に描画ができる。
# 画像読み込み
img = cv2.imread('./irasutoya.png')
# テキストを書く
cv2.putText(img, 'AI*HUMAN', (125, 350), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 3)
# 頑張ってハートを作る
cv2.ellipse(img, (197, 160), (10, 10), 180, -10, 160, (0, 255, 0), 2)
cv2.ellipse(img, (213, 160), (10, 10), 180, 20, 190, (0, 255, 0), 2)
pts = np.array([[187, 163], [205, 185], [222, 163]])
cv2.polylines(img, [pts], False, (0, 255, 0), 2)
cv2.imwrite('./pic1.png', img)
cv2.imshow('img', img)


OpenCVでは日本語入力に対応していないため、どうしても日本語を入れたい場合はPILライブラリを用いて入力できる。(Qiita内にも投稿複数あり)
変換関係
フリップ(反転)
# 画像読込
img = cv2.imread('./irasutoya2.png')
# 0:上下反転, 1:左右反転, -1:対角反転
img_flip1 = cv2.flip(img, 0)
img_flip2 = cv2.flip(img, 1)
img_flip3 = cv2.flip(img, -1)
# 画像をまとめる
img_flip_all = np.hstack((img, img_flip1, img_flip2, img_flip3))
# 画像を保存、表示
cv2.imwrite('./pic1.jpg', img_flip_all)
cv2.imshow('pic1', img_flip_all)
左から順に[元画像], [上下反転], [左右反転], [対角反転]

リサイズ
cv2でshapeで画像のピクセルを取得する際、PIL(size)の場合と(高さ、幅)の順番が異なるので注意。
# 画像読込
img = cv2.imread('./free_pic.jpg')
# 画像の縦横サイズ(縦、横、3(BGR))を取得
height = img.shape[0]
width = img.shape[1]
# リサイズ (リサイズカッコ内は横、縦)
img_resize1 = cv2.resize(img, (int(width*0.5), int(height*0.5)))
# 上記はこのコードでも同じ
# img_resize1 = cv2.resize(img, None, fx=0.5, fy=0.5)
img_resize2 = cv2.resize(img, (int(width*0.8), int(height*0.3)))
img_resize3 = cv2.resize(img, (500, 500))
cv2.imshow('pic0', img)
cv2.imshow('pic1', img_resize1)
cv2.imshow('pic2', img_resize2)
cv2.imshow('pic3', img_resize3)
左上から右下に向かって順に[元画像], [0.5width, 0.5height], [0.8width, 0.3height], [500, 500]
縦横どちらも0.5倍したものはアスペクト比は同じだがピクセル数が半分になっている。
元画像は(縦1280px, 横1920px), 概ね各サイズ比に合わせて表示している。




リサイズを使ってモザイク処理もできる。
以下のコードではリサイズを用いて画像を縮小した後、元のサイズに戻している。
画像サイズを戻す際、"interpolation = cv2.INTER_NEAREST"とすることできれいに補完されてしまうことを防ぐ。
# 画像読込
img = cv2.imread('./free_pic.jpg')
# 画像の縦横サイズ(高さ、幅、3(BGR))を取得
height = img.shape[0]
width = img.shape[1]
# 画像サイズを縮小した後、元サイズに戻すことでモザイク処理
img_resize_small = cv2.resize(img, (int(width*0.1), int(height*0.1)))
img_resize_return = cv2.resize(img_resize_small, (width, height), interpolation = cv2.INTER_NEAREST)
# 保存と描画
cv2.imwrite('./pic1.jpg', img_resize_return)
cv2.imshow('img', img_resize_return)
縮小サイズを小さくすればするほど戻した時のモザイク具合は大きくなる。
左から順に[元画像], [上記コード], [上記コードのinterpolation指定無ver]。



回転
# 画像読み込み
img = cv2.imread('./free_pic.jpg')
# 画像の縦横サイズを取得
height = img.shape[0]
width = img.shape[1]
#回転の中心定義
center = (int(width/2), int(height/2))
# 回転(中心座標、回転角度、スケール)
rot60 = cv2.getRotationMatrix2D(center, 60, 1.0)
#アフィン変換, warpAffine内最後の(width, height)は変換後画像サイズ
img_rot = cv2.warpAffine(img, rot60, (width, height))
# 画像の保存と表示
cv2.imwrite('./pic1.jpg', img_rot)
cv2.imshow('img', img_rot)
元の画像の中心部を中心に60度回転している。

射影変換
# 画像読込
img = cv2.imread('./free_pic.jpg')
# 画像の縦横サイズを取得
height = img.shape[0]
width = img.shape[1]
# 変換する前の座標
p1 = np.array([0, 0])
p2 = np.array([0, width])
p3 = np.array([height, width])
p4 = np.array([height, 0])
img_before = np.float32([p1, p2, p3, p4])
# 変換後の座標
q1 = np.array([height/4, width/4])
q2 = np.array([0, width])
q3 = np.array([height - height/4, width - width/4])
q4 = np.array([height, 0])
img_after = np.float32([q1, q2, q3, q4])
# 射影変換
perspective_mtx = cv2.getPerspectiveTransform(img_before, img_after)
img_perspective = cv2.warpPerspective(img, perspective_mtx, (width, height))
# 保存と表示
cv2.imwrite('./pic1.jpg', img_perspective)
cv2.imshow('pic1',img_perspective)
座標(0,0)ピクセルが変換後には(height/4, width/4)の位置に移動する感じ。
(サイズの関係で見切れていてわかりにくいが)

トリミング
# 画像の読込
img = cv2.imread('./free_pic.jpg')
# 画像の縦横サイズを取得
height = img.shape[0]
width = img.shape[1]
# 中心定義
center = (int(width/2), int(height/2))
#トリミング(画像中心から上下左右に400ピクセルの範囲)
img_tri = img[center[0] - 400:center[0] + 400, center[1] - 400:center[1] + 400]
# 保存と描画
cv2.imwrite('./pic1.jpg', img_tri)
cv2.imshow('pic1', img_tri)
画像中央部が切り取れた。

色関係
グレースケール化
画像読み込み時に" cv2.IMREAD_GRAYSCALE"で白黒になる。
# 画像を読み込むときに白黒指定
img_gray = cv2.imread('./free_pic.jpg', cv2.IMREAD_GRAYSCALE)
カラー画像に対して"cv2.COLOR_RGB2GRAY"でも可。
# カラー画像として読み込んだ後に白黒に変換
img = cv2.imread('./free_pic.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
閾値処理
閾値処理
閾値処理はある値より大きければ1, 小さければ0みたいな処理。
大きく分けて大域的二値化処理"threshold"と適応的二値化"adaptiveThreshold"がある。
大域的処理では画像全体に対し同じ閾値を用いて処理を行うが、適応的処理では画像内の小領域ごとに閾値を計算するため、影や照明などによってムラがある画像に対して有効である。
第4引数の閾値処理種類によって結果の感じが変わる。
他にも"cv2.inRange"を使えばある値からある値までの範囲を閾値として設定することができる。
# 画像読み込み
img_gray = cv2.imread('./free_pic2.jpg', cv2.IMREAD_GRAYSCALE)
# threshold(img, 閾値, 閾値処理の最大値, 閾値種類), 出力は2つ。retは大津の二値化を行う場合に用いる。
ret,thresh = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
# adaptiveThreshold(img, 閾値処理の最大値, 適応的閾値アルゴリズム(2種類ある), 閾値種類, x近傍領域, y近傍領域)
thresh = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, 7)
左から順に[元画像], [threshold], [adaptiveThreshold]。
画像内に明暗がある場合は適応的処理の"adaptiveThreshold"がよさそう。


色反転
# 色反転
img_rev = cv2.bitwise_not(img)

輝度平滑化
輝度の平滑化はグレースケール画像にのみ適用可。
# 輝度平滑化
img_equal = cv2.equalizeHist(img)
順に[元画像], [輝度平滑化]。


フィルタ処理(平滑化とか)
平滑化_opencv
平滑化は特定のピクセルを周囲のピクセルの平均など(輝度、色)で均す処理。
カーネルサイズで範囲は指定。
カーネルサイズが大きいほどぼやける感じ。
ブラー処理
指定したカーネルサイズの領域の平均で平滑化。
"cv2.boxFilter()"でも同様の処理。
# ブラー処理(カーネルサイズを指定)
img_blur = cv2.blur(img, (10, 10))
順に[元画像], [blur(カーネルサイズ10×10)], [blur(カーネルサイズ30×30)]。



メディアン処理
指定したカーネルサイズの領域の平均で平滑化。中央値で決めるため、第2引数は奇数のこと。
ごま塩のようなノイズに有効とのこと(平滑化リンク先参照)。
# メディアンブラー処理(カーネルサイズは奇数)
img_medianblur = cv2.medianBlur(img, 11)
順に[元画像], [medianblur(カーネルサイズ11×11)], [medianblur(カーネルサイズ31×31)]。


ガウシアン平滑化
周囲のピクセルまでの距離に重みを持たせる。
カーネルサイズは縦横ともに奇数であること。
# ガウシアンブラー処理(img, カーネルサイズ, 横方向標準偏差, 縦方向標準偏差)
img_gaussianblur = cv2.GaussianBlur(img, (11, 13), 15, 15)
順に[元画像], [gaussianblur(上記パラメータ)]。

画像の膨張と収縮
モルフォロジー処理_opencv
画像の膨張や収縮といったモルフォロジー処理を組み合わせることでノイズ除去ができる。
膨張はカーネルサイズ内の一番輝度の高い画素を選び、収縮はカーネルサイズ内の一番低い画素が選ばれる。
# カーネルサイズ
kernel = np.ones((4,4),np.uint8)
# 収縮, "itaratuins"は処理回数
img_erode = cv2.erode(img, kernel, iterations = 1)
# 膨張, "itaratuins"は処理回数
img_dilate = cv2.dilate(img, kernel, iterations = 1)
左から順に[元画像], [収縮], [膨張]。
女性の顔や服を見ると収縮では暗くなっており、膨張では明るくなっていることがわかる。



収縮後に膨張を行うことをオープニング、また膨張後に収縮を行う処理をクロージングと呼び、ノイズの除去に使われる。(わかりやすい例はモルフォロジー処理_opencvのリンク先)
# オープニング
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
# クロージング
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
オブジェクト除去
オブジェクト除去_opencv
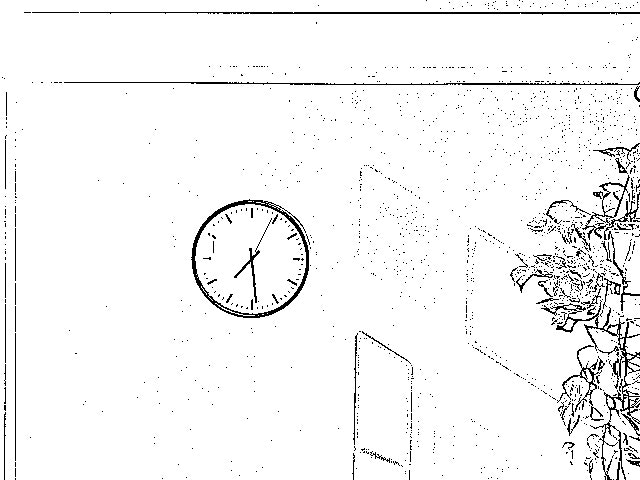
先ほどの壁掛け時計画像に対し、マスク画像を用いて時計を削除する。
マスク画像は削除したいオブジェクトの領域を指定するためのもの。
# 画像とマスク画像読み込み
img = cv2.imread('./free_pic2.jpg')
mask = cv2.imread('./mask.jpg', cv2.IMREAD_GRAYSCALE)
# inpaint(img, マスク画像, 修復される点周りの半径, 修復手法)
img_mask = cv2.inpaint(img, mask, 1, cv2.INPAINT_TELEA)
# 保存と表示
cv2.imwrite('./img_mask.jpg', img_mask)
cv2.imshow('img_mask',img_mask)
左から順に[元画像], [マスク画像], [時計の除去結果]



マスク画像は下記コードで作成した。
# マスク画像生成
mask = np.zeros((480, 640, 3),np.uint8)
cv2.rectangle(mask, (180, 180), (320, 320), (255, 255, 255), -1)
cv2.imwrite('./mask.jpg', mask)
今回は事前に時計の領域を確認しながらマスク画像を作成したが、オブジェクト検出APIなどを使えばより簡単に同様の処理が行えるだろうと思う。
またAPIを用いなくとも、下記の例では閾値処理を用いて比較的簡単にマスク画像を作ることができる。
# 画像読込
img = cv2.imread('./free_pic.jpg')
# 画像を汚す
cv2.line(img, (150, 50), (400, 400), (255, 255, 255), thickness = 3)
cv2.rectangle(img, (900, 800), (1000, 900), (255, 255, 255), -1)
cv2.circle(img, (1250,550),80,(255,255,255), 1)
cv2.circle(img, (1250,250),80,(255,255,255), 3)
cv2.putText(img, 'Deep Learning', (200, 450), cv2.FONT_HERSHEY_SIMPLEX, 5.0, (255, 255, 255), 2)
cv2.putText(img, 'Deep Learning', (200, 850), cv2.FONT_HERSHEY_SIMPLEX, 5.0, (255, 255, 255), 4)
# 保存
cv2.imwrite('./img_defile.jpg', img)
# 閾値処理でマスクを作る
mask = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
ret, mask = cv2.threshold(mask, 250, 255, cv2.THRESH_BINARY)
# 上手く線が除去できない場合はマスク画像を膨張させ、マスク領域を拡大するなどの工夫がある
# kernel = np.ones((4, 4), np.uint8)
# mask = cv2.dilate(mask, kernel)
# マスク画像での除去実行
img_mask = cv2.inpaint(img, mask, 1, cv2.INPAINT_TELEA)
# 保存と表示
cv2.imwrite('./automask.jpg', mask)
cv2.imwrite('./img_mask.jpg', img_mask)
cv2.imshow('img_mask', img_mask)
左から順に[適当に汚した画像], [生成されたマスク画像, [除去結果]。
除去する領域の周りのピクセル情報から除去するため、広い領域の除去の場合違和感が残るが、線については綺麗に除去できている。



おわりに
OpenCVでは他にもオブジェクト検出や二つの画像を用いての処理、動画処理、多彩なAPIなどまだまだ多くの内容があり、今後学習する機会があれば追記したい。