はじめに
OpenSearch 2.17 以降でディスクベースのベクトル検索 (ディスク最適化ベクトル) が利用可能になりました。Amazon OpenSearch Serverless でも 2025 年 9 月のアップデートでサポートされています
本機能を使用することでベクトル検索コレクションを利用するときのメモリ使用量を低減できます。Amazon Bedrock Knowledge Bases × OpenSearch Serverless の構成でも本機能が問題なく使用できるか、そして実際にどの程度コスト削減効果が得られそうかを、それなりの規模のデータを同期した上で検証してみます。
なぜベクトル検索コレクションではメモリ消費が大きくなるのか
OpenSearch Serverless のベクトル検索コレクションの場合、近似 k-NN 検索のためのアルゴリズムは HNSW のみがサポートされています。HNSW アルゴリズムではベクトル同士のグラフ構造(どのノードがどのノードとつながっているか)とベクトル値自体をメモリに格納します。HNSW は探索中に複数のノードを高速にランダムアクセスする必要があるため、ベクトルデータとグラフ構造のすべてがメモリ内に存在する必要があります。
ベクトルコレクションタイプは、ベクトルグラフを RAM に格納し、インデックスをディスクに格納します。ベクトルコレクションはインデックスデータを OCU ローカルストレージに保持します。ベクトルワークロードのサイズを決める際は、両方のニーズを考慮する必要があります。OCU の RAM 上限は OCU のディスク上限よりも早く到達するため、ベクトルコレクションは RAM の容量に制限されます。
これにより大規模なデータセットに対してもミリ秒単位の高速な検索を実現していますが、そのトレードオフとして、ベクトル数と次元数に比例してメモリ消費が大きくなるという特徴があります。
ディスク最適化ベクトルの仕組み
前提としてこの仕組みの詳細については以下のブログが詳しいです。
ディスクベースのベクトル検索では量子化されたデータを使用してベクトルグラフを構築し、メモリに保存します。フル精度のベクトルデータはディスクに保存されるため、必要なメモリは大幅に少なくなります。
一般に量子化によって高い圧縮率を得る代わりに検索精度が低下しますが、ディスク最適化ベクトルでは量子化されたインデックスをクエリした後に、これらの候補のフル精度のベクトルデータをメモリに遅延ロードし、再計算をおこなっています。
この 2 段階アプローチにより、ある程度のレイテンシーを犠牲にしつつも高い精度を維持しています。
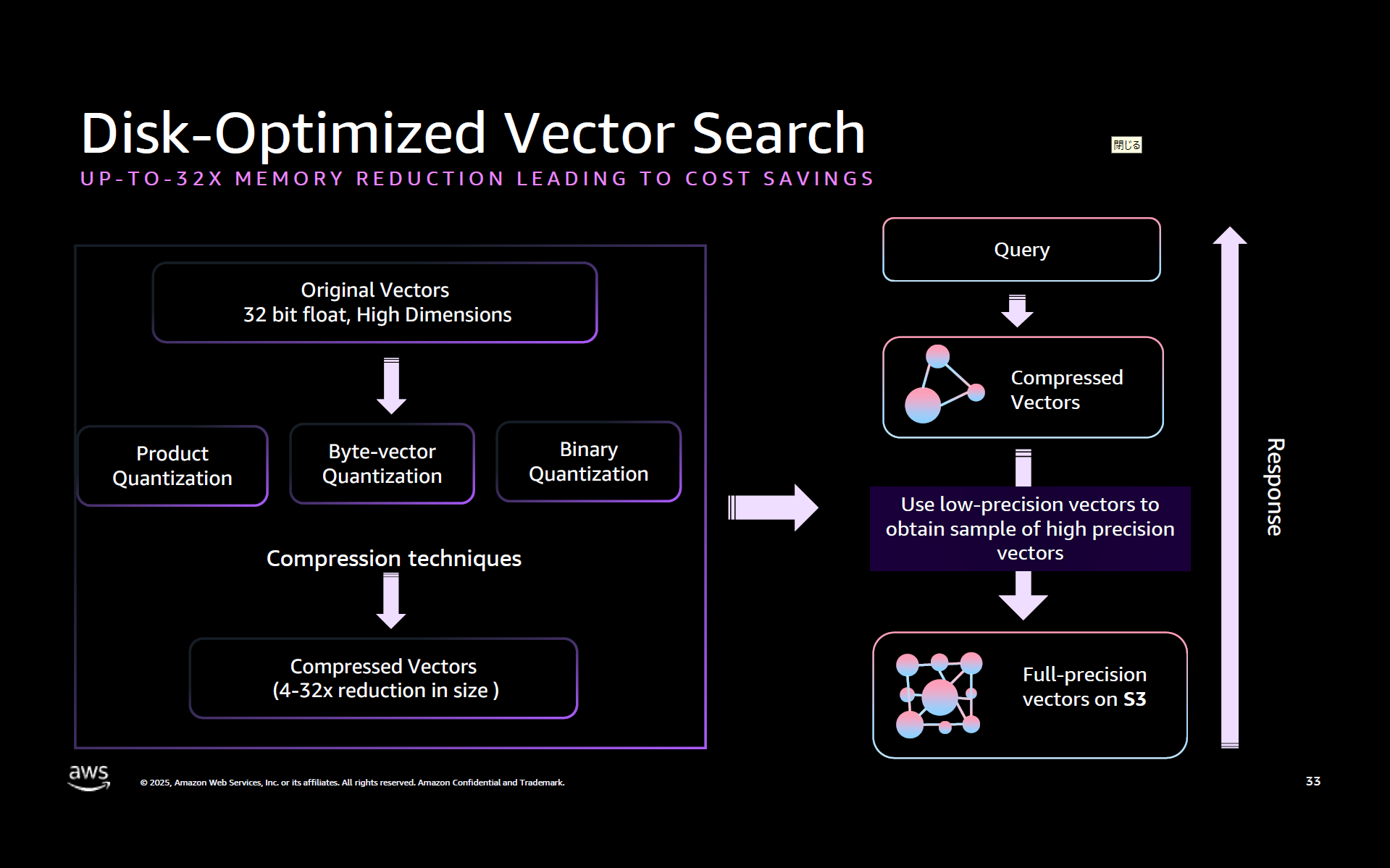
ANT201: What’s new in search, observability & vector databases with OpenSearch より引用
以下はコスト、検索精度、レイテンシーのトレードオフが解説されている資料です。ディスク最適化ベクトルは 1 桁または 2 桁ミリ秒でのレスポンスが不要で、100~300 ミリ秒のレイテンシーを許容できる要件の場合は大幅なコスト削減につながります。
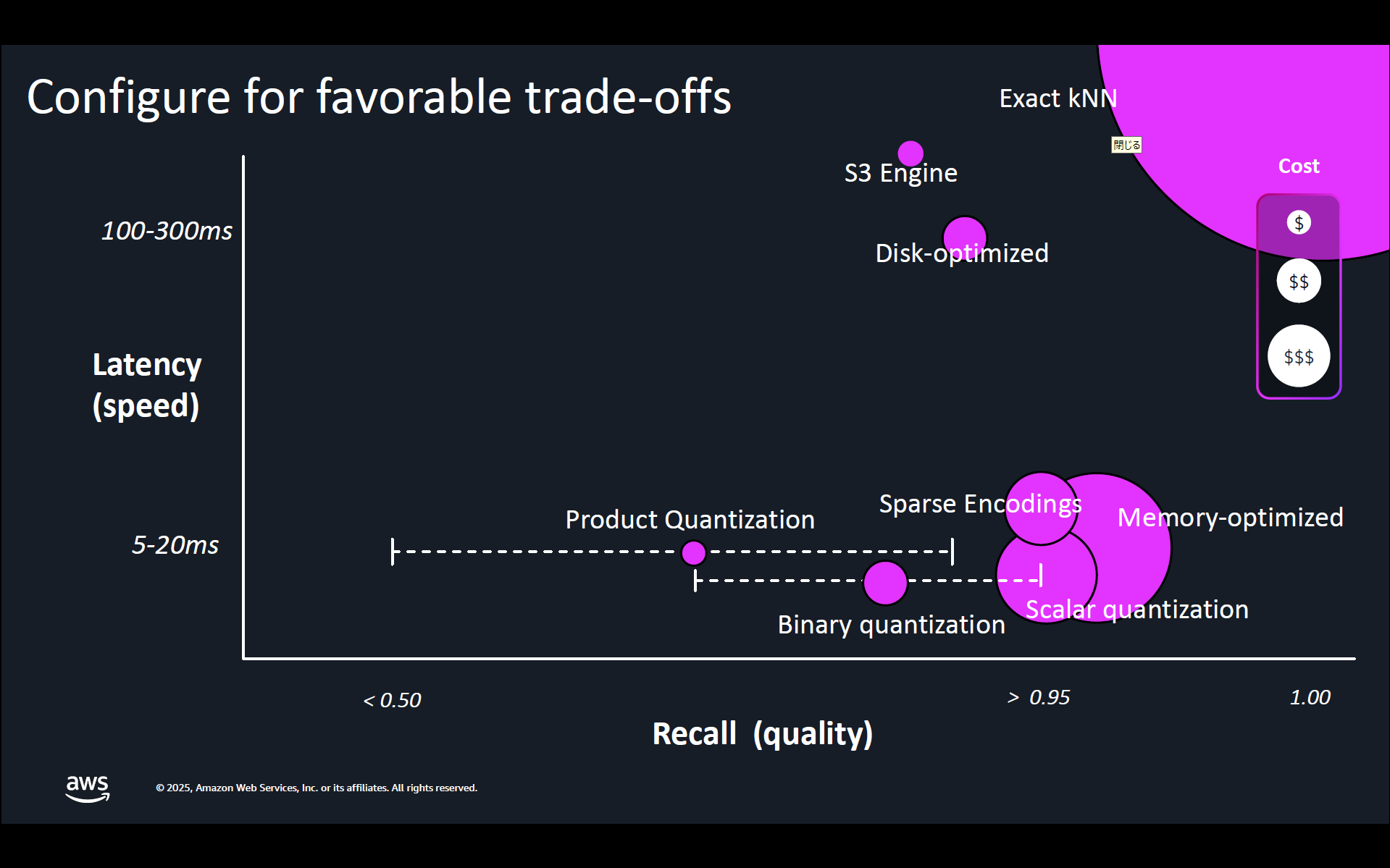
ANT213: Build GPU-boosted, auto-optimized billionscale VectorDBs in hours より引用
実際にやってみる
Amazon Bedrock Knowledge Bases × OpenSearch Serverless の構成で、ディスク最適化ベクトルの有効化有無でどれくらい Search OCU の使用量に差がでるかを検証してみます。
検証条件
データソース
| 項目 | 値 |
|---|---|
| 総ファイル数 | 17,431 |
| 合計サイズ | 791 MB |
| ファイルの種類 | すべてテキストファイル |
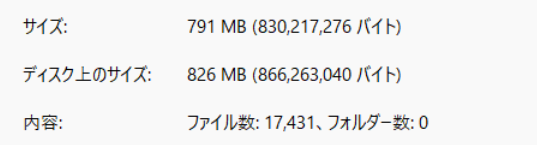
これらのファイルを単一の S3 バケットにアップロードしてナレッジベースに同期します。
Amazon Bedrock Knowledge Bases の設定
| 項目 | 値 |
|---|---|
| データソース | Amazon S3 |
| 解析戦略 | デフォルトパーサー |
| チャンキング戦略 | デフォルト |
| 埋め込みモデル | Amazon Titan Embedding v2 |
| 埋め込みタイプ | 浮動小数点ベクトル埋め込み |
| ベクトルの次元 | 1024 |
Amazon OpenSearch Serverless の設定
| 項目 | 値 |
|---|---|
| 冗長性 | 無効 |
メモリ最適化ベクトル (デフォルト)
ナレッジベース側でデータソース同期処理を実行し終了するまで待ちます。すべてのソースファールを正常に同期できました。実行にかかった時間は約 6 時間 (長い。。。)でした。

作成されたインデックスのサイズは 24.7 GB です。チャンク分割がおこなわれるため、最終的なドキュメント数は 1,381,927 でした。
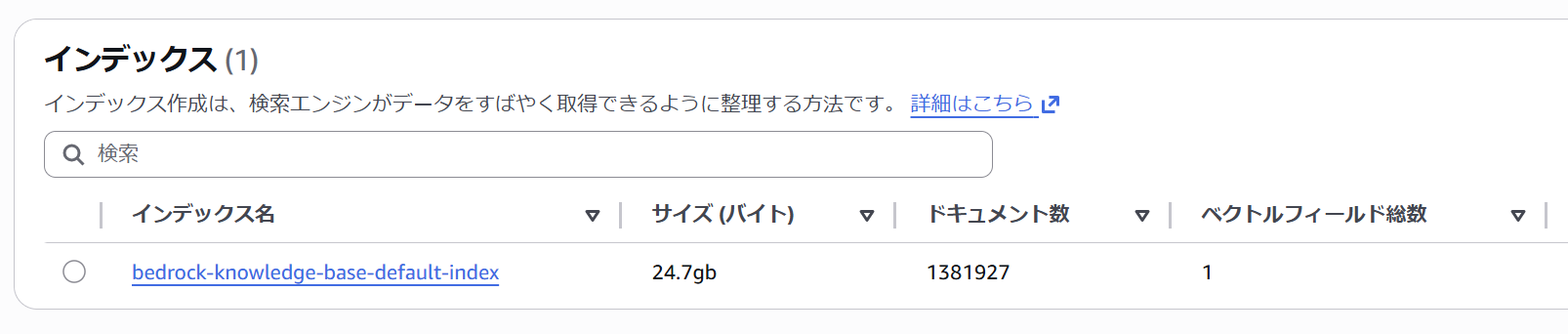
リソース消費をダッシュボードから確認すると Index OCU が 2、Search OCU 6 となっていました。東京リージョンの場合、月額約 $1,950 となり、なかなかのコストです。今回の検証では冗長性を無効化していますが、有効にした場合は更に倍の料金です。
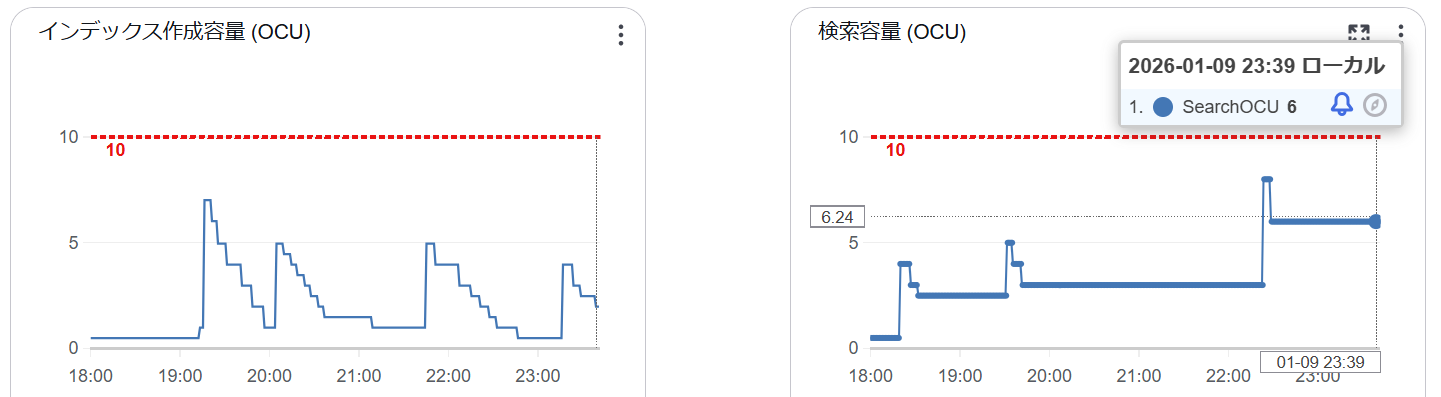
1 OCU あたりに割り当てられるメモリ容量は 6 GB なのですが、冒頭でも紹介したブログによれば、実際にベクトルグラフに使用されるのはこのうち 2 GB とのことです。
OpenSearch Serverless は、ベクトルコレクションに対して OCU リソースを次のように割り当てます。1 OCU では、オペレーティングシステムに 2 GB、Java ヒープに 2 GB、残りの 2 GB をベクトルグラフに使用します。OpenSearch インデックスには 120 GB のローカルストレージを使用します。ベクトルグラフに必要な RAM は、ベクトル次元、格納されるベクトル数、選択されたアルゴリズムによって異なります。
以下のブログにある計算式で今回のデータソースによるベクトルグラフのメモリ消費量も概算できそうです。
メモリ消費
HNSW は非常に優れた近似最近傍検索を低レイテンシーで実現できますが、大きなメモリを消費し得ます。HNSW の各グラフはおよそ1.1 * (4 * dimension + 8 * m) * num_vectorsバイトのメモリを消費します。
dimensionはベクトルの次元です。mはアルゴリズムのパラメータであり、1 つの層の中における各ノードの接続数を決めます。num_vectorsはインデックス内のベクトルの数です。
各値について補足すると以下のとおりです。
- 1.1: グラフ構造のオーバーヘッドの係数
- 4: ベクトルの数値1つあたりのバイト数(float32)
- dimension: ベクトル次元数
- m: グラフの接続数(デフォルト値 16)
- 8 byte をかけることでエッジ情報のメモリ消費量を算出
- num_vectors 格納されたドキュメント数
この計算式に今回の検証条件をあてはめてみると、ベクトルグラフのメモリ量は 約 6.1 GB ということになります。
1.1 \times (4 \times 1024 + 8 \times 16) \times 1,381,927 \approx 6.1\ GB
1 OCU あたりのベクトルグラフのメモリ割り当て量が 2 GB なので Search OCU は 4 OCU あれば足りそうなのではと思うかもしれません。私も思いました。
OpenSearch Serverless は予め決められたしきい値を元にスケーリングを自動的に行いますが、その値は公開されていません。状況から推測すると、恐らく 2 GB をフルで使い切るまえにスケーリングするのだと思われます。
ディスク最適化ベクトル
ナレッジベースのコンソールで OpenSearch Serverless を作成するとコレクションとインデックスまでセットで作成できてとても便利です。しかし自動作成されるインデックスはデフォルトのメモリ最適化ベクトル (in_memory モード) であるため、ここではナレッジベースでベクトルデータベースを選択する際に手動で作成済みのコレクションを指定しています。
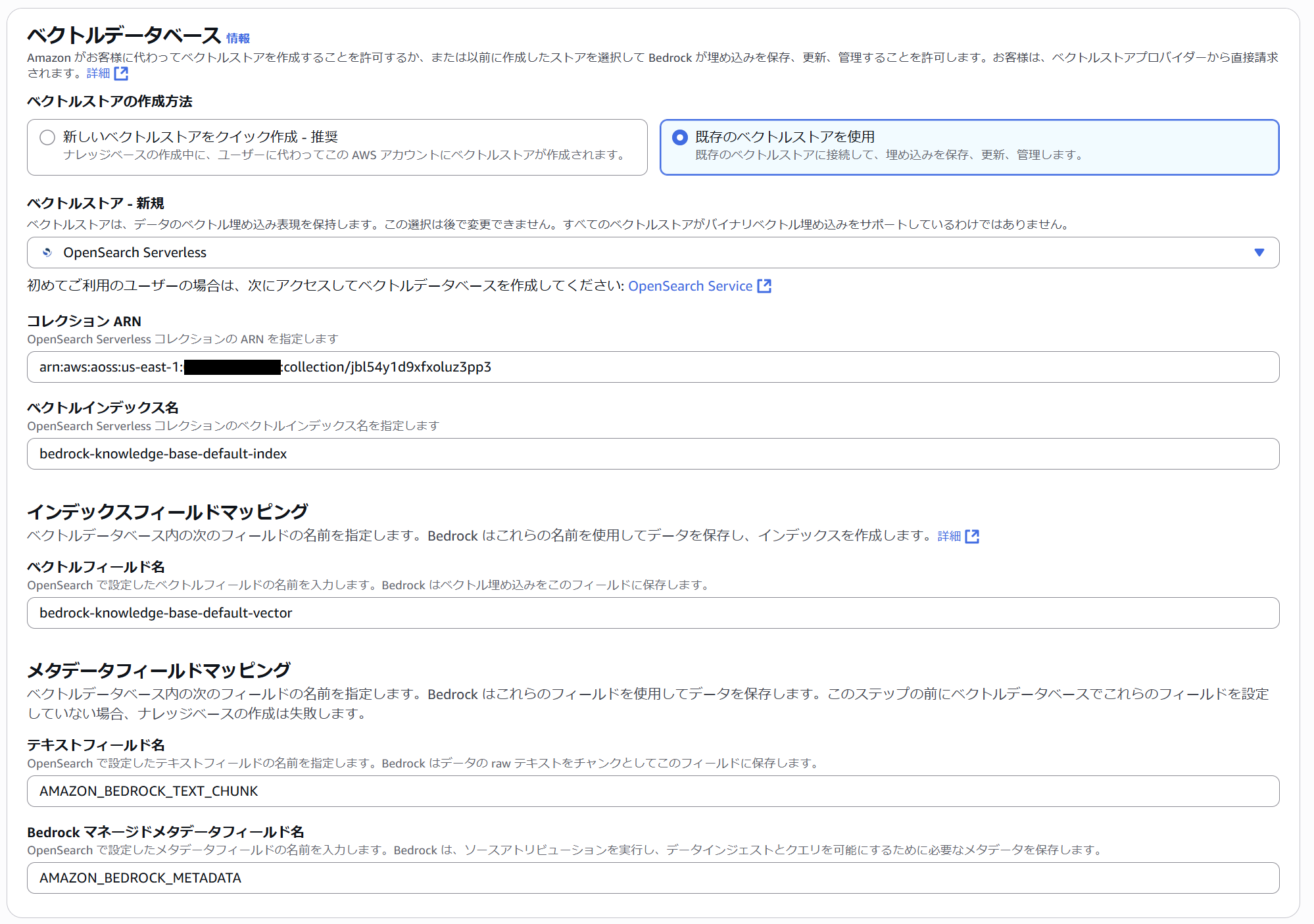
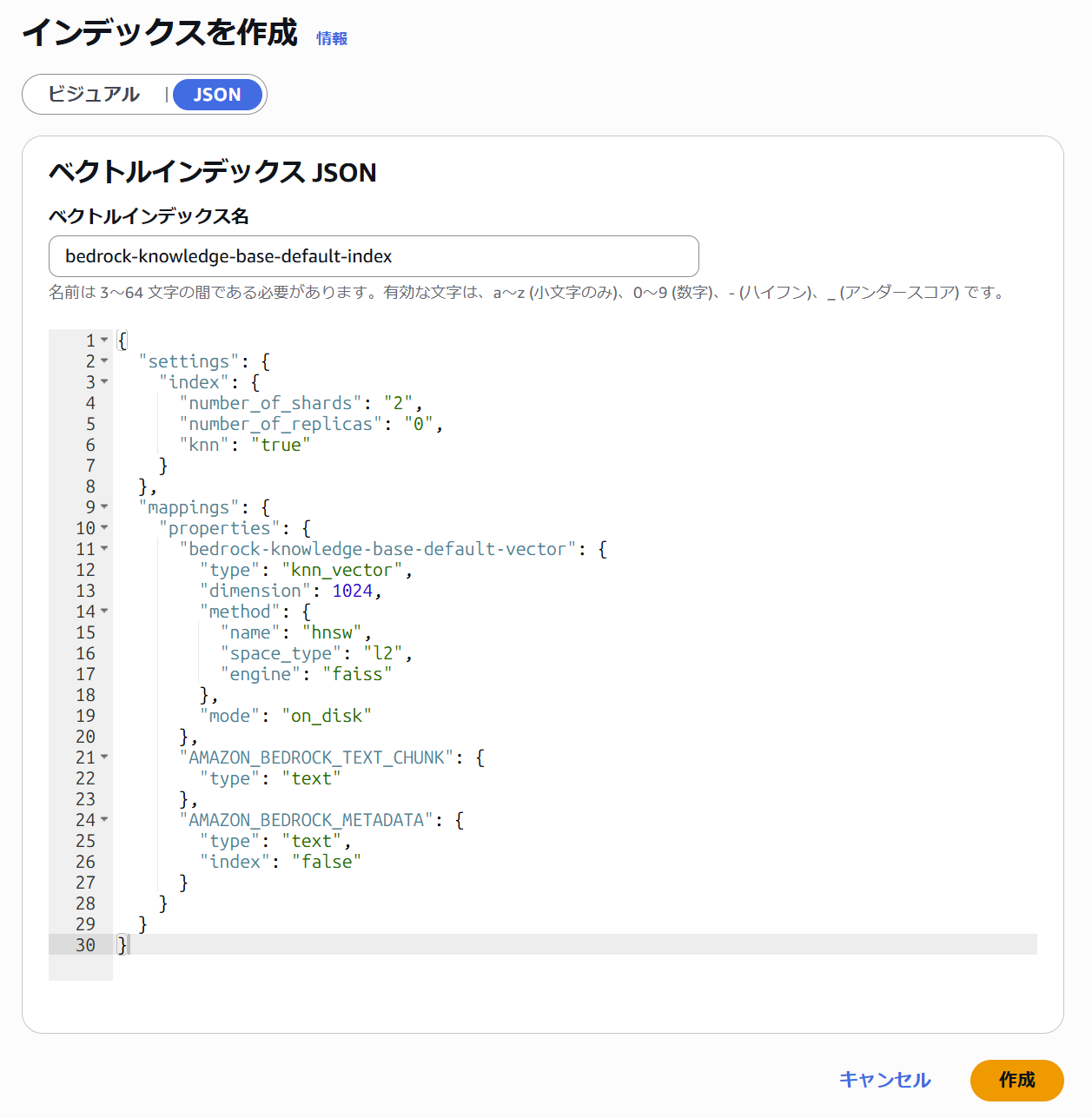
インデックスも手動で作成します。マネジメントコンソールのビジュアル UI ではディスク最適化ベクトル (on_disk モード) でのインデックス作成ができないため、JSON を指定して作成します。properties に "mode": "on_disk" を追加するだけです。簡単ですね。
{
"settings": {
"index": {
"number_of_shards": "2",
"number_of_replicas": "0",
"knn": "true"
}
},
"mappings": {
"properties": {
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "faiss"
},
"mode": "on_disk"
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text"
},
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": "false"
}
}
}
}
インデックスを作成したら先ほどと同じデータソースに対して同期処理を実行します。こちらも初回フル同期にかかった時間は 6 時間程度でしたので、in_memory と on_disk モードによる差はほとんどありませんでした。OpenSearch のインデックス化の処理よりも Bedrock 側の Embedding 生成処理がボトルネックになっているためと考えられます。

再度ダッシュボードからリソース消費状況を確認すると、結果は一目瞭然で、Index OCU および Search OCU の消費は最低サイズの 0.5 OCU に留まっています。最低料金の 1 OCU で運用できるため、1/8 という大きなコスト削減効果が見込めます。
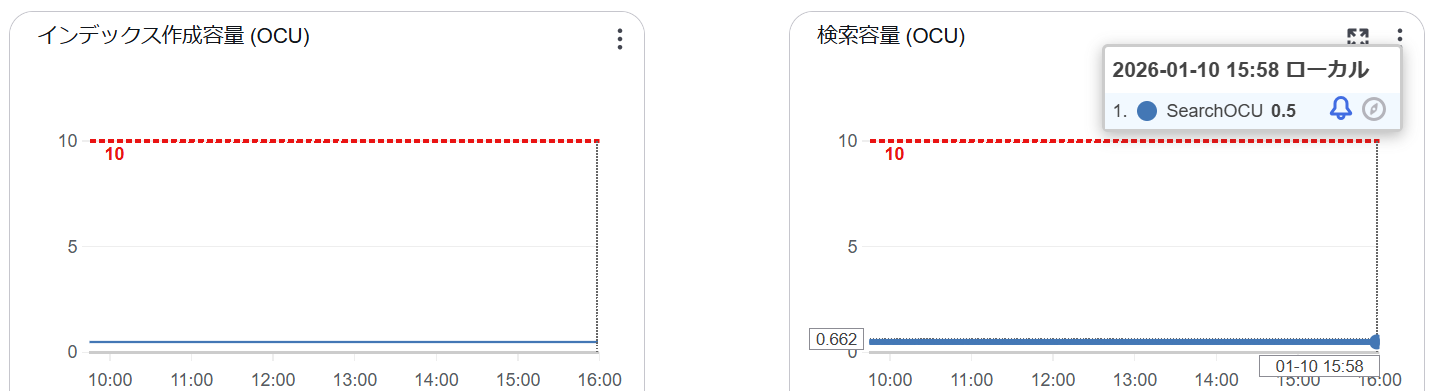
ディスク最適化ベクトル (on_disk モード) ではベクトルグラフ内には圧縮(量子化)されたベクトルを格納するため、メモリ消費だけでなくディスク上のインデックスサイズも削減されているようです。
デフォルトでバイナリ量子化 (1 次元あたり 1 bit) が適用され、圧縮率は 32 倍になります。そのため次元数を 8 で割ってメモリ消費量を計算します。(1 bit = 1/8 byte)
1.1 \times (dimension \div 8 + 8 \times m) \times num\_vectors
つまり、
1.1 \times (1024 \div 8 + 8 \times 16) \times 1,381,927 \approx 370\ MB
となるため、0.5 OCU でもメモリは足りているということになります。
参考: Managed Cluster の場合は?
今回は OpenSearch Serverless で検証しましたが、Managed Cluster においても基本的な考え方は同じです。ただし 各ノードで使用できるメモリ容量は 2 GB で固定ではなく、各ノードが備えるメモリ容量に応じて変化します。詳細は以下のブログを参照ください。
ベクトルの数
台のマシンに収まるベクトル数は、そのマシンのオフヒープメモリの可用量の関数で決まります。必要なノード数は、ノードごとにアルゴリズムで使用できるメモリ量と、アルゴリズムが必要とするメモリの総量に依存します。ノードが多いほど、メモリが増え、パフォーマンスが向上します。ノードごとに利用可能なメモリ量は、memory_available= (node_memory–jvm_size) *circuit_breaker_limitとして計算されます。パラメータの説明は以下の通りです。
node_memory– インスタンスの全メモリ容量。jvm_size– OpenSearch の JVM ヒープサイズ。これはインスタンス RAM の半分に設定され、約 32 GB で上限が設定されます。circuit_breaker_limit– サーキットブレーカーのネイティブメモリ使用量のしきい値。これは 0.5 に設定されます。
以上です。
参考になれば幸いです。