はじめに
Amazon AppFlow はさまざまな SaaS アプリケーションや AWS サービス間でデータを簡単に転送できるサービスです。
AppFlow でサポートされるアプリケーションは順次追加されており、AWS サービスも含めると約 80 のコネクタが提供されています。また Custom Connector SDK を使用して独自のコネクタを開発することもできます。
2023/6/15 のアップデートで Amazon AppFlow に Google BigQuery コネクタが追加されました。
データソース、データの宛先、どちらのユースケースにも対応しています
- データソースとして BigQuery から他のサービスにデータを転送する
- データの宛先としてデータを他のサービスから BigQuery へ転送する
やってみる
シンプルなパターンとして Google BigQuery から Amazon S3 へのデータフローを作成してみます。
BigQuery をデータソースとする場合、宛先として指定できるサービスには制限がありますのでご注意ください。
When you create a flow that uses Google BigQuery as the data source, you can set the destination to any of the following connectors:
- Amazon Honeycode
- Amazon Lookout for Metrics
- Amazon Redshift
- Amazon RDS for PostgreSQL
- Amazon S3
- HubSpot
- Marketo
- Salesforce
- SAP OData
- Snowflake
- Upsolver
- Zendesk
- Zoho CRM
データの準備
BigQuery 側に以下のようなテーブルとデータを準備しました。
詳細は後述しますが、2023 年 7 月時点で今回のサンプルデータの ADDRESS フィールドのようなネストされたデータの取得は未サポートでした。
スキーマ

データ

OAuth クライアントの作成
AppFlow が BigQeury にアクセスできるようにするため、事前に Google Cloud 側で OAuth クライアント ID を作成しておく必要があります。
Google Cloud コンソールの「API とサービス」から認証情報へ進み、OAuth クライアント ID を新規作成します。

以下を設定し、OAuth クライアント ID を作成します。
- アプリケーションの種類はウェブ アプリケーションとし、任意の名前を入力します
- 承認済みの JavaScript 生成元には
https://console.aws.amazon.comを入力します - 承認済みのリダイレクト URI には
https://<region>.console.aws.amazon.com/appflow/oauthを設定します-
<region>は使用する AppFlow のリージョンコードに書き換えてください
-

OAuth クライアント ID には適切な Scope を追加する必要があります。以下のドキュメントを参考に BigQuery API v2 のアクセスに必要な Scope を追加します。
| スコープ | 説明 |
|---|---|
| https://www.googleapis.com/auth/bigquery | View and manage your data in Google BigQuery and see the email address for your Google Account |
| https://www.googleapis.com/auth/bigquery.insertdata | Insert data into Google BigQuery |
| https://www.googleapis.com/auth/cloud-platform | See, edit, configure, and delete your Google Cloud data and see the email address for your Google Account. |
| https://www.googleapis.com/auth/cloud-platform.read-only | View your data across Google Cloud services and see the email address of your Google Account |
| https://www.googleapis.com/auth/devstorage.full_control | Manage your data and permissions in Cloud Storage and see the email address for your Google Account |
| https://www.googleapis.com/auth/devstorage.read_only | View your data in Google Cloud Storage |
| https://www.googleapis.com/auth/devstorage.read_write | Manage your data in Cloud Storage and see the email address of your Google Account |
API とサービスの OAuth 同意画面からスコープを追加します。今回は検証のためすべてのスコープを追加したのですが、BigQuery を宛先としてデータの書き込みを行わない場合は Write 系の Scope は不要と思われます。
接続の作成
AppFlow コンソールの接続で Google BigQuery コネクタを選択し、接続の作成をクリックします。

以下の項目を設定し、新規の接続を作成します。
- 任意の接続名を入力します
- access_type は
offlineのみ選択できます - 作成した OAuth クライアントのクライアント ID およびクライアントシークレットを入力します
- 必要に応じて KMS キーによるデータ暗号化を設定することもできます

接続するをクリックすると、Google の画面に遷移しますのでアクセスリクエストを許可します。

正常に接続が作成できたらフローの作成に進みます。
フローの作成
AppFlow コンソールのフローから新規のフローを作成します。
フローの詳細で任意のフロー名と説明を入力します。必要に応じて KMS キーによるデータ暗号化やタグを設定することもできます。
送信元の詳細を以下のように設定します
- 送信元名で Google BigQuery コネクタを選択します
- 接続の選択で先ほど作成した接続を選択します
- オブジェクトの選択では
Tableのみ選択できます - サブオブジェクトの指定で接続するプロジェクト、データセット、テーブル名をそれぞれ選択します
- Data transfer settings はデフォルトの
Automaticのままとしました

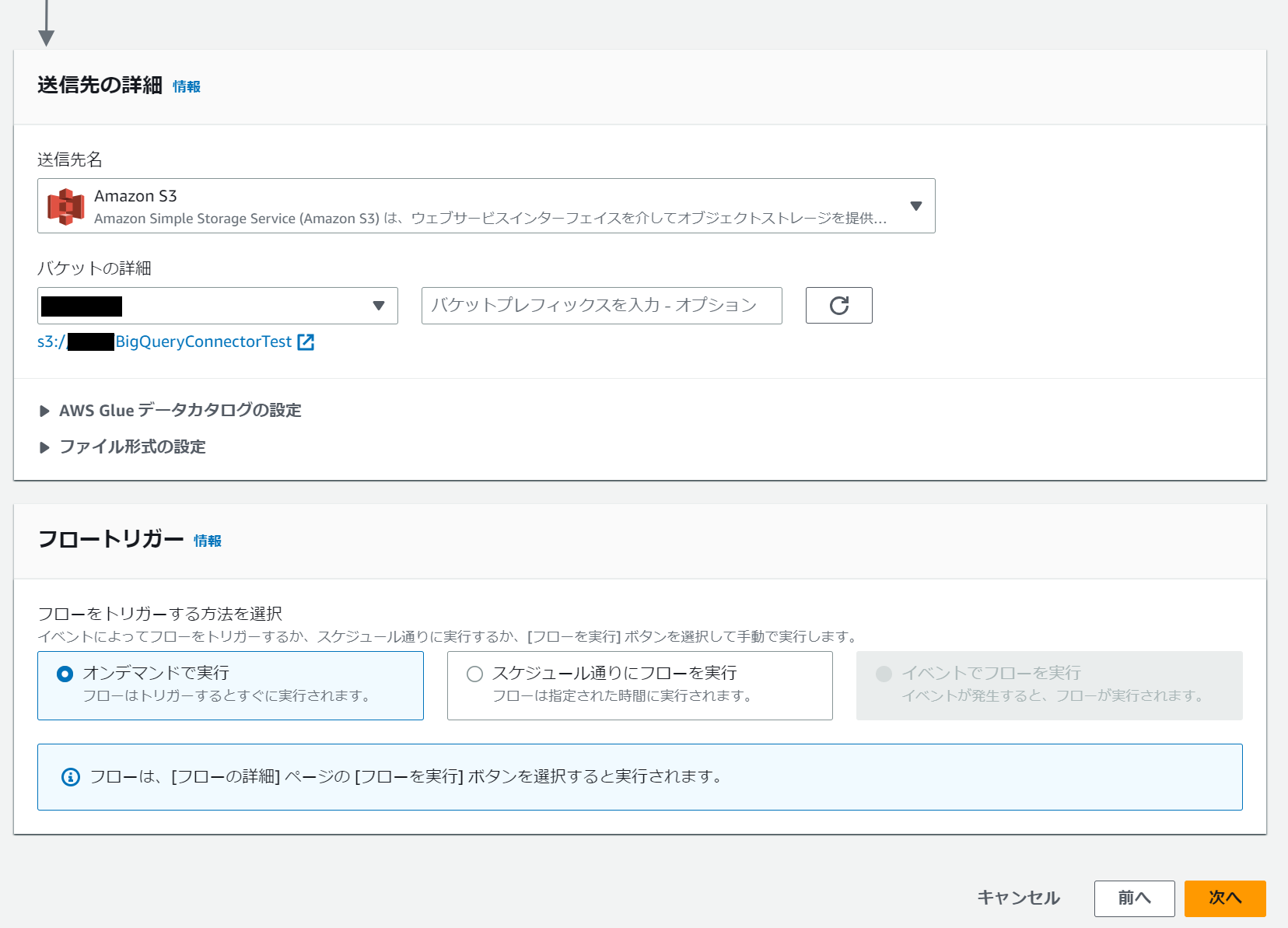
送信先の詳細で Amazon S3 を選択し、宛先となる S3 バケットの情報を入力します。オプションで AWS Glue Data Catalog へのテーブル登録やファイル形式の設定を行うことができます。今回はデフォルトのままデータカタログへの登録なし、JSON 形式での出力としています。
検証目的でスケジュール実行する必要がないため、フロートリガーはオンデマンドを選択しました。
データフィールドのマッピングではすべてのフィールドを直接マッピングしています。

パーティションを集約の設定はお好みで選択し、次に進みます。今回は実行 ID をパーティションとし、集約の設定は行いませんでした。

AppFlow ではデータフィールドにフィルターを追加することでフィルター条件を満たすレコードのみを転送することができますが、今回は特に追加せずそのまま次へ進みます。

確認画面で設定内容を確認し、フローの作成を完了します。
フローの実行とトラブルシューティング
動作確認を行うため。作成済みのフローからフローの実行をクリックします。

少し待つと、フローの実行がエラーになってしましました![]()

Amazon AppFlow received the following error:
The request failed because the service Source Google BigQuery returned the following error: Details: The request failed with status code 400 (Bad Request)., ErrorCode: ClientError.
AppFlow のエラーメッセージでは BigQuery 側からステータスコード 400 (Bad Request) が返り、リクエストが失敗したことしかわかりませんでした。このような場合の原因調査は Google Cloud 側で行う必要があります。
Cloud Logging で Big Query API 実行時のエラー詳細が確認できます。

Field <フィールド名> from table <テーブル名> is not a leaf field. Consider using SQL, which allows selecting non-leaf fields.
上記のエラーメッセージをもとに AWS Support に問い合わせをおこなったところ、2023 年 7 月時点でネストされたデータの取得は未サポートということがわかりました。
そのためフローを編集し、ADDRESS フィールドのマッピングを削除した上で再度実行してみます。

今度は正常に実行されました!

S3 バケットにファイルが出力されていることが確認できます。

冒頭で準備したデータが BigQuery から JSON 型式で取得できていました。
{"FIRST_NAME":"Jeff","LAST_NAME":"Smith","DATE_OF_BIRTH":"1980-10-10"}
{"FIRST_NAME":"Charlotte","LAST_NAME":"Lalande","DATE_OF_BIRTH":"1990-01-01"}
まとめ
AppFlow に BigQuery コネクタが追加されたことにより、BigQuery とのデータ連携が簡単に実装できるようになりました。対応するサービス間で双方向のフローを作成できるのは大きなメリットだと感じます。AWS 側から Google BigQuery のデータを取得するという観点では、これまでも Amazon Athena でデータソースコネクタが提供されていましたが、より手軽さや柔軟性が増したのではないかと思います。
参考
以上です。
参考になれば幸いです。